基于深度神經網絡的SSR 分子標記對茶葉產地的溯源研究
2023-11-13 07:16:12張莉莉陳富榮林麗霞陳意君孫春
廣東農業科學 2023年9期
龔 浩,張莉莉,陳富榮,林麗霞,陳意君,張 樂,孫春 蓮,孫 鍵
(1.惠州學院生命科學學院,廣東 惠州 516007;2.惠州學院經濟管理學院,廣東 惠州 516007)
【研究意義】茶樹〔Camelliasinensis(L.)O.Kuntze〕屬山茶科山茶屬多年生常綠木本植物,原產于熱帶及亞熱帶,是一種喜暖喜濕的葉用植物,其嫩葉經過加工后即為茶葉。茶葉具有防輻射、提神醒腦、利尿、助消化、減肥和預防疾病的作用,因此茶葉的飲用及流傳從古至今都極受重視,是中華民族的舉國之飲、世界三大飲品之首[1]。但是茶樹異花傳粉和長期自交不育的特性,使茶樹高度雜合、親緣關系復雜,茶葉品種難以輕易分辨、分類標準難以統一、鑒別結果有誤差等,這就需要對茶葉不同品種進行區分和產地溯源。SSR 廣泛應用于植物基因定位和QTL 分析、DNA 指紋和品種鑒定[2]、種質資源保存和利用、系譜分析以及標記輔助育種,通常呈共顯性遺傳,其多態位點豐富,實驗操作簡單易行[3]。基于深度神經網絡的簡單重復序列標記對茶葉產地的溯源研究不僅有利于茶葉的分類和產地溯源[4],還能為其他植物分類提供參考。
【前人研究進展】目前已發表相關論文的茶樹測序群體一般為100~200 個樣本,過于零散且群體覆蓋性和代表性較弱,無法用于深度的群體遺傳分析[5]。目前,國內對茶葉品種、產地、產季、年份和等級等真實屬性的鑒別還主要停留在傳統的理化分析與感官評定相結合的水平上,例如GB/T 19598-2006《地理標志產品 安溪鐵觀音》中評價標準是以感官為主,輔以部分理化檢測。一方面,具有感官評定能力的專家非常少,特別是面對我國品種繁多的茶葉,具有特定品種茶葉感官評定能力的專家更為稀缺;另一方面,人的感官靈敏度容易受到外界因素的干擾而改變,采用感官評價方法受人為主觀影響很大,可操作性較差,且目前還沒有明確且易于實現的評定指標或參數,易造成判定結果的偏差[6]。基于此產生電子鼻來分類茶葉,利用氣敏傳感器陣列對揮發性氣味物質響應,使氣味成為量化指標的新技術手段,具有檢測時間短、樣品預處理簡單、檢測結果可靠等優點[7],可以高效、快速、無損檢測不同種類的食品,可應用于茶葉貯藏時間[8]、加工方式、品質[9]和等級[10]等檢測。但這種方法會因為檢驗材料部位不同而出現較大的結果誤差。
【本研究切入點】近年來,分子生物學技術和生物信息學的發展有力地推動了DNA 分子標記的研究。與形態學標記、細胞標記、生化標記等相比,DNA 分子標記技術不易受外界環境及個體本身的影響,具有結果準確、信息量大、檢測簡單、重復性及穩定性較好等優點[11]。DNA 分子標記技術在植物分類學[12]、遺傳多樣性分析[13]、遺傳圖譜構建[14]和輔助育種[15]等方面的研究廣為應用,但在茶樹種質資源方面的研究應用較少,主要集中在遺傳多樣性及特異標記方面。【擬解決的關鍵問題】本研究旨在解決茶葉主成分分析、茶葉產地溯源及品種鑒定、DNN 模型構建等問題。
1 材料與方法
1.1 試驗材料
本研究根據Accession No.PRJNA595795 和PRJNA562973,從NCBI database 中下載323 份茶葉的轉錄組數據,其中來自福建、云南、浙江、湖南省的茶葉分別有130、96、54、33 份,其余10 份屬于外類群樣本即研究類群之外親緣關系最近的物種,這10 個外類群為全國收集的茶梅CamelliasasanquaThunb(表1)。
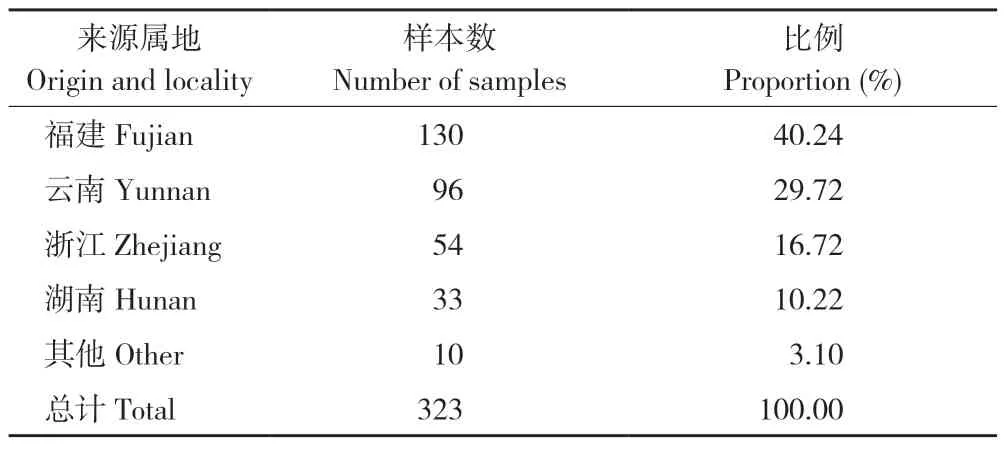
表1 茶葉樣本來源屬地統計Table 1 Statistics on the origin and locality of tea samples
1.2 試驗方法
1.2.1 鑒定SSR 標記位點 本研究先從323 份樣本中獲得樣本數據,使用PSR 軟件(Polymorphic SSR retrieval,PMID:26428628),鑒定茶葉參考基因組(Tea treeCamelliasinensis,舒茶早)中所有可能的SSR 標記位點。首先利用PSR 軟件,設置參數支持的reads 總數大于5,同時支持reads 的比例大于10%,其他參數均為默認參數;再過濾單個位點缺失率較大的位點;最后進行線性回歸分析,并結合不同SSR 位點的相關性,保留最終的SSR 位點[16]。
1.2.2 主成分分析 本研究將323 個茶葉樣本進行樣本間SSR 序列的相互比對,計算每個樣本與其他樣本的差異度,再基于樣本間的差異度計算323 個樣本的基因差異矩陣[17]。利用PCA 對323 個樣本基因差異矩陣進行分析,然后使用R語言中的read.table 函數讀入數據、ovun.sample 函數清理處理數據,最后利用內置函數princomp 進行PCA。
1.2.3 構建整體樣本的進化樹 先用perl 的自編腳本獲得所有個體的明氏距離矩陣,然后用PHYLIP 的neighbour 模塊構建原始進化樹,再用dendroscope 對進化樹進行展示和修飾。
1.2.4 建立及優化模型 本研究使用Matlab 軟件的神經網絡工具,建立線性回歸模型、隨機森林模型和DNN 模型。在建立線性回歸模型的過程中,根據樣本數據集,分別生成x 矩陣和y 矩陣,利用線性回歸代碼建模,并使用其模型進行預測。在建立隨機森林模型的過程中,先將整體樣本讀到內存中,按照8∶2 的比例分為80%的訓練集、20%的測試集;然后將訓練集的樣本先分詞,再轉換為詞向量;接著將訓練集的樣本和標簽統一傳入算法中,得到擬合后的模型;繼而將測試集的樣本先分詞,再得到詞向量;最終把測試集得出的詞向量添加到擬合后的模型中,得出結果并將結果轉換為準確率的形式。在建立DNN 模型的過程中,本研究通過下載WeightWatcher 安裝包,導入樣本數據,利用神經網絡代碼直接預測準確率。選取準確率最高的深度神經網絡模型作進一步優化。
2 結果與分析
2.1 SSR 標記位點鑒定結果
首先需要初步鑒定SSR 位點,通過PSR 軟件,從茶葉參考基因組數據庫中獲得所有可能的SSR 標記,最終得到3 668 個標記位點,其中,比對到染色體上的位點有3 304 個(表2)[18]。SSR 標記位點的鑒定:利用PSR 軟件,經過篩選后得到2 924 個位點;過濾單個位點缺失率大于20%的位點后,獲得2 155 個多態性位點;通過線性回歸分析,篩選在不同省份特異性存在的位點(P<0.001),獲得700 個位點;結合不同SSR位點的相關性,在兩個及其相關的位點中只保留差異性較大的位點,最終獲得54 個SSR 位點。
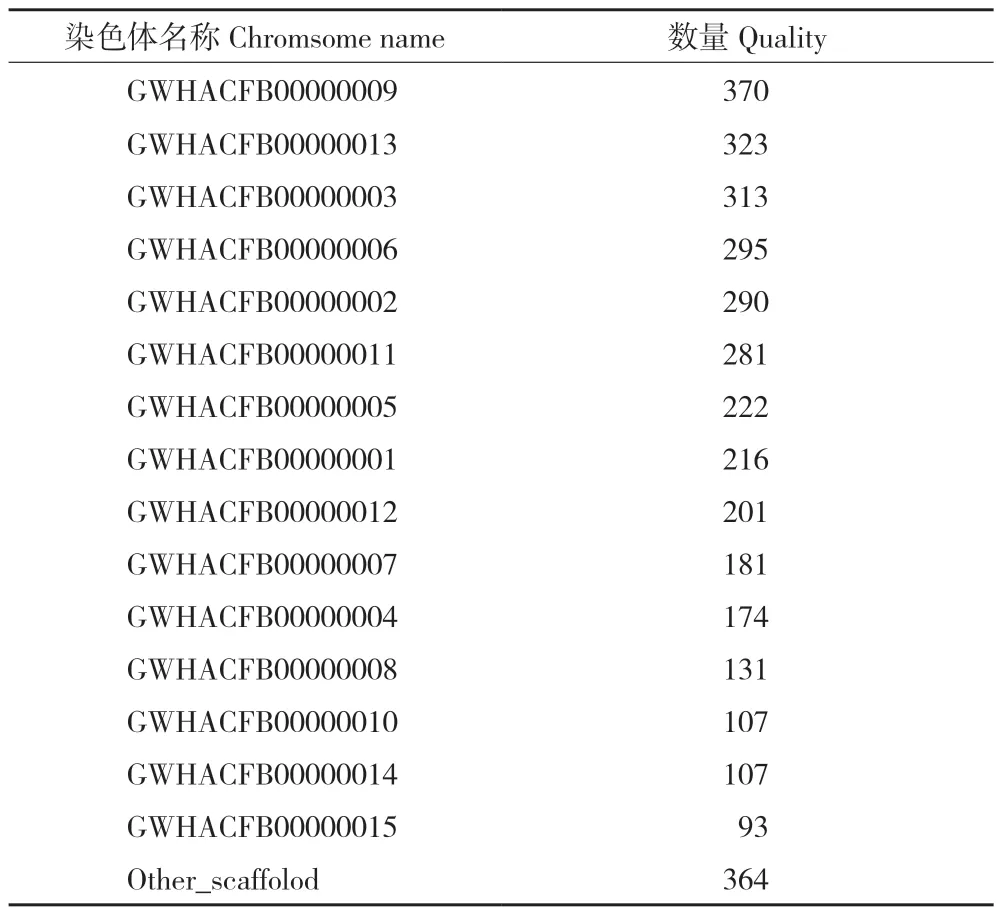
表2 各染色體中含有SSR 位點數目的統計Table 2 Statistics on the number of SSR loci contained in each chromosome
2.2 不同來源茶葉樣本PCA 結果
如圖1 所示,圖中每個點代表1 個樣本,兩點距離代表茶葉樣品受主成分影響下的相似性距離。全部樣本的PCA 結果表明,Dim1(7.6%)表示第一主成分貢獻率為7.6%,Dim2(4.3%)表示第二主成分貢獻率為4.3%,即前兩個主成分的累計貢獻率為 11.9%(圖1A);外類群與福建、湖南、云南、浙江4 省茶葉樣本差異顯著,部分與云南省樣品個體相近。本研究通過對4 省份數據進行PCA 來做進一步判斷。根據4 個省份間的PCA 結果(圖 1B),并排除外類群的影響,可以發現不同省份間的整體差異較明顯,而4 個省份內個體相對聚集。其中,云南省內的個體較其他省份差異大;福建、浙江、湖南的樣本分別聚集,這表明福建、浙江、湖南3 個省份間茶葉差異顯著,但有少量交叉,具有一定相似的遺傳結構特性,3 個省份間的親緣關系較近。其親緣關系遠近與地理來源并不呈現一致性,原因可能與茶葉人工馴化程度有關。PCA 也存在一定的不足之處,簡單的PCA 只能解釋部分個體的產地溯源問題,若要進一步研究溯源問題,則還需要用其他方法,如構建進化樹、神經網絡模型等方法,來進一步解釋和驗證交叉個體的溯源問題。
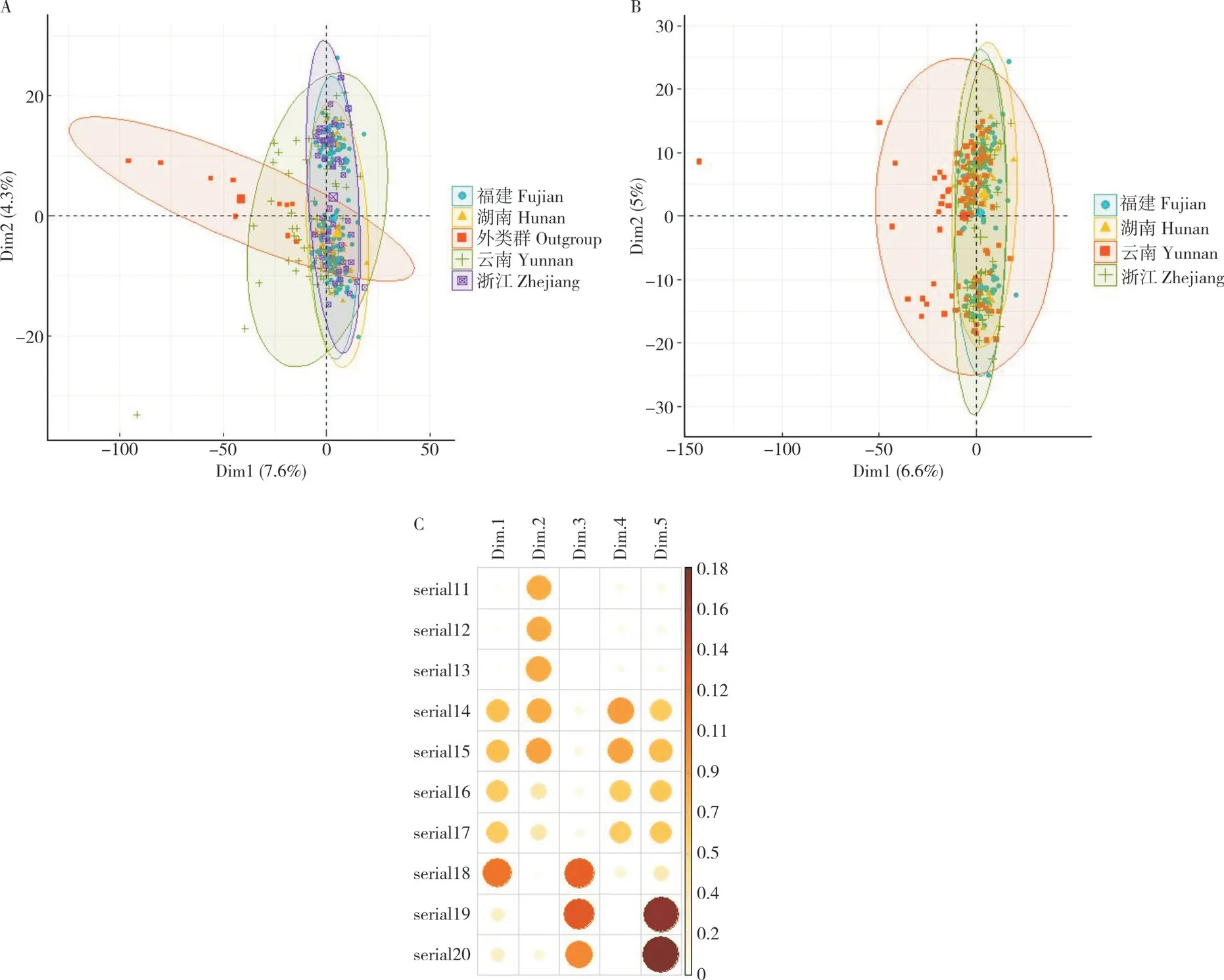
圖1 主成分分析結果Fig.1 Principal component analysis results
2.3 進化樹構建結果
從以上PCA 分析結果可以看出,不同省份的個體分別聚集,差異較為顯著,但也有少量的交叉,其中福建主要與浙江、云南鄰近,湖南與云南較近,外類群主要分布在云南附近,而云南個體分類較其他省份分散,由此構建不同省份茶葉的進化樹(圖2),其結果與PCA 結果相似。
2.4 模型構建與優化結果
2.4.1 不同模型預測結果 本研究利用3 種不同的模型對54 個SSR 分子標記矩陣構建模型,再初步鑒定不同模型的差異。通過線性回歸模型(81%)、隨機森林模型(77%)及DNN 模型(86%)對54 個SSR marker 矩形構建模型,發現深度神經網絡模型準確率最高、為86%,故選擇DNN 模型進行預測[19]。
2.4.2 DNN 模型的優化結果 本研究利用Matlab軟件的神經網絡工具對試驗數據進行建模。使用54 個SSR 和323 個樣本,構建預測模型,再用Tensorflow2.0 優化DNN 模型的一次訓練樣本個數(Batch size)、訓練次數(Step size)、隱藏層層數和每層節點數4 個參數。
將323 份樣本中除了外類群以外的數據分成訓練集、測試集和驗證集3 個部分,其中訓練集、測試集、驗證集的測試比例分別為0.8、0.1、0.1,即訓練集273 份,測試集20 份,驗證集20 份。先用訓練集訓練模型,再用測試集進行最后優化,并使用驗證集對優化后的模型進行驗證。
2.4.3 參數Batch size 和Step 的優化 本研究通過對參數Batch size 和Step 進行優化,測試不同參數對準確率的影響。對每次訓練選取的Batch size 分別設為150、200、250、300,而迭代的次數Step 分別為5 000、10 000、15 000、20 000、25 000、30 000。理論上Step 越高模型準確率就越高,但Step 過高會導致模型過度擬合。通過對測試集10 次重復驗證,發現參數Batch size 為150 和Step 為20 000 綜合起來表現效果最好(表3、表4)。

表3 測試集和驗證集最優準確率Table 3 Optimal accuracy of the test and validation set

表4 測試集和驗證集平均準確率Table 4 Average accuracy of the test set and validation set
2.4.4 隱藏層層數和每層節點數的優化(1)隱藏層層數的優化:利用不同的隨機參數模擬2~4 層神經網絡的測試集和驗證集的準確率。經對比,發現神經網絡為2 層時驗證集和測試集的準確率最高,約95%(圖 2 A)。(2)每層節點數的優化:確定隱藏層為2 層后,分別產生25~150間隔為5 的26 個可能節點數,隱藏層的兩層網絡組合一起是26×26 共676 個組合的矩陣,檢測不同參數對應的準確率,每個組合進行10 次重復。
然后按以下打分規則對最優準確率進行確定,通過統計不同指標對所有組合進行打分,每一種指標都能進10%得1 分:測試集和驗證集準確率的平均值;驗證集準確率的平均值;最優驗證準確率。最后統計2 分以上的次數(圖3),圖3A 為在最優Batch size 和Step size 時不同神經層數的柱狀圖,對比發現神經網絡為2 層時驗證集和測試集的準確率最高;圖3B、C、D、E 為2 層隱藏層神經網絡參數的優化,其中B 為不同維度模擬的自測數據的平均準確率,C 為不同維度模擬的驗證數據的平均準確率,D 為不同維度模擬的自測數據的最優準確率。綜合準確率方差等因素,本研究選擇隱藏層第一層95、第二層40 的模型為最優模型,其中自測集的平均準確率95%,自測集合驗證平均值準確率89%,驗證集的平均準確率75%以上,最優準確率為100%。

圖3 深度神經網絡層數和節點數的參數優化結果Fig.3 Oprtimization results of layer number and node for each layer for the Deep Neural Network
3 討論
我國是茶葉消費大國,隨著人們生活水平的提高,消費者對茶品質的要求也日益提高。為了確定茶葉的真實產地,研究者運用各種方法進行研究。目前,生物信息學在基因測序分析中發揮著舉足輕重的作用,國內主要是以實驗為基礎,通過測定農產物及其土壤中的礦質元素,再進行相關性分析、聚類分析、主成分分析等多種統計分析方法,進而對農產品進行溯源分析[20]。本研究主要以生物信息學為基礎,通過分析相關的基因位點,構建模型并進行優化,最終對茶葉溯源進行分析。
本研究通過基因組的SSR 位點進行基因數據分析。SSR 作為第二代分子標記,具有重復性好、多態性高、變異豐富、呈共顯性且廣泛分布于植物基因組等優點,已被廣泛應用于高粱、大麥、小麥、青稞等作物遺傳多樣性分析和基因研究[21]。與SNP 標記相比,SSR 標記的優勢是成本低、試驗技術簡單[22]。本研究先利用PSR 軟件從茶葉參考基因組中鑒定所有可能的SSR 標記位點,再比對到染色體上,利用PSR 設置參數支持的reads 總數大于5 同時支持reads 的比例大于10%[23],得到樣本后進行位點篩選,最終獲得54 個SSR 位點;再利用3 種不同的模型對54 個SSR 分子標記矩陣構建模型,初步鑒定不同模型的差異[24];選擇準確率最高的神經網絡模型,進行人工神經網絡模型的優化和參數選擇、Batch size 和Step size 的優化、隱藏層數目和每層節點數優化、2 層隱藏層神經網絡參數的優化,最后選擇準確率在95%左右最優的2 層神經網絡模型[25]。
在研究地理溯源領域中,大部分研究都是利用分子標記或化學標記構建變異圖譜,然后查看變異圖譜的相似性來進行溯源。本研究使用深度學習預測方法,在研究產地溯源領域使用量較少,主要通過建立樣本的基因差異矩陣,使用PCA 分析323 個樣本間的差異度,結果非常直觀。通過分析圖片,發現外類群與福建、湖南、云南、浙江4 省份間的差異顯著,而各省份內個體相對聚集,其中云南省內的個體差異較其他省份大;4省份有部分材料重疊在一起,表明不同省份的部分茶葉也具有一定的遺傳相似性[26]。構建整體樣本的進化樹,結果表明不同省份的茶葉個體分別聚集,差異顯著,但也有少量交叉,此結果與PCA 結果相似[27]。
本研究只研究福建、湖南、云南、浙江4 省份和10 個外類群共323 個樣本,茶葉轉錄組數據存在樣本量少的局限性,后續需要增加樣本容量,對茶葉溯源作進一步研究。
4 結論
本研究對來自湖南、云南、福建和浙江省的313 個茶葉樣本的來源屬地及10 個外類群關系進行研究,以篩選出的54 個高質量的SSR 位點為基礎,對樣本進行主成分分析,并通過3 種不同的分類模型比對及優化,得出2 層神經網絡模型對茶葉分析效果最佳,準確率約95%。本研究構建的分類模型也可以用于其他物種重測序數據的屬地來源鑒定。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
