基于改進熵權法和SECEEMD的短期風電功率預測
2023-10-12 10:40:28王永生張哲劉利民高靜劉廣文武煜昊
科學技術與工程 2023年27期
王永生,張哲,劉利民*,高靜,劉廣文,武煜昊
(1.內蒙古工業大學數據科學與應用學院,呼和浩特 010080; 2.內蒙古自治區基于大數據的軟件服務工程技術研究中心,呼和浩特 010080; 3.內蒙古農業大學計算機與信息學院,呼和浩特 010018)
隨著化石能源的逐漸枯竭和全球對于環境保護的愈加重視,風力發電逐漸代替火力發電,成為中國主要的發電方式。據相關統計,截至2021年底,中國的風電裝機容量已經達到了3.28億千瓦,成為全球風電裝機容量第一大國家[1],成了全球規模最大的風電市場。然而過大的風力發電規模給風電場的管理以及電網調度帶來了嚴重的影響。因此,對于實現高精度的風電功率預測迫在眉睫。
受到風的波動性影響,風電功率數據處于嚴重的不平穩狀態[2]。劉棟等[3]通過變分模態分解將原始數據分解,然后使用加權排列熵將分量進行重組,再通過麻雀算法對支持向量機進行優化,并通過優化后的支持向量機對風電功率進行預測。武新章等[4]通過互補集合經驗模態分解(complementary ensemble empirical mode decomposition,CEEMDAN)算法對風電功率數據以及風速數據進行分析,平穩其中的波動性,然后結合注意力機制以及時間卷積網絡對風電功率進行預測。通過信號分解可以將不平穩的數據分解為平穩的分量,實現數據的平穩化。高精度的風電功率預測除了需要對平穩的風電功率數據之外,還需要多維氣象特征的輔助。從風電產生的原理可以看出,通過使用多維氣象數據對風電功率數據進行預測,能夠實現較高精度的風電功率預測。楊國清等[5]利用皮爾遜相關系數對數值氣象預報 (numerical weather prediction,NWP)數據進行相關性分析,然后通過Attention-GRU(Attention-gate recurrent unit)對風速進行修正,最后通過Stacking框架,結合多種模型對風電功率進行預測。康文豪等[6]通過PCA(principal component analysis)對氣象數據實現降維,降低后續模型的訓練復雜度,然后結合MRFO(manta ray foraging optimization)算法和極端隨機數對風電功率進行預測。栗然等[7]利用PCA對多維氣象數據進行預處理,然后通過卷積網絡進一步降維,最后使用長短期記憶網絡(long short term memory,LSTM) 對風電功率進行預測。楊芮等[8]通過Pearson相關系數分析氣象特征與風電功率數據之間的相關性,然后通過結合卷積神經網絡和GRU對風電功率進行預測。
上述研究中,雖然通過信號分解算法將風電功率數據平穩化,然而存在分量較多,模態混疊加劇的問題;通過特征優化方法對氣象特征進行降維、優化,但單一特征優化方法存在一定的局限性,例如:主成分分析降低特征的可解釋性,破壞了原始特征的完整性,影響后續預測模型的預測精度;皮爾遜相關系數僅能評價線性關系,且要求數據服從正態分布[9]。因此,為解決該問題,同時實現風電功率的高精度預測,現提出基于改進熵權法和樣本熵-互補集合經驗模態分解 (sample entropy CEEMD,SECEEMD)的短期風電功率組合預測方法。首先,提出一種綜合相關性評價模型,通過結合多種相關性分析方法,對NWP數據進行分析,避免單一方法的局限性,準確地選擇出相關程度較高的氣象特征;然后,使用樣本熵對CEEMD分解算法進行改進,分別建立NWP-LSTM和SCEEMD-BP(back propogation)預測模型,并利用貝葉斯優化算法對其結構進行優化;最后,通過改進熵權法尋找最優權重,并對預測結果進行組合;最后通過內蒙古碧柳河風電場的實采數據證明本文所提預測方法的有效性以及合理性。
1 風電功率預測組合方法
風電功率預測不僅受到氣象數據的影響,同時也受到自身趨勢的影響,因此,從兩個角度出發,以NWP數據以及提出的綜合相關性評價 (comprehensive correlation evaluation,CCE)模型為基礎,提出了NWP-CCE-LSTM預測模型;以歷史風電功率數據和提出的SECEEMD分解算法為基礎,提出了SECEEMD-BP預測模型。為提高模型的預測精度,使用貝葉斯尋優對兩部分預測模型的模型結構進行尋優;為保證組合權重分配的客觀性,使用結合貝葉斯尋優的熵權法對最優權重進行計算,并對兩個預測模型的預測結果進行加權組合。
1.1 NWP-CCE-LSTM預測模型
1.1.1 綜合相關性評價模型
氣象特征對風電功率預測尤為重要,通過氣象對風電功率進行預測,可以實現相較于使用單一特征進行預測更高的預測性能。但過多的氣象特征會導致后續的預測模型訓練復雜程度上升,訓練速度變慢,影響模型的預測性能,同時,不同氣象特征對模型預測性能的影響不同,有影響模型預測精度的風險,因此,需要通過特征優化對氣象特征進行處理。然而,現有風電功率預測的研究中,大多數的特征優化方式為單一特征優化方式,該方法存在一定的缺陷,對模型預測精度的提升較弱,無法實現高精度的風電功率預測。因此,提出一種CCE模型,通過結合多種相關性評價方法對不同氣象特征進行評價,綜合所有的評價結果對氣象特征進行優化。
為保證特征的可解釋性和完整性,綜合相關性評價方法選擇了兩種特征選擇方法,分別為Pearson相關系數法和灰色關聯分析法。
Pearson相關系數法是卡爾·皮爾遜于是1897年提出的一種相關性評價方法,最為經典的相關性評價方法[10]。該方法通過計算數據之間的協方差和標準差來衡量數據之間的相關性。其計算公式為
(1)
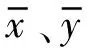
灰色關聯分析法是Deng[11]于1989年提出的針對灰色系統的相關性分析方法。針對了解不完全的系統,通過分析元素的差值,得出不同元素之間的相關性。鄧氏灰色關聯分析法的流程如下。
(1)計算差值。
ci=|ai-bi|
(2)
(2)計算差值的最大值和最小值。
Cmax=max(C),C={c1,c2,…,cn}
(3)
Cmin=min(C),C={c1,c2,…,cn}
(4)
(3)計算單一元素的灰色關聯度。
(5)
(4)計算總體灰色關聯度。
(6)
式中:ci、ai、bi分別表示第i個差值和不同序列的第i個元素;p為分辨系數,其范圍為[0,1],其值越大,分辨能力越強,通常取0.5。
通過Pearson相關系數分析氣象特征與風電功率數據之間的線性相關性[12],通過灰色關聯分析氣象數據曲線與風電功率數據曲線之間的關聯性[13]。同時,為了更加全面地對氣象特征與風電功率數據之間的相關性進行評價,提出一種趨勢相關系數(trend correlaction coefficient,TCC),用來衡量氣象數據發展趨勢與風電功率數據發展趨勢之間的相關性,其計算步驟如下。
(1)計算不同序列的趨勢變化值。
Ca=at-at-1,t=2,3,…,n
(7)
Cb=bt-bt-1,t=2,3,…,n
(8)
(2)比較單一時刻趨勢變化是否相同。
(9)
(3)計算整體趨勢相關系數。
(10)
式中:Ca、Cb分別表示序列a和序列b不同時刻的趨勢變化值;at-1、at分別表示序列a第t時刻和第t-1時刻的數據;ζt表示第t時刻兩序列的趨勢變化情況;ζ表示兩序列整體的趨勢相似系數,其范圍為[0,1],其數值越大,表示兩個序列之間的發展越相似。
通過上述的三種相關性評價方法對氣象特征和風電功率數據之間的相關性進行分析,然后計算均值作為最終的綜合相關性系數,實現更為全面、準確地對進行特征選擇,對后續預測模型精度較大的提高。CCE模型的結構如圖1所示。
1.1.2 LSTM神經網絡
LSTM神經網絡是目前常用于時間序列數據預測的深度學習模型。LSTM神經網絡的核心為三種“門”:遺忘門、輸入門、輸出門[14]。LSTM為實現對數據時序性的考慮,通過輸入門和遺忘門對細胞狀態進行更新,然后將在計算下一時刻的細胞狀態時,考慮該時刻的細胞狀態。其過程如下所示。
(1)遺忘門對上一時刻的隱藏狀態和該時刻的輸入進行計算。
ft=σ(Wf[ht-1,xt]+bf)
(11)
(2)輸入門對上一時刻的隱藏狀態和該時刻的輸入進行計算。
it=σ(Wi[ht-1,xt]+bi)
(12)
(13)
(3)更新該時刻的細胞狀態。
(14)

更新完細胞狀態后,便可以對當前時刻的輸出以及要向下一時刻傳遞的隱藏狀態進行計算,其計算公式為
ot=σ(Wo[ht-1,xt]+bo)
(15)
ht=ottanh(Ct)
(16)
式中:ot為第t時刻輸出門的輸出;Wo為輸出門的權重;bo為輸出門的偏置權重;σ為Sigmoid函數。
通過門控機制,LSTM可以實現對數據集時序性的考慮。同時,LSTM作為一種目前主流的深度學習模型,對多維數據的處理性能更優,因此,將LSTM與提出的CCE模型結合,通過多維氣象數據對風電功率進行預測。
1.2 SECEEMD-BP預測模型
風電功率數據除了受到多維氣象因素的影響外,還受到自身數據不平穩性的影響。由于風的波動性、隨機性,導致風電功率數據的不平穩性[15],使得后續預測模型的預測精度較低,因此,提出采用樣本熵改進的CEEMD分解算法對風電功率數據進行分解,在將其平穩化的同時,降低分量數量,保證分量的時序穩定性。
1.2.1 SECEEMD分解算法
針對非平穩的時序數據,對其使用時序分解便可以將其平穩化[16],使得可以更加容易地獲取到時序數據的特征趨勢,從而提高時序預測的精度。
CEEMD分解算法是目前信號分解領域較新的分解算法[17],該分解算法雖然解決了EMD分解算法存在的模態混疊問題[18]和EEMD存在的對數據完整性造成影響的問題[19],但隨著數據量的增大,CEEMD分解算法會出現分解出的分量過多,分解不完全,模態混疊程度加劇的情況。
針對這一問題,對CEEMD分解算法進行了改進。樣本熵作為一種衡量時序數據混亂性時序熵,其值越大,時序數據的混亂性、隨機性越大,產生新模式的可能性越高。其計算方式如下所示。
(1)將原始數據劃分為窗口大小為m的時間窗口序列。
Xi=[xi,xi+1,…,xi+m-1]
(17)
(2)計算除自身外,與其他窗口的距離。
d=max(|xi-xj|)
(18)
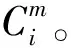
(19)
(4)計算平均值φm。
(20)
(5)將m+1,重復步驟(1)~(4),得出另一個平均值φm+1。
(6)計算樣本熵。
sampen=lnφm-lnφm+1
(21)
式中:xi和xj屬于不同時間窗口對應的數據;db為超過閾值的距離的個數。
由于樣本熵能夠對時序數據的混亂性進行衡量,因此,為了降低分量產生新模式的概率,提高預測模型的預測精度,提出使用樣本熵對CEEMD分解算法進行改進。該改進算法通過樣本熵對分量進行進一步篩選,剔除其中混亂程度較高的分量,保證分量的時序穩定性,其步驟如下所示。
(1)向原始數據中添加M組正負相抵的白噪聲。
X+(t)=X(t)+c+(t)
(22)
X-(t)=X(t)+c-(t)
(23)
(2)對添加白噪聲的數據進行EMD分解。
(3)將多次分解后的分量求平均,得到CEEMD分解的分量。
(24)
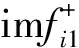
(4)計算每個分量的樣本熵。
(5)通過設定的混亂性閾值,對高于該閾值的分量從原始數據中剔除,低于該閾值的分量保留,作為后續預測模型的輸入特征。
通過SECEEMD分解算法,將非平穩的風電功率數據平穩化,并且降低了分量數量,保證了分量的時序穩定性,在提高后續預測模型訓練速度的同時,提高模型的預測精度。
1.2.2 BP神經網絡
BP神經網絡是最為經典的神經網絡。在目前風電功率預測領域中,很多研究將BP神經網絡作為風電功率單特征預測的預測模型。BP神經網絡的核心為“前向預測,反向修正”,結構為三層網絡結構,包括:輸入層、隱藏層、輸出層,每一層有多個神經元,每個神經元與下一層的每個神經元連接,并擁有一個權重。通過將輸入與權重相乘,然后加上每一層的偏置權重,得到該層的輸出,然后通過激活函數,輸出到下一層,作為下一層的輸入。
BP神經網絡的反向修正是其最為重要的核心。通過反向修正,可以依據預測與真實值的誤差對神經網絡的權重進行更新,從而實現對真實值更加貼近的預測。其主要公式為
(25)
(26)
ωjk=ωjk+ηHjek
(27)
(28)
bk=bk+ηek
(29)
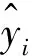
通過上述公式,可以對BP神經網絡每一層的權重進行更新,使預測值與真實值逐漸貼近,逐漸擬合。
1.3 改進熵權法以及組合模型
權重分配方式對于組合模型尤為重要,決定了組合模型最終的預測性能。為保證權重分配的客觀性,結合貝葉斯尋優算法對熵權法進行改進,通過改進的熵權法計算NWP-CCE-LSTM預測模型和SECEEMD-BP預測模型的權重,并對其預測值進行組合。
1.3.1 BO-EWM權重分配
熵權法(entropy weight method,EWM)是一種客觀權重賦予辦法,通過信息熵來對權重進行計算[20]。信息熵是一種衡量數據信息量的熵值,其數值越大,信息量越小,那么發生的概率越大。在目前的風電概率預測領域中,已有人使用熵權法作為組合模型的權重分配方式,例如:楊錫運等[21]通過熵權法計算了風電概率組合概率區間預測模型的權重。以NWP-CCE-LSTM預測模型為例,熵權法的步驟如下所示。
(1)將預測值與驗證值的MAE、MSE、MAPE組為N×3的矩陣。
(30)
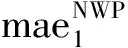
(2)計算單一指標占該指標全部數據的概率,以NWP-CCE-LSTM的MAE為例。
(31)
(3)計算單一指標的信息熵,以NWP-CCE-LSTM的MAE為例。
(32)
式(32)中:emae為通過NWP預測的預測值的mae的信息熵;N為預測數據的總量。
(4)計算該預測模型總體信息熵。
(33)
式(33)中:eNWP為通過NWP預測的預測值的整體信息熵;emae為預測值的emae的信息熵;emse為預測值的mse的信息熵;emape為預測值的mape的信息熵。
(5)計算信息效用值。
dNWP=1-eNWP
(34)
式(34)中:dNWP為通過NWP預測的預測值的信息效用值。
(6)計算權重。
WNWP=dNWP/(dNWP+dSECEEMD)
(35)
式(35)中:WNWP為通過NWP預測的預測值的權重;dSECEEMD為通過SECEEMD預測的預測值的信息效用值。
通過上述步驟,便可計算兩個預測模型的客觀權重。但客觀的權重分配無法使組合模型的預測精度達到最佳,因此,需要向對權重分配方案進行進一步尋優。
貝葉斯優化算法(Bayesian optimiazation,BO)是一種參數優化算法,可以對神經網絡的結構進行優化[22]。該算法的本質為通過給定的目標函數,通過采集函數來確定參數的范圍,然后考慮上一次的信息,來更好地選擇參數。相較于傳統的網格搜索,貝葉斯優化算法迭代次數少,尋優速度快。
因此,結合貝葉斯優化算法和熵權法,提出了基于貝葉斯優化的熵權法 (Bayesian optimiazation entropy weight method,BO-EWM)權重分配算法。將EWM算法計算的客觀權重作為權重分配的下限,通過貝葉斯優化算法尋找最優權重組合。
1.3.2 組合模型
本文提出了一種基于改進熵權法和SECEEMD的風電功率短期組合預測方法。該方法針對影響風電功率的多維氣象因素和風電功率自身趨勢,分別構建了NWP-CCE-LSTM預測模型和SECEEMD-BP預測模型,并使用BO算法對模型結構進行尋優,然后使用改進的熵權法對兩個模型的權重進行計算,并依據最優權重組合,將兩個模型的預測值組合為最終預測值。組合模型的整體結構如圖2所示。
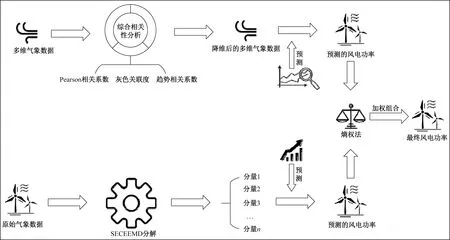
圖2 整體流程圖
2 實例驗證
2.1 實驗數據
本文所使用的數據為內蒙古碧柳河風電場2019年1月1日至2019年3月1日的實采數據,包含了風電功率數據以及多維氣象數據,其中多維氣象數據包括:風速、風向、溫度、濕度、空氣密度和氣壓。數據的采集頻率為15 min采集1次,共5 760條數據。本實例中將數據按照4∶1的比例將數據分為訓練集和驗證集。
2.2 模型評價指標
為合理、科學地對本文所提模型的預測性能進行評價,依照國家現行的關于風電功率預測系統的評價標準[23],選擇擬合優度(R2)、平均絕對誤差(mean absolute error,MAE)[24]、均方誤差(mean square error,MSE)、平均絕對百分比誤差(mean absolute percentage error,MAPE)[25]。以及運行時間作為評價標準,其公式如下所示。
平均絕對誤差:
(36)
均方誤差:
(37)
平均絕對百分比誤差:
(38)
2.3 數據預處理
2.3.1 缺失值填補
在神經網絡的訓練過程中,數據集的完整性對模型的性能也存在著一定的關系。時序數據會因為人為原因或一些不可抗的因素,如人為誤刪、數據采集傳感器損壞等原因,導致數據丟失或數據缺失[26],從而對數據集的完整性造成影響。針對缺失的數據,一般采用刪除法、權重法、填補法等方式[27]進行處理。由于本實驗所使用的數據集的損失率較低,因此,本實驗選擇較為簡單的均值填補方法對缺失值進行處理。
2.3.2 標準化
在多元特征預測中,由于不同的指標,其值的范圍不同,因此,為統一其范圍,需要進行標準化,將其數值統一在統一量綱分數內。無量綱化的方式有最大值-最小值方法、Z方法等。本實驗由于使用了灰色關聯分析算法,而使用該算法對使用最大值-最小值方法進行無量綱化處理的數據進行分析時,可能會存在灰色關聯度大于1的情況,因此,本實驗選擇使用Z方法。其公式為
(39)
式(39)中:Xmean為數據集的平局值;Xstd為數據集的標準差。
2.3.3 時間滑動窗口搭建
時間滑動窗口(time sliding window,TLW)是一種數據重構技術。風電輸出功率由于受到風速、風向等不穩定、隨機性強的氣象因素的影響,導致其數值同樣具有隨機性,但仍具有一定的周期性。為考慮到歷史風電功率在時間維度上的特征,提高預測精度,本實驗使用時間滑動窗口對風電功率數據進行相空間重構。
已知風電功率數據為[x1,x2,…,xn],時間滑動窗口大小為m,則重構后的風電功率數據可以表示為Xm(i)=[xi,xi+1,…,xi+m]。其重構過程如下式所示:
(40)
通過時間滑動窗口重構算法,對氣象數據、功率數據以及分解算法分解出來的分量進行重構,以便于后續的神經網絡可以捕獲到數據在時間維度上的特征。
2.4 實驗部分
2.4.1 NWP-CCE-LSTM預測
在NWP-CCE-LSTM預測部分,對全部氣象數據與風電功率數據進行相關性分析。經計算,全部氣象數據與風電功率數據之間的Pearson相關系數、灰色關聯度、趨勢相關系數以及綜合相關性系數如表1所示。
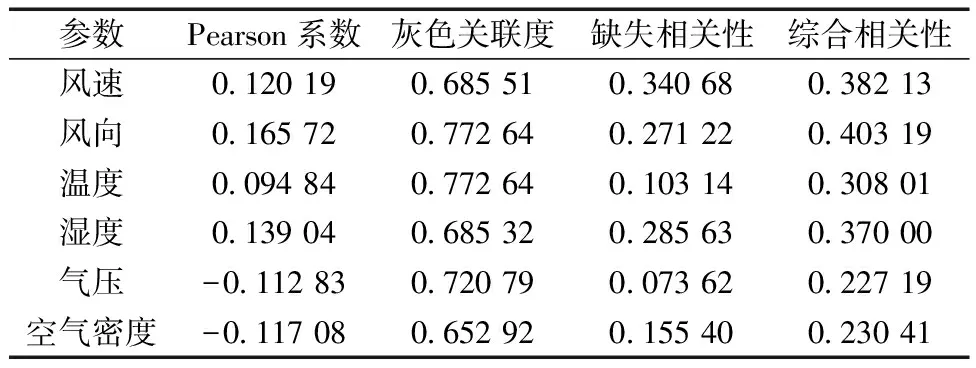
表1 不同相關性分析結果
通過表1可以看出,經過CCE模型進行相關性評價后,風速、風向、溫度和濕度相較于剩下的氣象特征與風電功率數據的相關性更強,因此,將其作為選擇的氣象特征,與風電功率數據一同作為NWP-CCE-LSTM預測模型的輸入特征。
為驗證本文所提NWP-CCE-LSTM預測模型的優勢,本實例做了大量的對比實驗,其實驗結果如表2所示。

表2 特征優化對比實驗結果
其中,實驗1為未進行特征優化,將全部氣象特征和風電功率數據一起作為LSTM的輸入特征,從中可以看出,其結果并不理想,擬合優度僅達到了91%,MAE和MSE也高達0.21和0.1,其MAPE值也超過了1,說明該模型屬于劣質模型;實驗2為使用灰色關聯度進行特征優化的結果,其R2相較于實驗1提高了1%,MAE和MSE均為輕微下降,約為0.01,MAPE下降較多,下降了0.27,但其預測精度依舊不是最理想;實驗3為使用主成分分析法對特征進行優化,雖然主成分分析法對特征數據的完整性和可解釋性造成了影響,但其作為目前主流的特征優化方法,其優化性能較為良好。經過主成分分析優化氣象特征后,模型的預測精度接近93%,提高較多,MAE、MSE和MAPE也有所下降,但由于對特征的完整性造成了影響,因此,該模型的預測精度仍有很大的提升空間;實驗4為本文提出了NWP-CCE-LSTM預測模型,經過CCE模型進行特征降維后,模型的預測性能有了很大的提升,R2達到了93.6%,相較于實驗1、實驗2和實驗3分別提高了2.4%、1.4%和0.8%,MAE、MSE和MAPE也有較大程度的下降,因此,證明了本文所提的CCE模型相較于目前主流的特征優化方法有較大的優勢,能夠為模型預測性能的提高提供更大的幫助。
2.4.2 SECEEMD-BP預測
在SECEEMD-BP預測部分,首先使用CEEMD分解算法將其分解為平穩分量,然后計算每個分量的樣本熵,其結果如表3所示。
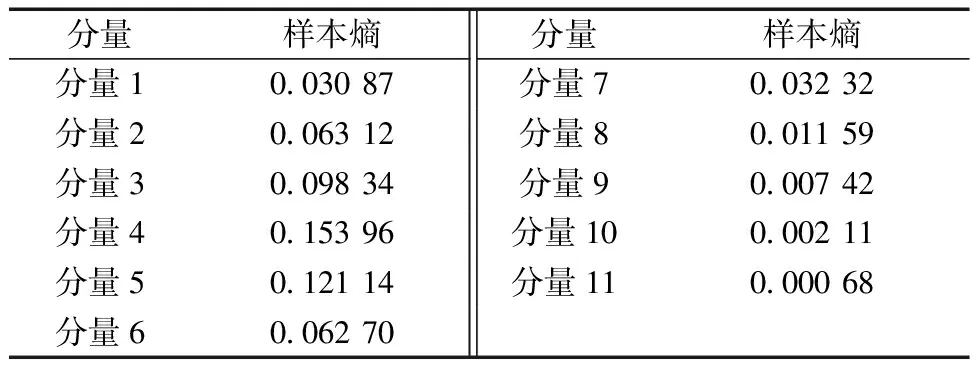
表3 所有分量的樣本熵
通過表3可以看出,經過CEEMD分解后,大部分分量處于較為平穩的狀態,其時序平穩性較好,產生隨機新模式的可能性較低,但其中仍有部分分量相較于其他分量平穩性較差,產生新模式的可能性較高,例如,分量4和分量5。因此,為提高模型的預測精度,設定樣本熵閾值,將超過閾值的分量從原始數據中剔除,保留穩定分量。為驗證本文所提SECEEMD分解算法對后續預測模型的預測性能有較大的提升,對比了CEEMD分解算法和SECEEMD分解算法,其對比結果如表4所示。

表4 不同信號分解算法的對比結果
從表4可以看出,相較于CEEMD分解算法,本文所提的SECEEMD分解算法精簡了分量,降低了分量的數量,因此使后續預測模型的運行速度較快,提高了35%。同時,由于使用樣本熵對分量進行了篩選,降低了分量產生新模式的幾率,使模型的預測精度有所提高,R2提高了0.3%,MAE降低了1.5%,MAPE的大幅度降低,說明SECEEMD更加適合對風電功率數據進行處理。
2.4.3 組合模型預測
在該部分,以NWP-CCE-LSTM預測模型和SECEEMD-BP預測模型的評價標準為基礎數據,通過改進的熵權法對兩種預測模型的權重進行計算。經計算最優權重為NWP-CCE-LSTM的預測值占10%,SECEEMD-BP的預測值占90%。為證明改進熵權法對組合模型的有效提高,本文做了對比實驗,其結果如表5所示。

表5 不同權重分配方式的對比結果
其中,實驗1為使用熵權法計算的客觀權重作為權重分配方式的組合模型預測性能,其R2已經達到了97.3%,相較于單一模型有了較大的提高,MAE為0.104 16,MAPE的結果并不理想,達到了2.12,屬于劣質模型,說明以熵權法計算的客觀權重作為權重分配方式并不合適;實驗2為使用改進的熵權法尋找出的最優權重作為權重分配方式,相較于實驗1,其預測精度提高了0.3%,MAE下降了1%,但MAPE降為了0.47,下降了77.6%,MAPE的大幅度下降,證明改進的熵權法模型對于風電功率預測更加合適。
組合后,模型的部分預測值與驗證值的擬合程度如圖3所示。

圖3 最終預測值與驗證值的擬合程度
3 結論
實現風電功率的高精度預測,結合多維氣象數據和風電功率本身趨勢對風電功率預測的影響,提出了一種基于熵權法和SECEEMD的風電功率組合預測方法。
(1)提出了一種新的相關性評價方法——CCE,綜合相關性評價方法,并且經過實例驗證,該方法相較于目前主流的相關性評價方法,能夠為預測模型提供更加準確的特征。然后結合該方法,針對多維氣象數據對風電功率預測的影響,提出了NWP-CCE-LSTM預測模型。
(2)使用樣本熵對CEEMD分解算法進行改進,并且經過實例驗證,SECEEMD能夠大幅度提高模型的預測速度,降低分量產生新模式的概率,提高模型的預測精度。
(3)結合貝葉斯優化算法對熵權法進行改進,結合熵權法的客觀權重計算方法和貝葉斯優化算法的尋優能力,計算出組合模型的最優權重分配方式。經實例驗證,改進后的熵權法能夠提高模型的預測精度,大幅度提高模型的合適程度。
本文所提的組合預測方法,在特征優化方法、信號分解方法以及組合模型權重賦予方法上進行了改進,并經過實例驗證,改進后的方法均能夠對后續模型的預測性能有所提升,為風電功率預測的研究提供了一種有效方法,但仍有改進地方,目前僅為時域的分析,對于整體趨勢的捕獲能力不足,使其預測精度無法達到最大值,后續會以這一點為研究目標進行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
