核主成分分析法在酒店數據文本分類中的應用
2023-11-22 06:03:25黃金銘
現代信息科技 2023年19期
關鍵詞:特征提取


摘? 要:核主成分分析法作為一種非線性數據處理方法,被廣泛應用于數據降維。文章將核主成分分析法應用于中文文本分類領域,使用核主成分分析法對酒店評論數據集進行特征提取。然后,基于核主成分分析法降維后的數據,對比極端梯度提升算法和邏輯回歸算法的文本分類效果。實驗結果表明,核主成分分析法能夠有效去除數據冗余,提升中文文本分類的準確率和查全率。相較于極端梯度提升算法,邏輯回歸算法在訓練集和測試集上的分類準確率差距不大,模型的泛化能力較好。
關鍵詞:核主成分分析法;特征提取;邏輯回歸;文本分類
中圖分類號:TP39? 文獻標識碼:A? 文章編號:2096-4706(2023)19-0160-04
Application of Kernel Principal Component Analysis in Text Classification of Hotel Data
HUANG Jinming
(Public Teaching Department, Heze Medical College, Heze? 274000, China)
Abstract: As a nonlinear data process method, Kernel Principal Component Analysis is widely used in data dimensionality reduction. This paper applies the Kernel Principal Component Analysis to the field of Chinese text classification and uses it to perform feature extraction of the hotel review datasets. Then, based on the data after dimensionality reduction by Kernel Principal Component Analysis, it compares the text classification performance of extreme gradient boosting algorithm and logistic regression algorithm. The experimental results show that the Kernel Principal Component Analysis can effectively remove data redundancy and improve the accuracy and recall rate of Chinese text classification. Compared to the extreme gradient boosting algorithm, the classification accuracy of the logistic regression algorithm between the training and testing sets is not significantly large, and the model has better generalization ability.
Keywords: Kernel Principal Component Analysis; feature extraction; logistic regression; text classification
0? 引? 言
作為一種監督學習技術,文本分類根據一定的規則自動對文本進行分類和標注。近年來,隨著數字化信息的持續增加,文本分類受到了信息檢索、數據挖掘和機器學習領域研究人員的極大關注。互聯網中信息和數據的持續增長導致對高性能文本分類的需求不斷增加[1]。然而,隨著數據量的急速膨脹,數據維度也越來越高,高維文本數據不僅會降低分類準確率和增加計算成本,對計算機的內存也提出了更高的要求。因此,為了消除數據冗余,為后續分類提供更加可靠的信息,在文本分類之前必須進行數據降維。
大多數的文本分類都可以分為四個階段:數據預處理、降維、文本表示和文本分類。數據降維是機器學習的一個重要組成部分,也是文本分類的必要步驟。恰當的降維方法能夠降低計算復雜度,提高分類性能,并避免過度擬合問題。因此,眾多領域的研究人員都對文本分類的降維給予了極大的關注,并提出了各種用于文本分類的降維方法。數據降維一般分為特征選擇和特征提取。其中,特征選擇方法通常分為兩種:一種是基于頻率統計方法,另一種則是基于特征與文本、特征與類別信息之間的相關性統計的方法,每種特征選擇方法都有其不足之處。
特征提取是模式識別領域對高維數據降維的另一種常見方法,其中,主成分分析法(Principal Component Analysis, PCA)、線性判別分析法等算法可以有效對線性數據進行降維。然而,真實情境下的數據大多是高度非線性的,這時上述線性方法將不再有效。為了處理非線性數據帶來的問題,學者們提出了非線性特征提取算法,比如,核主成分分析法(Kernel Principal Component Analysis, KPCA),流形學習算法等。
其中,核主成分分析法是在傳統PCA方法基礎上改進的方法,可以有效消除輸入數據的冗余信息。與其他非線性方法相比,核主成分分析法不涉及非線性優化,因為核主成分分析法只需要線性代數,這使得它和傳統主成分分析法一樣簡單,此外,核主成分分析法不要求在建模之前指定特征數量[2]。因此,核主成分分析法得到了廣泛的研究。文獻[3]將KPCA法與相關向量機結合用于鑒別人體動作變化。付華等[4]等人為了提高瓦斯涌出量預測精度,使用KPCA法提取樣本中的特征向量,有效提高了預測模型的準確度。診斷高壓斷路器機械故障時,文獻[5]首先使用KPCA法對故障特征進行數據降維,將提取的特征向量輸入到模型中學習,實驗結果表明,使用KPCA方法降維之后的數據可以加快模型的運行速度,提高運行效率。
為了驗證核主成分分析法在實際場景的適用性,本文選擇攜程酒店評論數據文本集,經過對數據集進行分詞處理、數據轉換、樣本均衡等預處理,使用核主成分分析法來提取文本特征,并使用邏輯回歸(Logistic Regression, LR)模型對文本進行分類。實驗結果表明,核主成分分析法可以應用于酒店數據文本分類問題,并能有效提高后續文本分類的準確率。基于降維后的數據,對比邏輯回歸和極端梯度提升(Extreme Gradient Boosting, XGBoost)算法的文本分類效果,實驗結果表明,邏輯回歸模型的分類準確率和查全率明顯優于XGBoost算法。
1? 核主成分分析法
KPCA法是非線性特征提取算法最具代表性的方法之一,其基本思想是通過非線性映射將原始數據映射到高維特征空間,將數據結構從非線性修改為線性,然后在高維特征空間基于PCA法進行數據處理。
設X = [x1,x2,…,xN] ∈ RD×N是一個高維數據集,其中xi ∈ RD(i = 1,2,…,N)表示第i個樣本,N表示樣本大小。首先通過非線性函數?(x)將訓練樣本xi映射到高維特征空間,經過標準化處理,高維空間中的數據?(xi)滿足式(1):
在PCA算法中,樣本X的協方差矩陣為 ,因此高維特征空間中的協方差矩陣為:·
,求解協方差矩陣的特征值問題:λi ξi = C ξi。其中,λi是協方差矩陣C的特征值,ξi是與特征值λi相對應的特征向量。
由于協方差矩陣C很難直接計算,因此引入核矩陣K。本文將核矩陣K定義為 ,求解核矩陣的特征值問題:。其中, 是核矩陣K的特征值;αi是與特征值? 相對應的特征向量。
隨后,將協方差矩陣C和核矩陣K引入核矩陣K的特征方程中,這樣,協方差矩陣C的特征向量ξi可以用非線性函數?(xi)表示,即 。其中, 是ξi的第i個系數。
計算得出核矩陣K的特征值 ,根據式(2)計算上述特征值的貢獻率gi和累計貢獻率G,將所有特征值按貢獻率大小降序排列:。
一般來說,若累積到第s個特征值,累計貢獻率高于85%時,則認為這些特征值對應的信息足以代表原始數據的信息。最后,高維特征空間中的數據?(xi)對特征值ξi的映射Pi(x)就是第i個主成分,其中,Pi(x)如式(3)所示:
原始數據集X = [x1,x2,…,xN]降維后得到的主成分矩陣記為D={P1(x),P2(x),…,Ps(x)},由映射組成,其中s<N,矩陣D充分保留了原始數據集X的信息[6]。經過KPCA法處理,去除了原始數據中的冗余信息,為文本分類提供了穩健的數據基礎。
2? 實驗數據集
2.1? 數據集來源
為了檢驗算法的適用性,本文采用由譚松波整理的攜程酒店評論數據集進行實驗。所有的程序均用PyCharm編程,在PyCharm社區版2022軟件實現,計算機的硬件配置是:Intel(R) Core(TM) i5-10500 CPU@3.10 GHz 3.10 GHz,系統類型是64位操作系統。
2.2? 評價指標
為了綜合評價LR算法和XGBoost算法對酒店評論數據集文本分類的效果,本文選取以下四個評價指標:召回率(recall)、精度(precision)、F1分數(F1 score)和準確率(accuracy)。召回率用于計算二分類問題中被正確預測的正樣本所占比例。精度計算被分類為正的實際為正的樣本數所占的比例。F1分數同時考慮了分類模型的召回率和精度,其最大值是1,最小是0,數值越大,表明模型分類能力越好[7]。準確率衡量分類準確的樣本數占樣本總數的比例。下面給出召回率(r)、精度(p)、F1分數和準確率(AUC)的定義:
其中,TP表示在二分類問題中被準確預測為正的正樣本數;FN表示在二分類問題中被錯誤預測為負的正樣本數;FP表示在二分類問題中被錯誤預測為正的負樣本數;TN表示在二分類問題中被準確預測為負的負樣本數。
2.3? 數據預處理
為了方便處理數據,首先將數據的格式轉換為字符串類型,去除評論中的標點符號和數字,并作分詞處理。為了節省存儲空間和提高后續的分類效率,處理數據時可以過濾某些極其普遍的、沒有任何實際含義的詞匯,由于本文討論的背景為酒店,故本文將酒店、賓館、攜程等這類作為業務背景常出現的詞匯加入停用詞處理范圍,以發現更加具備業務本身價值的特征。該酒店評論數據集共有7 766條評論,包括5 322條正面評論和2 444條正面評論。顯然,該數據集存在嚴重的樣本不平衡問題。為了解決樣本不均衡問題,本文使用下采樣策略,通過刪除分類中多數類樣本的樣本數量來實現樣本均衡。下采樣在保留少量樣本的同時,會丟失多數類樣本中的一些信息,樣本總量在減少。
在正式建模之前,本文首先將詞匯轉換為向量,即詞嵌入,本文采用TF-IDF(term frequency–inverse document frequency)方案,將每一個詞匯處理后得到一個詞匯向量。通過詞嵌入后的特征維度過多,導致計算量巨大,而且一些TF-IDF比較低的特征本身會對模型產生影響。為了消除上述負面影響,需要對特征進行精簡,去掉一些特征,因此在分類之前必須進行特征提取。
3? 實驗結果與分析
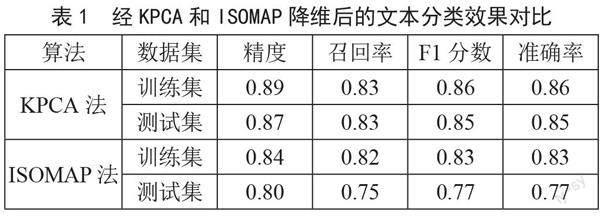
為了使獲得的實驗結果可信,將數據集按照3:1分為訓練集和測試集,每次實驗的訓練樣本集和測試樣本集隨機確定。為了驗證KPCA方法在文本分類中的降維效果,本文選取了同為非線性降維方法的等距特征映射(Isometric Feature Mapping, ISOMAP)算法進行對比,此處分類算法統一選用邏輯回歸算法,實驗結果如表1所示。從表1可以看出,使用核主成分分析法降維后的分類模型無論是在測試集上,還是在訓練集中,其分類召回率、精度、F1分數和準確率都優于ISOMAP算法,尤其在測試集中,使用核主成分分析法降維后的分類準確率提高了大約8%,召回率提高了約8%,精度提高了約7%,說明核主成分分析法適用于中文文本分類情境,而且具有良好的降維效果。
在KPCA算法的基礎上,分別采用邏輯回歸算法和XGBoost算法對酒店評論的分類效果進行比較研究。實驗結果如表2所示。表2對比了LR算法和XGBoost算法的文本分類效果,可以看出,邏輯回歸算法在訓練集和測試集上的分類準確率差距不大,模型的泛化能力良好。而XGBoost算法在訓練和測試集的分類準確率之差相比邏輯回歸算法較大,模型整體的泛化能力不足。
為了更加直觀評價邏輯回歸算法和XGBoost算法的文本分類效果,繪制出兩個算法在測試集上的ROC曲線,如圖1所示。圖1中藍色曲線表示XGBoost算法在測試集上的分類表現,紅色曲線代表邏輯回歸算法在測試集上的分類表現,ROC曲線下方的面積越大,說明算法的分類性能越優秀。從圖1可以看出,邏輯回歸算法的分類性能優于XGBoost算法。
4? 結? 論
本文基于攜程酒店點評數據,首先使用核主成分分析法對數據進行降維,然后使用邏輯回歸算法對文本進行分類。實驗結果表明,相較于等距特征映射算法,核主成分分析法能夠有效提升中文文本分類的準確率和查全率。基于核主成分分析法降維后的數據,對比極端梯度提升算法和邏輯回歸算法的酒店文本分類效果,結果表明邏輯回歸模型的召回率、精度、F1分數和準確率均高于極端梯度提升算法,邏輯回歸算法的分類性能優于極端梯度提升算法。
參考文獻:
[1] ABDALLA H,AMER A A. On the integration of similarity measures with machine learning models to enhance text classification performance [J].Information Sciences,2022,614:263-288.
[2] SCH?LKOPF B,SMOLA A,M?LLER K R. Kernel principal component analysis [C]//Artificial Neural Networks - ICANN '97,7th International Conference.Lausanne:DBLP,1997:583-588.
[3] 吳建寧,林秋婷,伍濱.基于核主成分分析的相關向量機人體動作分類新型模型 [J].中國生物醫學工程學報,2022,41(6):641-649.
[4] 付華,付昱,趙俊程,等.基于KPCA-ARIMA算法的瓦斯涌出量預測 [J].遼寧工程技術大學學報:自然科學版,2022,41(5):406-412.
[5] 張迅,黃軍凱,趙超,等.基于KPCA-SVM的高壓斷路器機械故障診斷 [J].測試技術學報,2023,37(2):158-164.
[6] LI X,JIA R,ZHANG R,et al. A KPCA-BRANN based data-driven approach to model corrosion degradation of subsea oil pipelines [J].Reliability Engineering and System Safety,2022:108231[2023-02-06].https://ideas.repec.org/a/eee/reensy/v219y2022ics0951832021007092.html.
[7] 周志華.機器學習 [M].北京:清華大學出版社,2016.
作者簡介:黃金銘(1995.09—),女,漢族,山東平
度人,助教,碩士研究生,研究方向:數據挖掘。
收稿日期:2023-04-09
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
