基于游覽行為和逆向強(qiáng)化學(xué)習(xí)的游客偏好學(xué)習(xí)
2023-10-22 08:00:04宣聞,常亮
桂林電子科技大學(xué)學(xué)報(bào) 2023年3期
宣 聞,常 亮
(桂林電子科技大學(xué) 廣西可信軟件重點(diǎn)實(shí)驗(yàn)室,廣西 桂林 541004)
利用旅游推薦技術(shù)為用戶提供個(gè)性化服務(wù)并提高推薦性能和游客滿意度,是當(dāng)前智慧旅游領(lǐng)域研究的熱點(diǎn)之一。在旅游推薦中,理解游客的行為模式,學(xué)習(xí)游客偏好是非常重要的。當(dāng)前的旅游推薦技術(shù)主要根據(jù)游客游覽展品的評分、簽到數(shù)據(jù)、訪問的頻次等數(shù)據(jù)作為游客對游覽展品喜好程度的評判依據(jù)。但是,具體景區(qū)內(nèi)部,如博物館、主題公園等,通常無法獲得游客針對游覽點(diǎn)或展品的具體評分?jǐn)?shù)據(jù),因此不能對游客進(jìn)行細(xì)粒度偏好學(xué)習(xí),從而也不能獲得針對特定景區(qū)內(nèi)部的游覽推薦。并且許多推薦算法需要大量的游客數(shù)據(jù)來訓(xùn)練,從而學(xué)習(xí)出游客偏好再進(jìn)行推薦,然而展館內(nèi)部的游客數(shù)據(jù)較為稀缺、不完整,因此,無法根據(jù)有限的游客數(shù)據(jù)學(xué)習(xí)出精準(zhǔn)的偏好。鑒于此,為了在游客數(shù)據(jù)較少的情況下獲得游客更加真實(shí)、細(xì)粒度的偏好,提出一種基于游覽行為和逆向強(qiáng)化學(xué)習(xí)的偏好學(xué)習(xí)方法。首先,通過物聯(lián)網(wǎng)和移動(dòng)傳感器技術(shù)采集游客在特定景點(diǎn)內(nèi)的各個(gè)游覽點(diǎn)的拍照次數(shù)、游玩時(shí)間等游覽行為數(shù)據(jù);然后,針對采集到的行為數(shù)據(jù)設(shè)計(jì)逆向強(qiáng)化學(xué)習(xí)算法,基于獲取到的真實(shí)數(shù)據(jù)進(jìn)行細(xì)粒度偏好學(xué)習(xí)。
1 研究現(xiàn)狀
1.1 位置感知技術(shù)
目前最常見的定位技術(shù)是GPS(global positioning system)全球定位系統(tǒng),它通過衛(wèi)星發(fā)射的基準(zhǔn)信號來工作,但是在有建筑物遮擋的情況下,就無法運(yùn)用GPS精準(zhǔn)定位,因此GPS也被稱為室外定位系統(tǒng)[1];在室內(nèi)定位技術(shù)中,WiFi(wireless fidelity)部署成本低,但是,目前的WiFi定位技術(shù)需要通過預(yù)先測量來提供相對應(yīng)的接入點(diǎn)(APs)、傳播參數(shù)(PPs)以及地圖上的具體位置,這個(gè)預(yù)先測量的過程既耗時(shí)又費(fèi)力[2];Wang等[3]使用射頻識(shí)別(radio frequency identification,簡稱RFID)技術(shù)來實(shí)現(xiàn)細(xì)粒度室內(nèi)定位,該系統(tǒng)利用RFID的多路徑效應(yīng)進(jìn)行精確定位,通過合成孔徑雷達(dá)(synthetic aperture radar,簡稱SAR)提取多路徑的配置文件,采用動(dòng)態(tài)時(shí)間規(guī)劃技術(shù)確定RFID 標(biāo)簽的位置,從而實(shí)現(xiàn)定位,但是RFID需要標(biāo)簽和讀寫器,部署成本較大,不適合在大型場合使用。iBeacon是蘋果公司于2013年9月發(fā)布的新一代室內(nèi)定位技術(shù),具有低功耗藍(lán)牙(bluetooth low energy,簡稱BLE)的通訊功能,它可以向周圍發(fā)送自己特有的ID,同時(shí)根據(jù)iBeacon設(shè)備所發(fā)出的廣播信號強(qiáng)度的變化,對智能手機(jī)和iBeacon之間的距離進(jìn)行計(jì)算,得出距離最近的iBeacon設(shè)備,從而實(shí)現(xiàn)定位。iBeacon具有成本低、功耗低、跨平臺(tái)、易安裝部署等優(yōu)點(diǎn),在室內(nèi)定位中具有較大的優(yōu)勢[4-5]。
1.2 用戶偏好評估和應(yīng)用
眾多的社交媒體提供了豐富的數(shù)據(jù)信息,可用于獲取游客的歷史位置并分析他們的偏好,從而為游客提供個(gè)性化的推薦服務(wù),因此,基于位置的社交網(wǎng)絡(luò)在游客偏好學(xué)習(xí)在旅游推薦中得到了廣泛的應(yīng)用。Yuan等[6]提出基于位置-時(shí)間-序列的方法,利用基于位置的社交網(wǎng)絡(luò)數(shù)據(jù)集從空間和時(shí)間兩個(gè)方面對用戶的偏好進(jìn)行建模,然后用時(shí)間和空間特征結(jié)合的方式對用戶的個(gè)人偏好進(jìn)行預(yù)測。Zhu等[7]提出了一種基于語義模式和偏好感知的挖掘方法,首先將位置分為不同的類型,從而進(jìn)行位置識(shí)別,然后從游客的位置軌跡、語義軌跡、位置的流行程度和用戶熟悉度4個(gè)方面為每位用戶進(jìn)行建模,從而獲取用戶偏好并推薦興趣點(diǎn)。Wang等[8]提出基于上下文感知的用戶偏好預(yù)測算法,構(gòu)建了云模型,將分類信息引入用戶和位置的相似性估計(jì)中,當(dāng)用戶在一個(gè)新景點(diǎn)時(shí),通過新景點(diǎn)的類別和訪問過該景點(diǎn)的用戶類別,預(yù)測用戶的偏好。Zhu等[9]在基于位置的社交網(wǎng)絡(luò)數(shù)據(jù)集上構(gòu)建了旅游推薦的系統(tǒng)架構(gòu),并對每位用戶的移動(dòng)模式進(jìn)行建模,最后根據(jù)產(chǎn)生的興趣點(diǎn)進(jìn)行推薦。
盡管上述的方法都可以學(xué)習(xí)游客的偏好,但是仍存在以下問題:首先,現(xiàn)有的游客偏好學(xué)習(xí)方法大多使用基于位置的社交網(wǎng)絡(luò)數(shù)據(jù)集,而基于位置的社交網(wǎng)絡(luò)數(shù)據(jù)集中,位置僅到景區(qū)級別,因此只能學(xué)習(xí)出游客對景區(qū)級別的粗粒度偏好,從而進(jìn)行粗粒度的旅游景點(diǎn)推薦;其次,現(xiàn)有方法僅考慮了游客的位置、簽到等數(shù)據(jù)信息,卻未考慮到游客訪問展品的先后順序?qū)τ慰推玫挠绊憽4送?在游客實(shí)際旅游的過程中,不會(huì)一直共享自己的位置信息,因此最后收集到的游客簽到的數(shù)據(jù)集僅包含了游客一部分的位置信息,從而導(dǎo)致數(shù)據(jù)稀疏,對游客偏好的學(xué)習(xí)不全面,無法對景區(qū)內(nèi)部景點(diǎn)進(jìn)行細(xì)粒度的推薦。
1.3 逆向強(qiáng)化學(xué)習(xí)
逆向強(qiáng)化學(xué)習(xí)(inverse reinforcement learning,簡稱IRL)是一種通過專家數(shù)據(jù)學(xué)習(xí)出回報(bào)函數(shù)的技術(shù),它首先通過馬爾科夫決策過程(Markov decision process,簡稱MDP)對應(yīng)用場景進(jìn)行建模,然后利用相關(guān)算法進(jìn)行學(xué)習(xí)。吳恩達(dá)等[10]通過觀察該領(lǐng)域的專家示例來學(xué)習(xí)用戶偏好,從而學(xué)習(xí)到背后的回報(bào)函數(shù),這個(gè)逆向強(qiáng)化學(xué)習(xí)的方法被稱為學(xué)徒學(xué)習(xí)。Ratliff等[11]將評估回報(bào)函數(shù)轉(zhuǎn)化為特征到回報(bào)的線性映射問題,在這種線性映射下,最優(yōu)的策略與專家策略十分接近,此方法稱為最大邊際規(guī)劃方法。但是基于最大邊際規(guī)劃方法的主要問題是會(huì)產(chǎn)生歧義,比如有很多不同的回報(bào)函數(shù)會(huì)導(dǎo)致相同的專家策略。為了解決這個(gè)問題,Ziebart等[12]提出基于最大熵的逆向強(qiáng)化學(xué)習(xí)方法,即在已知專家軌跡的情況下,求解產(chǎn)生軌跡分布的概率模型。上述方法雖然能夠?qū)W習(xí)出回報(bào)函數(shù),但是所需的數(shù)據(jù)量較大,需要較多的數(shù)據(jù)進(jìn)行不斷地迭代才能訓(xùn)練出較為準(zhǔn)確的回報(bào)函數(shù)。Babes等[13]提出的極大似然逆向強(qiáng)化學(xué)習(xí)方法,與前面的算法相比,優(yōu)勢在于可以在數(shù)據(jù)較少的情況下訓(xùn)練出回報(bào)函數(shù)。Massimo等[14]提出基于用戶與項(xiàng)目的交互來學(xué)習(xí)用戶偏好方法,該方法將極大似然逆向強(qiáng)化學(xué)習(xí)運(yùn)用于學(xué)習(xí)用戶對項(xiàng)目的偏好上,最后學(xué)習(xí)出用戶偏好;2018年,Massimo等[15]在之前方法的基礎(chǔ)上,提出一個(gè)基于上下文用戶行為模型的方法,該方法對用戶的軌跡進(jìn)行分類對于每個(gè)分類都產(chǎn)生一個(gè)基于上下文用戶行為模型,最后將用戶的軌跡與得出的行為模型相結(jié)合,從而學(xué)習(xí)出用戶的偏好。上述2個(gè)方法均考慮到在用戶與項(xiàng)目交互的過程中現(xiàn)場所產(chǎn)生的行為對偏好的影響。
2 預(yù)備技術(shù)
對游客在室內(nèi)展館的游覽行為進(jìn)行馬爾科夫決策過程建模。首先,簡單介紹了運(yùn)用iBeacon進(jìn)行數(shù)據(jù)采集的整體流程,然后詳細(xì)介紹了馬爾科夫決策過程建模過程,并對相關(guān)評估函數(shù)進(jìn)行簡要說明。
2.1 數(shù)據(jù)收集
場景布置在室內(nèi)展館。首先,給游客的智能手機(jī)上安裝導(dǎo)覽App,同時(shí)在展館入口處、展館內(nèi)部的每一個(gè)展品都布置iBeacon,用于獲取游客的位置信息,游客數(shù)據(jù)采集過程如圖1所示。游客智能手機(jī)上的導(dǎo)覽App通過手機(jī)照相機(jī)、加速度傳感器來接收iBeacon所發(fā)送的信號,從而收集游客多種游覽行為數(shù)據(jù)(比如拍照、停留時(shí)間等)。iBeacon設(shè)備就是利用低功耗藍(lán)牙(BLE)通信協(xié)議向周圍發(fā)送自己特有的設(shè)備ID;在iBeacon協(xié)議數(shù)據(jù)中,包含了Minor和Major兩種標(biāo)識(shí)符。在應(yīng)用場景中,將iBeacon設(shè)備進(jìn)行分組,其中Major用來識(shí)別iBeacon設(shè)備屬于哪一組,Minor用來標(biāo)識(shí)同一組內(nèi)的不同iBeacon設(shè)備,即Minor設(shè)置為展館內(nèi)部展品的ID,Major設(shè)置為展品所屬的分區(qū),因此可以通過Minor和Major兩種標(biāo)識(shí)的結(jié)合來對游客當(dāng)前游覽展品的位置信息進(jìn)行定位。

圖1 游客行為數(shù)據(jù)的采集
智能手機(jī)中的應(yīng)用程序接收到iBeacon設(shè)備廣播信號,然后智能手機(jī)讀取傳感器數(shù)據(jù)并監(jiān)聽拍照廣播,最后通過無線網(wǎng)絡(luò)將采集的數(shù)據(jù)上傳至系統(tǒng)服務(wù)器。當(dāng)有游客進(jìn)行拍照時(shí),智能手機(jī)中的應(yīng)用程序會(huì)立即檢測到拍照行為的發(fā)生,隨后向系統(tǒng)服務(wù)器發(fā)送廣播;系統(tǒng)服務(wù)器根據(jù)接收拍照廣播的次數(shù)和iBeacon的位置標(biāo)識(shí)統(tǒng)計(jì)出游客在某展品的拍照次數(shù),并存儲(chǔ)游客行為數(shù)據(jù)。如圖2所示,收集數(shù)據(jù)的日志中包含了游客與iBeacon交互的時(shí)間戳序列,用戶的行為加速度數(shù)據(jù)和瀏覽展品的標(biāo)識(shí)。
2.2 馬爾科夫決策模型構(gòu)建
通過馬爾科夫決策過程MDP模型對游客在室內(nèi)展館的游覽行為進(jìn)行建模,馬爾科夫決策過程可以用一個(gè)五元組(S,A,p,r,γ)來表示,其五要素的定義如下:
定義1狀態(tài)s表示游客當(dāng)前瀏覽展品的記錄,其狀態(tài)空間為S。
例如:游客剛進(jìn)入展館,狀態(tài)默認(rèn)為s0,其中s0=?;當(dāng)游客瀏覽了展品a1時(shí),則游客的狀態(tài)變?yōu)閟1,其中s1={a1};游客下一個(gè)瀏覽了展品a2,則游客的狀態(tài)變?yōu)閟2,其中s2={a1,a2},以此列推S={s0,s1,s2,…}。
定義2動(dòng)作a表示在狀態(tài)s下,游客下一個(gè)將要瀏覽的展品,其動(dòng)作空間為A。
定義3狀態(tài)轉(zhuǎn)移概率p(st+1|st,at)表示從狀態(tài)st通過動(dòng)作at轉(zhuǎn)移到狀態(tài)st+1的概率,其中,st∈S,at∈A。
例如,游客瀏覽展品記錄s1的情況下,接下來想要瀏覽展品a2或者展品a3,那么狀態(tài)轉(zhuǎn)移概率可定義為p(s2|s1,a2)=0.5,p(s3|s1,a3)=0.5。
定義4r(st,at)表示回報(bào)函數(shù),是在游客當(dāng)前瀏覽展品記錄st下,瀏覽展品at后所能獲得的回報(bào),其中,st∈S,at∈A。這個(gè)回報(bào)值與游客偏好值成正比,也就是說游客對展品at的偏好越高,那么回報(bào)值也就越高。為了方便計(jì)算,定義r(st,at)≤1。
定義5γ∈[0,1]代表折扣因子,用來計(jì)算累積的回報(bào)。
游客與展館內(nèi)展品的交互過程可看作一個(gè)馬爾科夫決策過程,如圖3所示。

圖3 馬爾科夫決策過程模型
游客從進(jìn)入展館內(nèi)開始,瀏覽記錄默認(rèn)為s0。當(dāng)瀏覽展品a1時(shí),會(huì)有相應(yīng)的拍照次數(shù)和停留時(shí)間;將拍照次數(shù)和停留時(shí)長作為特征值加入回報(bào)函數(shù)中,計(jì)算出回報(bào)值r1,并更新游客瀏覽記錄s1;然后游客瀏覽下一個(gè)展品a2,以相同的方式計(jì)算出回報(bào)值r2,游客瀏覽記錄相應(yīng)地變?yōu)閟2,一直交互下去,因此游客瀏覽時(shí)的交互序列如式(1)所示,其中s0,s1,…,st-1,st∈S。
馬爾科夫性是指下一個(gè)時(shí)刻游客瀏覽的展品記錄st+1,只取決于當(dāng)前時(shí)刻游客瀏覽過的展品記錄st和正在瀏覽的展品at,其他所有的歷史瀏覽過的展品記錄都可以被丟棄。如式(2)所示,其中p(st+1|st,at)為游客瀏覽展品的轉(zhuǎn)移概率:
而在各狀態(tài)下如何選擇動(dòng)作at的這一規(guī)則是由策略π決定的,見定義6。
定義6策略(policy)定義為π:S→A,代表游客瀏覽展品記錄的狀態(tài)空間到游客下一個(gè)瀏覽展品的行為映射。通過式(3)可知,策略π是指在給定狀態(tài)s時(shí),動(dòng)作集上的條件概率分布,即策略π可以在每個(gè)狀態(tài)s上指定一個(gè)動(dòng)作的概率,也就是策略π可以根據(jù)游客瀏覽展品的記錄s來決定下一步推薦給游客的展品a:
例如,一個(gè)游客瀏覽展品的策略為π(a2|s1)=0.3,π(a3|s1)=0.7,這表示游客在瀏覽記錄s1的情況下,瀏覽下一個(gè)展品a2的概率為0.3,瀏覽展品a3的概率為0.7,顯然游客瀏覽展品a3的可能性更大。
在給定策略π和馬爾科夫決策過程模型的基礎(chǔ)上,就可以確定一條游客游覽展品的交互序列τ:
游客瀏覽展品的交互序列所能獲得的累積回報(bào)為G(τ),總回報(bào)G(τ)如式(5)所示,其中rt表示游客瀏覽的第t個(gè)展品所獲得的回報(bào)。
因此,目標(biāo)就是學(xué)習(xí)出一個(gè)最優(yōu)策略π*,使得累積回報(bào)值G(τ)達(dá)到最大。但是,在當(dāng)前求得的策略π下,假設(shè)從狀態(tài)s1出發(fā),游客的瀏覽展品狀態(tài)序列可能如圖4所示。

圖4 游客瀏覽展品狀態(tài)序列示意圖
此時(shí),在策略π下,利用式(5)可以計(jì)算出累積回報(bào)G(τ);通過圖4可知,游客瀏覽展品的交互狀態(tài)序列存在多種可能性,所以此時(shí)計(jì)算出來的G(τ)也存在多種可能值,因此無法通過累積回報(bào)G(τ)評估當(dāng)前策略π是否最優(yōu),但是累積回報(bào)的期望是一個(gè)確定值,可以用來評估。因此在一個(gè)狀態(tài)s下,基于特定策略π,做出行為a得到累積回報(bào)的期望值可由式(6)得到:
因此,當(dāng)Q值達(dá)到了最大即Qmax時(shí),所求的策略π為最優(yōu)。
但是現(xiàn)實(shí)中很多情況下回報(bào)函數(shù)是未知的,用戶瀏覽某個(gè)展品時(shí),未必會(huì)給出反饋,因此,很多時(shí)候回報(bào)函數(shù)難以定義。針對此問題,可采用逆向強(qiáng)化學(xué)習(xí)算法來解決,根據(jù)已有的游客瀏覽展品相關(guān)軌跡示范數(shù)據(jù)學(xué)習(xí)出對應(yīng)的回報(bào)函數(shù)。
3 基于逆向強(qiáng)化學(xué)習(xí)的游客行為偏好學(xué)習(xí)
3.1 逆向強(qiáng)化學(xué)習(xí)
逆向強(qiáng)化學(xué)習(xí)是一個(gè)未知回報(bào)函數(shù)的馬爾科夫決策過程(MDP ),可以用一個(gè)四元組(S,A,p,γ)來表示。當(dāng)專家在完成某項(xiàng)任務(wù)時(shí),其動(dòng)作往往是最優(yōu)或者接近最優(yōu),那么可以假設(shè),當(dāng)所有的策略π所計(jì)算出的累積回報(bào)期望無限接近于專家策略所計(jì)算出的累積回報(bào)期望時(shí),可以認(rèn)為專家示例所學(xué)到的回報(bào)函數(shù)即為所需要的回報(bào)函數(shù)。因此,逆向強(qiáng)化學(xué)習(xí)可以從專家示例中學(xué)習(xí)到回報(bào)函數(shù),也就是在已知狀態(tài)S、行為A、狀態(tài)轉(zhuǎn)移概率為p的條件下,從已有的游客瀏覽展品相關(guān)軌跡數(shù)據(jù)中反推出相對應(yīng)的回報(bào)函數(shù)。也就是使算法產(chǎn)生的游客瀏覽展品軌跡與已有的游客瀏覽展品軌跡相近,這等價(jià)于在某個(gè)回報(bào)函數(shù)下求解最優(yōu)策略π*,在該策略下產(chǎn)生的軌跡與已有的游客軌跡相近,當(dāng)策略達(dá)到最優(yōu)時(shí),游客軌跡的累積回報(bào)達(dá)到最大,所學(xué)到的回報(bào)函數(shù)也達(dá)到最優(yōu)。
因?yàn)榛貓?bào)函數(shù)r(st,at)未知,所以可利用函數(shù)逼近的方法對其進(jìn)行參數(shù)逼近,其逼近形式為
式(7)中,?=(?1,?2,…,?d)T,?:S×A→Rd為數(shù)量有限并且固定有界的特征基函數(shù),d為特征基的個(gè)數(shù),?i為每個(gè)狀態(tài)的特征向量。θ=(θ1,θ2,…,θd)表示各個(gè)特征基之間的權(quán)重向量。通過這樣的線性表示,可以對權(quán)重進(jìn)行調(diào)整,從而改變回報(bào)函數(shù)值。逆向強(qiáng)化學(xué)習(xí)的目標(biāo)是學(xué)習(xí)出權(quán)重向量θ,從而計(jì)算出回報(bào)函數(shù)Rθ(s,a)。
在應(yīng)用的場景中,一共有15個(gè)展品,首先統(tǒng)計(jì)在當(dāng)前狀態(tài)s下,某展品的拍照次數(shù)ms和停留時(shí)間ys(以s為單位)2種游客行為特征。然后,將回報(bào)函數(shù)定義為瀏覽展品時(shí)所產(chǎn)生的瞬時(shí)回報(bào)與在該狀態(tài)下游客瀏覽展品時(shí)的拍照次數(shù)和停留時(shí)間所產(chǎn)生的回報(bào)之和。為了便于計(jì)算,將拍照次數(shù)和停留時(shí)間所產(chǎn)生的回報(bào)通過式(8)將數(shù)據(jù)歸一化,其中:x*代表當(dāng)前狀態(tài)下的拍照次數(shù)或者停留時(shí)間的值,min和max代表在所有狀態(tài)下拍照次數(shù)或者停留時(shí)間的最小值和最大值;
則在當(dāng)前狀態(tài)下的回報(bào)函數(shù)可表示為
將已有的游客瀏覽軌跡處理成“狀態(tài)-動(dòng)作-行為特征”序列。假設(shè)有N個(gè)游客軌跡數(shù)據(jù)D={ζ1,ζ2,…,ζN},每條軌跡數(shù)據(jù)長度為H,則一組軌跡數(shù)據(jù)序列可表示為ζi=((s1,a1,m1,y1),(s2,a2,m2,y2),…,(sH,aH,mH,yH)),其中sH∈S,aH∈A。將每條軌跡數(shù)據(jù)長度H定義為15。例如,一個(gè)游客u的瀏覽軌跡為ζu=((s1,a2,m1,y1),(s2,a4,m2,y2),…,(s15,a1,m15,y15)),則代表游客u在狀態(tài)s1下瀏覽了展品a2,其中在展品a2的拍照次數(shù)為m1,停留時(shí)間為y1;然后瀏覽了展品a4,其中在展品a4的拍照次數(shù)為m2,停留時(shí)間為y2,以此類推。逆向強(qiáng)化學(xué)習(xí)整體過程如圖5所示。首先,游客在狀態(tài)s下,選擇動(dòng)作a所能獲得的回報(bào)R(s,a)往往是未知的,因此需要通過專家示例(已有的相關(guān)游客瀏覽展品的軌跡數(shù)據(jù))來學(xué)習(xí)到背后的回報(bào)函數(shù)。而在學(xué)習(xí)過程中,加入了拍照次數(shù)、停留時(shí)間2種游客行為特征來進(jìn)行訓(xùn)練;最后通過逆向強(qiáng)化學(xué)習(xí)算法,學(xué)習(xí)出回報(bào)函數(shù)Rθ(s,a)。
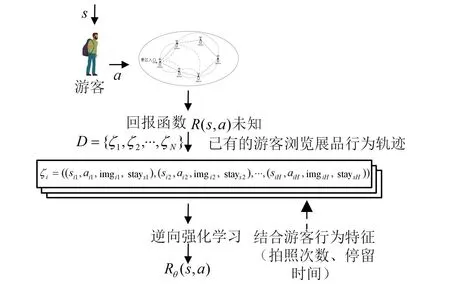
圖5 逆向強(qiáng)化學(xué)習(xí)過程示例圖
3.2 最大似然逆向強(qiáng)化學(xué)習(xí)
根據(jù)Babes等[13]提出的最大似然逆向強(qiáng)化學(xué)習(xí)(maximum likelihood inverse reinforcement learning,簡稱MLIRL)算法并結(jié)合游客行為特征(拍照次數(shù)、停留時(shí)間)來學(xué)習(xí)θ。最大似然逆向強(qiáng)化學(xué)習(xí)算法與貝葉斯逆向強(qiáng)化學(xué)習(xí)[16]類似,采用了一種概率模型,通過θ創(chuàng)建一個(gè)值函數(shù),然后假設(shè)專家在單個(gè)操作選擇級別隨機(jī)化;與最大熵逆向強(qiáng)化學(xué)習(xí)類似[12],在已知專家軌跡的情況下,求出產(chǎn)生該軌跡分布的最大似然模型;與策略匹配類似,它使用梯度方法求得用戶行為策略,并在訓(xùn)練的過程中,用戶行為策略不斷向?qū)<也呗钥拷R虼?最大似然逆向強(qiáng)化學(xué)習(xí)融合了其他逆向強(qiáng)化學(xué)習(xí)模型的特點(diǎn),且可在專家軌跡較少情況下對回報(bào)函數(shù)進(jìn)行估計(jì),通過專家軌跡尋找出最大似然模型,并不斷對初始的回報(bào)函數(shù)進(jìn)行調(diào)整,通過梯度不斷優(yōu)化策略π。因此,在一個(gè)狀態(tài)s下,做出行為a得到累積回報(bào)期望可表示為
在MDP中,動(dòng)作定義為下一個(gè)瀏覽的展品,所以動(dòng)作空間并不大,因此采用玻爾茲曼分布作為策略,可表示為
在此策略下,基于已有的游客瀏覽展品相關(guān)軌跡示范數(shù)據(jù)的對數(shù)似然估計(jì)函數(shù)可表示為
因此,最大似然逆向強(qiáng)化學(xué)習(xí)算法是通過梯度上升的方法求出函數(shù)中θ的最大值,即θ=argmaxθL(D|θ)。
在給定的馬爾科夫決策模型中,通過已有的游客瀏覽展品相關(guān)軌跡示范數(shù)據(jù)得到的最優(yōu)回報(bào)函數(shù)可能存在多個(gè);而MLIRL算法可以對觀測到的行為分配較高的權(quán)重,對于未觀測到的值分配較低的權(quán)重,從而解決回報(bào)函數(shù)不唯一的問題。MLIRL算法即極大似然逆向強(qiáng)化學(xué)習(xí)(maximum likelihood inverse reinforcement learning,簡稱MLIRL)如下所示。
4 實(shí)驗(yàn)
4.1 實(shí)驗(yàn)條件
客戶端應(yīng)用程序使用的是Android studio開發(fā),JDK1.7版本,運(yùn)行在Android智能手機(jī)系統(tǒng)版本6.0.1。相關(guān)應(yīng)用程序運(yùn)行在JetBrains PyCharm上。15個(gè)基于CC2541的iBeacon。
4.2 實(shí)驗(yàn)環(huán)境
應(yīng)用場景布置在一個(gè)具有15個(gè)展品的室內(nèi)展館,每個(gè)展品都提前安裝了iBeacon。本研究邀請了35名年齡段在20~22周歲的女大學(xué)生作為志愿者參觀展館,并且進(jìn)入展館前在他們的智能手機(jī)中裝上采集數(shù)據(jù)App。同時(shí),給每個(gè)志愿者發(fā)一份調(diào)查問卷,便于后期處理的時(shí)候獲取他們對展品的真實(shí)偏好。
4.3 參數(shù)設(shè)置
在實(shí)驗(yàn)中,將折扣因子γ設(shè)置為0.6。在MLIRL算法中,將參數(shù)β設(shè)置為0.75,步長λt=1/。
4.4 實(shí)驗(yàn)結(jié)果分析
4.4.1 游客偏好學(xué)習(xí)
利用調(diào)查問卷的形式獲取游客對展品的實(shí)際偏好排名。表1為選取的35位女大學(xué)生對15個(gè)展品的平均偏好排名。

表1 游客對15個(gè)展品偏好平均排名
若MDP模型得出的志愿者對某個(gè)展品偏好排名與調(diào)查問卷中的排名一致,則定義平均偏好準(zhǔn)確率為n/m;其中,n為MDP模型中學(xué)習(xí)出志愿者展品偏好排名與調(diào)查問卷中排名一致的總個(gè)數(shù),m為總的展品數(shù)。
將35位志愿者的軌跡數(shù)據(jù)進(jìn)行訓(xùn)練,從而得出志愿者的平均偏好準(zhǔn)確率分布,結(jié)果如圖6所示,其中,將僅包含了游客瀏覽點(diǎn)的數(shù)據(jù)記為原始數(shù)據(jù)。將原始數(shù)據(jù)訓(xùn)練出來的結(jié)果與每個(gè)瀏覽點(diǎn)加入游客行為特征(拍照次數(shù)和停留時(shí)間)的數(shù)據(jù)訓(xùn)練出來的結(jié)果做對比。

圖6 平均偏好學(xué)習(xí)準(zhǔn)確率
從圖6可看出,隨著人數(shù)的增加,軌跡數(shù)的增長,游客的平均偏好準(zhǔn)確率呈現(xiàn)出不斷上升的趨勢。加入游客行為特征(拍照次數(shù)和停留時(shí)間)的數(shù)據(jù)與原始數(shù)據(jù)相比,在每個(gè)瀏覽點(diǎn)中加入游客的行為特征所學(xué)習(xí)出的游客偏好性能比之前更好,準(zhǔn)確率提高更快,且在人數(shù)達(dá)到35個(gè)時(shí),游客平均偏好準(zhǔn)確率達(dá)到53.3%,這也表明在真實(shí)軌跡較少情況下,該算法在結(jié)合了游客行為特征,能夠較好地從游客的軌跡中學(xué)習(xí)出年齡段在20~22周歲的女學(xué)生對展品的平均偏好。在實(shí)際應(yīng)用中,隨著游客人數(shù)的增加、展館展品的增多,本方法對游客偏好的學(xué)習(xí)比傳統(tǒng)的調(diào)查問卷方式更有優(yōu)勢,軌跡數(shù)越多,偏好學(xué)習(xí)的結(jié)果也會(huì)更加全面、客觀。
4.4.2 游客行為特征對偏好學(xué)習(xí)的影響
在實(shí)驗(yàn)中,主要加入了2種游客行為特征:拍照次數(shù)和展品游玩時(shí)間。為了驗(yàn)證哪種特征對實(shí)驗(yàn)的效果影響更大,分別加入一種特征來測試,最后通過展品偏好準(zhǔn)確率來驗(yàn)證。圖7為分別在加入拍照次數(shù)和停留時(shí)間特征的情況下的偏好學(xué)習(xí)準(zhǔn)確率。從圖7可看出,隨著游客人數(shù)的增加,軌跡數(shù)的增多,游客在展品的游玩時(shí)間對偏好學(xué)習(xí)的影響更大,而拍照次數(shù)相對就小一些。

圖7 游客行為特征對實(shí)驗(yàn)效果的影響
4.4.3 基于逆向強(qiáng)化學(xué)習(xí)的游客偏好學(xué)習(xí)模型參數(shù)化
在實(shí)驗(yàn)中,參數(shù)的取值會(huì)對模型的準(zhǔn)確率產(chǎn)生一定影響。因此,為了提高模型的準(zhǔn)確率,對折扣因子γ取不同值來對比模型的準(zhǔn)確率,如表2所示。
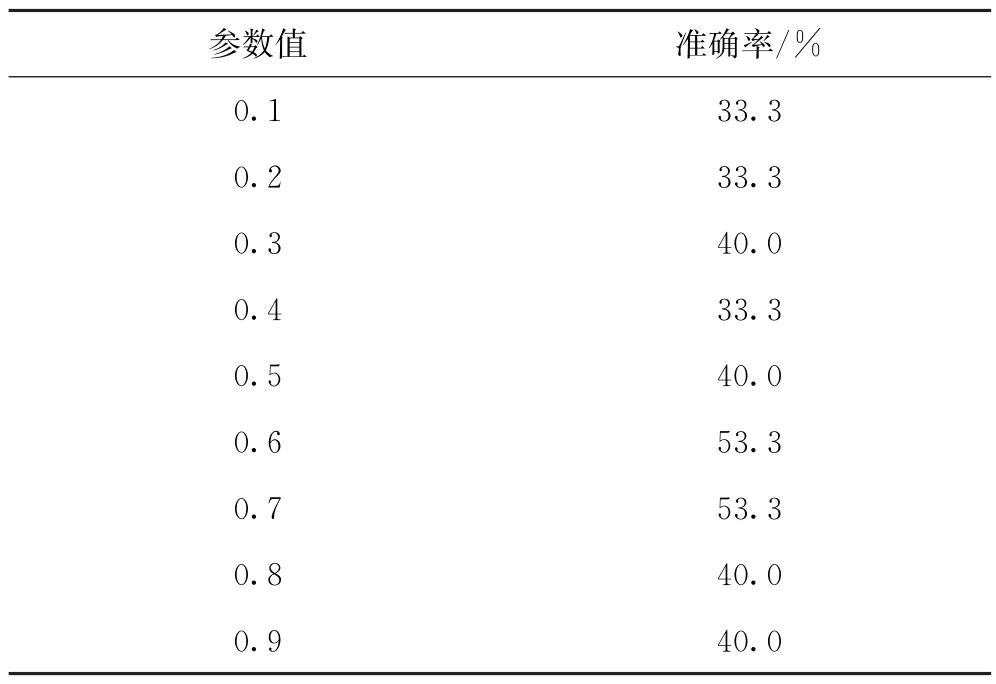
表2 準(zhǔn)確率對比
折扣因子γ代表了未來的回報(bào)相對于當(dāng)前的回報(bào)的重要程度,當(dāng)γ=0時(shí),代表只考慮當(dāng)前的回報(bào),不考慮長期回報(bào);當(dāng)γ=1時(shí),長期回報(bào)和當(dāng)前回報(bào)同等重要;通過表1可知,并不是γ越大越好,當(dāng)γ=0.6和γ=0.7時(shí),偏好學(xué)習(xí)的準(zhǔn)確率最高,為53.3%。
5 結(jié)束語
針對在景區(qū)內(nèi)中難以獲取游客細(xì)粒度偏好的問題,提出一種基于現(xiàn)場游覽行為感知和逆向強(qiáng)化學(xué)習(xí)的游客偏好學(xué)習(xí)方法。利用物聯(lián)網(wǎng)與移動(dòng)傳感器技術(shù)相結(jié)合采集了游客在特定景區(qū)內(nèi)的游覽行為數(shù)據(jù),即拍照次數(shù)和停留時(shí)間。將游客在每個(gè)展品的拍照次數(shù)和停留時(shí)間作為行為特征,將游客行為特征與逆向強(qiáng)化學(xué)習(xí)相結(jié)合,從而實(shí)現(xiàn)從較少的游客數(shù)據(jù)中學(xué)習(xí)出游客細(xì)粒度的偏好。實(shí)驗(yàn)結(jié)果表明,在真實(shí)的場景下,該方法能夠在少量游客游覽行為數(shù)據(jù)的情況下有效學(xué)習(xí)出游客的細(xì)粒度偏好。但是在實(shí)際游覽過程中,天氣的狀況、氣溫的變化、人群的密集度等多種特征都會(huì)影響游客的偏好,因此將來可以綜合性的考慮這些因素,更有效地學(xué)習(xí)出游客細(xì)粒度的偏好。
猜你喜歡
教學(xué)考試(高考化學(xué))(2021年2期)2021-05-30 06:15:52
中學(xué)生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
