基于改進YOLO v5s的甘蔗切種莖節(jié)特征識別定位技術(shù)
2023-11-23 04:37:56李尚平鄭創(chuàng)銳文春明李凱華甘偉光
農(nóng)業(yè)機械學(xué)報 2023年10期
李尚平 鄭創(chuàng)銳 文春明 李凱華 甘偉光 李 洋
(1.廣西民族大學(xué)電子信息學(xué)院, 南寧 530006; 2.廣西高校智慧無人系統(tǒng)與智能裝備重點實驗室, 南寧 530006)
0 引言
甘蔗是我國最重要的糖料作物,在我國國民經(jīng)濟中占有特殊的重要作用[1]。甘蔗種業(yè)是糖料甘蔗生產(chǎn)的基礎(chǔ),是促進甘蔗高產(chǎn)高糖的前提。甘蔗制種的工廠化、標(biāo)準(zhǔn)化以及智能化是促進糖業(yè)發(fā)展必由之路。
針對甘蔗制種的工廠化、標(biāo)準(zhǔn)化以及智能化生產(chǎn)技術(shù)的不足,課題組研發(fā)了甘蔗智能橫向切種工作站[2],它具有切種合格率高、傷芽率低等優(yōu)點,為甘蔗的工廠化制種奠定了良好的基礎(chǔ)。本文以提高甘蔗智能橫向切種工作站的效率及精度為目標(biāo),對其甘蔗莖節(jié)識別部分進行優(yōu)化改進以及部署于邊緣設(shè)備上,進一步提高甘蔗智能橫向切種工作站的實用性與可靠性。
目前甘蔗莖節(jié)識別與定位方法相關(guān)的研究可以分為傳統(tǒng)機器視覺方法、傳感器識別分析方法和深度學(xué)習(xí)方法。在傳統(tǒng)機器視覺方法方面,CHEN等[3]在甘蔗的感興趣區(qū)域二值化圖像內(nèi)使用垂直投影函數(shù),并對垂直投影函數(shù)連續(xù)求導(dǎo)后,根據(jù)可疑像素值確定莖節(jié),單個莖節(jié)點識別準(zhǔn)確率為100%。ZHOU等[4]提出了一種基于Sobel邊緣檢測的甘蔗莖節(jié)點識別方法,識別準(zhǔn)確率為 93%,平均時間為0.539 s。張圓圓等[5]利用甘蔗莖節(jié)處具有拐點和灰度值不連續(xù)的特性,在邊緣擬合法和灰度值擬合法的基礎(chǔ)上使用中值決策法對甘蔗莖節(jié)進行識別,識別率達到94.7%。在傳感器識別分析方法方面,CHEN等[6]利用加速度傳感器和薄膜壓電傳感器共同采集位置信息,基于小波分析對甘蔗莖節(jié)進行識別,識別精度為99.63%,單個莖節(jié)識別時間為0.25 s。MENG等[7]利用激光傳感器獲取甘蔗表面輪廓信號,并提出了一種基于多閾值多尺度小波變換的甘蔗莖節(jié)識別分析方法,識別率為100%,識別時間為0.25 s。在深度學(xué)習(xí)方法方面,陳延祥[8]在改進后的YOLO v3的基礎(chǔ)上使用邊緣提取算法和莖節(jié)定位算法,識別調(diào)和平均值為97.3%。趙文博等[9]在YOLO v5s的基礎(chǔ)上引入bifpn、EIoU損失函數(shù)和Focal loss損失函數(shù)提高識別平均精度,然后在頸部引入Ghost模塊使模型輕量化,平均識別精度為97.8%,模型內(nèi)存占用量為11.4 MB。而在甘蔗智能橫向切種工作站上使用的識別模型已有兩代。第1代識別模型為:廖義奎等[10]利用垂直投影方法確定甘蔗所在位置,然后利用卷積神經(jīng)網(wǎng)絡(luò)AlexNet搭建甘蔗蔗芽特征識別模型,模型實時動態(tài)檢測精度為88%,平均檢測時間為341.09 ms;第2代識別模型為:李尚平等[11]通過改進YOLO v3算法實現(xiàn)了甘蔗莖節(jié)實時動態(tài)識別,識別平均精度為90.38%,識別平均時間為28.7 ms,模型內(nèi)存占用量為118 MB。
傳統(tǒng)機器視覺和傳感器分析方法對于甘蔗莖節(jié)識別的研究大多數(shù)為靜態(tài)或縱向識別,對場景和目標(biāo)特征選擇的依賴性較強,面對顏色分布差異較大或者外觀形狀不規(guī)律的甘蔗種時,識別能力較差,魯棒性較低,效率低下,并不能滿足工廠化生產(chǎn)的需求。而其它基于深度學(xué)習(xí)方法的甘蔗莖節(jié)識別模型雖然展現(xiàn)出較高的應(yīng)用前景,但均未部署在嵌入式設(shè)備上,缺少實際切種任務(wù)的檢驗,真實效果有待檢驗,缺乏可靠性和真實性。
因此,本文針對甘蔗智能橫向切種工作站應(yīng)用需求,提出一種基于改進YOLO v5s的甘蔗莖節(jié)特征識別定位方法以及邊緣端部署,優(yōu)化甘蔗莖節(jié)實時檢測流程,使其在復(fù)雜的光照條件和實時檢測的動態(tài)環(huán)境下,克服特征模糊的影響,提高視覺系統(tǒng)的檢測精度及可靠性,并將視覺系統(tǒng)部署于邊緣設(shè)備上,使其具有更好的實用性與可擴展性,通過在切種工作站上進行實際切種試驗,驗證本文方法的優(yōu)越性。
1 甘蔗智能橫向切種工作站構(gòu)建
1.1 甘蔗智能橫向切種工作站組成與工作原理
甘蔗智能橫向切種工作站由二級耙結(jié)構(gòu)、圖像采集黑箱、切種平臺、液壓站、甘蔗分揀電機、甘蔗傳送電機、攝像頭、調(diào)節(jié)燈、光電傳感器、圖像識別及控制系統(tǒng)等零部件組成,如圖1所示。切種過程中,隨著二級耙的轉(zhuǎn)動,整根蔗種被橫向有序地送入黑箱中,黑箱頂部的攝像頭實時采集甘蔗圖像序列,接著由圖像識別系統(tǒng)同時檢測各莖節(jié)位置和計算各切口坐標(biāo)信息,并將其發(fā)送給控制器,由控制器調(diào)控多把切刀,同時完成一根甘蔗的雙芽段切種工作。

圖1 甘蔗智能橫向切種工作站Fig.1 Intelligent transverse sugarcane cutting workstation1.二級耙結(jié)構(gòu) 2.圖像采集黑箱 3.切種平臺 4.液壓站 5.甘蔗分揀電機 6.甘蔗傳送電機 7.攝像頭 8.調(diào)節(jié)燈 9.光電傳感器 10.圖像識別及控制系統(tǒng)
1.2 圖像采集黑箱結(jié)構(gòu)
圖像的采集工作主要在黑箱中完成,黑箱中包括頂部攝像頭和側(cè)邊的矩陣燈帶,如圖2所示。其中,攝像頭與傳送帶平面垂直距離為1.2 m,該距離的設(shè)置可以保證攝像頭能夠拍攝到傳送帶上的完整物體,避免甘蔗莖節(jié)信息缺失等問題。
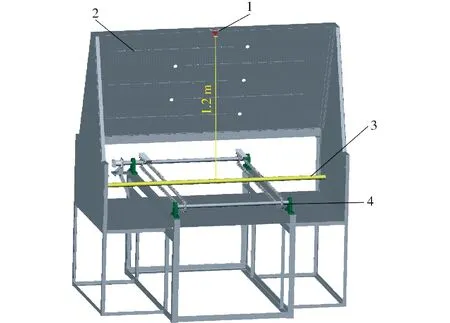
圖2 甘蔗智能橫向切種工作站黑箱內(nèi)部結(jié)構(gòu)圖Fig.2 Internal structure of black box of intelligent transverse sugarcane cutting workstation1.攝像頭 2.調(diào)節(jié)式矩陣燈帶 3.整根甘蔗 4.傳送鏈
為了得到最佳的圖像莖節(jié)特征,需要調(diào)節(jié)LED矩陣燈帶的光照分布。經(jīng)過多次試驗,目前平均光照強度為430.7 lx時效果最佳,可充分展示甘蔗莖節(jié)的特征。
在選用攝像頭時,考慮到實際應(yīng)用需求和成本限制,使用了RMONCAM的G200型高清攝像頭。該工業(yè)相機采集速度為30 f/s,分辨率為1 920像素× 1 080像素,曝光方式為卷簾曝光,曝光時間約為33 ms,圖像處理方式為自動曝光。這些參數(shù)的設(shè)置可以保證圖像的清晰度和穩(wěn)定性,同時滿足目標(biāo)檢測的實時性要求。
1.3 相機標(biāo)定
為了消除圖像識別定位的畸變誤差影響,需對工業(yè)相機進行精準(zhǔn)的標(biāo)定,實現(xiàn)相機坐標(biāo)和實際坐標(biāo)之間的轉(zhuǎn)換。在計算機上生成7×9的棋盤方格,每個方格的尺寸為2.5 cm×2.5 cm,如圖3a所示。利用打印機進行1∶1打印,再從不同角度對棋盤方格進行拍照,采集50幅不同角度的圖像,如圖3b、3c所示。

圖3 工業(yè)相機標(biāo)定流程Fig.3 Industrial camera calibration process
采用圖像處理算法對相機進行標(biāo)定處理,通過張正友相機標(biāo)定算法進行計算[12],可以得到相機內(nèi)部參數(shù)R1和畸變參數(shù)R2表達式為
(1)
(2)
2 甘蔗莖節(jié)圖像數(shù)據(jù)集采集與預(yù)處理
2.1 甘蔗莖節(jié)的數(shù)據(jù)采集
本研究以廣西甘蔗為研究對象,在崇左市扶綏縣的廣西大學(xué)廣西亞熱帶農(nóng)科新城進行甘蔗的采集[13-14]。為了保證數(shù)據(jù)的多樣性和魯棒性,從2022年10月到2023年3月,通過人工砍收的方式分3次收集404根甘蔗,甘蔗品種包括中蔗9號、桂糖42號和桂輻98-296。平均長度約為1.8 m,平均直徑達到30 mm,其中保留20根作為實際切種的試驗樣本,其余甘蔗置于切種工作站的傳送鏈上,傳送速度分別從0.1 m/s逐漸升高至0.15 m/s,并使用攝像頭對整桿甘蔗的莖節(jié)特征進行視頻采集。通過視頻幀分割方式,最終采集到共計2 336幅整根甘蔗圖像,格式為JPG。采集到的圖像包含不同擺放密度、不同光照、多品種的蔗種圖像,以保證目標(biāo)檢測的準(zhǔn)確性與魯棒性。如圖4所示。

圖4 整桿甘蔗的莖節(jié)圖像Fig.4 Image of stem nodes of whole sugarcane
2.2 數(shù)據(jù)篩選以及數(shù)據(jù)標(biāo)注
為提高實時動態(tài)環(huán)境下的甘蔗莖節(jié)識別的精度和速度,因此在篩選過程中,首先從傳送速度和曝光度等因素出發(fā),刪除一些不符合要求的圖像。其次,為了提高模型魯棒性,著重選擇一些模糊但仍具有莖節(jié)特征的圖像數(shù)據(jù)。最終保留449幅不同疏密、不同光照的甘蔗莖節(jié)圖像,便于YOLO目標(biāo)檢測算法更好地去學(xué)習(xí)標(biāo)注好的甘蔗莖節(jié)目標(biāo)細節(jié)特征,提高整體模型識別精度。
在數(shù)據(jù)標(biāo)注方面,本文使用LabelImg軟件對這些圖像進行了標(biāo)注,并將標(biāo)注信息轉(zhuǎn)換為YOLO需要的txt格式。在標(biāo)注過程中,得到包含莖節(jié)目標(biāo)的中心坐標(biāo)(x′,y′)、寬、高信息的xml文件。由于YOLO需要的標(biāo)注文件類型為txt文件,因此使用Python編程將xml文件轉(zhuǎn)化為txt格式的標(biāo)注文件,得到了可以在YOLO模型中運行的數(shù)據(jù)集[15-18]。YOLO數(shù)據(jù)格式如圖5所示。
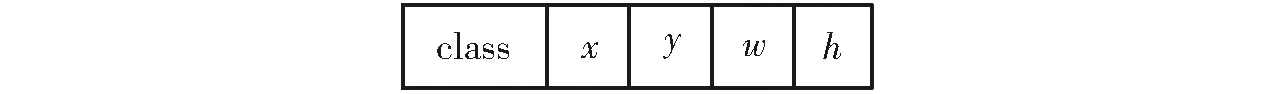
圖5 YOLO數(shù)據(jù)格式Fig.5 YOLO data format
xywh
(3)
(4)
式中W——圖像寬度H——圖像高度
w——歸一化后目標(biāo)寬度
h——歸一化后目標(biāo)高度
x——歸一化后目標(biāo)中心x坐標(biāo)
y——歸一化后目標(biāo)中心y坐標(biāo)
w′——目標(biāo)寬度h′——目標(biāo)高度
圖6為甘蔗莖節(jié)邊界框標(biāo)注示意圖。圖中的字符與式(3)、(4)對應(yīng)。圖像坐標(biāo)系的原點位于圖像的左上角,x軸方向沿著圖像水平向右,y軸方向沿著圖像豎直向下。

圖6 甘蔗莖節(jié)數(shù)據(jù)標(biāo)注示意圖Fig.6 Schematic of sugarcane stem node data labeling
通過對標(biāo)注的甘蔗莖節(jié)邊界框數(shù)據(jù)進行統(tǒng)計,449幅圖像經(jīng)過標(biāo)注后得到8 102個甘蔗莖節(jié)實例,因為1幅圖像可能存在多根甘蔗、多個莖節(jié),所以得到的實例數(shù)量較多。接著對圖中邊界框坐標(biāo)中心(x,y)和邊界框的寬、高進行了歸一化處理。統(tǒng)計結(jié)果如圖7所示,圖中顏色較深的區(qū)域表示數(shù)據(jù)高度重疊。

圖7 甘蔗莖節(jié)邊界框統(tǒng)計結(jié)果Fig.7 Statistical results of box of sugarcane stem node boundary
從圖7a可知,甘蔗莖節(jié)的邊界框的中心(x,y)主要分布在y軸0.3~0.7之間以及x軸0.2~0.8之間,這是因為在安裝攝像頭時,在其外部增加了一個黑色外殼,用于減弱光線的干擾,所以在識別畫面出現(xiàn)四周黑邊的情況,從而影響了甘蔗莖節(jié)邊界框的分布。
此外,根據(jù)圖7b可知,每個甘蔗莖節(jié)實例的邊界框面積都不超過整幅圖像區(qū)域的0.12%,總體呈現(xiàn)小目標(biāo)的特點,這也是在后續(xù)算法改進中需要解決的一個重點問題。
2.3 數(shù)據(jù)增強
采用Imgaug圖像增強庫擴大甘蔗莖節(jié)圖像數(shù)量,記錄數(shù)據(jù)增強前后的訓(xùn)練、測試效果對比。本實驗選擇 YOLO v5s模型作為基準(zhǔn)模型,并將原始數(shù)據(jù)隨機抽樣出約10%數(shù)據(jù)作為測試集,共50幅圖像。訓(xùn)練集、驗證集和測試集的劃分比例為 8∶1∶1,接著分別對訓(xùn)練集和驗證集采用仿射變換、翻轉(zhuǎn)變換、高斯模糊、高斯噪聲等方式擴增數(shù)據(jù)集7倍,測試集采用原始數(shù)據(jù)集分割得到的測試集,數(shù)據(jù)劃分結(jié)果如表1所示。

表1 數(shù)據(jù)集劃分Tab.1 Division of data set
分析數(shù)據(jù)增強前后數(shù)據(jù)集在每一輪訓(xùn)練后在驗證集上的效果,如圖8所示(圖中平均精度均值1指mAP@0.5,平均精度均值2指mAP@0.5∶0.95,YOLO v5s_aug指在訓(xùn)練YOLO v5s模型時使用數(shù)據(jù)增強后的數(shù)據(jù)集,YOLO v5s_noaug指在訓(xùn)練YOLO v5s模型時使用原始數(shù)據(jù)集)。從結(jié)果上可以看出,數(shù)據(jù)增強后的模型在精確率(Precision)、召回率(Recall)和平均精度均值(Mean average precision,mAP)上都有不同程度的提升,并且震蕩幅度更小,這是由于數(shù)據(jù)增強豐富了數(shù)據(jù)集的多樣性,使得模型能夠?qū)W習(xí)到更多的數(shù)據(jù)分布和場景,從而提高模型的泛化能力和魯棒性,降低了過擬合風(fēng)險。
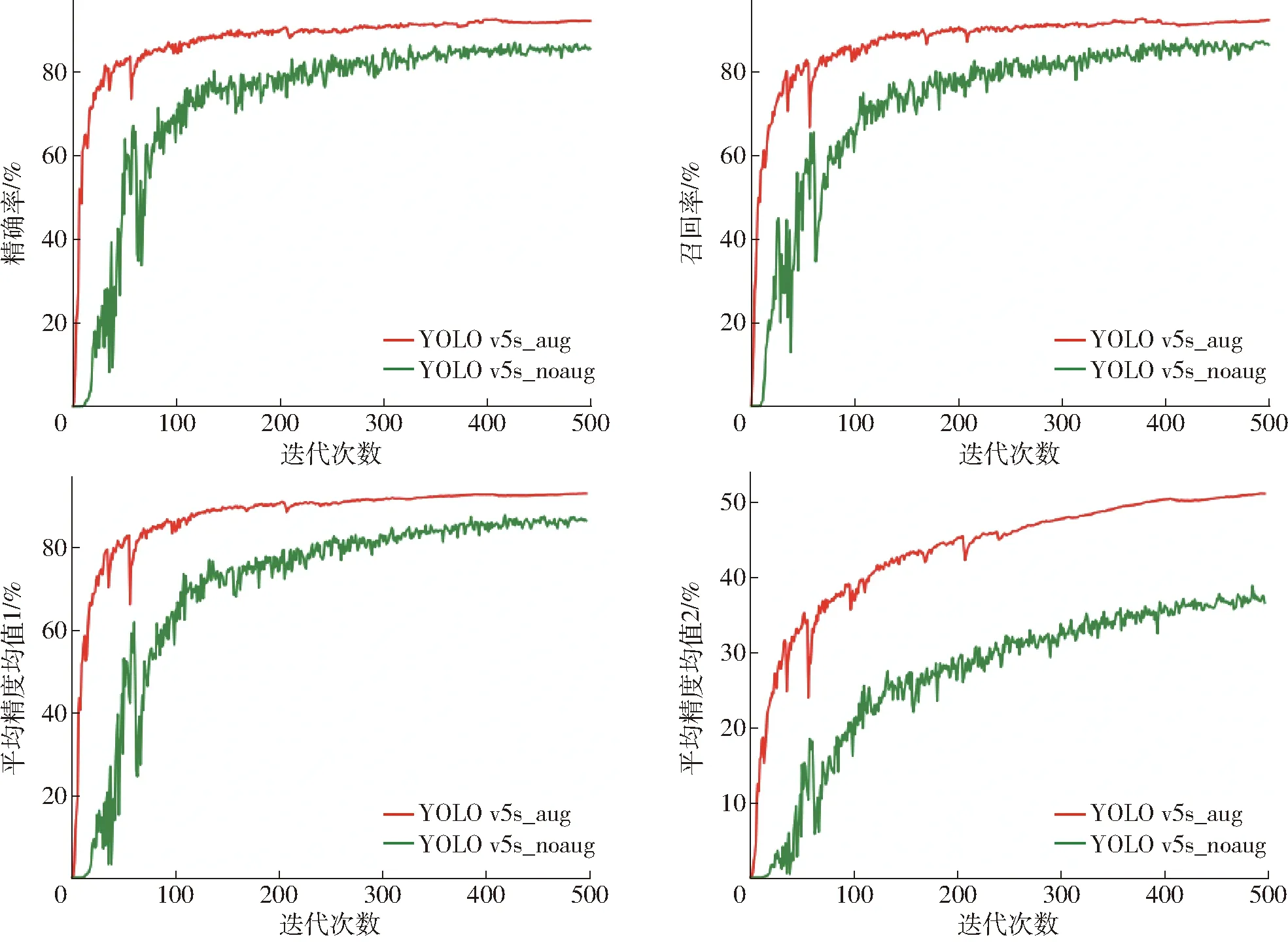
圖8 數(shù)據(jù)增強前后數(shù)據(jù)集訓(xùn)練過程驗證集性能評估結(jié)果Fig.8 Performance evaluation results of validation set before and after data enhancement for dataset training process
圖9為500輪訓(xùn)練過程中在訓(xùn)練集和驗證集下的box損失值以及object損失值,box損失值描述預(yù)測框與錨框之間的匹配程度,object損失值描述預(yù)測物體類別與真實類別的差異程度。從圖中可以看出,使用數(shù)據(jù)增強后的box損失值越小,object損失值也相對較低,說明經(jīng)過數(shù)據(jù)增強后模型收斂更快。

圖9 數(shù)據(jù)增強前后數(shù)據(jù)集訓(xùn)練過程損失值變化曲線Fig.9 Curves of loss value during training process of dataset before and after data augmentation
從圖9中還可以看出,在前100輪的訓(xùn)練以及驗證過程中,目標(biāo)損失出現(xiàn)先上升后下降的趨勢,其原因是在訓(xùn)練初期過程中,模型只能學(xué)習(xí)到一些基本的特征,導(dǎo)致目標(biāo)損失函數(shù)的值較高。隨著訓(xùn)練迭代次數(shù)的增加,模型會學(xué)習(xí)到更多的特征,從而降低目標(biāo)損失函數(shù)的值。
數(shù)據(jù)增強前后的模型在測試集上的檢測性能如表2所示。從表2可以看出,在原始數(shù)據(jù)集基礎(chǔ)上進行數(shù)據(jù)增強使精確率、召回率、平均精度均值1、平均精度均值2分別提高3.8、5.2、5.4、8.5個百分點,其中平均精度均值2提升最明顯。這是因為數(shù)據(jù)增強擴展了原始數(shù)據(jù)集,增加了樣本數(shù)量和多樣性,使得模型能夠?qū)W習(xí)到更多豐富的甘蔗莖節(jié)特征,一定程度上提高了模型的檢測精度、穩(wěn)定性和魯棒性。

表2 數(shù)據(jù)增強前后數(shù)據(jù)集訓(xùn)練所得模型在測試集上性能參數(shù)Tab.2 Performance evaluation results of trained model on test set before and after data augmentation of dataset %
YOLO v5s_aug模型性能參數(shù)和損失值如圖10所示。從圖中可以發(fā)現(xiàn),采用數(shù)據(jù)增強策略能顯著且穩(wěn)定提高模型檢測精度和穩(wěn)定性,加快收斂速度。
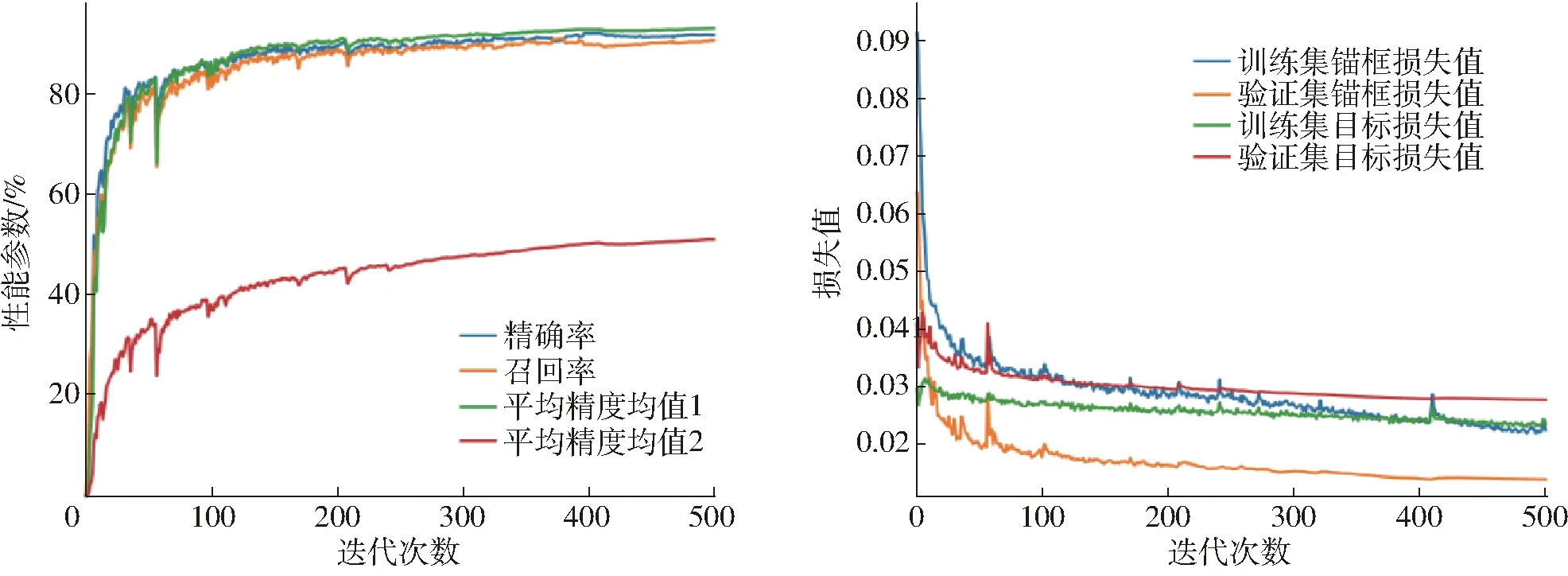
圖10 YOLO v5s_aug模型性能參數(shù)和損失值變化曲線Fig.10 Performance parameters and loss curves variations of YOLO v5s_aug model
3 基于改進YOLO v5s的甘蔗莖節(jié)識別模型
3.1 YOLO v5s算法結(jié)構(gòu)優(yōu)化
YOLO v5s是YOLO v5中模型復(fù)雜度較低,且兼具較高檢測精度和速度的模型,被廣泛應(yīng)用于各類工業(yè)生產(chǎn)活動。將它作為網(wǎng)絡(luò)優(yōu)化的基礎(chǔ),可以保證網(wǎng)絡(luò)結(jié)構(gòu)的可靠性和高效性,避免過多的參數(shù)冗余對實際應(yīng)用造成不良影響。所以,本研究將以YOLO v5s 算法為基礎(chǔ),對骨干網(wǎng)絡(luò)和Head網(wǎng)絡(luò)進行優(yōu)化改進,使其對甘蔗莖節(jié)小目標(biāo)的檢測性能提高,模型復(fù)雜度降低。
3.1.1骨干網(wǎng)絡(luò)優(yōu)化
骨干網(wǎng)絡(luò)是YOLO v5s模型的基礎(chǔ),負責(zé)提取輸入圖像的特征,它的模塊主要包括Conv模塊、C3模塊以及SPPF模塊。Conv模塊實現(xiàn)了對輸入特征的提取和轉(zhuǎn)化;C3模塊利用殘差網(wǎng)絡(luò)進行殘差學(xué)習(xí),提高了模型的深度;SPPF模塊是在SPP的基礎(chǔ)上減少網(wǎng)絡(luò)層數(shù),并對不同感受野的信息特征進行融合,提高特征圖的表達能力和特征融合的速度。但是,原始網(wǎng)絡(luò)對小目標(biāo)特征的提取能力有限,提取的特征圖中也包含了許多冗余特征信息,增加了計算量和內(nèi)存占用量。所以,為了進一步提高YOLO v5s的特征提取能力以及降低模型復(fù)雜度,本文將對它的骨干網(wǎng)絡(luò)進行優(yōu)化改進。圖11為YOLO v5s模型的原始骨干網(wǎng)絡(luò)以及改進后的骨干網(wǎng)絡(luò)結(jié)構(gòu)示意圖。從圖11b中可以看出,原始骨干網(wǎng)絡(luò)的SPPF層前面引入CA模塊,并將Conv模塊和C3模塊換成輕量級GhostConv模塊和C3Ghost模塊,最后將輸出結(jié)果同 P3、P4 和 P5 特征共同輸入至下一級 Neck 網(wǎng)絡(luò)。

圖11 改進前后的骨干網(wǎng)絡(luò)對比Fig.11 Comparison of backbone networks before and after improvement
CA注意力模塊的結(jié)構(gòu)圖如圖12所示,從圖中可以發(fā)現(xiàn),CA注意力模塊是通過對水平方向和垂直方向上分別進行平均池化,再使用轉(zhuǎn)換器對空間信息進行編碼,最后把空間信息通過加權(quán)的方式融合進通道中,這將有利于CA注意力機制全面考慮空間信息和通道信息,增強特征提取能力[19-20]。

圖12 CA注意力模塊Fig.12 CA attention module
Ghost結(jié)構(gòu)[21]由Ghost 卷積模塊和Ghost 瓶頸模塊組成。Ghost卷積模塊包括常規(guī)卷積和線性變換兩部分(圖13a),首先通過有限的常規(guī)卷積得到一部分特征圖,之后利用廉價的線性變換生成更多Ghost特征圖,生成的Ghost特征圖能夠極大的表現(xiàn)常規(guī)卷積中包含的冗余特征信息,最后通過恒等映射將兩組特征圖進行組合。Ghost瓶頸模塊(圖13b)是由兩個Ghost卷積模塊構(gòu)成的,其中一個Ghost 卷積作為擴展層,用于增加特征維度,擴張通道數(shù);另一個Ghost 卷積用于減少通道數(shù)使其與直連的特征相匹配,最后經(jīng)過shortcut連接后輸出特征。

圖13 Ghost結(jié)構(gòu)圖Fig.13 Ghost structure diagram
相比于原始骨干網(wǎng)絡(luò),在SPPF層前加入CA注意力模塊,不僅可以加強特征的表現(xiàn)力,使網(wǎng)絡(luò)更加關(guān)注重要的特征,而且可以在多尺度提取不受影響的情況下,保證特征圖精細程度,使得模型更加穩(wěn)定和準(zhǔn)確。這一點可以幫助骨干網(wǎng)絡(luò)有意識地提取出屬于甘蔗莖節(jié)的特征點,從而實現(xiàn)更好的檢測效果以及更高的檢測精度。
同時,引入Ghost網(wǎng)絡(luò)結(jié)構(gòu)的骨干網(wǎng)絡(luò)可以在不影響模型特征提取能力的情況下,降低模型計算量和參數(shù)量,減少模型的特征冗余。
3.1.2Head網(wǎng)絡(luò)的優(yōu)化
Head網(wǎng)絡(luò)通常接在Neck網(wǎng)絡(luò)之后,主要負責(zé)預(yù)測目標(biāo)檢測任務(wù)中的類別、位置、置信度等信息。它的輸入特征分別選取下采樣為32、16和8的卷積輸出結(jié)果,即分別對應(yīng)圖中的P5、P4和P3,在輸入圖像尺寸為640×640的情況下,分別用于檢測大小在32×32以上的大目標(biāo)、16×16以上的中目標(biāo)以及8×8以上的小目標(biāo)。然而在甘蔗莖節(jié)數(shù)據(jù)集的目標(biāo)面積占比均小于0.12%的任務(wù)中,Head網(wǎng)絡(luò)的大目標(biāo)檢測分支不適用于此目標(biāo)檢測任務(wù)。因此本文針對Head輸出網(wǎng)絡(luò)進行了如下優(yōu)化:將輸出的大目標(biāo)檢測分支剔除,只保留小目標(biāo)和中目標(biāo)檢測,這將有利于小目標(biāo)物體的位置信息檢測,降低模型后處理階段的容錯率,使模型更加專注于訓(xùn)練有用的特征,減少了網(wǎng)絡(luò)計算量和參數(shù)量,加快模型的推理速度,提高模型精度。其優(yōu)化結(jié)果如圖14。

圖14 Head網(wǎng)絡(luò)優(yōu)化示意圖Fig.14 Illustration of Head network optimization
3.2 算法優(yōu)化實驗對比
訓(xùn)練數(shù)據(jù)集均統(tǒng)一采用數(shù)據(jù)增強后的數(shù)據(jù),測試集采用原始數(shù)據(jù)10%的數(shù)據(jù),表3為不同模型及其對應(yīng)說明。

表3 模型名稱及其說明Tab.3 Model names and their descriptions
3.2.1算法優(yōu)化改進對比
不同YOLO v5改進算法在500輪訓(xùn)練過程中的性能指標(biāo)如圖15所示。
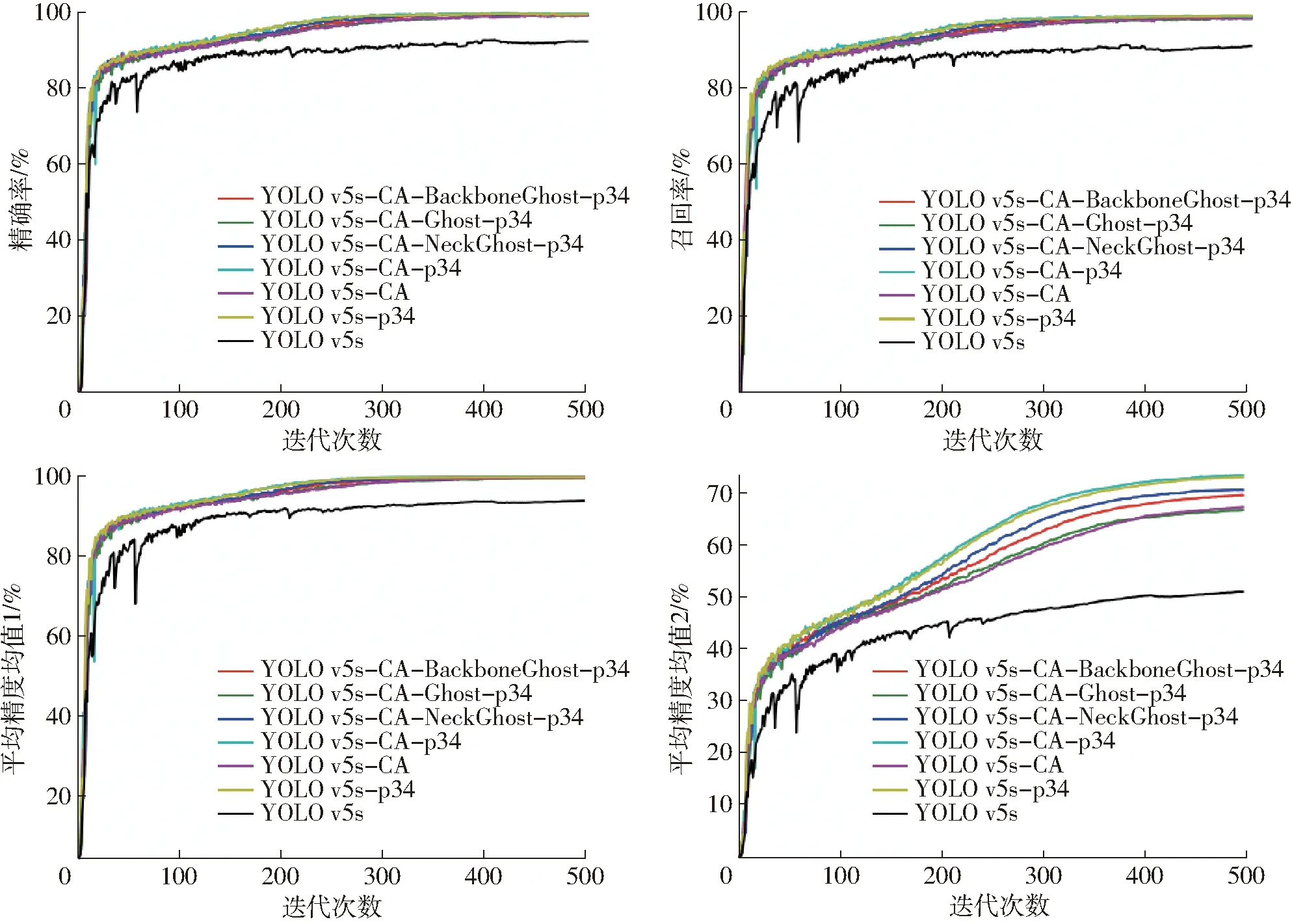
圖15 不同YOLO改進算法在訓(xùn)練過程中的性能結(jié)果Fig.15 Performance results of different YOLO improvement algorithms in training process
從圖15可得,單獨使用CA注意力機制或者單獨剔除大目標(biāo)檢測頭都能顯著提升模型性能,其中后者的優(yōu)化策略效果更佳。而同時使用CA注意力機制與剔除大目標(biāo)檢測頭的優(yōu)化策略,可獲得最佳性能表現(xiàn)。具體來說,單獨或者結(jié)合使用這兩種優(yōu)化策略對模型的精確率、召回率、平均精度均值1和平均精度均值2都有提升,在精度、召回率和平均精度均值1上差距較小,但在平均精度均值2上提升效果最為明顯。
在YOLO v5s-CA-p34的基礎(chǔ)上,對其骨干網(wǎng)絡(luò)、Neck網(wǎng)絡(luò)引入Ghost結(jié)構(gòu),發(fā)現(xiàn)在骨干網(wǎng)絡(luò)或Neck網(wǎng)絡(luò)中單獨引入Ghost結(jié)構(gòu)的模型在平均精度均值等性能指標(biāo)上都略微高于同時引入Ghost結(jié)構(gòu)的模型,特別是在平均精度均值2上的差異最大。而相比YOLO v5s-CA-p34模型,3種輕量化模型檢測精度都有細微下降,滿足在兼顧檢測精度的情況下實現(xiàn)模型輕量化需求。
通過訓(xùn)練得到7個模型的優(yōu)化參數(shù)后,使其在統(tǒng)一的測試集上進行測試,結(jié)果如表4所示。
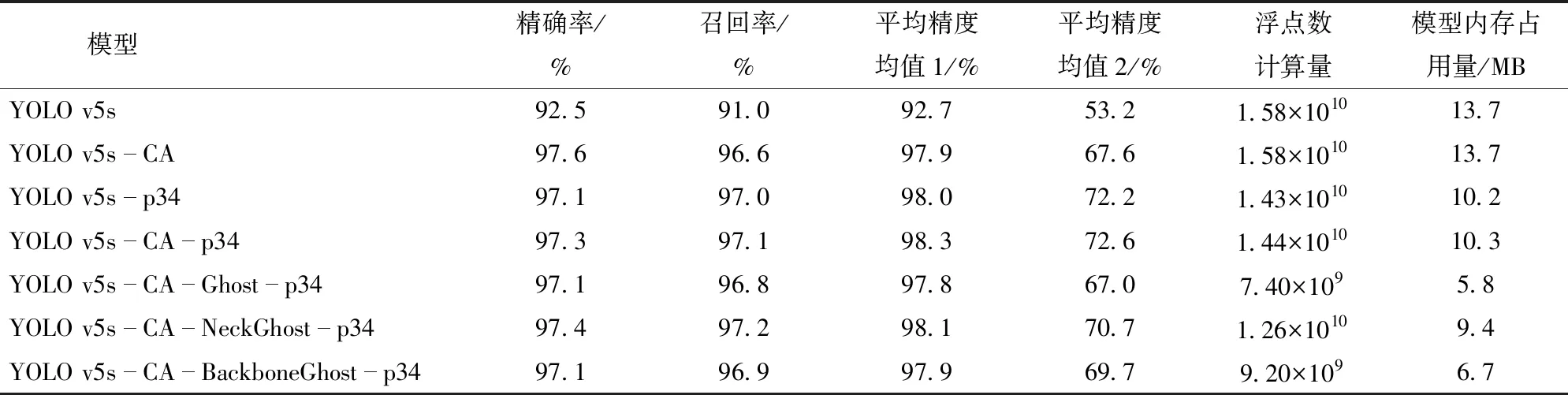
表4 算法優(yōu)化實驗測試集性能評估結(jié)果Tab.4 Performance evaluation results of algorithm optimization experiment test set
從表4可得,相比于 YOLO v5 原始模型,單獨采用 CA注意力模塊、單獨采用剔除大目標(biāo)檢測頭優(yōu)化策略的模型在測試集上的平均精度均值1分別提升5.2、5.3個百分點,在平均精度均值2上分別提高了13.6、19個百分點,當(dāng)兩種優(yōu)化方法結(jié)合時,其平均精度均值1和平均精度均值2分別提高5.6個百分點和19.4個百分點。
通過引入Ghost消融實驗,發(fā)現(xiàn)在Backbone網(wǎng)絡(luò)引入Ghost結(jié)構(gòu)的模型相比YOLO v5s-CA-p34模型在平均精度均值1僅降0.4個百分點,但是浮點數(shù)計算量和模型內(nèi)存占用量分別減少36%和35%。同時,與另外兩種引入Ghost結(jié)構(gòu)的模型相比,本模型在平均精度均值等性能上的優(yōu)勢十分有限,但是在浮點數(shù)計算量和模型內(nèi)存占用量的消減效果上優(yōu)化幅度較大,更符合實際部署應(yīng)用的需求。
從表4還可以發(fā)現(xiàn),無論是進行骨干網(wǎng)絡(luò)還是Head網(wǎng)絡(luò)優(yōu)化改進方法,其精確率差距小于0.5個百分點,召回率的差距小于0.6個百分點。該結(jié)果與在訓(xùn)練過程中驗證集的性能結(jié)果相近,說明模型并沒有過擬合。 最后通過對骨干網(wǎng)絡(luò)和 Head 網(wǎng)絡(luò)共同優(yōu)化改進,得到Y(jié)OLO v5s-CA-BackboneGhost-p34模型,其性能參數(shù)和損失值如圖16所示。
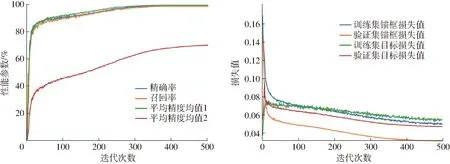
圖16 YOLO v5s-CA-BackboneGhost-p34模型性能參數(shù)與損失值變化曲線Fig.16 Performance parameters and loss curves variations of YOLO v5s-CA-BackboneGhost-p34
3.2.2與其他主流算法對比
為驗證本文提出的改進算法相較于其他檢測速度較快的主流目標(biāo)檢測算法的優(yōu)越性,本文將改進算法與DETR[22]、CenterNet[23]、YOLO v3-tiny、YOLO v4-Mish[24-25]、YOLO v5s、YOLO v5-lite-g、YOLOX-s[26]、YOLO v7-tiny[27]等算法在相同條件下進行比較實驗,實驗結(jié)果如表5所示。
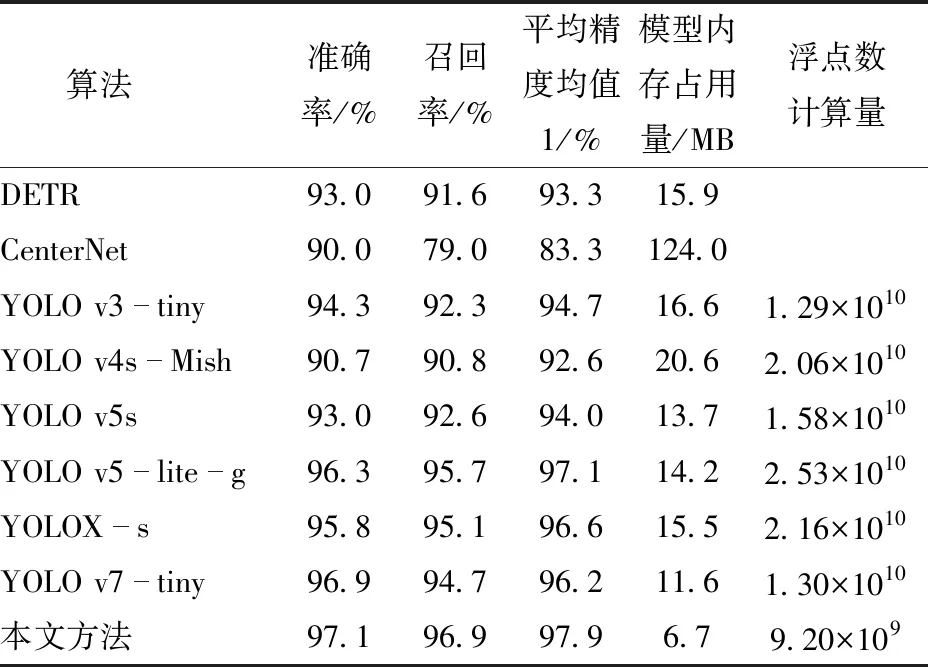
表5 主流算法性能對比實驗Tab.5 Comparative experiment of mainstream algorithms
通過表5可得,相較于其他主流的目標(biāo)檢測算法,本文提出的改進算法具有更高的檢測精度和更小的體積,優(yōu)勢非常明顯。
3.3 算法優(yōu)化后甘蔗莖節(jié)檢測實例
使用上述優(yōu)化算法,針對甘蔗莖節(jié)圖像實例在相同參數(shù)條件下進行了測試,如圖17所示(紫色圈表示漏檢,綠色圈表示誤檢)。在甘蔗莖節(jié)實例檢測中,檢測效果可以較為直觀通過誤檢情況、漏檢情況與正例的置信度區(qū)間3個指標(biāo)評價。

圖17 算法優(yōu)化后甘蔗莖節(jié)檢測實例對比Fig.17 Example comparison of sugarcane stem node detection after algorithm optimization
本文選擇了不同光照強度、不同莖節(jié)疏密程度的3個畫面進行甘蔗莖節(jié)實例檢測的對比分析。從圖17可以看出,頂部圖像為正常光照場景下,YOLO v5s模型存在漏檢甘蔗莖節(jié)的情況,而其余改進后的模型均能夠識別出全部甘蔗莖節(jié);中間圖像為莖節(jié)密集且燈光分布不均勻的場景下,大部分模型都出現(xiàn)了漏檢和誤檢情況,漏檢位置主要出現(xiàn)在光線較暗的一端;底部圖像為光線較暗的場景下,YOLO v5s-CA-BackboneGhost-p34識別出了所有莖節(jié),而其他兩種輕量化模型都出現(xiàn)了誤檢情況。
綜上所述,本文進行算法優(yōu)化得到的YOLO v5s-CA-BackboneGhost-p34模型在復(fù)雜光照場景下取得較好的檢測效果,也具有較小的體積,更符合作為邊緣端部署的模型。
4 模型邊緣端部署
將訓(xùn)練好的YOLO v5s-CA-BackboneGhost-p34模型部署到邊緣設(shè)備上,這將有利于提高數(shù)據(jù)傳輸過程中的響應(yīng)速度和數(shù)據(jù)安全性,同時為了提高模型檢測速度,利用TensorRT進行加速,進一步驗證了模型的可靠性,并且提高了檢測效率[28]。TensorRT加速前后速度對比如圖18所示。

圖18 TensorRT加速前后對比Fig.18 TensorRT acceleration before and after comparison
從圖18中可知,將模型部署在邊緣設(shè)備上,并通過TensorRT加速,模型檢測速度比原來提高1.1倍,檢測速度僅需10.5 ms,具有更高的實用性與便捷性,為實際工廠化切種提供了良好的基礎(chǔ)。
最后,利用VNC(Virtual neckwork computing)軟件進行桌面共享和遠程操作,實現(xiàn)檢測畫面的實時顯示。
本模型的開發(fā)環(huán)境如下:開發(fā)和調(diào)試是在PyCharm專業(yè)版上進行,模型的訓(xùn)練和測試是在Windows 10系統(tǒng)上,GPU為英偉達的3060顯卡。模型部署采用的嵌入式設(shè)備是英偉達的Jetson Orin NX 16GB版,它具有強大的計算能力和豐富的輸入輸出接口,適合進行邊緣計算任務(wù),部署環(huán)境是在Ubuntu 20.04.5系統(tǒng)上,深度學(xué)習(xí)框架采用Pytorch 2.0版本,采用TensorRT 8.5.2.2。
5 實際切種試驗與結(jié)果分析
5.1 切種質(zhì)量評價準(zhǔn)則
根據(jù)廣西壯族自治區(qū)甘蔗良繁基地的用種情況以及農(nóng)藝的需求,提出以下切種質(zhì)量評價準(zhǔn)則(如圖19所示):切口與莖節(jié)距離必須大于5 mm,否則屬于傷芽情況;蔗種必須包含2個或3個莖節(jié),否則屬于單芽段蔗種。這兩種類型的種子都不利于甘蔗種植。因為切口離莖節(jié)太近會破壞莖節(jié)的結(jié)構(gòu),影響種子吸收營養(yǎng)和水分,而種植單芽段的蔗種無法保證高出芽率,影響甘蔗產(chǎn)量。所以在進行切種作業(yè)時,既要保證切割位置的準(zhǔn)確性,還要保證足夠的莖節(jié)數(shù)量。

圖19 甘蔗種子切割質(zhì)量分類Fig.19 Classification of sugarcane seed cutting quality
5.2 實際切種試驗
為測試本文優(yōu)化改進模型的效果,在本課題組開發(fā)的橫向智能切種工作站試驗樣機上進行雙芽蔗切種驗證試驗。
(1)樣本準(zhǔn)備:本文將保留的20根長度約為1.8 m的甘蔗進行標(biāo)號,并測量記錄每根甘蔗的莖段長度和莖節(jié)數(shù)量,如圖20a、20b所示。

圖20 實際切種試驗流程Fig.20 Actual seed cutting test flow
(2)莖節(jié)特征檢測識別與定位:在傳送速度為0.15 m/s的情況下,蔗種被有序地送入檢測區(qū)域(圖20c),對整根甘蔗的莖節(jié)特征進行實時檢測識別與定位,并將數(shù)據(jù)保存。接著,系統(tǒng)會根據(jù)畸變矯正后的莖節(jié)坐標(biāo)的x軸從小到大排序,將相鄰的兩個莖節(jié)的中心坐標(biāo)計算出來,并將偶數(shù)下標(biāo)的中心坐標(biāo)作為切割位置發(fā)送給控制器。
(3)切種作業(yè):當(dāng)甘蔗經(jīng)過切刀平臺前的光電傳感器時,6把切刀將根據(jù)切割位置進行自動調(diào)刀與切種,如圖20d、20e、20f所示。
(4)結(jié)果統(tǒng)計分析:通過比較人工測量莖段長度與系統(tǒng)計算莖段長度,評測莖節(jié)識別方面的定位誤差,如圖21所示。最后,對切種結(jié)果進行人工統(tǒng)計,統(tǒng)計結(jié)果見表6。

表6 切種結(jié)果統(tǒng)計Tab.6 Statistics of seed cutting results

圖21 甘蔗莖段的檢測誤差分析圖Fig.21 Histogram of detection error of sugarcane stem segments
經(jīng)統(tǒng)計,20根甘蔗的莖段定位精度平均誤差約為2.4 mm,在均值加減2個標(biāo)準(zhǔn)差(±2σ)的范圍內(nèi)覆蓋大約97%的數(shù)據(jù)。甘蔗莖節(jié)檢測有1個漏檢,切種合格率為100%。由于漏檢的莖節(jié)位置位于甘蔗末端,所以并未對切種任務(wù)造成影響。因此,本試驗足以驗證本模型的優(yōu)越性、可靠性以及實用性。
6 結(jié)論
(1)經(jīng)實驗測試,數(shù)據(jù)增強可以有效提高模型精度和泛化能力,降低過擬合的風(fēng)險。其中精度、召回率、平均精度均值1以及平均精度均值2分別提高3.8、5.2、5.4、8.5個百分點。
(2)在YOLO v5s的基礎(chǔ)上,在骨干網(wǎng)絡(luò)中添加CA注意力機制以及引入Ghost結(jié)構(gòu),可以穩(wěn)定提升模型對甘蔗莖節(jié)的特征提取能力,幫助模型更好的檢測莖節(jié)這類小目標(biāo),并且可以在確保高精度的情況下降低模型復(fù)雜度,為部署在嵌入式設(shè)備上奠定基礎(chǔ);在Head網(wǎng)絡(luò)剔除大目標(biāo)檢測頭,有利于莖節(jié)小目標(biāo)的位置信息檢測,降低模型后處理階段的容錯率,使模型更加專注于訓(xùn)練有用的特征,減少網(wǎng)絡(luò)浮點數(shù)計算量和參數(shù)量,加快模型推理速度,提高模型精度。試驗表明,同時使用CA注意力模塊以及剔除大目標(biāo)檢測策略對模型提升效果最好,并且僅在骨干網(wǎng)絡(luò)引入Ghost結(jié)構(gòu)可以兼顧模型精度和大小,更符合邊緣端部署的應(yīng)用需求。經(jīng)實驗測試,YOLO v5s-CA-BackboneGhost-p34較原模型平均精度均值1提升5.2個百分點,平均精度均值2提升16.5個百分點,浮點數(shù)計算量和模型內(nèi)存占用量分別降低42%和51%,相比其他主流的目標(biāo)檢測方法,其具有更高的檢測精度和更小的體積。
(3)將YOLO v5s-CA-BackboneGhost-p34模型部署在Jetson Orin NX16GB邊緣設(shè)備上,并通過TensorRT加速后,每幅圖的檢測時間僅需10.5 ms,檢測速度提高1倍多。
(4)經(jīng)實際切種試驗驗證,在傳送速度為0.15 m/s的情況下,切割20根長度約為1.8 m的甘蔗,計算與測量的莖段長度平均誤差為2.4 mm,切種合格率為100%。
(5)所提方法可以有效提高甘蔗智能橫向預(yù)切種工作站的切種精度和效率,適于現(xiàn)場生產(chǎn)環(huán)境下對甘蔗莖節(jié)進行精準(zhǔn)、高速的檢測,滿足工廠化實時切種的需求,為甘蔗橫向切種工作站的工廠化、智能化以及標(biāo)準(zhǔn)化應(yīng)用提供有效的技術(shù)支持。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
