基于集成分類非定標攝像機單目表情識別的研究
2023-11-10 07:20:28鄒建華龍卓群
黑龍江科學 2023年20期
余 濤,鄒建華,徐 君,龍卓群
(1.西安航空學院電子工程學院,西安 710077; 2.西安交通大學系統工程研究所系統工程國家重點實驗室,西安 710049; 3.廣東順德西安交通大學研究院,廣東 佛山 528300)
0 引言
面部表情識別在很多領域都非常有價值,如醫療診斷[1]、教育[2]及人機交互系統[3]等。被識別的面部表情主要有兩種類型,即二維表情[3]與三維表情[4],前者直接識別在二維面部圖像中獲得的處理過的特征,后者利用多個攝像機拍攝多個視角的面部圖像、特定的3D數據庫、特定的傳感器獲得三維特征。可將二維與三維結合起來識別面部表情[5],獲取并處理特征。
面部表情識別方法主要包括神經網絡(Neutral network)[6]、支持向量機(Support vector machine)[5]、馬爾科夫鏈(Markov chains)[4]等。不同的學習機適應不同種類的數據集,當這些學習機被單獨利用時,它們無法克服自身的局限性,甚至常常使實際數據集以犧牲很多有用的特征信息為代價在很大程度上作出改變調整來適應學習機,這樣將影響識別的準確率。為盡可能保留這些原有的特征信息,需研究以某種架構集成學習機來提高整體性能。由于在多數情況下得到的是二維面部表情圖像,故嘗試直接從二維圖像中獲得并利用一些反應出的三維信息來實現逼近的三維識別。
本研究針對來自一個非定標攝像機的單目視頻人的面部表情提出一個進行自動識別的框架方法,通過一個類似面部肌肉分布的彈性模板提取出相關的表情特征。經過規則化和正則化,隨著一個表情的產生,這些特征在時空中變化形成的時間序列被逐行排列進一個矩陣中。利用保持鄰域嵌入法(NPE),對這個特征矩陣進行降維,以這個被提煉后的矩陣作為輸入,用一個集成了隱條件隨機場(HCRF)和支持向量機(SVM)的集成分類器來識別表情。
1 基本原理
圖1給出了面部表情識別的方法框架,其中單目視覺的二維動態表情序列或視頻被用來作為訓練或測試的輸入表情,用表情圖像中面部不同區域灰度值的質心作為特征。因為灰度包含亮度、對比度及飽和度的成分,它們都會隨著不同深度而變化,故灰度值含有一定量的深度信息,特別是它的相對變化值。隨著每個表情的產生,這些特征在時空中運動。
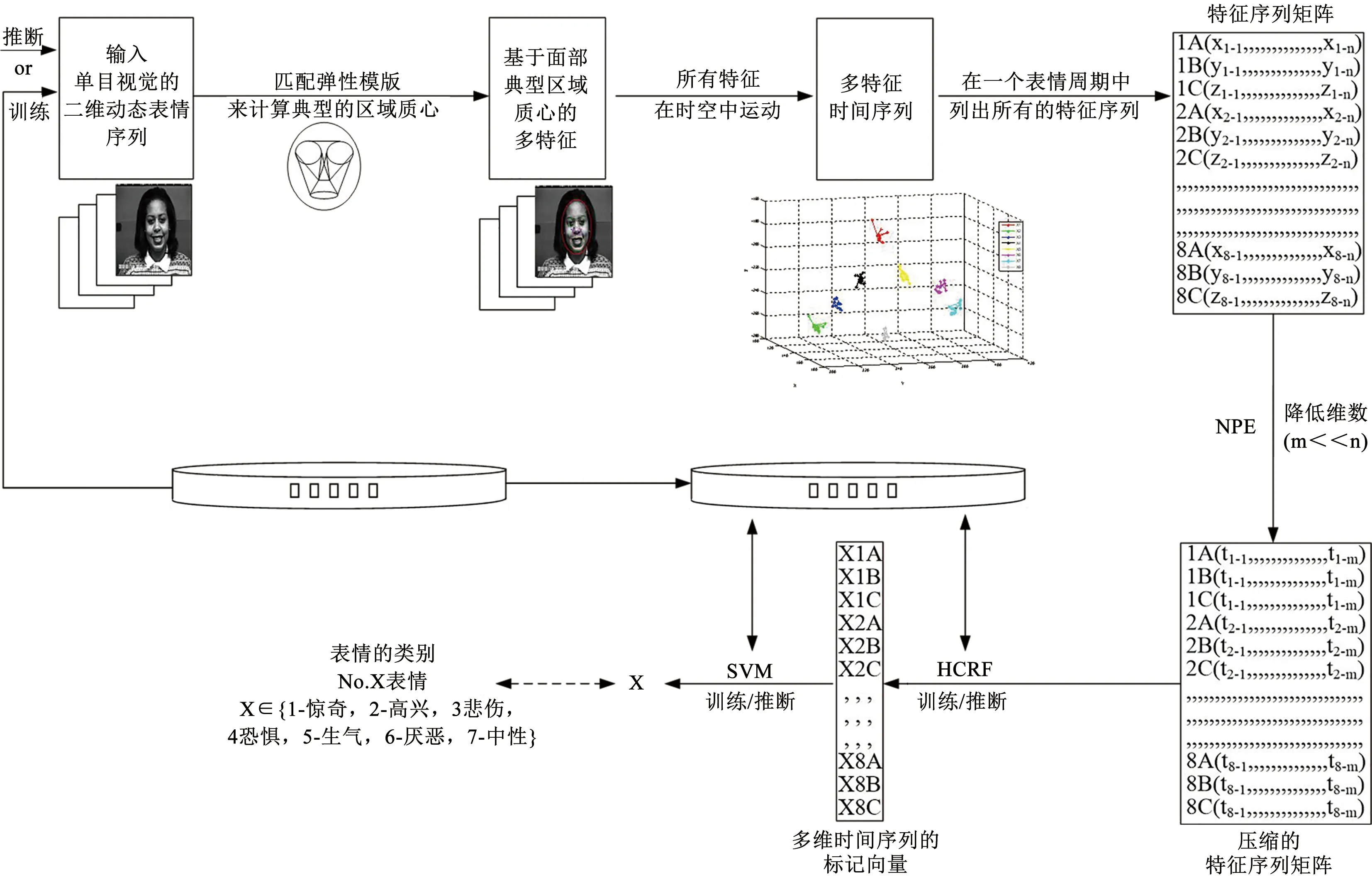
圖1 面部表情識別原理Fig.1 Principles of facial expression recognition
通常相同類別表情的特征在時空運動中具有類似的周期性形式,因此每種類型表情在識別框架中只需要一個面部表情周期。隨著表情產生過程,相關特征在時空中變化形成時間序列。將其排列成矩陣。這樣識別問題就轉化成處理所有時間序列數據的問題。
2 各環節處理及分析
2.1 特征提取與處理
用一個面部檢測器檢測人臉,如果檢測成功,就在此面部區域再用相關檢測器分別檢測眼睛、鼻子及嘴巴(若這些感官中的某一個檢測失敗,將基于標準普通人臉的一些通用先驗解剖學知識,按照一定比例在面部區域中確定可能的五官區域。如果面部檢測沒成功,就用面部檢測器在該圖像中其他區域搜索)。被檢測出的區域用對應的圓圈、三角及橢圓繪制。用線條來連接檢測出的區域邊緣的不同位置,構成彈性模板。此方法可節省處理時間,檢測器參照文獻[7]進行設計,可自動檢測,不需要手動輔助。圖2是用于檢測面部表情特征的彈性模板工作原理,可以看出,模板特征與人面部肌肉的一般分布在很大程度上是一致的,可從人體解剖學的角度來分析表情。圖3為用模板檢測一個人的常見表情。該檢測是在以Microsoft Visual C++ 6.0為平臺的環境下實現的。
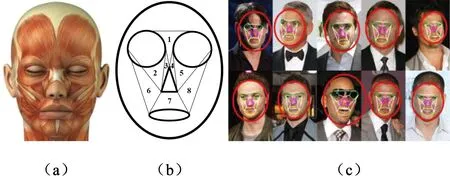
圖2 彈性模板匹配原理(a.面部肌肉分布 b.彈性表情模板c.真實人臉與彈性模板匹配示例)Fig.2 Elastic template matching principle (a.Facial muscle distribution, b.Elastic expression template, c.Real face and elastic template matching example)

圖3 彈性模板與真實人臉在不同表情下的匹配Fig.3 Matching of elastic template and real face under different expressions
根據人面部肌肉的分布及其動態性能的解剖學知識[8],將面部表情分為8個區域。在每個區域中用一個相關的質心來描述該區域的像素在時空中隨著不同表情而產生的整體變化。每一個質心通過公式(1)進行計算,其中,在時刻t時,ni是區域i中像素的數目;xm、ym和zm分別是每個像素的水平坐標、垂直坐標及灰度值。
(1)
圖4用Matlab工具描繪了從一個人的中性表情開始,逐漸產生上述典型表情過程中運動質心的時間序列分布。這些時間序列的分布與形狀因表情種類的不同而不同,故可用來作為區分彼此不同表情的依據。
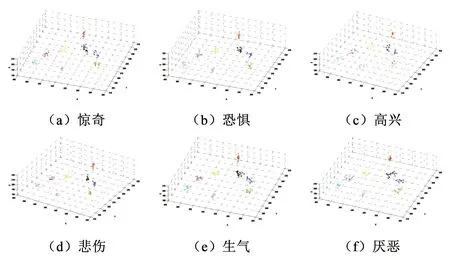
圖4 一個人由中性表情逐漸變化到不同種類表情中運動質心的時間序列分布Fig.4 Time series distribution of the center of mass of motion of a person from neutral expression to different kinds of expression
(2)
公式(2)描述了對上述時間序列預處理的原理,包括提取相對變化值、正則化及離散化。
2.2 NPE用于運動時間序列的降維
由于現實中時間序列長度很長,而序列在認知意義上的結構維數本身較低,需要降維。考慮到對同種類型的表情來說,所有特征的時間序列互相關聯且這種關聯性是重要的個性化特征,故希望這種結構相關性在進行降維的同時盡可能得以維持繼承。
文獻[9]中的保持領域嵌入法(NPE)是一種在維持數據流形的局部領域結構的流形學習方法,比主成分分析法(PCA)[10]對外圍數據的敏感度小,與流形學習方法(如Isomap[11]及LLE[12]相比,NPE方法不只局限于定義在訓練數據中,而是定義在全局意義上,故采用此方法來降維。
如文獻[9]所述,主要原理如公式(3)~(5)所示。需注意由相關曲線產生的每一個時間序列i(i=1,…,8×3=24)被看做一個數據點xi。為了保持曲線間的相關特性,構建領近圖的方式用KNN,設K為24。面部表情中的每個時間序列由領近的其他23個時間序列進行重構。盡管這些數據點可能屬于一種非線性的支流形,但對每個點的局部領域范圍內假設為線性流形也是合理的。用公式(3)來計算存在于這些數據點中的結構關系的權重矩陣W,用公式(4)來計算關于降維的投影,用公式(5)依次對各數據點xi進行降維轉換。
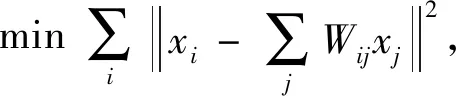
j=1,2,…,k
(3)
X(I-W)T(I-W)XTa=λXXTa,其中X=(x1,…,xk),I=diag(1,…,1)
(4)
yi=ATxi=(a0,a1,…,am-1)Txi,
(5)
其中,yi是一個m維向量。
最初,在一個表情周期下的每條表情特征運動曲線有50個空間采樣點,用NPE方法后,對應的時間序列維數從一個面部表情周期的50維降至24維,且其局部流形結構以優化嵌入的方式在低維空間中得以維持。
2.3 集成分類器SVM+HCRF用于分類所有時間序列
在識別的關鍵環節采用集成隱條件隨機場(HCRF)和支持向量機(SVM)來組建分類器,這種集成分類器同時具有HCRF與SVM的優勢:對每個時間序列以局部特征為條件的隱變量被訓練學習,觀測值不需要條件獨立,可在時空域上重疊[13];分類的最終決策邊界的分類間隔在被稱作特征空間的高維空間中被最大化[14],即這種分類器可解決存在于同一個時間段中的多序列分類問題。具體說明如下:
2.3.1 HCRF用于標記所有時間序列
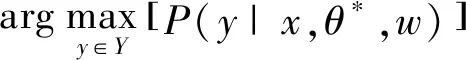
(6)
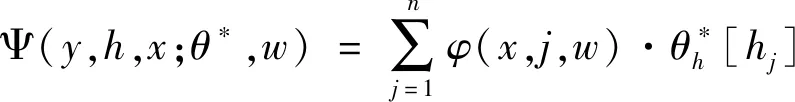
(7);
圖1中,對某第X(X=1,2,…,7)種表情,根據人面部表情中不同的質心點對應不同的運動時間序列,對應第X種表情的所有運動時間序列可以依次標記為:X01A,X01B,X01C,X02A,X02B,X02C,…,X08A,X08B,X08C。
由于所有時間序列彼此關聯,故這些觀測不是條件獨立過程。文獻[13]提出的隱條件隨機場(HCRF)分類方法用中間隱變量來模型化輸入域的潛在結構,并對類標記和以觀測為條件的隱狀態標記定義了一個聯合分布,依賴于由間接圖形關系表達的隱變量,不需要條件獨立,且在時空域中可以重疊,該方法能夠對幀間具有暫態依賴的潛在圖模型關系的序列進行建模,并能夠納入長范圍的依賴關聯,故采用HCRF作為一種描述模式來標記這些序列,且這些序列和對應標記間的映射是通過對HCRF的訓練及推理識別來進行的。HCRF具體方法參見文獻[15],相關公式如式(6)、式(7)所示。
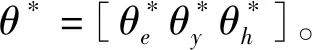
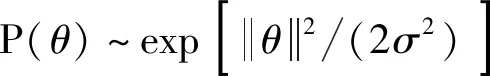
隱狀態的數目設為10,窗參數w依次設為0、1、2來測試對比。在訓練中,對所有的訓練個體的所有表情,人臉每個區域中其質心運動的每個維度的時間序列及對應的標記分別用一個HCRF模型來學習;在推斷中,被測試的序列用來自同樣的臉部區域的產生同種維度的時間序列HCRF模型來判別,具有最大測試概率的類標記則為對應該測試序列的標記。這樣就實現了多特征運動時間序列的標記訓練及標記推斷問題。
2.3.2 SVM用于對多序列的所有標記分類
通過HCRF的訓練,對于一個具體的人面部表情而言,一組標記與其對應的一組運動曲線,即對應的時間序列被用于學習,且這些標記的定義值因表情和面部區域而異,故將這些標記看作是一個具體面部表情的一組特征。但大多數人的表情風格中存在一些相似成分,盡管HCRF能夠在一定程度上克服時空域上的重疊,但在推斷中還可能存在一些表情的某些特征完全相同的情況,此時這些特征部分是重疊的。參閱文獻[14],根據SVM的性質,其決策邊界直接由訓練數據決定,最終決策邊界的分類間隔在被稱作特征空間的高維空間中被最大化,這樣多數在低維空間中不可分的數據映射在高維空間中變得可分。故將與面部表情相關聯的標記特征作為輸入,用SVM作為最終分類手段來識別表情。
分類支持向量機(multi-class SVM)有很多種設計方法。根據文獻[17]的比較測試,1對1(one-against-one)模型方法較適合于實際應用,采用此方法對訓練樣本中的所有類別的各類之間兩兩建立一個SVM模型,用以區別相關聯的兩類樣本,具體如文獻[18]所述,如果數據庫中被訓練的個體種類數量是K,則需要K(K-1)/2個二分類SVM分類器。每個分類器采用具有徑向基函數(RBF)核的C支持向量機(CSVC)模型,其中有兩個參數需要確定,即C和γ,通過平行網格搜索采用典型的交叉驗證法來實現參數選擇,所有K(K-1)/2個決策函數共享相同的參數(C,γ)。
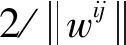
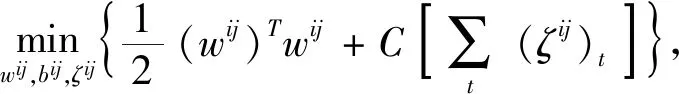
約束條件:
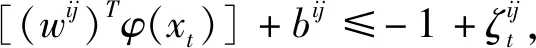
(8)
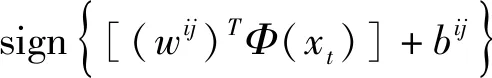
3 實驗測試方案及結果分析
3.1 實驗測試方案
為證明此方法在一般環境下的應用能力,以奔騰1.73 G的個人電腦為平臺,在VC++6.0環境下進行試驗。
面部表情識別框架方法用數據庫the Cohn-Kanade AU-Coded Facial Expression(CKACFE) Database[20]進行測試。該數據庫包含來自97個個體的486個640x480或640x490、8位灰度尺度值的圖像序列。每一個序列開始于一個中值表情,逐漸進入一個峰值表情。每一個序列的峰值表情對應一個情緒標記。每一個個體有至多7種情緒:中性,驚奇,悲傷,厭惡,生氣,恐懼及高興。在實驗中采用留一交叉驗證法(the leave-one-out cross validation)來訓練推斷表情。將第一個人的所有表情用于識別,其余人的所有表情用于訓練;將第二個人的所有表情用于識別,用其他人的所有表情用于訓練。再次改變識別人順序,用其他人的所有表情用于訓練,以此類推,直到所有人的表情都有機會被識別過。計算每種類型表情被成功識別的比率,并把它作為最終結果。計算公式如(9)所示。其中,函數function_infer可以看作是當第i個表情是測試的情緒xi(xi>0) 時,對應相關識別系統(HCRF+SVM)的整體函數,只有在此函數的結果等于輸入xi時,此結果才是正確的。
(9)
其中:δ是單位沖激函數: 若m=0,δ(m)=1 ;否則,δ(m)=0。在對HCRF的訓練中,文獻[16]中的共軛梯度法被用于估計相關參數;在對SVM的訓練中,文獻[18]中通過平行網格搜索的交叉驗證法被用于估計相關參數。試驗中共有97個實驗個體,每個個體有7種表情,每個表情對應8個3D時間序列,則共有8×3=24個HCRF模型和7×(7-1)/2=21個SVM分類器。當對CKACFE數據庫中的表情訓練結束時,HCRF模型與SVM分類器的所有訓練參數也被存儲在另一個數據庫database中。
在進行完相關時間序列的降維后,用暫態數據分別作為單個分類器HCRF及SVM的輸入來直接識別面部表情。在這種情況下,一個HCRF模型對應一種類型的表情,即此時共有7個HCRF模型,SVM分類器的數量與之前設置一樣。在相關訓練結束后也會產生另一個與相關訓練參數有關的數據庫。在同樣的窗口參數w下,將相應的識別結果與本方法的識別率及典型的Kotsia’s method[5]方法進行比較。
3.2 實驗結果及相關分析
圖5為CKACFE數據庫中所有個體不同表情的時間序列分布。不同種類的表情對應不同類型的時間序列分布。這為利用這些時間序列來識別表情提供了很大便利。
圖5 CKACFE數據庫中所有個體不同表情特征的時間序列分布Fig.5 Time series distribution of different facial features of all individuals in CKACFE database
表1給出了集成分類器HCRF+SVM方法與典型的Kotsia方法[5]及單個分類器HCRF/SVM用于表情識別的結果比較,可以看出,本方法的識別率比Kotsia方法更穩定,盡管在少數情況下Kotsia方法比本方法略高一些,但集成分類HCRF+SVM 比單個分類HCRF 或 SVM 的識別率高很多。當用NPE方法對時間序列降維時,相關數據流形的局部臨近結構得到保持;當用HCRF訓練或推斷時間序列標記時,這些在幀間具有暫態依賴的潛在圖模型關系的序列被模型化并納入長范圍的依賴關聯;當用SVM訓練或推斷相關標記的最終表情時,隨著分類數據被映射到高維空間中,相關分類的決策邊界的分類間隔被最大化。這樣與單個分類器HCRF或SVM相比,集成分類器(HCRF+SVM)在處理數據過程中包含了更多待分類數據的結構特征,使得識別更加充分。識別率隨著窗口w的不同而不同,當w等于1時,識別率普遍比其他尺度的窗口要高。從總體效果上看,此識別方法結果是令人滿意的。
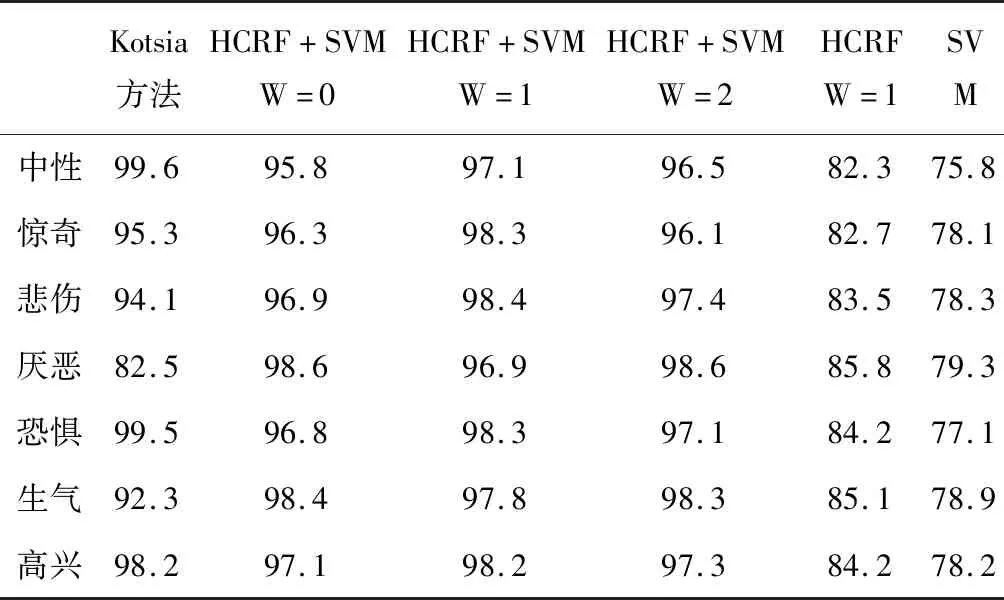
表1 在不同窗口w下與Kotsia方法及單個分類器HCRF/SVM表情識別率的比較Tab.1 Comparison of expression recognition rate with Kotsia method and single classifier HCRF/SVM under different window w
在進行完相關時間序列降維后, 用HCRF的識別率略高于SVM,這是因為HCRF比SVM更適合于分類時間序列,而SVM直接把相關序列作為獨立的參數來處理,是不合理的。無論是用單獨HCRF還是單獨SVM,在不同表情下識別率的變化趨勢與集成分類器HCRF+SVM在總體上是一致的。
4 結論
提出了一個基于集成分類器HCRF+SVM 用于面部表情識別的方法。根據人面部通常的肌肉分布,用面部圖像不同區域的質心作為特征,從人的解剖學結構角度來分析表情。隨著某個基本表情的產生,這些質心在時空中運動形成多個時間序列。用NPE方法對特征序列降維后,這些數據流形的局部臨近結構得以保持。在推斷過程中提出的集成分類器HCRF+SVM包含了數據在時空中更多的結構特征,故試驗測試中相比單個HCRF 或SVM 直接從特征序列的識別獲得了更高的識別率,比典型的Kotsia 方法[5]更加魯棒。
在后續研究中要進一步提高該方法在不同光照及遮擋條件下的魯棒性。用一個數學模型等價代替二級分類集成,直接實現多序列的分類,這樣可有效避免級間分類可能產生的累積誤差,進一步提高識別率。除了本研究測試的數據庫外,也可以通過新的測試將此方法應用于其他數據庫中。為提高方法的實時性,還需引入并行機制,進一步提高算法速度。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
