多標簽文本分類研究回顧與展望
2023-09-25 08:54:46張文峰奚雪峰崔志明鄒逸晨欒進權
計算機工程與應用 2023年18期
張文峰,奚雪峰,3,崔志明,3,鄒逸晨,欒進權
1.蘇州科技大學電子與信息工程學院,江蘇蘇州215000
2.蘇州市虛擬現實智能交互及應用技術重點實驗室,江蘇蘇州215000
3.蘇州智慧城市研究院,江蘇蘇州215000
文本分類是將文本內容劃分為一個或多個類別的過程,是NLP中的一個基礎任務。在現實世界中,由于文本數據環境復雜多變以及多義對象的存在,文本分類面臨諸多嚴峻挑戰。傳統的單標簽文本分類方法并不能完全滿足用戶的需求,多標簽學習方法應運而生[1]。多標簽學習是指從標簽集中將最相關的類標簽分配給每個文本的過程,從而直觀地反映模糊對象的各種語義信息內容。例如,一篇關于2019冠狀病毒病(“COVID-19”)的新聞報道會屬于“醫療衛生”類別和“經濟危機”或“國家安全”類別等多個類別。
多標簽文本分類問題是多標簽學習的重要研究方向,主要應用于情感分析[2]、主題標注[3]、問答[4]和對話行為分類[5]。其文本數據具有以下特點:一個文本可屬于多個標簽,因此需要捕獲語義特征的不同層次和方面;文檔較長時,語義信息會隱藏在冗余的內容中;大多數文本只屬于少量標簽[6];文本數據不平衡、標簽丟失以及標簽集過于龐大。基于上述問題,研究人員主要關注幾個方面:如何充分應用標簽的相關性;如何捕獲有效信息并提取相關的特征信息;以及如何減緩類別不平衡、標簽丟失、標簽壓縮的問題。
本文主要的主要貢獻歸納如下:
(1)對多標簽文本分類概念和流程進行闡述。
(2)對近年多標簽文本分類方法進行回顧,梳理多標簽文本分類常用數據集和評估指標;以及對部分模型或方法分析其優勢和存在問題。
(3)對多標簽文本分類領域的研究方向進行整理回顧。
(4)對多標簽文本分類當前的難點和未來研究方向進行總結和展望。
1 多標簽文本分類
1.1 多標簽文本分類概念
給定一個d維輸入空間X=X1×X2×…×Xd和一個輸出q標簽的空間Y={λ1,λ2,…,λq},q>1。每個標簽 |λi|=2 的基數,一個多標簽示例可以定義為一對(x,Y),其中x=(x1,x2,…,xd)∈X,Y∈Y 被稱為標簽集。D={(xi,Yi)|1 ≤i≤m} 是由一組m個文本構成的多標簽數據集。
多標簽文本分類是構建一個預測模型h:X →2Y,該模型將為文本提供一組相關標簽。每個文本可能具有來自先前定義的標簽集的與它相關聯的幾個標簽。因此,對于每個x∈X,有一個標簽空間Y∈Y 的二分區(Y,Yˉ),Y=h(x)是相關標簽集合,Yˉ是不相關標簽集合。多標簽文本分類如圖1所示。
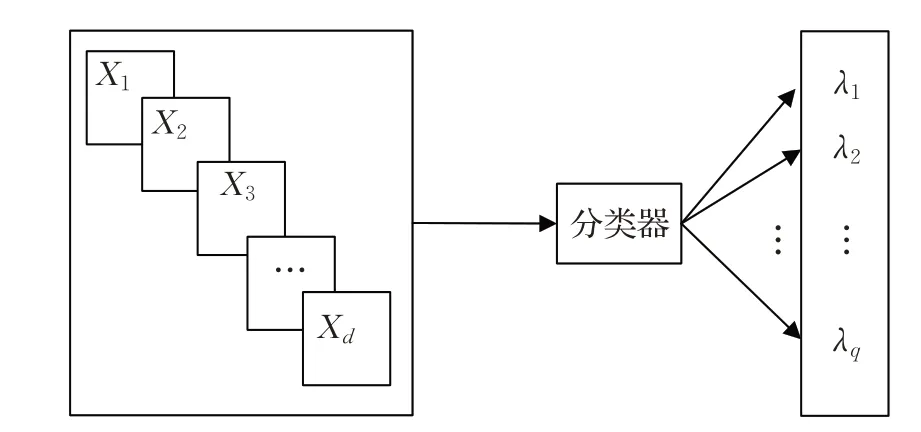
圖1 多標簽文本分類概念Fig.1 Multi-label text classification concept
1.2 多標簽文本分類流程
多標簽文本分類的流程如圖2所示。

圖2 多標簽文本分類流程Fig.2 Multi-label text classification process
(1)數據集
多標簽文本分類領域常用數據集在第3 章會有詳細介紹。
(2)文本預處理
文本預處理是指對原始數據集進行去除停止詞、分詞、詞性恢復等一系列操作,但目前對于上述處理已有非常成熟的技術。如果需要分詞,可以直接使用jieba、HanLP[7]等現成的工具,研究人員不需要在這項研究上花費太多精力。
(3)文本表示
文本表示是自然語言處理領域的基石。由于機器無法直接識別自然語言,因此將自然文本轉換為機器可以理解的表達式是文本表示的工作。文本表示的生成可以理解為按照一定的模型對文本數據進行編碼,其發展大致經歷了幾個階段,如One-hot、詞袋(bag of words,BOW)、語言模型(LM)、Word2Vec[8]、Glove[9]等。One-hot表示通過二進制編碼生成單詞向量,每個維度僅指示字典中對應的單詞是否在該位置取,該方法不僅會帶來維數災難,導致數據稀疏,還會造成文本語義的特征提取不足;BOW 在一元熱的基礎上用詞頻數據替代二進制數據,但仍未能解決維數災難和語義丟失的問題;LM模型使用條件概率來表達文本序列中單詞之間的關聯,但LM 模型的語義表示方法比較原始,因此已經發展到Word2Vec模型。Word2Vec模型由連續袋詞模型(CBOW)和Skip-Gram 模型組成。Word2Vec 模型使用類似于神經網絡的結構來建立詞之間關系的過程。近年來興起的文本表示方法專注于上下文的詞嵌入,如語言模型嵌入(ELMo),生成式預訓練(GPT)[10]方法和BERT[11]的用雙向編碼器進行文本表示。ELMo 首先通過語言模型學習每個單詞的單詞嵌入,對上下文動態調整嵌入,解決了一詞多義問題,同時實現語義關系判斷的功能。在特征提取方面,ELMo采用了LSTM,但后來提出了一種新的特征提取器Transformer,并且特征提取能力被證明優于LSTM。因此,基于Transformer作為特征處理提出了GPT。GPT模型通過語言模型預訓練,然后進行微調進行文本表示;但是,GPT是一種單向語言模型,只注意詞的上文,而不考慮詞的下文,所以它在語義理解上并不全面。為了同時考慮兩個詞序方向上的語義信息,提出了BERT針對大型數據集的訓練,從而可以學習更合理的詞表征,包括了上下文信息[12]。
(4)特征降維
向量化處理后文本特征較為稀疏,維度比較高。特征降維常用方式有TF-IDF[13]和互信息等。而在Transformer提出后,大多數都采用Transformer用作特征降維模塊。
(5)分類器和輸出類別
將特征降維后的數據送入分類器中進行模型訓練,然后用測試集對模型的輸出類別進行預測,用驗證集和評估指標來評判模型的優劣。
2 多標簽文本分類方法
多標簽文本分類方法主要可以分為:基于傳統機器學習和基于深度學習。傳統的機器學習方法根據解決策略角度可以劃分為問題轉換方法和算法自適應方法。問題轉換方法是將多標簽問題轉化為多個單標簽子問題,然后這些子問題直接利用成熟的單標簽算法來解決,所以問題轉換方法獨立于具體的算法,可以根據實際選擇合適的算法。算法自適應方法是將現有的單標簽算法進行拓展,使其能夠直接應用到多標簽數據上。多標簽文本分類方法詳細的分類如圖3所示。

圖3 多標簽文本分類方法Fig.3 Multi-label text classification method
2.1 問題轉換方法
目前,問題轉換算法主要基于以下三種方法:(1)二進制相關性(BR)轉換方法,(2)標簽冪集(LP)轉換方法,以及(3)成對方法(PW)。
2.1.1 BR轉換方法
BR 是最具代表性的問題轉換模型,它為每個標簽建立了二元分類模型,但基本的BR 模型[14]忽略了標簽相關性。為了利用BR 框架中標簽之間的這種相關性,常見的方法是將標簽作為額外的特征添加到原始特征中,然后構建相應的分類器,這些改進的BR模型可以分為兩種類型。第一種類型是構造兩層BR,第一層顯示了與原始BR相同的做法,在第二層中,第一層的輸出作為額外特征添加到原始特征中;然后,基于這些增強的特征,學習每個標簽的二進制分類器。第二層的輸出用作預測標簽,使用這種方式的BR 模型稱為基于堆疊的BR模型。第二種類型是將所有二進制分類器連接成一個鏈,鏈上的一個分類器將所有先前分類器的輸出作為額外的特征添加到原始特征中,這樣的框架稱為分類器鏈模型。下面詳細介紹了BR 模型、基于堆疊的BR 模型和分類器鏈模型。
(1)BR模型
2004 年,Boutell等人[14]首先提出了基本的BR模型。它將多標簽問題轉換為幾個二進制分類子問題,所有子問題共享相同的特征空間,但是標簽空間不同。盡管BR算法簡單,直觀且應用廣泛,但由于它忽略了標簽之間的關系,因此預測性能較差。
(2)基于堆疊的BR模型
Godbole 等人[15]將集成學習中的基于堆疊的學習策略引入到BR 算法中,考慮了標簽相關性。在訓練過程中,基于堆疊的BR模型建立了兩層BR模型:第一層是基礎層,與傳統BR學習過程相同,并為每個標簽分配相應的二進制分類模型。在元層次的第二層中,將基礎層次中所有二元分類模型的預測標簽添加到原始特征空間中,在這些擴展的特征上再次學習每個標簽,得到相應的二元分類模型。這種基于堆疊的BR算法假定任何標簽都與所有標簽相關,然而,這在大多數情況下是無效的。相關研究有算法BR+[16]和基于剪枝與堆疊的算法BR[17]。
(3)分類器鏈模型
Read等人[18]首次提出了分類器鏈(CC)模型。與BR算法不同,鏈中的標簽將所有先前標簽的二進制分類器輸出添加到原始特征空間中,作為新的特征進行訓練。CC 模型有兩個明顯的缺點:一是分類器的效果受標簽序列的影響很大,不同的序列帶來明顯不同的分類效果;另一個是當前標簽可能與序列的前一部分中的標簽無關,因此它可能通過使用所有先前標簽的輸出來引入噪聲。在同一文獻中,Read提出了CC的集成框架(ECC)。在ECC中,采用多個隨機標簽序列的CC模型的均值預測結果,可以在一定程度上解決隨機標簽序列對分類的影響,然而,這種計算費用成倍增加。Cheng 等人提出了概率分類器鏈(PCC)模型,并指出可以從標簽的條件聯合分布中獲得基于漢明或秩等損失函數的分類器鏈。除了改善基于概率推導的CC 算法的效果之外,還有一些其他方法可以找到最佳或更好的標簽序列。例如,GA-PratCC 通過使用遺傳算法搜索最佳標簽序列;OOCC從k近鄰中找到每個樣本的最佳標簽序列。
2.1.2 LR轉換方法
LP 變換方法[19]是將訓練集中所有標簽的組合視為一個類,然后將多標簽問題轉化為單標簽多類問題。從學習中獲得分類器后,看不見的實例是輸入,類是輸出,該類對應于一個標簽集,該標簽集涵蓋了實例所屬的所有標簽。
LP 變換方法只能預測出現在訓練集中的標簽集。此外,當有很多標簽時,可能會有很多標簽集。因此,許多集合可能具有一些相同的實例,從而導致類不平衡。這些問題不僅增加了學習的時間成本,而且降低了模型效果。為了解決這些問題,提出了兩個著名的算法RAkEL[19]和EPS[20]。
隨機k個標簽集(RAkEL)算法通過LP 變換方法訓練每個標簽集。RAkEL可以獲得比BR和LP更準確的性能。此外,RAkEL 還減少了必須學習的模型數量。在預測過程中,使用LP 方法獲得的所有學習者來預測看不見的實例,并對所有預測結果進行平均。因此,RAkEL是一種集成學習方法。
EPS算法計算與標簽集(Ri)相關的實例數(Count(Ri))。如果Count(Ri)高于指定的閾值,則將與Ri相關的所有實例添加到訓練集中。如果計數(Ri)低于閾值,則繼續對與Ri的子集相關的實例進行計數。如果子集的頻率高于指定閾值,則將與該子集相對應的樣本添加到與Ri相對應的訓練集中。這樣,LP方法就在Ri的相應訓練集上進行了訓練。同時,EPS還通過集成學習減少了過擬合問題。
2.1.3 PW轉換方法
2008 年,Hüllermeier 等人[21]提出了成對比較排序(RPC)算法,并將其應用于多標簽分類。該算法將包含q個標簽的多標簽問題轉換為q(q-1)/2 個二進制分類子問題,每個子問題對應一對標簽。標簽對(yi,yj)的子問題包含原始問題中與標簽yi或yj相關的所有實例,但同時與這兩個標簽相關的文本被排除在外。這樣,與標簽yi相關的實例是正例,而其余的則被視為負實例。因此,可以通過傳統的單標簽算法解決此子問題。
顯然,RPC算法的規模受標簽數量的影響很大。當標簽數量很大時,RPC 算法對于高復雜度是不切實際的。此外,RPC算法無法區分與測試一下實例相關的標簽。換句話說,它缺乏閾值或劃分點來區分標簽的哪一部分屬于實例。
Fürnkranz 等人[22]提出了校準標簽排名(CLR)算法來解決上述劃分點問題。在CLR 算法中,添加了校準標簽y0作為相關標簽和不相關標簽的邊界。與RPC算法相比,每個標簽yj只需添加一個子問題(yj,y0),其中數據涵蓋與標簽yj相關的所有實例(被視為與y0無關)和與標簽yj無關的實例(被視為與y0相關)。
2.2 算法自適應方法
算法自適應是對現有的單標簽算法進行拓展以輕松應用于多標簽文本數據。在本節中,介紹了幾種具有代表性和廣泛使用的算法自適應方法。
2.2.1 最近鄰
ML-kNN[23]是第一個使用最近鄰的多標簽算法。其基本思想是計算k個最近鄰中標簽的出現,然后計算每個標簽在不同出現時間下的概率,根據最大后驗原理給出預測結果。為了估計相應的概率,ML-kNN必須實現大量的計算和距離比較,時間復雜度相對較高。如果訓練集中存在噪聲,ML-kNN 算法的效果容易受到影響,并且ML-kNN不考慮標簽相關性。為了解決這個問題,LPLC[24]利用了最近鄰范圍內的一對標簽中的相關性。LPLC 與ML-kNN 的概率估計差異很小,關鍵差異在于LPLC 致力于為預測的標簽找到相關標簽集。LPLC 假設強相關性僅存在于與訓練實例相關的標簽之間,對于具有n個實例和q個標簽的訓練集,需要定義一個n×q矩陣M來記錄與每個實例相關的相關標簽。然后,基于M計算每個標簽的概率。
2.2.2 決策樹
Clare 等人[25]提出了一種基于決策樹的多標簽算法ML-C4.5。它從上到下構建決策樹,樹根包括所有訓練樣本。對于非葉節點中的實例,逐一調查每個特征,以找到合適的劃分點。此劃分點用于劃分此節點的實例,從而獲得最大的信息增益。
基于預測聚類樹(PCT)[26]實現了分層多標簽分類學習。與其他決策樹類似,PCT也根據最大程度地減少簇內方差的原則,從上到下將當前簇劃分為較小的簇。對于當前群集中的實例,方差度S定義為標簽向量(ci)與平均標簽向量(cˉ)之間的距離的平方和。
2.2.3 神經網絡
Bp-MLL[27]是第一個將傳統神經網絡轉換為多標簽分類的算法。它構造了一個簡單的三層網絡,輸入層有d個輸入單元,每個單元對應于訓練集的一個特征;隱藏層包含M個單元;輸出層具有q個單元,每個單元對應一個標簽。在Bp-MLL中,全局損失函數參與區分實例的相關標簽和不相關標簽,并指導學習系統輸出相對較大的相關標簽值以及相對較小的不相關標簽值。與傳統的直接比較輸出層各標簽預測值和實際值的損失評估方法相比,Bp-MLL 考慮了不同標簽之間的關系,取得了更好的效果。CA2E 是一種基于深度神經網絡(DNN)提出的多標簽分類算法。CA2E 算法的目標函數可以分為兩部分。第一部分是利用DNN模型求解目標函數,得到嵌入特征和標簽空間。第二部分旨在使整個模型的輸出恢復標簽空間,其中使用類似于Bp-MLL的方法來解決該問題。
2.2.4 支持向量機
Elisseeff提出Ranking-SVM算法[28]。首先,Ranking-SVM算法將高效率單標簽方法支持向量機(SVM)轉化為直接用于多標簽分類的方法。Ranking-SVM 首先為每個標簽定義線性分類器{hj(X)=<ωj,X>+bj=ωTj+bj|1 ≤j≤q},然后最大化所有相關和無關標簽對之間的距離。
2.3 深度學習方法
與傳統的機器學習方法不同,深度學習方法更為復雜,但極其促進了多標簽文本分類的發展,本節將深度學習模型根據其結構主要劃分為基于卷積神經網絡(convolutional neural network,CNN)、基于循環神經網絡(recurrent neural network,RNN)、基于注意力機制(attention)、基于Transformer、基于圖神經網絡(graph neural network,GNN)和混合結構。
2.3.1 基于CNN
CNN 包括卷積層、池化層和全連接層。典型CNN結構如圖4所示。
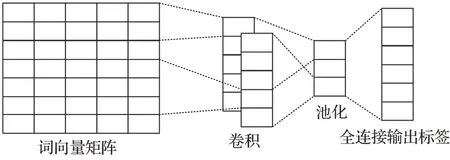
圖4 CNN結構Fig.4 CNN structure
CNN在檢測局部和位置不變模式很重要的情況下性能良好。2014 年,Kim 等人[29]提出了TextCNN 模型,在預先訓練的詞向量上訓練CNN,用于句子級分類任務,用一個具有少量超參數調優和靜態向量的簡單CNN測試,通過微調學習特定于任務的向量。但因為CNN中需要利用固定窗口的問題,因此不可以對長文本信息進行建模。Liu 等人[30]改進了TextCNN 的結構,提出XML-CNN。該模型與TextCNN 不同之處是通過將文檔通過各種卷積過濾器傳遞來學習大量的特征表示,采用動態最大池化,從文檔的不同區域捕獲更多細粒度的特征;利用輸出上的二進制交叉熵損失,在池化和輸出層之間插入了一個額外的隱藏瓶頸層,以學習緊湊的文檔表示形式。Shimura 等人[31]提出了一種利用CNN 的微調技術,一種分層卷積神經網絡結構(HFT-CNN),有效利用上層數據為下層分類做出貢獻。Yang 等人[32]提出了一種雙高光譜CNN(HSCNN)來處理不平衡數據,是一種混合-暹羅卷積神經網絡(HSCNN),即基于單網和暹羅網絡的多任務結構,對頭部分類采用通用網絡,對尾部分類采用少射技術。
盡管基于CNN的多標簽文本分類不需要花費大量的計算成本,但是由于CNN 的需要利用固定窗口的缺點以及池化操作會造成語義的丟失,所以當上下文文本過長時,基于CNN 的模型不利于捕捉上下文之間的標簽關系,因此不利于多標簽文本分類。
2.3.2 基于RNN
RNN是一種用于從時間序列數據中捕獲信息的網絡。RNN 結構如圖5 所示,其中,xt為t時刻輸入;St為t時刻隱層單元;yt為t時刻輸出;O為權重矩陣;U為輸入變換矩陣;V為輸出變換矩陣,與U在序列的不同時間點上共享,可以視為學習序列中固定的狀態轉移矩陣。
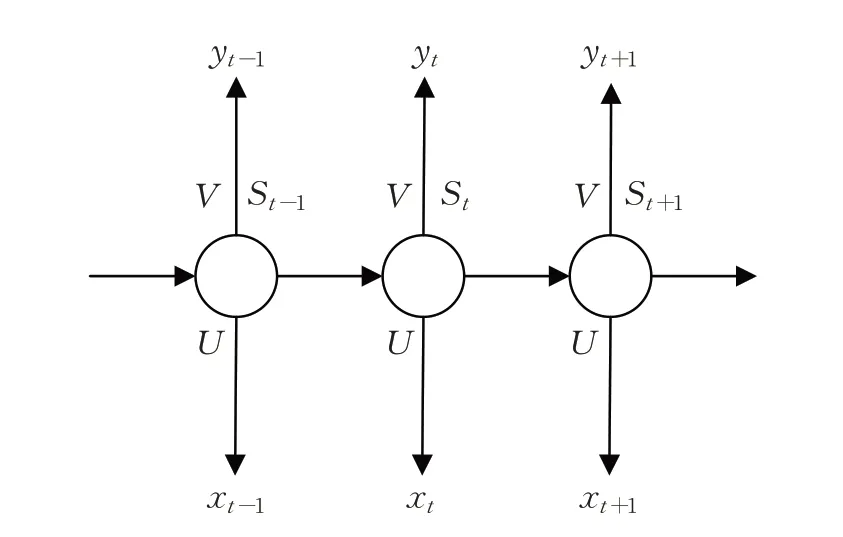
圖5 RNN結構Fig.5 RNN structure
基于RNN 的模型將文本視為一個單詞序列,旨在為TC捕獲單詞依賴關系和文本結構。對于多標簽文本分類,基于CNN 的方法通常不能捕獲多個標簽之間的復雜關聯,導致查全率低。為了解決這一問題,RNN被廣泛應用于探索標簽的相關性,用于多標簽文本分類[33-34],它是一種逐條預測標簽的遞歸神經網絡。Nam 等人[33]使用RNN 代替的分類器鏈,這是一種序列到序列的預測算法,最近已成功應用于許多領域的序列預測任務。這種方法的關鍵優勢在于,它允許僅專注于正標簽的預測,其集合比可能標簽的完整集合小得多。此外,所有分類器之間的參數共享可以更好地利用先前決策的信息。后續研究中,Yang等人[35]進一步將深度強化學習納入Seq2Seq 模型,以減少標簽排列對性能的影響。Lin等人[36]提出了基于Seq2Seq 模型的多級擴展卷積,擴張型卷積有效地降低了維數,支持接受域的指數擴展而不丟失局部信息。
但這些模型忽略標簽之間的相關性或者不考慮文本內容關鍵信息,因此,不能得到較好的預測結果。Yang等人[37]把多標簽文本分類問題當作序列生成,考慮標簽間相關性,對解碼部分進行改造,并且自動獲取文本的關鍵信息,提升標簽預測的有效性,這一改進在一定程度上改善了模型效果,但還有待提高。
2.3.3 基于Attention
注意力(Attention)機制由Bengio 團隊2014 年提出并應用于自然語言處理。Yang 等人[38]將單詞級和句子級的注意力納入模型,處理大規模文本分類。Hong等人[39]提出了注意力池化,增加了2D max 池化操作,以維護更重要的語義信息,降低噪聲的影響。此外,為了更好地突出不同情境下的重要文本信息,提出了多層次的注意力機制。Li 等人[40]采用兩級注意力來提高文本分類的性能,第一級注意力旨在同時捕獲局部和長距離相關的特征,第二級注意力通過雙向循環注意網絡對生成的特征進行注意。You等人[41]提出Attention XML捕獲文本與每個標簽最相關的部分,Attention XML 的出現超越所有傳統機器學習方法,并證明原始文本與稀疏特征相比的優越性。與在XML-CNN 中使用簡單全連接層進行標簽評分不同,Attention XML 采用了可以處理數百萬個標簽的概率標簽樹(PLT),通過其上層模型初始化當前層模型的權重,可以幫助模型快速收斂。但是,這仍然使Attention XML 在預測和從大型整體模型尺寸中獲取數據方面的速度非常慢。Du等人[42]首先使用卷積運算來捕捉注意力信號,每個信號代表一個詞在其上下文中的局部信息;然后這些注意信號再被進行預測。Xiao等人[43]第一個試圖在Seq2Seq模型中提出了基于歷史的注意力機制,以增強多標簽文本分類中標簽的預測能力。基于歷史的注意機制考慮了歷史上下文信息以避免陷入標簽陷阱,同時考慮了歷史標簽信息以緩解錯誤傳播問題。Liu 等人[44]提出了LAA_SD 方法,從冗余內容中選擇歧視性特征,考慮了語義標簽,并基于注意力機制建立了標簽與文本之間的關系,該方法將增強的文本特征表示與標簽語義依賴相結合,以執行文本多標簽學習。Song 等人[45]提出了一種標簽提示多標簽文本分類模型(LP-MTC),設計了一套多標簽文本分類的模板,將標簽集成到預先訓練好的語言模型的輸入中,并通過蒙面語言模型(MLM)聯合優化。通過這種方式,在自我注意力機制下捕獲標簽之間的相關性以及標簽與文本之間的語義信息,從而有效地提高了模型性能。
2.3.4 基于Transformer
RNN遇到的計算瓶頸之一是文本的順序處理。盡管CNN 的順序性不如RNN,但捕獲句子中單詞之間關系的計算成本也會隨著句子長度的增加而增加,這與RNN類似,Transformer克服了這些問題,其結構只保留了Attention,如圖6 所示,不需要與RNN 或CNN 相結合。應用自我注意力來并行計算句子或文檔中每個單詞的“注意力得分”,以模擬每個單詞對另一個單詞的影響。由于這一特性,Transformer允許比CNN和RNN更多地并行化,這使得在GPU 上對大量數據高效地訓練非常大的模型成為可能。

圖6 Transformer結構Fig.6 Transformer structure
Chang等人[46]提出了X-Transformer模型,它僅使用深度學習模型來匹配給定原始文本的標簽簇,并通過具有深度學習模型的稀疏特征和文本表示的高維線性分類對這些標簽進行排序。但由于Transformer模型的計算復雜度高,因此僅對Transformer 模型進行微調作為標簽聚類匹配器,無法充分利用Transformer 模型的功能。盡管X-Transformer可以以較高的計算復雜度和模型大小為代價,達到比AttentionXML更高的精度,但因為通過使用更多的集成模型,AttentionXML可以在相同的X-Transformer計算復雜度下達到更好的精度。Gong等人[47]提出了HG-transformer,該模型將輸入文本建模為圖結構;然后在詞、句、圖三個層次采用多層轉換結構,充分捕捉文本特征;最后利用標簽之間的層次關系生成t個標簽表示。Jiang 等人[48]提出LightXML,采用端到端訓練和動態負標簽采樣。在LightXML 中,使用生成式合作網絡對標簽進行調用和排序,其中標簽調用部分生成負標簽和正標簽,而標簽排序部分將正標簽與這些標簽區分開來。通過這些網絡,在標簽排名部分訓練期間,通過饋送相同的文本表示來動態采樣負標簽,提升模型的效果。Ye等人[49]提出了一種新穎的基于神經網絡的多標簽文檔分類方法,其中使用異構圖Transformer構造和學習兩個異構圖。一種是元數據異構圖,它對各種類型的元數據及其拓撲關系進行建模;另一個是標簽異構圖,它是根據標簽的層次結構及其統計依賴性構建的。Chen 等人[50]提出LitMC-BERT 模型使用共享Transformer主干,同時還捕獲特定于標簽的特征和標簽對之間的相關性,來進行多標簽分類。Zhang 等人[51]認為全局特征向量可能不足以表示文檔中語義的不同粒度級別,因此結合了Transformer 模型產生的局部和全局特征,以提高分類器的預測能力。
2.3.5 基于GNN
雖然自然語言文本表現出連續的順序,但是它們也包含內部的圖結構,例如語法和語義分析樹,其定義句子中的詞之間的語法和語義關系。為NLP 開發得最早的基于圖的模型之一是TextRank。作者提出將自然語言文本表示為圖形(V,E),其中V表示一組節點,E表示節點之間的一組邊。根據具體的應用,節點可以表示各種類型的文本單位,例如單詞、搭配、整句話等。同樣,邊緣可以表示任何節點之間的不同類型的關系,例如詞匯或語義關系、上下文重疊關系等。
在各種類型的GNN 中,圖卷積網絡(GCN)[52]及其變體,是最流行的一種,因為它們有效且方便地與其他神經網絡組合,并且在許多應用中已經實現了最先進的結果。GCN將卷積操作從網格數據推廣到圖數據。主要思想是通過聚合它自己的特征和相鄰的特征來生成節點的表示,GCN 堆疊多個圖卷積層以提取高級的節點表示。Liu 等人[53]提出的Text Level GCN 模型為每個輸入的文本建構獨立,但具有全局參數共享的圖而不是為整個訓練、測試語料庫建立一個巨大的單圖,并通過滑動窗口來構建圖形,當中可以設定n元語法的數量,用于提取更多的局部特征,并減少大量的計算資源,這也使圖神經網絡能夠從已有的資料中歸納出模式,并應用于新的任務。Velikovi等人[54]提出的圖注意力網絡(graph attention network,GAT)是GCN 的一個變體,它操作圖形結構數據,利用隱藏的自我注意力層來解決了先前基于圖卷積缺點。通過層層疊加,節點能夠參與到它們鄰近節點的特性,支持(隱式地)指定不同的權重一個鄰域中的不同節點,不需要任何昂貴的矩陣運算(如反轉)或依賴于預先了解圖的結構。Yao 等人[3]提出了TextGCN 模型,使用GCN 為整個資料集建立一個基于文本和詞的異構圖,可以用來得到全局圖的共現信息使GCN能夠對文本進行半監督分類。Pal等人[55]提出了一種基于圖注意力網絡的模型來捕捉標簽之間的注意依賴結構。圖注意力網絡使用特征矩陣和相關矩陣來捕獲和探索標簽之間的關鍵依賴關系,并為任務生成分類器。所生成的分類器被應用于從文本特征提取網絡(BiLSTM)獲得的句子特征向量以實現端到端訓練。Ding 等人[56]提出了一個原則性模型——超圖注意網絡(HyperGAT),它可以在文本表示學習中以更少的計算消耗獲得更強的表達能力。Zong 等人[57]提出了GNNXML,這是一個可擴展圖神經網絡框架。通過挖掘它們的共現模式來利用標簽相關性,并基于相關矩陣構建標簽圖;然后,通過使用低通圖濾波器進行圖卷積來聯合建模標簽依賴關系和標簽特征,從而進行屬性圖聚類,誘導語義標簽聚類。Zheng 等人[58]提出了一種標簽劃分門控圖神經網絡(LD-GGNN),可以更好地區分同級標簽,實現文本與標簽之間的自適應交互,優化了門控圖神經網絡(GGNN),以準確捕獲標簽層次結構的結構特征,并深入探索標簽依賴性,利用GGNN 更強的非線性特性來解決過平滑問題。
2.3.6 混合模型
許多混合模型已經被開發出來應用于多標簽文本分類。
Zhou 等人[59]提出了一種卷積LSTM(C-LSTM)網絡。C-LSTM 利用CNN 來提取較高級短語(n元語法)表示的序列,該序列被饋送到LSTM網絡以獲得句子表示。類似地,Zhang 等人[60]提出了用于文檔建模的依賴性敏感CNN(DSCNN)。DSCNN是一個分層模型,其中LSTM學習句子向量,這些句子向量被饋送到卷積和最大池層以生成文檔表示。Chen等人[34]提出了一種CNNRNN模型,以準確獲得全局和局部文本語義信息,建模高階標簽相關性。Transformer 的提出對自然語言處理領域產生了巨大的影響,但Transformer 模型所需的模型參數往往較多,網絡結構復雜,在實際應用過程中有一定的局限性。Liu 等人[61]提出了一種tALBERT-CNN的多標簽文本分類方法,使用LDA主題模型和ALBERT模型獲取每個詞(文檔)的主題向量和語義上下文向量,采用一定的融合機制獲得文檔的深度主題和語義表示,通過TextCNN模型提取文本的多標簽特征,訓練多標簽分類器,減少了模型參數。Yan 等人[62]本文提出了一種基于標簽嵌入和注意力機制的R-Transformer_BiLSTM模型用于多標簽文本分類。首次將實體識別模型引入文本分類利用R-Transformer模型結合部分語音嵌入來獲取文本序列的全局和局部信息;同時使用BiLSTM+CRF獲取文本的實體信息,使用自我注意力機制獲取實體信息的關鍵詞;然后,使用雙向注意力和標簽嵌入進一步生成文本表示和標簽表示;最后,分類器根據標簽表示和文本表示進行文本分類。
2.3.7 其他研究方法
Xiao 等人[63]提出了一種頭對尾網絡(HTTN),將元知識從數據豐富的頭部標簽轉移到數據貧乏的尾部標簽。Zhang等人[64]引入了一種具有多任務學習的新穎方法,以增強標簽相關性反饋。首先利用聯合嵌入(JE)機制同時獲得文本和標簽表示,在MLTC 任務中,采用了文檔標簽交叉注意力機制(CA)來生成更具歧視性的文檔表示。此外,提出了兩個輔助標簽共現預測任務來增強標簽相關性學習:(1)成對標簽共現預測(PLCP)和(2)條件標簽共現預測(CLCP)。Khataei 等人[65]提出了一種基于LSTM 網絡和SHO 算法的MLTC 的斑點鬣狗優化器-長短期記憶(SHO-LSTM)模型。在LSTM網絡中,將單詞嵌入到向量空間中,采用SHO算法優化LSTM網絡的初始權值。調整LSTM 中的權重矩陣是一個重大挑戰,如果神經元的權重準確,那么輸出的精度會更高。表1列舉了部分深度學習模型或方法。
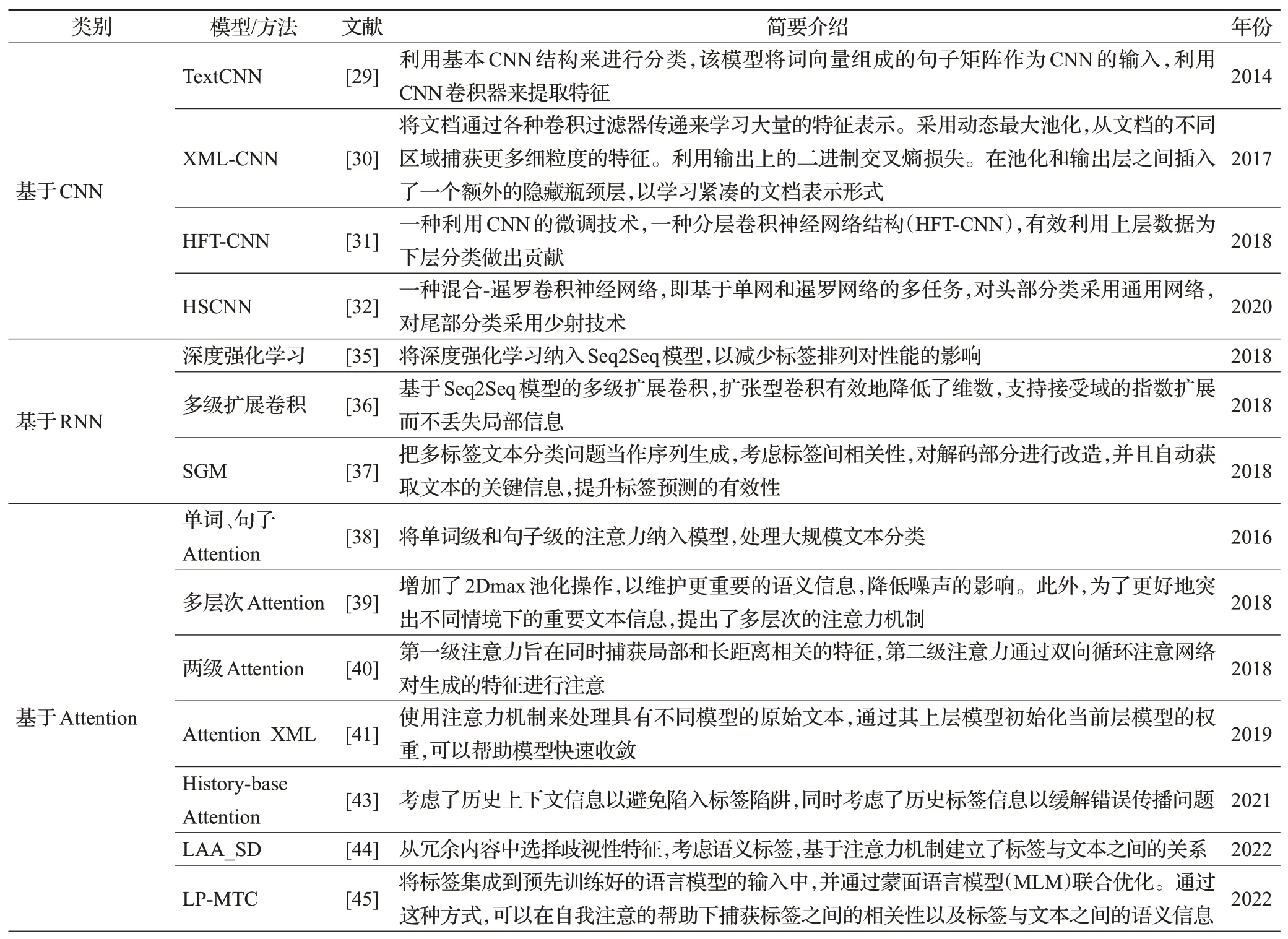
表1 深度學習模型及方法Table 1 Deep learning models and methods
3 多標簽文本分類數據集
總結了13 個多標簽文本分類領域的主流數據集,涵蓋中英文、長文本、短文本、極端多標簽和普通多標簽。并按照樣本的平均標簽數進行排列并在表2 中顯示了相關數據。

表2 多標簽文本分類數據集Table 2 Multi-label text classification dataset
(1)IMDB:包含117 196 個電影介紹(英文),共有27個電影類別,每個電影介紹都有一種或多種可能的類型。數據集根據電影是否屬于特定類型,為每個電影提供多標簽二進制掩碼。
(2)Ren-CECps1.0:該數據集是中文情感語料庫,包含37 678個中文博客的句子和11種情感標簽。
(3)Reuters-21578:數據集包含22 個文檔,總共10 788篇來自路透社的新聞文章,總共90個標簽。
(4)AAPD:該數據集收集了55 840 篇論文的摘要和相應學科類別,一篇學術論文屬于一個或者多個學科。
(5)RCV1:共有804 414篇新聞報道,涉及103個類別。每個報告可能包含一個或多個類別。平均而言,每個新聞報道包含3.2個類別標簽。
(6)RCV1-V2:該數據集共有804 414 篇新聞,每篇新聞故事分配有多個主題,共有103個主題。
(7)ToutiaoNews:該數據集為今日頭條統計新聞的中文數據集。
(8)Wiki-500K:數據也包含自維基百科,但與Wikil0-31K數據集相比,樣本數量更大,標簽數量更大。
(9)AmazonCat-13K:該數據集來自亞馬遜,包含用戶評論和產品信息等數據。
(10)EUR-Lex:數據集組織來自各種歐盟法律、條約等的文件,并包含15 449 個訓練文檔和3 865 個測試文檔,整個數據集總共有3 956個標簽。
(11)Amazon-670K:該數據集是亞馬遜商品的評論,有643 474條樣本數據。
(12)Wiki10-31K:數據集包含維基百科上的20 762篇文章,但標簽數量達到了30 938個。
(13)Amazon-3M:該數據集是亞馬遜商品的產品信息、鏈接和評論,標簽數量達到2 812 281個。
4 多標簽文本分類評估指標與模型分析
4.1 評估指標
多標簽文本分類(MLTC)模型的評估不同于單標簽分類模型的評估。因此,根據文獻[66],已經提出了幾種多標簽文本分類評估指標,它們分為兩種主要方法:基于實例的指標和基于標簽的指標。第一種方法是測試每個實例,然后對所有測試實例進行平均計算。第二種方法是對每個標簽計算,然后在所有標簽上取平均值。
4.1.1 基于實例的指標
下面介紹了用于評估多標簽文本分類模型的最常見的基于實例的指標。假設:m指數據集中的實例總數,i表示數據集中的實例(其中1 ≤i≤m),n為標簽總數,Zi和Yi分別指預測的和實際的標簽。
(1)漢明損失(Hamming loss):計算在實例標簽對中發現的平均錯誤數,并在所有實例上平均。此度量的表達式如公式(1)所示:
其中?定義了預測標簽和實際標簽之間的對稱差,因子1/n用于獲得[0,1]中的歸一化值。
(2)多標簽精度(ML-accuracy):計算正確預測的標簽與標簽總數的比率,計算如公式(2)所示:
(3)子集精度(Subset-accuracy):稱為精確匹配比或分類精度。這是一個非常嚴格的指標,用于測量預測標簽的比率,該比率與它們相應的實際標簽集完全匹配,計算如公式(3)所示:
(4)精度(Precision):該指標提供了正確分類的標簽與預測標簽的比率,計算如公式(4)所示:
(5)召回率(Recall):計算實際標簽的正確預測標簽的比率,計算如公式(5)所示:
(6)F-度量(F-measure):精度和召回率的調和平均,計算如公式(6)所示:
除了漢明損失度量之外,本小節中描述的所有基于示例的度量都表明具有越高值的度量具有更好的性能,漢明損失的值越低表示性能越好。
4.1.2 基于標簽的指標
基于兩種計算平均值的方法為所有標簽計算二進制評估指標(例如召回率、精度和F-度量);宏觀或微觀平均方法。這些指標被廣泛用于測量召回率、精度和F-度量的平均值。設B為一種用于計算這些指標的二進制評估度量,該度量基于真正類(tp)、假正類(fp)、真負類(tn)和假負類(fn)的數量進行計算。如公式(7)、(8)中說明了B(tp,fp,tn,fn)的宏觀平均和微觀平均指標的表達式。
4.2 模型分析
表3為對相關多標簽文本分類方法在部分數據集上的結果分析。

表3 模型方法結果分析Table 3 Analysis of model method results
從模型結果可以看出,隨著深度學習的發展,基于深度學習方法的模型在不同數據集上的F-measure值都有顯著的提升。在APPD 數據集上,F-measure 值從BR模型的0.641 2 提升到LP-MTC 模型的0.745 8,提升的效果十分明顯。在RCV1-V2數據集上,F-measure從BR模型的0.851 8 提升到R-Transformer_BiLSTM 模型的0.893 2。在EURLex-4K數據集上模型的效果從0.717 9提升到0.753 8。在其他的數據集上,隨著深度學習的發展,模型都有顯著的提升。R-Transformer_BiLSTM 模型在RCV1-V2數據集上的表現完全優于在AAPD數據集的表現,說明此模型對大規模數據標簽的文本分類依然具有良好的性能。
傳統的機器學習方法,如BR和CC 等,因為其不考慮標簽的相關性,并且當前標簽可能與序列的前一部分中的標簽無關,從而在使用先前標簽的輸入來引入了噪聲,導致分類器性能的降低,因此在部分數據集上的表現較差。
基于CNN 的深度學習網絡模型,如TextCNN 和XML-CNN等,由于CNN固定窗口的缺點以及其池化操作導致語義的丟失,影響了它的分類器的性能。雖然XML-CNN模型對這一缺點有一定程度上的改進,但是由于根本上CNN 結構簡單,因此在不同數據集的表現一般。
基于RNN 的深度學習網絡模型,如SGM 等,對模型進一步改善,提高了分類器的性能,但其在預測標簽時,基于序列的模型因為后一個標簽往往依賴于前一個標簽,所以前一個錯誤標簽的影響往往是疊加的,導致分類器性能下降。基于RNN的模型雖然考慮了標簽的相關性,但是模型的效果提升不明顯。
基于Attention 的深度學習網絡模型,如Attention XML 和LAA_SD 等,應用動態最大池化來學習文本表示,運用多層次Attention來捕捉特征,Attention XML使用雙向長短時記憶(BiLSTM)網絡從原始文本輸入中提取嵌入,在模型的性能上提升的效果明顯,但是因為不充分考慮局部或者全局的標簽相關性,在一定程度上影響了模型性能。
基于Transformer的深度學習網絡模型,如X-Transformer等,克服了文本的順序處理的問題以及減少了捕獲句子中單詞之間關系的計算成本,從而提升了模型的性能,但是在實際的應用場景中,Transformer模型所需的模型參數往往較多,網絡結構復雜,所以還是一定程度上影響了模型性能。
基于圖神經網絡的深度學習網絡模型,如GNNXML 和LD-GGNN 等,挖掘文本內部的圖結構,從網絡數據推廣到圖數據,提取更多的局部特征,減少大量的計算資源,不斷挖掘標簽之間的相關性,提高了模型的性能,在不同的數據集上表現明顯。
混合的深度學習網絡模型,如tALBERT-CNN和RTransformer_BiLSTM 模型利用注意力機制考慮上下文信息,考慮標簽之間的相關性,抽取出文本的關鍵信息,用于多標簽文本分類,其分類器效果顯著,但是分類效果依然有提升的空間。
近年來,其他研究模型在不同的數據集上的分類效果都有明顯提高,但是在面對大規模標簽數據集以及層次多標簽數據集時的分類效果并不明顯,未來研究需要進一步提升。
5 多標簽文本分類研究方向
5.1 標簽相關性
5.1.1 標簽相關性的類型
在多標簽問題中,標簽不是獨立的,而是存在一些相關性。標簽相關性的使用有利于學習更有效和穩健的分類模型。在多標簽文本分類問題中,某些標簽的正樣本很少,在這種情況下,使用標簽相關性是極其重要的。充分利用標簽相關性已成為目前多標簽分類的主要研究方向之一,它是許多算法的重要組成部分[67-68]。現有的標簽相關使用策略可以分為三種類型[69]:一階、二階和高階。
(1)一階算法
一階算法如BR、ML-C4.5 和ML-kNN[23]。BR 為每個標簽構建二進制分類方法,目的是學習相應的分類器hi:X→{0,1}。在學習過程中,輸入是原始特征空間,而輸出是標簽yi的值。因此,不同的標簽具有相同的輸入,但具有不同的輸出。ML-C4.5通過決策樹將訓練數據集逐層分成幾個小子集,樹根覆蓋所有訓練數據。對于非葉節點,應用信息熵和基尼指數等指標進一步將非葉節點劃分為子節點,使得子節點數據的“純度”高于父節點。ML-kNN是一種惰性學習方法。在預測時,MLkNN 模型根據預測數據在訓練數據的最近鄰中各標記的分布情況,采用最大化后驗概率的原則決定測試樣例是否與某一標記相關。但這些一階算法完全忽略標簽相關性。
(2)二階算法
二階算法如Rank-SVM[28]、CLR[22]、MLPP[70],CPNL[71]、PCT[72]和GBRAML[73]考慮了的標簽相關性。Rank-SVM定義了在相關性-非相關性標簽對中最大化距離的優化目標,并利用SVM 技術解決了多標簽分類問題。CLR算法通過成對比較方法將常見的學習擴展到多標簽文本分類中,引入一個人工校準標簽,在每個實例中,將相關標簽從不相關標簽中分離出來。MLPP 通過每對標簽對分類器進行訓練,并通過投票結合各種分類器的預測結果來確定標簽相關性的序列。CPNL 利用了標簽的正負相關性,擴展了BR 算法。PCT 根據排序損失的定義,提出了一種標簽兩兩比較變換方法,將每個原始的多標簽樣本轉化為特征向量相同、標簽向量不同的多個樣本。GBRAML是一種基于顆粒批處理模式的多標簽排序活動模型。從自下而上的角度來看,依次構造了三個造粒算子,以形成三個顆粒結構。在低級造粒算子中,引入輔助標簽以增強每個標簽的信息性和代表性。表4列舉了標簽相關性研究的一階算法和二階算法。

表4 一階算法和二階算法Table 4 First-order algorithms and second-order algorithms
(3)高階算法
高階算法如RAkEL[19]、CC[18]、BNCC[74]和MLMF[75]考慮幾個或所有標簽之間的相關性。作為一種集成學習方法,RAkEL 算法通過考慮一個小的標簽隨機子對于任何標簽,序列前部的標簽都會作為新特征添加到原始特征中,以這種方式利用了多個標簽之間的關系。BNCC利用貝葉斯網絡對標簽相關性進行建模,用條件熵描述標簽之間的依賴關系,以節點為標簽,以邊的權重為依賴關系,并引入了一種啟發式算法來優化BN結構,通過對優化后的BN 節點進行拓撲排序,得到構建CC 模型的標簽順序。MLMF設計一個有效的多標簽分類器,自動學習高階非對稱標簽相關性,降低特征空間的維數,處理完整標簽和缺失標簽的情況。從關系提取或使用角度來看,高階算法可以分為全局關系算法、局部關系算法和全局-局部組合關系算法。
①全局關系算法
全局關系算法認為標簽相關性是全局的,換句話說,標簽之間的相關性存在于所有訓練數據中。全局關系算法如CC、MLLS[76]、ML-LPC[77]、CLSF[78]和A-GCN[79]。CC將所有標簽放在一個隨機序列中。先前標簽的二進制分類器輸出作為新特征添加到標簽的原始特征空間中。MLLS 是一個通用的框架來提取多標簽分類中的共享結構,在這個框架一個公共子空間被多個標簽共享,從而闡明了它們的內在關系。ML-LPC學習標簽之間的相關性同時訓練多標簽模型。采用低秩結構來捕獲標簽之間復雜的相關性,利用標簽相關性得到不完整的標簽矩陣。CLSF首先定義每個標簽的基本要素和特征反映了內部特性和標簽之間的聯系。此外,還提供了計算單個標簽的基本元素的過程,其次,通過考慮不同標簽所確定的基本元素集合的重疊,描述了標簽的相關性以及與標簽集對應的相關性判斷矩陣,因此,幾個具有強關系的標簽被分配到一個相關的標簽組中,同時,可以計算局部和全局標簽相關性。A-GCN使用標簽圖來學習帶有單詞嵌入的全局標簽相關性。
②局部關系算法
在局部關系算法中,標簽相關性存在于訓練數據的一部分中。在這種情況下,標簽的依賴關系僅存在于某些數據中。如果從全局角度提取或使用此類標簽相關性,則將對所有實例施加不必要甚至誤導的約束,這將降低分類模型的性能。這些局部考慮標簽相關性的算法LPLC[80]。LPLC在局部考慮標簽相關性,為所有訓練實例找到每個標簽的正負標簽相關性。然后,對于每個測試實例,基于其k近鄰的局部正負標簽相關性,使用最大后驗概率進行預測。Ma等人[81]提出了一個具有局部特征選擇和局部標簽相關性的新框架,在該框架中,假設實例可以聚到不同的組中,且特征選擇權重和標簽相關性只能由同一組中的實例共享。該框架包括一個特定于組的特征選擇過程和一個特定于標簽組選擇過程。前者通過提取實例組-相關性將實例投射到不同的組中,后一個過程通過提取組-標簽相關性,基于相關組為每個實例選擇標簽集,并學習一個單標簽分類器來預測這個子集的冪集中的每個元素來構造集合的每個元素。CC 算法將標簽隨機放入一個序列中,為每個標簽構建二進制分類器。
③全局-局部關系算法
全局-局部組合關系算法同時考慮全局和局部標簽相關性,建立高效分類模型。例如,GLOCAL[82]通過流形正則化學習全局和局部標簽相關性。GLkEL[83]通過近似聯合互信息從標簽空間中選擇最相關的k標簽集,以評估全局標簽相關性。然后,它將訓練數據聚類為不同的組,并評估每個組中的局部標簽相關性。LFGLC[84]集成了全局和局部標簽相關性,以提取每個標簽的標簽特定特征。Liu等人[85]在整個標簽空間中計算一個全局標簽相關矩陣,根據簇內標簽的余弦相似度,為每個實例子集分配一個局部標簽相關矩陣,基于標簽相關性可以從原始類別空間轉移到數值標簽空間的假設,添加了全局和局部標簽相關性正則化項,將重要性估計和模型訓練整合到一個統一的框架中。表5 列舉了標簽相關性的高階算法。

表5 高階算法Table 5 High-order algorithms
5.1.2 標簽相關性的研究
(1)基于標簽相關性的特征壓縮
為了消除冗余和不相關的特征,研究人員提出了許多方法來壓縮多標簽數據特征。這些方法中的許多方法通過使用標簽相關性來選擇特征或實現特征轉換。在參考文獻[86]中,提出過濾特征選擇方法;最小冗余和最大相關性(mRMR);用互信息來衡量標簽的重要性;通過多種權重策略估計特征和標簽之間的關系。
(2)基于標簽相關性的特征擴展
上述方法基于標簽相關性對原始特征空間進行壓縮。一些算法通過使用標簽相關性來擴展特征,基于堆疊的BR算法[17],其中BR的第二層中二進制分類器從第一層中選擇強相關的輸出來擴展原始特征空間。在參考文獻[87]中,提出了一種分類器鏈模型來處理多標簽問題,主要創新在于它選擇了一個有向無環圖來對標簽相關性進行建模,并通過條件熵來測量標簽相關性,從而最大化了圖中表示的所有標簽之間的相關性之和;再根據這個有向無環圖和預測擴展了原始特征空間,即將與原有標簽相對應的二進制分類器的結果添加進去;最后,基于擴展特征訓練二進制分類器。ML-LOC[88]也是一種基于標簽相關性的特征擴展算法。
(3)基于標簽相關性的標簽嵌入
標簽嵌入是一種重要的多標簽分類算法,它可以聯合提取所有標簽的信息,從而獲得更好的性能。Chen等人[89]提出了使用圖卷積網絡學習標簽嵌入和標簽之間的相關性,使用融合層將標簽信息與文本的上下文語義信息結合起來。Wang等人[90]提出了一個新的基于跨視圖的模型,具有多標簽分類鑒別結構的魯棒交叉視圖嵌入(RCEDS)。該方法實現了一種魯棒和鑒別嵌入,在RCEDS中,設計了一種新的超圖融合技術,利用特征空間和標簽空間之間的互補性,同時利用雙邊度量學習挖掘特征空間和標簽空間的一致性。
5.2 特定標簽特性
2014年,Zhang等人[91]提出了一種提升算法,首次提出了標簽特定特征的概念。大多數現有的多標簽方法通常使用相同的實例表達式來為不同的標簽構建分類模型。換句話說,不同的標簽在學習過程中使用相同的特征矩陣。盡管如此,提升算法認為標簽應具有其唯一的表達式,因此,不同的標簽應使用適當的特征表達。只有利用這些特征,才能進一步提高分類模型的效果,這些功能被稱為“特定于標簽的功能”。標簽特定特征的概念與傳統特征壓縮的概念有明顯的區別。在傳統特征壓縮的概念中,一般通過特征提取或特征選擇向所有標簽提供統一的特征表達。標簽特定功能是指與特定標簽相關的功能,而不是與所有標簽相關的功能。
目前,構建標簽特定特征的方法主要有兩種:特征提取和特征選擇。前者用LIFT表示[91],后者用LLSF表示[92]。表6列舉了特定標簽特性的研究。

表6 特定標簽特性Table 6 Features of lable-specific
5.2.1 基于特定標簽特性的特征提取
LIFT通過特征提取為每個標簽提取特定于標簽的特征。具體來說,與任何標簽相關的樣本被視為正樣本,而其余樣品被視為負樣本。k均值分別用于對正樣本集和負樣本集進行聚類,計算從樣本到聚類中心的距離,這些距離形成了新的樣本特征。接下來,在這些新的標簽特定功能的空間上學習二進制分類器。對于不同的標簽,正樣本和負樣本的分布是不同的,因此構建的標簽特定特征彼此不同。在大量實驗的基礎上,證明其性能的非凡效果。此后,特定于標簽的功能引起了學術界的廣泛興趣,并相繼提出了一系列算法。
基于LIFT、LF-LPLCl[93]集成了標簽特定特征和局部成對標簽相關性,其中每個標簽的特定特征通過將相關標簽中的相關特征結合在一起來擴展,這豐富了標簽的語義信息,并在一定程度上解決了類別不平衡問題。LETTER[94]從實例和特征級別中提取標簽特定的特征。從實例層面,使用稀疏和原型約束來查找更具歧視性的實例中心;從特征層面,利用聚類從正負實例的原始特征中找到特征中心,最終的標簽特定特征由從上述兩個級別中提取的中心組成。Fan等人[95]提出了一種新的基于標簽相關性和特征冗余度的LFFS方法。首先利用嶺回歸建立特征選擇矩陣和低維嵌入;然后,采用低維嵌入挖掘標簽相關性,保持原始標簽空間的全局和局部結構;最后,利用余弦相似度分析特征冗余度,生成低冗余度特征子集。Wu 等人[96]引入了一個新的考慮LC 的領域集模型。首先,通過計算標簽之間的相似關系來探索LC,并將相關標簽劃分為多個標簽子集;然后,提出了一種新的鄰域關系,利用相關標簽下實例的最近鄰信息分布,解決了鄰域粒度選擇問題。
5.2.2 基于特定標簽特性的特征選擇
上述算法均采用特征變換提取標簽特有的特征,但是,Huang 等人[92]提出的LLSF 算法通過特征選擇技術來學習標簽特定的特征。LLSF假設每個標簽僅與一些原始特征相關,并且它在具有約束的線性回歸中表達了這種稀疏性,非零回歸參數表示相應的特征是特定于標簽的,而其他特征則不是。
LLSF的目標函數假設強相關標簽比弱相關標簽具有更多的標簽特定特征。由于LLSF通過線性回歸實現了特征選擇,它可以根據選擇的特征學習二進制分類模型。NSLSF[97]認為稀疏性假設在某些應用中不成立,提出了一種基于特征選擇的方法來選擇標簽特定的特征。它將邏輯標簽轉換為數字標簽,以傳達更多的語義信息,并嵌入標簽相關性。MCUL還利用系數矩陣上的范數正則化來學習稀疏標簽特定特征,從而處理缺失和完全未觀察到的標簽。Sun等人[98]提出了一種基于多標簽模糊鄰域粗糙集(MFNRS)和最大相關最小冗余(MRMR)的特征選擇方法,可用于缺少標簽的多標簽數據。首先,針對標簽缺失的多標簽數據,構造樣本關系系數、標簽互補矩陣和標簽特定特征矩陣,并在線性回歸模型中實現對缺失標簽的恢復;其次,建立了基于邊緣的模糊鄰域半徑、模糊鄰域相似關系和模糊鄰域信息顆粒;多標簽鄰域粗糙集與模糊鄰域粗糙集相結合,建立了多標簽鄰域粗糙集模型。基于代數和信息視圖,提出了基于模糊鄰域熵的MFNRS 不確定度測度,改進了基于模糊鄰域互信息的標簽相關MRMR 模型,用于評價候選特征的性能。Hu等人[99]提出一個基于權重特征選擇的方法(RWFS),基于兩種類型的變化比率,通過同時考慮兩種類型的特征相關性評估比率來提供更可靠的特征排序。
5.3 其他研究方向
5.3.1 類別不平衡
類別不平衡問題已成為許多標簽數據集的固有特征,其中樣本及其對應的標簽在數據空間上分布不均勻。多標簽文本分類中的不平衡問題給多標簽數據分析帶來了挑戰,可以從三個角度來看:標簽內部、標簽之間和標簽集之間的不平衡。
在傳統的二元類和多類問題中也普遍存在類不平衡問題。因此,該問題解決思路可以為處理多標簽不平衡問題提供一些啟示。Zhang等人[100]提出了一種COCOA算法來解決多標簽應用中的類不平衡問題。Charte 等人[101]提出了多標簽不平衡度的幾種復雜測量標準,同時Charte 等人還提出了用于多標簽數據不平衡預處理的欠采樣和過采樣算法(LP-RUS 和LP-ROS)。Pereira 等人[102]提出MLTL,是一種類似的基于啟發式的方法。該方法采用經典的Tomek Link 算法來解決不平衡問題,可以用作欠采樣或清洗技術。MLSMOTE 算法[103]討論了一種用于多標簽學習得過采樣技術,該技術與SMOTE使用了類似的策略。首先,MLSMOTE算法通過MeanIR和CVIR識別少數標簽;然后,為這些標簽合成新樣本。另一個提出的方法是MLSOL[104]。該方法主要通過觀察少數群體樣本的局部特征來分析不平衡,而不是整個數據集的不平衡。在文獻[105]中提出了一種適應方法來解決MLC 中的不平衡問題,它基于非對稱階段損失函數來動態調整正負樣本的損失成本。Rastogi等人[106]通過構建標簽權重矩陣來處理類不平衡問題,權重估計由標簽出現、缺席和未觀察的頻率來指導,利用類不平衡敏感權值和輔助標簽相關性,引入帶有歧視性標簽權值的加權平方損失函數,指導缺失標簽補全。
總之,通過采樣實現了多標簽問題種類不平衡的常見直觀處理,需要進一步研究如何在抽樣中使用標簽相關性。此外,通過集成學習和成本敏感性,可以盡可能消除類別不平衡的不利影響。
5.3.2 標簽丟失
在許多實際應用中,由于以下兩個主要原因,獲得訓練集中所有樣本的所有真實相關標簽是不切實際的[107-108]。一方面,許多應用程序包含許多需要大量標簽類;另一方面,不同標簽的含義可能會重疊,因此很難完全區分。因此,基于此類部分標簽的數據的學習模型可能無法準確捕獲標簽相關性以及標簽與特征之間的關系。Taha 等人[109]提出了基于聚合特征和標簽圖的缺失標簽處理方法(GB-AS)和基于統一圖的缺失標簽傳播方法(UG-MLP)。一方面,GB-AS算法根據基于特征的加權表示和基于標簽的加權表示兩種文檔級別的相似度,獲得初始標簽矩陣。另一方面,引入UG-MLP 構造一個混合圖,將GB-AS 和標簽相關結合到一個單一的基礎上,從不完整的訓練數據中獲取高階標簽相關性,并將其用于補充缺失的標簽矩陣,指導多標簽分類模型的建立。Ai 等人[110]提出了一種改進的MLTSVM(LSFML-MLTSVM),利用標簽缺失的標簽特定特征。LSFML-MLTSVM 首先通過半監督聚類分析提取標簽特異性特征,然后獲得樣本的結構信息和邊緣分布的幾何信息。Sun 等人[111]提出了一種基于兩階段鄰域的多標簽分類方法,用于鄰域決策系統中缺失標簽的不完全數據分類。首先,為了解決人工選取鄰域半徑的問題,以及在鄰域內平衡樣本,定義了基于特征分布函數的鄰域半徑,分別通過可識別矩陣和不可識別矩陣計算樣本間的異同,在此基礎上,提出了一種缺失特征值的恢復方法;其次,考慮到特征間的非線性關系,基于高斯核函數研究了樣本間基于鄰域的模糊相似關系;在模糊相似關系矩陣、標簽特定特征矩陣和標簽相關矩陣的綜合基礎上,提出了基于回歸模型的目標函數,給出了基于梯度下降策略的標簽特定特征矩陣和標簽相關矩陣的最優解,并在第二階段提出了一種新的缺少標簽的多標簽分類方法;最后,設計了兩階段多標簽分類算法。
5.3.3 標簽壓縮
由于許多實際的多標簽問題中的標簽數量可以達到數萬個,因此許多研究已經將注意力轉移到涉及大量標簽的多標簽分類上,過多的標簽可能會給算法帶來相當大的時間和空間成本。此外,許多成熟和常見的算法,如BR[14]和ECC[18]不適用于處理這些過多的標簽。為了解決這個問題,研究人員提出了標簽的空間尺寸壓縮技術,將高維標簽壓縮到低維標簽空間中,并在低維標簽空間中訓練分類模型以減少計算負擔。當然,低維標簽空間中的預測結果必須恢復到原始特征空間中。根據現有研究,標簽壓縮不僅可以縮短算法的運行時間,而且可以提高分類效果。Cao等人[112]提出了一種新的標簽壓縮編碼方法,同時考慮特征和標簽信息。基于標簽變換的標簽壓縮算法具有理論基礎強、易于實現等優點。但是,轉換后的標簽缺乏原始標簽的含義,因此它們很難相互連接。基于標簽子集的標簽壓縮算法經常使用群稀疏學習、隨機抽樣、布爾矩陣分解等。這些算法可以獲取低維標簽,或者標簽直接來自原始標簽,或者可以完全恢復原始特征空間。Yu等人[113]介紹了一種PML 方法(PML-LCom),使用標簽壓縮來有效地從部分多標簽數據中學習。PML-LCom 首先將觀察到的標簽數據矩陣分解為潛在的相關標簽矩陣和不相關的標簽矩陣,然后將相關的標簽矩陣分解為兩個低秩矩陣,一個對樣本的壓縮標簽進行編碼,另一個對潛在的標簽相關性進行探究;然后,對壓縮后的標簽矩陣對多標簽預測器的系數矩陣進行優化。Yang等人[114]提出一種多同步壓縮變換方法(MSST),對處理后的數據進行變換。在同步壓縮變換的基礎上,采用迭代重分布代替原始數據,完成模式識別。此外,針對樣本的特征相似度,對壓縮后的標簽矩陣進行正則化,并對標簽矩陣和預測器進行了一致性優化。因此,標簽壓縮算法具有很強的解釋力。表7 列舉了其他研究方向上的部分模型分析。

表7 其他研究方向Table 7 Other research directions
6 總結與展望
多標簽文本分類的研究隨著深度學習的到來取得了豐碩的成果,尤其是在BERT 的到來之后,大大提高了相關研究的準確性。盡管該領域已經有相當成熟和實用的技術,但仍有一些棘手的問題值得研究人員共同探索:
缺乏數據集和低質量數據集問題。多標簽文本分類比單標簽文本分類要復雜得多,因此數據集資源的缺乏極大地限制了研究人員對模型的開發,并且特定領域如醫療、法律、金融和建筑的數據集十分匱乏;其次,由于該領域的當前數據集普遍存在數據分布不均勻的問題,因此主要表現為長尾問題,即同一數據集中的大多數文檔僅與一個或極少數的標簽相關。因此,創建更多高質量的數據集是一個值得長期討論的問題。
文本相關標簽的動態劃分問題。目前,多標簽文本分類主要依靠監督學習,標簽發生變化,就需要對模型進行重新訓練,適應變化,但重新標記數據集或訓練模型都需要很高的成本。因此,如何低成本、快速地使訓練好的模型適應標簽的變化是一個值得考慮的問題。
極端多標簽文本分類問題。極端多標簽文本分類(XMC)目的是從一個極大的標簽集合中為給定的文本找到相關的標簽。XMC的主要難點是文本標簽的數目非常多。目前提出模型的內存占用隨著標簽空間的變大而變大。因此,如何減小極端多標簽文本分類模型的大小是未來主要研究方向之一。
層級多標簽文本分類問題。許多現實世界的文本分類任務通常處理以層次結構或分類法組織的大量緊密相關的類別。當需要處理大量緊密相關的類別時,層級多標簽文本分類(HMTC)變得非常具有挑戰性。層次標簽概念:一級標簽包含二級標簽,二級標簽包含三級標簽。HTMC 的難點在于考慮垂直類別相關性的平面多標簽以及同一級別類別之間的水平相關性;充分地建模層級依賴關系,提高各層級標簽,尤其是下層長尾標簽的預測性能,此外,整個層次結構中所有類別的結構特征及其類別標簽的單詞語義對于提高大量緊密相關類別的文本分類準確性非常有幫助。因此,如何設計這樣一個模型去解決這些問題是未來亟待解決的一個難點。
小樣本多標簽文本分類也是當前和未來研究熱點,在實際的應用場景中,得到文本數據可能會面臨分類類別多、樣本數據小和文本短等問題。小樣本數據集的構建,也更利于模型可以應用于不同的領域。
7 結語
本文對近年來多標簽文本分類概念、流程、方法和研究方向的文獻進行了綜述。將多標簽文本分類方法分為傳統機器學習方法和深度學習方法;研究方向劃分為標簽相關性、特定標簽特性、類別不平衡、標簽丟失和標簽壓縮;最后對多標簽文本分類的挑戰和未來方向進行了討論。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
