基于改進YOLOv5的自然環境下番茄果實檢測*
2023-11-11 04:03:02胡奕帆趙賢林李佩娟趙辰雨陳光明
中國農機化學報 2023年10期
胡奕帆,趙賢林,李佩娟,趙辰雨,陳光明
(1.南京工程學院,南京市,211167; 2.南京農業大學,南京市,210031)
0 引言
我國各地普遍種植番茄,是世界番茄產量最大的國家[1]。但是,番茄采摘主要依靠人工進行,采摘效率較低,無法保證采摘的質量。同時隨著城鎮化進程的不斷推進農村人口減少與人口老齡化,勞動力不足逐漸導致勞動力成本升高[2]。因此,研究番茄果實目標檢測算法,提升農業自動化、智能化水平,對于緩解人力資源不足,提高生產效率有著重大影響。
隨著農業自動化、智能化的發展,計算機視覺已經被廣泛應用于農業機器人當中,Liu等[3]基于YOLOv3網絡提出了一個密集的體系結構,可以更加精準地匹配番茄,檢測準確率為94.58%;劉芳等[4]為實現溫室環境下農業采摘機器人對番茄果實的快速、精確識別,提出了一種改進型多尺度YOLO算法(IMS-YOLO)檢測準確率為96.36%,檢測時間為7.719 ms;周云成等[5]為提高番茄器官目標識別的準確率,提出一種基于RGB和灰度圖像輸入的雙卷積鏈Fast R-CNN番茄器官識別網絡,雙卷積鏈Fast R-CNN識別網絡對果的識別平均準確率最高為63.99%,特征檢測時間為320 ms。目標檢測是計算機視覺的前提和關鍵,檢測的速度和精確度是考量算法的重要指標。以上方法雖然比傳統的番茄果實目標檢測方法提高了檢測性能,但是難以實現高精度、快速度和低成本等條件下智慧農業的應用。
考慮到檢測性能和速度的需求,本文提出一種改進YOLOv5s以檢測自然環境下番茄果實的方法,通過添加注意力機制、替換backbone(主干網絡)等手段,提高番茄果實檢測的準確率和實時性。
1 算法與改進
1.1 目標檢測算法
目標檢測算法作為計算機視覺的基礎,能夠提供關鍵的場景信息。目前方法可以分為兩大類:(1)基于候選區域的方法,先生成可能的目標區域,再對其進行分類,如Faster R-CNN和Mask R-CNN,這類方法識別準確,漏檢率低,但實時性較差。(2)基于回歸框的方法,直接預測目標的位置和類別,如SSD[6]和YOLO[7],這類方法實時性強,但識別準確率和漏檢率較第一類稍差。在YOLO系列模型中,YOLOv4和YOLOv5的綜合性能較優。尤其是YOLOv5的推理速度更快。
1.2 YOLOv5算法
YOLOv5通過模型設計和訓練技巧的改進,達到了精度和速度的平衡,是目前廣泛使用的實時目標檢測模型之一。數據增強可以通過增加訓練樣本數量和豐富樣本多樣性來增強模型的泛化能力,避免過擬合。具體來說,一種方法是通過改變圖像的拍攝角度、光照條件、添加遮擋等來獲得更多不同的樣本。另一種方法是對現有樣本進行裁剪、翻轉、平移、色域調整等圖像變換,制造更多樣化的訓練數據。這兩種數據增強方法可以有效提升模型對不同情景和變化的適應力。YOLOv5自帶了多種數據增強技術,主要包括mosaic、cutout、mixup、圖像擾動、隨機縮放、隨機裁剪、隨機擦除等。這能產生更多樣化的訓練數據,增強模型的泛化能力。
為了模型壓縮和加速,一種方法是替換網絡的backbone架構,通過移除網絡冗余信息來減小模型大小和計算量,另一種方法是引入注意力機制,它可以通過聚焦輸入信息的關鍵部分提升模型效率。注意力機制往往是一個較小的子網絡結構,可以很方便地集成到各種模型中,SEnet[8]通過對通道維度增加注意力機制,獲取每個特征通道的最佳權重值。CBAM[9]結合了空間和通道的注意力機制,取得更好的效果。Triplet Attention[10]在CBAM基礎上實現了跨維度交互,實現多維交互而不降低維度的重要性,因此消除了通道和權重之間的間接對應。特征融合用于加強目標檢測中對小物體檢測,因為卷積過程中,大物體的像素點多,小物體的像素點少,隨著卷積的深入,大物體的特征容易被保留,小物體的特征越往后越容易被忽略。BiFPN[5]相當于給各個層賦予了不同權重去進行融合,讓網絡更加關注重要的層次,而且還減少了一些不必要的層的結點連接。
1.3 具體改進方法
本文提出了四個模塊來改進YOLOv5:(1)數據增強模塊,使用mosaic、mixup[11]和cutout[12]等方式增強訓練集;(2)backbone模塊,使用Ghostconv[13]來減少參數量,加速計算;(3)注意力模塊,在backbone中添加協同注意力機制(Coordinate Attention[14],CA),聚焦位置信息;(4)特征融合模塊,使用改進的BiFPN[15]替換FPN,添加上下文信息,提高特征融合的效率。使用這四個模塊的改進,使得模型的檢測精度和速度都得到提升,改進后的網絡結構如圖1所示。
1.3.1 數據增強模塊
數據增強部分主要采用了mosaic、cutout和mixup三種方式。其中mosaic數據增強可以在不損失信息的前提下獲取二倍大小的特征圖。為了進一步提高效果,本文在使用mosaic的同時,引入了cutout和mixup進行組合的數據增強。圖2展示了mosaic增強的示例,圖3和圖4分別展示了cutout和mixup的增強效果,三種增強技術的組合,可以產生更豐富的訓練樣本,提升模型的泛化能力。

圖3 使用cutout增強

圖4 使用mixup增強
mixup是一種基于鄰域風險最小化的增強技術,其原理是在訓練過程中,以一定比例混合兩個樣本的圖像數據和標簽,從而構造出新的虛擬訓練樣本,這可以增強模型的泛化能力,并減少過擬合對錯誤標簽的依賴。簡單來說就是將兩張圖像及其標簽平均化為一個新數據。
圖像混合公式如式(1)所示。
x_mixup=α×x_i+(1-α)×x_j
(1)
式中:x_mixup——混合后的新圖像;
x_i、x_j——兩張原始圖像;
α——混合比例參數。
標簽混合公式如式(2)所示。
y_mixup=α×y_i+(1-α)×y_j
(2)
式中:y_mixup——混合后的新標簽;
y_i、y_j——兩張原始圖像對應的標簽。
mixup通過上述公式,以一定比例混合兩張圖像和標簽,從而構造出新的虛擬訓練樣本。這種數據增廣技術可以提高模型的泛化能力,增強對未知數據的適應性。
cutout則是通過在圖像中隨機遮擋一塊區域,迫使模型學習整體特征而非依賴局部信息,以提高模型的魯棒性。cutout可以增強卷積網絡利用全局視覺上下文的能力。
x_{cutout}=M⊙x+(1-M)⊙v
(3)
式中:x——原始圖像;
x_{cutout}——遮擋后的圖像;
M——與原始圖像x相同大小的遮擋Mask,被遮擋位置為0,其余位置為1;
v——用于填充被遮擋部分的真實值,通常設置為0;
⊙——元素對應位置的乘法操作。
1.3.2 backbone改進
傳統的深度學習特征圖是通過卷積得到的,卷積完成后輸入下一個卷積層計算,這樣存在大量冗余參數,提取到了大量無用的特征,消耗大量計算資源。如圖5與圖6所示,相比于YOLOv5的主干網絡CSPDarknet53中的傳統卷積,Ghostconv的計算成本更低,僅通過少量計算(cheap operations)就能生成大量特征圖的結構,并且可以適用在任何大型的CNN模型中。Ghostconv卷積部分將傳統卷積操作分為兩部分:第一步,使用少量卷積核進行卷積操;第二步,使用3×3或5×5的卷積核進行逐通道卷積操作,最終將第一部分作為一份恒等映射與第二部分進行拼接。
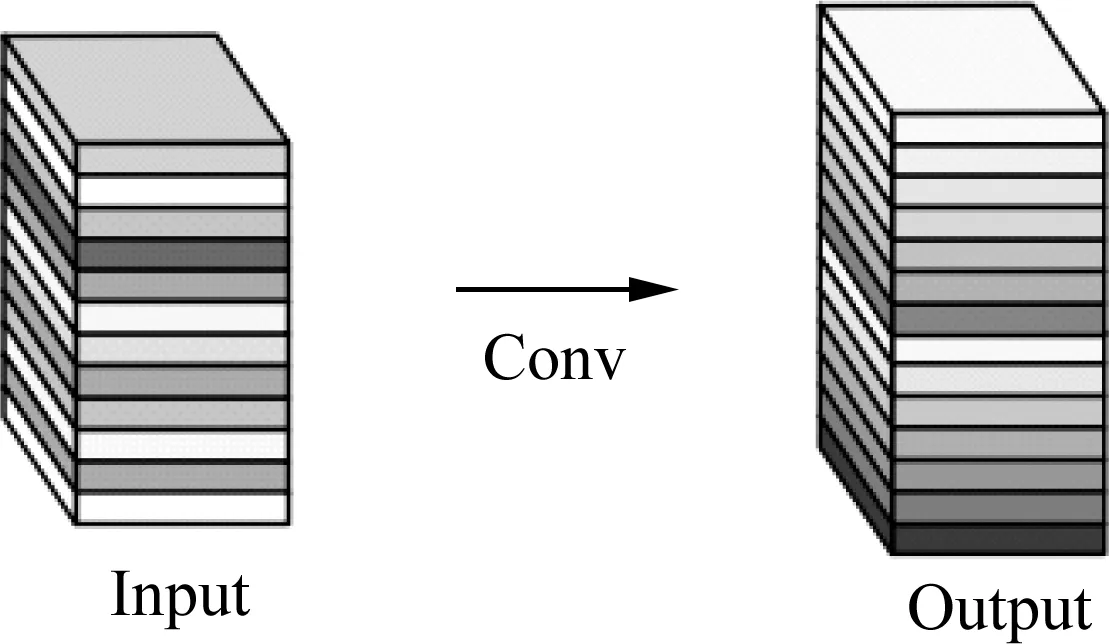
圖5 Ghost卷積
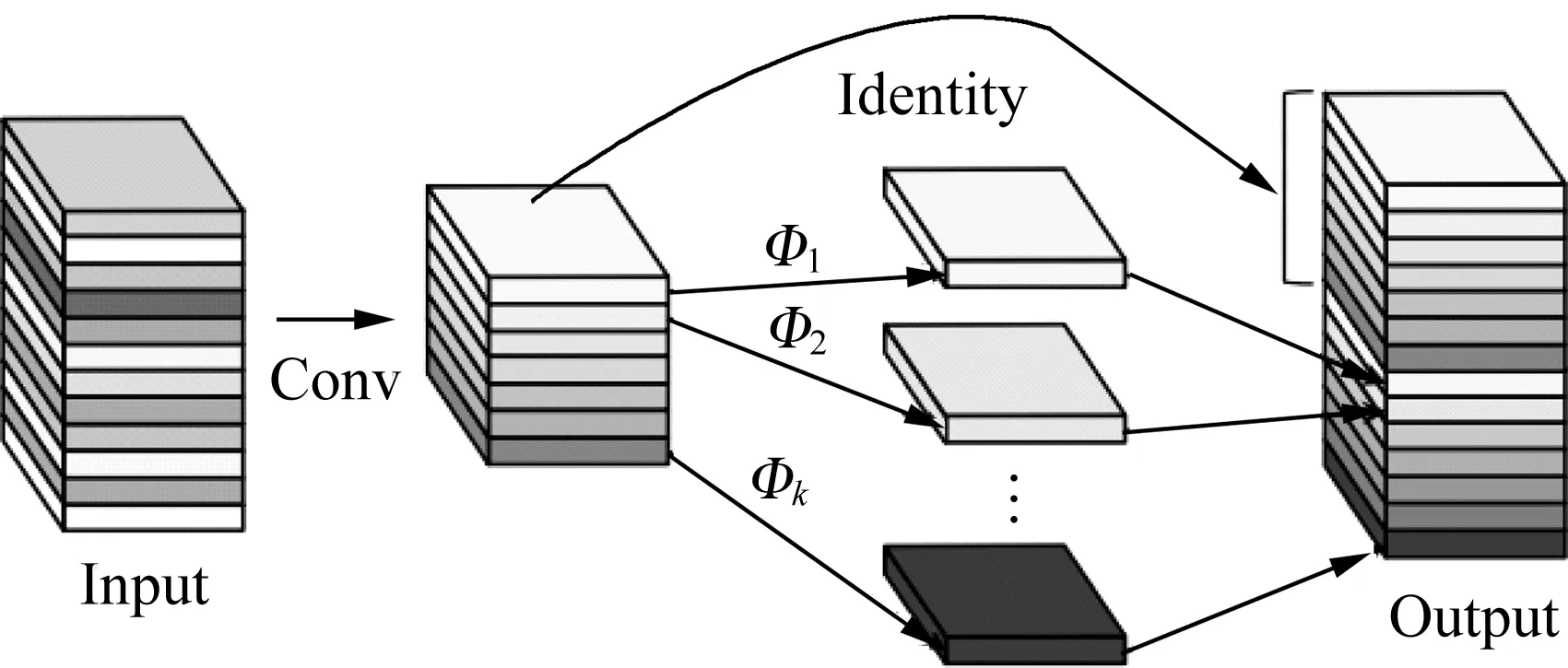
圖6 Ghost模塊
Ghost Bottleneck的作用和殘差塊的作用一樣,結構也和殘差塊的結構類似。如圖7所示,模塊部分有兩種結構,Stride=1,即當不進行下采樣時,直接進行兩個Ghostconv操作;Stride=2,當進行下采樣時,增加一個Stride=2的深度卷積操作。將Ghostconv替換YOLOv5的主干網絡后可以降低網絡的計算成本,加速計算。
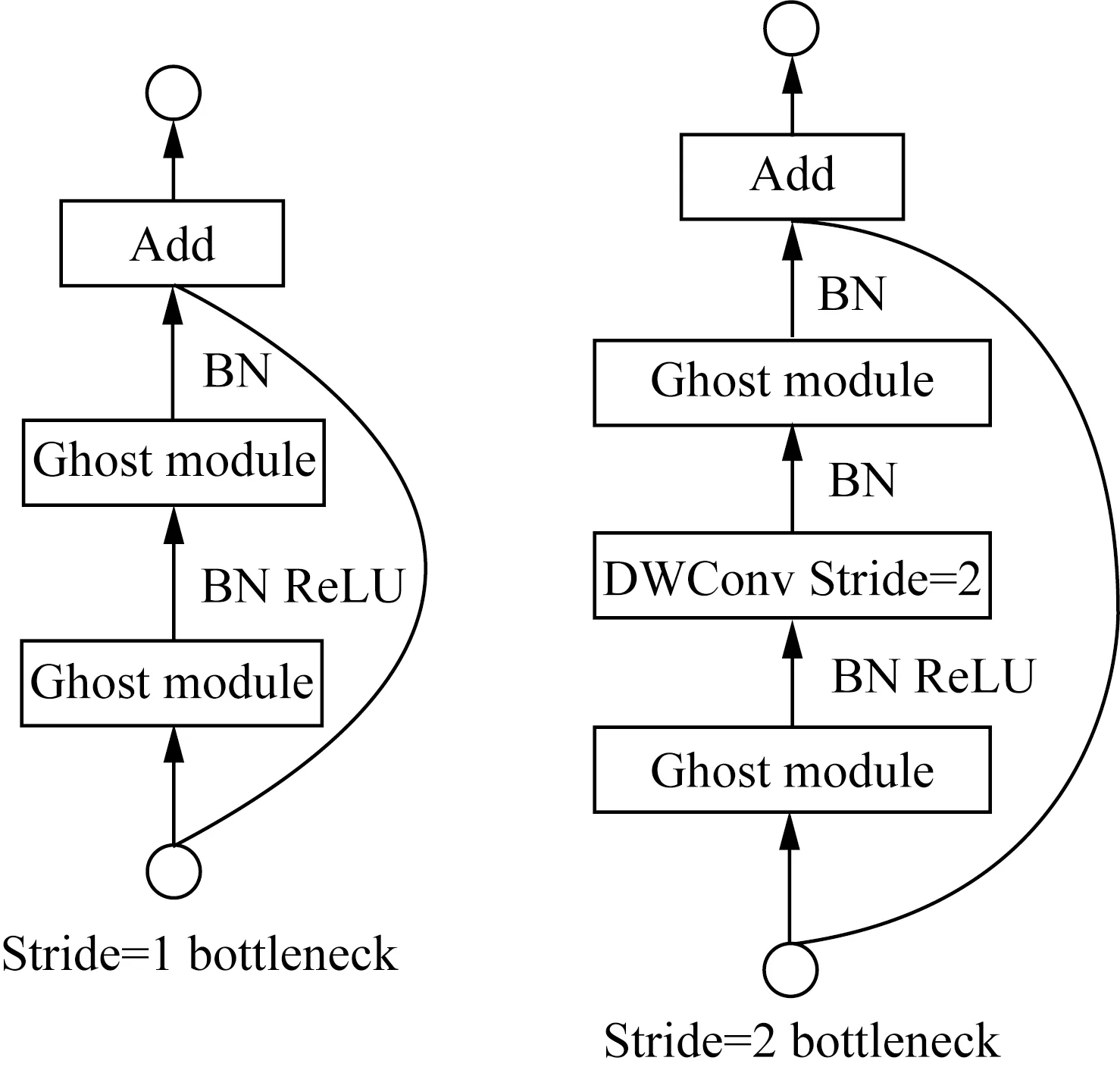
圖7 Ghost瓶頸層
1.3.3 注意力機制模塊
注意力機制可以顯著提升模型性能,主要分為通道注意力和空間注意力,通道注意力如SENet可以明顯增強效果,但通常會忽略位置信息,而位置信息對生成空間注意圖非常重要,先前的CBAM模塊雖然引入空間信息編碼,但未建立通道和空間注意力之間的關聯。CA模塊(圖8)通過精確的位置信息對通道關系和長期依賴性進行編碼,將通道注意力分解為兩個一維特征編碼過程,并分別沿兩個空間方向聚合特征。這樣,既可以沿一個方向捕獲遠程依賴,又可以沿另一方向保留精確的位置信息。
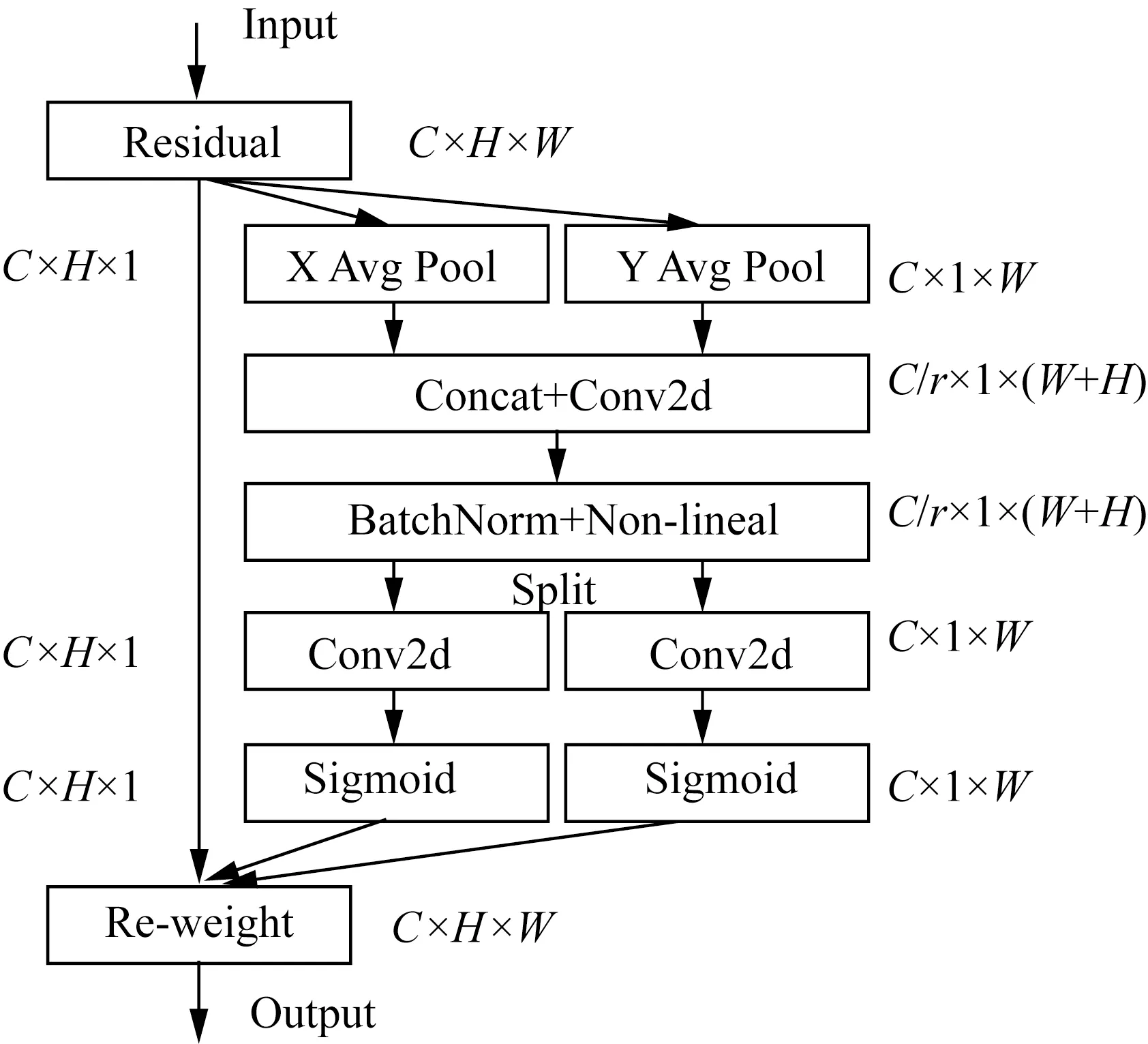
圖8 CA注意力機制結構
CA分兩個步驟:第一步是Coordinate Embedding,其目的是編碼每個位置的精確空間信息。具體做法是使用一維池化核對特征圖在高度和寬度上分別進行池化,得到一對編碼后的一維向量。第二步是Coordinate Attention生成,它基于第一步的編碼結果,通過全連接網絡學習生成每個位置的注意力權重。這樣通過編碼精確的坐標信息,CA模塊可以建模空間依賴關系,從而產生有效的注意力增強。具體公式如式(4)、式(5)所示。
h_c=δ[AvgPool1D(X;kernel_h)]
(4)
w_c=δ[AvgPool1D(X;kernel_w)]
(5)
式中:AvgPool1D——一維平均池化操作;
X——原始特征;
w_c——圖像的寬;
h_c——圖像的高;
kernel_h——特征圖高;
kernel_w——特征圖高。
將上述兩組編碼連接起來,輸入一個多層全連接網絡,學習注意力權重
f([h_c,w_c])=W2σ(W1[h_c,w_c])
(6)
式中:f——多層全連接網絡;
σ——激活函數;
W1、W2——權重矩陣。
最終的CA注意力映射
CA(X)=f([h_c,w_c])?X
(7)
其中?表示逐元素相乘,即對原特征X進行加權。
從效果上看,CA模塊相比SEnet、CBAM等注意力結構有更優秀的性能,因為CA通過精確的坐標編碼增強了網絡對目標的關注能力,這樣可以更好地提升模型的檢測性能,而計算量也比較低。總體來說,CA模塊設計精巧,既考慮了位置信息對注意力的重要性,又控制了計算復雜度,相比其他結構,CA可以產生更有針對性和高效的注意力機制來增強模型。
1.3.4 特征融合
深度學習中融合不同尺度特征是提高性能的關鍵,低層特征包括位置、細節,高層特征具有更強的語義信息,通過將兩者結合可以改善模型效果。FPN屬于neck部分,用于構建所有尺度的高級語義特征。如圖9所示,FPN結構存在缺陷,如層與層之間存在語義鴻溝,直接融合會降低作用;下采樣過程中會損失高層特征;各層ROI獨立參與預測導致各層關聯性小。在YOLOv5的neck部分中使用FPN+PAN結構,FPN引入了一條自頂向下的通道來融合特征,PANet在FPN基礎上增加了一條自底向上的通道,NAS-FPN使用了不規則拓撲結構,這需要消耗大量的計算資源。BiFPN使用了類似Resnet的結構并且移除了邊緣節點,然后將這兩層當成一個模塊,重復調用來獲取更高層次的特征融合。使用softmax會帶來較大的GPU延遲,因此BiFPN使用了Fast normalized fusion來模擬Softmax-based fusion,由于未使用指數因此計算速度更快,公式如式(8)所示。
(a) FPN
(8)
式中:wi——可學習的權重;
O——特征融合輸出;
Ii——輸入。
其中wi≥0并且在每個wi≥0后應用一個ReLu激活函數保證其大于0,ε=0.000 1來防止網絡不穩定。
2 試驗和結果分析
2.1 數據集和試驗環境
本文的數據集來源于自己制作的數據集,分為成熟的番茄和未成熟的番茄兩個類別。圖像分辨率為720像素×720像素,共830張照片。數據集以7∶3比例劃分訓練集和驗證集,其中訓練樣本為580張,驗證樣本為250張。本文試驗環境:Intel? Xeon Silver 4216 (64)內存128 GB,顯卡為NVIDIA GeForce RTX 2080 Ti 12G×2,操作系統為Ubuntu20.04,在Pytorch 1.10.0下實現模型的搭建及試驗。
訓練參數:將本文劃分好的數據集作為輸入,設置輸入為640×640,學習率設置為0.001,動量和權重衰減被設置為0.937和0.000 5。采用Adam優化器對網絡參數進行優化。Batch_size設置為32。
2.2 評價指標
目標檢測常用的評價指標:準確率(Precision,P)、召回率(Recall,R)、平均精度均值(mAP,mean Average Precision)、F1,計算公式如式(9)~式(12)所示。
(9)
(10)
(11)
(12)
式中:TP——檢測模型識別為番茄果實成熟或不成熟且正確的數量;
FP——檢測模型識別番茄果實成熟或不成熟但錯誤的數量;
FN——檢測模型遺漏識別番茄果實的數量;
AP——番茄果實檢測平均精度;
N——模型檢測所有種類的數量。
本文使用mAP@0.5、mAP和F1作為評價指標,來全面評估番茄檢測模型的性能,mAP@0.5聚焦不同檢測閾值下的精度,mAP給出不同類別的平均性能,F1綜合考慮精度和召回率。
2.3 與主要目標檢測算法性能對比
為進一步驗證本文提出算法的性能,與YOLOv3-spp、YOLOv5s+Mobilenet v3和YOLOv5s模型進行對比試驗,試驗結果如表1所示。

表1 不同模型在同一數據集的性能對比
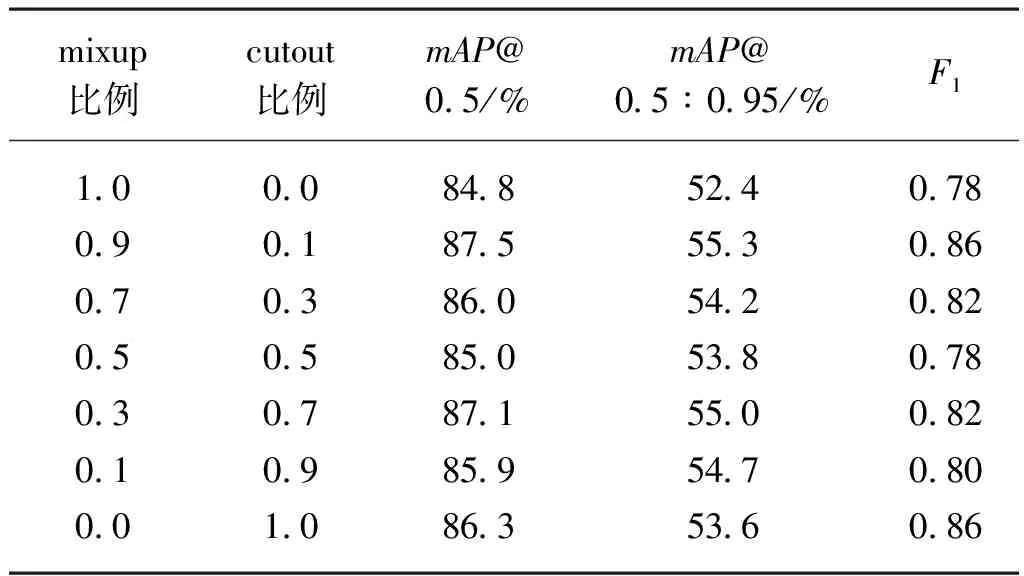
表2 不同數據增強比例對于YOLOv5s性能影響
YOLOv5s+Mobilenet v3是將YOLOv5s的主干網絡由CSPDarknet替換完Mobilenet v3來縮減模型大小,速度達到了174 fps,但是mAP下降,本文相對于原始的YOLOv5模型mAP@0.5提高了4.2%,成熟番茄的識別率提高了1.9%,未成熟的番茄提高了0.5%,檢測速度為101 fps,滿足檢測要求。圖10為本文方法和YOLOv5s檢測結果對比。總體而言,試驗驗證了所提方法在提高精度的同時,仍保持了較快的檢測速度。

(a) YOLO v5s
2.4 不同數據增強方式對比試驗
由于自然環境中番茄遮擋情況較多,因此采用cutout數據增強。在使用mosaic時,試驗了mixup和cutout不同比例的組合效果。將兩者比例之和設為1,測試了0∶1、0.1∶0.9、0.3∶0.7、0.5∶0.5、0.7∶0.3、0.9∶0.1的值。結果表明,當mixup為0.9比例、cutout為0.1比例時,mAP@0.5達到87.5%,F1為0.84,相較無增強分別提升了0.5%和0.02。該組合比例下模型精度最優。
2.5 消融試驗
為分析各改進對模型性能的影響,進行了消融試驗。試驗詳情見表3,其中“√”表示該模塊被使用,“×”表示未使用。YOLOv5s-A使用Ghostconv獲得mAP@0.5提升但mAP下降。YOLOv5s-B在A基礎上改用BiFPN,mAP@0.5和mAP較原網絡均有提升。YOLOv5s-C在B基礎上添加CA模塊,mAP@0.5相比B提升0.4%,mAP提升2.4%。YOLOv5s-D在C基礎上加入mixup和cutout,mAP@0.5達到87.5%,提升0.6%。

表3 消融試驗
綜上,各模塊對檢測精度均有提升,特別是CA模塊和數據增強的聯合使用取得了最佳效果。
3 結論
1) 本文針對自然環境下的番茄檢測任務,在YOLOv5s模型基礎上進行了以下幾點改進:引入cutout數據增強,緩解遮擋問題;使用Ghostconv降低模型冗余;添加CA注意力機制增強特征表達;改用BiFPN進行多尺度特征融合。
2) 改進后的模型mAP@0.5達到87.5%,檢測速度101 fps,精度和速度均滿足實際需求。與其他主流檢測算法比較,也顯示出計算效率和資源占用上的優勢,更適合本研究的應用場景。本研究為機器人番茄采摘與智能農業提供了有效的檢測算法支持,具有推動作用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
