多類屬性加權與正交變換融合的樸素貝葉斯
2023-09-25 08:55:12劉海濤陳春梅龐忠祥梁志強
計算機工程與應用 2023年18期
關鍵詞:分類
劉海濤,陳春梅,龐忠祥,梁志強,李 晴
西南科技大學信息工程學院,四川綿陽621002
樸素貝葉斯(Naive Bayes,NB)算法具有簡單、高效、可解釋性等優點,但是它的屬性條件獨立性假設在現實中很少成立[1],這將降低在現實中具有屬性依賴性樣本的分類性能。目前,學者們為了減弱屬性條件獨立性假設,已提出眾多改進方法,大致可分為七類:結構擴展[2-6]、屬性選擇[7-11]、屬性加權[12-14]、實例選擇[15-16]、實例加權[17-19]、微調[20-21]和屬性變換[22]。
結構擴展是一種通過添加有向弧來顯式地表示屬性依賴的方法。如何精確地尋找屬性依賴關系是這類方法需要解決的問題。為了解決這一問題,Friedman等人[2]提出了樹增強樸素貝葉斯(tree augmented Naive Bayes,TAN),屬性依賴性由樹狀結構表示。在TAN中,類節點直接指向所有屬性節點,每個屬性節點最多只有一個來自另一個屬性節點的父節點。事實上,TAN在學習屬性依賴性方面非常有效,但同時TAN 也帶來了相當大的計算成本。為了降低計算成本,Webb等人[3]提出了一種稱為平均單依賴估計(averaged one-dependent estimator,AODE)的集成模型。AODE將每個屬性依次視為所有其他屬性的父節點,從而構建多個超級父單依賴性估計器(super-parent one-dependent estimator,SPODE)。然后通過直接平均所有合格SPODE 的類成員概率來產生最終預測結果。除了AODE,Jiang等人[4]提出了另一種模型,稱為隱藏樸素貝葉斯(hidden Naive Bayes,HNB)。在HNB中,為每個屬性創建一個隱藏的父節點,并且隱藏父節點具有顯式語義。簡單來說,每個屬性的隱藏父級可以看作是匯聚了所有其他屬性的影響。因此,HNB 避免了學習最優結構的高計算復雜性,但考慮了所有屬性的影響。張文鈞等人[5]提出了一種基于特征增廣的生成-判別混合模型的構建方法。該方法利用特征增廣的思想對模型進行結合,從而減少了時間復雜度,增強了原始屬性的內在信息。最后將NB和HNB分別作為生成模型,將LR(logistic regression)作為判別模型,構建了NB-LR和HNB-LR兩種混合算法。
雖然結構擴展是有效的,但學習最佳結構仍然相當困難。近年來,諸多學者開始關注另一種改進NB算法的方法,即屬性選擇。由于數據集中的多余屬性不僅會增加分類模型的計算量,還會影響其分類性能。所以,屬性選擇方法[7]剔除了多余屬性,保留了樣本中貢獻度較高的相關屬性,在不改變NB結構的情況下,使其具有簡單、高效等特點[10]。但是在實際中樣本的不同屬性對該樣本的分類結果會產生不同的影響,屬性選擇方法沒有考慮不同屬性組合在分類過程中的不同重要性。
屬性加權[12]方法則考慮了不同屬性的權重問題。它通過為每個屬性分配一個不同的權重,來表示不同屬性對分類的重要程度。Jiang 等人[14]提出了一種基于相關性的屬性加權(correlation-based feature weighting,CFW)樸素貝葉斯。在CFW中,每個屬性的權重首先被定義為互相關性(屬性與類之間的相關性)和平均相互冗余(屬性之間的冗余)之間的差值。然后,再對權重進行s型變換,以確保權重值在一個規定的范圍內。實驗結果表明,CFW 的分類精度高于NB,同時還保持了最終模型的簡單性。寧可等人[23]針對多維連續型數據,通過高斯分割對屬性類別不同的多維連續型數據集進行離散化處理,并使用拉普拉斯校準、屬性關聯和屬性加權方法改進了樸素貝葉斯分類的過程。丁月等人[24]通過JS 散度公式來衡量特征項為文本帶來的信息量,然后結合類別內外的詞頻、文本頻以及用變異系數修正過的逆類別頻率對JS 散度作進一步的調整,最后將計算的屬性權重加入到樸素貝葉斯公式中,從而提升了樸素貝葉斯算法在文本分類中的性能。趙博文等人[25]利用泊松分布模型對文本特征詞進行加權,并結合NB算法對文本進行了分類。上述的屬性加權方法是通過給樣本中的屬性賦予權重,來量化不同的屬性對分類的影響。最近,Zhang 等人[26]認為原始屬性空間提供的信息可能不足以進行分類。因此,為了獲得原始屬性空間的潛在信息,Zhang等人提出了一種雙階段的屬性增強和加權樸素貝葉斯(attribute augmented and weighted Naive Bayes,A2WNB)算法。在A2WNB中,首先建立多個隨機單依賴估計器用于訓練樣本的分類。然后,將預測的類別作為潛在屬性并和原始屬性連接來得到增強屬性。最后,通過最大化模型的條件對數似然函數來優化增強屬性的權重。此外,Zhang 等人[27]提出了一種多視圖的屬性加權樸素貝葉斯(multi-view attribute weighted Naive Bayes,MAWNB)算法。該算法首先構建多個超級父單依賴估計和隨機樹,然后利用它們中的每一個依次對每個訓練實例進行分類,并使用它們的所有預測類標簽來構建兩個標簽視圖,最后通過最小化每個視圖中的負條件對數似然函數來優化每個類中的每個屬性的權重。
目前,一些研究人員又將他們的注意力轉向到了另一種更加細致的屬性加權方法,文獻[28-32]可通稱為屬性值加權,并且通過對屬性值的加權,可以使分類器性能得到進一步地提高。Yu 等人[28]假設高度預測的屬性值應該與類屬性強相關,但與其他屬性值不相關,并通過計算相關性和平均冗余之間的差值,為屬性值分配不同的權值。秦鋒等人[29]通過計算屬性值與類別之間的關聯性來獲取不同屬性值在后驗概率中的加權系數,從而提升樸素貝葉斯分類的準確率。Zhang等人[32]通過考慮屬性值的水平粒度和類標簽的垂直粒度來評估屬性之間的依賴性,并有區別地為每個類的屬性值分配一個特定的權重。
屬性變換主要是對樣本屬性之間的線性關系進行研究,如李福祥等人[22]提出的正交變換改進的樸素貝葉斯(Naive Bayes of orthogonal transformation,OTNB)算法,此算法是通過數值標記將離散屬性變換為連續屬性,之后對連續屬性和數值標記后的離散屬性進行正交變換,增強屬性之間的相互獨立性,去除屬性之間的線性關系,從而貼近了樸素貝葉斯算法的屬性條件獨立性假設。
為了保留NB 算法的簡單性,人們對樸素貝葉斯算法進行了微調,微調是指在第一階段建立標準的NB模型,在微調階段將每個訓練實例都進行分類,然后判斷對訓練實例的分類結果正確與否,再根據判斷結果對原樸素貝葉斯算法進行微調。Diab & Hindi 將樸素貝葉斯算法中的概率估計問題轉化為一個優化問題[33],并融合了差分進化(differential evolution,DE)、遺傳算法(genetic algorithms,GA)和模擬退火(simulated annealing,SA)三種算法,從中獲得啟發。實驗結果表明,該方法在不同的領域得到了廣泛的應用,特別是在樣本的基本分布不能通過訓練樣本充分體現時,該方法表現出了一定的優越性。Hindi等人[34]提出了一個用于文本分類的微調樸素貝葉斯(fine-tuning NB,FTNB)的分類符集成。他們修改了FTNB中的更新方程,使該方法產生不同的分類器。然后建立了一個FTNB集成分類器,以期望顯著提高分類的準確性。實驗表明,該算法在16 個基準文本分類數據集中的分類性能有明顯提升。Zhang等人[35]提出了一種微調屬性加權樸素貝葉斯(fine tuning attribute weighted NB,FTAWNB),是在對樸素貝葉斯算法進行屬性加權改進的基礎上進行了微調,它減少了樸素貝葉斯算法對測試樣本的分類時間,并提高了算法的精度。
上述的屬性和屬性值加權方法是針對離散屬性或連續屬性離散化之后的屬性值進行加權[32],這會導致連續屬性的內在信息丟失。因此,本文將離散屬性和連續屬性進行區分,只給離散屬性和離散屬性值賦予權重,而對于連續屬性使用正交變換的方法消除連續屬性之間的線性關系。這樣一來既保留了離散和連續屬性的內在信息,還量化了離散屬性和離散屬性值之間的相互關系以及對其所屬樣本分類的貢獻程度。
1 樸素貝葉斯分類算法的改進
針對多維混合屬性樣本,一般的樸素貝葉斯改進算法是先將連續屬性離散化[32]或離散屬性連續化[22]之后再對算法進行訓練。本文首先對離散屬性進行加權,對連續屬性進行正交變換,然后對兩者的條件概率分別計算,最后將計算結果進行融合,從而得到多類屬性加權與正交變換融合的樸素貝葉斯(Naive Bayes fusion of multiple attribute weighting and orthogonal transformation,MAWOTFNB)算法,以此來保留離散和連續屬性的內在信息,削弱屬性條件獨立性假設給NB算法造成的影響。
1.1 改進算法的框架
本文提出的MAWOTFNB 算法一方面將多類離散屬性和離散屬性值權重加入到離散屬性“頻率計數估計”的條件概率計算中,然后對正交變換后的連續屬性使用“概率密度函數”的條件概率計算方式進行計算。另一方面,將兩種不同的條件概率計算方式進行融合并加入類屬性權重,得到多維混合屬性的后驗概率計算公式。因此,MAWOTFNB算法可以對樣本中離散屬性和連續屬性的條件概率進行區分計算,并繼承了離散屬性和離散屬性值加權方法、正交變換方法的優點,從而保留了離散屬性與連續屬性的內在信息。MAWOTFNB算法使用式(1)對測試樣本的類別進行預測。
其中,xi為測試數據集中的第i個測試樣本,C?(xi)是測試樣本xi的類別預測函數,C是類集合,cd為類集合C中的第d個類,Dd為類cd中的離散屬性標識,Sd為類cd中的連續屬性標識。W為權重集合,且W={Wjkd,Wj,aj,Wjk},集合中Wjkd為類cd中第j個離散屬性的取值為aj關于第k個離散屬性取值為ak的聯合離散屬性值權重,Wj,aj為離散屬性值aj的權重,Wjk為樣本中第j個離散屬性與第k個離散屬性的聯合離散屬性權重。xiD為離散屬性向量,xiS為連續屬性向量。權重集合W中的各權重、P?Dd(xiD|cd)和P?Sd(xiS|cd)的定義見1.2節和1.3節,先驗概率P?(cd)由式(2)表示:
其中,Nd為訓練數據集的類cd中的樣本數量,N為訓練數據集中樣本的數量,D為訓練數據集中類的數量,Wd為類cd的權重,其定義見1.2節。圖1為MAWOTFNB算法框架。

圖1 MAWOTFNB算法框架Fig.1 MAWOTFNB algorithmic framework
1.2 離散屬性加權
1.2.1 類特定的聯合離散屬性值加權
文獻[36]中的樸素貝葉斯條件概率計算公式是將待測樣本不同屬性的取值對此樣本屬于某個類別的支持度平等對待的,即每個離散屬性值的權重都默認為1,這樣一來在很大程度上限制了樸素貝葉斯分類器的分類精度。針對上述問題,本文通過式(3)構造類特定的聯合離散屬性值權重Wjkd:
其中,njd和nkd分別是類cd中第j個離散屬性和第k個離散屬性的取值數量,且1 ≤j≤nD,1 ≤k≤nD,nD是樣本離散屬性的數量,Count(aj,ak,cd)代表類cd中第j個離散屬性和第k個離散屬性取值為aj和ak的樣本數量,Count(ak,cd)代表類cd中第k個離散屬性取值為ak的樣本數量,Wjkd表示在類cd中第j個離散屬性取值為aj關于第k個離散屬性取值為ak的聯合離散屬性值權重。Wjkd的取值是由Count(aj,ak,cd)、Count(ak,cd)、njd以及nkd共同決定的,且在訓練數據集固定情況下,其取值確定后不會再改變。若njd=nkd,Count(ak,cd)=Count(aj,cd),Count(aj,ak,cd)=Count(ak,aj,cd),則Wjkd=Wkjd。Wjkd越大表示類cd中第j個離散屬性的取值aj和第k個離散屬性的取值ak所在樣本屬于此類別的支持度越大。
為了進一步說明離散屬性值與類之間、離散屬性值之間的相關程度,本文使用基于相關互信息的方法來對其相關性進行衡量。將單個離散屬性值的權重由離散屬性值與類之間以及離散屬性值之間相關性的乘積得到,具體計算步驟如下。
步驟1 離散屬性值與類標簽c的相關性、離散屬性值aj和ak的相關性使用相關互信息進行度量,分別由式(4)和式(5)給出:式(4)中的I(aj,c)是離散屬性值aj與類標簽c之間的相關互信息,P(aj,cd)是離散屬性值aj與類屬性值cd的聯合概率,P(aj)和P(cd)分別為離散屬性值aj和類屬性值cd的先驗概率。式(5)中的I(aj,ak)是離散屬性值aj和ak之間的相關互信息,P(aj,ak)是離散屬性值aj和ak的聯合概率,P(aj)和P(ak)分別為離散屬性值aj和ak的先驗概率。
步驟2 使用式(6)和式(7)分別對I(aj,c)和I(aj,ak)進行歸一化。
其中,nD是離散屬性的數量,R(aj,c)和R(aj,ak)分別是歸一化之后的離散屬性值與類之間、離散屬性值之間的相關互信息,可以將其用于計算單個離散屬性值的權重。
步驟3 單個離散屬性值權重由式(8)定義:
其中,Wj,aj為離散屬性值aj的權重,它用來量化離散屬性值aj對樣本分類的貢獻程度,且在訓練數據集固定情況下,其取值確定后不會再改變。
1.2.2 聯合離散屬性加權
樣本中的每一個屬性對樣本的重要程度是不同的,但是在文獻[36]的樸素貝葉斯判定準則中是將每個屬性對樣本分類的貢獻程度都默認為1,這在現實應用中是不可行的。因此,本文采用基于條件互信息的離散屬性加權方法為每個離散屬性分配不同的權重,以進一步提高分類器的性能。離散屬性Aj與Ak的條件互信息由式(9)定義:其中,nD是離散屬性的數量,D為訓練數據集中類別的數量,I(Aj,Ak|c)是在已知類標簽c的情況下觀察Ak的取值帶來關于Aj的信息量,P(aj,ak,cd)為離散屬性值aj和ak與類屬性值cd的聯合概率,P(aj,ak|cd)為離散屬性值aj和ak關于類cd的聯合條件概率,P(aj|cd)和P(ak|cd)分別為離散屬性值aj和ak關于類cd的條件概率。
由離散屬性Aj與Ak的條件互信息獲取聯合離散屬性權重由式(10)定義:
其中,Wjk為樣本第j個與第k個離散屬性的聯合離散屬性權重,且在訓練數據集固定情況下,其取值確定后不會再改變。
1.2.3 類屬性值加權
分類器是給定一個輸入(測試樣本),判斷此輸入所屬的類別信息。而在分類器訓練過程中由于訓練數據集中每個類別之間的樣本數量存在差異,則訓練出來的分類器算法對測試樣本的類別預測結果更傾向于訓練樣本數量比較多的類。由于訓練數據集中可能存在某一類中的樣本數量很少,而某一類中的樣本數量較多的情況,這些不平衡的數據集會導致測試樣本的條件概率和后驗概率的計算結果受到極大的影響[37],從而影響分類器的性能。針對上述問題,本文使用類屬性值權重來降低類中樣本稀疏性對分類器性能造成的負面影響。其定義如式(11)所示:
其中,Wd為類cd的權重,在訓練數據集固定情況下,其取值確定后不會再改變。N為訓練數據集中樣本的數量,D為訓練數據集中類別的數量,Nd為訓練數據集的類cd中的樣本數量。
結合上述加權方法并假設離散屬性向量為xiD=(a1,a2,…,anD),則基于離散屬性加權的條件概率計算由式(12)定義:
式(13)中,P(aj|cd)是離散屬性值aj關于類cd的條件概率,|Daj,cd|是類cd中離散屬性值為aj的樣本數量,njd是類cd中第j個屬性的取值數量,Nd為訓練數據集的類cd中的樣本數量。式(14)中,P(ak|aj,cd)是離散屬性值ak關于離散屬性值aj和類cd的聯合條件概率,|Daj,ak,cd|是訓練數據集的類cd中第j個屬性與第k個屬性分別取值為aj與ak的樣本數量,nkd為訓練數據集的類cd中第k個屬性的取值數量。
1.3 連續屬性正交變換
基于連續屬性正交變換的樸素貝葉斯算法利用正交變換的方法,結合樸素貝葉斯的屬性條件獨立性假設將屬性之間的線性關系進行了消除,并且削弱了樸素貝葉斯分類器的屬性條件獨立性假設所帶來的影響。因為在某些數據集中樣本會存在既有離散屬性又有連續屬性的情況,本文為了保留離散和連續屬性的內在信息,對樣本中的離散屬性與連續屬性的條件概率進行區分計算。因此,本文對樣本中的連續屬性使用正交變換的方法,來去除連續屬性之間的線性關系。針對連續屬性的正交變換、概率密度函數的計算步驟如下。
步驟1 設有樣本集為XS={x1S,x2S,…,xNS},每一個樣本中的連續屬性由xiS=(anD+1,anD+2,…,an)確定,訓練數據集中每個連續屬性在類cd中的樣本均值μj,d使用式(15)計算:
其中,Nd為訓練數據集的類cd中樣本的數量,aij為第i個樣本的第j個連續屬性的值,且nD 步驟2 由步驟1 得到的每個類中連續屬性的樣本均值向量,通過式(16)求協方差矩陣。 步驟3 計算步驟2得到的類cd中連續屬性的協方差矩陣Md的特征值與特征向量。在Md的特征值存在重根的情況下,通常是先將特征向量施密特正交化,然后單位化,即可獲得相似對角化所需的可逆正交矩陣P;如果沒有出現重根的情況,就只需對特征向量進行單位變換,然后獲得可逆正交矩陣P,并使得PTMd P=Λ。 步驟4 令yiS=PT(xiS-μd),i=1,2,…,Nd,并計算類cd中對連續屬性樣本xiS正交變換后的y樣本集{y1S,y2S,…,yNdS}中的樣本均值向量和方差向量 步驟5 假設正交變換后的連續屬性的概率密度函數服從正態分布,即,其中y?j表示樣本yiS的第j個屬性,和分別是類cd中的樣本正交變換之后在第j個屬性上的樣本均值和方差,則其概率密度函數由式(17)計算: 由于正交變換之后的連續屬性消除了線性關系,滿足連續屬性之間相互獨立的假設,則連續屬性的概率密度函數由式(18)計算: 將上述基于離散和連續屬性的條件概率計算方式進行融合,得到本文所改進的樸素貝葉斯算法由式(1)表示,詳細的訓練和分類過程分別使用算法1 和算法2描述。 算法1 MAWOTFNB-Training 輸入:訓練數據集。 (1)計算離散屬性值aj和ak在類cd中共現的樣本數量Count(aj,ak,cd)和離散屬性值ak在類cd中出現的樣本數量Count(ak,cd),統計類cd中第j個屬性和第k個屬性的取值數量njd和nkd,其中1 ≤j≤nD,1 ≤k≤nD。 (2)由式(3)計算聯合離散屬性值權重Wjkd。 (3)由式(4)和式(5)計算各離散屬性值的I(aj,c) 和I(aj,ak)。 (4)由式(6)和式(7)對各離散屬性值的I(aj,c)和I(aj,ak)進行歸一化得到R(aj,c)和R(aj,ak)。 (5)由式(8)計算各單個離散屬性值權重Wj,aj。 (6)由式(9)計算各離散屬性的I(Aj,Ak|c)。 (7)由式(10)計算聯合離散屬性權重Wjk。 (8)將Wjkd、Wj,aj、Wjk組成集合W={Wjkd,Wj,aj,Wjk}。 (9)由式(11)計算類cd的權重Wd。 (10)將權重Wd代入式(2)計算先驗概率 (11)計算訓練數據集類cd中連續屬性的樣本均值向量μd及正交矩陣P。 (12)對訓練數據集類cd中每一個樣本的連續屬性進行正交變換得到y={y1S,y2S,…,yNdS}。 算法2 MAWOTFNB-Classification 輸入:W、P?(cd)、μd、P、y、單個待分類樣本xi。 輸出:待分類樣本xi的類別預測結果 (1)取出待分類樣本xi的連續屬性向量xiS,利用式yiS=PT(xiS-μd)對xiS進行正交變換,并將yiS放到y樣本集中。 (2)計算y樣本集的樣本均值向量μ′d與方差向量σ′d。 (3)由式(18)計算關于類cd的連續屬性正交變換之后的概率密度函數 (4)將權重集合W以及待分類樣本xi的離散屬性向量xiD代入式(12)計算離散屬性條件概率 (5)將待分類樣本xi的連續屬性正交變換結果yiS從y樣本集中移除。 (7)預測待分類樣本xi的類別 在現實生活中的數據采集過程中會遇到許多未知的問題,這樣會導致采集到的數據存在一定的錯誤,包括數據缺失、噪聲數據等。數據缺失的類型有很多種,比如缺失數量的差異、缺失變量的差異等。為了便于數據的預處理,現在一般是從缺失值數量和結構上進行區分,根據包含缺失值變量的個數,可分別將其分為單個變量和多個變量的缺失[38],如表1 所示。單個變量缺失表示要分析的數據集樣本中只有一個缺失屬性值,而多個變量的缺失表示要分析的數據集樣本中存在兩個或兩個以上的屬性有缺失值[38]。表1 中的xi表示第i個樣本,A1、A2、A3分別表示樣本中第1、第2、第3 個屬性,“1”表示含有屬性值,“0”表示缺失屬性值。 表1 單變量缺失與多變量缺失的表示Table 1 Univariate deletion and multivariable deletion 數據預處理的方法有很多,主要包含將含有缺失屬性值的樣本進行刪除、對樣本中缺失的屬性值進行補充、將錯誤數據或未知數據擱置這三種方法來處理存在問題的數據[38]。若訓練數據集中某個樣本的某個或多個屬性存在缺失值就直接刪除的話,很有可能會丟失重要的分類信息。如果對這些缺失數據進行擱置,會對分類器的類別預測準確率造成很大的負面影響[38]。本文使用的數據集包括9 個“UCI 機器學習數據集”和1 個“Poor Students(實測)”的貧困生數據集。其中,Poor Students(實測)數據集來源于我校校園一卡通的整理數據。對數據集中的缺失數據均采用統計學的眾數原理[39]進行插值,即對類中的某個樣本的某個屬性缺失值使用在該類中其他所有樣本在該屬性上出現次數最多的屬性值進行補充。 為了驗證本文所提出的多類屬性加權與正交變換融合的樸素貝葉斯(MAWOTFNB)算法的有效性和適用性,本文使用9 個“UCI 機器學習數據集”和1 個“Poor Students(實測)”的貧困生數據集,利用“分層k折交叉驗證”的驗證方式[40]對NB、OTNB、FTAWNB、NB-LR、HNB-LR、A2WNB、MAWNB以及MAWOTFNB算法進行對比。其中NB 為基礎分類算法;OTNB 代表了使用屬性變換方法改進的算法;FTAWNB 代表了使用微調和屬性加權方法改進的算法;NB-LR 和HNBLR 代表了使用結構擴展方法改進的算法;A2WNB 和MAWNB代表了使用雙階段屬性加權方法改進的算法。 本文所使用的“分層k折交叉驗證”的驗證步驟如下。 步驟1 隨機使用不同的劃分折重復pk次,且pk=k,每次將數據集劃分為k個大小相似且類間樣本數量比例保持劃分前的互斥子集。 步驟2 依次將每次劃分的k-1 個子集的并集作為訓練集,剩余的子集作為測試集對算法進行驗證。 步驟3 記錄每次劃分中的平均分類準確率。 步驟4 獲取pk次劃分中平均準確率最高的一次,將此次分折作為“分層k折交叉驗證”中k的取值。 上述步驟3 中的“準確率”表示類別預測正確的樣本數占測試樣本總數的比例。“分層k折交叉驗證”原理如圖2所示。 圖2 分層k 折交叉驗證原理圖Fig.2 Schematic diagram of layered k-fold crossed verification 本文所使用數據集的具體描述如表2所示。 為了準確評估本文改進的樸素貝葉斯算法在分類任務中的表現,本文選擇由“分層k折交叉驗證”所得到的準確率和加權平均F1 值,即Fwa作為算法的性能評價指標,其計算公式分別由式(19)和式(20)表示。 其中,accuracy是各算法的分類準確率,m是測試樣本的總數,pk是“分層k折交叉驗證”中第k折驗證重復的次數,m1k,m2k,…,mpkk是每次k折驗證時類別預測正確的測試樣本數量。 其中,L是測試樣本集的類別預測結果中的類別個數,counti為第i個類的樣本數量,Fi是將樣本類別進行正負化之后,第i個類為正類,其他類為負類時的F1值,由式(21)定義: 其中,Precisioni和Recalli分別為測試樣本被分到第i個類的查準率和召回率,Precisioni和Recalli由式(22)和式(23)表示: 式(22)中的TPi是正確分類到第i個類的樣本數量,FPi是把其他類的樣本分到第i個類的樣本數量。式(23)中的FNi是把第i類的樣本分到其他類的樣本數量。 本文算法與其他分類算法的時間復雜度對比如表3所示。表3 列出了各算法的訓練時間復雜度和預測時間復雜度,其中,m表示訓練數據集中類別的個數;n表示屬性的個數;t表示訓練數據集中的樣本個數,v表示屬性值的平均數量;f表示FTAWNB 算法在第二階段訓練的循環次數;nD表示離散屬性的個數;nS表示連續屬性的個數。由表3可知,由于本文的MAWOTFNB算法在訓練階段首先將數據集中的離散屬性和連續屬性進行了區分,然后利用貢獻度與相關互信息的方法量化了離散屬性和離散屬性值的權重,此過程的時間復雜度為;接著本文又利用正交變換方法對連續屬性進行了正交變換,此過程的時間復雜度為O(tnS) ;因此,MAWOTFNB 算法的時間復雜度為各算法在各數據集上的訓練時間如表4所示,訓練時間對比圖如圖3所示,表4中的加粗字體為算法在當前數據集上訓練時,耗時最多的算法訓練所用的時間。 表3 各算法時間復雜度Table 3 Time complexity of each algorithm 表4 各算法在各數據集上的訓練時間Table 4 Training time of each algorithm on each dataset單位:s 圖3 各算法在各數據集上的訓練時間對比Fig.3 Comparison of training time of each algorithm on each dataset 由表4 和圖3 可知,NB-LR、HNB-LR、A2WNB 和MAWNB 算法在Adult 和Mushroom 數據集上的訓練時間存在激增,而本文的MAWOTFNB 算法僅在Adult 數據集上的訓練時間微有增加。由表2 可知,Adult 和Mushroom數據集相較于表中其他數據集中的樣本數和屬性數較多,特別是Adult 數據集中的樣本數量達到了48 842個,屬性個數達到了14個。因此,NB-LR、HNB-LR、A2WNB 和MAWNB 算法易受訓練數據集中的樣本個數和屬性個數的影響,而本文的MAWOTFNB算法僅在訓練數據集中的樣本個數較多時,訓練所耗時間才稍有增加。MAWOTFNB 算法在各數據集上的平均訓練時間,比NB算法僅高0.015 s,比OTNB算法減少了0.016 s,和FTAWNB算法相等,比NB-LR算法減少了0.512 s,比HNB-LR減少了0.485 s,比A2WNB算法減少了0.109 s,比MAWNB算法減少了0.133 s。 本文在9 個“UCI 機器學習數據集”和1 個“Poor Students(實測)”的貧困生數據集上對比了NB、OTNB、FTAWNB、NB-LR、HNB-LR、A2WNB、MAWNB 和MAWOTFNB算法的性能評價指標。表5列出了本文改進的樸素貝葉斯算法與其他比較對象在每個數據集上的分類準確率。表6 展示了實驗獲得各算法在各數據集上的Fwa值。表5和表6中加粗的數字為該數據集上獲得的最高分類準確率和Fwa值,本文將每個算法在10個數據集上的平均分類準確率和平均Fwa 值匯總在了表格底部。 表5 各算法在各數據集上的分類準確率Table 5 Classification accuracy of each algorithm on each dataset單位:% 表6 各算法在各數據集上的Fwa 值Table 6 Fwa values of each algorithm on each dataset單位:% 為了分析各分類算法在各數據集中的分類效果,使用簇狀柱形圖對比各算法的分類準確率、Fwa 值,分別如圖4、圖5所示。分析結論如下: 圖4 各算法在各數據集上的分類準確率對比Fig.4 Comparison of classification accuracy of each algorithm on each dataset 圖5 各算法在各數據集上的加權平均F1對比Fig.5 Comparison of weighted average F1 values of each algorithm on each dataset (1)OTNB算法忽略了離散屬性取值先后順序的不確定性,直接對其進行連續化操作,導致離散屬性原有信息丟失。從表5 和表6 中可知,此算法的平均分類準確率和平均Fwa 值都是最低的,在實驗數據集上的平均分類準確率僅有73.79%,平均Fwa 值僅有74.31%,其可視化對比圖見圖4和圖5的最后一簇。 (2)相比于OTNB,FTAWNB 算法結合了微調和屬性加權的方法。由表5 和表6 可知,其平均分類準確率達到了82.81%,比OTNB 算法高了9.02 個百分點;平均Fwa 值達到了80.58%,比OTNB 算法高了6.27 個百分點,其可視化對比圖見圖4和圖5的最后一簇。 (3)相比于FTAWNB,NB-LR 和HNB-LR 算法使用結構擴展的方法來構建混合分類算法。由表5和表6可知,NB-LR 算法的平均分類準確率達到了83.29%,比FTAWNB 算法高了0.48 個百分點,平均Fwa 值達到了82.78%,比FTAWNB 算法高了2.2 個百分點;HNB-LR算法的平均分類準確率達到了82.92%,比FTAWNB 算法高了0.11 個百分點,平均Fwa 值達到了82.88%,比FTAWNB 算法高了2.3 個百分點,其可視化對比圖見圖4和圖5的最后一簇。 (4)相比于NB-LR 和HNB-LR,A2WNB 算法利用雙階段的屬性加權改進算法來獲得增強屬性。由表5和表6可知,其平均分類準確率達到了85.34%,比NB-LR算法高了2.05個百分點,比HNB-LR算法高了2.42個百分點;平均Fwa值達到了85.14%,比NB-LR 算法高了2.36 個百分點,比HNB-LR 算法高了2.26 個百分點,其可視化對比圖見圖4和圖5的最后一簇。 (5)與A2WNB 類似,MAWNB 算法是使用雙階段屬性加權算法來構建兩個標簽視圖,從而改進NB 算法。由表5和表6可知,其平均分類準確率達到了85.56%,比A2WNB算法高了0.22個百分點;平均Fwa值達到了85.82%,比A2WNB 算法高了0.68 個百分點,其可視化對比圖見圖4和圖5的最后一簇。 (6)不同于前面所述的OTNB、FTAWNB、NB-LR、HNB-LR、A2WNB 以及MAWNB 算法,本文所提出的MAWOTFNB 算法在數據集上的平均分類準確率達到了92.75%,在同等條件下,不僅比NB高11.93個百分點,比OTNB高18.96個百分點,還比目前最新的FTAWNB、NB-LR、HNB-LR、A2WNB 以及MAWNB 算法分別高9.94 個百分點、9.64 個百分點、9.83 個百分點、7.41 個百分點、7.19個百分點,且其平均Fwa值達到了92.22%,同樣高于上述分類算法。這說明了本文算法將離散和連續屬性進行區分處理,更加有利于對多維混合屬性數據集的分類任務,其可視化對比圖見圖4和圖5的最后一簇。 為了進一步闡述各分類算法在各數據集上的分類優勢,表7展示了各算法在各數據集上所獲得準確率的WDL,其中W、D、L 分別為各算法分類準確率兩兩比較中獲勝數據集的數量、持平數據集的數量和落后數據集的數量。圖6 為各算法WDL 值對比的三維柱形圖可視化。 表7 各算法的WDL值Table 7 WDL value of each algorithm 圖6 各算法的WDL值對比Fig.6 WDL value comparison of each algorithm 由表7 可知,本文的MAWOTFNB 算法在實驗中相較于NB、OTNB、A2WNB、MAWNB算法的W值均為最高;相較于FTAWNB 算法在7 個數據集上獲勝,1 個數據集上持平;相較于NB-LR 算法在7 個數據集上獲勝;相較于HNB-LR 算法在8 個數據集上獲勝。其可視化對比圖如圖6所示。 為了描述各權重參數對MAWOTFNB 算法分類性能的影響,本節對MAWOTFNB 算法的四個重要參數:類屬性值權重Wd,類特定的聯合離散屬性值權重Wjkd,單個離散屬性值權重Wj,aj以及聯合離散屬性權重Wjk展開研究。分別將這四個參數從MAWOTFNB 算法中刪除來觀察各部分權重在各數據集上對MAWOTFNB算法分類性能的影響。對應算法描述如下: 去除類屬性值權重的MAWOTFNB算法,將該算法描述為A1; 去除類特定的聯合離散屬性值權重的MAWOTFNB算法,將該算法描述為A2; 去除單個離散屬性值權重的MAWOTFNB算法,將該算法描述為A3; 去除聯合離散屬性權重的MAWOTFNB算法,將該算法描述為A4; 將四個權重參數全部去除的MAWOTFNB算法,將該算法描述為A5。 表8列出了各參數對比算法在每個數據集上的分類準確率。表9 展示了實驗獲得各參數對比算法在各數據集上的Fwa值。表8和表9中加粗的數字為該數據集上獲得的最高分類準確率和Fwa值,本文將每個參數對比算法在10 個數據集上的平均分類準確率和平均Fwa值匯總在了表格底部。 表8 各參數對比算法在各數據集上的分類準確率Table 8 Classification accuracy of parameter comparison algorithms on each dataset 單位:% 表9 各參數對比算法在各數據集上的Fwa 值Table 9 Fwa values of parameter comparison algorithms on each dataset單位:% 為了分析各參數對比算法在各數據集中的分類效果,使用簇狀柱形圖可視化各參數對比算法的分類準確率、Fwa值,分別如圖7、圖8所示。分析結論如下: 圖7 各參數對比算法在各數據集上的分類準確率對比Fig.7 Comparison of classification accuracy of parameter comparison algorithms on each dataset 圖9 各參數對比算法的WDL值對比Fig.9 WDL value comparison of parameter comparison algorithms (1)算法A1是將類屬性值權重去除的MAWOTFNB算法,該算法在訓練時易受不平衡類的影響。由表8和表9 可知,其平均分類準確率和平均Fwa值相對于MAWOTFNB 算法分別低了9.92 個百分點和9.79 個百分點。因此,在算法訓練時考慮訓練數據集中類的平衡性是必要的。 (2)算法A2 是將類特定的聯合離散屬性值權重去除的MAWOTFNB算法,該算法在訓練時沒有對不同類中不同屬性值之間的相關性進行衡量。由表8和表9可知,其平均分類準確率和平均Fwa值相對于MAWOTFNB算法分別低了9.28 個百分點和10.25 個百分點。因此,在算法訓練時衡量不同類中的不同屬性值之間的相關性可以大幅度提高算法的分類性能。 (3)算法A3 是將單個離散屬性值權重去除的MAWOTFNB算法,該算法在訓練時忽略了單個離散屬性值對其所在樣本所屬類別的貢獻程度。由表8和表9可知,其平均分類準確率和平均Fwa值相對于MAWOTFNB算法分別低了10.37 個百分點和9.66 個百分點。因此,在算法訓練時考慮單個離散屬性值對其所在樣本所屬類別的貢獻程度可以有效地提高算法的分類性能。 (4)算法A4是將聯合離散屬性權重去除的MAWOTFNB算法,該算法在訓練時將訓練數據集中離散屬性之間的相關程度默認為1。由表8 和表9 可知,其平均分類準確率和平均Fwa值相對于MAWOTFNB 算法分別低了9.86 個百分點和10.71 個百分點。因此,準確地衡量離散屬性之間的相關程度可以有效提高算法的分類性能。 (5)算法A5 是將所有權重去除的MAWOTFNB 算法,該算法在訓練時,針對離散屬相互獨立的假設,而針對連續屬性則使用正交變換的方法來獲取待分類樣本的類條件概率。由表8 和表9 可知,其平均分類準確率和平均Fwa值相對于MAWOTFNB算法分別低了8.17個百分點和7.77個百分點。因此,使用多類屬性加權和正交變換融合的方法來改進NB 算法,可以有效提高其分類性能。 為了進一步說明離散屬性和離散屬性值權重的重要性,本文對各參數對比算法在各數據集上的分類表現進行了對比,表10 展示了各參數對比算法在各數據集上所獲得準確率的WDL。 表10 各參數對比算法的WDL值Table 10 WDL value of parameter comparison algorithms 由表10 可知,本文的MAWOTFNB 算法與其他去除權重參數的MAWOTFNB 算法相比,其W 值均為最高;相較于算法A1、A2、A5均在9個數據集上獲勝,1個數據集上持平;相較于算法A3 和A4 在10 個數據集上均獲勝。這充分證明了本文使用多類屬性加權和正交變換方法改進NB 算法的有效性。其可視化對比圖如 目前大多數削弱樸素貝葉斯算法的屬性條件獨立性假設的改進方法中,針對多維混合屬性大多是將離散屬性連續化或者連續屬性離散化之后再進行下一步的改進。不同于已有的改進方法,本文提出了一種多類屬性加權與正交變換融合的樸素貝葉斯改進算法,該算法首先對類屬性值、離散屬性和離散屬性值進行加權,然后將加權后的離散屬性及離散屬性值加入到其條件概率計算公式中,最后融合基于連續屬性正交變換改進的樸素貝葉斯算法,對后驗概率進行計算,減小了不平衡數據集以及屬性條件獨立性假設對分類精度造成的負面影響。實驗結果表明,該算法在處理多維混合屬性的分類任務時可保留離散屬性和連續屬性內在信息,提高樸素貝葉斯算法的分類性能。此外,該算法在“Poor Students(實測)”數據集上的分類性能明顯優于另外7種分類算法,這可以為各高校的貧困生判定工作提供決策參考。1.4 多類屬性加權與正交變換的融合
2 實驗與對比
2.1 缺失屬性預處理

2.2 實驗方法與數據

2.3 性能評價指標
2.4 算法時間復雜度分析



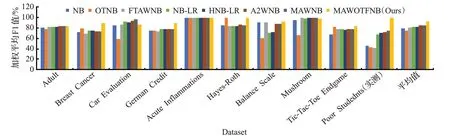
2.5 實驗結果與分析





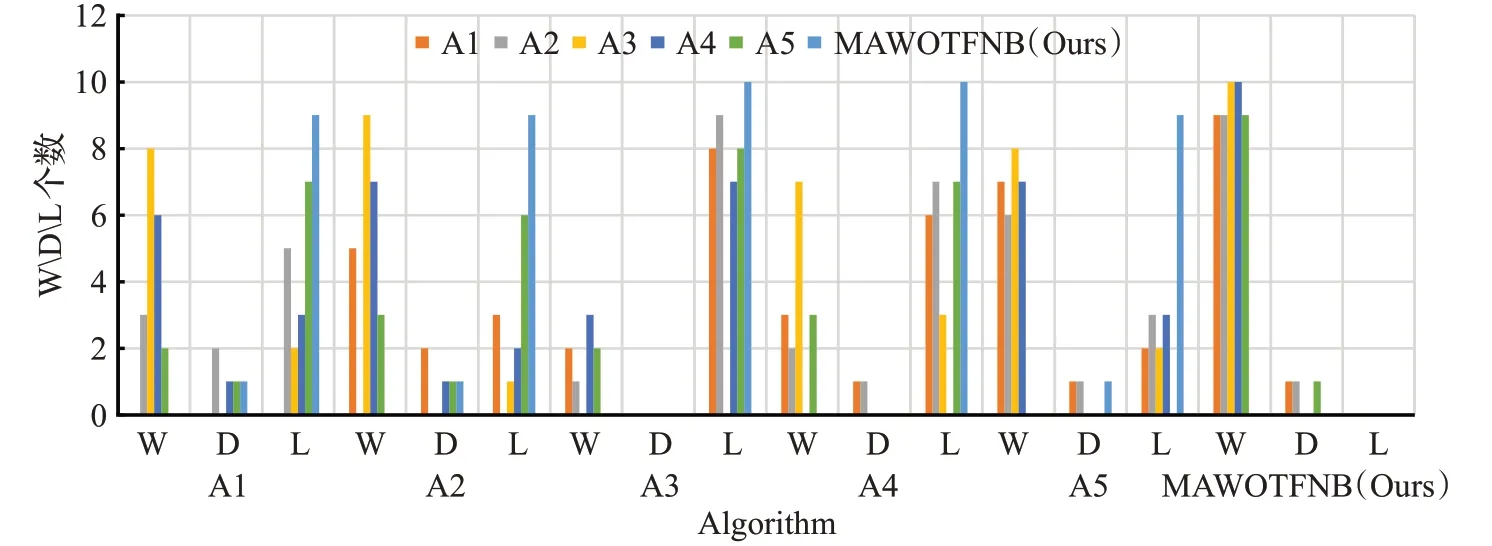
2.6 權重參數的影響




3 結束語
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
