基于GA-BP 神經(jīng)網(wǎng)絡(luò)的汽車空氣阻力系數(shù)預測研究
2023-10-12 04:29:24姜豐李卓汪怡平
汽車工程學報 2023年5期
關(guān)鍵詞:模型
姜豐, 李卓, 汪怡平
(武漢理工大學 現(xiàn)代汽車零部件技術(shù)湖北省重點實驗室,武漢 430070)
隨著一系列能耗政策的出臺,續(xù)駛里程成為了消費者購車時的重要參考指標,甚至會決定其購買意向。汽車空氣動力性能與續(xù)駛里程的相關(guān)性極強,降低空氣阻力系數(shù)是提升汽車續(xù)駛里程最經(jīng)濟的手段之一。此外,降低空氣阻力也是汽車行業(yè)實現(xiàn)“雙碳”目標的重要途徑。
在整車空氣動力性能開發(fā)中,通常采用數(shù)值計算確定概念車型的空氣阻力系數(shù),通過反復的造型修改和仿真嘗試,將空氣阻力系數(shù)控制在風險范圍內(nèi),最后進行風洞試驗驗證。這種開發(fā)思路對計算資源要求極高,需耗費大量時間,難以滿足當前汽車開發(fā)周期短、響應快的需求。因此,在現(xiàn)代工程開發(fā)中,急需一種能快速高效獲得汽車空氣阻力系數(shù)的方法。
自人工智能及機器學習興起以來,基于數(shù)據(jù)驅(qū)動的空氣動力特性建模在空氣阻力系數(shù)預測方面得到初步應用。ANDRéS-PéREZ[1]重點探討了利用機器學習技術(shù)對數(shù)值計算結(jié)果進行數(shù)據(jù)挖掘的可能性,展現(xiàn)了機器學習在空氣阻力系數(shù)預測上的巨大潛力。目前,利用機器學習實現(xiàn)空氣阻力系數(shù)預測主要有兩種方式:一是基于深度學習,根據(jù)輸入圖形實現(xiàn)風阻預測,如CHEN Hai 等[2]基于卷積神經(jīng)網(wǎng)絡(luò)提出了一種飛機翼型空氣動力系數(shù)的圖形預測方法;二是基于淺層監(jiān)督學習,根據(jù)特征參數(shù)實現(xiàn)風阻預測,如GUNPINAR 等[3]通過提取汽車縱截面二維輪廓特征,建立回歸模型進行空氣阻力系數(shù)預測,ANDRéS-PéREZ 等[4]比較了各種回歸模型在不同機翼形狀空氣阻力系數(shù)預測方面的效果,機器學習方法能有效減少仿真次數(shù)。
在項目開發(fā)中,應盡可能減少數(shù)據(jù)集容量,緩解仿真壓力,降低計算成本。深度學習模型泛化能力強,能自動提取特征,但對數(shù)據(jù)量要求過高[5],樣本數(shù)量在1 000 個以上,短期內(nèi)難以實現(xiàn)工程應用。監(jiān)督學習具有模型結(jié)構(gòu)簡潔,計算效率高及建模需求數(shù)據(jù)量較小等優(yōu)點,因此,更適用于汽車空氣阻力系數(shù)預測。
在監(jiān)督學習的主流算法中,極端梯度增強算法、支持向量回歸以及BP 神經(jīng)網(wǎng)絡(luò)等諸多模型均可實現(xiàn)數(shù)據(jù)挖掘及預測[6]。其中,BP神經(jīng)網(wǎng)絡(luò)作為一種具有代表性的監(jiān)督學習算法,具有訓練速度快、擬合程度高等優(yōu)點,已被廣泛應用。
本文擬將BP 神經(jīng)網(wǎng)絡(luò)應用到汽車空氣阻力系數(shù)預測中,通過流場仿真獲取數(shù)據(jù)集,利用BP 神經(jīng)網(wǎng)絡(luò)建立預測模型,并使用遺傳算法(GA)對BP 神經(jīng)網(wǎng)絡(luò)初始權(quán)值及閾值進行尋優(yōu),最終得到GA-BP神經(jīng)網(wǎng)絡(luò)模型。在訓練集樣本容量較小的條件下,該模型只需輸入汽車特征參數(shù)即可獲得精度較高的空氣阻力系數(shù)預測值,從而為快速得到汽車空氣阻力系數(shù)提供了一種新方法。
1 數(shù)據(jù)集建立
1.1 階梯背式MIRA模型
MIRA 模型組是由MIRA 公司提出的經(jīng)典汽車模型組,具有普遍代表性。國內(nèi)外學者已經(jīng)對各類MIRA模型做過大量研究,試驗數(shù)據(jù)豐富[7]。
階梯背式MIRA 模型保留了較多汽車特征造型,其基本結(jié)構(gòu)及總體尺寸如圖1所示。
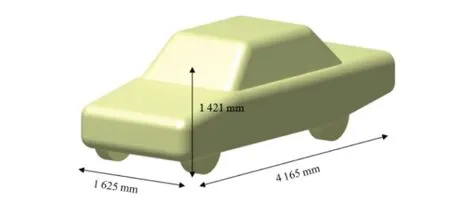
圖1 階梯背式MIRA模型
1.2 外流場計算
1.2.1 計算域確定
計算域尺寸參考中國汽車工程學會發(fā)布的乘用車空氣動力學仿真技術(shù)規(guī)范[8]來確定,如圖2 所示,計算域基本尺寸見表1,其中速度入口與車頭距離L1超過3倍車長,壓力出口與車尾距離L2超過8 倍車長。階梯背式MIRA 模型正投影面積為1.856m2,滿足阻塞比要求。

表1 計算域尺寸
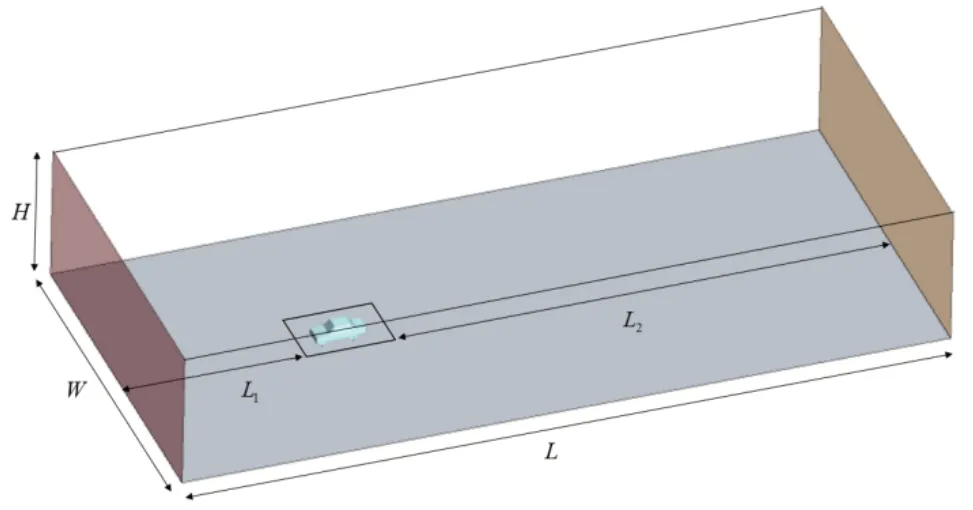
圖2 計算域
湍流模型選擇realizablek-ε模型,空氣設(shè)置為恒密度氣體。為保證雷諾數(shù)滿足要求,速度入口風速賦值為110 km/h,出口壓力為0。
1.2.2 網(wǎng)格生成
網(wǎng)格生成方式選擇切割體網(wǎng)格,并設(shè)置棱柱層。為減小網(wǎng)格數(shù)量,在速度入口、壓力出口及計算域壁面處禁用棱柱層。棱柱層數(shù)量為5 層即可滿足精度要求,其中延伸率為1.2。
為提高計算精度,除對車身面網(wǎng)格設(shè)置面加密控制外,同時設(shè)置4 層體加密區(qū),如圖3 所示。不同加密區(qū)的位置、大小及加密網(wǎng)格尺寸見表2~3。
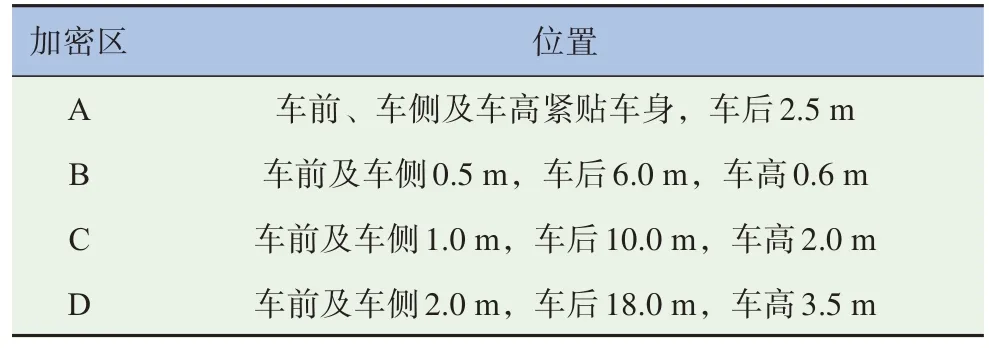
表2 加密域位置及大小
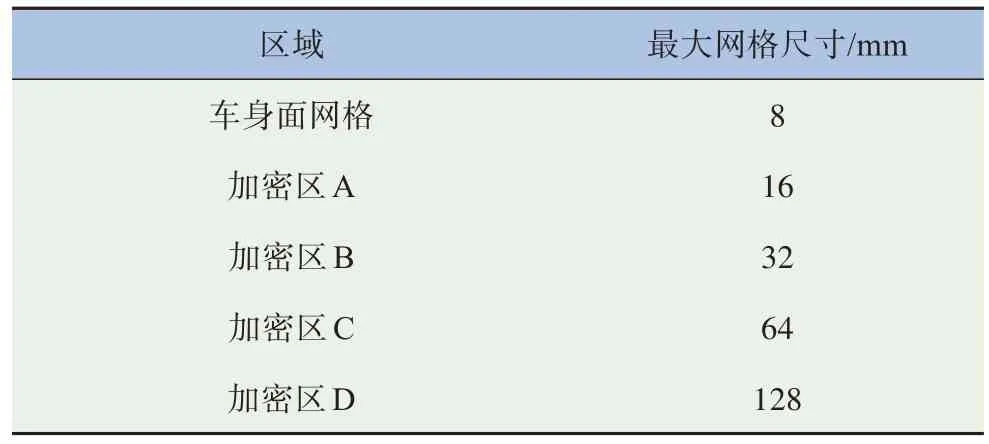
表3 加密網(wǎng)格尺寸
1.2.3 仿真結(jié)果驗證
為排除體網(wǎng)格數(shù)量差異帶來的影響,驗證3 組不同體網(wǎng)格數(shù)量下的仿真結(jié)果,并與風洞試驗結(jié)果對比[9],見表4。
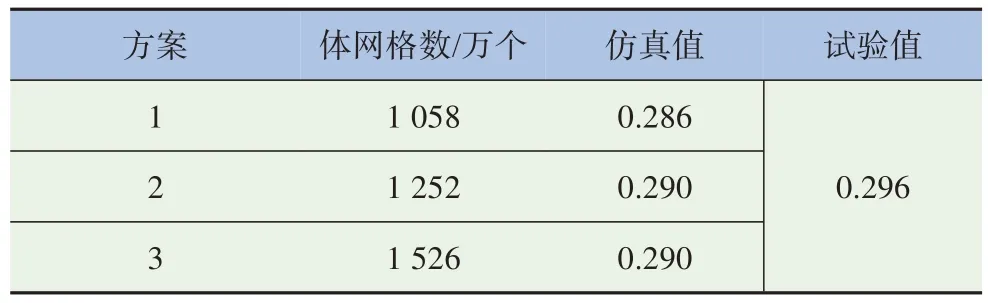
表4 仿真結(jié)果對照表
在體網(wǎng)格數(shù)達到1 252 萬個時,空氣阻力系數(shù)誤差為2.02%,計算精度滿足要求。
1.3 變量選擇
一般地,發(fā)動機蓋傾角與汽車頭緣高度相關(guān),它和前風窗傾角一起影響整車迎風面氣流狀態(tài),從而改變正壓區(qū)分布范圍,而后風窗傾角和離去角則會直接影響尾渦到汽車尾部距離[10],這些特征參數(shù)均會對汽車空氣阻力系數(shù)產(chǎn)生顯著影響。王佳等[11]的研究結(jié)果表明,發(fā)動機蓋傾角對MIRA 模型空氣阻力系數(shù)的影響最顯著,其次是后風窗傾角和離去角,而前風窗傾角影響程度最小。因此,選擇前發(fā)動機蓋傾角α、后風窗傾角β、離去角γ作為預測模型輸入變量,如圖4所示。
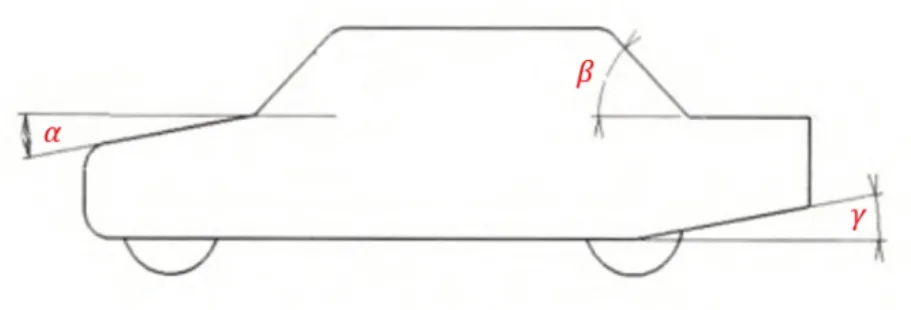
圖4 特征參數(shù)
特征參數(shù)的取值會受到各種因素的影響,不能過分脫離工程實際。最終發(fā)動機蓋傾角α、后風窗傾角β及離去角γ的變化范圍和梯度,見表5。
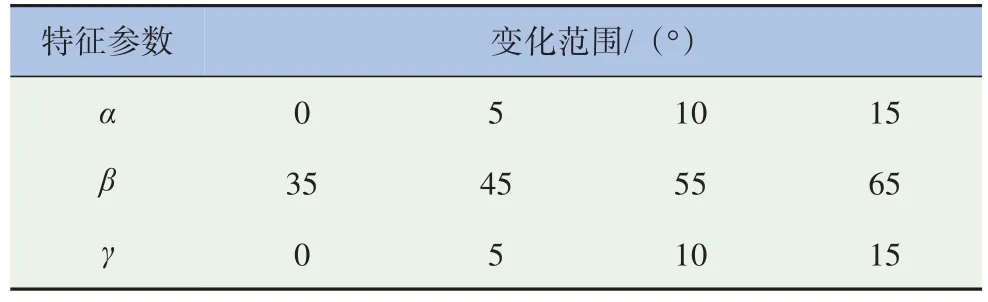
表5 特征參數(shù)及變化梯度
1.4 構(gòu)建數(shù)據(jù)集
分別對表內(nèi)3 種特征參數(shù)組合的64 種MIRA 模型進行仿真計算,從而建立包含64 組不同特征參數(shù)和相應空氣阻力系數(shù)的數(shù)據(jù)集,按照3∶1 的比例隨機劃分成訓練集和測試集,訓練集數(shù)據(jù)見表6,測試集數(shù)據(jù)見表7。將原始數(shù)據(jù)的輸入變量映射至區(qū)間[-1,1],保證輸入數(shù)據(jù)范圍的差別不會對訓練時間及效果產(chǎn)生影響。
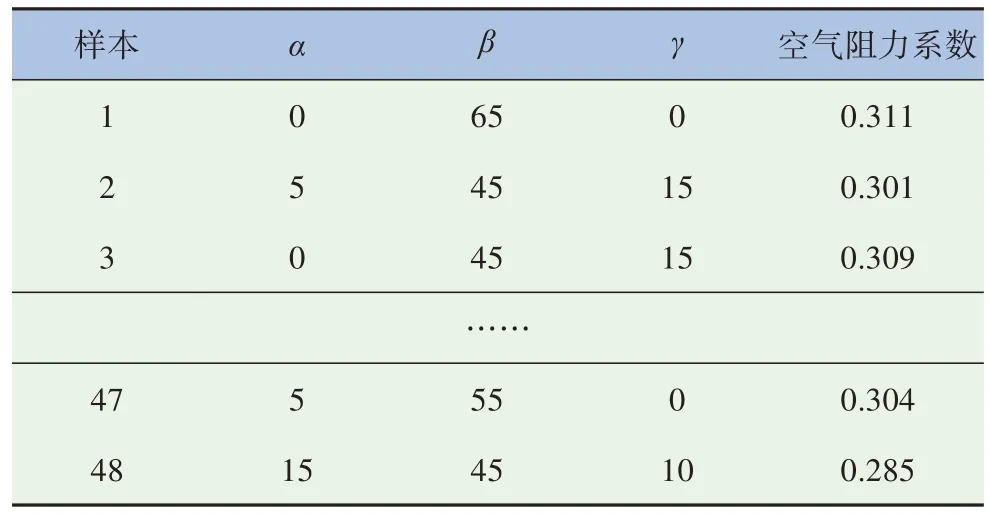
表6 訓練集樣本數(shù)據(jù)
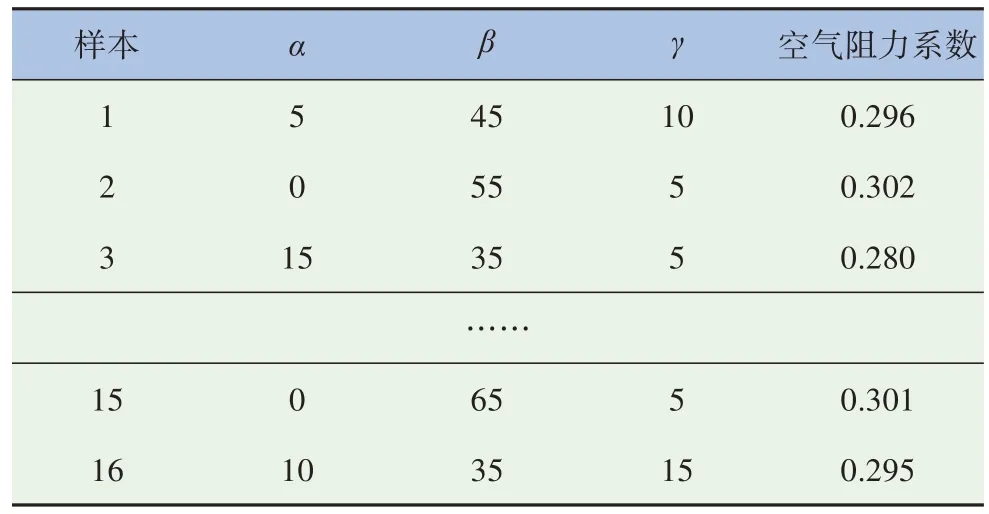
表7 測試集樣本數(shù)據(jù)
2 GA-BP神經(jīng)網(wǎng)絡(luò)預測模型
2.1 傳統(tǒng)BP神經(jīng)網(wǎng)絡(luò)模型
2.1.1 BP神經(jīng)網(wǎng)絡(luò)
BP 神經(jīng)網(wǎng)絡(luò)即誤差逐層反向傳播的人工神經(jīng)網(wǎng)絡(luò),能很好地解決非線性數(shù)據(jù)問題。在神經(jīng)元數(shù)量足夠時,甚至能擬合任何函數(shù)[12]。
數(shù)據(jù)集的輸入變量有3 種,在樣本數(shù)量較少的情況下,采用單隱含層神經(jīng)網(wǎng)絡(luò)即可滿足預測精度要求。建立的BP神經(jīng)網(wǎng)絡(luò)基本結(jié)構(gòu)如圖5所示,由輸入層、隱含層及輸出層組成,輸入層由3 個神經(jīng)元組成,輸出層由1 個神經(jīng)元組成,不同神經(jīng)元之間連接的權(quán)值和閾值均不相同。
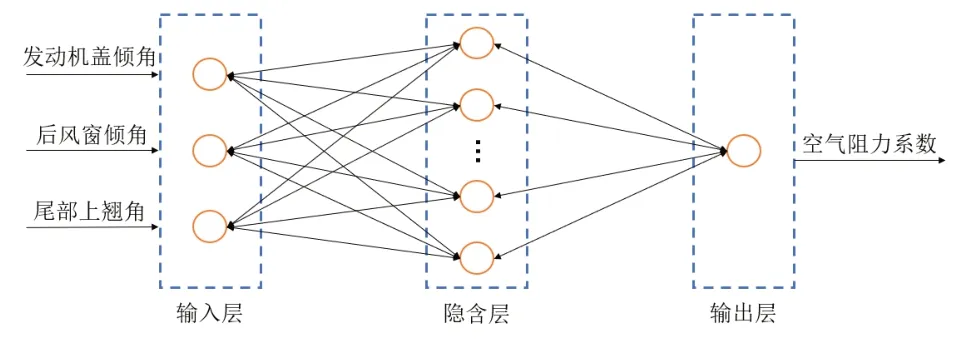
圖5 BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
2.1.2 隱含層神經(jīng)元數(shù)量選擇
BP 神經(jīng)網(wǎng)絡(luò)的隱含層神經(jīng)元數(shù)量對預測精度影響較大,當隱含層神經(jīng)元數(shù)量過少,網(wǎng)絡(luò)提取數(shù)據(jù)信息能力較差,而當隱含層神經(jīng)元數(shù)量過多,則會出現(xiàn)“過擬合”[13],即預測模型學習并保留了數(shù)據(jù)的錯誤信息。
首先通過經(jīng)驗公式[14]確定隱含層神經(jīng)元個數(shù)范圍,如式(1)所示。
式中:m為隱含層神經(jīng)元個數(shù);n為輸入層神經(jīng)元個數(shù);而α為[1,10]區(qū)間內(nèi)的整數(shù)。
在訓練樣本相同的條件下,測試不同隱含層神經(jīng)元個數(shù)對神經(jīng)網(wǎng)絡(luò)預測精度的影響。
為準確評判模型性能,采用EMSE(平均平方誤差)、EMAPE(平均絕對百分比誤差)和R2(決定系數(shù))3種評價指標,如式(2)~(4)所示。
式中:EMSE為平均平方誤差;EMAPE為平均絕對百分比誤差;yi為真實值,而yi′為預測值。其中,EMSE和EMAPE越接近0,且R2越接近1,則表明該模型的預測精度越高。
詳細結(jié)果見表8,隨著神經(jīng)元個數(shù)增加,預測精度逐漸提高,在神經(jīng)元個數(shù)達到10 時,平均平方誤差EMSE降為0.6%,繼續(xù)增加神經(jīng)元個數(shù)可能會導致過擬合,所以隱含層神經(jīng)元個數(shù)選擇10。

表8 隱含層神經(jīng)元個數(shù)對預測精度關(guān)聯(lián)表
2.1.3 預測結(jié)果分析
傳統(tǒng)BP 神經(jīng)網(wǎng)絡(luò)模型雖能實現(xiàn)汽車空氣阻力系數(shù)快速預測,但存在以下問題。
1)預測魯棒性較差。一般地,當隱含層神經(jīng)元數(shù)量越多時,神經(jīng)網(wǎng)絡(luò)模型預測精度越高。如表8數(shù)據(jù)所示,在神經(jīng)元數(shù)量分別為6、7、10 及11 個時,其預測精度呈現(xiàn)為相反的結(jié)果。因為除隱含層神經(jīng)元數(shù)量影響以外,神經(jīng)網(wǎng)絡(luò)創(chuàng)建時隨機生成的權(quán)值及閾值對預測模型的泛化能力亦會產(chǎn)生較大影響,所以這直接導致BP 神經(jīng)網(wǎng)絡(luò)預測精度的波動。初始權(quán)值及閾值的隨機性會降低預測模型的魯棒性,需要尋找并固定最優(yōu)權(quán)值及閾值,以保證模型預測精度穩(wěn)定。
2)泛化能力不足。汽車空氣阻力系數(shù)的精確程度會直接影響諸如動力經(jīng)濟性設(shè)計等其他性能的目標達成,對整車性能達標產(chǎn)生重大影響。因此,預測汽車空氣阻力系數(shù)時,應盡可能提高模型預測精度。傳統(tǒng)BP 神經(jīng)網(wǎng)絡(luò)的初始權(quán)值及閾值為隨機生成,泛化能力及預測精度存在提升空間。
為解決上述問題,需將智能優(yōu)化算法運用于BP神經(jīng)網(wǎng)絡(luò)的初始權(quán)值及閾值尋優(yōu)。
2.2 GA-BP神經(jīng)網(wǎng)絡(luò)模型
2.2.1 GA-BP神經(jīng)網(wǎng)絡(luò)建立
遺傳算法(GA 算法)源于對自然界遺傳和選擇機理的模擬研究,具有搜索效率高、不易陷入局部最優(yōu)解等優(yōu)點[15]。
GA-BP 神經(jīng)網(wǎng)絡(luò)搭建流程如圖6 所示。根據(jù)已確定的神經(jīng)網(wǎng)絡(luò)拓撲結(jié)構(gòu),隨機產(chǎn)生初始權(quán)值及閾值,并編碼為基因數(shù)據(jù),建立初始種群。將所有個體對應的神經(jīng)網(wǎng)絡(luò)預測誤差返回,作為適應度函數(shù),計算初始種群的個體適應度。對舊種群進行選擇、交叉和變異等操作,獲得新一代種群,并計算適應度。在若干代種群更新后,將最優(yōu)個體的基因數(shù)據(jù)解碼獲得權(quán)值及閾值,即實現(xiàn)GA 算法尋找BP神經(jīng)網(wǎng)絡(luò)的最優(yōu)初始權(quán)值和閾值。完成訓練后,利用測試集樣本驗證模型預測精度。
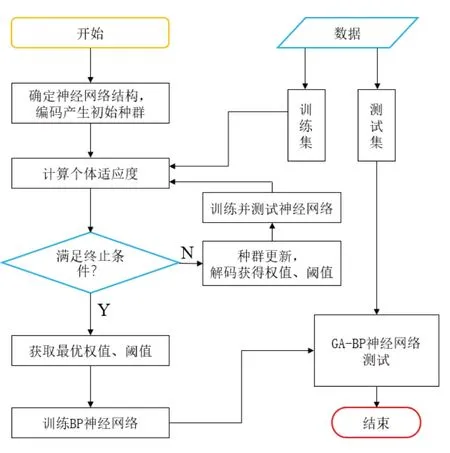
圖6 GA-BP神經(jīng)網(wǎng)絡(luò)建模和尋優(yōu)流程
初始種群規(guī)模設(shè)置為50 個,進化次數(shù)為100代,適應度函數(shù)設(shè)置為神經(jīng)網(wǎng)絡(luò)預測平均平方誤差的倒數(shù)。BP神經(jīng)網(wǎng)絡(luò)拓撲結(jié)構(gòu)及參數(shù)保持不變。
2.2.2 預測結(jié)果分析
遺傳算法迭代過程如下,圖7 為每代種群的神經(jīng)網(wǎng)絡(luò)預測值和仿真值的均方誤差,圖8 為適應度曲線。藍色曲線為個體最小平均平方誤差,紅色曲線為群體平均平方誤差。個體最優(yōu)適應度呈現(xiàn)階梯式變化趨勢,即需通過一定代數(shù)的更新,種群才能出現(xiàn)適應度更優(yōu)的個體。種群平均適應度保持上升,保證遺傳算法的快速收斂。種群的個體最優(yōu)適應度在第60 代已接近最高值。在較少的迭代時間內(nèi),GA-BP神經(jīng)網(wǎng)絡(luò)預測誤差已達到極小值。

圖7 平均平方誤差變化曲線
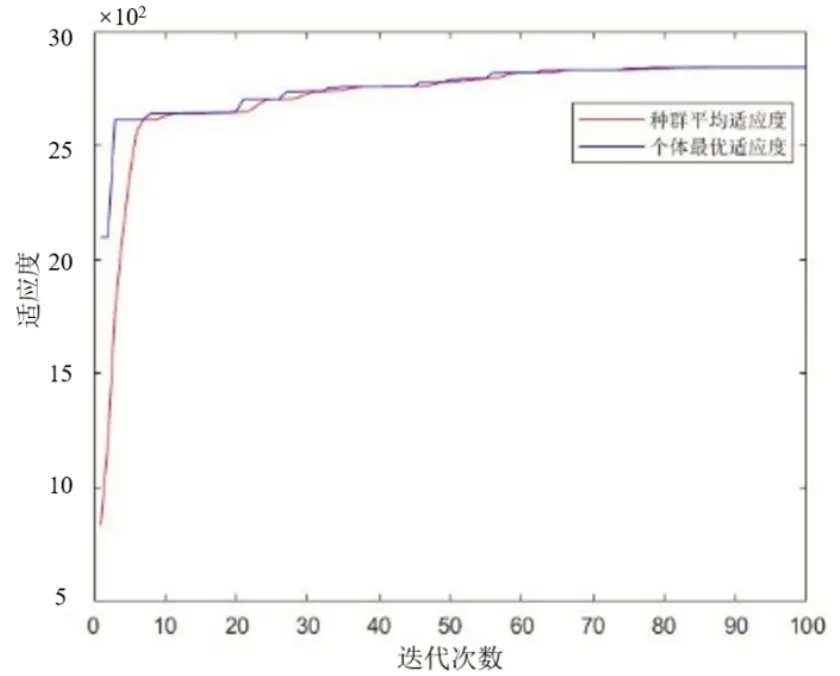
圖8 適應度變化曲線
算法預測效果對比如圖9~10 所示,在相同樣本下,GA-BP神經(jīng)網(wǎng)絡(luò)的預測精度和泛化能力明顯強于傳統(tǒng)BP 神經(jīng)網(wǎng)絡(luò)。黃色菱形點代表GA-BP 神經(jīng)網(wǎng)絡(luò)預測值,基本處于對角線附近。紅色方形點代表傳統(tǒng)BP 神經(jīng)網(wǎng)絡(luò),不少節(jié)點偏離對角線較遠。
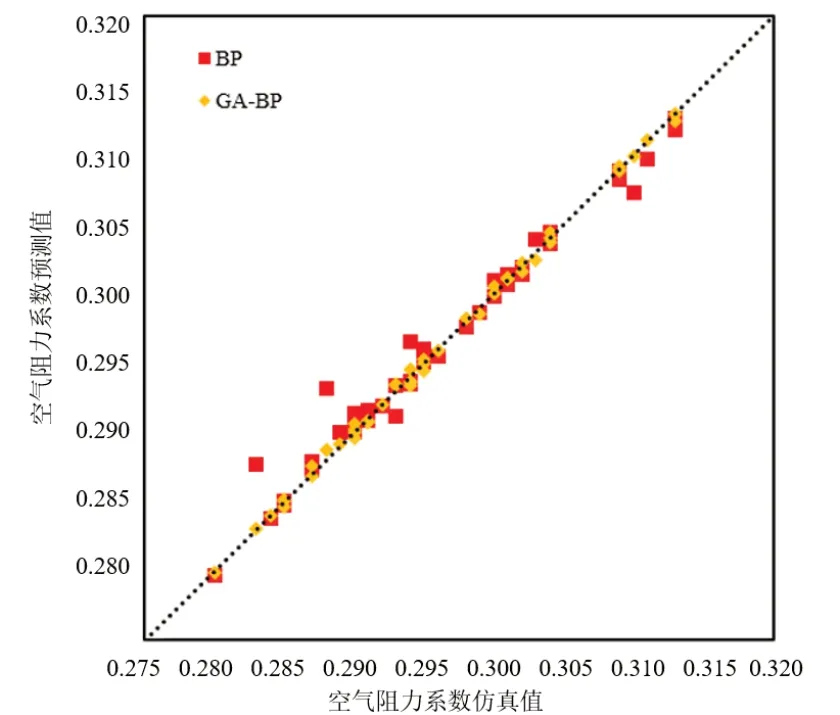
圖9 GA-BP和BP訓練集預測對比
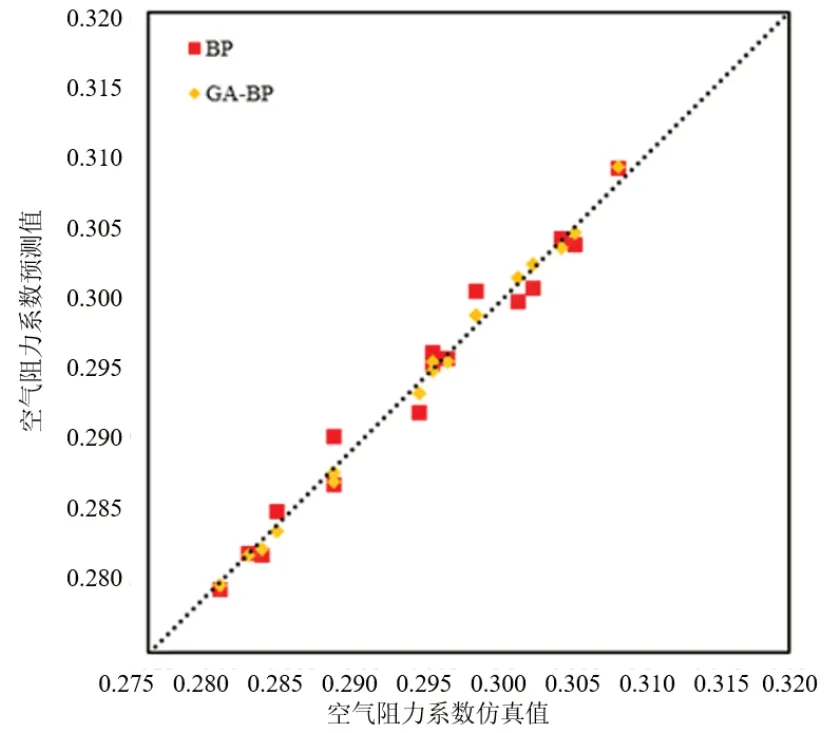
圖10 GA-BP和BP測試集預測對比
詳細預測結(jié)果如圖11~12 及表9 所示。在16組測試樣本中,模型預測結(jié)果與仿真值基本一致,預測誤差在0.001以內(nèi)。
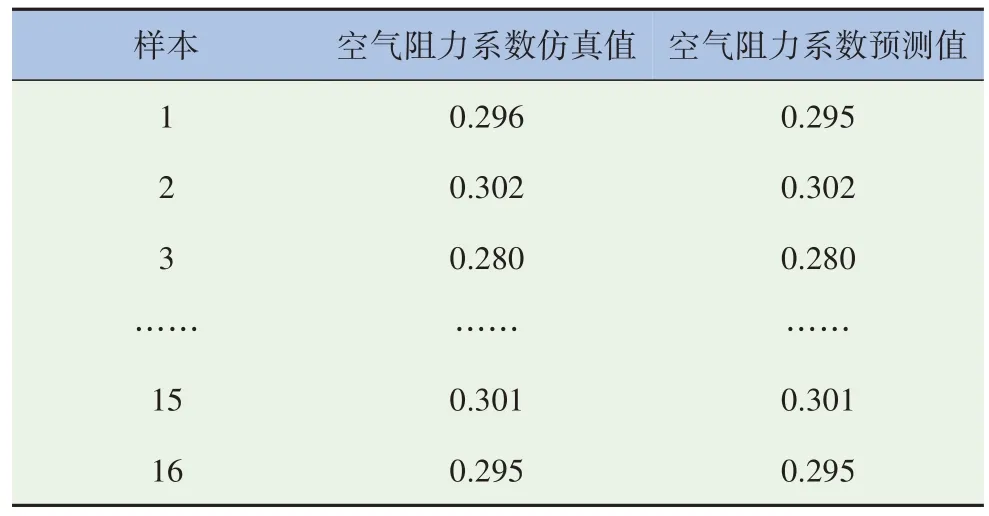
表9 測試集樣本預測結(jié)果
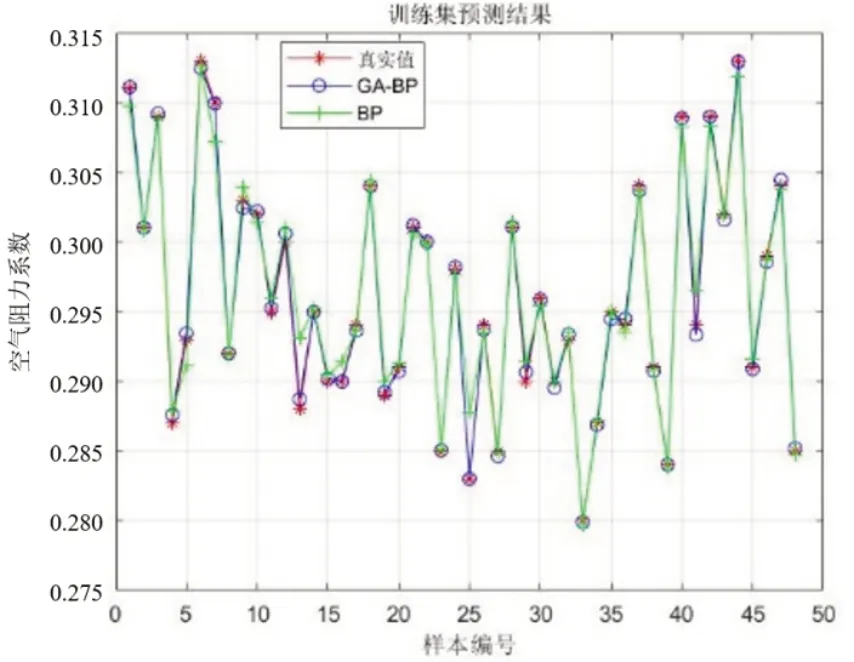
圖11 訓練集詳細預測結(jié)果
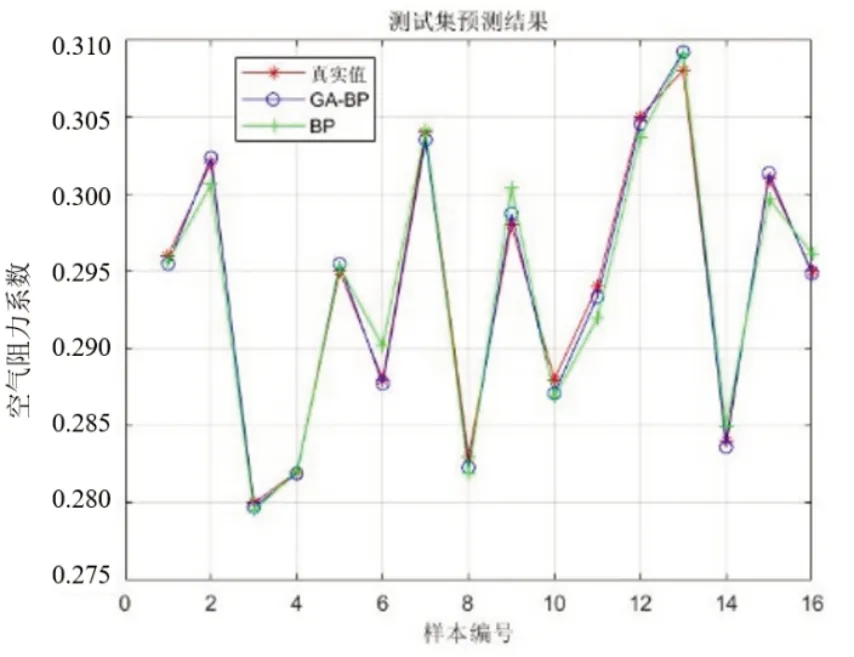
圖12 測試集詳細預測結(jié)果
評價指標情況見表10~11,GA-BP 神經(jīng)網(wǎng)絡(luò)在EMSE和EMAPE兩項指標上均明顯小于傳統(tǒng)BP 神經(jīng)網(wǎng)絡(luò),且R2提升程度約為1.9%。
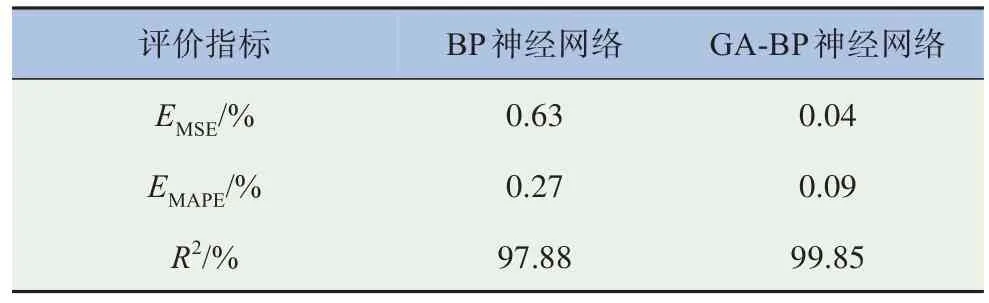
表10 訓練集預測結(jié)果對比
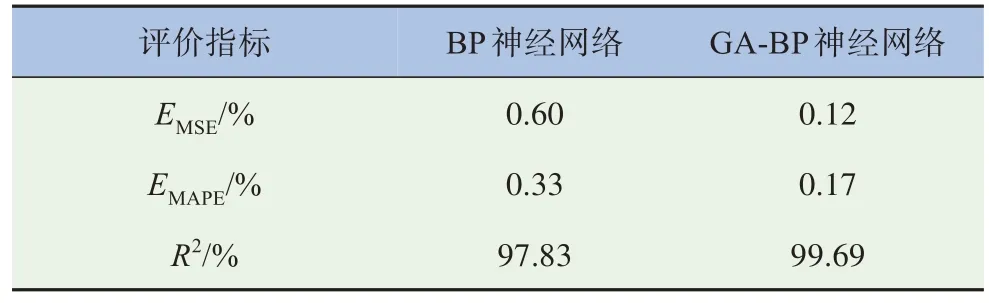
表11 測試集預測結(jié)果對比
綜上所述,將GA算法用于BP神經(jīng)網(wǎng)絡(luò)初始權(quán)值及閾值尋優(yōu)時,收斂速度快,尋優(yōu)效果好。相較于傳統(tǒng)BP 神經(jīng)網(wǎng)絡(luò)而言,GA-BP 神經(jīng)網(wǎng)絡(luò)的預測精度顯著提升,魯棒性更強。
2.2.3k折交叉驗證
k折交叉驗證是指將原有數(shù)據(jù)集隨機劃分為k個相同容量的子集,并將其中k-1 個子集作為訓練集用作模型學習,剩余的1 個子集作為測試集,檢驗模型性能,如此重復k次,最終返回k次測試的平均誤差,最終作為評估模型的性能指標,具體流程如圖13所示。
本文數(shù)據(jù)集樣本數(shù)量為64 個,k取值為16,對GA-BP 神經(jīng)網(wǎng)絡(luò)模型進行交叉驗證,結(jié)果見表12,如表可見,k折交叉驗證結(jié)果與隨機劃分測試集測試結(jié)果基本一致,這也證明了模型的泛化能力較強。
3 樣本數(shù)量對預測精度的影響分析
GA-BP神經(jīng)網(wǎng)絡(luò)模型通過輸入特征參數(shù)即可實現(xiàn)高精度的空氣阻力系數(shù)預測,這證明通過建立GA-BP神經(jīng)網(wǎng)絡(luò)模型來預測空氣阻力系數(shù)具有可行性。但數(shù)據(jù)集容量為64,所需仿真次數(shù)過多,難以滿足工程需求,因此需驗證訓練集樣本數(shù)量對預測精度的影響,以確定在較少樣本數(shù)量下預測模型能否滿足精度要求。擬通過正交試驗法[16]來設(shè)計樣本容量較小的訓練集。
選取標準正交表L32(43)作為基準,選取32 組訓練樣本,以4 為梯度設(shè)置不同容量的訓練集,分別用于訓練模型,并使用相同測試集進行測試,測試結(jié)果見表13。
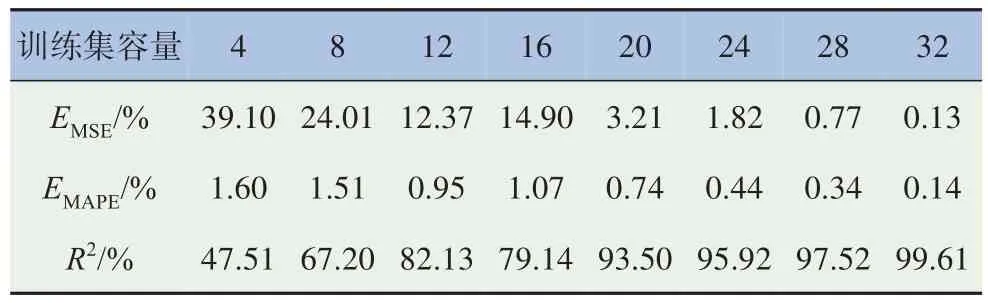
表13 樣本數(shù)量對預測精度影響
根據(jù)測試結(jié)果可知,GA-BP 神經(jīng)網(wǎng)絡(luò)僅需28組訓練樣本,即可滿足模型預測精度要求,此時EMSE小于1%,而EMAPE小于0.5%,且決定系數(shù)接近98%。綜上可知,在小樣本容量條件下GA-BP神經(jīng)網(wǎng)絡(luò)可實現(xiàn)空氣阻力系數(shù)的高精度預測。
4 結(jié)論
本文通過數(shù)值模擬獲得汽車空氣阻力系數(shù),構(gòu)建包含不同特征參數(shù)及空氣阻力系數(shù)的數(shù)據(jù)集,最終建立基于GA-BP 神經(jīng)網(wǎng)絡(luò)的預測模型,并驗證不同訓練集樣本容量對預測精度的影響。研究結(jié)論如下。
1)利用GA-BP 神經(jīng)網(wǎng)絡(luò)預測汽車空氣阻力系數(shù),當隨機選取測試集或k折交叉驗證時,測試評價指標R2均大于99%,模型預測精度高。GA 算法優(yōu)化效率較高,在種群更新至第60 代時,個體最優(yōu)適應度已達到極大值。GA-BP神經(jīng)網(wǎng)絡(luò)為空氣阻力系數(shù)的快速準確預測提供了一種新思路。
2)通過正交試驗法選取樣本能將訓練集容量降至28 組,此時EMSE小于1%,而EMAPE小于0.5%,且決定系數(shù)接近98%,預測精度滿足需求。采用正交試驗法選取樣本能有效減少訓練集容量,減小數(shù)據(jù)集建立時的仿真壓力。
5 展望
現(xiàn)有模型仍存在一些問題,后續(xù)工作將主要從以下兩個方面展開。
1)驗證模型對于其他離散值的適應性。現(xiàn)有數(shù)據(jù)集樣本均為相同間距離散數(shù)據(jù),后續(xù)可選擇更小梯度的離散值或不同間距離散值作為樣本數(shù)據(jù),從而檢驗模型對多種離散值樣本的適應性。
2)擴大車型樣本量。將該模型應用于多種實際車型中,選取具有普適性的整車特征參數(shù)作為預測模型的輸入,比如前、后風窗的傾角、離去角等,驗證該模型在預測實車空氣阻力系數(shù)時的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
