基于分段組合特征降維的交叉視角目標(biāo)定位研究
2023-09-24 05:33:08趙化啟
現(xiàn)代計(jì)算機(jī) 2023年13期
關(guān)鍵詞:特征實(shí)驗(yàn)
劉 琳,趙化啟
(佳木斯大學(xué)信息電子技術(shù)學(xué)院,佳木斯 154007)
0 引言
交叉視角目標(biāo)定位是根據(jù)參考圖像找到無人機(jī)圖像中目標(biāo)位置的過程。交叉視角目標(biāo)定位技術(shù)具有廣闊的應(yīng)用前景,能夠?qū)崿F(xiàn)無人機(jī)定位、導(dǎo)航以及事件檢測等任務(wù)[1-3]。早期的圖像地理定位任務(wù)是通過查詢圖像與帶地理標(biāo)簽的街景圖像匹配來完成的[4-5],然而由于帶地理標(biāo)記的圖像大部分集中在城市地標(biāo)中,從而限制了該方法的應(yīng)用。Lin 等[6]最早提出了交叉視角圖像匹配,并制作了包含地面圖像、航空?qǐng)D像以及地面屬性圖像的數(shù)據(jù)集,圖像定位成功率為17%。而后學(xué)者們也提出了基于地面圖像與航空?qǐng)D像的地理定位數(shù)據(jù)集[7-8]。目前基于深度學(xué)習(xí)的方法已經(jīng)廣泛應(yīng)用于交叉視角目標(biāo)匹配任務(wù),比如Liu 等[8]提出了OriCNN,提高了所學(xué)特征的分辨性; Hu 等[9]提出了CVM-Net,使用完全卷積層提取局部圖像特征并結(jié)合Net-VLAD[10]將其編碼為圖像全局描述符。考慮到地面圖像與航空?qǐng)D像存在差異,Zheng 等[11]提出了University-1652 數(shù)據(jù)集,該數(shù)據(jù)集包括了三個(gè)視角的數(shù)據(jù),包含了無人機(jī)圖像、衛(wèi)星圖像以及地面圖像,能夠更好地學(xué)習(xí)視角不變特征,彌補(bǔ)了不同數(shù)據(jù)間外觀的差異。Wang 等[12]提出了LPN(local pattern network)網(wǎng)絡(luò),充分利用了圖像相鄰區(qū)域的上下文信息,提高了交叉視角目標(biāo)定位的精度。薛朝輝等[13]提出了一種融合NetVLAD 和三元神經(jīng)網(wǎng)絡(luò)的交叉視角圖像定位方法,取得了較高的定位精度。
雖然基于深度學(xué)習(xí)的方法在交叉視角目標(biāo)定位上取得了較好的效果,但是存在學(xué)習(xí)所得特征維度過高、區(qū)分性不足的缺點(diǎn),這會(huì)影響交叉視角目標(biāo)定位的速度和精度。因此,針對(duì)上述問題,本文先通過Resnet-50 網(wǎng)絡(luò)選取實(shí)例損失[14]作為損失函數(shù),選取University-1652數(shù)據(jù)集的無人機(jī)圖像及衛(wèi)星圖像進(jìn)行訓(xùn)練得到特征提取模型。另外,圖像經(jīng)過特征提取后,提出了一種分段組合降維方案對(duì)圖像全局特征進(jìn)行降維,保留了特征的主要信息并降低了特征維度,最終提高了交叉視角目標(biāo)的檢測精度和速度。
1 基于迭代降維的交叉視角圖像定位
1.1 整體框架
本文所提方法整體框架如圖1所示,包括了訓(xùn)練以及檢測兩個(gè)步驟。其中訓(xùn)練網(wǎng)絡(luò)為Resnet-50 網(wǎng)絡(luò),訓(xùn)練數(shù)據(jù)為無人機(jī)圖像和衛(wèi)星圖像,并選取實(shí)例損失作為損失函數(shù)進(jìn)行訓(xùn)練得到特征提取模型。在檢測階段,將目標(biāo)圖像(無人機(jī)圖像)和衛(wèi)星圖像數(shù)據(jù)庫輸入到特征提取模型,得到512維的全局圖像特征,基于主成分分析(PCA)方法提出了一種迭代特征降維方案對(duì)特征進(jìn)行降維,最后將兩者特征進(jìn)行相似性比對(duì)得到目標(biāo)圖像的匹配圖像。
1.2 特征提取網(wǎng)絡(luò)
本文選取ResNet-50[15]作為網(wǎng)絡(luò)的主干,其中ResNet 是一種殘差神經(jīng)網(wǎng)絡(luò),主要思想是在傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)中加入殘差學(xué)習(xí),這樣可以避免在網(wǎng)絡(luò)模型層數(shù)加深后出現(xiàn)學(xué)習(xí)退化問題。殘差網(wǎng)絡(luò)結(jié)構(gòu)的應(yīng)用,在避免上述問題出現(xiàn)的同時(shí)使得網(wǎng)絡(luò)系統(tǒng)性能得到一定提升。由此可見,ResNet-50 是一種簡單易用、性能優(yōu)化、內(nèi)部結(jié)構(gòu)提供更小卷積內(nèi)核的殘差學(xué)習(xí)網(wǎng)絡(luò)架構(gòu)。本文所用到的ResNet-50 的網(wǎng)絡(luò)結(jié)構(gòu)組成是通過49 個(gè)卷積層和1 個(gè)全連接層組成的。其中,從輸入到輸出分別由5 個(gè)階段組成,第1階段是對(duì)輸入的預(yù)處理操作,后4個(gè)階段是由結(jié)構(gòu)相似的Bottleneck 組成。第2 階段的Bottleneck數(shù)量是3 個(gè);第3 階段的Bottleneck 數(shù)量是4 個(gè);第4 階段的Bottleneck 數(shù)量是6 個(gè);第5 階段的Bottleneck數(shù)量是3個(gè)。
1.3 損失函數(shù)
了解語義關(guān)系,本文需要一個(gè)目標(biāo)來消除不同視角間的差距。因?yàn)樗峁┑臄?shù)據(jù)集為每個(gè)目標(biāo)地點(diǎn)提供了多個(gè)圖像,所以可以將每個(gè)地點(diǎn)視為一個(gè)類來訓(xùn)練分類模型。鑒于圖像語言雙向檢索的最新發(fā)展,采用一種稱為實(shí)例損失的分類損失進(jìn)行訓(xùn)練。其主要思想是共享分類器可以將獲取到的不同圖像映射到同一個(gè)共享特征空間。我們將xs、xd和xg表示為位置c的三個(gè)圖像,其中xs、xd和xg分別是衛(wèi)星視圖圖像、無人機(jī)視圖圖像和地面視圖圖像。給定來自兩個(gè)視圖的圖像對(duì){xs,xd},基本實(shí)例損失可以表述為
其中,Wshare是最后一個(gè)分類層的權(quán)重。p(c)是對(duì)c類的預(yù)測可能性。與傳統(tǒng)的分類損失不同,共享權(quán)重對(duì)高級(jí)特征提供了軟約束。其中,可以把W看作一個(gè)線性分類器。優(yōu)化后,不同的特征空間與分類空間對(duì)齊。在本文所研究內(nèi)容中,通過進(jìn)一步擴(kuò)展基本實(shí)例丟失處理不同來源的數(shù)據(jù)。例如,如果提供了一個(gè)以上的視圖,則只需要包括一個(gè)以上的條件項(xiàng):
1.4 基于分段組合的降維方案
分段組合降維是基于PCA(principal component analysis)完成的,包括了特征分段與特征組合兩部分。首先,通過對(duì)特征進(jìn)行劃分,可以得到若干特征子集,對(duì)若干特征子集分別進(jìn)行PCA 降維,最后將降維后的特征子集匯集到一起得到分段降維結(jié)果。然后,是特征組合,在特征分段部分設(shè)置不同的劃分維度,可以得到不同維度的特征子集,將這若干個(gè)不同維度的特征子集匯集到一起進(jìn)行二次降維,得到最終降維結(jié)果。PCA降維過程如下:
設(shè)查詢圖像經(jīng)過特征提取模型所得的特征維度為M維,數(shù)據(jù)可以表示為X=(X1,X2,…,XM),其中Xk是一個(gè)N*1維的列向量,則X是一個(gè)N*M的矩陣,降維后的低維度輸出是f(f<<M)。其主要步驟為如下幾個(gè)部分:
(1)去除平均值。
式中,i= 1,2,…,N;k= 1,2,…,M。
(2)計(jì)算原始數(shù)據(jù)集高維數(shù)據(jù)均值的標(biāo)準(zhǔn)矩陣。
(3)計(jì)算協(xié)方差矩陣。
(4)計(jì)算協(xié)方差矩陣的特征值λ1,λ2,…,λM,其中前一個(gè)λ取值是遠(yuǎn)大于后一個(gè)的取值,以及其對(duì)應(yīng)的特征向量a1,a2,…,aM,并且將求得的特征值進(jìn)行排序,依次是從大到小進(jìn)行排序,相對(duì)應(yīng)的特征向量也會(huì)隨著特征值的大小順序進(jìn)行依次排列;通過特征值的具體數(shù)值可以計(jì)算主成分所包含的貢獻(xiàn)率ηi和累計(jì)貢獻(xiàn)率ω。
(5)取最大的f個(gè)特征值(f<<M),將其對(duì)應(yīng)的特征向量a1,a2,…,af組成一個(gè)轉(zhuǎn)換矩陣B=[a1,a2,…,af],利用以下公式計(jì)算得到原始目標(biāo)檢測視圖數(shù)據(jù)X降至f維的數(shù)據(jù)Y。
通過以上變換之后,原始特征中的絕大部分信息都可以排在前面的數(shù)個(gè)主成分分量中,其他比較靠后分量所包含的信息基本就是噪聲,所以PCA算法在一定程度上也起到了降噪的作用。
2 實(shí)驗(yàn)分析
2.1 實(shí)驗(yàn)數(shù)據(jù)集
本文選用University-1652 數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),University-1652 數(shù)據(jù)集包含了72 所大學(xué)的1652座大學(xué)建筑作為目標(biāo),包含了無人機(jī)圖像、地面圖像以及衛(wèi)星圖像。其中,作者使用谷歌地球提供的3D 模型來模擬無人機(jī)相機(jī),通過改變視角來收集模擬圖像作為無人機(jī)圖像,通過Google 地圖來收集目標(biāo)建筑的街景圖像作為地面圖像。最后,每個(gè)目標(biāo)建筑平均有1張衛(wèi)星圖像、54張無人機(jī)圖像及3.38張真實(shí)街景圖像。選取其中1402 座具有完整數(shù)據(jù)的目標(biāo)建筑進(jìn)行實(shí)驗(yàn),將1402組圖像劃分為不重復(fù)的訓(xùn)練集和測試集,剩余250組圖像作為噪聲干擾輔助訓(xùn)練。
2.2 評(píng)價(jià)準(zhǔn)則
Recall@K 是對(duì)首個(gè)匹配圖位置敏感的評(píng)估協(xié)議,并可以使用到圖庫里只有一個(gè)真實(shí)匹配圖的測試集的情況。但是,在University-1652數(shù)據(jù)集中,圖庫有許多視點(diǎn)不一致的實(shí)際匹配圖像,使得Recall@K 無法準(zhǔn)確表示出其他地面圖像的匹配程度。所以,在Recall@K 的基礎(chǔ)上,也采用平均精度(AP)。平均精度(AP)實(shí)際上真正表示的是精度召回(PR)曲線下面的面積之和,能得到圖庫中所有地面的實(shí)際圖像。針對(duì)Recall@K,主要計(jì)算AP并給出所有查詢的平均AP的數(shù)值。在對(duì)University-1652數(shù)據(jù)集進(jìn)行PCA降維后,其主要的評(píng)價(jià)仍然考慮上述給出的幾個(gè)重點(diǎn)標(biāo)準(zhǔn),體現(xiàn)出對(duì)原始數(shù)據(jù)創(chuàng)新降維后各個(gè)評(píng)價(jià)的數(shù)值變化。
其中,AP(average precision)為平均精準(zhǔn)率,具體是(某一個(gè)類別)每個(gè)樣本的精確率求和/樣本總數(shù)N。
Recall@K 為預(yù)測正確的相關(guān)結(jié)果占所有相關(guān)結(jié)果的比例:
2.3 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)選取101張衛(wèi)星圖像作為目標(biāo)圖像,與衛(wèi)星圖像對(duì)應(yīng)的無人機(jī)圖像作為待匹配圖像,通過訓(xùn)練的特征模型得到整體特征分別用query_f 和gallery_f 來表示。其中目標(biāo)圖像的特征維度是101*512,待匹配圖像的特征維度是5022*512。設(shè)置分段降維實(shí)驗(yàn)以及分段組合降維實(shí)驗(yàn)來驗(yàn)證本文所提方法的有效性。
2.3.1 分段降維實(shí)驗(yàn)
通過對(duì)特征進(jìn)行劃分,可以得到若干特征子集,對(duì)若干特征子集分別進(jìn)行PCA 降維,最后將降維后的特征子集匯集到一起得到最終的特征降維結(jié)果。如圖2所示,實(shí)驗(yàn)分別選取劃分后特征子集維度為3、4、5、10、15、20、25、30、35、40、45、50 維進(jìn)行對(duì)比,評(píng)價(jià)指標(biāo)為AP 和Recall。以特征子集維度為3 維為例,是將原特征中相鄰的3 個(gè)維度降成1 維,并以類推,直至完成整體特征降維。未進(jìn)行降維時(shí),AP 為47.5%、Recall@1 為40.66%、Recall@5 為71.51%、Recall@10 為83.71%、Recall@top1 為52.55%。使用經(jīng)過降維后的特征進(jìn)行評(píng)價(jià)時(shí),指標(biāo)均優(yōu)于未降維的特征。其中,將特征劃分子集維度為20 維時(shí),效果能達(dá)到最好,其AP 為49.48%、Recall@1為42.81%、Recall@5為72.94%、Recall@10 為84.35%、Recall@top1 為54.62%。圖3、圖4 分別為不同分段數(shù)降維后的Recall@1和AP 評(píng)價(jià)結(jié)果,可以直觀看出將特征劃分子集維度為20維時(shí),效果能達(dá)到最好。

圖2 不同分段數(shù)降維后的整體評(píng)價(jià)結(jié)果

圖3 不同分段數(shù)降維后的Recall@1評(píng)價(jià)結(jié)果

圖4 不同分段數(shù)降維后的AP評(píng)價(jià)結(jié)果
2.3.2 分段組合降維實(shí)驗(yàn)
在上面分段降維實(shí)驗(yàn)的基礎(chǔ)上,再進(jìn)一步對(duì)不同維度的特征子集進(jìn)行整合降維。具體為,首先按照2.3.1 節(jié)描述,將整體特征劃分為子集維度為3、4、5的子集,分別對(duì)這三個(gè)維度的特征子集進(jìn)行降維,隨后三個(gè)降維后的特征子集匯合到一起進(jìn)行二次降維。本節(jié)實(shí)驗(yàn)選取了子集為3、4、5,20、25、30,25、30、35 和30、35、40 維度的特征子集進(jìn)行實(shí)驗(yàn),整體結(jié)果如圖5 所示,二次降維結(jié)果仍然比未降維特征要好,其中子集維度為3、4、5進(jìn)行二次降維的實(shí)驗(yàn)結(jié)果最優(yōu)。圖6為不同維度整合二次降維后的Recall@1 評(píng)價(jià)指標(biāo),從中可以看出經(jīng)過二次降維后Recall@1 的數(shù)值均高于分段降維的實(shí)驗(yàn)結(jié)果,其中子集維度為3、4、5 的Recall@1 值最高為44.92%。圖7 不同維度整合二次降維后的AP評(píng)價(jià)指標(biāo),從中可以看出經(jīng)過二次降維后AP的數(shù)值均高于分段降維的實(shí)驗(yàn)結(jié)果,其中子集維度為3、4、5 的AP 值最高為51.42%,達(dá)到了最高精度。
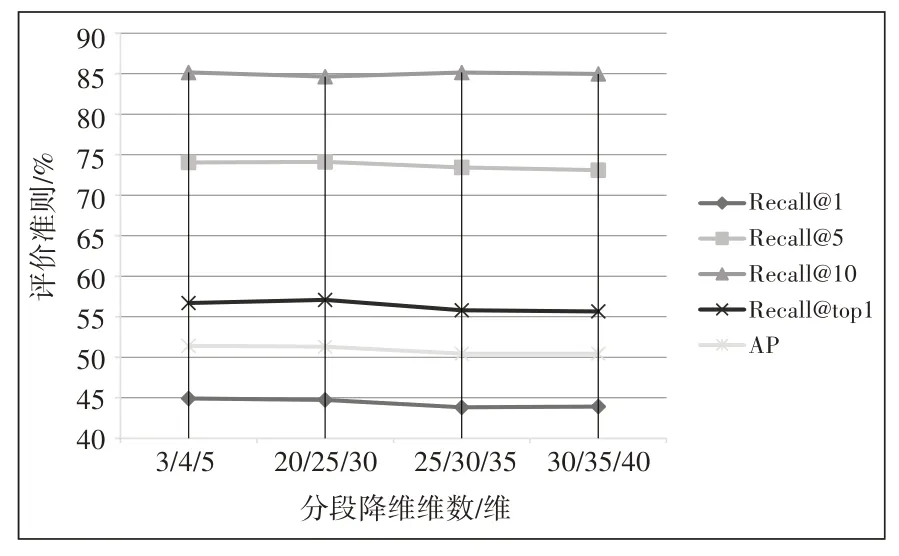
圖5 不同維度整合二次降維后的整體評(píng)價(jià)結(jié)果

圖6 不同維度整合二次降維后的Recall@1評(píng)價(jià)指標(biāo)

圖7 不同維度整合二次降維后的AP評(píng)價(jià)指標(biāo)
3 結(jié)語
針對(duì)交叉視角目標(biāo)定位任務(wù),本文首先通過Resnet-50 網(wǎng)絡(luò),并選取實(shí)例損失作為損失函數(shù),選取University-1652數(shù)據(jù)集的無人機(jī)圖像及衛(wèi)星圖像進(jìn)行訓(xùn)練得到特征提取模型。然后,圖像經(jīng)過特征提取后,本文提出了一種分段組合降維方案對(duì)圖像全局特征進(jìn)行降維,保留了特征的主要信息并降低了特征維度。實(shí)驗(yàn)表明分段降維后的AP 和Recall@1 對(duì)比原始特征進(jìn)行匹配分別提升了1.04 倍和1.05 倍。在分段組合降維對(duì)比原始特征匹配的AP 和Recall@1 分別提升了1.08 倍和1.1 倍。實(shí)驗(yàn)結(jié)果表明,通過分段組合降維方案能夠有效提高交叉視角目標(biāo)定位精度。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55

- 現(xiàn)代計(jì)算機(jī)的其它文章
- 無人智能物流小車控制系統(tǒng)設(shè)計(jì)
- 感知信息的反事實(shí)特征增強(qiáng)社交推薦
- 基于協(xié)同過濾算法的求職推薦系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
- 基于Docker容器的高并發(fā)Web系統(tǒng)架構(gòu)設(shè)計(jì)與實(shí)現(xiàn)
- 基于YOLOv5的智能果蔬識(shí)別與成熟果蔬計(jì)數(shù)系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
- 基于BIM技術(shù)的設(shè)計(jì)項(xiàng)目多源數(shù)據(jù)挖掘融合協(xié)同化設(shè)計(jì)平臺(tái)