多標簽分類綜述
2023-11-16 00:50:40李冬梅孟湘皓張小平趙玉鳳
計算機與生活 2023年11期
李冬梅,楊 宇,孟湘皓,張小平,宋 潮,趙玉鳳+
1.北京林業大學信息學院,北京 100083
2.國家林業草原林業智能信息處理工程技術研究中心,北京 100083
3.中國中醫科學院中醫藥數據中心,北京 100700
隨著信息技術的不斷發展,蘊含豐富信息的標簽數據在呈指數級別地增長。為了從中獲取更多有價值的信息,研究人員開展了一系列與標簽分類相關的研究。傳統的單標簽分類包括二分類和多分類,其最終結果都是將標簽集中的單個標簽分配給一個實例。目前,這一研究方向已有許多成熟的算法,這些算法具有較好的性能,并成功地應用于許多領域[1]。然而,在現實情況中,一個實例往往同時與多個標簽相關聯[2]。例如,在文本分類中,一份電子病例可能與糖尿病、高血壓、冠心病等多種疾病有關[3];在圖像分類中,一張舌診圖像可以同時表達舌色、舌苔、形狀等特征[4],進而能推斷出患者的多種體征標簽[5];在音樂分類中,一段音頻可以傳遞各種信息,如鋼琴、古典樂、莫扎特等[6]。這一研究方向被稱為多標簽分類,其本質是將一個實例與一個標簽集合相關聯。與單標簽分類不同的是,在多標簽分類中,每個實例對應的標簽不止一種,標簽的數量也是不確定的。此外,標簽與標簽之間存在語義相關性,一些領域的數據集還存在標簽不均衡現象,這些問題都給多標簽分類任務帶來了一定的挑戰。
多標簽分類問題的研究出現在2000 年初,Tsoumakas等人[7]于2007 年首次對多標簽分類進行了綜述。隨后,Zhang 等人[8]介紹了多標簽學習的基本原理,同時還分析了挖掘標簽之間相關性的3 種策略,并對8 種典型的多標簽學習算法進行了討論。Mayano 等人[9]根據標簽間的依賴性和維數等特征,對來自不同領域具有不同特征的20 個數據集上的18種多標簽分類集成算法進行了評估。武紅鑫等人[10]從監督學習和半監督學習兩方面對多標簽分類算法進行了綜述,同時還從不同的領域對其實際應用進行了介紹。近年來,深度學習技術發展迅猛,不少結合深度學習的多標簽分類方法被提出。目前,多標簽分類方法可以分為傳統的多標簽分類方法以及基于深度學習的多標簽分類方法。傳統機器學習方法從機器學習的理論出發,存在文本表示向量特征表達能力不足、人工實現特征表示的成本過高等問題;深度學習方法則通過卷積神經網絡、循環神經網絡等結構自動對特征進行提取,釋放了人工成本,增強了特征表達能力。因此,本文將從傳統和深度學習兩個角度分別對多標簽分類方法進行介紹,總體框架如圖1 所示。
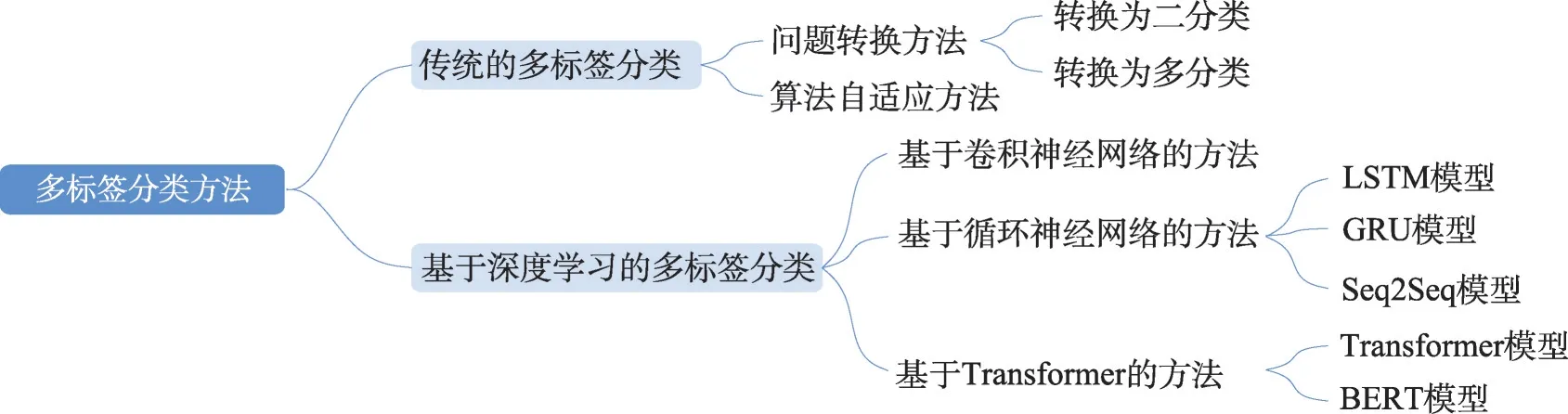
圖1 多標簽分類方法的總體框架Fig.1 Overall framework of multi-label classification methods
1 多標簽分類的定義
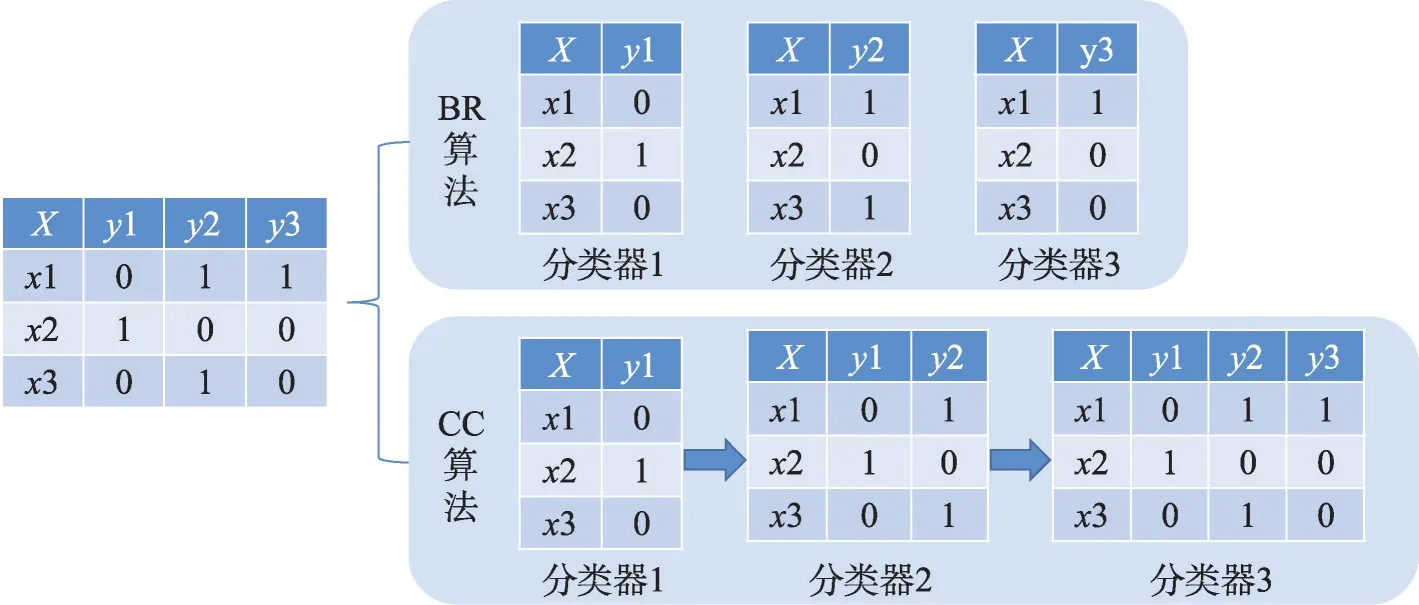
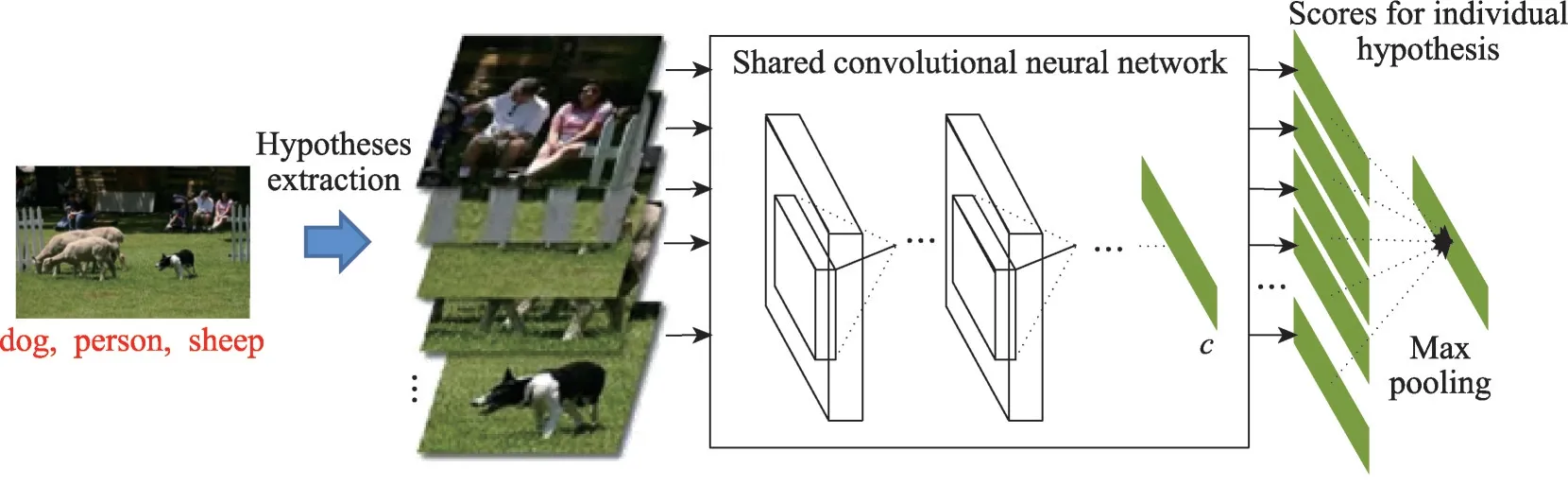
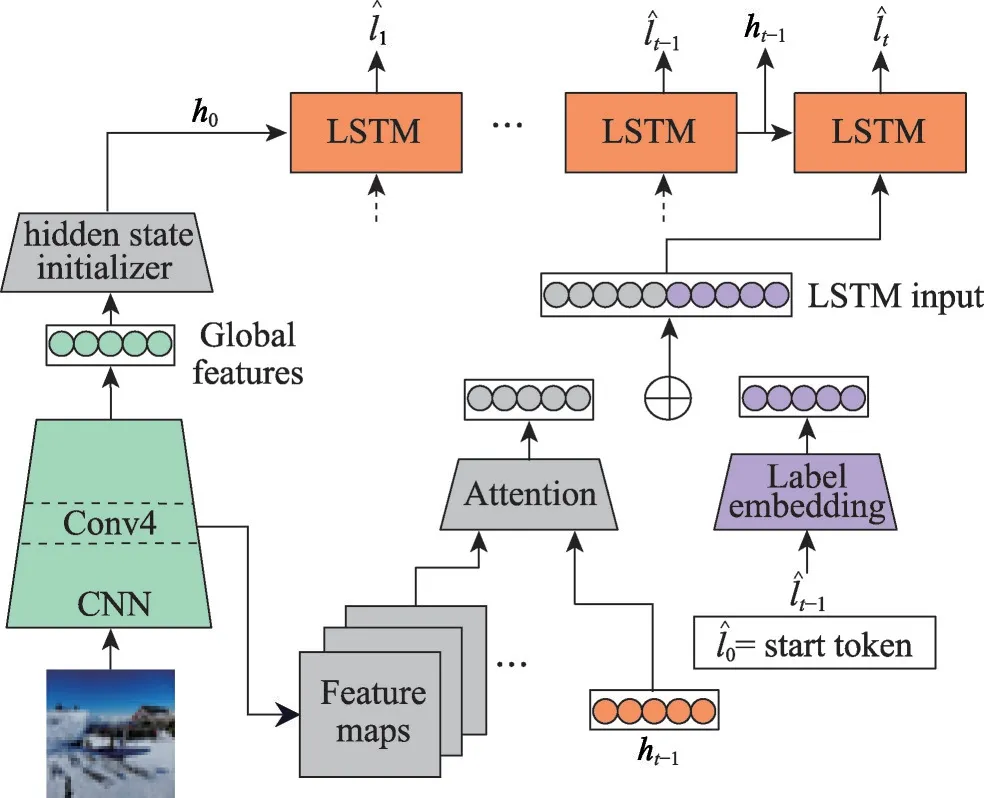
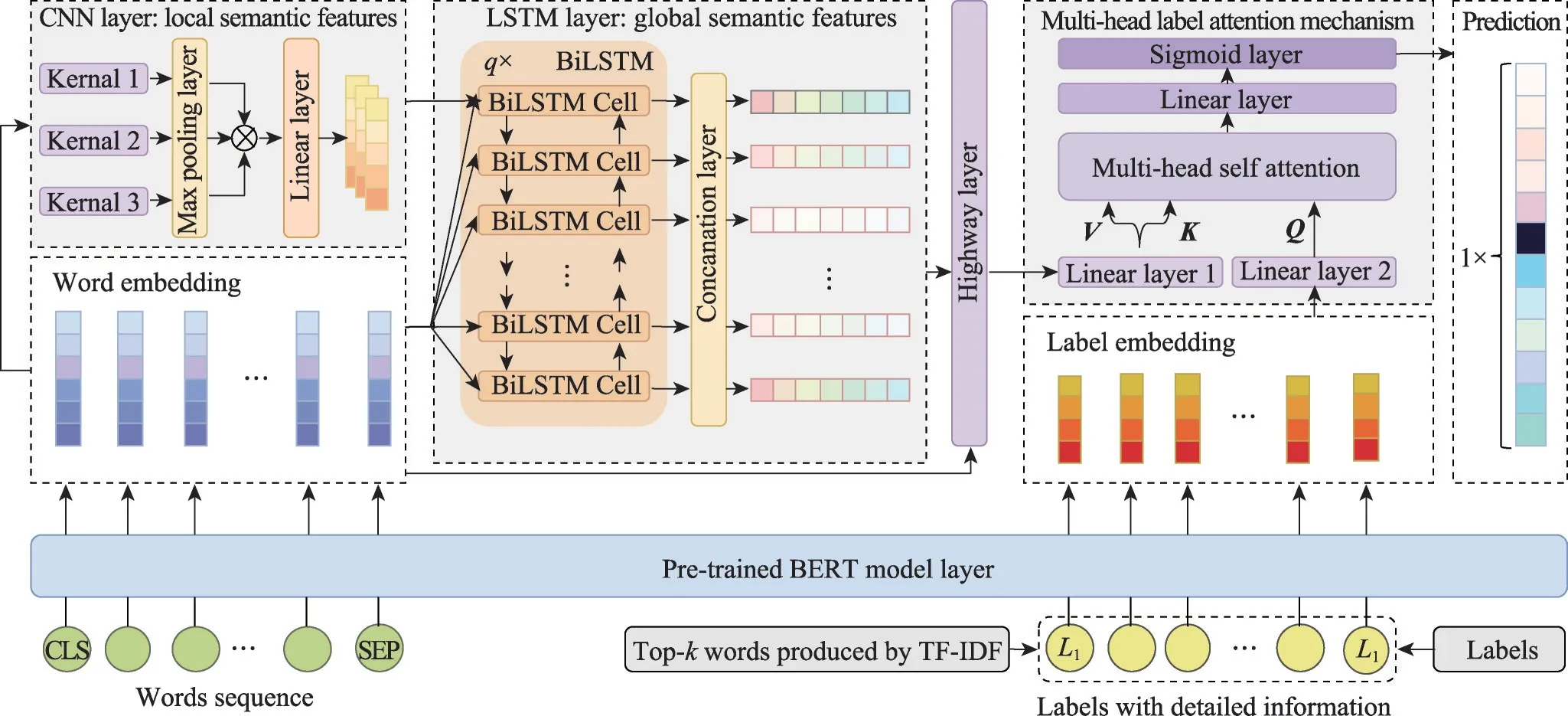
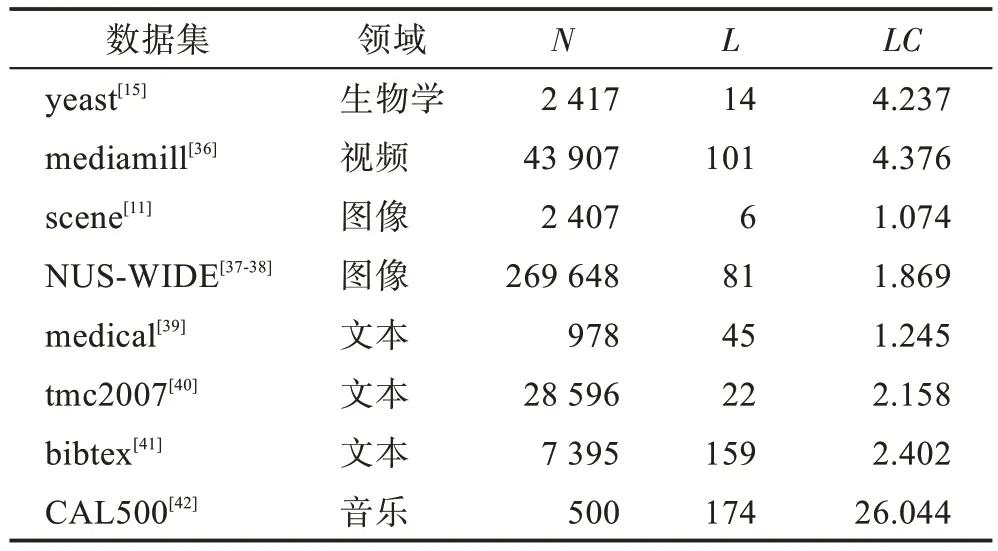
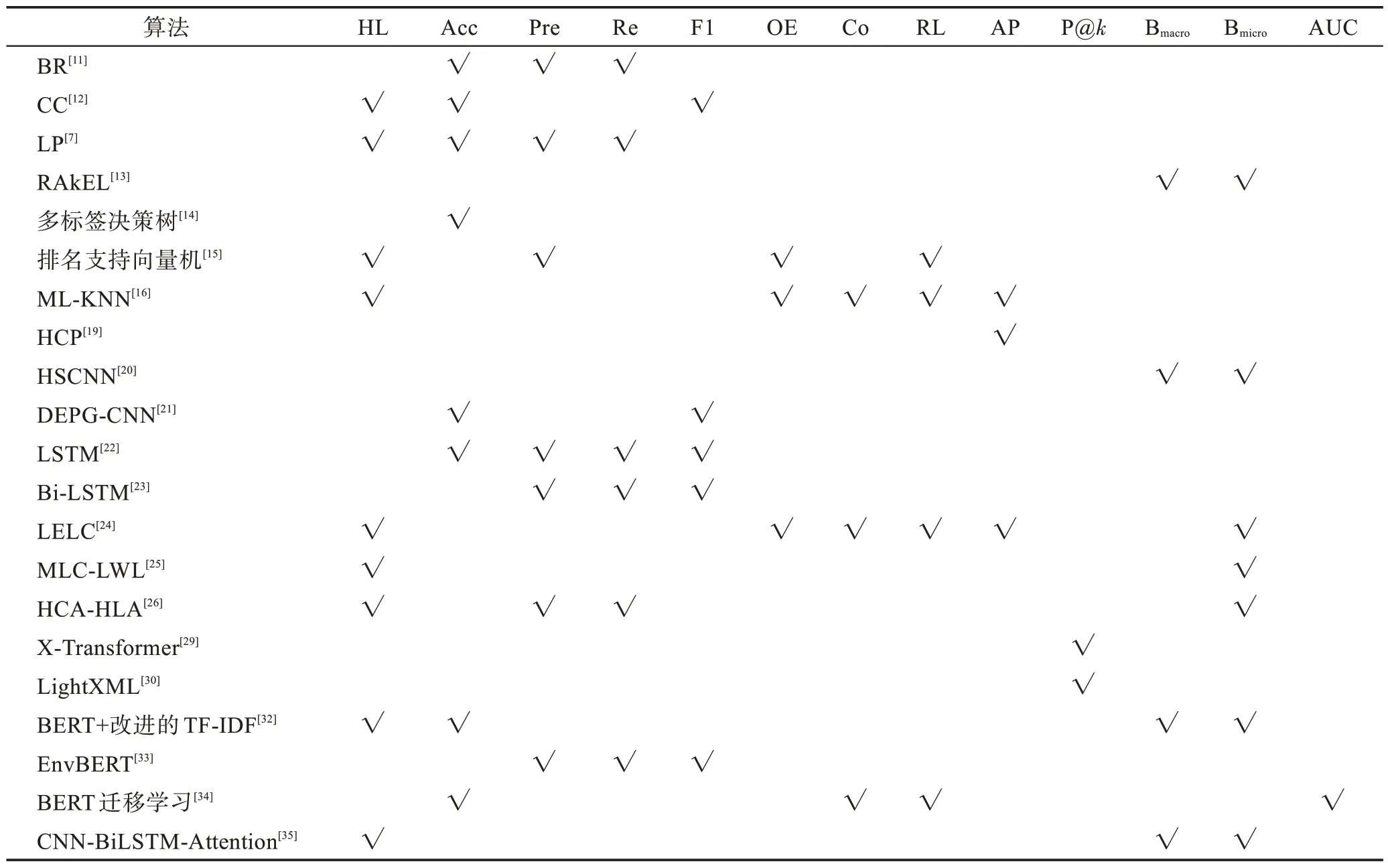
給定一個樣本空間X=R,xi∈X是維度為d的特征向量,以及標簽空間Y={y1,y2,…,yq},yi∈Y表示標簽集合中的各個標簽,q表示標簽空間的大小。當標簽j和樣例xi相關時,yj等于1;當標簽j和樣例xi不相關時,yj等于0。多標簽分類任務的最終目的是學習一個分類器h(X),該分類器使預測樣本P的預測結果h(P)∈Y。因此,對于每個樣例xi∈X,都能產生標簽空間Y的二分集合(Yi,,其中Yi表示相關標簽的集合,Yˉi表示不相關標簽的集合。在大多數情況下,多標簽分類模型對應于一個實值函數f:X×Y→R,其中f(x,y)表示y∈Y是x的正確標簽的置信度。該實值函數也可以轉換為一個排名函數rankf(x,y),它將輸出映射至[1,q]的空間中,排名越靠前代表該標簽評分越高,即如果f(xi,y1)>f(xi,y2),那么rankf(xi,y1) 多標簽分類的流程如圖2 所示,包括數據預處理、特征工程、多標簽分類模型訓練以及性能評估4個階段。原始數據集中往往包含了許多噪聲數據,如停用詞、數據缺失以及拼寫錯誤等。這些噪聲和不必要的特征在一定程度上會影響模型的性能,因此需要對數據進行預處理操作。特征工程是分類任務中最重要的部分,包含特征表示以及特征選取兩大步驟。典型的特征表示方法有one-hot、Word2Vec等,典型的特征選取方法有TF-IDF、期望交叉熵等。不同性能的多標簽分類算法對分類的結果有著直接影響,可以分為傳統的多標簽分類算法和基于深度學習的多標簽分類算法。在最終的性能評估環節中,將符合預期的模型保留下來即可得到最佳分類模型。 圖2 多標簽分類的流程圖Fig.2 Flowchart of multi-label classification 根據處理問題的角度,可以將傳統的多標簽分類算法分為兩大類,分別為問題轉化方法和算法自適應方法。 2.1.1 問題轉換方法 問題轉換(problem transformation,PT)方法的本質是簡單地將多標簽分類問題轉換為多個單標簽分類問題。Boutell 等人[11]提出了一種二元相關(binary relevance,BR)算法。該算法為每一個標簽訓練一個單獨的二分類器,然后用所有的分類器對樣本進行預測。這樣的做法實現起來較為容易,但是并沒有考慮各標簽間的相關性。在實際應用中,考慮標簽間的相關性在一定程度上對多標簽問題模型具有促進效果,如具有“武俠”標簽的電影很可能同時具有“動作”標簽。針對該問題,Read 等人[12]提出了分類器鏈(classifier chains,CC)算法。該算法在BR 的基礎上對樣本標簽進行了排序,在預測樣本某一個標簽時,除了要考慮對應的特征之外,還要考慮當前標簽的上一個標簽。圖3 對比了BR 算法和CC 算法,其中X表示輸入樣本空間,Y表示標簽空間。這兩類算法都將一個多標簽分類問題轉換為了3 個二元單標簽分類問題,不同的是,CC 算法在各分類器上額外考慮了之前的標簽。 圖3 BR 算法和CC 算法對比Fig.3 Comparison of BR algorithm and CC algorithm 更為復雜地,可以將多標簽分類問題轉換為多分類問題。Tsoumakas 等人[7]提出了標簽冪集(label power-set,LP)算法。該算法將每個樣本對應的標簽集合當作一個新的類別標簽,當兩個樣本對應的標簽集合相同時,則將這兩個樣本歸為一類。然而,當標簽數量n過多時,其產生的類別標簽數量將在[0,2n-1]的空間中分配,導致數據變得非常稀疏。由此可見,LP 算法的本質就是將多標簽分類任務轉化為具有2n個類別標簽的多分類任務,它僅適用于標簽較少的場景。針對LP 的缺陷,Tsoumakas 等人[13]提出了隨機子標簽集成(randomk-labelsets,RAkEL)算法。該算法結合了集成學習和LP 算法,將初始標簽集根據相交策略或者重疊策略劃分為若干個隨機的小標簽集,然后集成多個LP 分類器以保證預測的完整性。 2.1.2 算法自適應方法 不同于PT方法,算法自適應(algorithm adaptation,AA)方法的核心思想是通過修改現有合適的算法直接處理多標簽分類問題。Clare 等人[14]提出了多標簽決策樹算法。該算法借鑒了決策樹的思想,首先計算每個特征對所有標簽的鑒別能力,即特征對應的信息增益,然后根據信息增益挑選特征并生成分類器。Elisseeff等人[15]提出了排名支持向量機算法。該算法遵循支持向量機的原理,核心思想是利用最大間距的方法。為了使排序損失評價指標最小化,該算法定義了一組線性分類器,同時還針對非線性分類任務引入了核技巧的思想。Zhang 等人[16]根據K近鄰算法(Knearest neighbors,KNN)的思想提出了ML-KNN,其偽代碼如下所示。 該算法基于多標簽訓練實例,首先計算未知標簽的樣本與所有已知標簽的樣本的距離,然后選出K個最近的已知標簽樣本,最后選擇概率最大的標簽作為當前樣本最終的標簽。具體而言,步驟1 和2 用于估計先驗概率P(),步驟3 到13 用于估計后驗概率,步驟14 到18 利用貝葉斯規則,根據估計的概率計算算法的輸出。其中,rt是一個實數值向量,該向量用于計算標簽排名,以便利用多標簽分類的評價指標來分析算法的性能。 總體來說,問題轉換方法的關鍵思想是數據與算法的擬合,通過轉換問題數據的方式,將轉換后的數據應用于現有的算法。而算法自適應方法的關鍵思想則是算法與數據的擬合,將特定的算法進行擴展或者改進,使之能應用于多標簽數據。由于問題轉換方法需要額外進行預處理操作,即將多標簽問題轉換為單標簽問題,在標簽類別過多的情況下,這一過程可能會導致算法性能下降。因此,當數據集中的標簽類別過多時,建議采用算法自適應方法。為了方便地分析傳統的多標簽分類算法的性能和優缺點,表1 從代表算法、應用領域、優缺點等方面對所提出的算法進行了總結。 表1 傳統的多標簽分類算法Table 1 Traditional multi-label classification algorithms 在多標簽分類領域,各種深層神經網絡結構得到了廣泛應用,并且取得了良好的分類效果。其中,用于多標簽分類的神經網絡結構可分為三種類型,分別為卷積神經網絡、循環神經網絡以及Transformer結構。 2.2.1 基于卷積神經網絡的方法 卷積神經網絡(convolutional neural network,CNN)最初應用于計算機視覺領域,隨著研究的深入,該類神經網絡在圖像分類、文本分類等領域取得了較大的進展。Kim等人[17]首次在文本分類任務中使用了CNN結構并提出了Text-CNN。Johnson等人[18]在此基礎上進一步研究了單詞級別的CNN,并提出了一種深層金字塔CNN,用來捕獲訓練數據的全局表示。在多標簽圖像分類領域,Wei 等人[19]提出了一種靈活的深度CNN 架構(hypotheses CNN pooling,HCP)。如圖4所示[19],首先通過假設選擇方法,將數量較少的候選窗口作為假設;然后將選定的假設輸入到共享的CNN中,并將輸出的置信度向量通過融合層與最大池化操作組合在一起,生成最終的多標簽預測。其中,共享的CNN 首先在大規模單標簽圖像數據集上進行預訓練,然后在目標多標簽圖像數據集上進行微調。實驗表明,HCP 相較于其他先進模型具有更加優越的性能,在VOC 2007和VOC 2012多標簽圖像數據集上的平均精確度分別達到了90.9%和90.5%。 圖4 HCP 的模型結構圖Fig.4 Model structure diagram of HCP Yang 等人[20]在前人工作的基礎上提出了一種孿生卷積神經網絡(hybrid-Siamese convolutional neural network,HSCNN),該網絡可以用于處理不平衡數據中的尾標簽問題。在多標簽分類任務中,他們對樣本數量更多的標簽采用相同的CNN結構,而對樣本數量更少的標簽則采用HSCNN 結構。Tan 等人[21]提出了一種動態嵌入投影門控(dynamic embedding projection gate,DEPG)卷積神經網絡,該模型首次在詞嵌入矩陣上應用DEPG。通過使用門控單元來轉換和攜帶單詞信息,可以有效地將單詞嵌入矩陣中每個元素所攜帶的信息與對應位置的上下文信息進行合并。 上述基于CNN 的多標簽分類模型大多都是在現有CNN 結構的基礎上進行不同程度的改進或者與其他先進模型相結合,其本質都并未對CNN 自身的缺陷進行改進。在利用CNN 進行池化操作時,容易丟失關鍵信息。同時,在處理長文本時,CNN 也并不適用于捕捉長距離文本的語義消息。 2.2.2 基于循環神經網絡的方法 與CNN 相比,循環神經網絡(recurrent neural network,RNN)更適用于自然語言處理中序列化數據的輸入。隨著研究的深入,RNN在多標簽分類領域也得到越來越廣泛的應用。然而,由于RNN自身存在梯度消失、梯度爆炸以及長距離依賴等問題,現階段研究大都集中于改進后的LSTM(long short-term memory)、GRU(gated recurrent unit)以及Seq2Seq模型。 Yazici等人[22]提出了一種用于訓練多標簽分類任務的無序LSTM 模型的方法,其模型結構如圖5 所示[22],包括CNN 圖像編碼器、LSTM 文本解碼器和注意力機制。其中,CNN 編碼器用于從圖像中提取緊湊的視覺表示,LSTM 解碼器使用編碼生成的標簽序列對標簽依賴進行建模。注意力模塊關注的則是圖像的不同部分,它將這些不同部分的注意力加權特征與前一個時間步中預測的類的詞嵌入連接起來,作為當前時間步的輸入提供給LSTM。實驗表明,這種圖像編碼器和語言解碼器的標準架構在MS-COCO、NUS-WIDE 多標簽圖像分類數據集上的F1 值分別為77.14%、72.37%。 圖5 基于LSTM 的模型結構圖Fig.5 Model structure diagram based on LSTM 然而,由于LSTM 模型基于單向傳播,Yazici 等人的模型忽略了反向內容之間的語義相關性。Hu 等人[23]利用Word2Vec 和雙向LSTM 對模型進行訓練。該模型充分考慮了正反兩個方向的語義相關性,提高了多標簽文本的分類精度。Liu 等人[24]為了解決包含大量類標簽的多標簽分類問題,提出了一種基于多層注意力和標簽相關性的多標簽文本分類模型LELC(label embedding and label correlation)。該模型首先利用雙向GRU 捕獲文本的內容信息和序列信息,然后利用注意力機制選擇與標簽相關的有效特征,最后通過標簽相關矩陣進行空間降維。在11 個真實數據集上的實驗表明,LELC 能取得最先進的性能。Chen 等人[25]提出了一種具有潛在詞標記的多標簽分類模型(multi-label classification with latent word-wise label,MLC-LWL),并在學術文獻和新聞數據集上取得了71.10%和88.10%的微觀F1 值。該模型首先利用標簽主題模型構造有效的詞標簽信息,然后利用門控網絡將單詞所攜帶的標簽信息和上下文信息結合起來,最后通過標簽到標簽的結構獲取標簽之間的相關性。Xiao等人[26]提出了一種基于歷史注意力機制的Seq2Seq模型,通過考慮歷史信息,有效地探索多標簽文本分類中標簽預測的信息表示。其中,基于歷史的上下文注意力(history-based context attention,HCA)著重考慮上下文歷史權重趨勢,有助于瑣碎標簽的預測;基于歷史的標簽注意力(history-based label attention,HLA)通過探索歷史標簽來緩解錯誤傳播的問題。相較于MLC-LWL,HCA-HLA 的微觀F1 值分別提高了0.10%和0.7%。 2.2.3 基于Transformer的方法 Google 于2017 年提出了Transformer[27]網絡結構。該網絡打破了原有的編碼器、解碼器模式,僅僅采用注意力機制來執行自然語言處理任務。面對更具挑戰的極端多標簽分類(extreme multi-label classification,XMC)[28]任務,Chang等人[29]提出了X-Transformer模型。其中,XMC 是指在一個非常大的標簽空間中,為每一個樣本分配最相關的若干標簽。X-Transformer模型由語義標簽索引組件、深度神經匹配組件和集成排名組件構成,是第一個用于微調Transformer 的可擴展框架,并在4 個基準數據集上取得了最佳分類效果。Jiang 等人[30]發現X-Transformer 模型在訓練標簽排序模型時,靜態采樣負值標簽的方法降低了模型的效率和準確性。因此,他們提出了LightXML 模型。該模型采用端到端訓練和動態負值標簽采樣的方法,使用生成式合作網絡對標簽進行回收和排序,并在5 個XMC 數據集上表現優于最先進的方法。 隨后,基于Transformer 提出的BERT(bidirectional encoder representations from transformers)預訓練模型[31]在自然語言處理領域取得了突破性的進展。這類模型本質上是利用海量語料訓練大量參數,免去了從零開始訓練的過程。在多標簽分類領域,大量研究人員也逐漸引入該類模型。Jin 等人[32]提出了一種基于BERT 和改進TF-IDF 的多標簽文本分類模型,通過計算單個類別標簽的不同權重,更好地反映其重要性。在餐廳顧客評論數據集上進行的多標簽分類實驗表明,該模型與基準BERT 相比,性能略有提高,微觀F1 值達到了73.59%。Kim 等人[33]提出了一種基于KoBERT 的多標簽文本分類模型EnvBERT,通過數據過采樣技術解決了多標簽數據的不平衡問題。實驗表明,該方法對不平衡的、有噪聲的多標簽新聞數據具有更加優越的預測性能,準確度達到了80%。林森等人[34]針對地震災害社交媒體數據的特點,提出了一種BERT 遷移學習模型。他們利用BERT 預訓練模型建立地震災害社交媒體信息多標簽分類模型,并達到了91.6%的準確度,為災后快速輔助響應決策提供科學依據。 目前已有的多標簽文本分類器存在以下問題:一方面,忽略了文本中不同層次的語義特征;另一方面,忽略了語義標簽的意義以及標簽與底層文本之間的關系。為了克服這些問題,Lu 等人[35]設計了一種CNN-BiLSTM-Attention 分類器,如圖6 所示[35]。該分類器結合了BERT 模型,可以更好地利用標簽和基礎文本之間的多級語義特征。首先,使用預先訓練好的BERT 模型生成詞嵌入和標簽嵌入。然后,利用CNN 層提取文本的局部語義特征。BiLSTM 層將該局部語義特征作為初始狀態,通過融合文本的上下文特征,生成表示全局語義信息的混合特征。最后,利用注意力層為每個標簽選擇最相關的特征。在某市電子政務多標簽數據集以及新聞、法律兩個領域公共數據集上的微觀F1 值分別達到了87.52%、77.22%、84.42%。基于Transformer 的方法利用了預訓練模型的優點,未來可以對各類預訓練模型進行改進,使其更適用于下游任務。 圖6 CNN-BiLSTM-Attention 的模型結構圖Fig.6 Model structure diagram of CNN-BiLSTM-Attention 總體來說,深度學習模型無需人工構造特征,就能從原始數據中學習有利的特征,從而獲得更加有效的特征表示。這類模型能很好地解決多標簽分類任務中的數據表達能力不足、標簽相關性考慮不充分以及模型復雜程度高等問題。為了方便地分析基于深度學習的多標簽分類算法的性能和優缺點,表2從代表算法、應用領域、優缺點等方面對所提出的算法進行了總結。 表3 展示了來自不同領域的多標簽分類數據集。其中,N表示數據集中實例的數量,L表示數據集中預定義的標簽的數量,LC表示標簽基數,其定義如式(1)所示,表示與每個實例相關聯的標簽的平均數量。所有數據集和它們的更多相關信息可以從https://mulan.sourceforge.net/datasets-mlc.html 或其原始文獻中獲得。 表3 多標簽分類數據集Table 3 Multi-label classification datasets yeast 數據集包含2 417 個酵母基因的微陣列表達和系統發育譜,每個基因都與一組功能類相關,共注釋了14 個功能類別子集,如代謝、能量等。 mediamill 數據集是一個類別不平衡的大規模數據集,共包含43 907 個視頻幀,通過手動注釋的方式產生了101個語言概念的詞典,如軍事、沙漠、籃球等。 scene 數據集用于多標簽場景分類,包含2 407 張圖像,每張場景圖像可能包括海灘、落日、落葉、山脈、田野、城市這6 類概念中的一種或多種。 NUS-WIDE 數據集由新加坡國立大學媒體檢索實驗室創建,共包含269 648 張圖片,邀請具有不同背景的學生手動標注了81個屬于不同類別的概念,如游泳、跑步等活動類概念和沙灘、馬路等場景類概念。 medical 數據集來源于美國辛辛那提兒童醫院醫學中心放射科,經過消除歧義、匿名化等預處理步驟,最終得到978 份臨床文本報告,每份病歷標記有45 種疾病代碼中的一種或多種。 tmc2007 數據集包含28 596 份自由文本形式的航空安全報告,注釋了飛行期間出現的22 種問題類型中的一種或多種。 bibtex 數據集包含7 395 個由論文標題、作者等信息組成的bibtex 條目,注釋了159 個由用戶分配的標簽集,如統計、數據挖掘等。 CAL500 數據集包含500 首西方流行音樂,每首歌曲都有至少3 位聽眾的注釋,考慮了135 個屬于不同類別的音樂相關概念,如鋼琴、吉他等樂器類概念和古典、流行等流派類概念,最終經過語義特征處理得到174 個概念標簽。 在多標簽分類任務中,評價指標可以概括為兩種。如圖7 所示,一種是基于實例的評價指標,另一種則是基于標簽的評價指標。基于實例的評價指標是針對每個實例去預測標簽,而基于標簽的評價指標則是對每個標簽預測實例。 圖7 多標簽分類評價指標的總體框架Fig.7 Overall framework of multi-label classification evaluation metrics 基于實例的評價指標用于評估模型在各測試實例上的性能,最終返回其在整個測試集上的平均值。 根據多標簽分類器h(?),可以定義以下6 個基于實例的分類指標。 (1)子集準確度 子集準確度用于評估正確分類實例的比例。其中對于???,如果“?”成立則返回1,否則返回0。它對應于傳統分類任務中的準確度,只有當實例預測的標簽完全正確時才被認定為正確分類,因此過于嚴格,將導致較低的度量值。 (2)漢明損失 漢明損失用于評估錯誤分類標簽的實例的比例。其中Δ 表示兩個集合之間的異或關系。當數據集中的每個實例僅與標簽集中的單個標簽相關聯時,即在單標簽情況下,漢明損失將退化為傳統誤分類率的2/q。 (3)準確度 準確度用于評估正確分類標簽的實例的比例。 (4)精確度 精確度用于評估樣本中被正確分類標簽的實例的比例。 (5)召回率 召回率用于評估所有實例成功預測相關標簽的平均比例。 (6)F值 F值通常被認為是比精確度和召回率更好的性能評價指標,它通過精確度和召回率加權得到。其中β表示平衡因子,通常取值為1。 根據實值函數f(?,?),還可以定義以下5 個基于實例的排序指標。 (1)1-錯誤率 1-錯誤率用于評估排名最高的標簽不在相關標簽集合中的實例的比例。 (2)覆蓋率 覆蓋率根據排序后的標簽列表,計算覆蓋實例所有相關標簽的步數。 (3)排序損失 排序損失用于評估錯誤排序標簽對的比例,即不相關標簽的排名高于相關標簽。 (4)平均精確度 平均精確度用于評估排名高于某一特定標簽的相關標簽的平均得分。 (5)前k個的精確度 前k個的精確度用于評估前k個評分標簽中正確分類標簽的百分比。 在上述基于實例的評價指標中,對于1-錯誤率、覆蓋率和排序損失,值越低,模型的性能越好;對于其他評價指標,值越高,模型的性能越好。 基于標簽的評價指標用于評估模型在每個類別標簽上的性能。對于第j類標簽,根據多標簽分類器h(?),可以定義以下兩個基于標簽的分類指標。 (1)宏觀平均值 (2)微觀平均值 宏觀平均值是在單個類別標簽上計算得到的,而微觀平均值是在所有類別標簽上計算得到的。其中B∈{Arruracy,Precision,Recall,Fβ},TP、FP、TN、FN分別表示真陽性、假陽性、真陰性、假陰性的數量。 根據實值函數f(?,?),還可以定義以下兩個基于標簽的排序指標。 (1)宏觀AUC (2)微觀AUC 曲線下面積(area under curve,AUC)代表特征曲線下的面積,它是一種統計度量,表示真陽性占實際陽性的比例以及假陽性占實際陰性的比例。 對于上述所有基于標簽的評價指標而言,值越高,模型的性能越好。 在評價算法性能時,通常不僅僅考慮某一特定的評價指標,而是結合多個評價指標一起使用。為了方便地了解評價指標在多標簽分類中的作用,表4對上述多標簽分類算法的評價指標進行了總結。其中HL 代表漢明損失,Acc 代表準確度,Pre 代表精確度,Re 代表召回率,OE 代表1-錯誤率,Co 代表覆蓋率,RL 代表排序損失,AP 代表平均精確度,P@k代表前k個的精確度。 表4 多標簽分類算法的評價指標Table 4 Evaluation metrics of multi-label classification algorithms 由于子集精確度在評估時過于嚴格,大多數算法并沒有考慮該評價指標。若要研究分類器的性能,則可以采用一些分類指標對算法進行評估;若要考慮返回的實值函數,則可以采用一些排序指標對算法進行評估。在XMC 任務中,標簽數量非常多,通常意義上的精確度等指標不太適用,因此選擇P@k作為評價指標。AUC 在單標簽領域較為常用,在多標簽分類領域,也可以對結果計算宏觀AUC 或微觀AUC,其更適用于一些標簽不平衡數據集。 現有的一些多標簽分類方法已經能較好地運用在實際使用中,但目前仍有一些問題需要解決,例如多模態數據多標簽分類、基于提示學習的多標簽分類和不平衡數據多標簽分類。下面將對這三類問題進行分析,并將其作為未來的研究方向。 (1)多模態數據多標簽分類 隨著時代的發展,數據類型不僅僅局限于文本一種,人們可以借助各種設備采集音頻、視頻、圖片等多模態數據。于玉海等人[43]提出了生物醫學圖像多標簽分類方法,融合了圖像內容和相關說明文本這兩種模態的數據,可以更加有效地識別生物醫學模式標簽。井佩光等人[44]提出了一種基于多模態子空間編碼的短視頻多標簽分類模型,充分將短視頻的多模態特性與多標簽相關聯。Tang 等人[45]提出了一種用于多標簽皮膚病分類的兩階段多模態學習算法FusionM4Net-FS,在標簽不平衡的醫學數據集上取得了強大的分類性能。Zhang 等人[46]提出了一種用于多標簽情感識別的通用多模態學習方法,通過對抗性多模態細化模塊,充分挖掘不同模態之間的共性。由于各模態數據之間存在差異性,如何更好地融合多個模態的特征是一大難點。針對這一問題,可以根據模態特征的粗細粒度采用分層交叉模態融合的方法。此外,在多標簽分類中合理地融入多模態數據,將多模態表示與標簽語義對齊,也具有重要的研究價值。 (2)基于提示學習的多標簽分類 近年來,人們對于提示學習的研究越來越深入,它作為自然語言處理領域的第四范式,在實體關系抽取、問答、推薦等任務中取得了不錯的效果[47]。在多標簽分類任務中,Chai等人[48]提出了一種基于提示的多標簽情感預測模型,該模型利用標簽提示和對比學習來捕獲標簽信息,能夠更好地預測情感標簽。Song 等人[49]提出了一種標簽提示多標簽文本分類模型,設計了一套多標簽文本分類模板,將標簽集成到預訓練模型的輸入中,有效地提高了模型的性能。Wang等人[50]提出了一種自動多標簽提示AMuLaP,為少樣本文本分類設計了一種自動選擇標簽映射的方法。上述方法通過引入標簽提示,將標簽整合到預訓練語言模型的輸入中,可以有效地捕獲標簽和文本間的語義信息。此外,鑒于提示學習可以有效地應用在小樣本甚至零樣本場景下,基于提示學習的低資源多標簽分類也是未來的一個研究方向。 (3)不平衡數據多標簽分類 不平衡是大多數多標簽數據集的固有特征,其特點是樣本及其對應的標簽在數據空間上的分布是不均勻的。現有的分類算法更適用于對平衡數據進行分類,在處理不平衡數據時,分類性能會急劇下降。Tarekegn 等人[51]對處理多標簽數據中的不平衡問題的方法進行了綜述。在多標簽分類任務中,集成方法通常被用來解決不平衡和標簽相關性問題。Zhu 等人[52]提出了一種新的多標簽分類與動態集成學習方法,通過選擇并組合最有效的基分類器集合來預測每個未知的實例。鑒于不同的基分類器組合對于特定的問題具有不同的性能,如何在多標簽分類中選擇基分類器也有待進一步研究。此外,還可以采用重新采樣的方法對不平衡數據進行擴充,以減輕類不平衡造成的影響。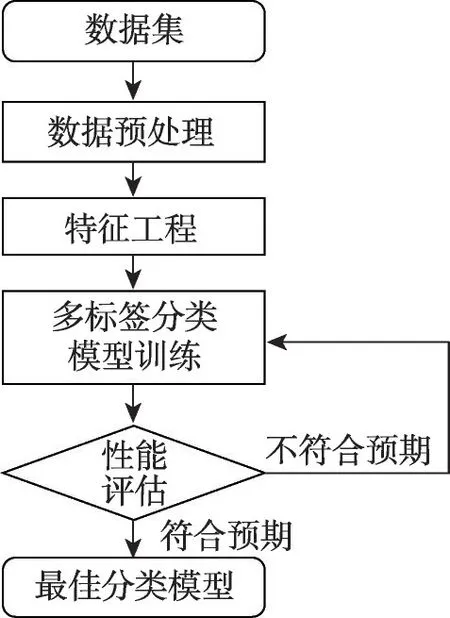
2 多標簽分類方法
2.1 傳統的多標簽分類

2.2 基于深度學習的多標簽分類
3 數據集
4 評價指標
4.1 基于實例的評價指標
4.2 基于標簽的評價指標
4.3 小結
5 未來工作展望
猜你喜歡
車迷(2018年11期)2018-08-30 03:20:32
海峽姐妹(2018年3期)2018-05-09 08:21:02
電子測試(2018年1期)2018-04-18 11:52:35
光學精密工程(2016年4期)2016-11-07 09:05:00
光學精密工程(2016年3期)2016-11-07 09:03:33
公民與法治(2016年10期)2016-05-17 04:12:58
計算機工程(2015年8期)2015-07-03 12:20:27
高中生學習·高三版(2014年3期)2014-04-29 06:11:18
高中生學習·高三版(2014年3期)2014-04-29 06:10:49
電測與儀表(2014年15期)2014-04-04 12:05:20
