基于XOR 的TAR-CAU 數(shù)據(jù)更新方法
2023-10-14 02:55:16肖逸飛周世杰
電子科技大學(xué)學(xué)報(bào) 2023年5期
關(guān)鍵詞:實(shí)驗(yàn)
肖逸飛,周世杰
(電子科技大學(xué)信息與軟件工程學(xué)院 成都 611731)
糾刪碼(erasure codes)[1-2]是云存儲(chǔ)中一種較為先進(jìn)的數(shù)據(jù)容錯(cuò)技術(shù),相較于傳統(tǒng)的多副本技術(shù),采用糾刪碼提供數(shù)據(jù)冗余存儲(chǔ),會(huì)極大地降低系統(tǒng)的存儲(chǔ)開銷。如QFS 文件系統(tǒng)(qunantcast file system)和MapReduce 框架的數(shù)據(jù)存儲(chǔ)后臺(tái)采用糾刪碼進(jìn)行冗余存儲(chǔ),比原來的HDFS 采用多副本技術(shù)節(jié)省了50%的存儲(chǔ)空間[3]。然而,糾刪碼也引發(fā)了2 個(gè)新問題:數(shù)據(jù)修復(fù)[4]和數(shù)據(jù)更新[5]。在數(shù)據(jù)更新中,由于糾刪碼提供的冗余校驗(yàn)數(shù)據(jù)是多個(gè)原始數(shù)據(jù)的線性變換組合,因此,當(dāng)原始數(shù)據(jù)更新時(shí),為了保證數(shù)據(jù)一致性,其校驗(yàn)數(shù)據(jù)也需要進(jìn)行更新(稱為校驗(yàn)更新)。根據(jù)文獻(xiàn)[6-7]提供的數(shù)據(jù)訪問記錄,可以得出以下兩個(gè)結(jié)論。
1) 更新非常普遍,在大約1.73 億次的寫請(qǐng)求中,超過91%的請(qǐng)求是更新數(shù)據(jù);
2) 更新的數(shù)據(jù)量小,在所有的更新請(qǐng)求中,超過60%的更新小于4 KB。
數(shù)據(jù)中心由成千上萬個(gè)節(jié)點(diǎn)組成,其網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)非常復(fù)雜,數(shù)據(jù)中心的數(shù)據(jù)更新性能往往受到網(wǎng)絡(luò)的限制[8],如何降低校驗(yàn)更新的網(wǎng)絡(luò)開銷是糾刪碼中亟待解決的問題。為了優(yōu)化網(wǎng)絡(luò)開銷,國(guó)內(nèi)外學(xué)者提出了很多數(shù)據(jù)更新方法。如PUM-P 算法是利用更新管理器(update manager)計(jì)算數(shù)據(jù)變化(delta 值),并傳輸delta 值給相關(guān)的校驗(yàn)節(jié)點(diǎn)進(jìn)行更新[9];PDN-P 算法摒棄更新管理器,直接通過數(shù)據(jù)節(jié)點(diǎn)計(jì)算并傳輸delta 值到相關(guān)的校驗(yàn)節(jié)點(diǎn)[9];TUpdate 算法發(fā)現(xiàn)傳統(tǒng)的數(shù)據(jù)傳輸模型是星型結(jié)構(gòu),不利于充分利用網(wǎng)絡(luò)帶寬,同時(shí)容易造成單點(diǎn)瓶頸,因此,將傳輸模型改為樹型結(jié)構(gòu),增加網(wǎng)絡(luò)并行度[10]。文獻(xiàn)[8]提出CAU(cross-rack-aware updates)算法,將數(shù)據(jù)中心的各個(gè)存儲(chǔ)節(jié)點(diǎn)按照機(jī)架(rack)分組,為了減少機(jī)架之間的網(wǎng)絡(luò)開銷,提出了2 種可選的更新方式:
1)校驗(yàn)增量更新(parity-delta update),當(dāng)數(shù)據(jù)機(jī)架(專用于存放數(shù)據(jù)節(jié)點(diǎn))的更新量大于校驗(yàn)機(jī)架(專用于存放校驗(yàn)節(jié)點(diǎn))的更新量時(shí),選擇將同一機(jī)架中的所有delta 值都匯聚到一個(gè)數(shù)據(jù)節(jié)點(diǎn)(數(shù)據(jù)轉(zhuǎn)發(fā)節(jié)點(diǎn)),再由數(shù)據(jù)轉(zhuǎn)發(fā)節(jié)點(diǎn)計(jì)算并轉(zhuǎn)發(fā)校驗(yàn)更新給各個(gè)相關(guān)的校驗(yàn)節(jié)點(diǎn);
2)數(shù)據(jù)增量更新(data-delta update),當(dāng)數(shù)據(jù)機(jī)架的更新量小于校驗(yàn)機(jī)架時(shí),分別將各個(gè)數(shù)據(jù)節(jié)點(diǎn)的delta 值發(fā)送給同一個(gè)校驗(yàn)節(jié)點(diǎn)(校驗(yàn)轉(zhuǎn)發(fā)節(jié)點(diǎn)),再由校驗(yàn)轉(zhuǎn)發(fā)節(jié)點(diǎn)計(jì)算校驗(yàn)更新并轉(zhuǎn)發(fā)給其他校驗(yàn)節(jié)點(diǎn)[8]。
本文的主要目標(biāo)是對(duì)數(shù)據(jù)更新的網(wǎng)絡(luò)傳輸進(jìn)行優(yōu)化,基于CAU 算法的思想,提出了改進(jìn)算法—TAR-CAU,該算法針對(duì)更新數(shù)據(jù)量普遍較小的現(xiàn)象,借鑒tar 打包原理,提出將同一個(gè)節(jié)點(diǎn)中的多個(gè)更新數(shù)據(jù)打包成一個(gè)塊,再利用CAU 算法更新,從而減少網(wǎng)絡(luò)往返時(shí)間,降低發(fā)送端與接收端的更新處理頻率,提高數(shù)據(jù)更新的效率。
本文的主要研究工作有以下3 點(diǎn)。
1) 基于CAU 算法,提出了TAR-CAU 算法。該算法基于XOR 進(jìn)行數(shù)據(jù)更新,同時(shí),利用更新數(shù)據(jù)量小的特點(diǎn),將多個(gè)更新打包傳輸,從而減少網(wǎng)絡(luò)往返次數(shù),提高數(shù)據(jù)更新效率。
2) 實(shí)現(xiàn)原型系統(tǒng)。本文基于Go 語言在Ubuntu 18.04 平臺(tái)實(shí)現(xiàn)了TAR-CAU 原型系統(tǒng),該系統(tǒng)包含中央控制器、算法調(diào)度器和節(jié)點(diǎn)代理的統(tǒng)一調(diào)度框架,不僅可以穩(wěn)定運(yùn)行TAR-CAU 算法,同時(shí),可以方便擴(kuò)展并運(yùn)行其他數(shù)據(jù)更新算法。
3) 驗(yàn)證算法的有效性。本文基于仿真實(shí)驗(yàn)和本地集群實(shí)驗(yàn),利用微軟劍橋研究院和哈佛NSR 提供的真實(shí)數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),與CAU 算法進(jìn)行了對(duì)比,從實(shí)驗(yàn)的結(jié)果來看,本文提出的算法能夠有效提高數(shù)據(jù)更新吞吐量。
1 相關(guān)工作
1.1 糾刪碼概述
糾刪碼也稱為糾錯(cuò)碼,它將原始數(shù)據(jù)編碼為數(shù)據(jù)量更大的編碼數(shù)據(jù),并能利用編碼后的部分?jǐn)?shù)據(jù)恢復(fù)出原始數(shù)據(jù)。糾刪碼一般需要指定n和k兩個(gè)參數(shù),用k份數(shù)據(jù)進(jìn)行編碼,產(chǎn)生n份數(shù)據(jù)。RS 編碼是最經(jīng)典的一種糾刪碼[1],圖1 為一個(gè)典型的RS(5, 3)的云存儲(chǔ)系統(tǒng)(n=5,k=3),其中有3 個(gè)數(shù)據(jù)節(jié)點(diǎn)和2 個(gè)校驗(yàn)節(jié)點(diǎn),每個(gè)節(jié)點(diǎn)中的數(shù)據(jù)都按照大小固定的塊存儲(chǔ)(塊大小一般為1~64 MB),編碼后的數(shù)據(jù)塊與校驗(yàn)塊組成一個(gè)條帶(stripe),大多數(shù)數(shù)據(jù)更新算法都是按照條帶順序一條一條進(jìn)行更新。圖1 展示了一個(gè)條帶信息,其中,di,j表示數(shù)據(jù)塊,pi,j表示校驗(yàn)塊,同一條帶中屬于同一節(jié)點(diǎn)的數(shù)據(jù)塊或校驗(yàn)塊稱為條塊(strip)[11]。

圖1 RS(5, 3)云存儲(chǔ)系統(tǒng)
1.2 數(shù)據(jù)更新
糾刪碼的數(shù)據(jù)更新主要有基于RS 的更新和基于XOR 的更新。
1)基于RS 的更新。基于RS 的更新主要利用范德蒙德矩陣或柯基矩陣生成校驗(yàn)數(shù)據(jù)[3],圖2 為圖1 的編碼過程,其中,

圖2 RS (5, 3)編碼過程
編碼時(shí),利用生成矩陣(generator matrix)左乘各個(gè)數(shù)據(jù)節(jié)點(diǎn)的數(shù)據(jù)向量 (d0,d1,d0),生成碼字(d0,d1,d0,p0,p1), 其中,p0和p1為校驗(yàn)塊,表示為:
當(dāng)數(shù)據(jù)i更新時(shí),用替換di, 或在數(shù)據(jù)節(jié)點(diǎn)i中計(jì)算delta 值(⊕di),然后將delta 值傳輸給pi所在的校驗(yàn)節(jié)點(diǎn),最后計(jì)算出最新的校驗(yàn)數(shù)據(jù)。本文參考的CAU 算法就是基于RS 的數(shù)據(jù)更新。
2)基于XOR 的更新。從式(1)可以看出,基于RS 的更新會(huì)產(chǎn)生大量的乘法運(yùn)算(αj,idi),消耗CPU 資源。因此,可以利用有限域(galois field)將所有的乘法和加法運(yùn)算轉(zhuǎn)化為XOR 運(yùn)算[12-13]。
如圖3 所示,利用 G F(23)的矩陣表示法可以將柯基矩陣轉(zhuǎn)換為位矩陣(binary distribution matrix,BDM), GF(23)表示所有數(shù)據(jù)均用3 位2 進(jìn)制數(shù)表示,數(shù)據(jù)范圍為0~7。
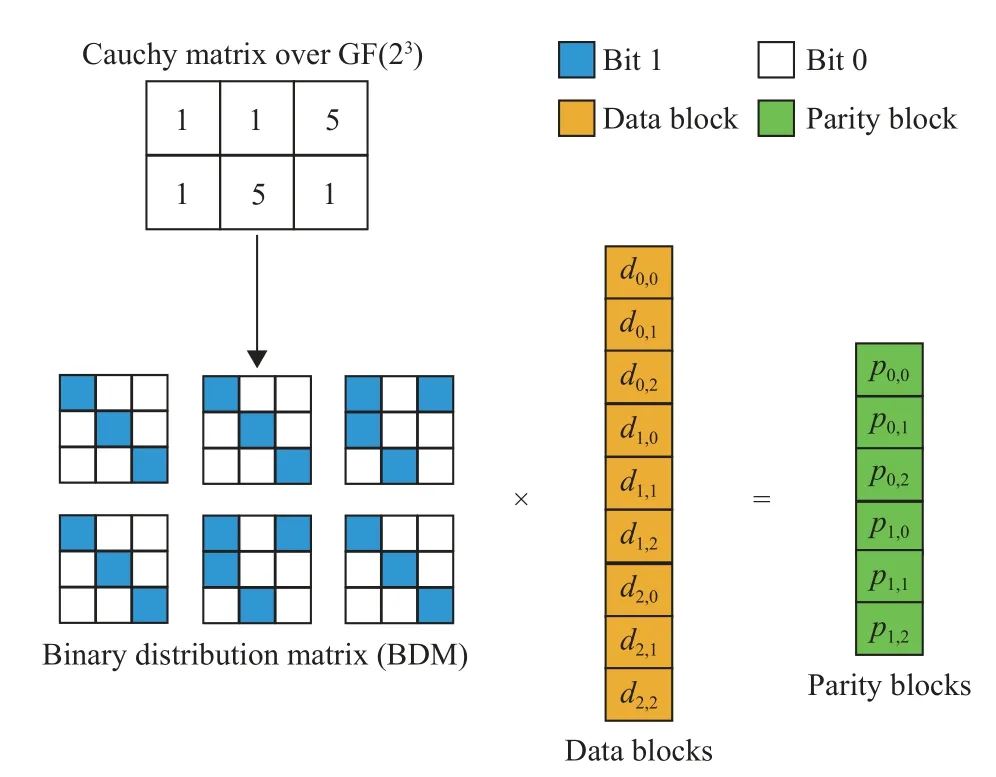
圖3 基于XOR 的編碼
圖中,深色表示1,白色表示0,這樣,所有的校驗(yàn)數(shù)據(jù)都可僅用XOR 公式表示:
基于XOR 的數(shù)據(jù)更新方法僅依賴簡(jiǎn)單的XOR 運(yùn)算,CPU 可以直接執(zhí)行XOR 操作,相比于乘法運(yùn)算,XOR 運(yùn)算效率更高,因此,數(shù)據(jù)更新效率也更高。同時(shí),根據(jù)文獻(xiàn)[3]研究表明,基于異或的編碼方式更適合采用現(xiàn)代CPU 的SIMD技術(shù)執(zhí)行并行加速計(jì)算。如采用AVX2 指令,可同時(shí)進(jìn)行256 位異或運(yùn)算。本文在一臺(tái)配有4 核2.2 GHz Intel CPU、16 GB DDR3 內(nèi) 存、1 TB SSD 存儲(chǔ)的Mac 操作系統(tǒng)環(huán)境中進(jìn)行測(cè)試,發(fā)現(xiàn)采用AVX2 指令、基于XOR 進(jìn)行數(shù)據(jù)更新,更新1 MB 的數(shù)據(jù)僅需20 ms,而采用基于RS 的數(shù)據(jù)更新,需要300 ms。因此,與CAU 不同,本文選擇基于XOR 進(jìn)行數(shù)據(jù)更新。
2 基于XOR 的TAR-CAU 算法
CAU 算法的核心思想可以用圖4 表示,如前所述,CAU 按照節(jié)點(diǎn)所在的機(jī)架進(jìn)行分組,其中,Ri和Rj分別表示數(shù)據(jù)節(jié)點(diǎn)機(jī)架和校驗(yàn)節(jié)點(diǎn)機(jī)架,CAU 并不是實(shí)時(shí)處理每一個(gè)更新請(qǐng)求,而是設(shè)置了一個(gè)批處理閾值(如100),當(dāng)請(qǐng)求數(shù)量超過該閾值時(shí),分條帶批量處理更新請(qǐng)求。當(dāng)同一條帶中,Ri的數(shù)據(jù)更新量小于Rj的校驗(yàn)數(shù)據(jù)更新量時(shí),采用data update 方法,即分別將數(shù)據(jù)節(jié)點(diǎn)的delta值發(fā)送給某一校驗(yàn)轉(zhuǎn)發(fā)節(jié)點(diǎn),再由校驗(yàn)轉(zhuǎn)發(fā)節(jié)點(diǎn)通過式(1)計(jì)算校驗(yàn)更新并傳輸給相關(guān)的校驗(yàn)節(jié)點(diǎn),如圖4a 所示;相反,當(dāng)Ri的數(shù)據(jù)更新量大于Rj的校驗(yàn)數(shù)據(jù)更新量時(shí),采用parity update 方法,即匯總所有的delta 值到數(shù)據(jù)轉(zhuǎn)發(fā)節(jié)點(diǎn),再由數(shù)據(jù)轉(zhuǎn)發(fā)節(jié)點(diǎn)利用式(1)計(jì)算校驗(yàn)更新并傳輸給相關(guān)的校驗(yàn)節(jié)點(diǎn),如圖4b 所示。

圖4 CAU 的2 種更新方法
相比于傳統(tǒng)的星型數(shù)據(jù)更新方式(各個(gè)數(shù)據(jù)節(jié)點(diǎn)各自將數(shù)據(jù)傳輸給相關(guān)的校驗(yàn)節(jié)點(diǎn)),CAU 利用匯聚節(jié)點(diǎn)的轉(zhuǎn)發(fā),確實(shí)可以減少網(wǎng)絡(luò)開銷,尤其是跨機(jī)架的網(wǎng)絡(luò)開銷。然而,數(shù)據(jù)更新性能可以進(jìn)一步優(yōu)化。
1) 采用打包更新。因?yàn)榇蟛糠值臄?shù)據(jù)更新量小(不超過4 KB),而一般設(shè)置的塊大小為1~64 MB。因此,在同一個(gè)機(jī)架中,如果同一節(jié)點(diǎn)有多個(gè)數(shù)據(jù)塊進(jìn)行了更新,可以采用tar 打包模型進(jìn)行校驗(yàn)數(shù)據(jù)更新。
2) 基于XOR 進(jìn)行更新。如前文所述,基于RS 計(jì)算更新會(huì)產(chǎn)生大量的乘法運(yùn)算,對(duì)于CPU 資源開銷較大,鑒于此,本文采用基于XOR 的更新方法,在計(jì)算校驗(yàn)更新時(shí),采用式(2)~式(7),將有限域乘法與加法運(yùn)算都轉(zhuǎn)化為XOR 運(yùn)算。
如圖5 所示,在同一數(shù)據(jù)節(jié)點(diǎn)中,可能有多個(gè)數(shù)據(jù)塊被修改(比如 Node 0的0 號(hào)、6 號(hào)數(shù)據(jù)塊),考慮到修改的數(shù)據(jù)量較小,本文采用tar 打包的方式,如圖6 所示,將同一個(gè)節(jié)點(diǎn)的數(shù)據(jù)進(jìn)行打包,增加一個(gè)頭數(shù)據(jù)(用H 表示),頭數(shù)據(jù)中記錄該塊所在的條帶編號(hào)、塊內(nèi)起始位置、修改數(shù)據(jù)大小等信息。
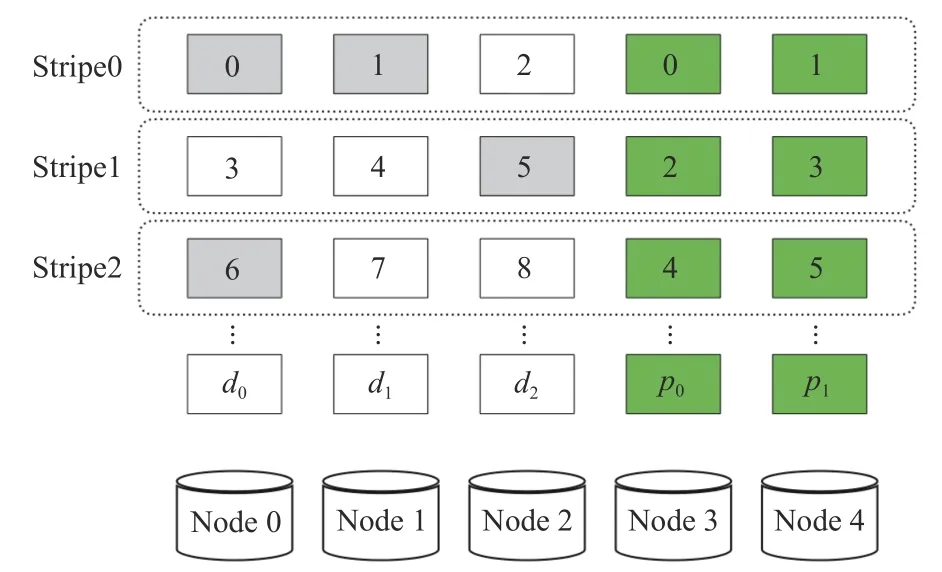
圖5 數(shù)據(jù)更新示例(CAU 模型)
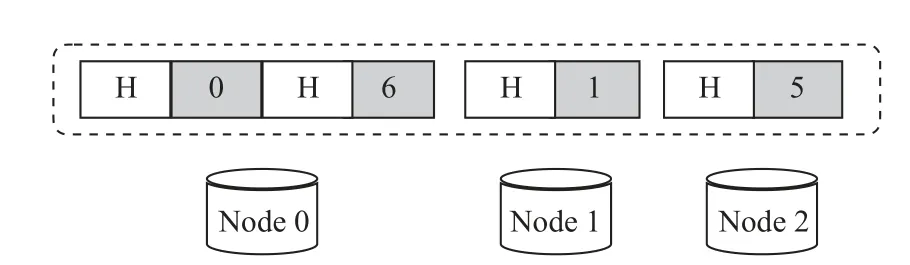
圖6 TAR-CAU 模型
如此,同一個(gè)塊的大小可以容納至少200 個(gè)小更新(假設(shè)塊大小為1 MB),從而可在處理一個(gè)條帶時(shí),同時(shí)處理多個(gè)更新數(shù)據(jù),然后按照CAU的傳輸模型進(jìn)行數(shù)據(jù)更新。
同時(shí)本文發(fā)現(xiàn)在進(jìn)行批處理更新時(shí),同一個(gè)數(shù)據(jù)塊(如 Node 0的0 號(hào)數(shù)據(jù)塊)可能會(huì)被多次修改,但是每一次修改的位置和大小不一定相同。這就需要在進(jìn)行tar 壓縮時(shí),對(duì)同一個(gè)數(shù)據(jù)塊的多次訪問進(jìn)行記錄和合并。如圖7 所示,假設(shè)數(shù)據(jù)塊大小為1 MB,在進(jìn)行批處理更新時(shí),發(fā)現(xiàn)0 號(hào)塊有多次修改記錄,于是,本文將多次修改的數(shù)據(jù)進(jìn)行合并(XOR),同時(shí)找出其中的最小和最大范圍(rangeL 和rangeR),并將這2 個(gè)值轉(zhuǎn)化為塊內(nèi)起始位置和修改數(shù)據(jù)大小,記錄到H。
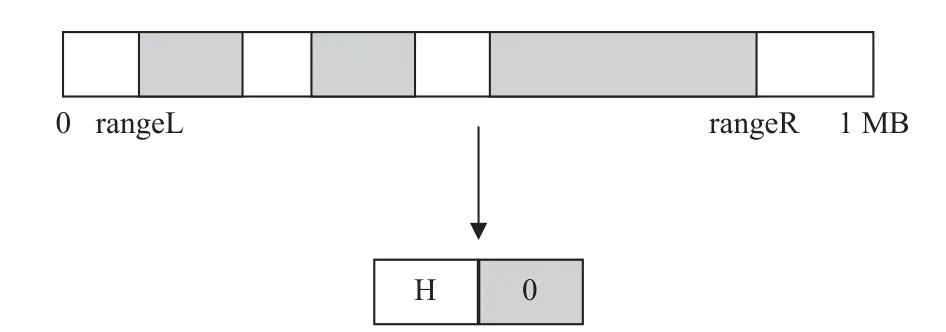
圖7 TAR-CAU 對(duì)同一塊多次訪問的合并處理
從圖7 可以看出,TAR-CAU 算法的優(yōu)化空間是blockSize-(rangeR-rangeL),優(yōu)化代價(jià)是進(jìn)行了打包與解包處理,增加了CPU 開銷。因此,TARCAU 算法性能對(duì)于數(shù)據(jù)訪問有一定的依賴性,優(yōu)化效果與具體的數(shù)據(jù)訪問記錄有關(guān)。
3 實(shí)驗(yàn)
3.1 仿真實(shí)驗(yàn)
本文通過微軟劍橋研究院提供的真實(shí)數(shù)據(jù)集進(jìn)行仿真實(shí)驗(yàn),數(shù)據(jù)集記錄了來自微軟13 個(gè)服務(wù)器,179 塊磁盤中36 個(gè)分區(qū)一周內(nèi)的訪問日志,每條記錄包含訪問時(shí)間、請(qǐng)求地址、訪問數(shù)據(jù)大小等信息,本文隨機(jī)選擇了3 個(gè)數(shù)據(jù)集進(jìn)行仿真測(cè)試,仿真實(shí)驗(yàn)平臺(tái)采用Go 語言環(huán)境搭建,通過改變塊大小、節(jié)點(diǎn)數(shù)量等參數(shù),以平均更新時(shí)間、吞吐量為指標(biāo)點(diǎn),與CAU 算法、基本更新算法(簡(jiǎn)稱Base)進(jìn)行了比較。仿真環(huán)境如表1 所示。

表1 仿真環(huán)境
1) 平均更新時(shí)間
如圖8 所示,本文比較了3 個(gè)數(shù)據(jù)集的平均單塊更新時(shí)間,發(fā)現(xiàn)TAR-CAU 算法更新效率最高,平均更新時(shí)間為0.009 4 s,時(shí)間效率比BASE 提高54%,比CAU 提高30%。
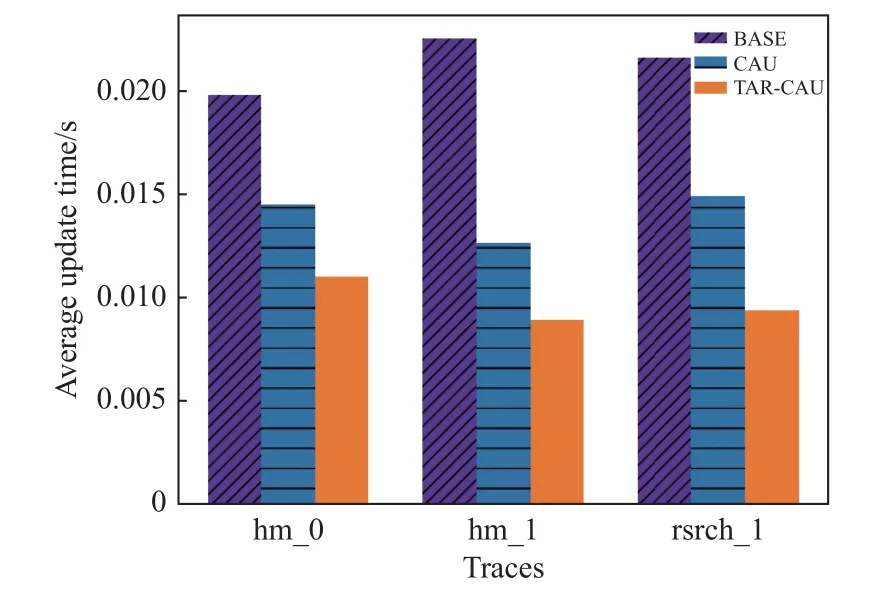
圖8 平均更新時(shí)間(不同數(shù)據(jù)集)
2) 吞吐量
如圖9a 中,盡管本文提出的算法TAR-CAU需要在進(jìn)行網(wǎng)絡(luò)傳輸之前進(jìn)行打包處理,增加了CPU 開銷,但是由于降低了網(wǎng)絡(luò)傳輸?shù)念l率,因此,更新效率大大提高,在3 種數(shù)據(jù)集中表現(xiàn)最佳,吞吐量比BASE 提高了119%,比CAU 提高了43%。
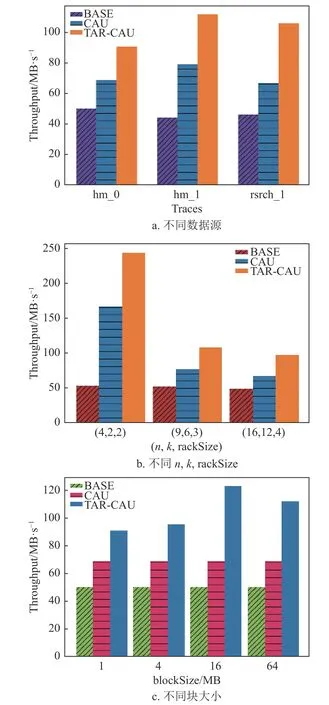
圖9 吞吐量
如圖9b 中,本文比較了常見的RS(n,k)配置:RS(4, 2)、RS(9, 6)、RS(16, 12),機(jī) 架 容 量(rack size)分別設(shè)置為2、3、4。仿真結(jié)果表明,TAR-CAU 的吞吐量比CAU 提高了44%。
如圖9c 中,通過改變塊大小(block size)的實(shí)驗(yàn)對(duì)比發(fā)現(xiàn),TAR-CAU 的吞吐量提高了60%。
3.2 本地集群實(shí)驗(yàn)
本文采用Go 語言在Ubuntu 18.04 平臺(tái)實(shí)現(xiàn)了基于TAR-CAU 算法的原型系統(tǒng),并在本地局域網(wǎng)搭建集群進(jìn)行測(cè)試,以了解在較為真實(shí)的環(huán)境中TAR-CAU 算法的性能。局域網(wǎng)內(nèi)部署了3 臺(tái)服務(wù)器(2 臺(tái)華為H12M-03,1 臺(tái)華為H22M-03),利用pve 虛擬管理平臺(tái)[14]搭建了虛擬機(jī)集群環(huán)境,共有13 臺(tái)虛擬機(jī),網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)如圖10 所示,主要由3 個(gè)部分組成:中央控制器(central controller)、算法調(diào)度器(scheduler)以及節(jié)點(diǎn)代理(agent)。其中,中央控制器位于元數(shù)據(jù)服務(wù)器(metadata server,ms)中,負(fù)責(zé)整個(gè)流程控制,包括發(fā)送命令給節(jié)點(diǎn)代理、收集代理返回的響應(yīng)ACK、統(tǒng)計(jì)時(shí)間和跨域流量等;而算法調(diào)度器是整個(gè)系統(tǒng)的大腦,負(fù)責(zé)根據(jù)指定的算法指揮中央控制器進(jìn)行調(diào)度,算法調(diào)度器也位于元數(shù)據(jù)服務(wù)器中;節(jié)點(diǎn)代理負(fù)責(zé)接受中央控制器的命令,執(zhí)行相關(guān)任務(wù),并返回給上級(jí)ACK。
每臺(tái)虛擬機(jī)的配置如表2 所示。
為了模擬真實(shí)的網(wǎng)絡(luò)環(huán)境,本文采用Linux tc工具[15]進(jìn)行網(wǎng)絡(luò)帶寬限制,設(shè)置機(jī)架內(nèi)部帶寬1 Gbps,機(jī)架外部200 Mbps,該設(shè)置可以根據(jù)具體的應(yīng)用場(chǎng)景自行配置。與仿真實(shí)驗(yàn)一致,本文采用hm_0、hm_1、rsrch_1 這3 個(gè)數(shù)據(jù)集進(jìn)行測(cè)試。
1) 平均更新時(shí)間
如圖11 所示,設(shè)置塊大小為4 MB,實(shí)驗(yàn)結(jié)果與仿真結(jié)果大體相同,TAR-CAU 算法表現(xiàn)最佳,平均單塊更新時(shí)間為0.454 4 s,相比Base 節(jié)省約78%的時(shí)間開銷,相比CAU 節(jié)省近70%的時(shí)間開銷。
2)吞吐量
如圖12a 所示,設(shè)置塊大小為4 MB,通過3 種數(shù)據(jù)集對(duì)比,在吞吐量方面,本文提出的TAR-CAU 算法大大優(yōu)于Base 和CAU,平均吞吐量比Base 高出9 倍,比CAU 也高出206%,這樣的表現(xiàn)也是出乎意料。當(dāng)然,值得注意的是,如前所述,TAR-CAU 的算法性能依賴于用戶訪問數(shù)據(jù)的位置,如果rangeL 和rangeR 過于靠近邊界(0 和blockSize),TAR-CAU 的算法表現(xiàn)甚至?xí)匀跤贑AU。
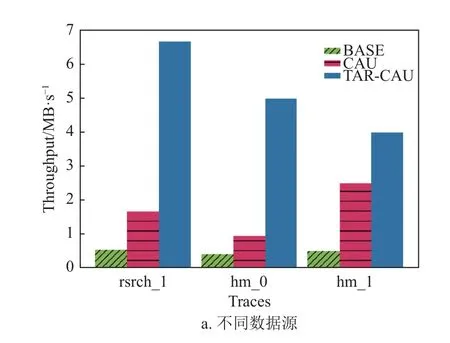
圖12b 展示了不同塊大小對(duì)各個(gè)算法的影響,當(dāng)塊大小較小時(shí)(如1 M),CAU 算法略優(yōu)于TARCAU,原因可能是rangeL 和rangeR 過于靠近邊界,導(dǎo)致打包產(chǎn)生的收益不如打包帶來的額外開銷。而隨著塊大小的逐漸增大,TAR-CAU 算法的優(yōu)勢(shì)愈發(fā)明顯,尤其是在塊大小達(dá)到16 M 以上時(shí),頻繁IO 的開銷逐漸成為了性能的主導(dǎo)因素,所以,僅傳輸delta 值的TAR-CAU 算法表現(xiàn)更佳。
由于引入了打包和解包過程,因此,TARCAU 算法相比于CAU 算法會(huì)產(chǎn)生額外的CPU 開銷,如圖13 所示,設(shè)置數(shù)據(jù)塊大小分別為1、4、16、64 MB,同時(shí)隨機(jī)產(chǎn)生100 個(gè)數(shù)據(jù)塊更新,每個(gè)數(shù)據(jù)更新的大小都不超過數(shù)據(jù)塊大小的1 /100,本文在一臺(tái)虛擬機(jī)中測(cè)試打包與解包性能發(fā)現(xiàn),打包與解包時(shí)間均不超過300 ms。因此,對(duì)于整體的數(shù)據(jù)更新性能影響可以忽略不計(jì)。
4 結(jié) 束 語
為解決云存儲(chǔ)中數(shù)據(jù)更新的網(wǎng)絡(luò)瓶頸,本文針對(duì)數(shù)據(jù)更新的網(wǎng)絡(luò)傳輸進(jìn)行了優(yōu)化,基于CAU 算法,提出了TAR-CAU,并針對(duì)數(shù)據(jù)更新量普遍較小的現(xiàn)象進(jìn)行優(yōu)化,將同一節(jié)點(diǎn)的多條帶更新數(shù)據(jù)打包到同一條帶進(jìn)行處理。仿真實(shí)驗(yàn)和本地集群實(shí)驗(yàn)均表明,相比于CAU 算法,當(dāng)數(shù)據(jù)更新量較小時(shí),本文的TAR-CAU 算法能夠至少提高44%的數(shù)據(jù)更新吞吐量。
猜你喜歡
作文·小學(xué)低年級(jí)(2025年2期)2025-02-13 00:00:00
小雪花·小學(xué)生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學(xué)低年級(jí)(2024年2期)2024-04-29 00:00:00
作文·小學(xué)低年級(jí)(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(bào)(2022年4期)2022-08-09 08:52:06
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
