基于半直接法的高度激光里程計
2023-11-13 16:10:06高珂肖輝勇姜宇凡李瓊峰楊濟源王斐
應用科技 2023年5期
關鍵詞:特征
高珂,肖輝勇,姜宇凡,李瓊峰,楊濟源,王斐
1. 東北大學 信息科學與工程學院,遼寧 沈陽 110819
2. 湖南柿竹園有色金屬有限責任公司,湖南 郴州 423037
3. 西北工業大學 瑪麗女王工程學院,陜西 西安 710129
4. 東北大學 機器人工程學院,遼寧 沈陽 110819
隨著國家對礦山安全要求指標不斷提高和對井下作業人員安全的重視,目前的井下作業系統已經不足以滿足信息化的需求。物聯網、無人駕駛以及5G 等新一代技術日趨成熟,基于同步定位與建圖(simultaneous localization and mapping,SLAM)技術的井下作業自動導向車(automated guided vehicle,AGV)的研究逐漸成為熱點。對于井下作業AGV 來說,在降低計算成本的同時,保證AGV 運動的穩定性也非常重要。在SLAM 系統中,最重要的部分之一是前端部分,它通常執行逐幀姿態估計,從而形成里程計子系統[1]。目前主流的里程計分為視覺里程計(visual odometry,VO)和激光雷達里程計(liDAR odometry,LO)2類[2]。視覺里程計在紋理不豐富、光照變化明顯的環境下魯棒性較差;相比之下,激光里程計通過匹配激光點云數據完成幀間的匹配從而進行運動估計,在光照條件不足的情況下魯棒性較強,是更加穩定的選擇。但是激光雷達采集的數據中過多的點云數量造成了激光里程計計算成本過高的問題[3]。于是,研究人員開始嘗試將激光與視覺傳感器的優勢融合在一起,形成激光雷達視覺里程計,這樣的結合可能在各種場景環境中尤其是在特殊結構或者光照不足的環境中會具有更強的魯棒性[4]。但是使激光里程計融合1 臺或多臺攝像機需要更復雜的設置,他們的融合并不容易;并且,同時使用2 種以上的傳感器很難使系統速度更快。
目前現有的視覺SLAM 與激光SLAM 方法根據其地圖的表示方式可分為2D、3D 和2.5D 這3 種[5]。其中由于2D 能體現的信息較少,因此不能應用于許多開放的室外環境;而3D 地圖的信息量雖然較大,但一般效率較低[6];采用2.5D 的表示方法,可以縮小點云的維數和計算代價,從而實現精度與計算代價之間的平衡[7]。
在基于直接法的SLAM 算法中,瑞士蘇黎世大學的研究人員[8]提出了基于半直接法的半直接視頻里程計(semi-direct monocular visual odometry,SVO)。SVO 算法通過對關鍵幀提取(features from accelerated segment test,FAST)視覺點特征來構建新地圖點,并采用深度濾波器進行地圖點的深度估計。因為算法作用于稀疏的像素點,因此能夠在機載嵌入式計算機上以55 f/s 的速度運行。同濟大學的研究人員[1]使用基于2.5D 網格圖的直接LO 方法用于室外環境中的自動駕駛汽車。該方法借鑒了SVO 結構,將視覺中的直接方法與ORB (oriented fast and rotated brief)方法[9]中的FAST 關鍵點相結合,專注于解決運算性能問題。該方案是基于視覺方法的高效激光測距里程計,不僅充分利用高度圖信息,也在一定程度上降低了直接法的不確定性;并且提出的方法使用激光雷達代替相機,解決了傳統VO 受光照影響較大的問題,可以在大多數系統上實現高效定位。到目前為止,研究人員已經在這一領域進行了大量的研究工作,但是想要在復雜的環境中保持系統的輕量化與高效率仍然面臨較大的挑戰[10]。
受到以上研究啟發,本文專注于使用純三維激光點云數據完成快速精確的定位,而無需任何額外的視覺傳感器或強度信息。同時,為了節省計算資源,本文提出了基于半直接法的高度激光里程計(height laser odometer based on semi-direct method,SLO)方法,將三維激光點云投影至指定平面上,然后存儲每個點云在世界坐標系中的高度信息,將其點云高度平均值作為圖像中該像素點的灰度值,生成2.5D 深度圖像,從而避免了對三維點云的直接計算。因為視覺方法中的灰度不變假設是一個很強的假設,在實際應用中很難成立。對此,本文算法將灰度不變假設改進為高度不變假設,在激光里程計中使用視覺里程計中的方法,基于高度不變假設[11]進行位姿估計,這在現實中比灰度不變假設的魯棒性更強。
本文的主要貢獻是將激光雷達與基于2.5D柵格地圖的半直接單目視覺方法相結合,將其應用于復雜的室外環境,大大降低了復雜環境數據計算成本,保持了系統的輕量化和高效率。
1 SLO 系統概述
1.1 預處理
首先給定圖像序列和激光雷達序列,其次假設已經完成了激光數據球坐標向笛卡爾坐標的變換。本文將激光的局部坐標設置為本體坐標,將世界坐標設置為本體坐標的起點。
1.2 系統總體框架
系統的整體框架如圖1 所示,該框架包含位姿估計與局部地圖構建2 個運行線程。在運動估計過程中,SVO 將運動估計與建圖分成了2 個并行計算的線程。它基于構建的稀疏地圖點,首先通過最小化圖像之間的光度誤差,初步計算了每幀圖像的位姿;然后通過優化視覺點特征位置并最小化重投影誤差,進一步優化了位姿估計。由于算法作用于稀疏的圖像像素點,因此它能夠在CPU 上以很高的幀率運行。本文提出的SLO 算法參照了SVO 的架構,綜合了直接法和特征點法的優點,設計了3 步策略。此方案能夠很好地處理稀疏的3D 點云數據,從而比一般的激光里程計更加輕量,比基于直接法的視覺里程計更加魯棒。
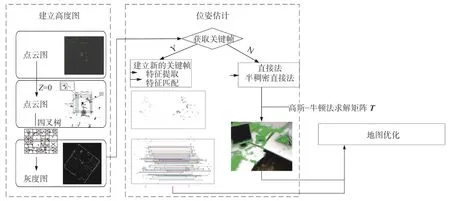
圖1 SLO 算法整體框架
1.3 創建高度圖
三維激光里程計獲取的大量點云數據可以顯示環境物體的位置和高度,但點云數據是在重建過程中采集的,這消耗了大量的處理器硬件資源。因此,本文主要關注點云表征數據,以減少CPU 的計算壓力。為了識別地面,提出了2 個假設:一是假設傳感器大致安裝在水平移動底座上;二是假設地面的曲率很低。
采用灰度值保存高度信息的方法,在不犧牲物體高度信息的情況下,將3D 點云轉換為2D 圖像,保留了2D 網格圖易于存儲和構建的優點,同時也保留了高度信息,生成的高度圖如圖2 所示。

圖2 激光點云數據轉化
1.4 跟蹤線程初始化
算法首先初始化變換矩陣T為單位矩陣,檢測第1 張灰度圖像的特征點,若灰度圖像中檢測的特征點數量超過設定的閾值,就把這張圖像作為第1 個關鍵幀。然后從第1 幀圖像開始,使用LK (lucas-kanade)光流法持續跟蹤特征點,并計算從第1 幀圖像開始的連續圖像與第1 幀圖像的視差,如果視差中位數大于閾值,就認為初始化成功,并將與此對應的幀設定為第2 個關鍵幀,將提取的特征點作為地圖點加入局部地圖,進入正常跟蹤模式。
1.5 位姿估計
在運動估計線程中,SVO 算法基于構建的稀疏地圖點,通過最小化圖像之間的光度誤差,初步計算每幀圖像的位姿;然后通過最小化重投影誤差優化了視覺點特征的位置,進一步優化了位姿估計[12]。本文SLO 算法位姿估計跟蹤線程流程如圖3 所示。
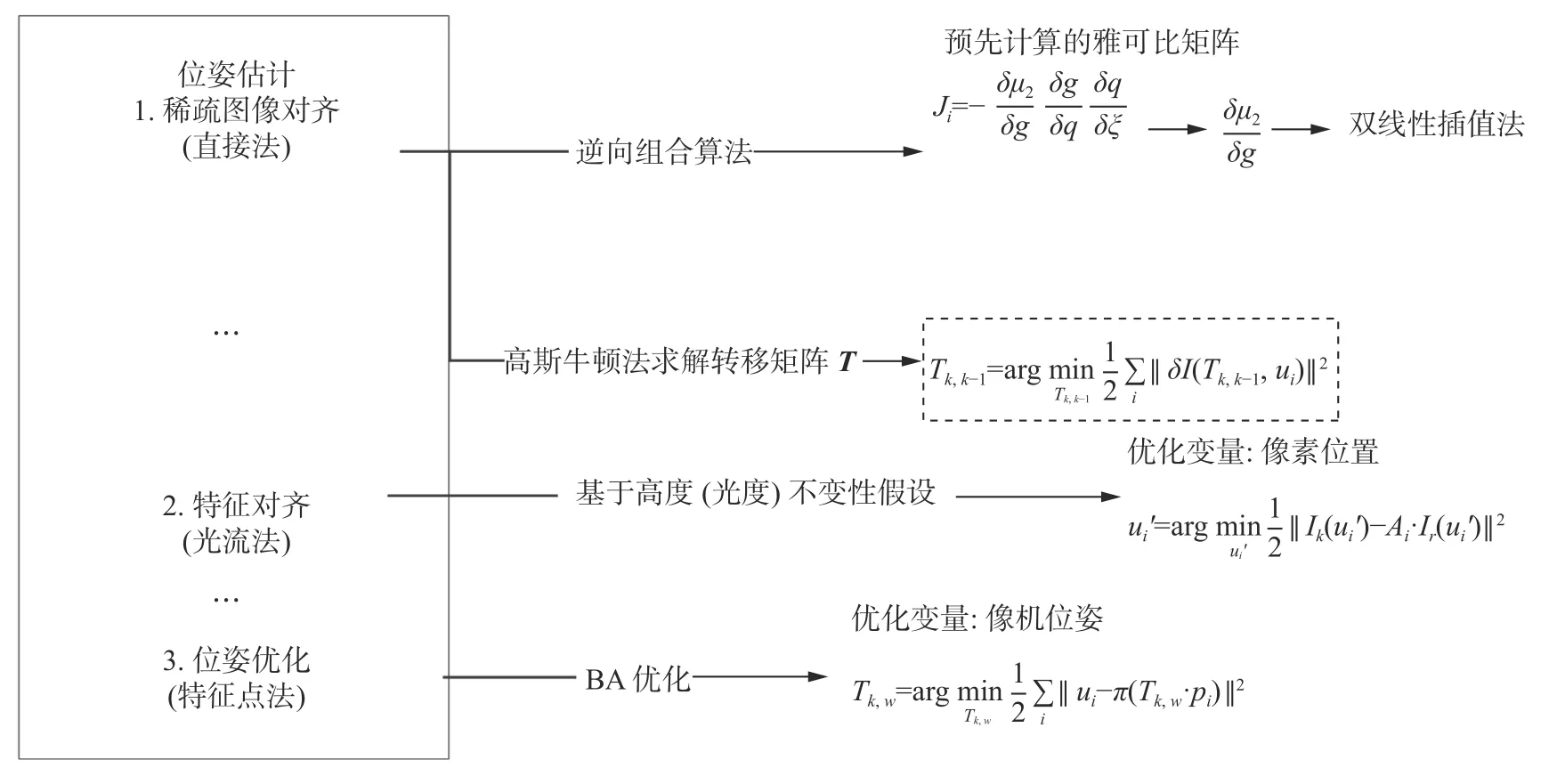
圖3 跟蹤線程流程
1)基于角點的圖像對齊。使用稀疏直接法粗略計算當前幀的位置和姿態,并建立損失函數(最小化光度誤差),利用高斯–牛頓(Gauss-Newton,GN)優化算法得到幀間的2 個位姿變換。目標函數為
式中
其中:π-1(u,du)為根據高度圖像素位置u逆投影到三維空間后得到的三維點坐標p,T·π-1(u,du)為將三維坐標點旋轉平移到當前幀坐標系下,π(T·π-1(u,du))為將當前幀坐標系下的三維坐標點投影到當前幀高度圖像坐標,I(u)為特征點周圍4×4的像素塊的高度值。由于這一步是一個粗略的計算,為了加快計算速度,因此沒有進行仿射變換。
利用GN 法求解2 個高度映射的轉移矩陣T,即2 個柵格地圖之間的最小高度差誤差[1]。根據直接法和鏈式法則,雅克比矩陣Ji可分為3 部分。
式中:
像素梯度計算使用雙線性插值方法計算,即
然后,用高斯牛頓法求出擾動
式中。H=JTJ
最后,判斷此幀是否滿足關鍵幀要求,若滿足則插入局部地圖,并在這個新的關鍵幀上檢測新的特征點作為地圖點。
2)基于點的特征對齊。關鍵幀中提取的特征點在被賦予深度后得到的三維點被稱為地圖點,由于本文使用的灰度圖為激光點云投影生成的圖片,激光關鍵幀中的關鍵點信息伴隨著深度信息,他們的灰度值就是深度,即整個圖片相當于“上帝視角”的圖片,故本文算法去除了SVO 中的深度估計步驟,地圖點經過篩選后可直接放入到局部地圖中[13]。
完成角點的圖像對齊后,算法獲得了當前幀雷達的位姿,因此可以通過重投影將地圖點投影到當前幀中,而正是由于這種幀與幀之間的位姿估計會有累計誤差,所以投影后的地圖點在新的圖像幀中的投影位置也會隨之產生誤差。因此算法可以根據高度不變假設構造一個殘差,對于每個特征點單獨考慮,對特征預測位置進行優化,即
式中:Ik(ui′)為當前第K幀圖像中第i個特征點的亮度值(即高度值);后一部分為Ir(ui)而不是Ik-1(ui),因為它是根據局部地圖投影的地圖點追溯到這個地圖點所在的關鍵幀中的像素值,而不是相鄰幀。
相比于基于角點的圖像對齊粗測,基于點的特征對齊選取了8×8的圖像塊范圍來比較均值差,可以得到亞像素級別的精度。
3)位姿迭代優化。利用優化后的特征塊預測位置,使用直接法再次對位姿構建優化函數進行估計:
最后建立局部地圖,判斷這個幀是否是關鍵幀,如果是關鍵幀,提取新的特征點。
2 SLO 算法驗證實驗
采用KITTI 數據集[14]與AGV 移動平臺來驗證所提出的算法。在本實驗中,使用HDL-16 激光雷達在東北大學渾南校區收集數據來進行實驗測試。
將圖像分成固定大小的單元(像素值大小為800×800)。算法中的參數設置為:處理點云數據截取的窗口的寬度Iwidth=400、高度Iheight=400,灰度圖的每個柵格的大小fx=0.1、fy=0.1,像素值倍增系數cx=200、cy=200。
正態分布變換與迭代最近點方法是傳統的處理三維激光點云的算法,因此本文首先對比了他們的性能。本部分實驗全部為完成畸變補償的情況下進行,在實驗中分別比對了PCL (point cloud library)中集成的迭代最近點(iterative closest point,ICP)算法、正態分布變換 (normal distributions transform, NDT)算法以及改進的基于高斯牛頓算法的ICP 算法。實驗記錄了每50 和100 m 的階段誤差以及全程的累計誤差,階段誤差實驗結果對比如圖4 所示。數據如表1 和表2 所示,由數據可以看出在3 種算法的每50 m 均方根階段誤差(root mean squared error, RMSE)和每100 m 的均方根階段誤差的對比實驗中,NDT 算法的效果最好,基于高斯牛頓的ICP 算法次之。
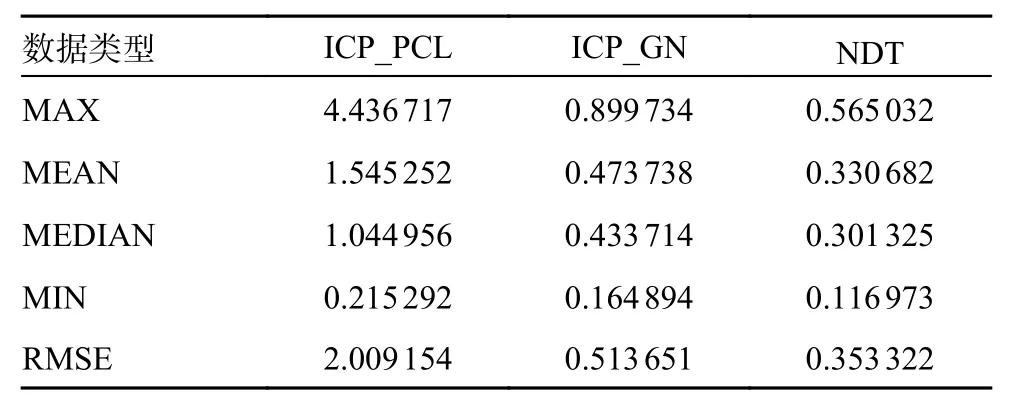
表1 ICP 和NDT 的分段距離誤差/50 m
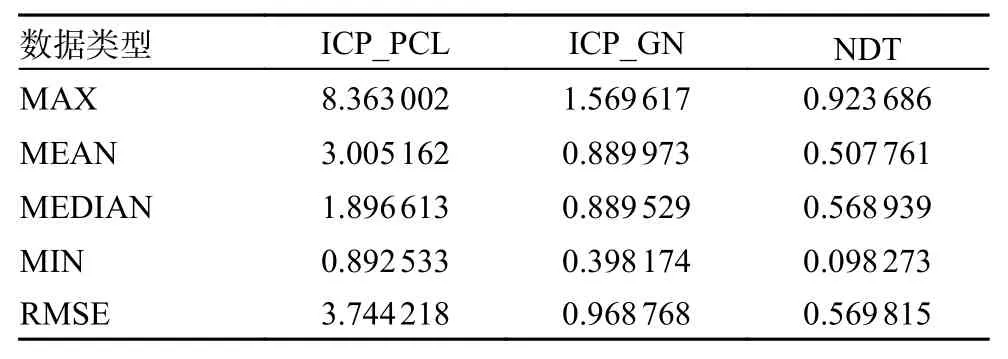
表2 ICP 和NDT 的分段距離誤差/100 m
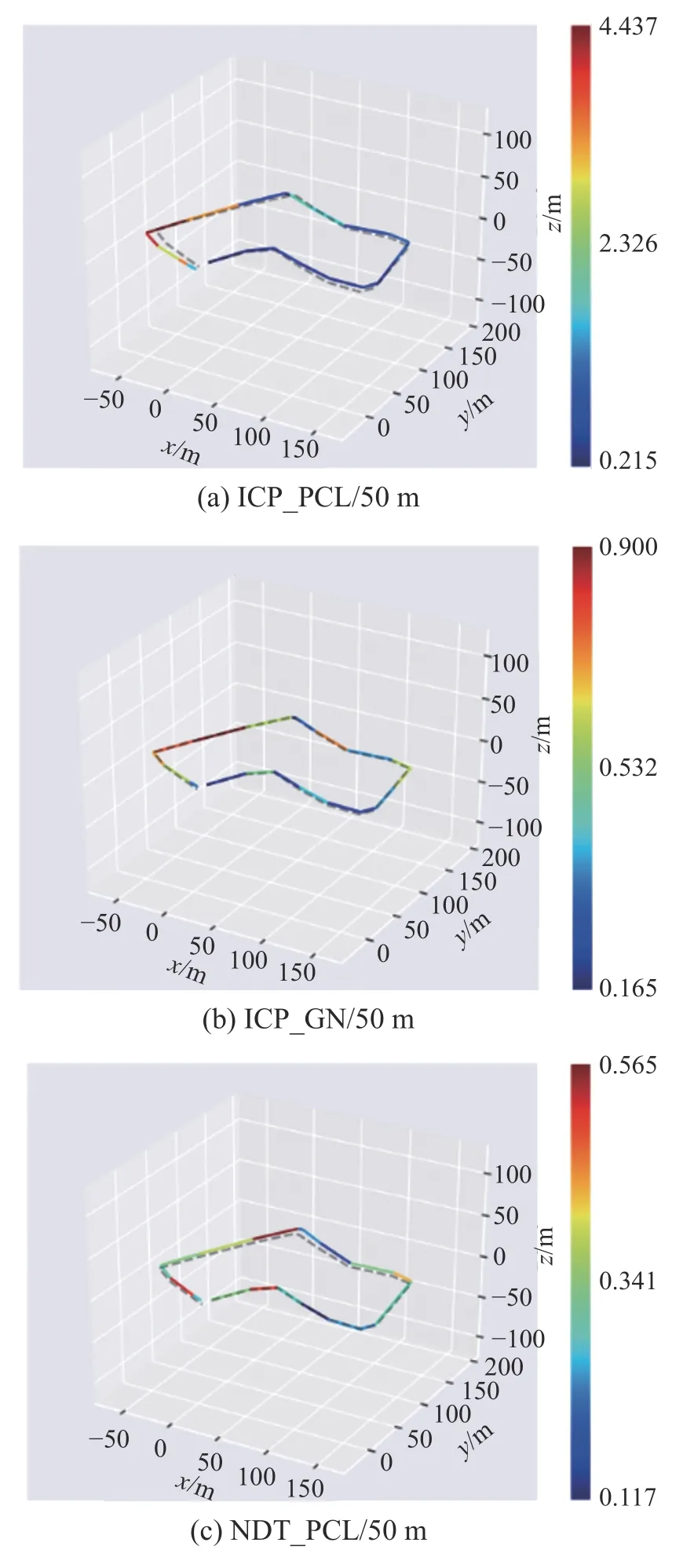
圖4 3 個匹配算法的位姿估計結果與真值的對比
累計誤差的實驗結果圖如圖5 所示,在全程的累計誤差中,基于高斯牛頓的改進ICP 算法顯示出了更好的優勢,數據如表3 所示。
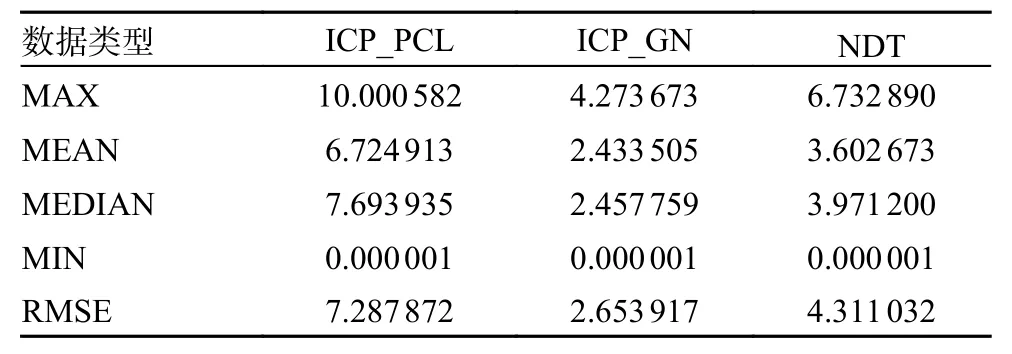
表3 ICP 和NDT 的全程累計誤差
本文提出的SLO 算法在預處理部分參考了DLO[1]中的方法,算法使用KITTI 數據集中序列07 的軌跡中的某幀點云來測試提出的投影方法,算法生成灰度圖后使用LK 光流跟蹤算法[15]跟蹤的結果如圖6 所示。

圖6 某幀灰度圖LK 光流法的效果
算法針對相鄰兩幀點云進行了ORB 特征點[16]的提取與匹配,特征點的匹配結果如圖7 所示,可以看出匹配結果絕大多數是正確的。

圖7 某幀灰度圖的ORB 特征點匹配結果
本文在真實環境中分別進行了灰度圖的生成以及匹配實驗,實驗選用的平臺為AGV 移動平臺,該平臺配置16 線激光雷達,雷達測量距離為100 m 左右,垂直測量角度30°(±15°),掃描過程中從下往上計數,-15°記為初始線(第0 線),一共16 線。使用鐳神16 線激光雷達進行實驗的結果如圖8 和圖9 所示。
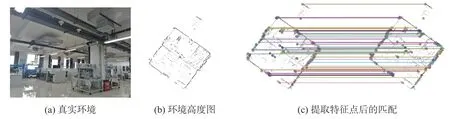
圖8 東北大學324 室實驗室場景圖匹配實驗
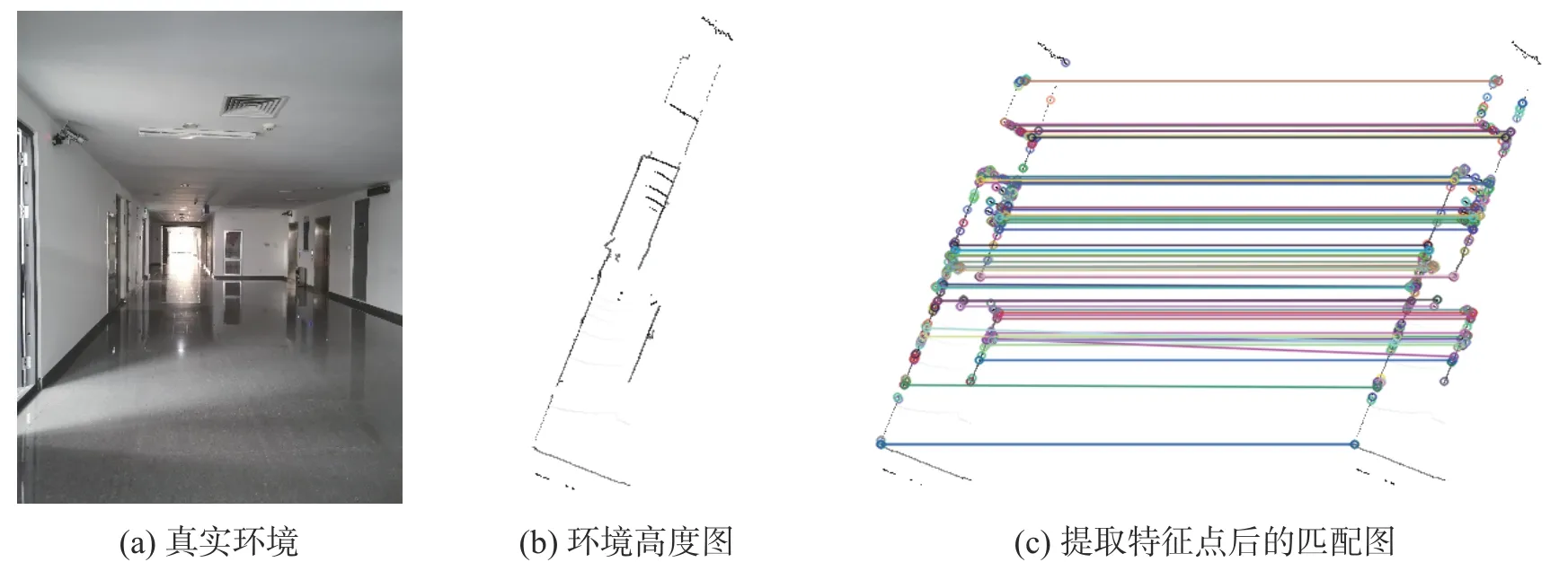
圖9 東北大學教學樓3 樓走廊場景圖匹配實驗
SLO 算法將點云處理成高度圖階段的精簡效果如表4 所示。由表4 中數據可以看出,本文提出的投影方法有效地縮少了點云的原始數據;并且在對高度圖進行特征點提取后,算法可以在保證場景環境特征的基礎上完成對數據大數量級的精簡。
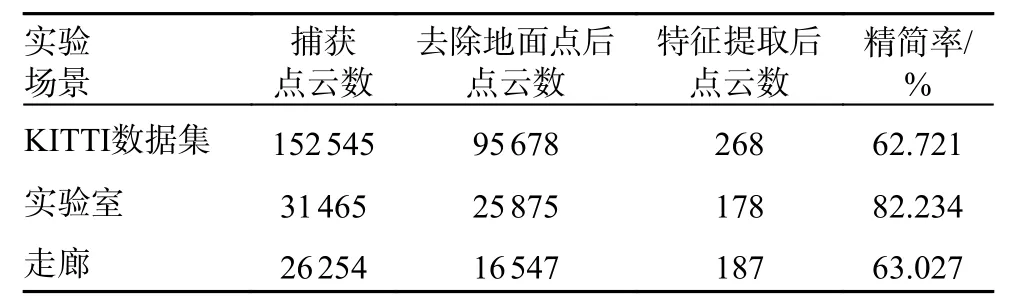
表4 點云精簡效果
3 結束語
由于井下作業AGV 平臺的應用場景可以是室內也可以是室外,因此本文選擇了一種不受環境因素影響的激光里程計來估計平臺的姿態。考慮到激光數據處理需要大量的計算量,本文選擇將點云數據轉換為高信息特征點,它將三維點云轉換為灰度,可大大節省數據存儲和計算,并且通過應用半直接法,提高了精度,使整個過程輕量化。此外,當圖像特征匹配時,使用迭代最近點法執行姿勢估計,這使得最小二乘問題實際上具有解析解,并且不需要迭代優化。
本文提出的SLO 方法合理地結合了視覺里程計和激光里程計的優點。在未來的研究中,基于高度圖提取點和線特征會更容易,基于投影構建拓撲圖也是一個值得嘗試的思路。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
河南科技(2014年23期)2014-02-27 14:19:15
