改進爬行動物搜索算法優(yōu)化ENN模型預測管道腐蝕速率
2023-11-23 10:56:00盧鵬飛王霄楊文博陳卓秦國偉
科學技術與工程 2023年30期
盧鵬飛,王霄,楊文博,陳卓,秦國偉
(1.長慶工程設計有限公司,西安 710018; 2.中國石油長慶油田分公司第一采氣廠,榆林 718500;3.西安石油大學石油工程學院,西安 710065)
管道運輸作為一種運輸量大、經(jīng)濟可控的方式被廣泛應用于現(xiàn)代工業(yè)。隨著管道“老齡化”程度加深,因腐蝕引起的管道失效造成的經(jīng)濟損失以及人員傷亡事故頻發(fā)[1]。因此,及時掌握管道的腐蝕情況并在管道失效前對存在的安全隱患進行排除,是確保管道安全運行的關鍵內(nèi)容[2-3]。目前關于管道腐蝕的研究有很多,其中管道腐蝕速率的預測一直是研究的重點。
迄今為止,中外學者對管道腐蝕情況預測方法進行了大量的研究。主要可歸納為概率統(tǒng)計法、可靠度函數(shù)分析法、灰色系統(tǒng)理論預測法、機器學習預測法等[4]。其中在管道腐蝕速率的預測研究中,機器學習預測法發(fā)揮了重要的作用。機器學習預測法在對大量實驗數(shù)據(jù)進行學習的基礎上,通過建立相關模型來預測未知數(shù)據(jù),其不需要探究影響管道腐蝕速率的具體機理,目前已廣泛應用于管道腐蝕速率的預測中[4]。張新生等[4]為更精確地預測海洋管道外腐蝕速率,建立了基于因子分析(factor analysis,FA)和天牛須搜索算法(beetle antennae searc,BAS)的極限學習機(extreme learning machine,ELM)腐蝕速率預測模型。駱正山等[5]通過對管道內(nèi)腐蝕機理及影響因素進行分析,提出了基于主成分分析法(principal component analysis,PCA) 和改進甲蟲天牛須算法(improve beetle antennae search,IBAS)的極限學習機(extreme learning machine,ELM)預測模型。趙清娜等[6]建立了支持向量機(support vector machine,SVM)和反向誤差傳播(back propagation,BP)神經(jīng)網(wǎng)絡模型對管道腐蝕速率進行預測,對比發(fā)現(xiàn)SVM具有更高的預測精度。夏俏健等[7]引進主成分法分析(principal component analysis,PCA)各因素與腐蝕速率的關系,建立了PCA-SVM管道腐蝕速率模型。Zhang等[8]引入粒子群算法(particle swarm optimization,PSO)對SVM模型的參數(shù)進行優(yōu)化,建立了PSO-SVM管道腐蝕預測模型。Sobhan等[9]引入烏鴉搜索算法(crow search algorithm,CSA)對最小二乘支持向量機(least squares support vector machine,LSSVM)的懲罰參數(shù)和核參數(shù)進行尋優(yōu)處理,構(gòu)建了CSA-LSSVM管道腐蝕速率模型。Liang等[10]引入遺傳算法(genetic algorithm,GA)優(yōu)化BP神經(jīng)網(wǎng)絡的權重與閾值,構(gòu)建了GA-BPNN腐蝕速率模型。上述學者所提出的模型方法都具有獨特的優(yōu)勢,但受限于優(yōu)化算法和神經(jīng)網(wǎng)絡自身局限性,可能導致針對多因素、高維度問題無法實現(xiàn)對管道腐蝕速率的精確預測。
在神經(jīng)網(wǎng)絡預測中,Elman神經(jīng)網(wǎng)絡是較為常用的一種,其具有實時反饋、短期記憶的功能(在傳統(tǒng)三層網(wǎng)絡結(jié)構(gòu)的基礎上增加了關聯(lián)層)[11]。與BP神經(jīng)網(wǎng)絡相比,Elman神經(jīng)網(wǎng)絡雖在網(wǎng)絡穩(wěn)定性和計算精度上更優(yōu),但也存在一定缺陷(泛化能力不足、易陷入極小值)[12],如何通過相關優(yōu)化算法對其進行改進仍是目前研究的一個重要內(nèi)容。爬行動物搜索算法(reptile search algorithm,RSA)是種新型元啟發(fā)式算法,其具有求解精度高、運算速度快的優(yōu)點[13]。爬行動物搜索算法在應用過程中,其存在的一個難題就是如何取得全局與局部搜索之間的最佳平衡。事實上,這也是該算法存在的一個不足。
考慮到爬行動物搜索算法的優(yōu)勢以及目前研究的不足,現(xiàn)引入圓形混沌映射(circle chaotic map)并結(jié)合鯨魚優(yōu)化算法(whale optimization algorithm,WOA)的狩獵策略,提出一種改進爬行動物搜索算法(improved reptile search algorithm,IRSA),構(gòu)建了IRSA-ENN模型并通過實例驗證所建新模型的有效性,研究結(jié)果對于管道腐蝕速率的準確預測具有重要的指導意義。
1 基于改進爬行動物搜索算法的優(yōu)化ENN模型構(gòu)建
1.1 ENN模型構(gòu)建
Elman神經(jīng)網(wǎng)絡是典型的局部回歸網(wǎng)絡,其在傳統(tǒng)三層結(jié)構(gòu)(輸入層、隱含層、輸出層)的基礎上增加了承接層,通過將上一時刻的隱層狀態(tài)連同當前的網(wǎng)絡輸入一同作為隱層輸入,因此具有記憶的特性。
文中隱含層的傳遞函數(shù)采用Sigmoid函數(shù),ENN的非線性狀態(tài)空間表述為
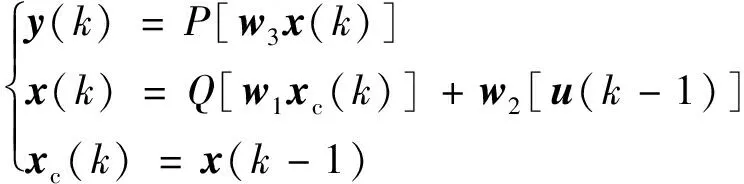
(1)
式(1)中:k為時刻;y(k)為輸出節(jié)點單元的輸出;x(k)為中間層的輸出;xc(k)為承接層的輸出;u為輸入層單元向量;w1、w2、w3分別為承接層與隱含層的連接權矩陣、輸入層與隱含層的連接權矩陣、輸出層與隱含層的連接權矩陣;P為輸出神經(jīng)元的傳遞函數(shù);Q為中間層神經(jīng)元的傳遞函數(shù)。
1.2 爬行動物搜索算法原理
爬行動物搜索算法是由Abualigah等[13]提出的元啟發(fā)式算法,其是一種通過對自然界中鱷魚的社會行為、包圍獵物機制和狩獵機制的研究而建立的基于種群且無梯度的算法。文獻[13-14]已給出爬行動物搜索算法的詳細原理。爬行動物搜索算法尋優(yōu)過程,主要分為2個階段:探索階段和開發(fā)階段,表述如下。
(1)探索階段(環(huán)繞)。爬行動物在包圍獵物時,有兩種行走方式,即高位行走和低位匍匐行走,其數(shù)學表達式為
Xi,j(t+1)=
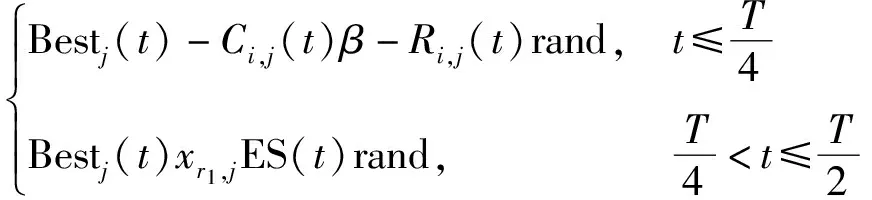
(2)
式(2)中:Xi,j(t+1)為第i結(jié)果上位于階段j位置獲得的當前解;Bestj(t)為該階段j位置上獲得的最優(yōu)解;t為當前的迭代步數(shù);T為最大的迭代步數(shù);Ci,j為第i結(jié)果上的第j位置上的狩獵運算符;β為修正參數(shù),控制該階段中高走約束條件下解的精度;Ri,j為Reduce函數(shù),主要作用是縮小搜索范圍;r1為[1,N]的隨機數(shù),N為候選解的數(shù)量;xr1,j為第i個解的隨機位置;ES(t)為進化比,是迭代過程中介于[-2,2]隨機遞減的概率比;rand為[0,1]的隨機數(shù)。
(2)開發(fā)階段(狩獵)。爬行動物在狩獵階段,有兩種社會行為,即協(xié)調(diào)與合作,其數(shù)學表達式為
Xi,j(t+1)=

(3)
式(3)中:Pi,j為第j位置上的最優(yōu)解的與當前解之差的百分比;δ為一個小值。
1.3 改進爬行動物搜索算法的基本思路
爬行動物搜索算法作為新的群體智能優(yōu)化算法,其和傳統(tǒng)的優(yōu)化算法都存在共同的缺陷,即:無法在局部和全局搜索之間獲得最佳平衡,尤其是當其應用于高維數(shù)據(jù)集中的特征選擇時[14]。全局搜索與局部搜索不平衡則會導致收斂緩慢并很快陷入局部最優(yōu)問題。因此,本文提出改進爬行動物搜索算法,主要從兩方面著手,第一方面是將圓形混沌映射應用于初始解來增強算法的種群多樣性;第二方面是通過引入鯨魚優(yōu)化算法中的狩獵策略對爬行動物搜索算法的原始狩獵策略進行改進。
具體來說,改進爬行動物搜索算法是利用圓形混沌映射增強種群多樣性和借鑒鯨魚優(yōu)化算法的優(yōu)勢改進爬行動物搜索算法的一種耦合算法。在IRSA中,圓形混沌映射被用作豐富RSA的種群探索空間范圍的能力;WOA的狩獵策略被用作RSA的局部搜索從而提高其解決不同優(yōu)化問題的能力,兩者增加了IRSA探索和利用搜索空間的能力和靈活性。
1.3.1 圓形混沌映射的引入
混沌映射是用于解決優(yōu)化算法中種群多樣性問題和低收斂速度的有效方法。使用圓形混沌映射來初始化種群位置,可以有效提高算法的求解性能[14]。此外,引進圓形混沌映射可進一步擴展搜索空間(與原始隨機搜索方法相比),其表達式為
CircleChaosMap=xn+1=xn+b-
CircleChaosMap∈(0,1)
(4)
式(4)中:xn為混沌序列的第n個混沌數(shù);b和a為控制變量,b取0.2,a取0.5;CircleChaosMap的值用來更新改進爬行動物搜索算法中隨機粒子初始位置;mod為取余函數(shù)。
1.3.2 鯨魚優(yōu)化算法狩獵策略的引入
鯨魚優(yōu)化算法主要是模仿座頭鯨捕獵時的生物學行為。分為兩種策略:包圍策略和狩獵策略。改進爬行動物搜索算法主要引入鯨魚優(yōu)化算法的狩獵策略,利用螺旋修正位置機制來修正Bestj(t)和Xi,j(t+1) 之間的距離,計算公式為
Xi,j(t+1)=Dis′eblcos(2πl(wèi))+Bestj(t)
(5)
式(5)中:l為對數(shù)螺旋形狀的值,為[-1,1]的隨機數(shù);Dis′為當前搜索個體到當前最優(yōu)解之間的距離;b為定義螺旋線的形狀參數(shù);Bestj(t)為該階段j位置上獲得的最優(yōu)解。
2 基于改進爬行動物搜索算法優(yōu)化ENN模型的建模過程
2.1 IRSA-ENN模型構(gòu)建
將改進爬行動物搜索算法應用到優(yōu)化傳統(tǒng)ENN模型的初始權值和閾值,從而構(gòu)造出IRSA-ENN模型。通過這種方法構(gòu)造的改進ENN模型能克服傳統(tǒng)ENN模型預測精度低、泛化能力不足等問題,模型建立步驟如下。
(1)在對管道腐蝕速率實驗數(shù)據(jù)進行歸一化處理的基礎上,對傳統(tǒng)ENN模型進行初始化,確定輸入層、隱含層、輸出層的層數(shù)。并引入爬行動物搜索算法,對初始參數(shù)進行設置(包括種群數(shù)量、迭代次數(shù)、問題維度等)。
(2)引入圓形混沌映射[式(4)],初始化爬行動物種群序列和豐富爬行動物探索空間。并對構(gòu)造的適應度函數(shù)(訓練樣本的均方誤差)進行計算,用以衡量整體尋優(yōu)過程中的最優(yōu)解。
(3)利用鯨魚優(yōu)化算法的狩獵策略對爬行動物搜索算法進行改進,體現(xiàn)為采用鯨魚優(yōu)化算法的狩獵策略[式(5)]來替換爬行動物搜索算法的狩獵策略[式(3)]。并時刻更新迭代各爬行動物位置,進一步尋找各爬行動物的全局最優(yōu)位置。
(4)通過每次迭代尋找的各爬行動物全局最優(yōu)位置對適應度函數(shù)進行更新計算。達到終止條件時,終止計算,否則繼續(xù)步驟(3)。
(5)將獲取的最優(yōu)爬行動物位置賦值給傳統(tǒng)ENN模型,通過重新訓練學習后,進而構(gòu)造出改進的ENN模型,并輸出最優(yōu)的預測解,流程如圖1所示。
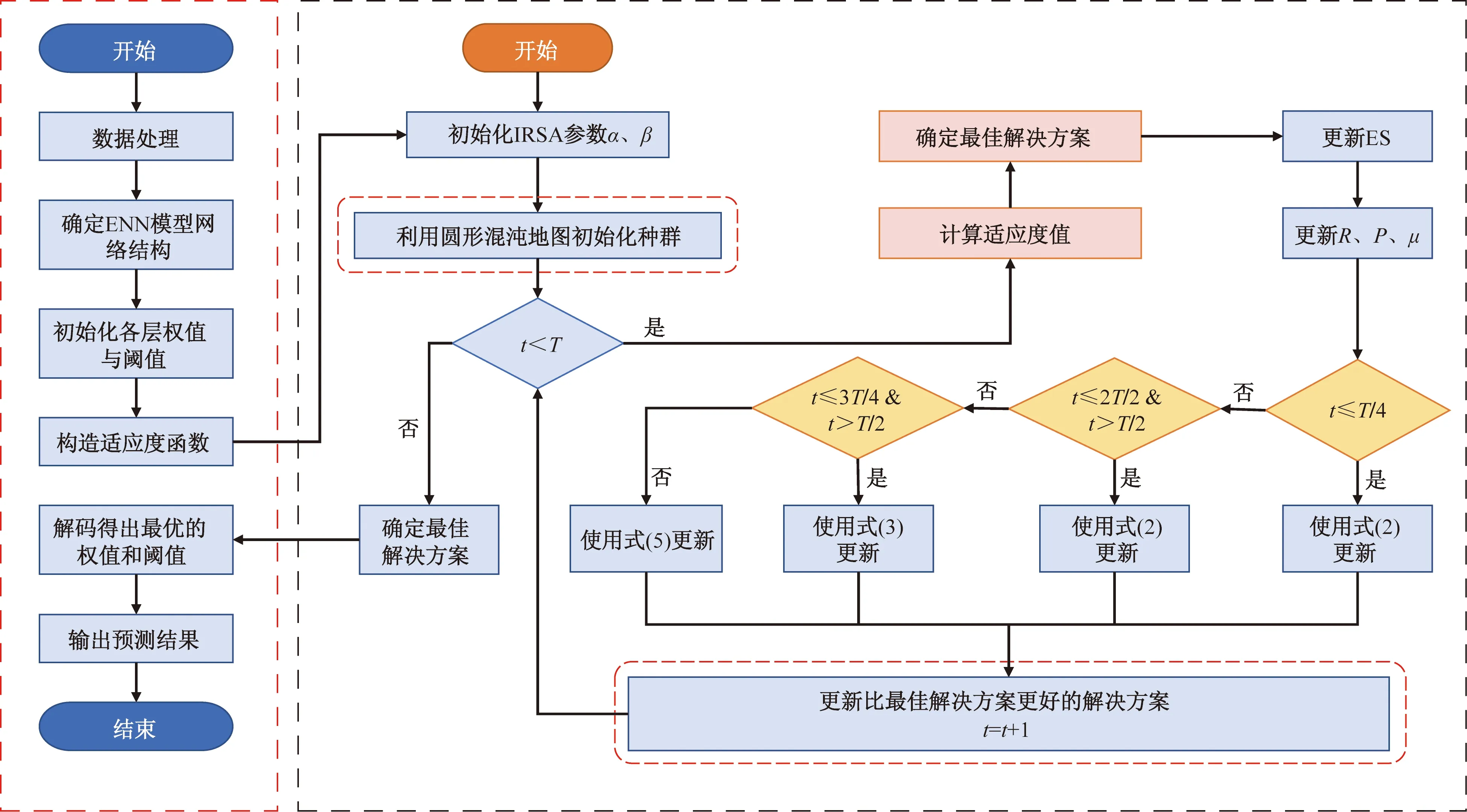
圖1 IRSA-ENN模型建模流程
2.2 模型驗證指標
引進3個評價參數(shù)對模型的預測精度進行評估,均方根誤差(root mean square error,RMSE)、平均絕對百分比誤差(mean absolute percentage error,MAPE),兩者數(shù)值越小則證明模型預測精度越高。相關系數(shù)R2越接近于1,則證明預測數(shù)據(jù)與實際數(shù)據(jù)越接近。其三者計算公式為
(6)
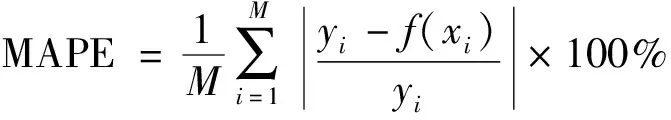
(7)
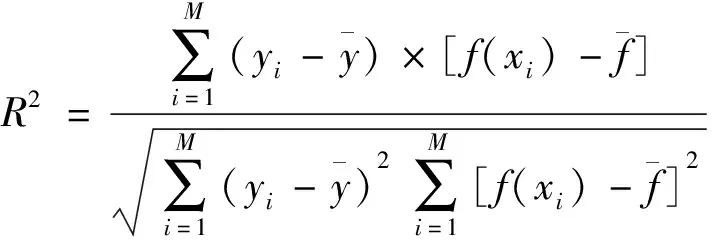
(8)
3 基于實測數(shù)據(jù)的改進新模型預測精度分析
3.1 數(shù)據(jù)選取與預處理
以文獻[15-16]中給出的兩組不同環(huán)境因素下的管道腐蝕速率實驗數(shù)據(jù)為例(分別對應實例一、實例二),用以驗證改進模型的泛化性能(對不同實驗樣本的學習能力),并對比分析所建IRSA-ENN模型和其他模型的預測精度。文獻[15-16]中給出的腐蝕速率實驗數(shù)據(jù)均為20組,分別隨機選取其中的15組數(shù)據(jù)作為訓練樣本建立模型,采用剩余的5組數(shù)據(jù)(預測樣本)來對比分析各模型的預測精度。具體的管道腐蝕速率實驗數(shù)據(jù)分別如表1和表2所示。
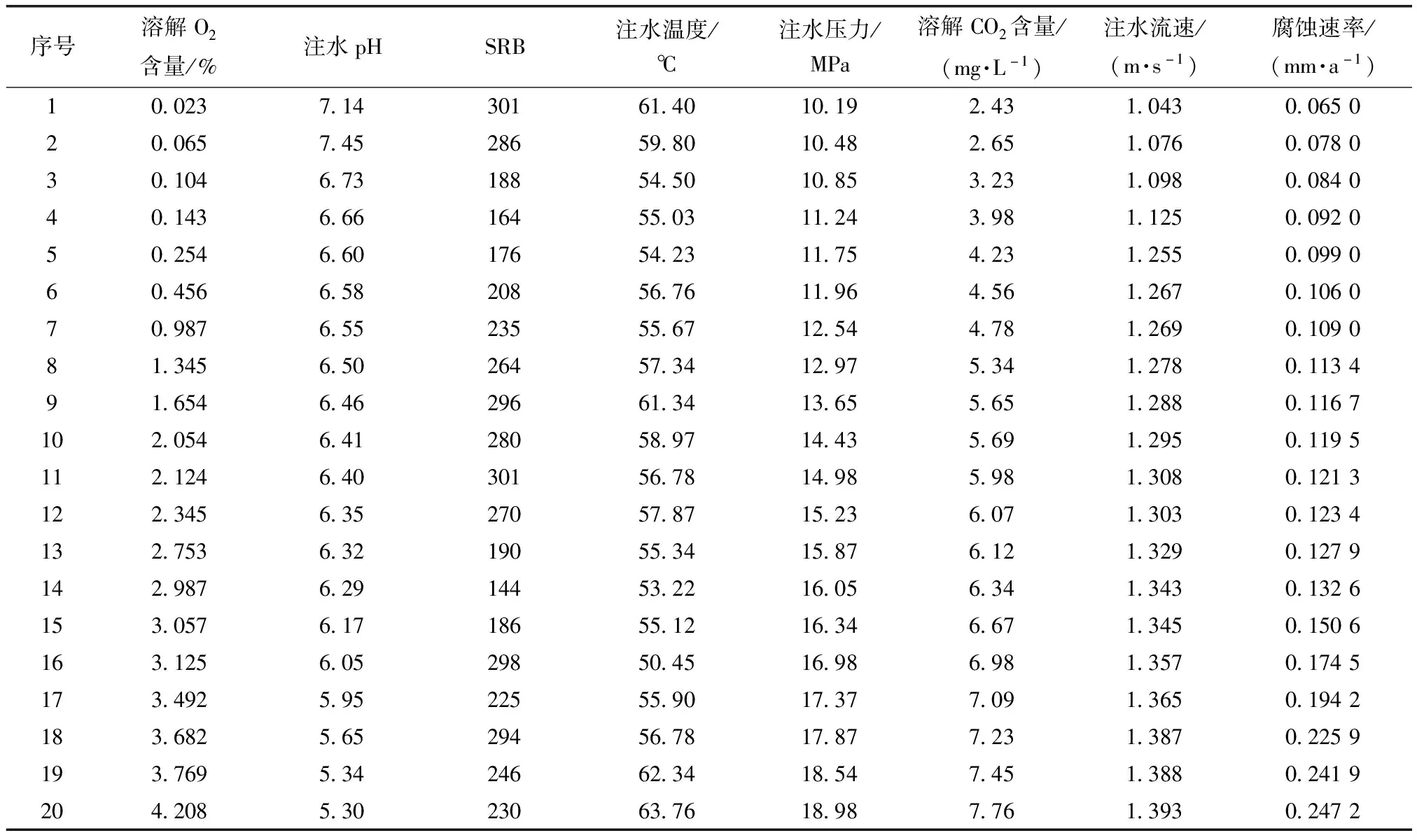
表2 管道腐蝕速率實驗數(shù)據(jù)[16](實例二)
在對訓練樣本進行學習時,由于變量間的量綱不同,需要使用mapminmax函數(shù)對數(shù)據(jù)進行歸一化處理,即把各變量轉(zhuǎn)化為[0,1]的數(shù)。
3.2 仿真結(jié)果對比分析
使用MATLAB軟件自主編程實現(xiàn)仿真過程,其中電腦端參數(shù)如表3所示。

表3 電腦軟硬件參數(shù)
傳統(tǒng)ENN模型在對實例一、實例二訓練樣本進行機器學習時,以訓練樣本的均方誤差最小為衡量標準,確定最佳隱含層節(jié)點數(shù)。其中傳統(tǒng)ENN模型學習設定參數(shù)如表4所示。
傳統(tǒng)ENN模型針對實例一、實例二管道腐蝕速率實驗數(shù)據(jù)確定隱含層節(jié)點數(shù)H時,經(jīng)驗公式為
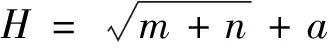
(9)
式(9)中:m為輸入層節(jié)點個數(shù);n為輸出層節(jié)點個數(shù);a取1~10的整數(shù)。
基于實例一、實例二不同隱藏層節(jié)點數(shù)求解的訓練樣本均方誤差結(jié)果,如表5和表6所示。

表5 不同隱含層節(jié)點數(shù)計算訓練樣本的均方誤差(實例一)

表6 不同隱含層節(jié)點數(shù)計算訓練樣本的均方誤差(實例二)
由表5可見,當隱藏層節(jié)點數(shù)為9時,對應的訓練樣本均方誤差最小(實例一),故實例一仿真試驗確定構(gòu)建10-9-1三層ENN模型。同樣由表6可見,當隱藏層節(jié)點數(shù)為10時,對應的訓練樣本均方誤差最小(實例二),故實例二仿真試驗確定構(gòu)建7-10-1三層ENN模型。
為了驗證和評估IRSA-ENN模型的預測精度,建立了ENN、WOA-ENN、RSA-ENN模型與其對比。為了便于分析,保持上述模型種群規(guī)模為30,迭代次數(shù)50次,其中WOA-ENN模型初始化常量取a=[0,2],b=1,l=[-1,1];RSA-ENN、IRSA-ENN模型初始化常量取α=0.1,β=0.005。各模型基于實例一在訓練過程中的均方誤差迭代曲線,如圖2所示。

圖2 基于不同算法耦合ENN模型的訓練迭代過程(實例一)
圖2通過各模型在訓練過程中均方誤差求解迭代結(jié)果對比,可明顯看出,IRSA較RSA和WOA具有更高的求精精度。
仿真求解結(jié)束后,得到各模型腐蝕速率的預測結(jié)果并計算相對誤差,結(jié)果分別如表7~表9、圖3和圖4。

表7 不同模型的預測結(jié)果及相對誤差(實例一)
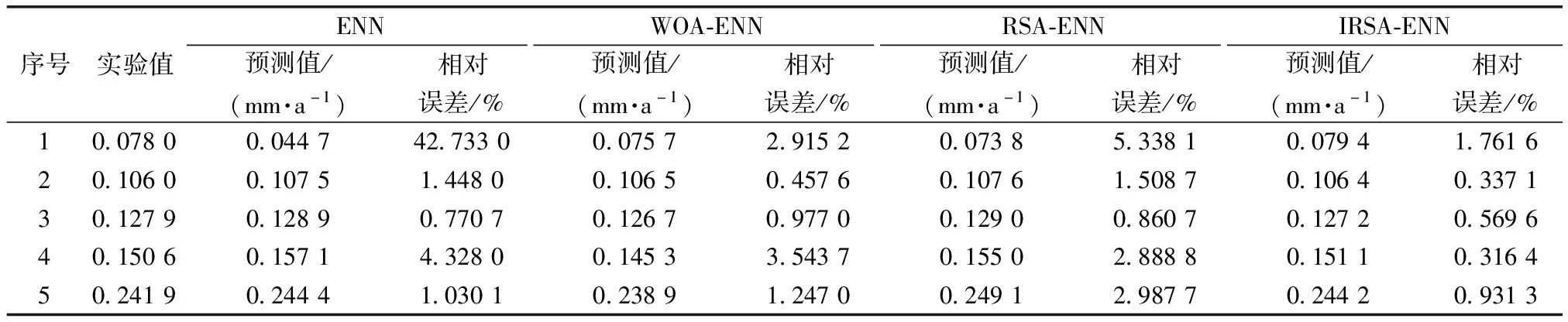
表8 不同模型的預測結(jié)果及相對誤差(實例二)

表9 不同模型預測精度對比
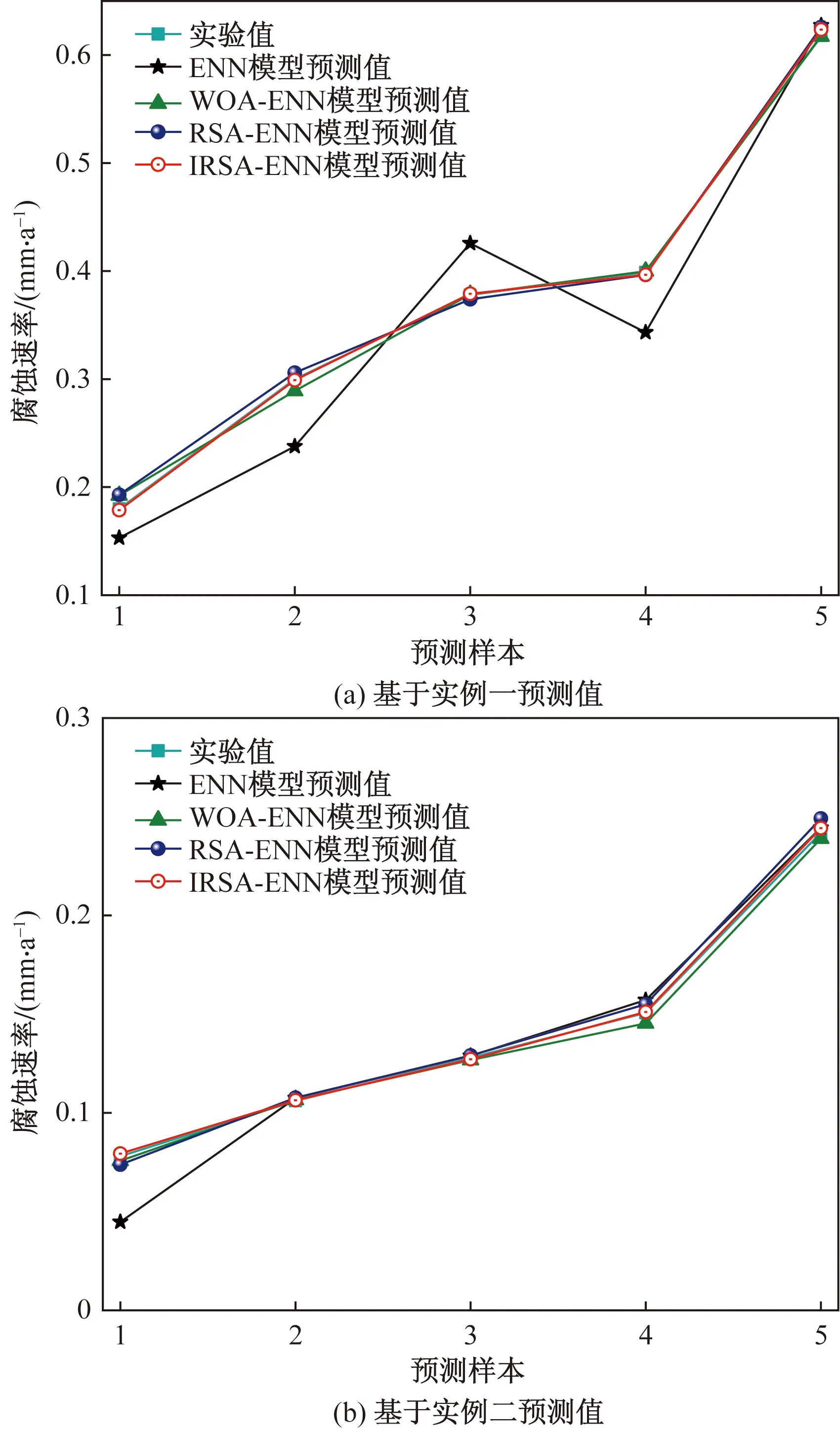
圖3 不同模型預測值結(jié)果對比
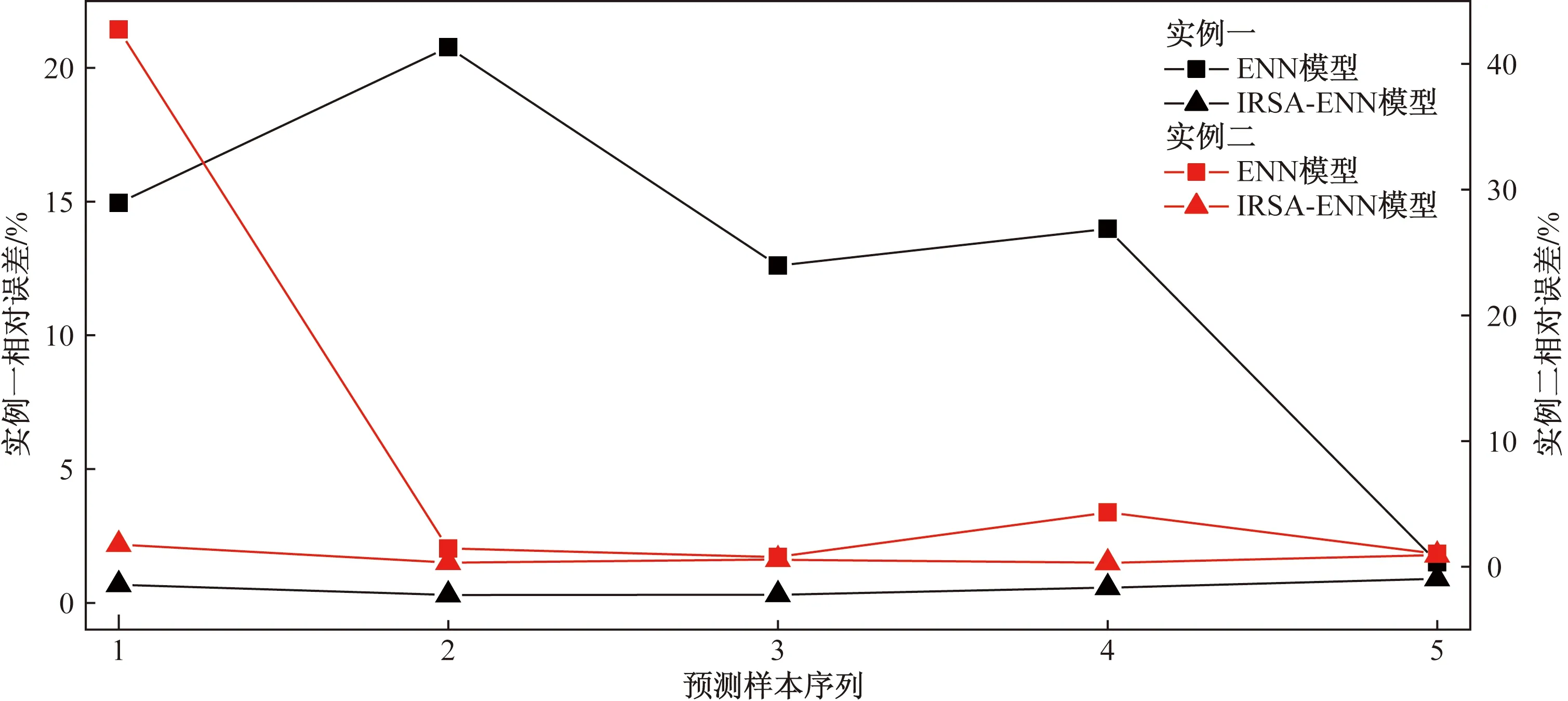
圖4 IRSA-ENN與ENN模型預測誤差對比
從表7~表9、圖3及圖4可見,對于實例一預測結(jié)果而言,ENN模型的MAPE為12.766 9%,相關系數(shù)R2為0.944 98;WOA-ENN模型的MAPE為2.202 1%,相關系數(shù)R2為0.997 59;RSA-ENN模型的MAPE為2.419 8%,相關系數(shù)R2為0.998 1;IRSA-ENN模型的MAPE為0.547 6%,相關系數(shù)為0.999 87。對于實例二預測結(jié)果而言,ENN模型的MAPE為10.062%,相關系數(shù)R2為0.966 62;WOA-ENN模型的MAPE為1.828 1%,相關系數(shù)R2為0.998 97;RSA-ENN模型的MAPE為2.716 8%,相關系數(shù)R2為0.999 28;IRSA-ENN模型的MAPE為0.7831 %,相關系數(shù)為0.999 76。
從兩組不同實例預測結(jié)果來看,新建的IRSA-ENN模型預測精度最高,傳統(tǒng)ENN模型的預測精度相對較低,WOA-ENN、RSA-ENN模型的預測精度均高于傳統(tǒng)ENN模型,這也證明了所用改進模型的有效性。通過所建模型對兩組不同管道腐蝕速率實驗數(shù)據(jù)的學習預測,可以明顯看出傳統(tǒng)ENN模型泛化能力不強(基于實例一、實例二兩組管道腐蝕速率預測時,MAPE分別為12.766 9%、10.062 0%)。而改進的ENN模型在對不同樣本進行學習預測時,具有較強的泛化能力(對不同實驗樣本的管道腐蝕速率預測時,精度較高)。其原因是:傳統(tǒng)的ENN模型采用基于梯度下降法求解E(k)對權值的偏導數(shù),因此存在容易陷入局部極小點的缺陷,對Elman神經(jīng)網(wǎng)絡的訓練較難達到全局最優(yōu)[17-19]。而使用改進算法可對傳統(tǒng)ENN模型隨機初始化的權值與閾值進行迭代尋優(yōu)處理,最終獲得最優(yōu)的權值與閾值,因此能夠大幅度提高傳統(tǒng)模型的預測精度,且可以避免初始權值與閾值的隨機性導致泛化能力不強的缺陷。
此外新建的IRSA-ENN模型較RSA-ENN模型預測精度也有所提升,這主要是因為:引入圓形混沌映射豐富了種群多樣性,擴展了種群的搜索空間,可克服RSA在迭代尋優(yōu)初期全局搜索能力不足的缺陷;同時新模型采用WOA的狩獵策略改進了RSA的狩獵策略,能夠進一步提高RSA的局部搜索能力。綜合來看,改進爬行動物搜索算法無論是全局搜索能力還是局部搜索能力都較爬行動物搜索算法有很大提升,故其預測精度較高。
從仿真結(jié)果可見,新建的IRSA-ENN模型同樣較WOA-ENN模型預測精度有所提升,這主要是因為:IRSA將其狩獵策略分為兩個階段,既保留了WOA局部搜索能力強的優(yōu)勢,又在迭代后期很好地平衡了全局搜索與局部搜索之間的關系,能夠克服原始WOA過早陷入局部最優(yōu)解的缺陷,故其預測精度仍較高。
4 結(jié)論
(1)引入圓形混沌映射并結(jié)合鯨魚優(yōu)化算法的狩獵策略對爬行動物搜索算法進行改進,提出了一種基于改進爬行動物搜索算法的優(yōu)化ENN模型并預測了管道的腐蝕速率。仿真結(jié)果表明,所建的優(yōu)化ENN模型預測結(jié)果與實際值吻合很好,其用來預測管道的腐蝕速率完全可行。
(2)對比IRSA-ENN模型與其他模型的預測精度可知,IRSA-ENN模型的預測精度最高(兩個實例的MAPE分別為0.547 6%、0.783 1%),其次是鯨魚優(yōu)化算法建立的改進ENN模型(兩個實例的MAPE分別為2.202 1、1.828 1%)和傳統(tǒng)爬行動物搜索算法建立的改進ENN模型(兩個實例的MAPE分別為2.419 8%、2.716 8%),而傳統(tǒng)ENN模型的精度較差(兩個實例的MAPE分別為12.766 9%、10.062 0%)。
(3)新建的IRSA-ENN模型有效解決了傳統(tǒng)ENN模型預測時泛化能力不足、易陷入極小值的缺陷,且克服了傳統(tǒng)爬行動物搜索算法在迭代尋優(yōu)初期全局搜索能力不足和迭代尋優(yōu)后期易陷入局部最優(yōu)解的缺陷,其為管道腐蝕速率的準確預測提供了一種新思路。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
中學生數(shù)理化(高中版.高考數(shù)學)(2021年12期)2021-03-08 01:28:50
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
