基于直方圖分析和自適應遺傳的雷達道路目標識別特征優選方法
2023-11-06 08:57:58瓦其日體趙志純則正華
雷達學報 2023年5期
瓦其日體 李 剛 趙志純 則正華
①(清華大學電子工程系 北京 100084)
②(深圳北理莫斯科大學 深圳 518172)
③(廣東省智能感知與計算普通高校重點實驗室 深圳 518172)
1 引言
近年來,毫米波雷達因其能夠穿透雨、霧、煙、灰塵,不受光照條件影響而全天時、全天候工作[1],同時還具有體積小、重量輕、空間分辨能力高[2]等優點而受到道路運動目標識別領域的廣泛關注。道路目標的運動特性使同一目標的不同散射點的距離和速度信息更容易被毫米波雷達觀測到,因此距離多普勒(Range-Doppler,RD)譜被廣泛應用于雷達道路目標識別領域[3]。在得到目標的RD譜之后,提取和目標相關的微動和微距特征對目標進行有效識別。雷達目標識別領域特征提取時可依據自動和手動分為兩類,自動特征提取一般是將RD譜、合成孔徑雷達(Synthetic Aperture Radar,SAR)圖像等直接輸入到神經網絡中從而獲得大量的特征,比如文獻[3]提出了一種融合卷積神經網絡和長短時記憶網絡的方法對RD譜進行特征提取從而完成對人體跌倒的檢測。文獻[4,5]利用深度學習方法對海上艦船的SAR圖像進行檢測識別,實驗表明RetinaNet及其改進的網絡是近年來雷達目標識別領域深度學習方法中性能較好的網絡之一。文獻[6]則將RD譜和改進的RetinaNet網絡相結合,對自行車、汽車、行人和貨車等道路目標進行分類識別,實驗表明相比于VGG16+FPN+BN+data enhancement,ResNet50+FPN+BN+data enhancement,ResNet101+FPN+BN+data enhancement等5種網絡,改進RetinaNet的識別性能最優。雖然深度學習網絡能夠自動提取特征,但它們對抽象特征和大數據集的過度依賴,完全舍棄了傳統成熟的手動特征,給特定目標的針對性學習以及識別準確性的進一步提升帶來限制[7]。而手動特征提取通過充分利用目標的先驗信息,對目標的RD譜分布進行統計分析提取具有針對性的特征,從而達到對特定目標分類的效果。比如文獻[8]通過對RD譜提取散射點個數、目標散射點占距離單元個數、目標散射點占速度單元個數等特征完成對行人和汽車的有效識別。文獻[9]通過對RD譜提取徑向速度、距離維峰值信號方差和速度維峰值信號方差等特征完成對行人、橫向汽車以及縱向汽車的分類。上述方法利用較少數量的特征完成了對目標的有效識別,但是在目標種類多變且目標特性相近時,上述方法的性能受限。針對上述問題,通過增大特征數量來提高識別性能是一個常用的有效方法。然而特征維數的增多,不但會造成維數災難[10],有時甚至會因為特征向量包含有和目標無關的信息導致識別性能降低[11]。因此,從所提取的高維特征集中進一步優選得到使識別性能更高的特征組合,就顯得尤為重要。
目標識別領域的特征選擇方法一般可分為過濾法和包裝法[12]兩類,其中過濾法是根據信息論[13]、主成分分析(Principal Component Analysis,PCA)[14]等特定的統計標準對特征進行排序[15],之后選取前N維特征作為新的特征集從而達到特征優選的目的。文獻[16]針對人體目標識別中人體微多普勒特征的優選問題,提出用互信息計算特征的貢獻值作為特征的物理相關性和估計質量的函數,從而對特征重要度進行排序,實現了特征優選和對人體運動狀態的有效識別。文獻[17]針對5類飛機目標的分類識別問題,通過利用PCA對波形熵、中心矩和信號幅度方差等特征進行降維,該方法雖然特征選擇時效較高,但是特征評估函數與學習器相互獨立,導致目標總體識別率不高。過濾法具有計算量小、特征選擇時效較高的優點[18],但是由于此類方法的特征選擇操作和后續的分類模型是相互獨立的[19],往往使得分類性能受限。包裝法則依賴于機器學習,利用篩選后的特征子集訓練分類器,根據驗證樣本在分類器中的學習性能來評價特征子集的優劣[12]。遺傳算法(Genetic Algorithm,GA)是最常用的包裝式特征選擇算法之一,文獻[20]針對極化合成孔徑雷達(SAR)圖像分類提出了一種基于GA特征選擇的分層分類算法,得到了更好的識別效果。文獻[21]首次將GA應用于SAR圖像的特征選擇中,用GA和貝葉斯鑒別器得到最優特征組合。文獻[22]提出了一種基于GA的SAR圖像監測系統,用于洪澇災害的檢測。但是當特征維數增多時,特征組合數呈指數型增長,導致GA隨機搜索時無法快速收斂獲得最優解[23],這一缺陷限制了GA在高維特征集中特征選擇領域的應用。針對這一問題,文獻[24,25]提出了一種PCA和GA相結合(PCA-GA)的特征選擇算法,先利用PCA算法對原始特征集進行降維,將降維后的特征輸入到GA加快特征選擇算法的收斂速度。然而該算法在特征集預降維階段僅考慮了特征間的相關性,未對特征組合與目標類別的匹配度進行考慮,從而使得識別性能受限。文獻[26,27]提出了一種基于ReliefF的改進自適應遺傳(ReliefF-IAGA)特征選擇算法,該算法首先使用ReliefF算法獲得特征重要性得分,并消除不相關的特征,接著利用自適應遺傳算法(Adaptive Genetic Algorithm,AGA)得到優選特征子集。文獻[28]提出了基于信息增益(Information Gain,IG)和GA (IG-GA)的特征選擇方法,首先利用IG得到每個特征的信息增益值作為預降維依據,設定閾值對待選特征集進行預降維后利用GA得到最終的特征子集。然而上述方法在預降維階段僅考慮了單個特征與目標類別的相關性或者信息增益,忽略了特征組合與目標類別的相關性,導致優選后的特征組合對目標類別的區分度有限。
針對該問題,本文通過在自適應遺傳算法框架中引入直方圖分析[29]考慮不同特征組合與目標類別的相關性,提出了一種基于直方圖分析和自適應遺傳(Adaptive Genetic Algorithm via Histogram Analysis,HA-AGA)的雷達道路目標識別特征優選方法。該算法首先通過AGA迭代搜索得到由各代平均F測度最高的特征組合構成的特征組合庫,接著引入直方圖分析統計該特征組合庫中各特征的分布頻次。頻次較高的特征構成的特征組合與目標類別匹配度更高,因此選取頻次最高的K維特征輸入到AGA優選出使目標識別精度更高的特征組合。基于毫米波雷達實測數據集和公共數據集CARRADA[30]上的實驗表明,與PCA-GA[24,25],ReliefF-IAGA[26,27],IG-GA[28]3種方法相比,本文提出的方法選出的特征組合與目標類別相關度更高,能夠得到更高的識別準確率。
2 自適應遺傳算法
自適應遺傳算法[26]是對傳統遺傳算法[31]的遺傳操作步驟進行改進得到的具有隨機搜索特性的優化方法,具體算法流程如下:
步驟1 參數初始化。將待優選特征集中的各特征組合以“基因”的形式編碼成染色體x。編碼規則可根據實際情況選擇二進制編碼、浮點數編碼以及符號編碼等方式。隨機生成M條染色體組成初始種群W1={x11x12...x1M},染色體xij表示第i代的第j個特征組合。
步驟2 搜索迭代。假設迭代i-1次后得到第i代種群Wi={xi1xi2...xiM},為判斷第i代種群Wi里各特征組合的優劣,并給接下來的自適應遺傳操作提供依據,由式(1)計算每個特征組合的適應度:
其中,操作 F是將該特征組合輸入到機器學習分類器后得到相應的適應度fitnessij,對Wi中的每一個特征組合都計算適應度后得到第i代種群的適應度向量FITi=[fitnessi1fitnessi2...fitnessiM]。接著對Wi進行雙重輪盤賭選擇,將Wi={xi1xi2...xiM}中所有染色體根據適應度向量FITi從大到小進行排序得到={yi1yi2...yiM},染色體yij被選擇的概率為
得到={yi1yi2...yiM}中所有染色體被選擇的概率后,將[0,1]根據中每條染色體被選擇的概率分成M段,接著隨機生成M個[0,1]之間的數,染色體被選擇的概率越大,對應的區間長度越長,隨機產生的數字落入該區間的概率越大,統計落在各個片段的數量,并選擇數量最多的片段對應的染色體zi1存入種群,則適應度越大的染色體被選中的概率越大。重復選擇直到=M,選擇完成后得到={zi1zi2...ziM}。然后進行自適應交叉,對于Wi′′中的染色體zij(j依次取1,2,···,M),在里剩下的染色體中隨機選取另一條染色體zim(m=j),從zim中隨機選取一個基因與zij中相同位置的基因以概率Pc進行互換得到新的染色體vij,遍歷所有染色體得到={vi1vi2...viM}。最后進行自適應變異,對于中的染色體vij(j依次取1,2,···,M),隨機選取某個基因以概率Pm進行突變得到新的染色體,遍歷所有染色體后得到下一代種群Wi+1。其中自適應交叉概率Pc和變異概率Pm為
其中,Pa0為設定的初始交叉或變異概率,fitnessj(j=1,2,···,M)為各染色體對應的適應度,fitnessmax為當代最優適應度,fitnessavg為當代平均適應度。
步驟3 重復步驟2直到進化代數達到預設的最大代數I。當迭代結束后適應度最高的特征組合即為最終選擇結果。
3 基于直方圖分析的改進自適應遺傳特征優選方法
3.1 RD譜特征集的構建
為對道路目標進行有效識別,本文所提方法對目標RD譜中的散射點分布特點進行統計分析提取波形熵、能量密度等30個特征構建RD譜特征集。在特征提取之前需要對雷達回波數據進行預處理得到只包含單個目標信息的RD譜,具體處理流程如圖1所示。在得到雷達回波后首先進行2DFFT得到原始RD譜[3],接著將RD譜中徑向速度小于某個預設的速度參數值v的速度單元置零,去除靜止或者低速度雜波。然后運用2D-CFAR算法進行目標檢測,去除其他噪聲從而得到只包含目標信息的RD譜。最后判斷目標個數,若為單個目標,則直接得到只包含單個目標信息的RD譜;若為多個目標,則利用DBSCAN算法對不同目標的特征數據進行切割,得到只包含單個目標信息的RD譜,并根據雷達回波對應的光學視頻對RD譜中的目標進行區分和標注。預處理完成后,根據RD譜中散射點的分布特點,分別從RD譜的距離維、速度維和距離速度兩維聯合分布進行統計分析提取平均距離、平均速度、能量密度、波形熵等30個特征構建高維特征集F=[f1f2...f30],如表1所示。其中,s表示RD譜的散射點個數,ri,vi和Ai(i=1,2,...,s)分別表示每個散射點對應的距離、速度和幅值,N ×M為RD譜的尺寸,A(n,m)表示位于(n,m)點的散射點幅值,Ag(g=1,2,...,G)表示每個距離單元(或速度單元)里幅值最大的散射點的幅值,G表示某個目標的RD譜中散射點占據的距離單元(或速度單元)個數,,表示距離(或速度)維峰值點所占的比重,AG=表示距離(或速度)維平均幅值,表示該點幅值占所有點幅值中的比重,和分別表示距離維方向和速度維方向上的質心,Ai表示所有散射點的平均幅值。峰值點及其周圍T個點均為主分量,剩下的點為副分量。
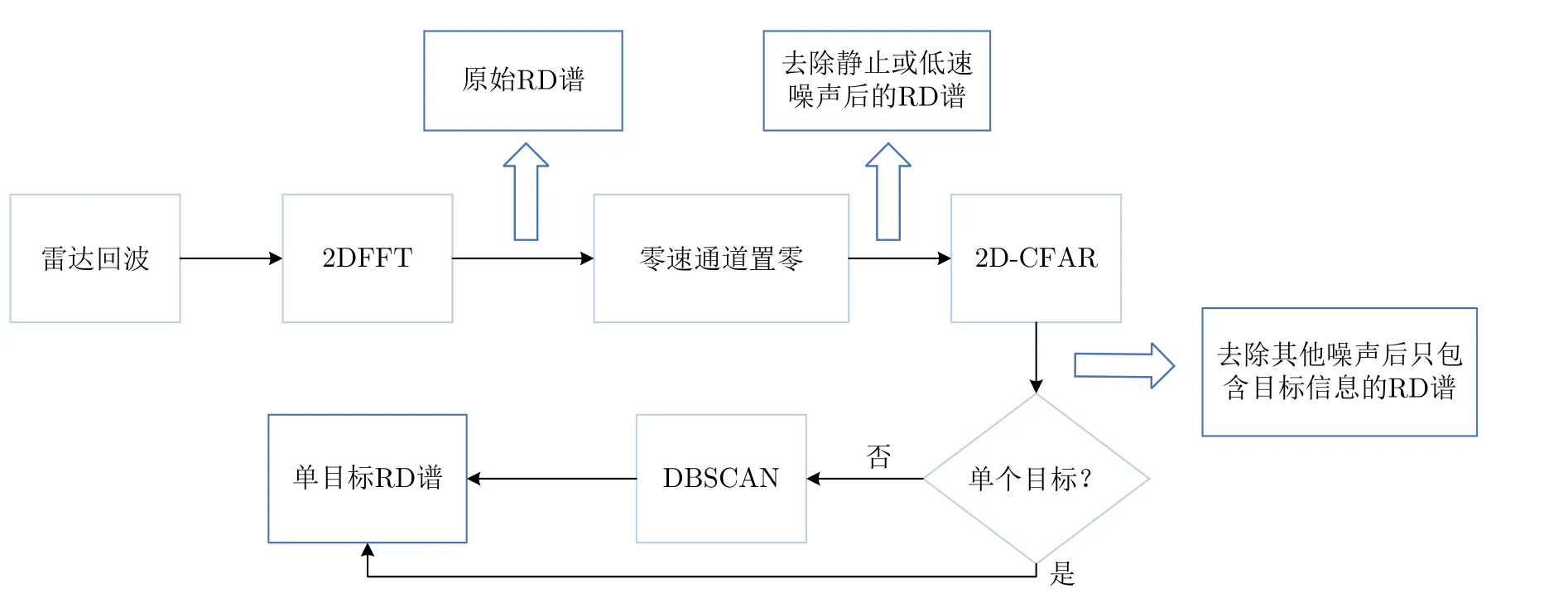
圖1 數據預處理流程圖Fig.1 Data preprocessing flow chart
3.2 基于直方圖分析的特征優選
為了加快AGA的收斂速度,通過充分考慮不同特征組合與目標類別的匹配度對待選特征集進行預降維并保留與目標類別相關度較高的特征組合。該方法具體流程如圖2所示,描述如下:
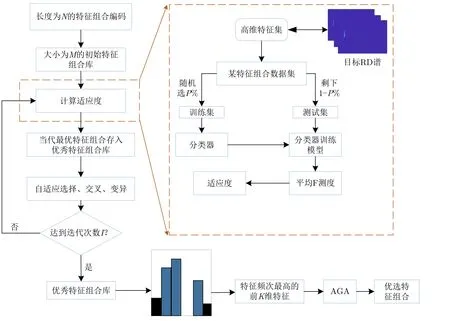
圖2 基于直方圖分析的特征優選流程圖Fig.2 Flow chart of feature optimization via histogram analysis
步驟1 根據AGA算法對特征組合進行編碼,本文采用的編碼方式為二進制編碼,假設待選特征集F=[f1f2...fN]總共有N個特征,則編碼后的特征組合x由N個“0”,“1”構成,且“0”,“1”的組合形式由特征組所包含的特征編號決定,比如x為“0101100”,代表該特征組合由第2號、第4號和第5號特征組成。編碼完成后,隨機生成M個特征組合作為接下來進行搜索迭代的初始特征組合庫F1={x11x12...x1M},其中xij表示第i代的第j個特征組合編碼之后的染色體。
步驟2 迭代搜索優秀特征組合庫。假設迭代i-1次后得到第i代特征組合庫Fi={xi1xi2...xiM},為對Fi中的每個特征組合的優劣提供評價指標,給各代最優特征組合的選擇提供依據,進行特征組合適應度的計算。假設所有目標同等重要,且本文所提算法旨在優選出使目標識別性能更好的特征組合,因此將xij對應的數據集按一定比例隨機分成訓練集和測試集,對分類器進行訓練和測試后分類器輸出的平均F測度作為該特征組合的適應度fitnessij,平均F測度的計算公式為
其中,T為目標種類數,Pm=TPm/(TPm+TNm)和Rm=TPm/(TPm+FNm)分別為第m類目標的精確率和召回率。TP,TN和FN分別為真正例、真反例和假反例[32]。適應度越高,則該特征組合與目標類別的匹配度越高,識別性能越好。對Fi中的所有特征組合依次計算適應度得到Fi相應的適應度向量FITi=[fitnessi1fitnessi2...fitnessiM],根據FITi找到Fi中適應度最高的特征組合xib,將其存入優秀特征組合庫Fbest中。存儲完成后,通過對Fi依次進行雙重輪盤賭選擇、自適應交叉和自適應變異3個步驟得到下一代特征組合庫Fi+1,再對Fi+1重復執行以上操作,不斷地進行迭代搜索直到迭代次數達到預設的最大迭代次數I。迭代終止后,輸出迭代I次得到的優秀特征組合庫Fbest={x1bx2b...xIb}。
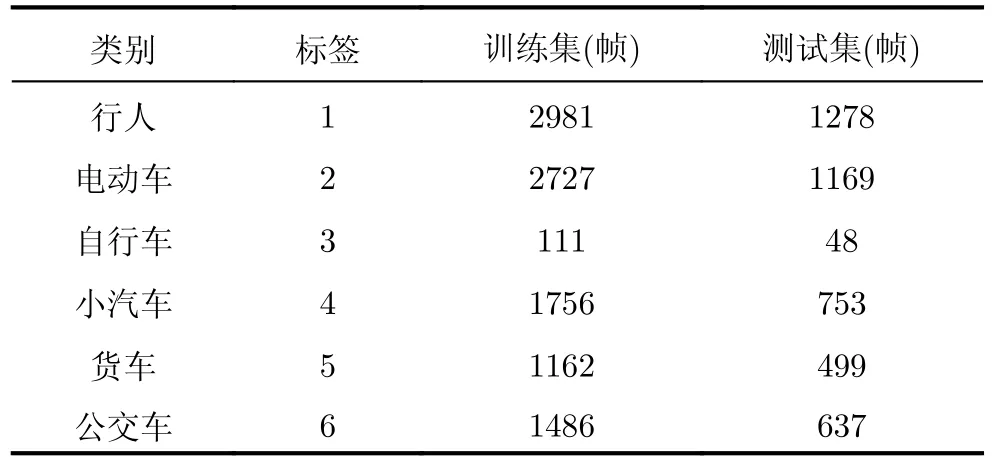
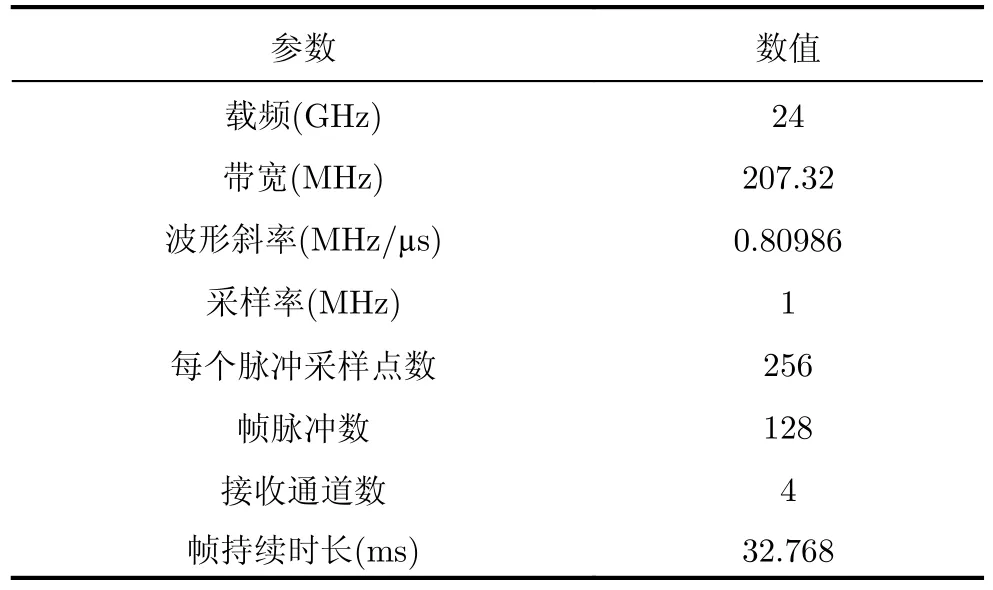
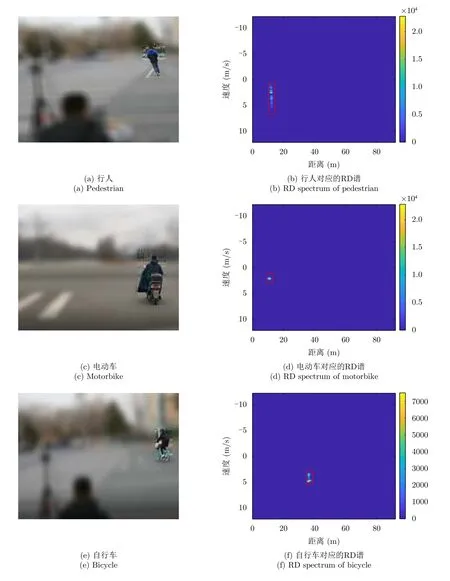
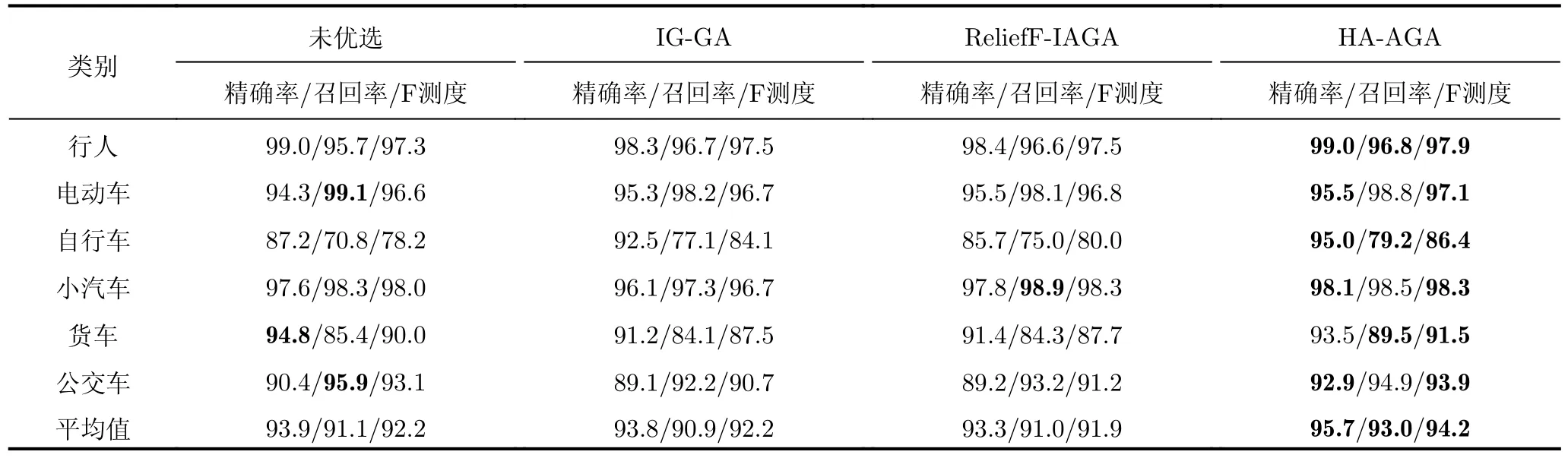
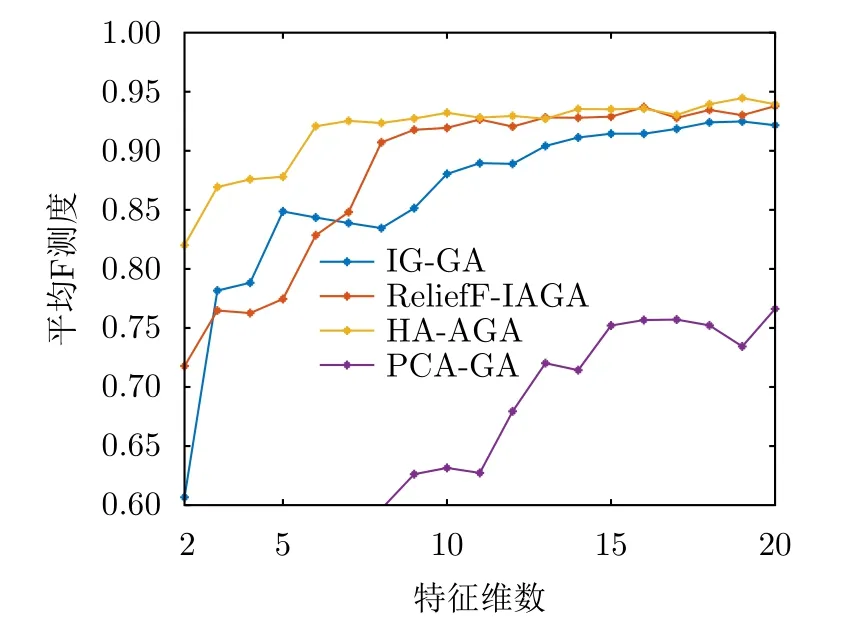
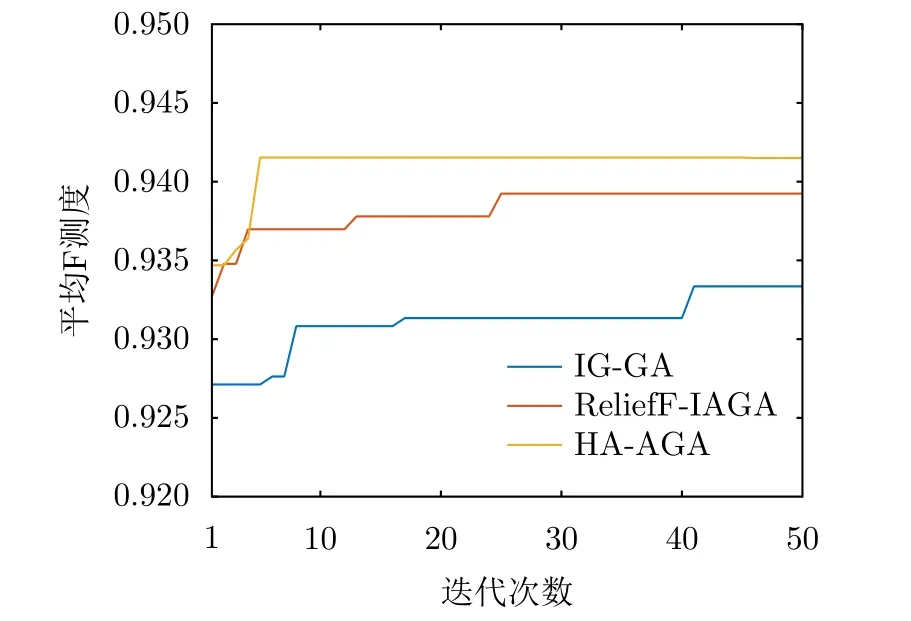
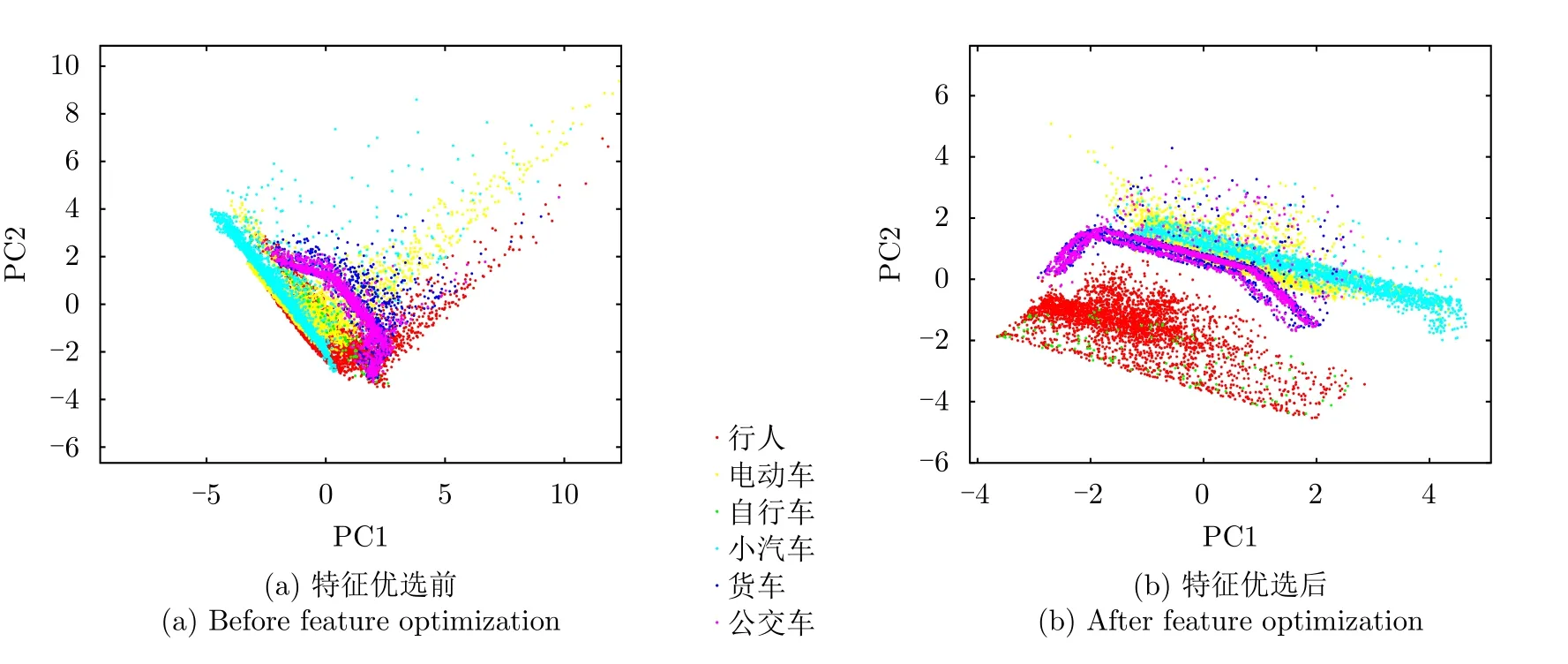
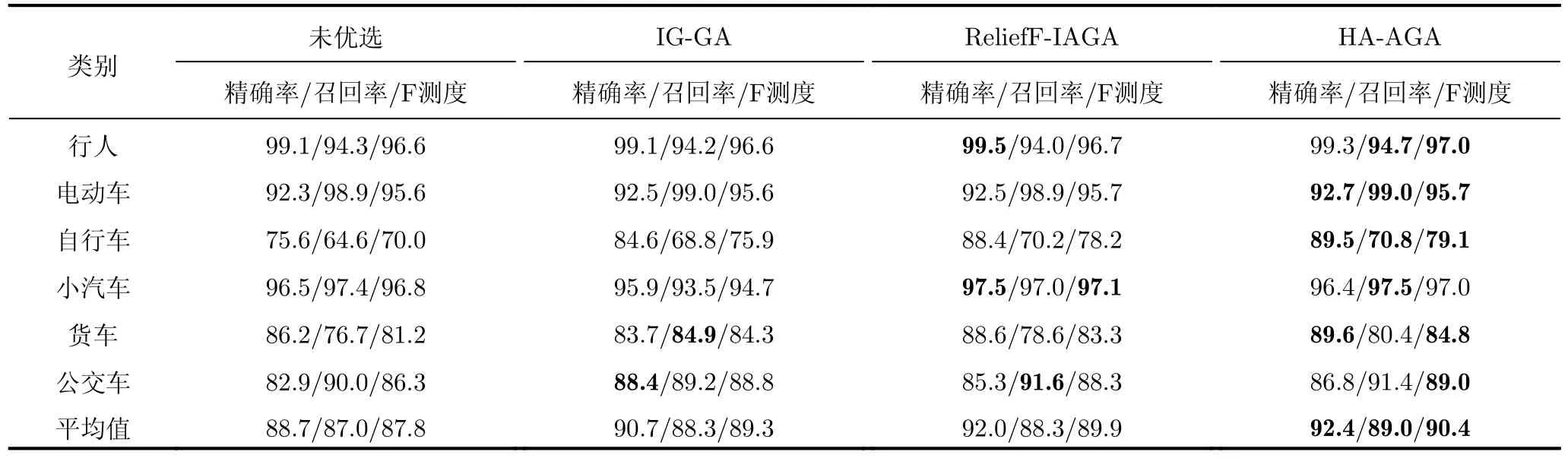
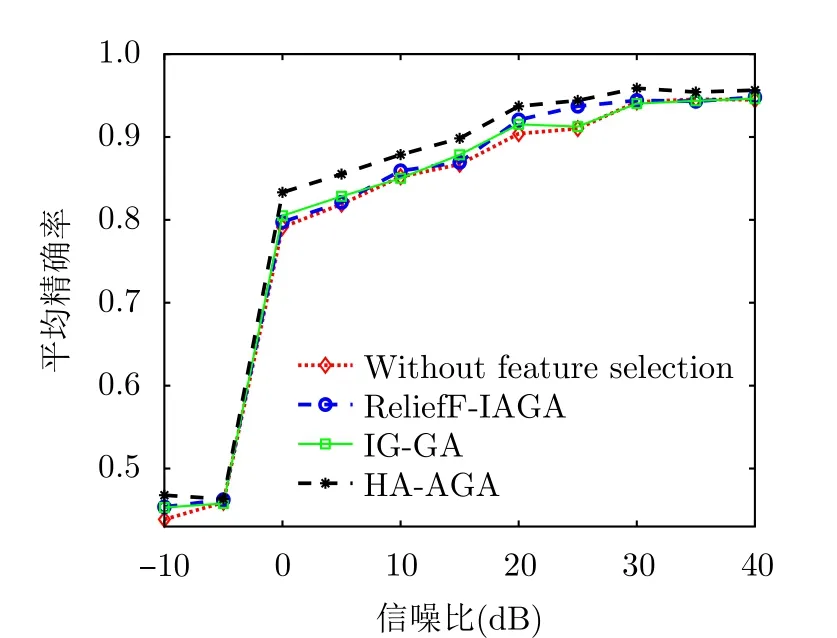
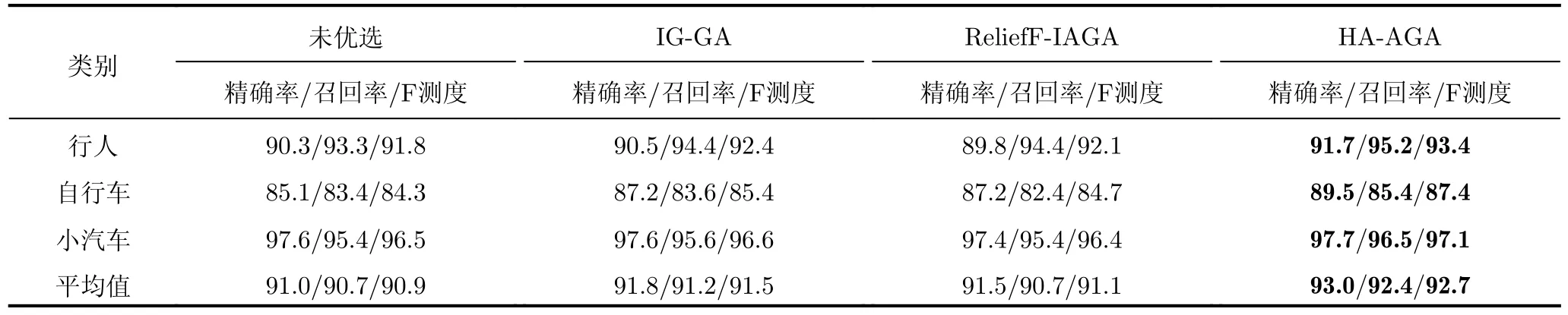
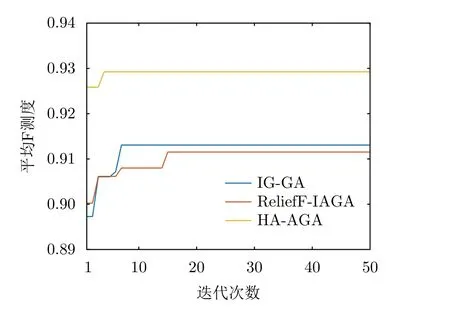
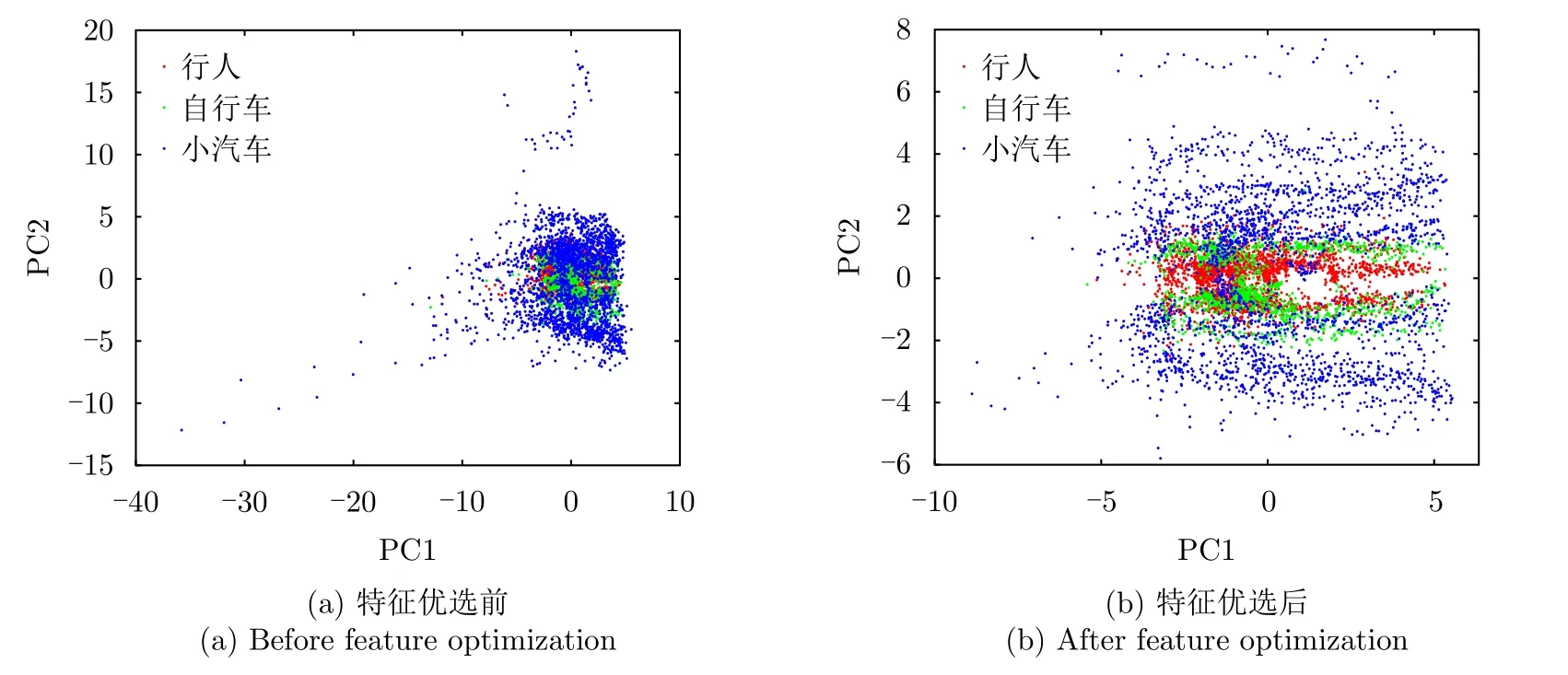
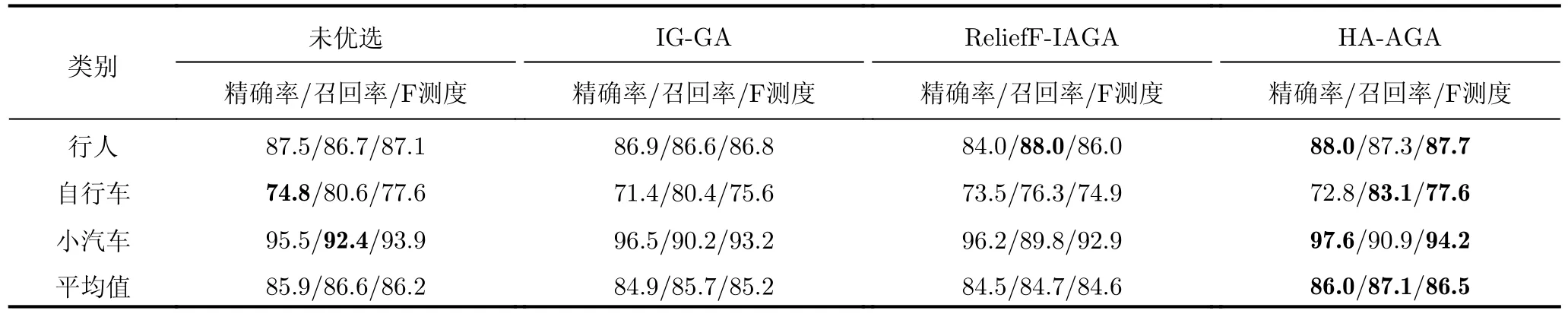
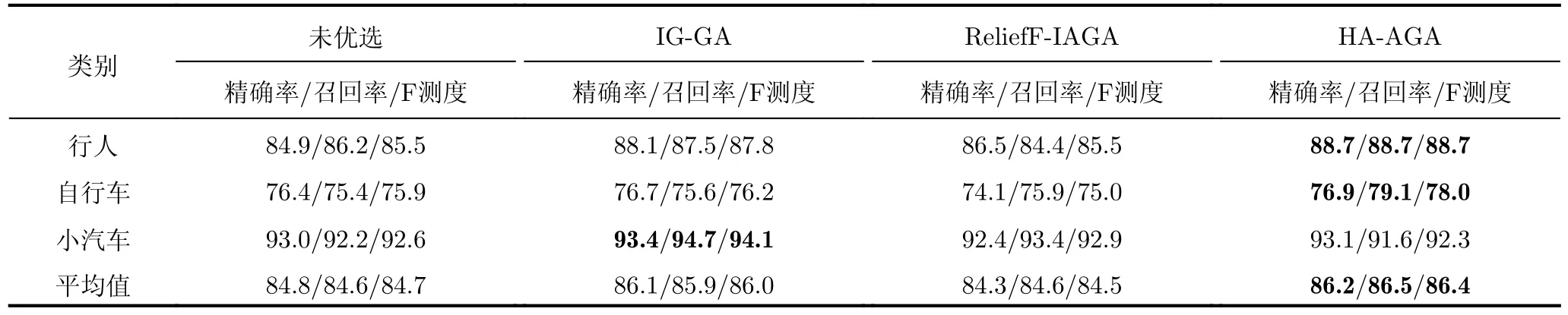
步驟3 為給待選特征集F=[f1f2...fN]T的預降維提供有效的特征選擇依據,提高降維后的特征組合與目標類別的匹配度,利用直方圖分析方法對步驟2得到的優秀特征組合庫Fbest中每個特征出現的頻次進行統計,將第i號特征fi(i=1,2,···,N)在優秀特征組合庫Fbest中出現的頻次qi(i=1,2,···,N)作為該特征的權重,遍歷所有特征,最終得到待選特征集F=[f1f2...fN]對應的權重向量Q=[q1q2...qN]。權重越大的特征,其組合與目標類別的相關度越高,因此取權重最大的前K(K 步驟4 為進一步去除預降維后的特征子集F′中的冗余特征,將F′輸入到AGA進行優選得到最終的特征組合。 通過HA-AGA得到優選的特征組合后,將該特征組合的數據集劃分成訓練集和測試集,并將訓練集輸入分類器進行模型訓練和測試,得到最終的目標分類識別結果。 為驗證本文提出的算法的有效性,將本文所提的HA-AGA算法和PCA-GA[24,25],ReliefF-IAGA[26,27],IG-GA[28]3種兩階段特征選擇算法在毫米波雷達實測數據集和公開數據集CARRADA[30]兩個不同的數據集上進行比較,以驗證本文所提算法的有效性和優越性。 4.1.1 實驗設置 在實驗過程中,將毫米波雷達架設在路口、天橋(均為面向道路水平放置)等地方對行人、電動車、自行車、小汽車、貨車和公交車6類道路目標進行測量采集,采集完成后首先進行數據預處理,其中去除靜止或低速度雜波時的速度參數值v設為0.4 m/s,某個場景及其對應的雷達回波預處理結果如圖3所示。雷達回波中包含有如圖3(a)場景所示的公交車和大貨車。圖3(b)為該場景對應的原始RD譜,圖3(c)為去除靜止或低速度雜波后的RD譜,圖3(d)為經2D-CFAR檢測并去噪后的RD譜,因為該RD譜包含有兩個目標,利用DBSCAN算法將不同目標分割開,圖3(e)和圖3(f)分別為數據切割后只包含公交車和貨車信息的RD譜。預處理完成后得到有效數據共14607幀,將每類目標的數據按7:3的比例分為訓練集和測試集進行特征選擇與識別實驗。表2為各目標類別的標簽以及訓練集和測試集的數量。具體的雷達參數如表3所示。該雷達體制為線性調頻連續鋸齒波,包含4個接收通道,載頻為24 GHz,帶寬為207.32 MHz,調頻斜率為0.80986,采樣率為1 MHz,每幀持續時間為32.768 ms且包含128個脈沖,每個脈沖采樣點數為256。各目標實際場景以及相應的RD譜如圖4所示,由圖可看出行人和自行車的散射點占據的距離單元的個數(距離寬)明顯比速度單元的個數(速度寬)少,而貨車和公交車的情況恰好相反,電動車和小汽車的散射點占據的距離單元和速度單元的個數都很少。并且小汽車、貨車和公交車的徑向速度大于行人、電動車和自行車的徑向速度,說明各目標的RD譜散射點分布存在差異,通過提取相應的特征可對道路目標進行有效識別。 表2 實測數據集描述Tab.2 The real radar dataset description 表3 雷達參數Tab.3 Radar parameters 圖3 數據預處理各步驟實驗結果Fig.3 Experimental results of each step of data preprocessing 圖4 各類目標及其對應的RD譜Fig.4 All kinds of targets and their corresponding RD spectrum 進行特征選擇實驗時首先從道路目標RD譜提取如表1所示的高維特征集F=[f1f2...f30]作為待選特征集。HA-AGA的種群大小M,初始交叉概率Pc0和初始變異概率Pm0分別設為20,0.5和0.2,預降維階段和優選階段的最大迭代次數M分別設為100和50。PCA-GA,ReliefF-IAGA,IG-GA 3種算法的種群大小和迭代次數均設為20和50。各算法取權重最大的前20維特征(K=20)作為預降維后的特征子集。 4.1.2 實驗結果與分析 為驗證本文所提方法在特征優選方面的優越性,進行了不同算法結合集成裝袋樹的特征預降維和優選的對比實驗,預降維實驗中K的值從2取到20,得到的實驗結果如圖5所示,可知HA-AGA在K取不同值時得到的平均F測度均最高,表明本文提出的特征權重計算方法更加合理有效。且PCA-GA方法和其他3種方法相比,識別性能較差,因此在接下來的對比實驗中將不再比較PCA-GA算法。特征優選實驗結果如圖6所示,可知本文所提方法在第5代即收斂,收斂速度最快且識別效果最好,各算法最終選出的特征組合如表4所示,本文所提方法和ReliefF-IAGA方法均選出了14維特征,IG-GA選出了11維特征,但IG-GA選出的特征組合的識別效果最差。本文所提方法特征優選前后的特征向量經PCA降維后的可視化分布圖如圖7所示。其中圖7(a)為優選前的特征分布圖,可知各目標的特征分布混疊較為嚴重,對目標的可分性較差。圖7(b)為優選后的特征分布圖,可看出各目標經過特征優選后的特征分布較分散,對目標的可分性較好。將優選前的特征集和各算法優選得到的特征組合分別輸入到集成裝袋樹分類器進行目標識別實驗,識別結果如表5所示,可知HA-AGA方法的識別效果最好,特別是平均精確率、平均召回率和平均F測度分別達到95.7%,93.0%和94.2%,分別比未進行特征優選時提高了1.8%,1.9%和2.0%,說明原特征集中確實存在特征冗余;比IG-GA提高了1.9%,2.1%和2.0%;比ReliefF-IAGA提高了2.4%,2.0%和2.3%。由此可知HA-AGA方法選出了與類別相關度更高的特征組合,選擇效果更好。 表4 各算法優選后的特征組合Tab.4 Feature combination of different algorithms after optimization 表5 各算法結合集成裝袋樹優選后識別結果(實測數據集)(%)Tab.5 Recognition result of different algorithms combined with integrated bagging tree after optimization (Real radar dataset) (%) 圖5 各算法特征預降維結果Fig.5 Pre-dimensionality reduction results of different algorithms 圖6 各算法特征優選結果Fig.6 Feature optimization results of different algorithms 圖7 由PCA降維得到的實測數據集特征優選前后可視化分布圖Fig.7 Visual distribution of real data set features before and after optimization obtained by PCA dimension reduction 在利用集成裝袋樹分類器實驗的基礎上,為進一步分析和驗證所提特征優選算法結合不同分類器對于其他特征優選算法的優勢,將各算法分別與精細樹和K最近鄰(K-Nearest Neighbor,KNN)相結合進行實驗,優選后的識別結果如表6和表7所示,可知與IG-GA,ReliefF-IAGA算法和未進行特征優選前相比,本文所提的HA-AGA算法結合不同分類器均具有不同程度的優勢,表明所提算法具有一定的廣泛適用性。 表6 各算法結合精細樹優選后識別結果(實測數據集)(%)Tab.6 Recognition result of different algorithms combined with fine tree after optimization (Real radar dataset) (%) 為進一步驗證本文所提方法的優越性,將本文所提方法和深度學習方法即改進的RetinaNet[6]進行對比實驗,實驗識別結果如表8所示。由表可看出本文所提方法與深度學習方法改進的RetinaNet相比,得到的所有指標均最高,表明了本文所提方法能得到更好的識別結果。 為驗證本文所提方法的魯棒性,進行了不同信噪比條件下各算法特征選擇對比實驗。實驗結果如圖8所示,可知,在–10 dB和–5 dB條件下各算法識別精度都很差,但總體而言,在不同信噪比條件下本文所提的HA-AGA算法均獲得了最高的平均精確率,表明本文所提的HA-AGA特征優選方法對噪聲具有更好的容忍性。 圖8 不同信噪比條件下各特征選擇算法識別結果Fig.8 The recognition results of feature selection algorithm in different SNR 4.2.1 實驗設置 公共數據集CARRADA[30]提供了包括兩個場景在內的行人、自行車和小汽車3類目標的RD譜,數據集所用雷達參數如表9[30]所示。該雷達載頻為77 GHz,帶寬為4 GHz,幀脈沖數為64,每個脈沖采樣點數為256,最大探測距離為50 m,距離分辨率為0.20 m,最大徑向速度為13.43 m/s,速度分辨率為0.42 m/s。首先通過對該數據集篩選并進行數據預處理,去除靜止或低速度雜波時的速度參數v設為0.4 m/s。某個場景對應的雷達回波預處理實驗結果如圖9所示。雷達回波中包含有如圖9(a)場景所示的自行車和小汽車,自行車向遠離雷達方向行駛,小汽車低速靠近。圖9(b)為該場景對應的原始RD譜,圖9(c)為去除靜止或低速度雜波后的RD譜,圖9(d)為經2D-CFAR檢測并去噪后的RD譜,因為該RD譜包含有兩個目標,利用DBSCAN算法將不同目標分割開,圖9(e)和圖9(f)分別為數據切割后只包含小汽車或自行車信息的RD譜。預處理完成后得到有效數據8693幀,接著對每幀RD譜提取特征向量F=[f1f2...f30]構成RD譜特征集。將每類目標的數據按7:3的比例分為訓練集和測試集,進行實驗時各目標的類別標簽以及訓練集和測試集的數量如表10所示。特征選擇實驗中各特征選擇算法的參數設置和4.1.1節一致。 表9 CARRADA數據集雷達參數[30]Tab.9 Radar parameters of CARRADA dataset[30] 表10 CARRADA數據集描述Tab.10 CARRADA dataset description 4.2.2 實驗結果與分析 為驗證本文所提方法的優越性,進行了不同算法結合集成裝袋樹特征預降維和優選的對比實驗,預降維實驗中K的值從2取到20,實驗結果如圖10所示,可知HA-AGA在K取不同值時得到的平均F測度均最高,表明本文提出的特征權重計算方法更加合理有效。特征優選的實驗結果如圖11所示,本文所提方法在第4代即收斂,收斂速度最快且識別效果最好,各算法最終選出的特征組合如表11所示。本文所提方法特征優選前后的特征向量經PCA降維后的可視化分布圖如圖12所示。其中圖12(a)為優選前的特征分布圖,可看出各目標的特征分布混為一簇,對目標的可分性較差。圖12(b)為優選后的特征分布圖,可知各目標的特征分布較分散,對目標的可分性有所提升。將優選前的特征集和各算法優選得到的特征組合分別輸入到集成裝袋樹分類器進行目標識別實驗,識別結果如表12所示,可知HA-AGA方法的識別效果最好,平均精確率、平均召回率和平均F測度分別達到93.0%,92.4%和92.7%,分別比未進行特征優選時提高了2.0%,1.7%和1.8%;比IG-GA均提高了1.2%;比ReliefF-IAGA提高了1.5%,1.7%和1.6%。由此可知HA-AGA方法選出了與類別相關度更高的特征組合,驗證了本文所提方法的優越性。 表11 不同算法優選后的特征組合Tab.11 Feature combination of different algorithms after optimization 表12 各算法結合集成裝袋樹優選后識別結果(CARRADA)(%)Tab.12 Recognition result of different algorithms combined with integrated bagging tree after optimization (CARRADA) (%) 圖10 不同算法特征預降維結果Fig.10 Pre-dimensionality reduction results of different algorithms 圖11 不同算法特征優選結果Fig.11 Feature optimization results of different algorithms 圖12 由PCA降維得到的CARRADA數據集特征優選前后可視化分布圖Fig.12 Visual distribution of CARRADA data set features before and after optimization obtained by PCA dimension reduction 在利用集成裝袋樹分類器實驗的基礎上,為進一步分析和驗證所提特征優選算法結合不同分類器對于其他特征優選算法的優勢,將各算法分別與精細樹和KNN相結合進行實驗,優選后的識別結果如表13和表14所示,可知與IG-GA,ReliefF-IAGA算法和未進行特征優選前相比,本文所提的HA-AGA算法結合不同分類器均具有不同程度的優勢,表明所提算法具有一定的廣泛適用性。 表13 各算法結合精細樹優選后識別結果(CARRADA)(%)Tab.13 Recognition result of different algorithms combined with fine tree after optimization (CARRADA) (%) 表14 各算法結合KNN優選后識別結果(CARRADA)(%)Tab.14 Recognition result of different algorithms combined with KNN after optimization (CARRADA) (%) 在毫米波雷達實測數據集和公共數據集CARRADA上的實驗表明,與ReliefF-IAGA,IG-GA,未進行特征優選前和改進的RetinaNet網絡相比,本文所提的HA-AGA方法獲得了與目標類別相關度更高的特征組合,提高了目標的識別精度,且在實測數據集中的信噪比對比實驗驗證了本文所提算法具有更好的噪聲魯棒性。 隨著自動駕駛技術的不斷發展,道路目標識別領域中的特征優選技術受到社會各界的廣泛關注。本文針對現有改進AGA特征優選方法因未考慮不同特征組合與目標類別的匹配度從而導致優選得到的特征組合對目標的區分度有限的問題,提出了一種基于直方圖分析和自適應遺傳的雷達道路目標識別特征優選方法。該方法在AGA框架中通過引入直方圖分析對優秀特征組合庫中各特征的頻次進行統計,并選取頻次最高的特征集輸入AGA優選出與目標類別相關度更高的特征組合,以提升特征優選的效率和準確度。基于毫米波雷達實測數據集和公共數據集CARRADA的一系列對比實驗表明與PCA-GA,ReliefF-IAGA和IG-GA等特征選擇方法相比,本文所提方法結合不同分類器選出的特征組合與類別相關度最高,能夠得到更高的識別精度,且對噪聲的魯棒性更強,適用性更加廣泛。4 實驗驗證
4.1 毫米波實測雷達數據實驗


4.2 公共數據集CARRADA實驗



5 結語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
