基于混合注意力機制的視頻序列表情識別
2023-10-29 01:50:00李金海
計算機仿真 2023年9期
李金海,李 俊
(1. 桂林電子科技大學電子工程與自動化學院,廣西 桂林 541004;2. 桂林電子科技大學計算機與信息安全學院,廣西 桂林541004)
1 引言
表情能傳遞人類的情緒、心理和身體狀態信息。研究表情自動識別技術能夠有效地輔助人工智能機器分析判斷人類的情緒,近年來該研究廣泛應用于智能教育[1]、交通安全[2]、醫療[3]等領域,使得許多學者逐漸開始關注動態表情識別方面的研究。
傳統的視頻表情識別算法主要有LBP-TOP[4]與光流法[5]等,這些手工提取特征的方法很大程度上依賴于特定的任務,且這些方法都具有缺乏泛化性與穩定性的特點。
近幾年來,隨著人工智能的迅猛發展,許多深度學習方法應用在表情識別領域上,并且識別精度比手工提取特征方法有很大提升。現階段主要有級聯網絡[6]、三維卷積神經網絡[7]、多網絡融合[8]等方法對視頻表情進行識別。以上方法對特征的提取具有一定的隨意性,且忽略了對表情峰值幀的關注,而表情在變化過程中表情峰值幀往往具有更多判別性的特征。此外,深度學習方法在訓練模型時候要有大規模的數據量支撐。而表情識別任務中可靠的數據集規模較小,在該類數據集上直接訓練會導致模型出現過擬合現象。
本文提出了一種混合注意力模型。該模型在通道維度上能有效地增強與表情相關性高的通道信息,時間維度上給予表情峰值幀更多的關注,以此增強網絡提取有效特征的能力。數據集方面通過數據增強,增加訓練樣本數量,解決數據集規模小的問題。最后通過對比結果驗證本文方法能夠明顯提高識別準確率。
2 基于混合注意力機制的表情識別模型
本文提出了一種基于混合注意力機制的時空網絡對視頻中的臉部表情進行分類。模型主要包括了三部分:空域子網絡、時域子網絡和混合注意力模塊。
2.1 空域子網絡
空域子網絡中,通過VGG16網絡中的卷積層和池化層來學習人臉各類表情的空域特征。本文對VGG16網絡進行了修改,首先是保留VGG16的卷積層部分,并使用自適應平均池化(Adaptive average Pooling,APP)代替原始網絡中的全連接層。其中自適應平均池化層的池化窗口(kernel size)大小為4*4,滑動步長(Padding)為4,經過池化層的操作實現特征降維。最終得到的特征向量的通道數(channel)為512,大小為1*1的特征圖。
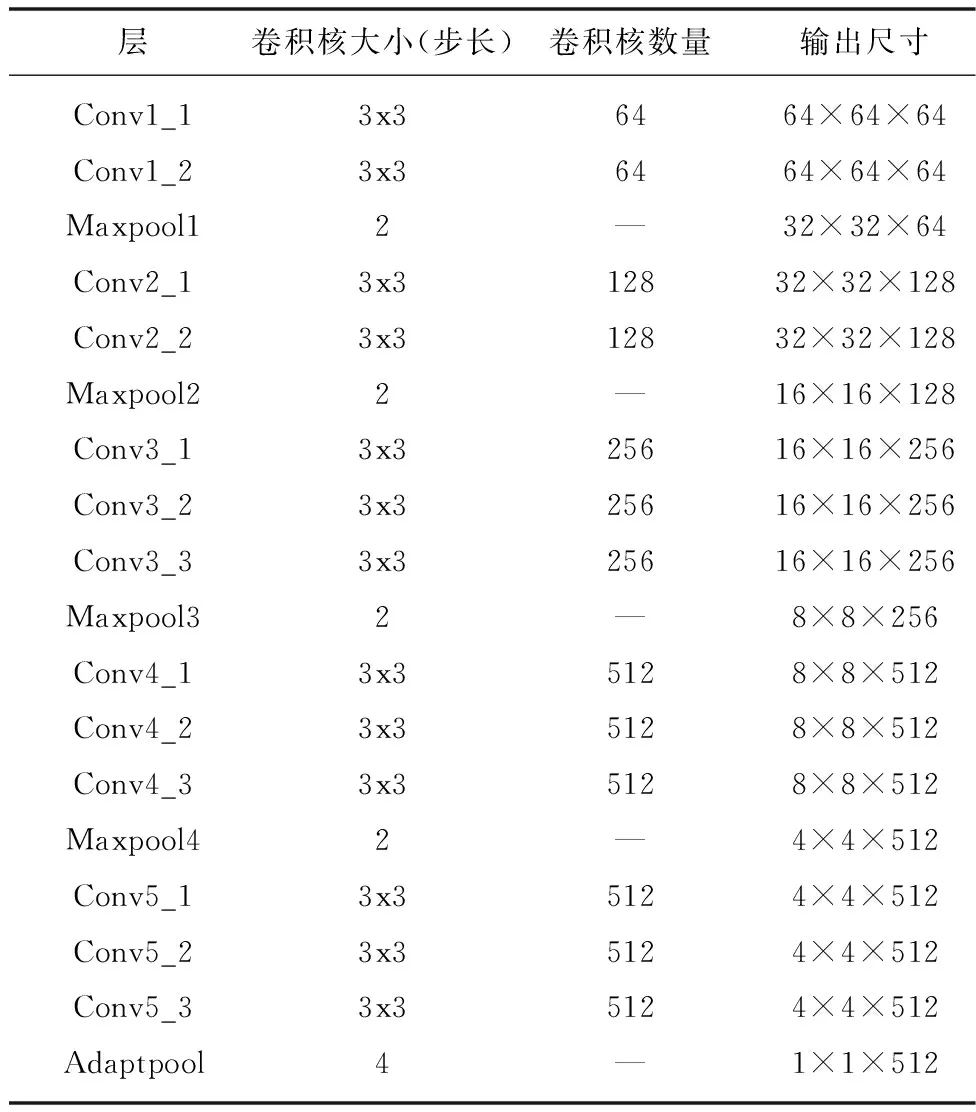
表1 改進的VGG16結構
2.2 時域子網絡
對于視頻幀中的表情識別,需要觀察表情和時間變化之間的關系。由于VGG神經網絡對于時序變化的表達能力不足,因此需要引入其它網絡來解決該問題。長短時記憶網絡能夠通過隱藏狀態來記錄先前序列的內容,從而解決時序問題。
GRU網絡中重置門rt與更新門zt(t代表當前時刻)具有重要要作用,如圖1所示。rt與zt都能接收當前時刻輸入xt和先前時刻隱藏層狀態ht-1輸入,對應的權值分別是Wr與Wz。根據圖1的GRU內部結構圖,網絡的主要操作過程如下式所示
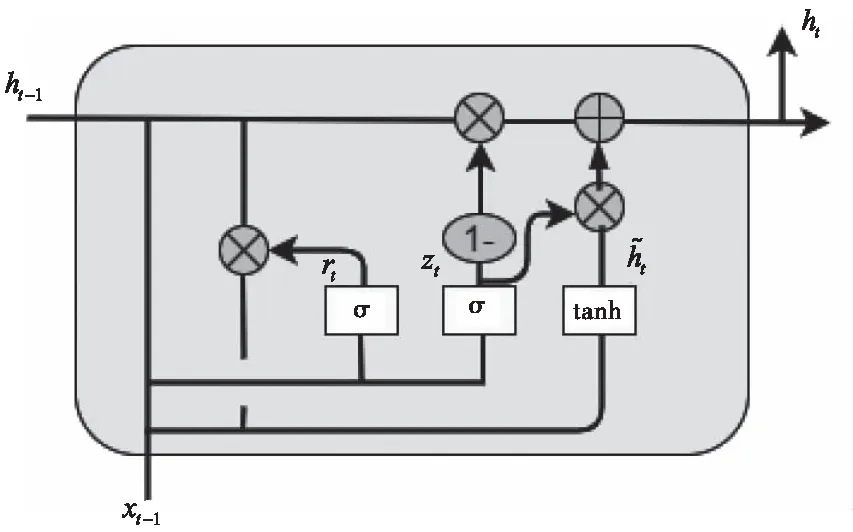
圖1 GRU內部結構
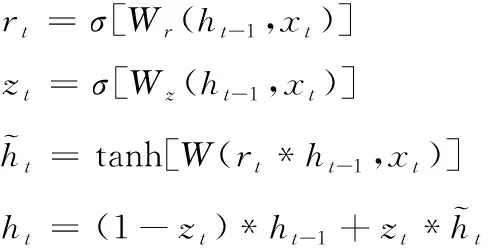
(1)
模型訓練過程中,將一組序列中的視頻幀當成一批次輸入,空域子網絡提取該批次的特征再經過AAP層,得到n個大小為1*1,通道數為512的特征向量。然后把這些向量輸入時域子網絡里,GRU讀取視頻的時間變化獲得大小為n×512特征矩陣,隨后將特征矩陣進行平鋪處理成1×512n的特征矩陣,最后輸入到混合注意力模塊中。
2.3 混合注意力模塊
本文設計的混合注意力主要為了有效提取通道特征與表情變化的時間特征。通道注意力采用自學習的方式獲得各個特征通道的權重,并按照權重大小增強對表情分類有用的通道,抑制非相關的通道,提高了網絡對顯著性特征的提取性能。時間注意力通過判別幀間的表情強度,賦予表情強度大的視頻幀更高的權重,使網絡更關注于表情峰值幀。根據文獻[9]的實驗原理,本文將兩個注意力模塊按照串聯的方式排列。設計完成后混合注意力如圖2所示。
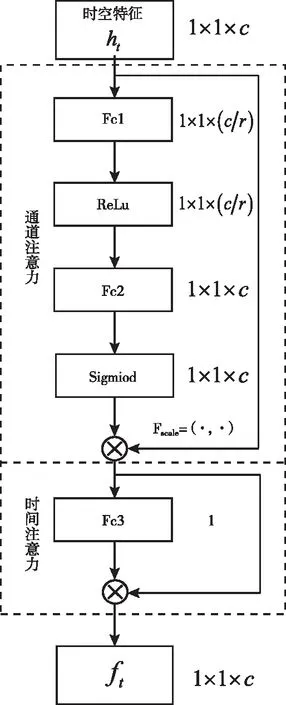
圖2 混合注意力模塊
2.3.1 通道注意力原理
通道注意力主要有激勵和特征通道賦值這兩個過程。其中激勵操作的原理如式(2)所示
s=Fex(ht,WcATT)=δ(WcATT2σ(WcATT1ht))
(2)
其中ht為序列表情的時空特征,δ與σ為ReLU激活函數和Sigmoid激活函數,Fex為激勵處理,WcATT1、WcATT2分別代表通道注意力中兩個全連接層的權值。激勵操作中,先采用第一個全連接層WcATT1與時空特征ht相乘,WcATT1的維度是C/r*C,r表示縮減倍數,即為了減少運算量,對原特征通道總數進行壓縮,根據文獻[10],r取16。此時WcATT1ht的維度為[1,1,C/r]。激活函數使用ReLU函數,保持輸出維度不變;隨后經過全連接處理,將結果和WcATT2相乘,并利用sigmoid激活函數進行非線性轉換。得到數值范圍為0到1的通道權重值sc。此時sc的維度大小為[1,1,C]。最后進行特征通道賦值操作,即將權重sc與注意力機制前的時空特征ht進行相乘,通道賦值公式如式所示
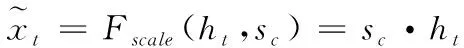
(3)
通道賦值中,對應的權值sc表示為各個特征通道對表情的相關性大小。模型訓練時,通過sc的大小對相應的特征進行增強或者抑制。通過這種方式,能夠實現對最具鑒別性表情特征的聚焦,提升模型的性能。
2.3.2 時間注意力原理
在視頻序列的識別任務中,并不是每一時刻的表情都對識別的貢獻相同。因此本文提出一種時間注意力機制,賦予表情峰值幀更多的權重,以生成更有判別性的特征。在時間注意力中,提出了一種比較幀強度的方法,即通過一個全連接層,將每個幀特征映射為時間注意力分數。公式如下
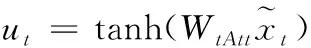
(4)
式中,WtAtt為時間注意力模塊中可學習的參數矩陣。ut表示序列第t幀圖片時間注意力分數;然后,通過Softmax函數歸一化每幀的注意力分數
(5)
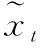

(6)
最后,使用兩個全連接層降維,并使用Softmax函數分類得出六種表情結果。
3 實驗與分析
3.1 表情數據集預處理
為了驗證本文算法在視頻序列表情識別的效果,本文選取了公開主流數據庫:CK+數據庫與Oulu-CASIA數據庫。
在實驗過程中使用dlib庫提供的人臉檢測器對眼睛、眉毛、鼻子、嘴巴和面部輪廓在內的68個人臉關鍵點進行檢測。利用68個點位置,計算臉部中間點的信息。根據視頻第一幀的位置信息,利用仿射變換矩陣調整后續圖像,使后續人臉臉部對齊。最后將臉部圖片裁剪成64x64尺寸,圖3為裁剪后的表情圖像。

圖3 部分裁剪后圖像樣本
由于兩個數據集中序列表情圖片較少,為了保證模型的泛化性與魯棒性,本文實驗對數據集采取了數據擴充的方法。具體地,首先將裁剪到的所有人臉區域圖片進行水平反轉得到翻轉圖像數據集;然后,將原數據集與反轉圖像數據集分別偏移-10°、-5°、5°、10°得到偏移數據集,最后獲得10倍于原先的實驗數據量。因為各個視頻的幀數都不同,而模型的輸入維度是不變的,因此對CK+與Oulu-CASIA中每個表情視頻序列均從起始幀按照時間序列連續采樣16幀,作為神經網絡的輸入。此外,如果視頻序列幀數少于16幀的長度,則復制最后一幀直至每個序列變為平均長度。
3.2 實驗設置
本文實驗軟件框架為Pytorch1.8.1。實驗在訓練時采用隨機梯度下降法優化模型在模型訓練時,CK+的訓練集損失函數變化情況如圖4所示,當迭代到150個epoch后,損失函數已基本收斂,損失函數值接近0.1,因此實驗中epoch取160。為了能更好地體現出算法的實驗效果,本次實驗使用十折交叉驗證方法得到最后的準確率。
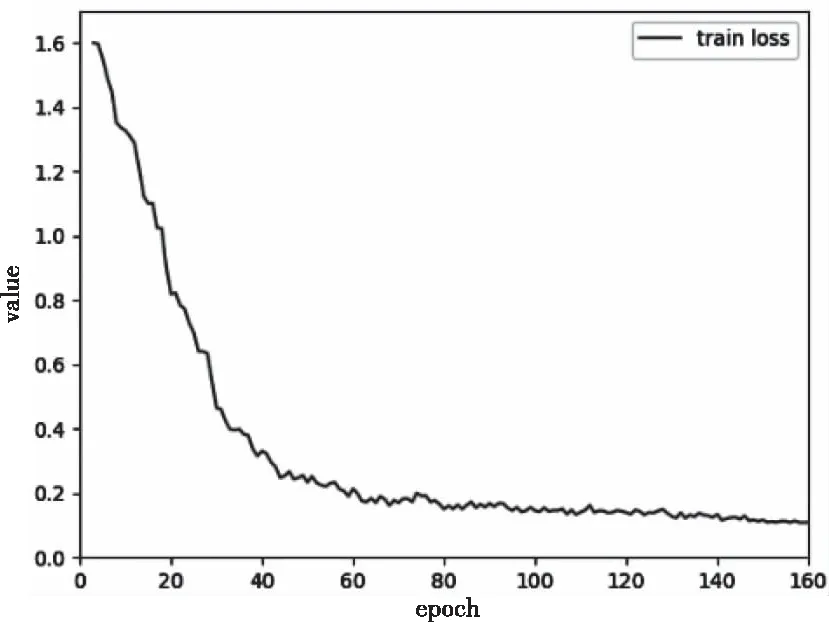
圖4 CK+訓練損失函數圖
3.3 消融實驗
為了體現加入了混合注意力機制的效果提升,對其進行了消融實驗。其中,Baseline是指改進的VGG16與GRU的級聯網絡,CA代表通道注意力模塊,TA代表時間注意力模塊,HA代表CA與TA相結合的混合注意力模塊。
表2為消融實驗中各個模型的準確率。單獨加入通道注意力模塊與單獨加入時間注意力的網絡在兩個主流數據集上所得的準確率相對于Baseline都有明顯的提高。
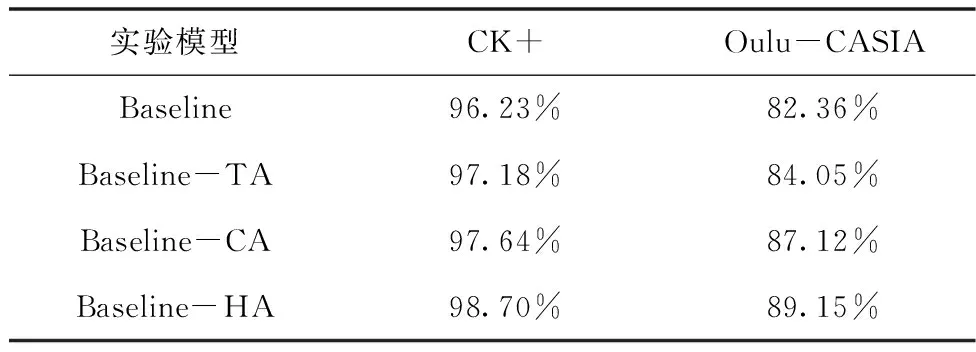
表2 各個模型準確率
對于CK+數據集,單個時間與單個通道注意力模塊的加入分別比Baseline提高0.95%和1.41%。在Oulu-CASIA的實驗中,分別提高了1.69%與4.76%。由此可得,通道注意力的性能略優于時間注意力的識別性能,說明在視頻表情識別中全局通道維度比全局時間維度提供更多的信息。此外,Baseline-HA模型在CK+與Oulu-CASIA的準確率分別比Baseline高出2.47%和6.75%,這表明混合注意力模塊能夠有效地將兩個注意力模塊的性能進行互補,不僅能夠在視頻序列中給予表情峰值幀更多的關注,而且能抑制無關通道干擾,提取更具顯著性的臉部紋理特征。
3.4 混淆矩陣分析
圖5與圖6展示了本文方法在兩個數據集上的混淆矩陣。混淆矩陣的行表示當前表情的真正類別,列為模型的分類表情。不難得知,CK+數據庫的整體表情識別準確率比Oulu-CASIA的要高,這是因為CK+中大多數為清晰的人物正臉圖像;而Oulu-CASIA中圖像分辨率不夠高,而且部分人物有眼鏡和圍巾的遮擋,導致識別率較低。

圖5 CK+識別結果混淆矩陣
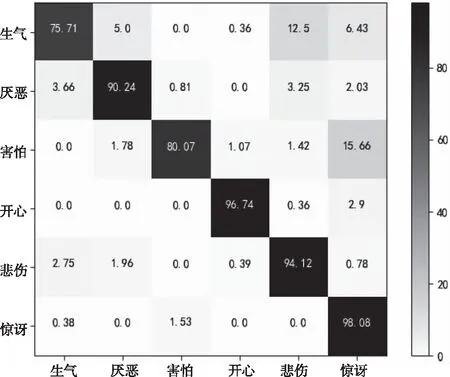
圖6 Oulu-CASIA識別結果混淆矩陣
比較兩個混淆矩陣的數據可知,文中模型對驚訝與開心兩個表情取得了優異的識別效果。模型對于生氣和害怕兩個表情識別性能較弱,主要原因是,數據集中害怕與驚訝大部分都是瞪眼和張嘴的動作,而生氣與悲傷都伴隨著鎖眉和撇嘴的動作。具體而言,表情的相似導致模型出現混淆分類的情況。
3.5 與現有方法對比
表3展示了本文所提模型與其它主流模型在所選數據集上實驗的對比結果。
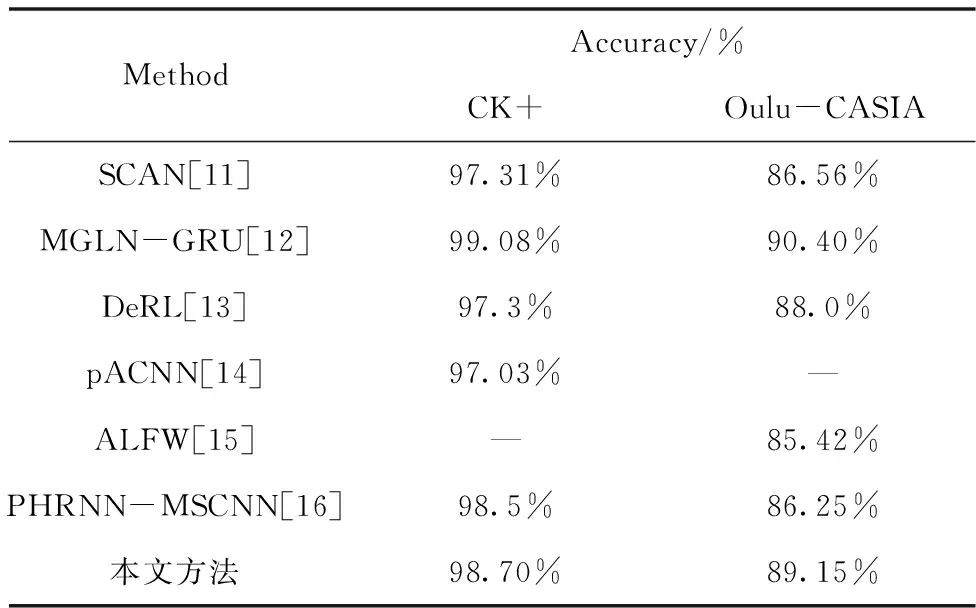
表3 不同方法的準確率對比
從中可得,本文所提出模型對CK+與Oulu-CASIA這兩個數據集的識別準確率僅次于MGLN-GRU,而優于其它方法。值得注意的是,本文模型只關注于表情特征,而識別準確率高于同時利用表情特征和幾何路標點的PHRNN-MSCNN。而MGLN-GRU利用復雜的多任務模型實現了99.08%與90.40%的識別率,比文中模型分別高了0.38%和1.25%,但是MGLN-GRU模型與本文的實驗設置不同,該模型的輸入是選取視頻序列的第一幀、中間幀和最后一幀來表示表情演化,這種離散幀的識別方法會造成峰值信息缺失。本文提出模型將視頻的連續多幀作為輸入,使文中模型注重于連續幀之間的表情依賴性,較好地適應了表情強度的變化,更符合現實生活人臉表情變化過程。
4 結束語
本文設計了一種混合注意力機制視頻序列表情識別模型。該方法的主體為改進的卷積神經網絡與GRU網絡的級聯網絡,可以提取序列時空信息的同時減少特征提取的計算量。其次,提出了由通道與時間注意力組成的混合注意力模塊,更關注于表情峰值幀中與表情相關性高的特征通道。通過數據擴充方法,解決目前表情數據規模較小的難題,保證模型的泛化性。實驗結果表明,嵌入混合注意力模塊使得模型在CK+與Oulu-CASIA兩個數據集上的識別準確率分別提高2.47%與6.79%。最后,通過與其它研究方法對比,該模型在表情識別準確率有明顯優勢。驗證了本文提出的方法能夠有效地提取最具表達能力的特征,提高識別準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
