基于深度強化學習的對抗攻擊和防御在動態視頻中的應用*
2023-10-21 12:17:50熊水彬
通信技術 2023年9期
熊水彬
(江西理工大學,江西 贛州 341000)
0 引言
深度強化學習是深度學習與強化學習相結合的產物[1],是一種新興的人工智能技術。但是,深度強化學習模型會面臨一些安全性和魯棒性的問題,其中之一就是對抗攻擊和對抗防御[2]。對抗攻擊是指攻擊者針對深度強化學習模型的弱點或缺陷對模型進行攻擊,使得模型產生錯誤的預測或輸出,從而使得深度強化學習模型的效果降低甚至完全失效。對抗防御則是防御者為了保護深度強化學習模型免受對抗攻擊的干擾,降低對抗攻擊帶來的危害,從而采取的一系列防御方法。
對抗攻擊會影響深度強化學習智能體的性能,能夠暴露其內部的弱點和缺陷。在此基礎上進行針對性的對抗防御能夠大大提高面對類似對抗攻擊的防御效果。因此,深入研究深度強化學習模型的對抗攻擊和防御問題,對于提高深度強化學習模型的安全性和魯棒性,保證其在實際應用中的可靠性和穩定性具有非常重要的意義。目前對抗攻擊與對抗防御的研究大多是面向靜態圖像的分類任務,在動態視頻方面的應用研究關注較少。由于Atari 游戲[3]簡單的游戲規則和動態的游戲畫面,因此本文選擇Atari 游戲作為實驗平臺,在Atari 游戲[4]中設計實驗實現深度強化學習模型中的對抗攻擊與對抗防御,在動態視頻方面對對抗攻擊與防御方法進行綜合性探討研究。
1 DQN 算法
深度Q 網絡(Deep Q-Network,DQN)屬于基于值函數的算法[5],它的基本思想是用一個深度神經網絡來表示Q 值函數,輸入數據是一幅圖像或者一個狀態,輸出數據則是對應的選擇各個動作時的Q 值。DQN 使用經驗回放機制和目標網絡來提高學習效率和穩定性,通過梯度下降最小化損失函數來不斷更新網絡權重,從而逼近最優的Q 值函數。
本文利用經驗回放機制[6]、目標網絡和對輸入狀態圖像進行預處理等技巧完成DQN 算法設計。DQN 模型在Atari 中的Pong 游戲上表現得分情況如表1 所示。

表1 不同訓練輪次DQN 模型得分情況
2 對抗攻擊實現
2.1 FGSM 攻擊
快速梯度符號方法(Fast Gradient Sign Method,FGSM)是一種基于梯度的對抗樣本生成方法[7-8]。FGSM 的基本思路是在原始輸入樣本的基礎上計算損失函數對輸入樣本的梯度,然后將梯度符號作為擾動方向,并將梯度的絕對值作為擾動大小,向著使分類結果最差的方向添加擾動,從而得到對抗樣本[9],使得模型對該樣本的分類結果發生錯誤。對抗樣本生成過程如圖1 所示,第1 行原始圖像加上第2 行擾動,得到第3 行的對抗樣本。設x為原始輸入樣本,θ表示模型參數,y表示輸入樣本真實標簽,J(θ,x,y)表示損失函數,sign是符號函數,ε表示擾動的大小。對抗樣本生成公式為:
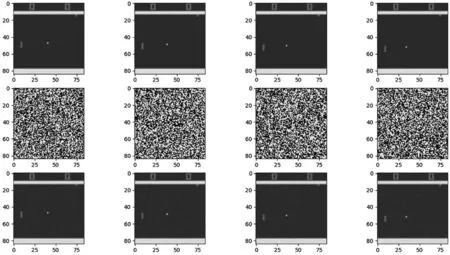
圖1 對抗樣本生成過程
得到對抗樣本后,將對抗樣本作為輸入圖像,輸入到DQN 模型中,繼而影響模型判斷,通過不斷地生成對抗樣本就可達到攻擊模型的效果。
在白盒環境中[10],基于DQN 模型的Q 值和動作張量使用交叉熵損失函數計算出損失函數,然后進行反向傳播得到梯度,再用sign()符號函數得到梯度方向,之后擾動量乘以梯度方向再加上原本狀態張量得到對抗樣本。在實驗過程中還設置了攻擊概率,即對每一幀圖像以一定概率值選擇是否生成對抗樣本。不同概率進行FGSM 白盒攻擊時,實驗結果如表2、表3 和表4 所示。

表2 100%概率進行FGSM 白盒攻擊時擾動量與得分關系
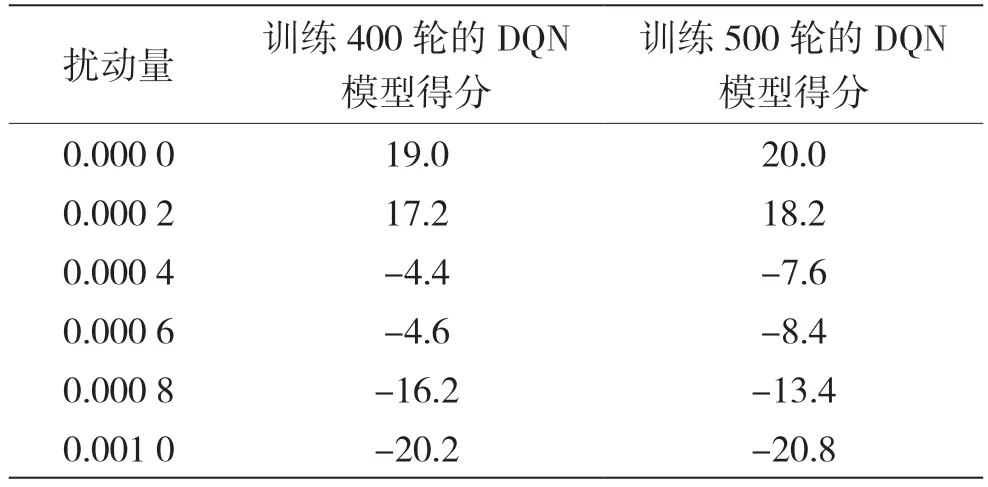
表3 80%概率進行FGSM 白盒攻擊時擾動量與得分關系
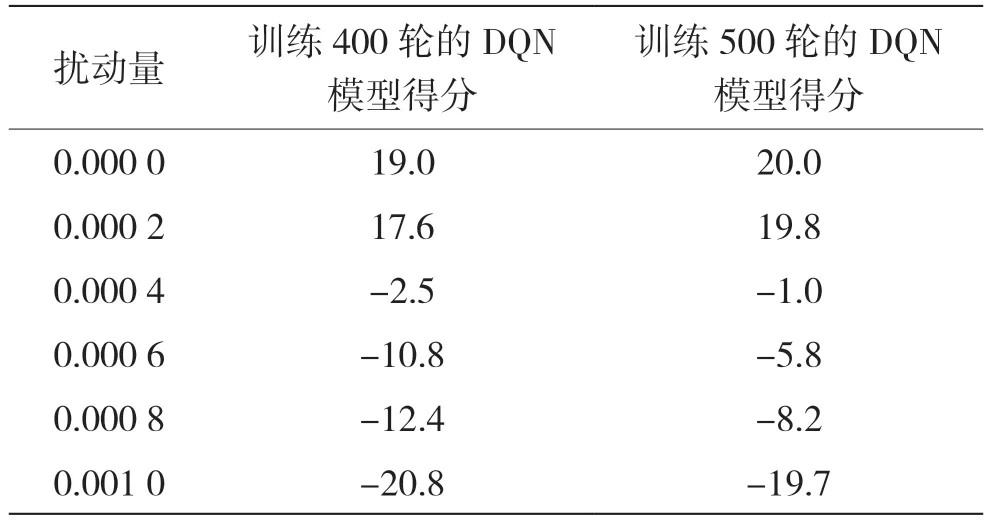
表4 50%概率進行FGSM 白盒攻擊時擾動量與得分關系
在黑盒環境中[11],首先根據游戲觀測畫面得到狀態,然后將該狀態輸入替身模型中得到選擇各個動作的Q 值,再用替身模型計算出選擇的動作,同時將動作轉化為張量類型。然后將該Q 值和動作張量使用交叉熵損失函數計算出損失函數,再進行反向傳播得到替身模型的梯度,將這個梯度作為目標模型的梯度,再用sign()符號函數得到梯度方向,之后擾動量乘以梯度方向再加上原本狀態張量得到最終的對抗樣本。當替代模型為訓練400 輪的DQN模型時,FGSM 黑盒攻擊的實驗結果如表5 所示。
利用FGSM 攻擊方式對輸入圖像進行攻擊擾動,模型效果明顯變差。白盒攻擊時效果都較好,使用很小的擾動量即可以對模型性能造成較大影響;黑盒攻擊的攻擊效果很大部分取決于替代模型,當替代模型越接近最優策略時,攻擊效果就越好。
2.2 PGD 攻擊
投影梯度下降(Projected Gradient Descent,PGD)攻擊是一種迭代的基于梯度的攻擊方法,它通過多次迭代來使攻擊更加精確,適用于求解帶有約束條件的凸優化問題[13]。PGD 攻擊的主要思想是利用梯度下降法在每次迭代時將當前解投影到可行域內,以滿足約束條件,從而得到“最優”的擾動,即輸出最差的結果使模型獲得更低的獎勵。
PGD 攻擊具體的步驟如下:
(1)給定輸入數據為xt、標簽為y及模型的參數為θ;
(2)計算模型的損失函數L(θ,xt,y),并根據損失函數的梯度得到擾動d=?×sign(?xJ(θ,xt+1,y));
(3)利用截斷函數將xt+d投影到一個預定義的范圍內,得到新的輸入樣本xt+1;
(4)以xt+1為輸入,重復步驟(2)~(3),直到達到指定的迭代次數或滿足停止條件。PGD 攻擊可表示為:
式中:Clip為截斷函數。
PGD 攻擊在迭代次數為3、截斷值為0.2 時,不同擾動量對DQN 模型的攻擊結果如表6 所示。
通過比較PGD 攻擊結果與FGSM 攻擊結果,發現PGD 攻擊進行多次小步的迭代得到的對抗樣本效果比FGSM攻擊進行一次一大步的擾動好很多。FGSM 白盒攻擊時,擾動量為0.000 4 時模型被干擾效果僅相當于PGD 迭代3 次、截斷為0.2、擾動量為0.000 2 的效果。可見PGD 攻擊是個強大的對抗攻擊算法。
2.3 單像素攻擊
單像素攻擊(One Pixel Attack)[14]是一種典型的黑盒攻擊方法,只需獲取輸入圖像即可對模型進行攻擊。它的基本思想是通過改變圖像中較少的像素點,甚至只改變其中的一個像素點就能夠實現較好的攻擊效果。
對原始游戲畫面進行像素攻擊后得到的圖像如圖2 所示,其中一個像素點被改變。表7 是進行簡單隨機像素攻擊時,改變像素的個數與得分的關系。
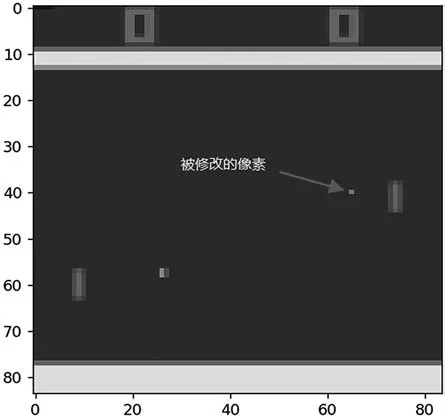
圖2 像素攻擊后Pong 游戲圖像
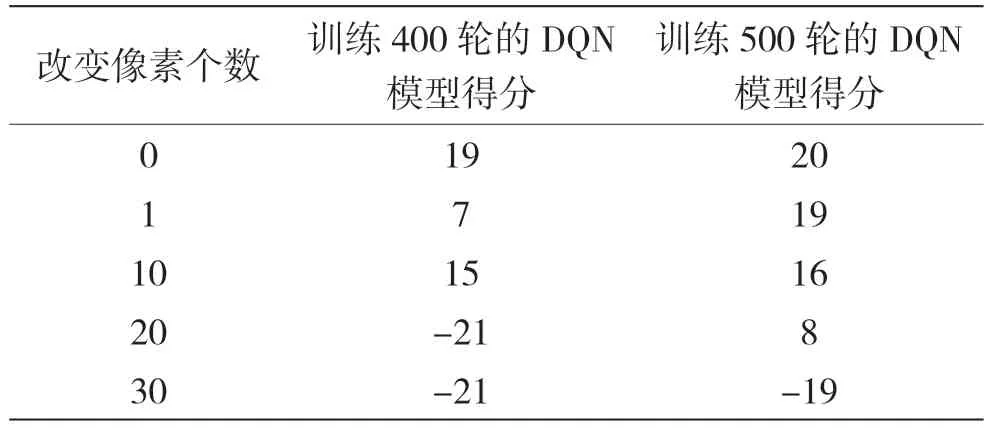
表7 像素攻擊時改變像素數目與得分關系
實驗結果表明,改變圖像像素點的像素攻擊方式可以對DQN 模型進行攻擊,能夠對DQN 模型產生威脅,而且改變的像素個數越多,模型的得分就越低,像素攻擊對模型的攻擊效果就越明顯。
3 對抗防御
3.1 隨機化防御
隨機化防御是一種基于隨機化思想的對抗性防御方法,通過在程序代碼、內存布局、執行文件等多個層面引入隨機性、多樣性和動態性,來消除軟件的同質化現象,實現軟件的多態化,減小或者動態變化系統攻擊面,增加攻擊者漏洞利用難度,能有效抵御針對軟件缺陷的外部代碼注入型攻擊、文件篡改攻擊、數據泄露攻擊、感染攻擊等攻擊。隨機化防御方法的核心思想是對輸入數據進行隨機化,使得攻擊者難以構造有效的對抗樣本。
本文使用高斯數據增強方法對DQN 模型進行隨機化防御[15]。在實驗中,高斯數據增強通過在行為網絡的輸出上使用Pytorch內置的高斯函數添加高斯噪聲來實現,其中高斯噪聲均值為0,標準差為0.01(由交叉驗證方法得出)。進行FGSM 白盒攻擊時,高斯數據增強DQN 模型得分情況如表8 所示,FGSM 黑盒攻擊得分情況如表9 所示,PGD 攻擊得分情況如表10 所示,像素攻擊得分情況如表11所示。

表9 FGSM 黑盒攻擊時模型得分情況

表10 PGD 攻擊時模型得分情況

表11 像素攻擊時模型得分情況
使用高斯數據增強會影響一些DQN 模型的訓練效果,但從實驗結果中可以得到高斯數據增強對FGSM 攻擊、PGD 攻擊和像素攻擊都能有一定的防御能力,尤其對FGSM 黑盒攻擊和像素攻擊防御效果較好。但是整體而言防御效果并不是很顯著,當對抗攻擊強度增大到一定值時,模型性能仍然會受到較大影響。造成該結果可能的原因是訓練輪次不足,使用高斯數據增強訓練時會影響訓練效果,所以需要更多的訓練次數才能使模型達到較好的效果,以及得到更強的防御能力。
3.2 對抗訓練
對抗訓練(Adversarial Training)是一種主動防御方法[16-17],它通過向訓練集中添加對抗樣本,做一次數據增強,使得深度強化學習(Deep Reinforcement Learning,DRL)系統在訓練過程中能夠更好地學習到對抗干擾,從而提高其抵抗能力。對抗訓練方法包括基于FGSM 算法的對抗訓練、基于PGD 算法的對抗訓練等。
對抗訓練的步驟如下:
(1)初始化DRL 策略πθ和對抗攻擊算法A;
(2)從環境中采樣一個狀態s,并使用策略πθ選擇一個動作a;
(3)使用對抗攻擊算法A生成一個對抗觀察sadv=s+δ,其中δ是一個小的擾動,使得πθ(sadv)=πθ(s);
(4)將對抗觀察sadv和原始觀察s加入訓練集中,作為輸入特征;
(5)使用訓練集中的數據更新策略πθ的參數,使其能夠在對抗觀察和原始觀察下都表現良好;
(6)重復步驟(2)~(5),直到策略πθ達到預期的性能或收斂。
對對抗訓練后的DQN模型進行對抗攻擊實驗,進行500 輪對抗訓練的模型防御FGSM 白盒攻擊時得分情況如表12 所示;對抗訓練500 輪的模型防御FGSM 黑盒攻擊的得分情況如表13 所示;進行PGD 攻擊時,對抗訓練500 輪的模型得分情況如表14 所示;進行像素攻擊時,對抗訓練500 輪的模型得分情況如表15 所示。

表12 FGSM 白盒攻擊時防御模型的得分情況

表13 FGSM 黑盒攻擊時各防御模型的得分情況
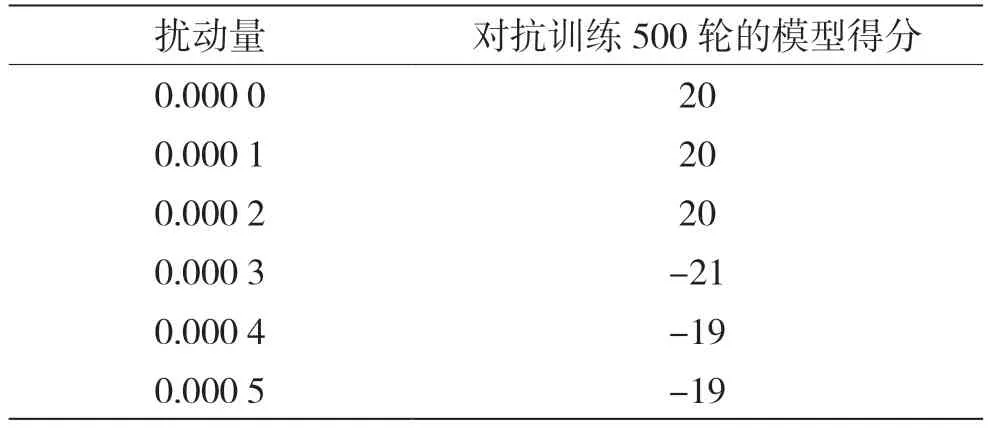
表14 PGD 攻擊時防御模型的得分情況

表15 像素攻擊時防御模型的得分情況
使用基于FGSM 的對抗訓練方法,對FGSM 白盒攻擊與黑盒攻擊這兩種同類型的對抗攻擊具有很強大的防御能力;對于PGD 攻擊也有一定的防御效果,需要擾動量增大到一定值才能對模型產生影響。不過對于像素攻擊,對抗訓練并沒有體現出良好的防御能力。總體而言,經過對抗訓練,模型的魯棒性得到明顯提高,可見對抗訓練防御方法是一種有效的對抗防御方法。
4 結語
本文首先闡述了深度強化學習中的DQN算法,并且在Atari 中的Pong 游戲中訓練了DQN 智能體模型;其次引入對抗攻擊和對抗防御,詳細介紹了FGSM 攻擊、PGD 攻擊、單像素攻擊3 種對抗攻擊方法和對抗訓練、隨機化防御、對抗檢測3 種對抗防御方法,闡述了它們的基本原理,然后對DQN模型進行了對抗攻擊和對抗防御實驗,并且相互之間進行了分析比較。最后得出結論,對抗攻擊可以輕松地影響DRL 模型,能降低DRL 模型的性能,會對DRL 模型產生很大的危害,而對抗防御方法可以在一定程度上提高模型的魯棒性,提高對對抗攻擊的防御能力。
深度強化學習的對抗攻擊與對抗防御是一個不斷發展和改進的領域,需要不斷地進行研究和探索,未來應更加深入研究各種對抗攻擊,尋求破解之道,研究出更加有效的對抗防御方法,讓智能體模型能夠抵御攻擊,不被干擾,發揮出它強大的能力,從而造福社會、造福人類。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
