基于改進YOLOv3的缺陷檢測算法研究
2023-10-18 06:10:04成霄翔宋寶宇
鞍鋼技術 2023年5期
關鍵詞:檢測
成霄翔,宋寶宇
(鞍鋼集團北京研究院有限公司,北京 102211)
近年來,隨著機器視覺和深度學習技術的迅猛發展,機器代替人工的優勢愈發凸顯,對基于深度學習的鋼鐵領域缺陷檢測的相關研究也愈發受到廣大科技人員的重視。對于缺陷檢測,不同于將其視為目標分類任務來求解,提出了一種更實用的基于目標檢測的問題求解算法。目標檢測任務是找出圖像中所有感興趣的目標,確定其位置、大小以及類別信息,即不僅需要輸出圖片中物體的類別信息,還需要得到物體所在的位置信息。此外,由于目標分類針對輸入圖片整體得到輸出,而目標檢測能夠細化到圖片中的物體,因而目標檢測對于輸入圖片中含有混合缺陷的情形仍然適用。
現有的目標檢測算法大致可分為兩類:一是以R-CNN[1]系列為代表的兩階段算法,首先使用區域候選網絡產生候選區域,然后使用檢測網絡對候選區域做缺陷類別分類和位置定位回歸;另一類是以YOLO[2-3]為代表的一階段算法,僅通過卷積神經網絡直接預測不同目標的位置和類別,因其不需要經過區域候選階段,相較于二階段檢測算法,速度更快,但檢測精度較低。結合實際工業應用場景,在鋼鐵缺陷檢測任務中,對檢測速度的考量是衡量缺陷檢測效率的一個重要指標,因此YOLO系列算法更為適用。
然而,聚焦到鋼鐵缺陷檢測中,深度學習算法直接應用到工業環境中需要一定的策略。由于工業檢測對實時性要求較高,因此適用于工業環境的算法設計必須考慮算法的高效性,這就需要研究網絡結構輕量化策略來減少計算量提升效率。此外,由于鋼鐵領域生產線的全流程性,必須充分衡量當前產線缺陷檢測的誤檢率和漏檢率,以最大化降低缺陷產品對后續工序的影響,因此針對缺陷數據集特點提升準確率也是需要研究的方向。
綜上,本文針對鋼鐵領域的缺陷檢測任務,研究YOLOv3[3]目標檢測算法從輕量化設計和提升檢測精度兩個維度的自適應改進,推動算法落地應用。
1 YOLOv3算法原理
1.1 網絡結構
YOLOv3總體上將目標檢測任務視為回歸問題。其基本思路為將輸入圖像分成S×S大小的網格,每個單元格負責檢測中心點落在該單元格中的目標。首先將輸入圖片經過特定的骨干網絡提取特征,并結合多尺度預測策略,得到分別為原始圖片1/8、1/16、1/32分辨率的特征圖。之后分別在三種維度的特征圖上同時預測類別概率和定位概率。
YOLOv3網絡框架結構如圖1所示,其中DBL由卷積層、批歸一化層和非線性激活函數Leaky ReLu組成。Res_n是指包含n個殘差單元的殘差塊,每個殘差單元包含2個DBL單元和一個快捷鏈路。Conv是指1×1卷積操作,Concat為張量拼接操作。

圖1 YOLOv3網絡框架結構圖Fig.1 Structure Diagram of YOLOv3 Network Framework
YOLOv3使用自定義的Darknet53網絡提取圖像特征,并在此過程中進行對原始圖片的下采樣。Darknet-53網絡由3×3和1×1卷積連接而成,共有53層卷積層,并借鑒了ResNet的殘差結構,使得網絡層數加深時不會出現梯度消失或者爆炸的現象。此外為了降低池化操作帶來的梯度負面影響,舍棄了池化操作,使用步長為2的卷積進行下采樣。
YOLOv3 借鑒了特征金字塔(FPN)[4]的思想進行多尺度預測,相對于之前版本,尤其提升了對小缺陷目標的檢測性能。通過將經過上采樣的深層特征和淺層特征進行融合,對原始圖片分別進行32、16和8倍下采樣,相應得到原始圖片的1/32、1/16、1/8三種不同分辨率特征圖,從而實現對大、中、小目標的檢測。
以將輸入圖片映射到1/32分辨率為例 (圖2),若輸入圖片為416×416,則經過骨干網絡提取特征后,特征圖大小為13×13,這樣便實現了對輸入圖片劃分網格的操作。每一網格負責檢測中心點落在該網格內的物體,并且輸出三個邊界框,每個網格的輸出分別對應一個多維向量,包含邊框坐標、邊框置信度和目標類別概率。為了降低網絡訓練的難度,YOLOv3根據數據集,通過K-均值聚類算法生成九個錨框,分別應用于三個特征尺度,作為該尺度下預測框的先驗知識。在錨框的基礎上,模型對錨框進行微調,計算相對于錨框的偏移量得到預測框。

圖2 網絡輸出結果示意圖Fig.2 Schematic Diagram of Network Output Results
由于網絡對同一個目標可能進行多次檢測,通過非極大值抑制(NMS)算法消除重疊較大的冗余的預測框,得到最終輸出。其基本思想是,如果有多個預測框都對應同一個物體,則只選出得分最高的預測框,丟棄剩余預測框。其算法流程如下:
(1)從所有候選框中選取置信度最高的預測邊界框B1作為基準,將所有和B1重疊程度超過指定閾值的其他邊界框移除;
(2)從所有候選框中選取第二置信度的邊界框B2作為基準,將所有和B2重疊程度超過指定閾值的其他邊界框移除;
(3)重復上述操作,直至所有預測框都被當成基準。
1.2 損失函數
YOLOv3將目標檢測定義為回歸問題,損失函數包含三部分目標定位損失 ,目標置信度損失和目標分類損失。目標定位損失衡量的是預測框和真實框之間偏移量。目標置信度損失為預測框的類別概率和預測框的置信度相乘而來,不僅表征是否含有目標,還包含預測框與真實框的接近程度。目標分類損失則用于衡量預測框的類別。
2 YOLOv3算法改進
2.1 輕量化改進
2.1.1 骨干網絡輕量化改進
針對圖像進行的卷積操作,標準卷積操作是將卷積核作用在所有的輸入通道上,而深度可分離卷積則是將標準卷積拆分為一個深度卷積和一個逐點卷積,通過將卷積核拆分成單通道的形式,在不改變輸入特征圖像的深度的情況下,對每一通道進行卷積操作,這樣就得到了和輸入特征圖通道數一致的輸出特征圖。逐點卷積就是1×1卷積,進一步對特征圖進行升維和降維(圖3展示了深度可分離卷積的構成)。因此深度可分離卷積的整體效果和一個標準卷積相差不多,但是能夠大大減少模型的參數量和計算量。

圖3 深度可分離卷積構成圖Fig.3 Composition Diagram of In-depth Separable Convolution
原始的YOLOv3(YOLOv3-Darknet53)中采用了Darknet-53網絡來提取特征,該網絡為標準的卷積結構,卷積運算部分計算量大。針對上述問題,采用卷積操作為深度可分離卷積的MobileNet[5]網絡作為骨干網絡。
2.1.2 檢測尺度改進
通常情況下,為了能夠檢測到不同尺度的目標框,需要進行多尺度預測,這也是原始YOLOv3通過多尺度檢測能夠提升對小缺陷目標檢測能力的創新性所在。在進行預測框的先驗計算時,K-means算法聚類得到9個錨框,按照面積大小均勻應用到三個不同尺度的特征圖中。小分辨率的特征圖(13×13)由于其下采樣倍數大,感受野較大,因此分配大尺度的三個錨框 (16×90)、(156×198)、(373×326),用于檢測大缺陷目標。中等分辨率和小分辨率的特征圖(26×26,52×52)則分別用于檢測中等大小的目標和小缺陷目標,如表1所示。

表1 多尺度預測中錨框的初值(圖片大小為416×416×3)Table 1 Initial Value of Anchor Frame in Multi-scale Prediction (Picture Size 416×416×3)
對大多數數據任務而言,由于錨框使用從大型COCO數據集上聚類得到的三種尺度的錨框,適合檢測大、中、小三尺度的缺陷,錨框參數具有代表性,因此無需進行更改。然而,對于鋼鐵領域的表面缺陷檢測,數據集的缺陷尺度并非如此分布。缺陷大小不能天然地分出層級,小缺陷目標并不常見。
因此,為了進一步減少模型參數量和計算量,將原始網絡中三個尺度預測減少為兩個尺度的預測,只進行32倍和16倍下采樣,去除針對小缺陷目標的檢測分支,得到針對中等缺陷目標和大缺陷目標的特征圖檢測分支。改進后的網絡結構如圖4所示。
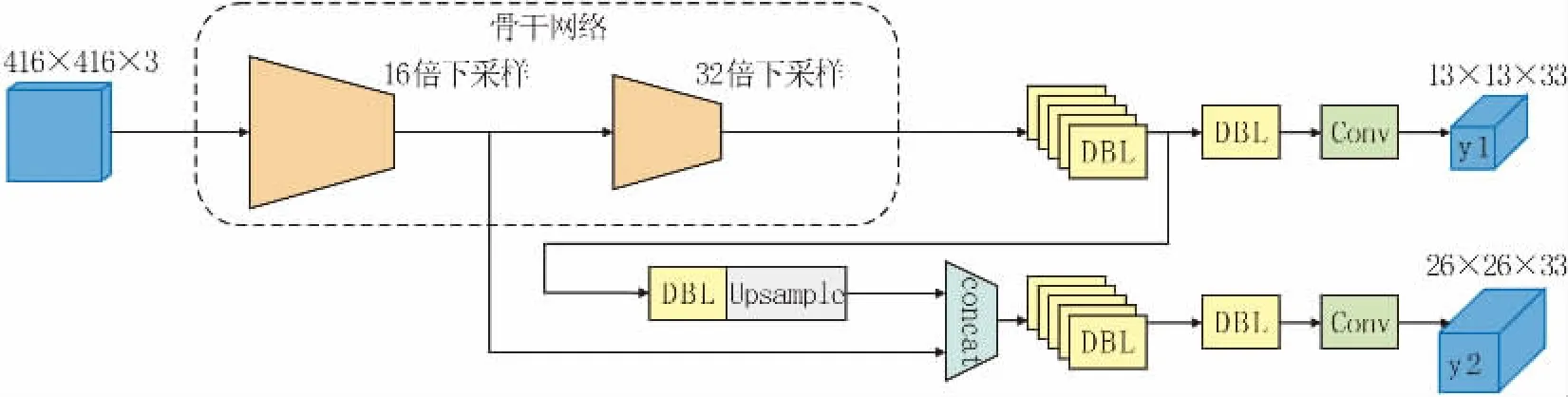
圖4 改進后的網絡結構圖Fig.4 Network Structure Diagram after Improvement
2.2 檢測效果提升
由于鋼鐵缺陷成因復雜且類型多樣,部分缺陷類別圖片呈現出背景干擾且無固定形狀的特征。此外,由于部分缺陷樣本類間差異較小,容易導致分類錯誤,為檢測增加了難度。針對這種類別錯檢的情況,引入對分類損失函數進行類別加權的策略,通過加大對某種類別的懲罰來進一步約束模型的訓練過程,進而提升檢測精度,緩解模型在目標檢測中出現的漏檢問題。
對數據集中的缺陷類別,默認類別的重要程度均相等。在損失函數中對類別加權則是將某一類別賦予更大的權重,如果該類出錯則損失函數增大更多,增加了誤判成本。
具體而言,YOLOv3的目標分類損失lossclass中,默認類別權重數組為:
其中,數組長度為數據集的缺陷類別數。如果第i類缺陷的檢測精度較低,且該類缺陷圖像上呈現出缺陷特征不明顯,與其他類別缺陷類間差異較小,則在類別權重數組中將該類缺陷的權重設為α(α>1),此時類別權重數組更新為:
之后重新開始訓練網絡。
3 實驗及結果分析
3.1 數據集
訓練和測試所采用的數據集為東北大學表面缺陷檢測數據集(NEU-DET)[6]。 該數據集包含六種典型的熱軋帶鋼表面缺陷,分別為開裂(Crazing,Cr)、夾雜(Inclusion,In)、斑塊(Patches,Pa)、點蝕(Pitted Surface,PS)、氧化鐵皮壓入(Rolled-in Scale,RS)和劃痕(Scratches,Sc)。 每種缺陷圖像各有 300 張,將數據集按照8:1劃分,則訓練集1 600張,驗證集200張。NEU-DET數據集部分圖片如圖5所示。

圖5 NEU-DET數據集部分圖片Fig.5 Some Pictures of Neu-det Data Set
3.2 實驗環境
在PaddlePaddle深度學習框架上進行實驗,并在 Win10系統 NVIDIA GTX 3080 GPU,11th Gen Intel(R)Core (TM)i9-11950H@2.60 GHz處理器的筆記本電腦中完成訓練和測試。
3.3 結果分析
3.3.1 輕量化改進相關實驗及結果分析
對于輕量化改進,輕量化網絡應在保證檢測精度的前提下,具有參數量少,計算量小,推理時間短的特點。其中參數量為模型所需要學習的參數總數,計算量用浮點運算數(floating point operations,FLOPs)來衡量,表征算法的復雜度。推理時間是指模型處理一張圖片所需時間,根據推理時間也可得到模型的推理速度,即每秒內可以處理的圖片數量。檢測精度用平均精確度均值 (mean Average Precision,mAP)來衡量,其計算公式如下:
式中,TP為被正確預測的正樣本;FP為被錯誤預測為正樣本的負樣本;FN為被錯誤預測為負樣本的正樣本;n為檢測類別數;AP為各類的檢測精度。
輕量化改進涉及到原始YOLOv3算法(YOLOv3-Darknet53),骨干網絡更換后的YOLOv3算法(YOLOv3-Mobilenetv3)以及更改檢測尺度的YOLOv3算法。
實驗表明,將骨干網絡從Darknet53更換為輕量級網絡Mobilenet,模型的檢測精度在千分位量級的誤差上沒有差異,但是后者的參數量、計算量以及推理時間均有所減小。輕量化改進模型結果對比如表2所示,可以看出改進算法對生產環境中的輕量化部署和實時檢測需求更為適用。

表2 輕量化改進模型結果對比(圖片大小為416×416×3)Table 2 Comparison of Results of Lightweight Improved Model(Picture Size 416×416×3)
對檢測尺寸的更改是基于對數據集的分析,將原始的Pascal VOC數據集[7]和本實驗所用的NEUDET數據集分別采用K-Means算法聚類出9個錨框并進行可視化,如圖6所示。

圖6 VOC數據集和NEU-DET數據集分布情況對比Fig.6 Comparison of Distribution between VOC Data Set and NEU-DET Data Set
Pascal VOC數據集聚類得到的錨框按照面積排列有大、中、小三個尺度,適合原始YOLOv3輸出三種分辨率下特征圖的多尺度檢測策略。而NEUDET數據集按照面積難以區分為三個尺度,且沒有過于狹小的缺陷。因此,相對于原始YOLOv3中的多尺度檢測檢測策略,將改進后的YOLOv3算法檢測尺度調整為2。其和檢測尺度為3的YOLOv3算法對比見表2。改進后的網絡模型更為輕量,且減少了由于數據集中部分目標大小相近而導致的標簽重寫現象[8],檢測精度有所提升。
3.3.2 檢測精度提升相關實驗及結果分析
統計各類別的檢測精度,類別權重對模型檢測精度的影響如表3所示。
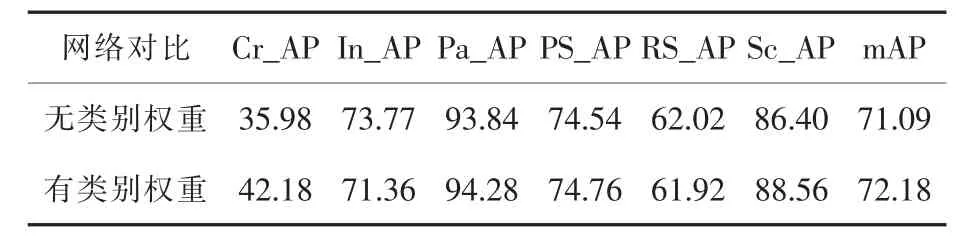
表3 類別權重對模型檢測精度的影響(圖片大小為 416×416×3)Table 3 Comparison of Results of Lightweight Improved Model(Picture Size 416×416×3) %
由表3可以看出,開裂(Cr)類別的檢測精度是最低的。因此,將YOLOv3損失函數中的原始類別權重數組 [1.0,1.0,1.0,1.0,1.0,1.0]調整為[10.0,1.0,1.0,1.0,1.0,1.0],其中數組的第一個位置為開裂類別。實驗表明,由于該類別的分類權重遠高于其他類別,所以在訓練過程中加大了對該類別出錯的懲罰,對該類別的檢測精度有所提高。
3.3.3 部分檢測結果展示
使用改進的YOLOv3算法得到的部分檢測結果圖如圖7所示。訓練好的模型不僅能夠檢測到各類別缺陷,而且對于包含混合缺陷的圖像也能得到較好的檢測效果。

圖7 部分檢測結果圖片Fig.7 Pictures of Some Test Results
由圖7(c)可以看出,斑塊類別樣例包含斑塊和夾雜缺陷,可見本文模型能很好地檢測到混合缺陷,也進一步驗證了相較于將缺陷檢測視為圖片分類而言,將其視為目標檢測更能夠正確檢測圖片中存在混合缺陷的情形。
4 結語
鋼鐵領域缺陷檢測是保證鋼鐵生產質量的重要環節,通過目標檢測算法來得到缺陷的類別和信息具有重要意義。以東北大學帶鋼表面缺陷數據集(NEU-DET)為實驗對象,開展YOLOv3算法在實際生產環境中的自適應改進,進一步降低了模型的參數量和計算量,從提高單一類別的性能著手,提升了檢測精度。通過實驗驗證了改進后的YOLOv3算法更能滿足實際工業場景中輕量化部署以及快速推理的需求。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
