基于預(yù)訓(xùn)練模型的代碼分類(lèi)研究
2023-10-08 13:15:14洪慶成謝春麗
軟件工程 2023年10期
梁 瑤, 洪慶成, 王 霞, 謝春麗
(江蘇師范大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院, 江蘇 徐州 221116)
0 引言(Introduction)
隨著開(kāi)源代碼倉(cāng)庫(kù)的出現(xiàn),網(wǎng)絡(luò)上存在大量的源代碼文件,對(duì)代碼進(jìn)行功能分類(lèi)可幫助開(kāi)發(fā)者快速找到要復(fù)用的代碼或組件,有利于開(kāi)發(fā)過(guò)程中代碼的重用、理解、查找和維護(hù),因此代碼分類(lèi)是各種軟件開(kāi)發(fā)任務(wù)的基礎(chǔ)工作。HINDLE等[1]的研究表明程序語(yǔ)言和自然語(yǔ)言都包含豐富的統(tǒng)計(jì)特性,利用自然語(yǔ)言的文本分類(lèi)技術(shù)能夠有效地實(shí)現(xiàn)源代碼分類(lèi)。基于深度學(xué)習(xí)的文本分類(lèi)從淺層表示轉(zhuǎn)變到深層學(xué)習(xí)表示,分類(lèi)的準(zhǔn)確性與穩(wěn)定性得到了顯著提升。但是,目前的方法多屬于有監(jiān)督學(xué)習(xí),需要大量帶標(biāo)注的數(shù)據(jù)集作為訓(xùn)練樣本,而人工標(biāo)注數(shù)據(jù)集不僅代價(jià)高,而且耗時(shí)長(zhǎng)。針對(duì)這一現(xiàn)狀,提出了基于CodeBERT的代碼預(yù)訓(xùn)練模型,首先利用無(wú)監(jiān)督學(xué)習(xí)技術(shù)針對(duì)大量無(wú)標(biāo)簽的源代碼學(xué)習(xí)其語(yǔ)法、語(yǔ)義、上下文語(yǔ)境等特征信息,其次構(gòu)建分類(lèi)器,在少量有監(jiān)督數(shù)據(jù)集上進(jìn)行微調(diào),實(shí)現(xiàn)代碼分類(lèi)任務(wù)。
1 相關(guān)工作(Related work)
代碼分類(lèi)是通過(guò)一定的標(biāo)準(zhǔn)、規(guī)則將實(shí)現(xiàn)不同功能、語(yǔ)義不相似的代碼進(jìn)行區(qū)分,最終將語(yǔ)義相似、功能相同的源代碼歸為同一類(lèi)別的過(guò)程。代碼分類(lèi)首先要從代碼不同的抽象層次上提取代碼文本中蘊(yùn)含的特征信息,其次根據(jù)分類(lèi)器映射到不同的類(lèi)別中,不同的表征方式會(huì)影響特征提取的有效性。對(duì)于實(shí)現(xiàn)不同功能的源代碼進(jìn)行相似度檢測(cè)的前提,是將源代碼按照一定的粒度級(jí)別切分為基本代碼單元,即檢測(cè)粒度。目前,代碼分類(lèi)研究根據(jù)粒度劃分級(jí)別主要采用固定切分和自由切分兩種方式。固定切分主要包括按行切分、按塊切分、按函數(shù)切分、按文件切分和按項(xiàng)目切分等,對(duì)于固定切分,如果劃分的粒度級(jí)別太大,則源代碼切分后的丟失檢查概率會(huì)很高,如果劃分的粒度級(jí)別太小,則檢測(cè)工作會(huì)耗費(fèi)更多的時(shí)間與精力。因此,在具體的應(yīng)用中,可以采用多種粒度對(duì)源代碼進(jìn)行切分操作,例如按照Token切分、按字符串切分、按特征向量切分、按樹(shù)結(jié)點(diǎn)切分和按子圖結(jié)構(gòu)切分等,不同源代碼的表征粒度直接影響相似性計(jì)算的精度。
早期的代碼分類(lèi)是借鑒文本分類(lèi)的方法,20世紀(jì)50年代至60年代,文本分類(lèi)領(lǐng)域的資深學(xué)者通過(guò)積累的工作經(jīng)驗(yàn)定義一些規(guī)則,從而實(shí)現(xiàn)分類(lèi),這種方法不僅耗時(shí)費(fèi)力,還要求研究人員必須對(duì)某一領(lǐng)域有足夠深入的了解,才能總結(jié)分類(lèi)規(guī)則并進(jìn)行分類(lèi)篩選,因此文本分類(lèi)方法的局限性較大。針對(duì)該問(wèn)題,基于統(tǒng)計(jì)學(xué)中字詞頻率的思想,提出了支持向量機(jī)(Support Vector Machine,SVM)技術(shù),推動(dòng)了文本分類(lèi)的進(jìn)一步發(fā)展。與此同時(shí),深度學(xué)習(xí)技術(shù)在自然語(yǔ)言領(lǐng)域的成功應(yīng)用給代碼分類(lèi)帶來(lái)了新的突破,MOU等[2]通過(guò)一個(gè)單層神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)抽象語(yǔ)法樹(shù)(Abstract Syntax Tree,AST)中上層結(jié)點(diǎn)的詞向量,提出一種基于樹(shù)的卷積神經(jīng)網(wǎng)絡(luò)模型(Tree-Based Convolutional Neural Network,TBCNN)進(jìn)行代碼分類(lèi)。BEN等[3]針對(duì)代碼本身具有的一些結(jié)構(gòu)化特性,提出了連續(xù)空間的語(yǔ)句向量(Inst2vec)模型,該模型在代碼分類(lèi)和性能預(yù)測(cè)等多種任務(wù)中獲得了很好的效果。ZHANG等[4]提出了語(yǔ)句級(jí)別的向量嵌入,有效捕獲了代碼的語(yǔ)法和語(yǔ)義信息,學(xué)習(xí)的代碼向量被用于代碼克隆檢測(cè)和代碼分類(lèi),取得了良好的分類(lèi)效果。預(yù)訓(xùn)練模型能從大量無(wú)標(biāo)簽數(shù)據(jù)中學(xué)習(xí)代碼的特征信息,因此被廣泛應(yīng)用于代碼表征任務(wù)[5]。例如,自監(jiān)督預(yù)訓(xùn)練模型(InferCode)[6]和基于BERT的預(yù)訓(xùn)練模型(CodeBERT)[7]。本文將CodeBERT預(yù)訓(xùn)練模型引入代碼分類(lèi)任務(wù),一方面利用預(yù)訓(xùn)練模型強(qiáng)大的特征學(xué)習(xí)能力提高代碼分類(lèi)的性能,另一方面避免進(jìn)行昂貴的人工標(biāo)記,降低了實(shí)驗(yàn)成本。
2 代碼分類(lèi)模型(Code classification model)
代碼分類(lèi)模型主要由源碼預(yù)處理、源代碼文本表征以及構(gòu)建分類(lèi)器三個(gè)部分組成,數(shù)據(jù)預(yù)處理主要是克服源代碼文本的篇幅長(zhǎng)度、空白字符等消極因素對(duì)模型的影響。源代碼文本表征指利用CodeBERT模型將源代碼文本中的每一個(gè)詞映射為詞向量,所有詞向量經(jīng)過(guò)拼接處理、特征提取后,可以得到整篇文本的向量化表示,文本表征的輸出向量是分類(lèi)器的輸入,將源代碼的表征向量送入Softmax層進(jìn)行測(cè)試并評(píng)估結(jié)果,實(shí)現(xiàn)代碼分類(lèi)。
2.1 源碼預(yù)處理
首先將獲取的源代碼數(shù)據(jù)集進(jìn)行預(yù)處理,使數(shù)據(jù)集盡可能地符合預(yù)訓(xùn)練模型的輸入要求,其次對(duì)處理后的源代碼數(shù)據(jù)集進(jìn)行向量化操作,使得分類(lèi)的源代碼文本向量可以被模型訓(xùn)練學(xué)習(xí)。目前,常見(jiàn)的文本預(yù)處理方法有清除文本雜質(zhì)、去停用詞、類(lèi)別匹配和文本過(guò)濾等[8]。清除中文文本雜質(zhì)的具體流程一般包括消除難以識(shí)別的特殊符號(hào)、刪除多余的空白字符、將繁體漢字轉(zhuǎn)換為簡(jiǎn)體漢字三個(gè)過(guò)程。由于本文數(shù)據(jù)集是源代碼文本,因此本文中去除源代碼文本雜質(zhì)的流程包括清除計(jì)算機(jī)難以辨識(shí)的特殊符號(hào)和刪除多余的空白字符兩項(xiàng)操作,使源代碼文本的特征表示只關(guān)注源代碼中每一個(gè)token的語(yǔ)義和特征信息,從而提取源代碼文本中有價(jià)值的特征信息,以獲得更加有效的代碼表征。由于源代碼文本中通常存在輸入輸出、語(yǔ)句分隔符、括號(hào)等反復(fù)出現(xiàn)且無(wú)重要信息的詞,所以本文將這類(lèi)詞加入停用詞詞庫(kù)進(jìn)行篩選,避免無(wú)特殊含義的詞作為輸入詞。由于在分類(lèi)任務(wù)中需要少量有監(jiān)督的樣本,因此需要預(yù)先知道源代碼實(shí)現(xiàn)的功能并對(duì)其進(jìn)行標(biāo)注處理,將實(shí)現(xiàn)相同功能的源代碼文本整理在同一個(gè)文件夾中。為防止源代碼文本篇幅長(zhǎng)度超過(guò)本文模型的輸入范圍和樣本數(shù)據(jù)分布不一致問(wèn)題,本文將對(duì)源代碼文本的篇幅長(zhǎng)度進(jìn)行篩選并對(duì)所有類(lèi)別的文本進(jìn)行整體過(guò)濾。
2.2 源代碼文本表征
傳統(tǒng)研究方法通過(guò)詞向量(Word2vec)模型[9]得到源代碼文本的詞向量,經(jīng)過(guò)此模型訓(xùn)練得到的不同詞向量的大小固定,而一篇完整的文本可能由許多不同的字詞組成,真正有價(jià)值的字詞往往只占很小的一部分。此外,由于Word2vec模型訓(xùn)練得到的詞向量相同,而相同詞向量對(duì)應(yīng)的字詞在不同的語(yǔ)境中表達(dá)的含義不同,因此為符合現(xiàn)實(shí)的語(yǔ)義要求,使用CodeBERT模型替代Word2vec模型訓(xùn)練文本向量。
在預(yù)訓(xùn)練階段,CodeBERT模型的輸入通常設(shè)置為自然語(yǔ)言片段與程序語(yǔ)言片段組成的一個(gè)句子對(duì),它們之間用一個(gè)特殊分隔符[SEP]進(jìn)行分隔,具體的輸入形式為[CLS],w1,w2,…,wn,[SEP],c1,c2,…,cm,[EOS],其中第一個(gè)片段w1,w2,…,wn是自然語(yǔ)言文本,n為文本長(zhǎng)度,第二個(gè)片段c1,c2,…,cm則是程序語(yǔ)言文本,m為程序長(zhǎng)度。[CLS]、[SEP]和[EOS]是具有特殊作用的標(biāo)志,[CLS]固定位于輸入語(yǔ)句對(duì)的開(kāi)頭,[SEP]標(biāo)志僅用于分隔輸入語(yǔ)句對(duì)中不同模態(tài)的語(yǔ)言,在后面的訓(xùn)練過(guò)程中一般無(wú)特殊作用,[EOS]則固定位于輸入語(yǔ)句對(duì)的結(jié)尾,它本身不具有任何特殊的含義。
CodeBERT的輸出包括每個(gè)token的上下文向量表示和[CLS]的表示。[CLS]作為聚合序列表示蘊(yùn)含整篇文本的豐富語(yǔ)義信息,在下游任務(wù)中一般使用[CLS]表征向量,對(duì)其參數(shù)進(jìn)行微調(diào)可以實(shí)現(xiàn)不同的功能應(yīng)用。由于實(shí)驗(yàn)數(shù)據(jù)集使用的是C++源碼,其本質(zhì)不含有任何自然語(yǔ)言的單模態(tài)數(shù)據(jù),所以輸入的具體形式為[CLS],c1,c2,…,cm,[EOS]。通過(guò)模型訓(xùn)練可以得到源代碼中每一個(gè)token的向量化表示和蘊(yùn)含整篇文本信息的[CLS]向量,在后期的分類(lèi)任務(wù)中,利用[CLS]向量初始化分類(lèi)器。
2.3 構(gòu)建分類(lèi)器
2.3.1 Softmax回歸模型
本文使用Softmax回歸模型[10]實(shí)現(xiàn)代碼功能的多分類(lèi)任務(wù)。Softmax回歸模型是邏輯回歸模型在多分類(lèi)問(wèn)題中的延伸與擴(kuò)展,一般采用極大似然估計(jì)的方法進(jìn)行參數(shù)估計(jì),主要是對(duì)已知標(biāo)簽類(lèi)型的樣本進(jìn)行學(xué)習(xí)訓(xùn)練從而優(yōu)化模型,因此經(jīng)過(guò)預(yù)處理的數(shù)據(jù)非常適合有監(jiān)督學(xué)習(xí)任務(wù)。例如,{(x1,y1),(x2,y2),…,(xN,yN)},xi(i=1,2,…,N)表示第i篇源代碼文本對(duì)應(yīng)的向量表征,N是訓(xùn)練集中源代碼文本的數(shù)量,yi∈{1,2,…,K},K是分類(lèi)數(shù)量,yi表示第i篇源代碼文本對(duì)應(yīng)的標(biāo)簽,即該篇源代碼實(shí)現(xiàn)的功能,由于本文研究的代碼分類(lèi)屬于多分類(lèi)問(wèn)題,所以K>2。
在測(cè)試集中,輸入樣本xi,Softmax回歸模型會(huì)根據(jù)分布函數(shù)公式計(jì)算條件概率,即給定測(cè)試集中樣本xi屬于某一個(gè)類(lèi)別的概率,其中出現(xiàn)概率最大的類(lèi)別即當(dāng)前樣本xi所屬的代碼功能類(lèi)別。
因此,最終分布函數(shù)會(huì)輸出一個(gè)K維向量,每一維度的數(shù)值表示當(dāng)前樣本屬于已知類(lèi)別中某一類(lèi)別的概率,并且模型將K維向量進(jìn)行求和運(yùn)算,然后做歸一化處理,使得所有向量元素和為1,Softmax回歸模型的判別函數(shù)hθ(xi)如公式(1)所示:
(1)
判別函數(shù)中的概率公式p(yi=j|xi;θ)(j=1,2,…,K)是當(dāng)前樣本屬于目標(biāo)類(lèi)別j的概率,根據(jù)網(wǎng)絡(luò)的前向運(yùn)算獲得K個(gè)輸出概率值,選擇具有最大輸出值的類(lèi)別yk作為本文研究的預(yù)測(cè)值,θ為網(wǎng)絡(luò)權(quán)值參數(shù)。
2.3.2 代碼分類(lèi)模型構(gòu)建
本文提出基于CodeBERT的代碼分類(lèi)模型,其輸入為訓(xùn)練集U的源代碼文本U={(x1,y1),(x2,y2),…,(xN,yN)},(xi,yi)∈U(i=1,2,…,N),xi為第i篇源代碼文本,yi為第i篇源代碼文本對(duì)應(yīng)的標(biāo)簽,即該篇源代碼實(shí)現(xiàn)的功能,輸出是源代碼分類(lèi)模型,具體步驟如下。
(1)訓(xùn)練集U經(jīng)過(guò)預(yù)處理后得到訓(xùn)練集U′,源代碼文本預(yù)處理首先刪除文本空白字符,降低輸入樣本的特征維度,其次去除停用詞,消除沒(méi)有價(jià)值的字詞對(duì)模型訓(xùn)練的消極影響,最后進(jìn)行長(zhǎng)度切分處理,使輸入源代碼文本的篇幅長(zhǎng)度符合模型的輸入要求。
(2)使用CodeBERT預(yù)訓(xùn)練模型在訓(xùn)練集U上進(jìn)行微調(diào),通過(guò)CodeBERT模型處理之后輸出得到訓(xùn)練集U′對(duì)應(yīng)的特征表示V={v1,v2,…,vN},其中vi∈V(i=1,2,…,N)是每條源代碼文本xi對(duì)應(yīng)句子級(jí)別的特征向量。在具體的實(shí)驗(yàn)過(guò)程中,輸入的源代碼文本經(jīng)過(guò)CodeBERT模型訓(xùn)練得到的[CLS]向量包含該篇源代碼的綜合語(yǔ)義信息,提取了每一語(yǔ)句中重要字詞的特征信息。
(3)將每一篇源代碼對(duì)應(yīng)的特征表示V輸入Softmax回歸模型進(jìn)行分類(lèi)處理,Softmax回歸模型會(huì)根據(jù)分布函數(shù)的條件概率公式計(jì)算出該篇源代碼最有可能對(duì)應(yīng)的功能類(lèi)別。
(4)源代碼文本分類(lèi)模型輸出每一篇源代碼的標(biāo)簽。
3 實(shí)驗(yàn)與分析(Experiment and analysis)
本文主要進(jìn)行了兩個(gè)實(shí)驗(yàn),即基于CodeBERT和基于Text-CNN的代碼分類(lèi),本節(jié)主要介紹實(shí)驗(yàn)中使用的實(shí)驗(yàn)數(shù)據(jù)、實(shí)驗(yàn)過(guò)程及實(shí)驗(yàn)結(jié)果。基于CodeBERT的代碼分類(lèi)如圖1所示。
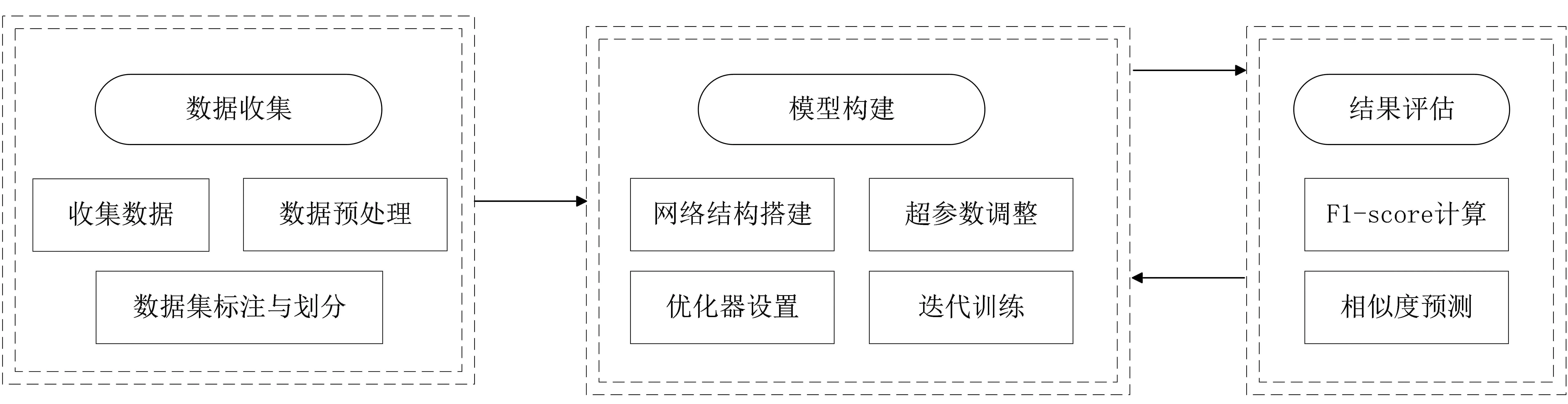
圖1 基于CodeBERT的代碼分類(lèi)Fig.1 Code classification based on CodeBERT
3.1 數(shù)據(jù)集
本文收集了江蘇師范大學(xué)教學(xué)科研輔助平臺(tái)中學(xué)生提交的C++源代碼課程作業(yè)作為數(shù)據(jù)集,其中包括35個(gè)種類(lèi),共905篇源代碼,每個(gè)文件夾種類(lèi)都代表一種功能的實(shí)現(xiàn),包括但不限于進(jìn)制轉(zhuǎn)換、歐幾里得算法、求逆序數(shù)、迪杰斯特拉算法及判斷閏年。雖然每個(gè)種類(lèi)的文件夾內(nèi)又包含了數(shù)量不等的源代碼文本,但是不同種類(lèi)的源代碼文本的數(shù)量符合相同的數(shù)學(xué)分布,即具有大致相同的均值與方差,所以將這些數(shù)據(jù)進(jìn)行訓(xùn)練學(xué)習(xí)可以避免實(shí)驗(yàn)誤差。本文設(shè)置的兩組實(shí)驗(yàn)均采用相同的數(shù)據(jù)集,模型評(píng)價(jià)指標(biāo)主要為精確率(Precision)、準(zhǔn)確率(Accuracy)、召回率(Recall)和F1值。
3.2 實(shí)驗(yàn)
3.2.1 基于CodeBERT的實(shí)驗(yàn)
本文實(shí)驗(yàn)主要使用CodeBERT預(yù)訓(xùn)練模型對(duì)預(yù)處理后帶標(biāo)簽的源代碼數(shù)據(jù)進(jìn)行訓(xùn)練與驗(yàn)證,最終得到每一篇源代碼的特征向量,該特征向量不僅含有源代碼的語(yǔ)法與語(yǔ)義信息,還包含豐富的上下文語(yǔ)境信息,最終將每一篇源代碼的特征向量送入全連接層進(jìn)行拼接,連接Softmax層實(shí)現(xiàn)分類(lèi)。本文實(shí)驗(yàn)將預(yù)處理后生成的帶有標(biāo)簽的數(shù)據(jù)集劃分為訓(xùn)練集、驗(yàn)證集,便于后續(xù)CodeBERT模型讀取和處理,數(shù)據(jù)文件的每一行都表示為源代碼標(biāo)簽。訓(xùn)練集和驗(yàn)證集均經(jīng)過(guò)充分的打亂,服從同樣的數(shù)據(jù)分布,便于模型訓(xùn)練的調(diào)參和結(jié)果評(píng)估。
由于本文實(shí)驗(yàn)設(shè)備存在內(nèi)存限制與運(yùn)行效率低的局限性,因此對(duì)本文實(shí)驗(yàn)的數(shù)據(jù)進(jìn)行劃分,按批次輸送到模型中。本文模型在驗(yàn)證集上取得的精確率最高為0.983,F1值最高為0.96,具體的實(shí)驗(yàn)結(jié)果如表1所示。

表1 CodeBERT模型實(shí)驗(yàn)結(jié)果Tab.1 Experimental results based on CodeBERT
3.2.2 基于Text-CNN的實(shí)驗(yàn)
本文實(shí)驗(yàn)對(duì)數(shù)據(jù)集進(jìn)行預(yù)處理,匹配并標(biāo)記源碼,按8∶1∶1的比例將其劃分為訓(xùn)練集、測(cè)試集和驗(yàn)證集。由于Text-CNN模型數(shù)據(jù)最終的輸入形式為源碼的路徑信息,因此需要將樣本數(shù)據(jù)集轉(zhuǎn)化為文本文件,該文本文件的具體內(nèi)容為組合后源代碼的不同路徑信息及它們的標(biāo)簽。本文實(shí)驗(yàn)同樣劃分?jǐn)?shù)據(jù),將其按批次輸送到模型中計(jì)算余弦相似度衡量代碼語(yǔ)義相似度。
本文模型經(jīng)過(guò)反復(fù)訓(xùn)練,相似度閾值范圍取[0,1],F1值的最好結(jié)果為0.846(如圖2所示),其對(duì)應(yīng)的精確率為0.853,召回率為0.840。
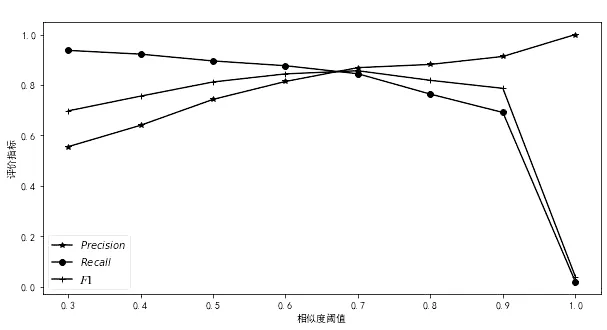
圖2 基于Text-CNN實(shí)驗(yàn)結(jié)果Fig.2 Experimental results based on Text-CNN model
3.3 實(shí)驗(yàn)結(jié)果與分析
本文的兩個(gè)實(shí)驗(yàn)使用了相同的C++源碼數(shù)據(jù)集,并采用了兩種不同的方式從本質(zhì)上實(shí)現(xiàn)了代碼分類(lèi)。因此,本文實(shí)驗(yàn)對(duì)比分析具有可信度且從對(duì)比結(jié)果來(lái)看,本文實(shí)驗(yàn)為代碼分類(lèi)研究提供了新方法、新工具。基于CodeBERT的模型訓(xùn)練和基于Text-CNN的模型訓(xùn)練對(duì)比結(jié)果如表2所示。

表2 實(shí)驗(yàn)對(duì)比結(jié)果Tab.2 Comparison of experimental results
實(shí)驗(yàn)結(jié)果表明,基于CodeBERT預(yù)訓(xùn)練模型的方法可以更全面、準(zhǔn)確地反映代碼之間的結(jié)構(gòu)關(guān)系、語(yǔ)義關(guān)系,具有更好的性能指標(biāo)。但是,該實(shí)驗(yàn)存在模型整體結(jié)構(gòu)單一、在識(shí)別粒度更小的結(jié)構(gòu)上存在不足等問(wèn)題。對(duì)于相似度計(jì)算實(shí)驗(yàn),后期將進(jìn)一步研究關(guān)鍵詞、語(yǔ)義、語(yǔ)法、結(jié)構(gòu)等方面對(duì)代碼分類(lèi)結(jié)果的影響,設(shè)計(jì)更全面的檢測(cè)方法。
4 結(jié)論(Conclusion)
在數(shù)據(jù)量日益激增的信息化時(shí)代,如何高效地處理與提取文本數(shù)據(jù)的有效信息具有非常重要的研究?jī)r(jià)值。本文在解決源代碼的分類(lèi)問(wèn)題時(shí),使用CodeBERT預(yù)訓(xùn)練模型替代傳統(tǒng)的Word2vec模型作詞嵌入操作,利用學(xué)習(xí)得到的文本向量實(shí)現(xiàn)分類(lèi)。實(shí)驗(yàn)通過(guò)更新參數(shù)為模型挑選適合的優(yōu)化器,其性能比一般基于文本的詞向量方法優(yōu)越。
通過(guò)實(shí)驗(yàn)對(duì)比發(fā)現(xiàn),本文實(shí)驗(yàn)中源代碼的表征方法可以充分利用文本的結(jié)構(gòu)與上下文信息,但對(duì)代碼文本的局部特征信息進(jìn)行學(xué)習(xí)時(shí),其效果不如基于CNN模型表征學(xué)習(xí)得到的局部信息豐富。因此,在充分抽取文本局部特征信息的同時(shí),如何利用源代碼文本的結(jié)構(gòu)和上下文信息提高分類(lèi)效率,是未來(lái)需要進(jìn)一步研究的內(nèi)容。
猜你喜歡
小獼猴智力畫(huà)刊(2022年9期)2022-11-04 02:31:42
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
