基于優化YOLOv5s的老人跌倒檢測算法
2023-11-09 01:37:42李春華王玲玲付睿智
河北科技大學學報 2023年5期
李春華,王玲玲,左 珺,付睿智
(1.河北科技大學文法學院,河北石家莊 050018; 2.河北科技大學信息科學與工程學院,河北石家莊 050018;3.河北工業職業大學工商管理系, 河北石家莊 050091)
隨著人口老齡化趨勢的日益加劇,老年群體的健康問題備受關注。跌倒是造成老年人傷害甚至死亡的重要原因,不僅會給老人自身帶來痛苦和困擾,還給家庭、社會和國家帶來了許多影響[1]。為了應對處置這些危險,需要進行快速準確的跌倒檢測。
近年來,隨著深度學習[2]的發展,目標檢測算法取得了重大進展。現有算法可以分為二階段(two-stage)檢測算法和一階段(one-stage)檢測算法2類[3]。二階段檢測算法需要先通過CNN(convolutional neural networks)[4]網絡等方法錨定候選區域(region proposal)[5],再在候選區域上進行分類與回歸。一階段檢測算法有SSD(single shot multibox detector)[6],YOLO(you only look once)[7]等,可以僅使用一個CNN網絡直接預測不同目標的類別與位置,經過單次檢測得到最終的檢測結果。其中YOLO算法提供end-to-end的檢測,即一端輸入原始數據一端輸出最后的結果,檢測速度更快,能實時檢測跌倒行為,快速響應,降低跌倒帶來的損害。由于跌倒行為在不同的環境和姿勢下呈現出多樣性,YOLO算法可能會受到這些變化的影響,導致檢測結果的不穩定性和不準確性。
針對上述問題,提出一種實時準確的跌倒檢測算法,在YOLOv5算法[8]基礎上引入改進的RepVGG模塊,以提高檢測特征的可靠性,采用K-Means++算法聚類優化訓練數據集,以增強分類特征的顯著性。
1 YOLOv5目標檢測優化算法
YOLOv5網絡模仿人體大腦對數據進行學習和分析的過程,通過人工智能網絡訓練,自動提取行為特征,得到模型分類最佳的權重,高效分類跌倒行為和非跌倒行為。在YOLOv5算法中,YOLOv5s模型相對較小,具有參數少和計算量低、檢測速度更快的優勢,所以能夠在資源受限的移動設備上高效運行,以高精度和低成本實現目標檢測任務[9]。改進算法以YOLOv5s為基礎模型并對其進行改進,算法框架如圖1所示。首先,對原始圖像進行填充、自適應錨框預處理等;然后,經過主干網絡的Focus結構和C3卷積網絡進行行為特征提取;再次,基于SPP結構生成分類特征,將Neck頸部層PAN+ FPN[10]的網絡結構與C3_1×N進行特征融合后,在網絡輸出端預測跌倒行為是否發生;最后,篩選出目標框,輸出跌倒檢測結果圖像。
1.1 YOLOv5s網絡模型
YOLOv5s的網絡結構主要分為輸入端、Backbone主干網絡、Neck頸部層、Prediction預測層4個部分。其中Backbone主干網絡又包括Focus,C3和SPP(spatial pyramid pooling)3個模塊[11]。Focus模塊實現了自我復制和切片操作,以減少計算量和加快特征提取的速度,它通過將輸入圖像分割成4個較小的圖像塊,并將它們連接在一起,形成了一個更深的特征圖。在C3模塊中,通過卷積、歸一化和激活操作對輸入圖像進行處理,其中使用了CSP(cross stage partial)殘差結構來優化網絡中的梯度信息,并減少推理的計算量,從而加快網絡的計算速度[12]。CSP結構將特征圖分成2部分,其中一部分進行卷積操作,另一部分直接與卷積結果相加,以增強特征的表示能力。SPP模塊用于解決輸入圖像尺寸不統一的問題[13],通過對輸入特征圖進行空間金字塔池化操作,將不同尺度的特征圖轉換為相同尺度的特征圖,增強目標檢測的能力。頸部層位于主干網絡和預測層之間,主要負責特征融合。YOLOv5s使用了PAN(path aggregation network)和FPN(feature pyramid network)的結構來融合不同層次的特征圖,這種融合方式有助于綜合不同層次的特征信息,提高目標檢測的精度和魯棒性。預測層是YOLOv5s的最后一部分,它分別在網絡的第18層、21層和24層作為輸出端進行預測,這些預測層會產生大量的預測框,并通過非極大值抑制(NMS)[14]篩選目標框。
1.2 YOLOv5s網絡模型的改進
復雜應用場景下,傳統的YOLOv5模型易出現漏檢和錯檢的問題,檢測精度不高。在YOLOv5s模型的基礎上,一方面在Backbone主干網絡添加RepVGGs模塊,以便增強目標特征提取能力,降低復雜背景的干擾;另一方面改進損失函數,實現對High IoU(high intersection over union)目標高精度的回歸。改進后的網絡結構如圖2所示。
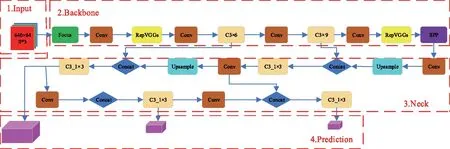
圖2 改進后的YOLOv5s網絡結構Fig.2 Improved YOLOv5s network architecture
1.2.1 引入RepVGGs模塊
RepVGGs[15]是一種簡單而有效的卷積神經網絡結構,RepVGG模塊如圖3所示。它的主要特點是采用了重復使用的塊結構,其中每塊由一個或多個3×3卷積層和ReLU激活函數組成。每個塊與一個1×1卷積層并行處理,用于調整通道數。通過這樣的設計,RepVGG塊可以在保持較少參數的同時,提供更豐富的特征表示能力。RepVGG還引入了一種與ResNet[16]類似的設計思想,即引入shortcut連接。這些shortcut連接通過跳躍連接的方式,將輸入直接連接到輸出,能夠捕獲更豐富的特征。這種設計使得RepVGG可以在更深的層次上學習和利用信息,增強了模型的表示能力,特別適用于在GPU和專用推理芯片上進行高效的目標識別和分類任務。
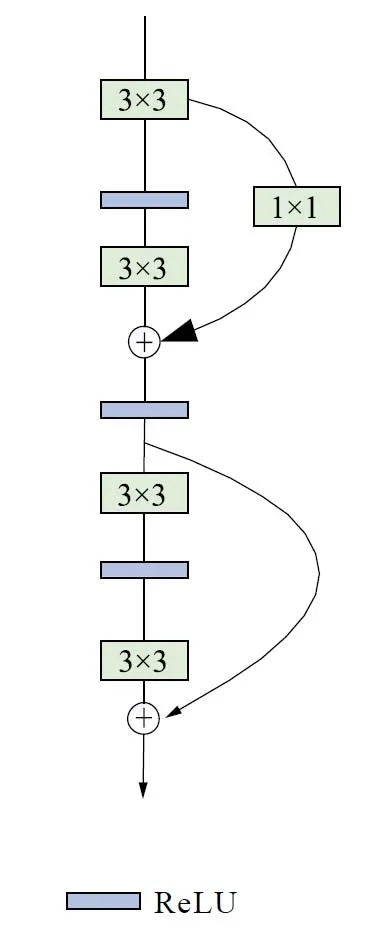
圖3 RepVGG模塊示意圖Fig.3 Schematic diagram of RepVGG module
RepVGG采用的ReLU激活函數可能出現梯度消失的問題,導致在訓練過程中無法進行有效的權重更新。因此提出的算法在RepVGG的基礎上進行改進,使用SiLU激活函數代替ReLU函數,如圖4所示。
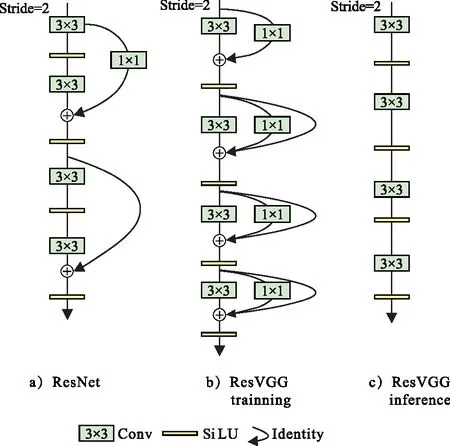
圖4 改進RepVGG模塊示意圖Fig.4 Schematic diagram of improved RepVGG module
相較于傳統的ReLU激活函數,SiLU具有更加平滑的特性,在整個輸入范圍內都具有連續的導數,這有助于更好地傳播梯度和提高模型的訓練效果,減輕梯度消失問題,并且SiLU的平滑特性有助于更好地保留和融合特征信息,提高了網絡的表示能力和學習能力[17]。這種改進可以幫助模型更好地捕捉和利用特征之間的相關性,從而提高目標檢測的準確性和魯棒性。
改進后的RepVGG模塊結合了多分支模型訓練的優勢和單路模型推理的高效。在模型訓練階段,多分支殘差結構使得網絡具有多條梯度流通路徑,從而提高訓練的精度和速度,實驗結果表明,精確率提高了0.83%。
1.2.2 改進損失函數
損失函數是衡量模型預測結果準確性的一種方法。早期損失函數主要用于邊界框回歸,然而隨著目標檢測方法的發展,近年來更多地采用IoU作為定位損失。IoU損失是一種衡量預測框與真實框重疊程度的指標。它通過計算預測框和真實框的交集面積與并集面積之比評估定位的準確性。當預測框與真實框不重疊時,IoU損失梯度消失接近于0,無法提供足夠的更新信號來調整模型的參數,導致模型收斂減慢。由此也就激發了幾種改進的基于IoU的損失函數,為了解決當IoU Loss恒等于0時,梯度恒為0,導致無法反向傳播的問題,REZATOFIGI等[18]提出了GIoU Loss。ZHENG等[19]認為衡量預測框的好壞應該考慮預測框與真實框的中心點距離以及長寬比之間的差異等因素,于是提出了DIoU和CIoU。然而它們都無法對High IoU的目標實現高精度的回歸,因此本文使用損失函數Alpha IoU Loss[20],通過引入power變換,將現有的基于IoU的損失函數(包括GIoU,DIoU和CIoU)綜合到一個新的power IoU損失函數中,以實現更準確的邊界框回歸和目標檢測效果。實驗結果表明,通過調整損失函數中的超參數α,可以有針對性地增加High IoU目標的損失和梯度,從而提高邊界框回歸精度。
Alpha IoU Loss的定義為
(1)
加入懲罰項時,上述公式可以擴展到更加一般的形式:
lα-IoU=1-IoUα1+pα2(B,Bgt) ,
(2)
式中:α-IoU可以通過壓縮表示出GIoU,DIoU,CIoU。實驗結果表明,參數α(α>1)增加了High IoU目標的損失和梯度,進而提高了bbox回歸精度。為了提高High IoU 目標的回歸精度,本文使用Alpha IoU Loss代替CIoU Loss,經過實驗測試表明,α參數為3取得的效果最好,并且精確率較改進前提高了0.56%。
1.3 基于K-means++聚類算法的錨框優化
在訓練時,YOLOv5s采用K-means算法對COCO數據集進行聚類預處理并生成目標物體的錨框。K-means算法雖然簡單,易于實現,但在聚類之前需要自主選擇初始化的k個樣本作為初始聚類中心,這些初始中心是需要人為確定的,并且在實際應用過程中不同的初始聚類中心可能導致完全不同的聚類結果。當k值較小時,K-means算法產生的錨框的值較大,容易導致模型無法定位較小的目標;當k值較大時,運算量增大降低效率。
確定合適的錨框大小是實現高精度檢測的前提,由于K-means算法的初始化樣本數量難以預見,影響預測模型性能。因此,采用K-means++算法對所用數據集進行聚類優化,以獲取適合不同尺寸的目標物體的錨框。K-means++算法的聚類中心通過“輪盤法”生成,輪盤法的基本思想是將一系列對象(通常是候選解或個體)與一個帶權重的輪盤相聯系,其中每個對象的權重與其被選擇的概率成正比,可以克服K-means的不足,更好地選擇初始化聚類中心,提高聚類的質量和穩定性。K-means++算法步驟如下。
1) 在數據點中隨機選擇一個中心點mi。
2) 使用歐式距離平方計算其余采樣點x與中心點mi的距離D(x):
(3)
3)分別計算每個采樣點成為新聚類中心點的概率,選取概率值最大的點成為新的聚類中心。
4)重復步驟2)和步驟3),直到選出k個初始聚類中心點,對于每個初始聚類中心點i∈{1,2,…,k},定義最近點集M并更新M集的質心。
K-means++聚類優化算法對比實驗結果,如圖5所示。圖5 a)為K-means算法檢測得到的目標物體的錨框,尺寸為[23,22,17,27,32,23],[39,71,77,51,60,114],[129,93,197,244,403,239],相對于目標對象偏大;圖5 b)為K-means++算法檢測得到的目標物體的錨框,尺寸為[8,24,10,45,14,34],[20,55,23,80,26,38],[38,68,59,112,98,198],錨框縮小,較為準確地框定目標對象。

圖5 聚類對比結果圖Fig.5 Cluster comparison result graph
2 實驗設計
2.1 數據集
實驗中使用的數據集分為2類,一類選取通用數據集UR-Fall-Detection和Le2i Fall Detection Dataset中的跌倒圖像,共3 500多張圖片;另一類為自建數據集,從網絡收集跌倒圖片進行創建,共500多張圖片。圖片分為2個子集:訓練集和測試集,其中訓練集占總數的92%,測試集占總數的8%,數據標注格式統一為VOC數據格式,標注了人體框的3個姿態:up(站立)、bending(彎腰,蹲下)和down(躺下)。
2.2 評估標準與實驗環境
實驗訓練環境和框架等具體配置如表1所示。實驗使用YOLOv5s優化算法進行訓練,訓練迭代輪數epochs=200,batchsize=4,輸入圖像大小為640×640。為了客觀評價提出網絡模型的性能,使用精確率(precision,P)、召回率(recall,R)、平均精度(average precision,AP)、平均精度均值(mAP),計算公式如下:

表1 實驗環境配置Tab.1 Experimental environment configuration
(4)
(5)
式中:TP(true positives)表示正確識別為正樣本的正樣本數量;FP(false positives)表示錯誤識別為正樣本的負樣本數量;FN(false negatives)表示錯誤識別為負樣本的正樣本數量;N表示目標類別的數量;AP表示IoU閾值為0.5情況下模型的檢測性能,代表P-R曲線與坐標系圍成的面積,AP值越高,表明模型越準確地檢測出目標;mAP表示各類別AP的平均值,該值越高網絡性能越好。
2.3 消融實驗設計
為了更充分地分析所提的K-means++聚類錨框、改進RepVGG模塊、Alpha IoU Loss對最終模型檢測的貢獻度,設計了7組消融實驗,系統分析每個改進部分對最終跌倒檢測算法的影響,從而更全面地評估優化算法的有效性和優勢。
2.4 對比實驗設計
為了驗證所提方法的有效性和可靠性,本文將模型的檢測結果與目前一些主流的深度學習算法—YOLOv3算法、YOLOv4,YOLOv5s和CBAM-YOLOv5s算法[21]進行對比分析。
3 結果分析
3.1 消融實驗結果分析
實驗結果如表2所示。由表2可知,基準模型YOLOv5s添加RepVGGs模塊和K-means++聚類后,精確率提升了1.49%,mAP0.5值提升了1.57%,mAP(0.5~0.95)值提升了1.27%;基準模型YOLOv5s添加RepVGGs模塊和Alpha IoU Loss后,精確率提升了1.02%,mAP0.5值提升了1.17%,mAP(0.5~0.95)值提升了1.08%。相較于基準模型,本文算法精確率提升了2.36%,mAP0.5值提升了1.84%,mAP(0.5~0.95)值提升了4.68%。綜上可知,提出的3種改進方式均能夠提升模型的性能,同時與基準模型或者使用任一種以上模塊的模型相比,使用本文所提出的完整模型性能最優,檢測效果最好。
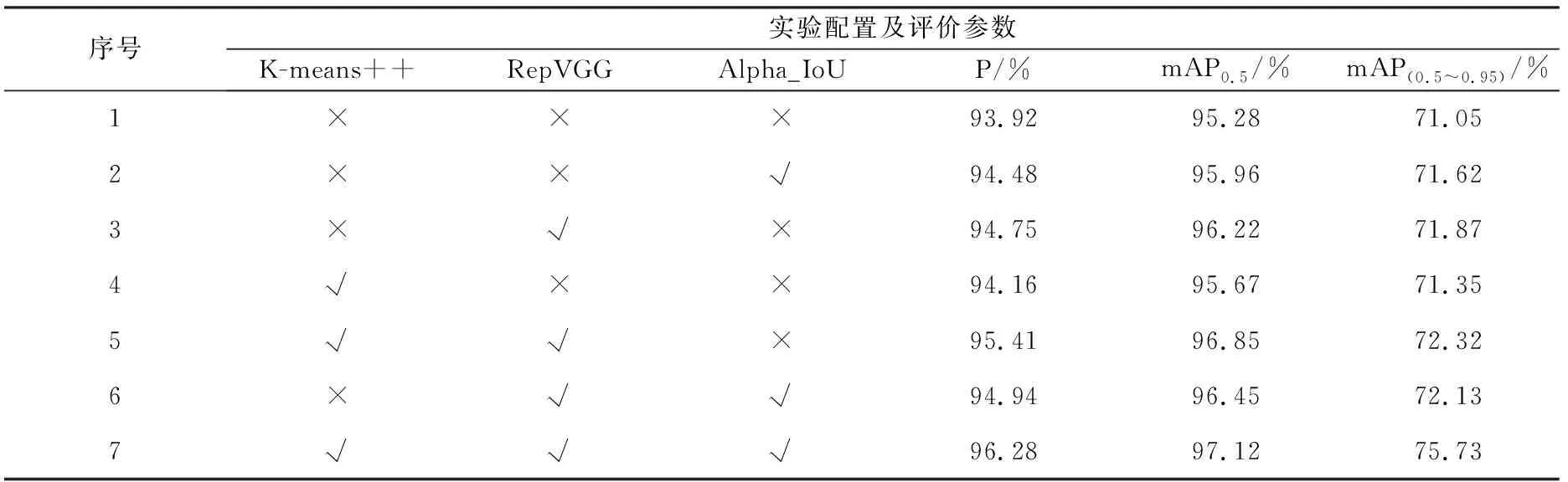
表2 消融實驗結果Tab.2 Ablation experiment result table
3.2 對比實驗結果分析
對比結果如表3所示。由表3可知,所提YOLOv5s優化模型相較于其他模型檢測效果最好。其中P比YOLOv3,YOLOv4,YOLOv5和CBAM-YOLOv5s分別提高了8.75%,8.02%,2.96%和1.12%;R比YOLOv3,YOLOv4,YOLOv5和CBAM-YOLOv5s分別提高了7.55%,7.31%,2.19%和1.60%;mAP0.5比YOLOv3,YOLOv4,YOLOv5和CBAM-YOLOv5s分別提高了8.07%,7.09%,1.84%和0.70%;mAP(0.5~0.95)比YOLOv3,YOLOv4,YOLOv5和CBAM-YOLOv5s分別提高了7.26%,6.40%,4.68%和3.15%,各項指標顯著高于其他模型。優化算法的訓練時長為10.5 h,模型大小為15.4 MB,由于引入新的網絡模塊,網絡變得更深且參數更多,相較于 YOLOv5s算法,訓練時間和模型大小略微增加。
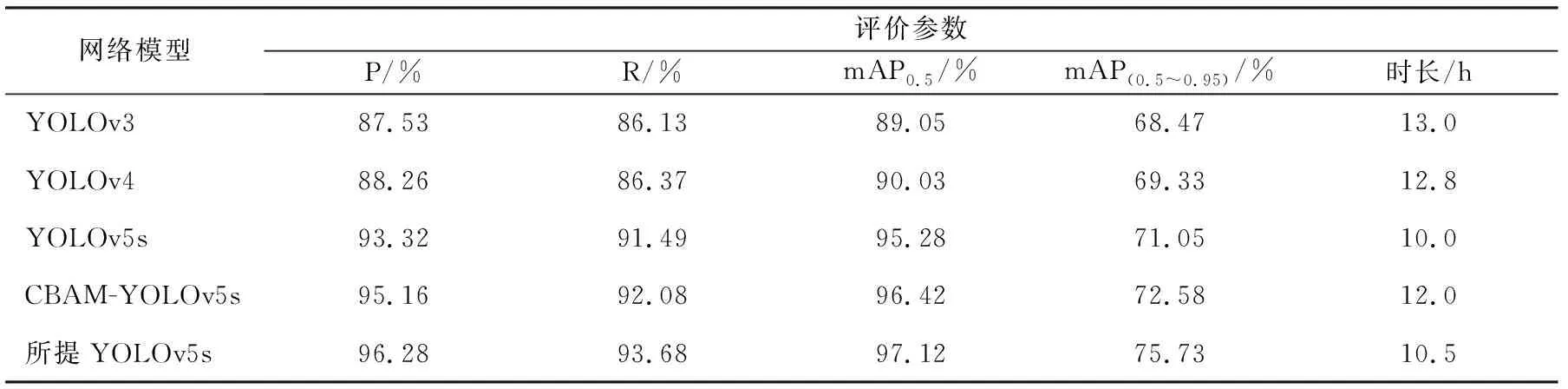
表3 不同模型實驗結果對比表Tab.3 Comparison table of experimental results of different models
3.3 應用場景實驗結果分析
使用網上隨機選取場景下老人跌倒情況的視頻或者圖片作為測試樣本,分單目標和多目標2種情況測試檢測算法的性能,檢測結果分別如圖6和圖7所示。所提算法標注了人體框的3個姿態,其中跌倒狀態單目標和多目標的平均置信度為92.2%,明顯優于其余4類算法的80.4%,84.5%,88.2%,90.5%。可見,所提算法在不同場景下的檢測性能均得到改善,魯棒性得到提升。

圖6 家庭場景模型檢測結果Fig.6 Home scene model detection results

圖7 通用場景模型檢測結果Fig.7 Generic scenario model detection results
3.4 模型評估結果分析
最終的模型評估結果如圖8所示。經過200輪(epoch)的模型訓練,模型精確率達到97%;整個訓練過程中,R和mAP0.5持續提升,并逐漸接近于100%。在RTX 3090(24 GB) ×1上,識別速度達到30幀/s,能夠較好地滿足實時檢測的要求。
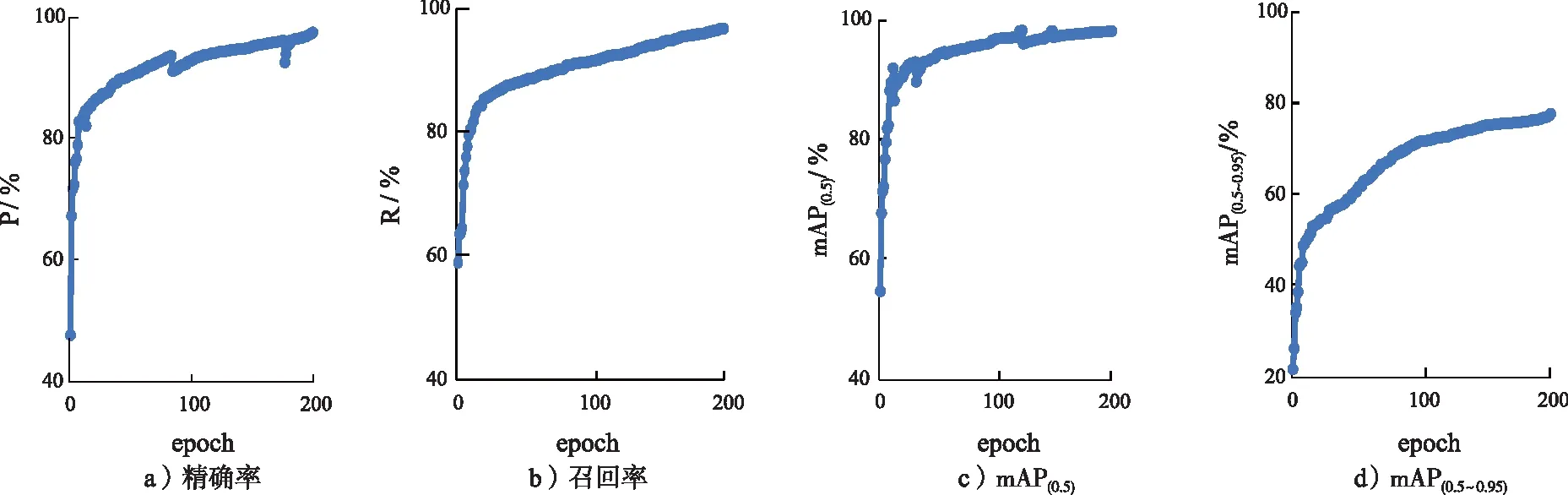
圖8 模型評估結果Fig.8 Model evaluation results
所提YOLOv5s改進模型的P-R曲線如圖9所示。通過P-R曲線,可以得出以下結論。在大部分情況下,綠色曲線(down)更接近坐標(1,1)的位置,相比于淺藍色曲線(up)和黃色曲線(bending),綠色曲線表示的類別更具準確性。同時,深藍色曲線表示的所有類別的mAP也高于up類別曲線和bending類別曲線,這表明改進后的YOLOv5s模型顯著提升了檢測準確性。圖10為改進后的算法與其他4類算法在訓練時的mAP對比。從圖10可以清楚看出,改進后模型的檢測精度優于其他4個模型,且有了顯著的提升,取得了更好的檢測效果。
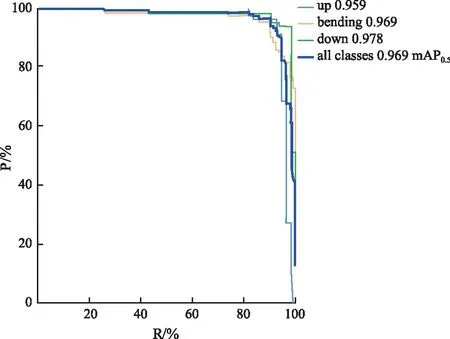
圖9 改進YOLOv5s算法的P-R曲線Fig.9 Improved the P-R curve of YOLOv5s algorithm
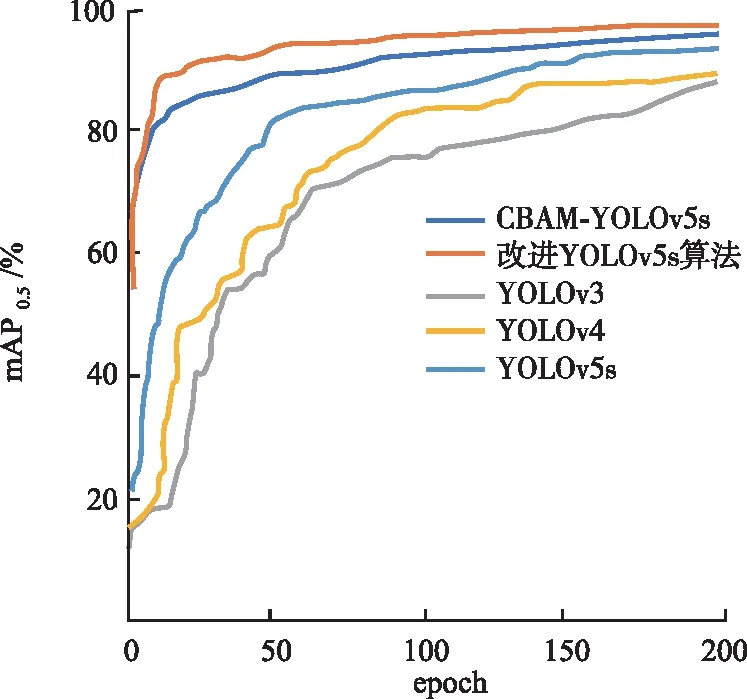
圖10 改進YOLOv5s與其他算法訓練時mAP對比圖Fig.10 Comparison of mAP during training between the improved algorithm and other algorithms
4 結 語
為了改善YOLOv5s算法在人體跌倒檢測方面仍存在實時性和準確性較差,不同場景易出現誤判和漏檢的情況,所提算法針對YOLOv5s在特征提取等部分存在的不足進行了改進,使用K-means++算法對所用數據集進行聚類優化,改進損失函數,使得模型更關注于高質量的正樣本信息,因此提升了檢測精度和檢測速度。結果表明,所提算法的準確率高于YOLOv5s算法,能夠滿足現實中不同場景對老人跌倒行為的檢測需求,可以應用于移動設備或者監控設備中,完成跌倒檢測和報警工作。但所提算法在檢測人物出現遮擋或者光線較暗情況下的檢測效果還需進一步研究。今后將致力于提升算法對遮擋人物和光線情況下的魯棒性研究,以便能夠適用更加復雜的檢測場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
