基于改進YOLOv5的擁擠行人檢測算法
2023-10-12 09:46:48王宏韓晨袁伯陽田增瑞盛英杰
科學技術與工程 2023年27期
王宏,韓晨,袁伯陽,田增瑞,盛英杰
(1.鄭州輕工業大學建筑環境工程學院,鄭州 450002; 2.河南省智慧建筑與人居環境工程技術研究中心,鄭州 450002)
行人檢測作為計算機視覺領域的熱門研究方向,對于行人重識別、行人多目標跟蹤、視頻監控、智慧交通等領域具有重要意義。由于實際場景復雜、目標密度較大、重疊率過高,以及目標距離攝像設備較遠等情況,導致當前行人檢測算法存在精度低、漏檢和誤檢率高等問題,因此提出一種可用于密集場景下的行人目標檢測算法具有相當的可行性[1]。
基于深度學習的目標檢測算法可分為基于區域推薦的Two Stage算法和基于回歸的One Stage算法。Two Stage算法首先根據圖像生成可能包含檢測目標的候選框,然后對生成的候選框進行類別識別和位置校準,代表性的算法主要有R-CNN(region-convolutional neural network)[2]、Fast R-CNN[3]、Faster R-CNN[4]、Mask R-CNN[5]等,其特點是檢測精度較高,但推理和檢測時間較長。One Stage算法不需要生成候選框,僅需要一次特征提取,就可以直接生成被檢測目標的類別概率和位置信息,代表性的算法主要有YOLO(you only look once)[6-10]、SSD(single shot multibox detector)[11]、EfficientDet[12]等,其特點是推理和檢測速度顯著提高,但檢測精度較低。
近年來,許多學者針對基于深度學習的行人檢測算法展開了相關工作。張秀再等[13]將YOLOv5模型與注意力機制、殘差網絡和軟閾值化函數相融合,有效提高了對小行人目標和密集行人目標的檢測精度,但網絡結構過于復雜,導致檢測速度較慢。鄒斌等[14]提出了改進 Faster-RCNN的密集人群檢測算法,在特征提取階段添加空間與通道注意力機制并使用S-BiFPN(strong bidirectional feature pyramid network)替代原網絡中的多尺度特征金字塔,使網絡可以加強對圖像深層特征的提取,但該算法無法滿足目標檢測的實時性。Zhang等[15]提出一種基于改進YOLOv3的輕量級行人檢測算法,通過引入正則化減少了不重要的通道數,充分降低了模型的計算量和復雜度,但該算法在擁擠場景下的行人檢測精度還有待提高。齊鵬宇等[16]提出一種全卷積One Stage目標檢測框架,通過增加尺度回歸提升了行人檢測的性能,但該模型受行人深度特征影響較大,對遮擋目標的檢測精度欠佳。劉振興等[17]提出了一種融合上下文及空間信息的擁擠行人檢測算法,通過改進特征金字塔網絡結構和添加帶權融合分支,有效提升了行人檢測算法在擁擠場景中的檢測效果,但在實驗論證過程中發現該模型存在性能不穩定、檢測不夠精準和檢測速度較慢的情況。
現有的深度學習算法在不同程度上提升了密集人群檢測的性能,但部分改進后的算法網絡結構較復雜,以及對遮擋程度較高的目標和極小尺寸目標的檢測性能有所欠佳,導致改進后算法存在檢測速度較慢、漏檢和誤檢率高等問題。因此現提出改進YOLOv5的擁擠行人檢測算法,通過公開數據集Crowd Human[18]對該算法進行訓練,以期在密集場景中的擁擠行人檢測能夠達成更好的效果。主要工作如下。
(1)在主干網絡中嵌入坐標注意力機制CA(coordinate attention)[19],用以增大主干網絡的感受野和提高YOLOv5捕獲位置信息的能力。
(2)在原網絡三尺度檢測的基礎上再增加一層淺層檢測層,同時改進特征融合部分,提高了對于小尺寸目標的檢測性能。
(3)使用深度可分離卷積[20](DSConv)替換部分普通卷積(Conv),在對特征提取影響較小的前提下大幅降低了模型的參數量和計算量。
(4)使用有效交并比損失函數(efficient intersection over union loss,EIOU_loss)[21],融合邊界框寬高比的尺度信息,有效提升了YOLOv5模型的檢測精度。
1 YOLOv5算法原理
YOLOv5是YOLO系列算法中強大的一代,具有較強的實時處理能力和較低的硬件計算要求。YOLOv5包括4種不同的網絡結構,考慮檢測速度和精度兩方面因素,以網絡深度和寬度最小的YOLOv5s(簡稱“YOLOv5”)為基礎網絡進行優化。如圖1所示,YOLOv5網絡結構由輸入端(Input)、主干網絡(Backbone)、特征提取網絡(Neck)、預測端(Prediction)四部分組成。
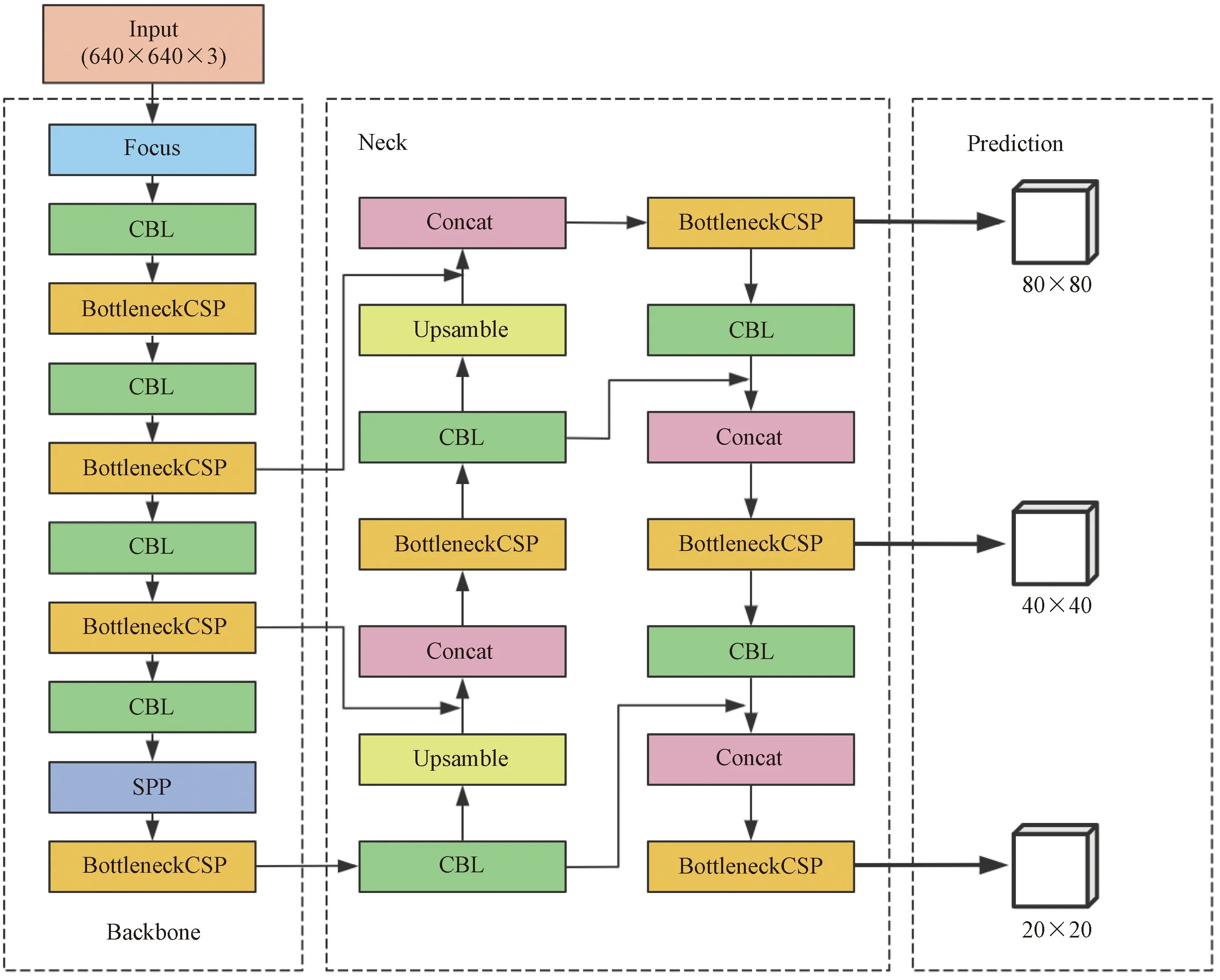
圖1 YOLOv5網絡結構
輸入端包括Mosaic數據增強、圖像尺寸處理和自適應錨框計算[22]。主干網絡為CSP-Darknet53,主要包括Focus、CSP(cross stage partial)和SPP(spatial pyramid pooling)三部分。其中Focus模塊能夠實現快速下采樣操作;CSP結構將輸入分為分別執行卷積運算的兩個分支,其中一個分支中信息通過CBL模塊(CBL=卷積+正則化+激活函數)后進入多個殘差結構,另一分支則直接進行卷積信息,之后將兩個分支合并起來[23],使網絡在提高模型學習能力的同時保證準確率;SPP模塊由Conv、max-pooling和concat三部分組成,其作用主要是在不影響推理速度的前提下增加特征提取的感受野,同時增強網絡的非線性表示。Neck的核心為FPN(feature pyramid network)和PAN(path aggregation network)。FPN 通過自上而下的上采樣實現了語義特征從深層特征圖到淺層特征圖的傳遞,PAN 通過自下而上的路徑結構實現了定位信息從淺層特征層到深層特征層的傳遞,二者的組合大大增強了網絡的特征融合能力。預測端利用GIOU_loss損失函數和非極大值抑制(non-maximum suppression,NMS)獲得最優的目標框,提高了網絡識別的準確性。
2 YOLOv5算法改進
以YOLOv5原算法為基礎,分別對其主干網絡、檢測尺度、特征提取網絡和損失函數進行了一系列改進。改進后的YOLOv5網絡結構如圖2所示。
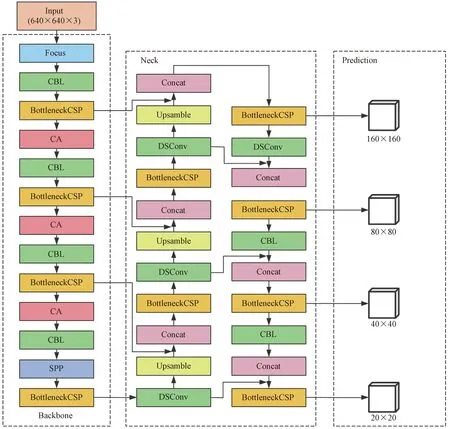
圖2 改進后YOLOv5網絡結構示意圖
2.1 主干網絡改進
在目標檢測中加入注意力機制可以使模型聚焦于圖像中的關鍵特征,抑制無關特征。為解決密集場景中背景信息雜亂導致行人目標的特征不明顯,以及目標相互遮擋、重疊的問題,在主干網絡中嵌入一種坐標注意力機制,使模型更準確地定位和識別感興趣的目標。通常注意力機制會在一定程度上提高模型的精度,但同時也會使模型增加額外的計算量,影響其檢測速率。但簡單輕量的CA模塊幾乎沒有額外的計算開銷,能夠在不影響模型檢測速率的情況下提升模型的性能。
如圖3所示,CA分為坐標信息嵌入和坐標信息特征圖生成。
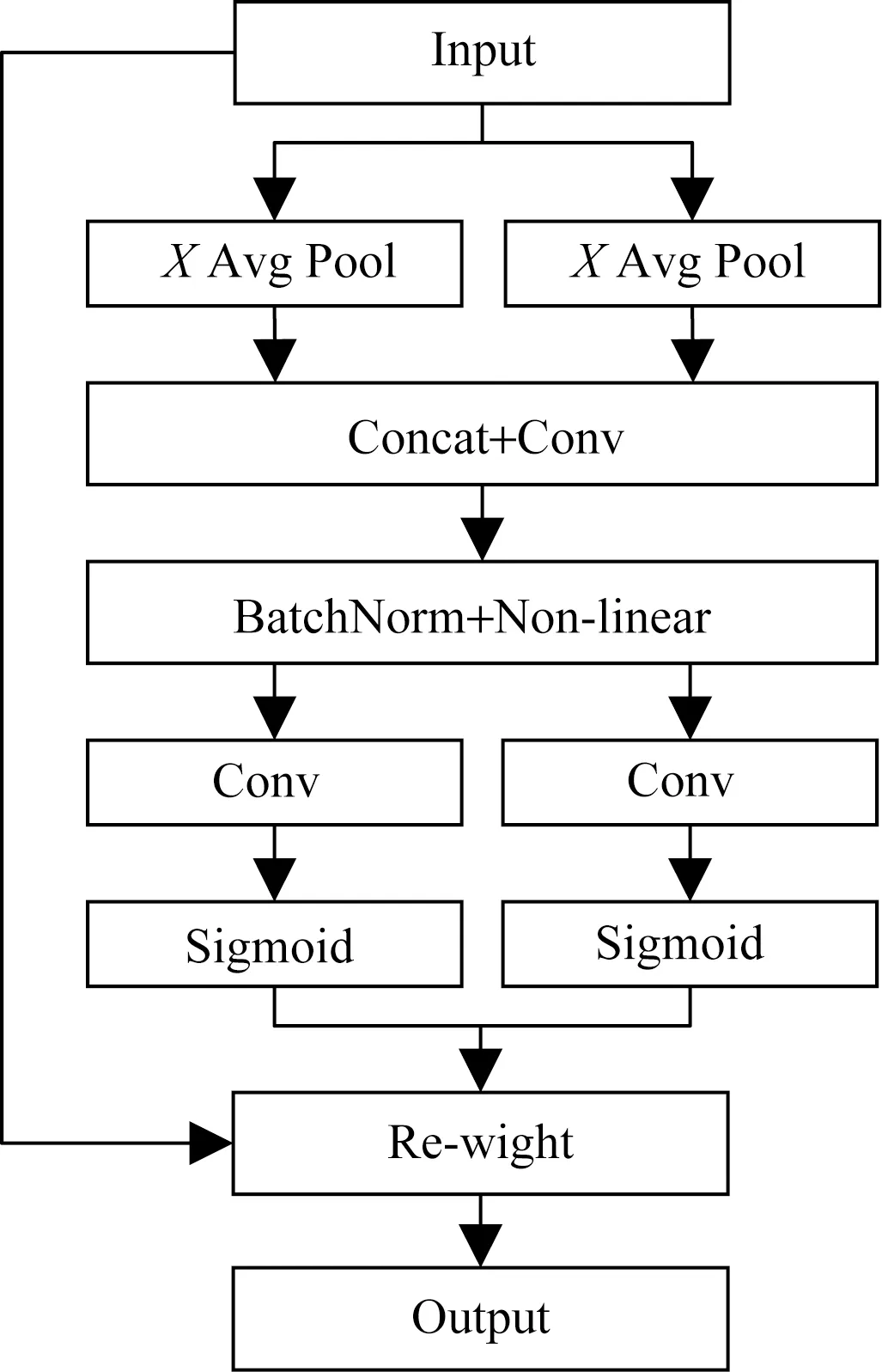
圖3 CA結構示意圖
第一步,CA對輸入特征圖X使用尺寸為(H,1)和(1,W)的池化核進行通道編碼,得到高度為h的第c個通道與寬度為w的第c個通道的輸出,產生兩個獨立方向感知特征圖zh與zw,大小分別為C×1×H和C×1×W,公式為
(1)
(2)
第二步,通過Concat融合上述操作生成的zh和zw,并使用卷積核大小為1的卷積變換函數F1對其進行變換操作,生成在水平和垂直方向進行空間信息編碼的中間特征圖f,公式為
f=δ[F1([zh,zw])]
(3)
式(3)中:δ為非線性激活函數。沿著空間維度將f分解為兩個獨立的張量fh∈RC/r×H和fw∈RC/r×W,其中r表示下采樣比例。然后利用兩個卷積核大小為1的卷積變換函數Fh和Fw將特征圖fh和fw變換為與輸入X具有相同通道數的張量[24]。公式為
gh=σ[Fh(fh)]
(4)
gw=σ[Fw(fw)]
(5)
式中:σ為sigmoid激活函數。最后將輸出gh和gw進行拓展,分別作為注意力權重分配值,最終輸出公式為
(6)
2.2 檢測尺度改進
對于輸入尺寸為640×640的圖像,YOLOv5分別利用8倍、16倍、32倍下采樣輸出檢測尺度為20×20、40×40、80×80的特征圖,對應檢測大、中、小3種尺度的目標。但在實際場景中,很多行人目標由于距離當前攝像頭較遠,導致其在圖像或視頻中所占像素過小,而用來檢測小目標的80×80尺度的特征圖無法有效檢測到這些更小尺寸的目標,極大地影響了檢測結果。
針對以上問題,在YOLOv5原有網絡結構上增加一層尺度為160×160的檢測層,同時將原來的特征融合部分改為對應的四尺度特征融合。具體操作為:第17層后繼續增加CBL層和上采樣,使得特征圖進一步擴大;在第20層時,將擴展得到的尺度為160×160的特征圖與Backbone中第2層特征圖進行Concat拼接,融合其細節信息和語義信息,獲取更大尺度的特征圖用以檢測更小尺寸的目標;第21層增加尺度為160×160的淺層檢測層,其他3個檢測層保持不變。改進后的四尺度檢測有效利用了淺層特征信息和深層特征的高語義信息,使模型能夠從更深層的網絡中提取特征信息,提高了模型在密集場景下多尺度學習的能力。
2.3 特征提取網絡改進
改進YOLOv5的四尺度檢測雖然提高了模型的檢測精度,但同時也在一定程度上加深了網絡深度,再加上YOLOv5網絡中存在大量的卷積操作,導致模型參數量過多,檢測速度較慢。使用深度可分離卷積替換Neck中的部分普通卷積,旨在確保精度基本不變的情況下降低模型的復雜度。深度可分離卷積的原理如圖4所示。
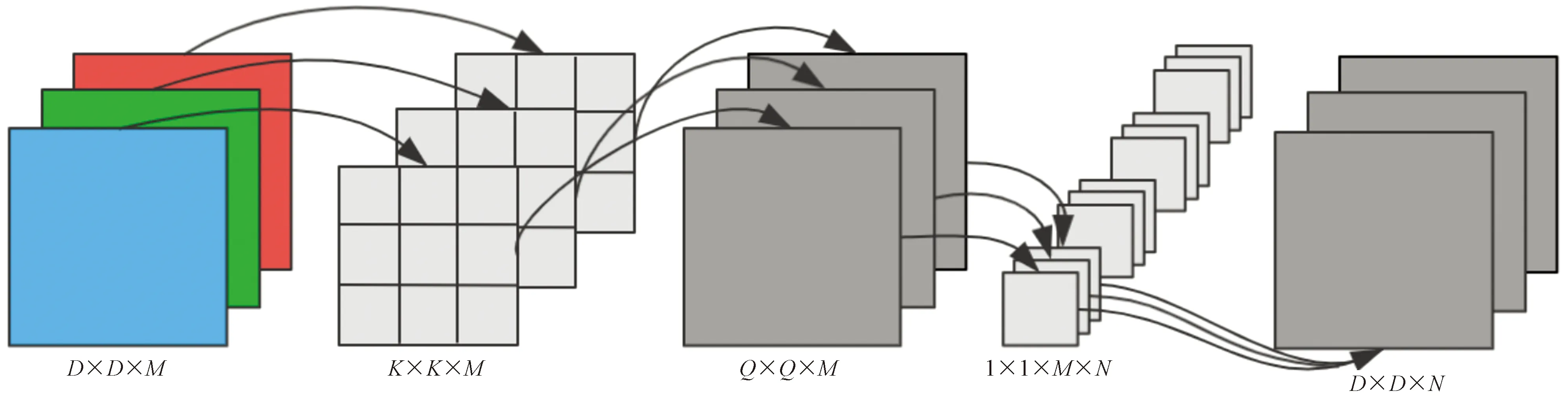
圖4 深度可分離卷積原理圖
深度可分離卷積將普通卷積分解為深度卷積和點態卷積。首先使用尺寸為K×K的卷積核對通道數為M的輸入特征圖做逐通道卷積,得到M個尺寸為Q×Q的特征圖。然后由N個過濾器對特征圖進行點態卷積操作,最終得到通道數為N,尺寸為D×D的輸出特征圖。普通卷積的計算公式為
K×K×M×N×D×D
(7)
深度可分離卷積的計算公式為
K×K×M×D×D+M×N×D×D
(8)
深度可分離卷積與普通卷積的計算量之比為1/N+1/K2,所以將特征提取網絡中的部分普通卷積替換為深度可分離卷積可以降低模型參數量,提高模型檢測速度。
2.4 損失函數改進
YOLOv5的損失函數包括邊界框回歸損失(bounding box loss)、置信度損失(objectness loss)以及分類概率損失(classification loss)三部分[25]。原YOLOv5算法采用GIOU_loss作為Bounding box的損失函數,其缺點是沒有考慮到預測框在目標框內部且預測框尺寸相同的問題。針對這一情況,CIoU_loss通過考慮邊界框回歸的重疊面積和中心點距離,以及預測框和目標框的長寬比,使YOLOv5模型更精確地定位回歸框。CIoU_loss計算公式為
(9)
(10)
(11)
式中:ρ2(b,bgt)表示預測框和真實框中心點之間的歐氏距離;c表示兩框相交時構成的最小外接矩形的對角線距離;w和h表示預測框的寬度和高度;wgt和hgt表示真實框的寬度和高度;IOU表示預測框和真實框的交并比。
CIoU_loss提高了模型的檢測性能,但未考慮到寬高與其置信度的真實差異。因此,引入性能更優的EIoU_loss作為bounding box的損失函數。EIoU_loss由重疊損失LIOU、中心距離損失Ldis和寬高損失Lasp三部分組成,前兩部分保留了CIOU_loss的優勢,寬高損失將優化目標設置為預測框與真實框的最小寬高差,能夠加快模型的收斂速度和提高模型的精度。EIoU_loss計算公式為
LEIOU=LIOU+Ldis+Lasp
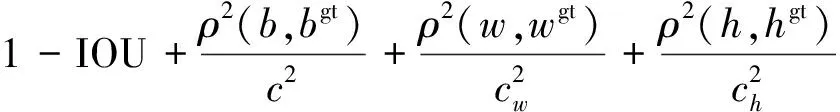
(12)
式(12)中:cw和ch為預測框和真實框的最小外接矩形的寬度和高度。
3 結果與分析
3.1 實驗平臺
所有實驗均在操作系統 Windows10下進行,硬件設備為 GPU NVIDIA Tesla,深度學習框架為Pytorch 1.12.0,開發環境為 Python 3.8,CUDA 11.2。實驗參數配置:初始學習率設置為0.01,使用余弦退火算法動態調整學習率,以實現有效收斂;學習率動量設置為0.937,以防止過擬合。訓練批次設置為16,一共訓練200個epoch。
3.2 實驗數據集
采用開源的CrowdHuman數據集,主要采集于背景復雜多變的密集人群場景。該數據集包含約24 000張圖片,共有470 000個標注實例,平均每張圖片的行人數量達到了22.6人,存在各種遮擋情況。CrowdHuman數據集的目標邊界框有3種,分別為頭部框、可見身體框和目標全身框。本實驗在訓練時采用可見身體框,隨機抽取8 000張圖片作為訓練集,2 000張圖片作為測試集。
3.3 評價指標
為了更好地分析模型檢測性能,采用平均精度均值(mean average precision,mAP)[26]、每秒處理圖像幀數(frame per second,FPS)、參數量M、計算量(floating point operations,FLOPs)和模型大小,作為本實驗模型的評價指標。其中mAP的計算公式為
(13)
(14)
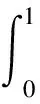
(15)
(16)
式中:P為精確率;R為召回率;TP為正確檢測的行人數量;FP為誤檢的行人數量;FN為未被檢測出的行人數量。
3.4 實驗結果與分析
為驗證模型改進后的效果,分別將改進前后模型的平均精度均值迭代曲線以及損失迭代曲線進行對比,結果如圖5所示。
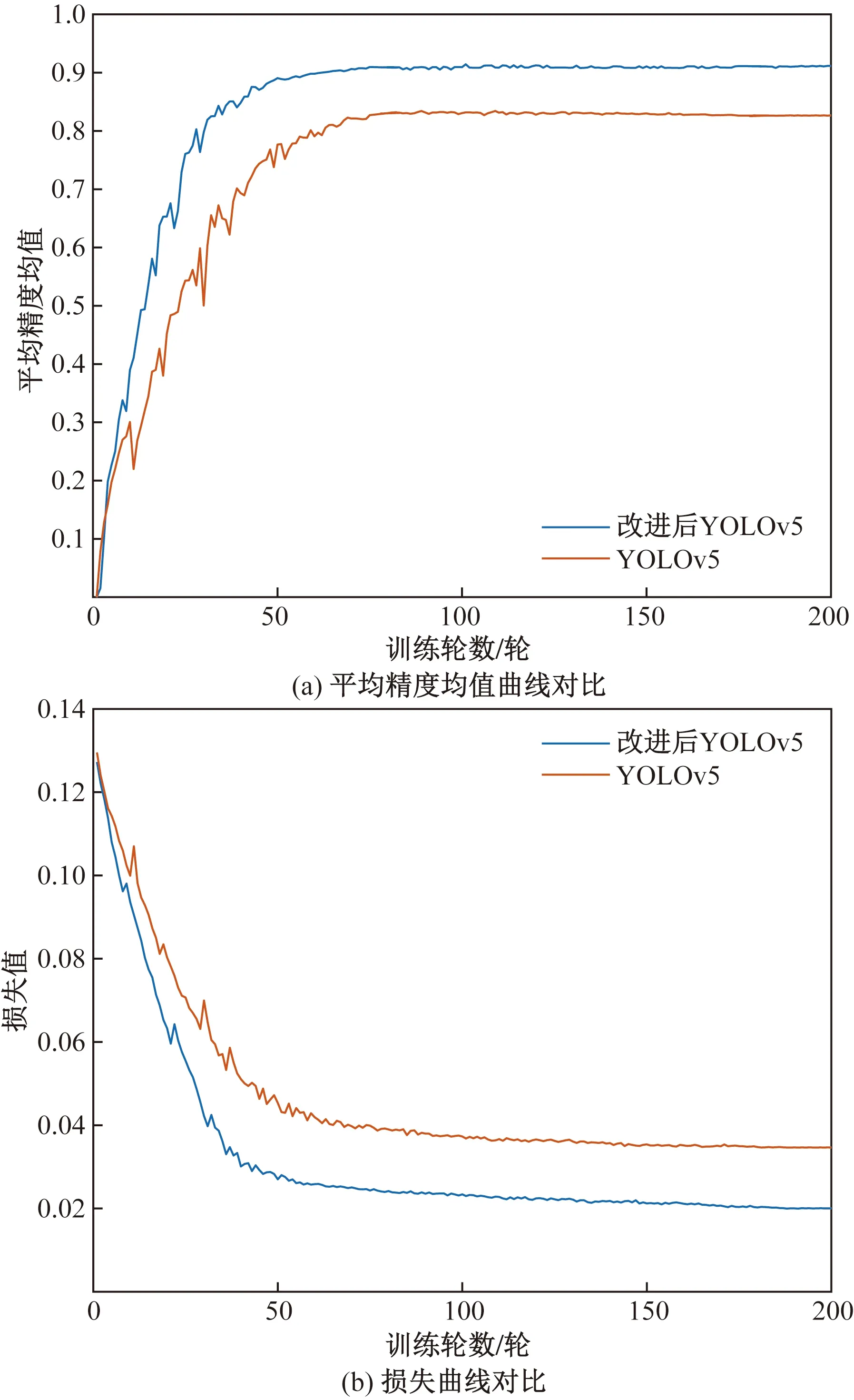
圖5 結果對比
從圖5(a)中可以看出改進后模型的曲線增長速度較快,mAP最終穩定在0.907,相較于原模型提高了7.4個百分點,且改進后模型的迭代曲線更加平穩,波動較原算法更小,從一定程度上反映了改進后的YOLOv5算法擁有更穩定的性能和更高的檢測精度。從圖5(b)中可以看出改進后模型的收斂速度更快和平滑性更好,損失值隨著迭代次數的增加在50個epoch后逐漸趨于平穩,且最終穩定在0.020 04,相比原模型下降了0.014 6,表明改進后模型的訓練效果更加理想。
為分析改進后YOLOv5的復雜度,將改進前后模型的參數量、計算量和模型大小進行對比,結果如表1所示。其中參數量可看作模型的空間復雜度,模型的參數越多則訓練模型所需的數據量就越大;計算量可看作模型的時間復雜度,計算量越大則模型的訓練和預測時間越長。由表1可知,相較于原YOLOv5模型,改進后模型的參數量減少了11.6%,計算量減少了10.7%,模型大小減少了11.1%。結果表明改進后YOLOv5能夠在降低模型復雜度的同時大幅提高檢測精度。

表1 模型復雜度對比
3.4.1 消融實驗
本文改進后的模型在原YOLOv5的基礎上添加了CA模塊,將三尺度檢測改為四尺度檢測,使用深度可分離卷積和有效交并比損失函數。為了進一步分析每個改進點對原模型的優化作用,以YOLOv5原算法為基礎模型設計消融實驗,結果如表2所示。
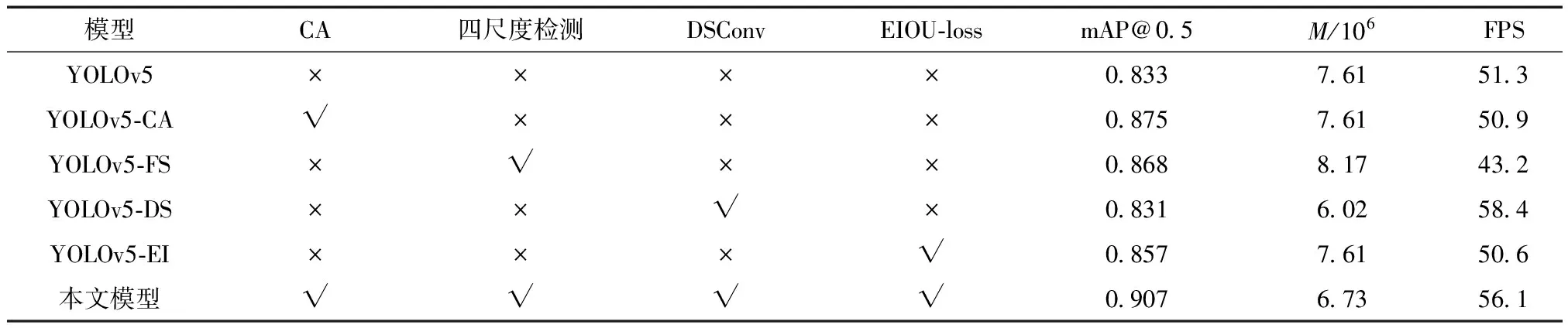
表2 消融實驗
由表2可知,模型YOLOv5-CA 加入CA模塊較原模型mAP增加了4.2個百分點,主要是因為原算法對特征的提取不夠準確,將多個密集行人目標誤檢為一個目標,從而造成漏檢,而添加CA后的模型精度得到大幅提升,并且對模型的參數量和FPS幾乎沒有影響。模型YOLOv5-FS 將三尺度檢測擴展為四尺度檢測,可以檢測出原算法漏檢的較小尺寸目標,將mAP提高了3.5個百分點,但新增的檢測尺度加深了網絡結構,導致模型參數量增加5.6×105,檢測速率降低。模型YOLOv5-DS將部分普通卷積替換為深度可分離卷積,使參數量較原模型減少1.59×106,模型檢測速度顯著提高,mAP值雖略有下降,但對模型的精度幾乎沒有任何影響。模型YOLOv5-EI 使用EIoU_loss作為邊框回歸的損失函數,考慮到了預測框和目標框的重疊面積、中心點距離和長寬比,有效提高了模型邊界框的定位精度,將mAP提高了2.4個百分點。對YOLOv5原算法同時使用以上4種改進方法,檢測精度和檢測速度均有明顯的提升,且模型參數量較原模型減少8.8×105。實驗結果表明CA模塊、四尺度檢測、深度可分離卷積和EIoU_loss的共同改進可以大幅提高擁擠行人檢測模型的性能。
3.4.2 不同目標檢測模型性能對比
為進一步分析改進YOLOv5算法的性能,將其與目前幾種主流目標檢測算法進行對比,結果如表3所示。
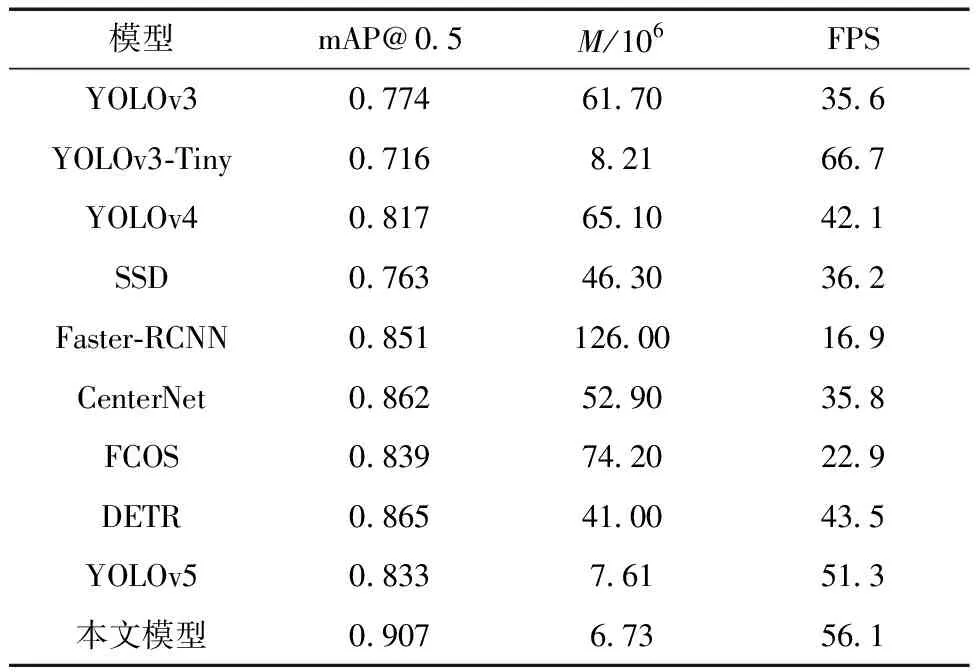
表3 不同算法性能對比
由表3可知,基于同一數據集,本文改進后模型與同系列YOLOv3和YOLOv4模型相比,參數量分別減少了54.97×106和58.37×106,mAP分別提升了13.3個百分點和9個百分點,檢測速率分別快了1.58倍和1.34倍,表明改進后的YOLOv5模型在精度和速度方面有較大的優勢;YOLOv3-Tiny模型的檢測速率最高,但其mAP較改進后的YOLOv5模型減少了19.1個百分點,這是因為YOLOv3-Tiny算法在YOLOv3算法基礎上去除了一些特征層,對小目標的檢測精度影響較大;與同為One Stage算法的SSD 相比,本文模型的參數量降低了39.57×106,mAP提高了14.4個百分點;Two Stage算法Faster-RCNN較YOLOv5原算法mAP提升了1.8個百分點,但其模型參數量過大,對硬件設備要求較高,以及檢測速率較慢,無法滿足目標檢測所需的實時性;與近幾年的CenterNet、FCOS(fully convolutional one-stage object detection)和DETR(detection transformer)模型相比,本文模型的參數量分別減少了46.17×106、67.47×106和34.27×106,mAP分別提升了4.5個百分點、6.8個百分點和4.2個百分點,檢測速率分別快了1.57倍、2.45倍和1.29倍,表明改進后YOLOv5模型能夠以更低的空間復雜度達到更好的檢測效果。由以上結果得出,本文改進后算法在顯著減少模型參數量的同時具有較高的檢測精度和速度,實現了更好的檢測性能。
3.4.3 改進前后檢測效果對比
為進一步驗證改進YOLOv5算法的檢測性能,本文使用CrowdHuman數據集中未經訓練和測試的圖片,對原YOLOv5算法與改進后YOLOv5算法在密集人群場景中的檢測效果進行對比,結果如圖6所示。由圖6(a)和圖6(d)可以看出,兩種算法對遮擋程度較低的大尺寸行人目標均有較好的檢測效果,但原算法對嚴重遮擋的小尺寸目標的檢測效果不佳,改進后的算法能夠更準確地識別此類目標;由圖6(b)和圖6(e)可以看出,兩種算法均能較準確地檢測出被遮擋目標,但原算法將人群旁邊的壁畫誤檢成行人目標,以及個別遮擋程度較低的小目標存在漏檢情況,改進后的算法有效改善了此類問題;由圖6(c)和圖6(f)可以看出,原算法將廣告牌上的人物和圖片中的水印誤檢成行人目標,以及未能檢測出被嚴重遮擋的小行人目標,改進后的算法針對此類問題的檢測效果更佳。綜上,原YOLOv5算法在嚴重遮擋的密集人群場景中的誤檢和漏檢率較高,改進后的YOLOv5算法雖不能完全準確地檢測出所有行人目標,但對于遮擋程度較高的小尺寸行人目標具有更好的檢測效果。
4 結論
為解決目前擁擠人群目標檢測存在的目標相互重疊、遮擋以及目標尺寸偏小等問題,本文提出了基于改進的YOLOv5擁擠行人檢測算法。
(1)通過添加坐標注意力機制顯著提升了模型檢測精度,且對模型參數量幾乎沒有影響。
(2)在原算法的基礎上增加小目標檢測尺度,有效提升了模型在密集場景中多尺度學習的能力。
(3)將部分普通卷積替換為深度可分離卷積,在確保精度基本不變的前提下減少了模型的參數量。
(4)通過優化邊界框回歸損失函數,使模型在訓練時的收斂速度更快,精度更高。
在公共數據集上的實驗結果表明,改進后YOLOv5算法的平均精度均值為0.907,檢測速度達到了56.1f/s,具有較好的檢測精度和實時檢測速度,能夠有效應用于密集場景下的擁擠行人檢測任務中。接下來將進一步完善算法的具體功能,通過結合自適應卡爾曼濾波實現多行人目標的檢測和跟蹤。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
