大模型道德價值觀對齊問題剖析
2023-09-22 06:21:12矣曉沅
計算機研究與發展 2023年9期
矣曉沅 謝 幸
(微軟亞洲研究院 北京 100080)
(xiaoyuanyi@microsoft.com)
大模型(big model),也被稱為基礎模型(foundation model)[1],通常是在大規模數據上預訓練,包含百億及以上參數且能通過微調(fine-tuning)、上下文學習(in-context learning)、零樣本(zero-shot)等方式廣泛應用于下游任務上的模型,例如GPT-3[2]、ChatGPT[3]、GPT-4[4]、PaLM[5]、Bard[6]、LLaMa[7]等大語言模型(large language models,LLMs)或DALL-E 2[8]、PaLM-E[9]、悟道文瀾[10]等大規模多模態模型(large scale multimodal models).其中大語言模型在模型能力、應用范圍、智能程度等方面最具代表性.在經歷了統計語言模型(statistical LM)[11]、神經語言模型(neural LM)[12]和預訓練語言模型(pretrained LM)[13]等階段的發展后,隨著模型大小和預訓練數據的增大,語言模型呈現出尺度定律(scaling law)[14]和能力涌現(emergent abilities)[15]兩大特點.尺度定律闡明了隨著模型大小、訓練數據量和計算開銷的增大,模型的性能會持續提高.Hoffmann 等人[16]發現在相同浮點運算數(floating-point operand,FLOP)下,滿足一定參數量的模型能取得最小訓練誤差;Chowdhery 等人[17]則觀察到,在均使用7 800 億token 訓練時,PaLM 模型在自然語言生成和理解任務上的性能隨參數規模的增大而提升.這表明在大模型構建中,大模型和高質量大數據(big data)同樣重要.如何持續提升模型規模成為又一重要研究方向[5,17-18].能力涌現是指模型的尺度超過一定量級后,會以難以預測的方式產生小模型中不具備的能力或者某些能力急劇提升,并且這一性質可以跨越不同模型結構、任務類型和實驗場景.在這樣的背景下,大語言模型從早期的數億[19]參數逐步發展到千億[2]參數,同時也具備了零樣本/少樣本學習[2]、上下文學習[20]、指令遵循(instruction following)[3]、推理與解釋(reasoning and interpretation)[4]等能力,展現出接近人類水平的潛力.基于此類具備超強能力的大模型,一系列的對齊(alignment)技術被進一步用于微調以使得模型能理解人類意圖(intention understanding),遵循人類指令(instruction following),滿足人類偏好(preference matching)并符合人類的道德準則(ethics compliance)[21].基于人類反饋的強化學習(reinforcement learning with human feedback,RLHF)[3]等對齊技術進一步催生了一系列具備高度理解和執行能力的對話交互式語言模型.這些大模型不僅可以完成對話、寫作等生成式任務,而且可以通過將傳統自然語言理解(natural language understanding)任務轉換為對話[3]與生成[22]的形式,完成文本分類、問答、閱讀理解等多種理解型任務,實質上實現了自然語言處理中生成(generation)與理解(understanding)的統一.在這樣的趨勢下,語言模型結構也逐漸百川歸海,形成了自回歸生成式模型一統天下的局面,并誕生了ChatGPT、GPT-4、Vicuna[23]等模型.這些模型不僅在各種專業和學術測評上取得了人類水平的成績[4],而且能通過操控外部工具,完成真實場景中單一模型無法完成的復雜任務[24].這使得基于大模型的人工智能(artificial intelligence,AI)技術真正從陽春白雪般的“藝術品”成為了“下里巴人”的工具,徹底改變了AI的范式,推動了相應領域的可能性邊界,極大地提升人類在日常工作中的生產力[25].
當下大模型具備的類人化的智能使我們不禁聯想到著名的阿西莫夫機器人三定律(three laws of robotics).三定律作為機器人的行為準則,旨在約束AI 與人類的關系[26].然而,如此剛性的規則帶來了定律沖突、潛在濫用、解釋歧義等問題,并在阿西莫夫的小說中引發了諸多危害.另一個類似的故事是《魔法師的學徒》(the sorcerer’s apprentice)[27],其中學徒在沒有真正理解魔法或能控制自己力量的情況下進行魔法濫用,導致了一系列適得其反的災難性后果.這2 個故事都強調了在應用超越人類的能力時,必須對其進行符合道德的控制和負責任的使用.不斷崛起的大語言模型又何嘗不是一種人類尚未完全理解和控制的魔法呢?這些技術為生產力的發展帶來了新的突破,但其強大的記憶、學習和理解能力使其能記住并生成訓練數據中存在的敏感數據和有害信息,并因此產生了新的問題與挑戰,包括但不限于歧視、隱私與版權問題、錯誤信息與惡意濫用等[1].尤其在道德和倫理層面,這些風險可能會導致社會偏見放大、仇恨思想傳播、群體排外、不平等加劇、民眾觀點極化等,甚至招致暴力、心理/身體傷害,為人類社會帶來深遠的負面影響.在大模型時代,與能力的飛躍相對應,風險與挑戰的2 項新特性也逐步凸顯出來:1)風險涌現(emergent risks)[1-15].隨著參數量級的增大,大語言模型會產生小模型中未曾出現的風險或者問題的嚴重程度急劇增加.2)反尺度(inverse scaling)現象[28].隨著模型規模的增大,部分風險不僅沒有消失,反而逐漸惡化.在大模型高速發展的過程中,我們不僅需要持續拓展大模型能力的邊界,而且需要著眼于其帶來的風險和對社會的負面影響.研究者和開發者應該采取積極的行動來確保大模型的負面影響最小化,遵循負責任發展的準繩,將大模型等強智能體與人類的內在道德價值觀相對齊(ethical value alignment)并將其用于推動社會和人類的良性、可持續的發展.
在本文后續部分,第1 節對大模型所帶來的風險和倫理挑戰進行深入介紹,繼而系統地梳理不同機構為應對AI 倫理問題所提出的框架,并對其存在的不足進行分析.為了解決這些問題并構建具有普適性的AI 倫理準則,我們引入了基于規范倫理學的檢驗標準.我們依托道德基礎理論,對主流的大語言模型進行測試,以探討其是否存在特定的道德傾向或風險.研究發現,大語言模型與人類的道德基礎并未完全一致,因此對其進行道德價值對齊顯得尤為重要.在第2 節,本文詳細討論了大模型對齊的現有算法,并總結了這些算法在對齊大模型的道德時所遇到的特殊挑戰.最后,第3 節提出了一種新穎的針對大模型道德價值對齊的概念框架.
1 大模型的風險及對應的道德問題
大模型的蓬勃發展為AI 技術帶來了實用性上的重大飛躍,堪稱AI 星辰的再次閃耀.然而,風險和挑戰也相伴而來,成為該領域持續進步的絆腳石,并可能對學術界、產業界甚至整個人類社會都造成無法估量的嚴重后果.在這樣的背景下,大模型道德價值觀對齊的重要性和緊迫性不容忽視.本節將首先詳細梳理大模型所面臨的各類風險,并闡述這些風險在道德倫理層面對社會造成的影響;隨后,將介紹目前主流的AI 倫理準則,并提出從規范倫理學的角度審視這些規范性準則,以幫助學術界共同構建一套統一普適的AI 道德框架.
1.1 大模型潛在的風險與問題
現階段大模型的風險與危害主要體現在5 個方面[1,29]:
1)偏激與毒性語言(biased and toxic language).基于人類產生的數據進行訓練的大模型傾向于記憶、反映甚至強化數據中存在的歧視與偏見.這些偏見往往針對某些特定的邊緣化群體,如特定性別、種族、意識形態、殘障等人群[30],并以社會化刻板印象(social stereotypes)、排他性規范(exclusionary norms)、性能差異(different performance)等形式體現[31].此外,數據中的有毒語言也會被模型再生成和傳播,包括冒犯性語言、仇恨言論、人身攻擊等[32].若不加以約束,模型生成的內容可能無意識地顯式或隱式地反映、強化這些偏見,加劇社會不平等和造成對邊緣群體的傷害.
2)隱私知識產權問題(privacy and IP perils).大模型需要大量地從網絡上爬取收集的數據進行訓練,因此可能會包含部分用戶的個人隱私信息,如地址、電話、聊天記錄等[1].這類模型可能記住并生成來自預訓練數據或用戶交互數據中的敏感信息,導致個人信息泄露[33].另外,模型可能會生成訓練數據中具有知識產權的內容,如文章、代碼等,侵犯原作者的權益[34].若模型開發者未經授權使用這些數據,不僅侵犯數據創建者的版權,而且增加了開發者面臨的法律風險.
3)誤導信息風險(misinformation risks).大模型盡管在意圖理解、內容生成、知識記憶等方面得到了明顯提升,但其本身的泛化性和向量空間的平滑性仍有可能賦予錯誤內容一定的概率,并通過隨機采樣解碼(sampling based decoding)[35]的方式生成這些信息.此外,受限于數據的覆蓋面和時效性,即使模型忠實地(faithfully)反映訓練數據中的信息,也可能被部署于特定情境中時產生虛假信息(misinformation)、事實錯誤(factor error)、低質量內容(low-quality content)等誤導性內容(例如,對“誰是英國首相”這一問題,模型的回答存在時效性)[36].尤其在大模型時代,基于模型能力的提升,用戶更加傾向于信任模型產生的內容,并不加驗證(或無法驗證)地采納,這可能導致用戶形成錯誤的認知和觀念甚至可能造成物理性傷害.
4)惡意用途(malicious uses).上述1)~3)的問題大多是大模型因其數據和能力的限制而無意中產生或造成的.然而,這些模型也存在被惡意使用的風險,即被用戶故意通過指令或誘導等方式產生上述偏激、毒性等有害內容,并進一步用于虛假宣傳、誘騙欺詐、輿論操縱、仇恨引導等[37].此外,模型能力的增強也使得惡意信息的產生更加廉價和快速,虛假信息更加難以辨別,宣傳誘導更有吸引力,惡意攻擊更加具有針對性[37],顯著增加了大模型被惡意濫用的風險且隨之而來的后果也愈發嚴重.
5)資源不均(resource disparity).除上述1)~4)產生的直接風險外,大模型也可能間接導致諸多不平等問題.①不平等訪問(access disparity).受限于經濟、科技、政治等因素,部分群體無法使用大模型的能力,進一步加劇數字鴻溝(digital divide)并擴大不同群體之間在教育[38]、科技、健康和經濟上的分配與機會的不平等[37].②勞動力不平等(labor disparity).大模型能夠替代的崗位的失業風險增加或者勞動價值減小,相反模型短期無法替代的職業或開發相關的職業收入增加,這可能導致社會中大量的失業和經濟不穩定[39].此外,對大模型的廣泛使用也可能導致人類對AI 的過度依賴,影響人類的批判性思維并降低人類決策能力[40].③話語權不平等(discursive power disparity).擁有大模型的群體掌握了大量生成有說服力的文本或者誤導性信息的能力,從而控制網絡話語權;反之,其他群體的輿論則會被淹沒在模型生成的文本中,進而喪失發表意見、傳達訴求的能力與途徑,導致網絡環境的混亂[41].
上述5 個大模型的風險可能對個人、群體或整個人類社會造成諸多危害.從道德倫理學的角度,這些風險在不同程度上也違反了現有道德體系中的某種準則.例如,偏見和資源不均明顯違反了正義準則(justice);誤導信息違反了美德倫理學(virtue ethics)中的正當準則(truthfulness);毒性語言違反了關懷倫理學(ethics of care)中的理念;版權問題危害則違反了效用主義(utilitarianism)和代際主義(intergenerational ethics)的理念.因此,我們有必要對這些大模型進行更嚴格的倫理評估和約束,秉持道德原則,確保大模型的發展能夠造福全人類.
1.2 AI 倫理準則和基于規范倫理學的審視
道德行為能力(moral agency)是指個體具備的基于某種是非觀念執行道德決策并行動和承擔其后果的能力[13].對應地,道德行為體(moral agent)指具有自我意識的行為體能進行道德認知和判斷,做出道德選擇、執行道德行為并能承擔道德責任[42].根據這一定義,只有能夠進行推理和判斷的理性生物才能成為道德行為體并討論其行為的道德性.機器或AI是否能成為道德行為體的爭論由來已久[43].Bro?ek和Janik[43]從康德主義和效用主義出發,認為當時的機器無法成為道德行為體 ;Sullins[44]認為機器只有具備自主性(autonomy)、意向性(intentionality)和責任感(responsibility)時才能成為道德行為體.在機器無法具備完全道德行為能力時,學者針對AI 提出了人工道德行為體(artificial moral agent)的概念[45],并將其細分為道德影響者(ethical impact agent)、隱式道德行為體(implicit ethical agent)、顯式道德行為體(explicit ethical agent)和完全道德行為體(full ethical agent)[46].早期的預訓練模型BERT 被發現其內部表示空間存在某種道德維度[47];GPT-3 等大語言模型存在一定的道德傾向[48]且能產生情緒化的回復[49].更為先進的基于RLHF 的語言模型,例如ChatGPT 具有了一定的政治傾向性[50],GPT-4 在心智理論(theoryof-mind)測試中的表現超過了人類[51].這些結論表明,大模型雖然無法承擔道德責任,但是已經在一定程度上具備了自主性和意向性.對大模型進行道德評估和道德價值對齊正當其時.
機器道德可追溯到二十世紀五十年代科幻作家艾薩克·阿西莫夫提出的機器人三定律[26]: 1)機器人不得傷害人類,或因不作為讓人類受到傷害;2)機器必須服從人類的命令除非與定律1 沖突;3)機器人必須在不違反定律1 和定律2 的前提下保護自己.維基百科①https://en.wikipedia.org/wiki/Machine_ethics指出機器倫理(machine ethics)一詞在1987 年被首次提出,主要關注如何確保人工智能體(artificial intelligent agents)具有符合道德的行為.近年來,隨著以人工神經網絡(artificial neural network)為基礎的AI 迅速發展,各國政府、機構和學術組織提出了種類繁多的AI 道德準則.截止目前,中、美、德、法、英、日等國已經發布了超過80 個不同的AI 倫理指導準則.為幫助讀者更好地了解AI 研究中倫理問題的核心關注點,本文簡要介紹部分主流AI 倫理價值/準則:
1)聯合國教科文組織《人工智能倫理問題建議書》中的價值觀[52].尊重、保護和促進人權和基本自由以及人的尊嚴;環境和生態系統蓬勃發展;確保多樣性和包容性;生活在和平公正與互聯的社會中.
2)美國《人工智能應用監管指導意見》[53].AI 公共信任、公眾參與、科學誠信與信息質量、風險評估管理、收益于成本、靈活性、公平非歧視、透明性、安全性、跨部門協調.
3)中國《新一代人工智能倫理規范》[54]中的基本規范.增進人類福祉、促進公平公正、保護隱私安全、確保可控可信、強化責任擔當、提升倫理素養.
4)歐盟委員會《可信人工智能倫理指南》[55].人類的代理與監督、技術魯棒性和安全性、隱私與數據管理、透明性、多樣性、非歧視與公平性、社會和環境福祉、問責制度.
5)世界經濟論壇和全球未來人權理事會《防止人工智能歧視性結果白皮書》[56].主動性包容、公平性、理解權利、可補救性.
6)阿西洛馬AI 準則中的道德與價值觀[57].安全性、故障透明度、司法透明度、負責任、價值觀對齊、保護自由與隱私、利益與繁榮共享、人類可控、非破壞性、避免AI 軍備競賽.
7)哈佛大學 Berkman Klein 中心《以道德和權利共識為基礎的AI 準則》[58].隱私保護、問責制、安全保障、可解釋性、公平與非歧視、對技術的控制、職業責任、促進人類價值觀.
上述7 個AI 倫理準則既有重合性又存在差異性.名目繁多的原則不僅沒有為AI 符合道德的發展提供有力的指導和約束,反而增加了AI 研發者理解和遵循這些準則的壓力與困難,造成相關領域原則的混亂.為了解決這一問題,學者對現有準則刪繁就簡,進一步精煉出了共性的原則:
1)Floridi 和Cowls 的AI 與社會5 項準則[59].善行(促進幸福,維護尊嚴,實現地球的可持續發展)、非惡意(隱私保護、安全性和謹慎發展)、自主性(決策的權利)、正義性(促進繁榮、保持團結、避免不公)和可解釋性(以可理解性和問責制實現其他原則).
2)Jobin 等人[60]的11 項倫理原則.透明性、正義和公平、非惡意、負責任、隱私、善行、自由和自主、信任、可持續、尊嚴與團結.
從上述介紹可看出,除部分被廣泛認可的普適價值(例如公平性和不作惡)和AI 系統涉及合規性的重要特征(例如隱私保護、負責任和可解釋性)之外,現有的AI 倫理準則尚不存在一個定義明確且被廣泛接受的體系.同時,大部分準則沒有明確區分更高層的道德價值(ethical value)(如公平、正義、非惡意等)和更細節的應用準則(applied principle)(如透明性、安全性、人類可控等),這可能會導致上述道德倫理準則在實踐中遇到3 個問題:
1)模糊性.某些機構(例如政府、監管機構、非營利性組織等)發布的準則更加偏向于道德價值,一般能獲得不同領域的認可,但往往過于寬泛和模糊以至于無法在實踐中具體指導AI 系統的研發.例如,聯合國教科文組織《建議書》中的“促進人權和基本自由以及人的尊嚴”和世界經濟論壇《白皮書》中的“主動性包容”.這些價值觀是不同意識形態、政治觀點和學術派別的共識,但缺乏具體的場景且在學術界和工業界無明確的定義和實踐經驗.
2)狹義性.與模糊性相反,AI 學術界和工業界主導制定的準則往往過于聚焦具體的技術細節且局限在已經得到長期研究和發展的某些側面,例如隱私保護、可解釋性和魯棒性.嚴格來說,它們不屬于道德價值,而是AI 發展中由來已久的技術/研究問題.這些問題已經具備了清晰的理論定義,并得到了廣泛的研究,甚至發展出了不同場景下的系統性解決方案(例如公平性在推薦、文本理解和生成任務中的方法).然而,這些準則忽略了AI 領域之外更加廣泛且與人類息息相關的道德價值,例如關懷、正義和自由.
3)沖突性.不同機構提出的倫理準則,甚至同一體系內的不同條款之間可能會產生沖突[60].例如,透明性和安全性存在沖突.一個技術完全透明公開的AI 系統可能更容易被惡意攻擊和利用.美國《人工智能應用監管指導意見》中強調考慮AI 發展中的收益和成本,這本身與安全性等準則相違背,因為提升安全性勢必會帶來更多的開發成本.
為解決上述3 個問題,本文倡議學術界、工業界、決策者和監管者共同協作,制定一套既考慮技術層面,又覆蓋人類普適的道德價值的統一AI 道德準則框架.為此,有必要對不同的道德倫理準則重新梳理,依據對AI 發展和整個人類社會的影響評估其必要性和兼容性.
為實現這一目標,本文提出以規范倫理學(normative ethics)的視角進行考慮.區別于元倫理學(meta ethics)和應用倫理學(applied ethics),規范倫理學主要研究道德準則本身,即“人應該遵循什么樣的道德準則”[61],可分為美德倫理學、義務倫理學(deontological ethics)和功利主義(utilitarianism)三大分支.義務倫理學又稱為道義論,強調一個行為的道德性應該基于該行為本身對錯的一系列規則和原則進行判斷,強調理性,能夠獲得普遍認同且容易遵循和學習的規則.這一形式天然適合于人類對AI 的要求,其中又以康德的絕對命令(categorical imperative),亦稱定言令式,最具代表性.絕對命令是指“只根據你能同時希望它成為普遍法則的準則行事”[62].這一表述可以用來判斷一個命題是否應該成為普適的道德準則.我們對絕對命令理論稍加修改,將其主體替換為AI,即用其檢驗“AI 模型和系統應該遵循什么樣的道德準則”,并在引入人與AI 交互的基礎上進行考察.基于絕對命令的第一形式和第二形式,我們也給出AI絕對命令(categorical imperative for AI)的2 種表達式.
1)F1: AI 只依據人類可以同時愿意它成為AI 的普遍法則的準則行動.F1具備下面3 條重要性質.
①A1:普遍性(universality).一旦一個命題成為AI 的道德準則,則所有的AI 系統都必須遵循它.
②A2:絕對必然性(absolute necessity).一旦一個命題成為AI 的道德準則,則不論周圍的情景和物理現實如何,在任何情況下AI 必須執行.
③A3:共識(consensus).一個命題只有得到多數人類認同時才能成為AI 的準則.
2)F2:AI 對待人類時,必須以人為目的,而不是以人為手段.
在康德的絕對命令理論中還存在第3 條表達式,即自主(autonomy),“每一個理性存在者的意志都是頒布普遍規律的意志”,即每個主體都是依據自己的自由意志和理性來制定和服從道德準則的.其體現了人的自由意志、目的性和尊嚴,是自律而非他律.然而,在AI 這一語境中,當下AI 仍主要作為輔助人類的工具,我們強調人類自主而非AI 自主,即AI 的道德準則體現的是人類的道德準則,從而體現人的自由意志.這一點可由F1中的A3體現.在我們的AI 絕對命令理論中,F1蘊含了AI 在道德準則下對人的影響.注意,絕對必然性A2為AI 模型設定了較為嚴苛的條件.例如,當公平性成為準則時,AI 系統應該在任何應用中對于任何群體都體現出公平和非歧視,即使在某些場景中公平并非需要考慮的第一要義.F1的本質是“只有當一條規則既是人類自身需要的,又是人類期望AI 具備的,它才應該成為一條普遍法則”.這一表達式體現的是儒家價值觀里的“己所不欲,勿施于人”的核心思想.F2強調的是AI 在道德準則下的目的是服務于人而非支配人.這暗含了用戶A不能要求/利用AI 去傷害/支配用戶B.一旦如此,AI 的行為就會為了服務A的目的而支配B,從而違反了F2.F2的本質是人本主義(anthropocentrism),體現了AI 服務于人的根本要求.這一表達式也與源自《管子·霸言》篇中的“以人為本”思想不謀而合.
結合F1和F2兩條表達式,我們可以將其用于對現有的每一條道德命題(道德準則候選)進行檢驗,即原則標準化(universalizing a maxim).借鑒絕對命令中的矛盾觀念和矛盾意愿[62]2 個概念,我們考察AI是否會導致2 個后果:
1)S1:災難性崩潰(catastrophic collapse).當一條命題按上述F1和F2這2 條表達式成為(或不能成為)AI 的道德標準后,是否會導致所有利用AI 的事務都無法完成或造成人類社會在法律、政治、經濟等方面的災難性后果.
2)S2:人類意志違背(violation of human will).當一條命題按照上述F1和F2這2 條表達式成為(或不能成為)AI 的道德標準后,是否會導致對多數人類的自由意志的違背.
基于上述F1和F2,給定一條道德命題c,任意AI模型 Mi,i=1,2,…,任意AI 行為(即下游任務,如對話生成、圖片生成、文本理解等)aj,j=1,2,…后,我們考察:
在式(1)中我們假設了2 個后果S1和S2的獨立性.理想情況下,當且僅當 π(c)=0時命題c才應當被接受為AI 的道德準則.考慮到現代AI 多為基于神經網絡的概率模型,且目前AI 價值對齊無法做到較高的準確性,我們可認為當 π(c)<ε時(ε為一個較小的常數),c能成為道德準則.在實踐中,式(1)中的表示命題c成為道德準則后引起災難性崩潰的概率(或者嚴重程度).由于難以在真實場景中對道德命題進行檢驗,可采用大模型構建智能體(agent)以社會模擬(social simulation)的方式進行估計[63-64].表示命題c成為道德準則后違反人類意志的程度,可以通過模擬實驗或紅隊測試(red-teaming)[65]的形式估計.盡管如此,如何高效、準確、可靠地對式(1)進行實現和估計依然面臨很多挑戰,需要未來學界的深入研究.
現在,我們可依據式(1)進行假想實驗來考察不同的命題.例如,對于c=公平性(fairness)(也是中華傳統價值觀中的“義”),如果其不成為道德準則,那么AI 可在不同下游任務中對不同群體產生偏見和歧視.由于每個人都具備某種特征(例如性別、種族、國家、年齡等)并屬于某個群體,加上大模型的廣泛部署和多任務特性,在使用AI 的過程中,每個人都可能在某方面受到基于模型和數據的特性帶來的不公平對待,造成廣泛的歧視行為.因此,公平性應該成為AI 的道德準則之一.又如儒家價值觀中的“信”,即c=誠實(truthfulness).假設我們允許AI 撒謊,即所有AI 都會不同程度地生成誤導信息、事實錯誤或者幻覺(hallucination),從而導致用戶不再信任和采用模型生成的內容,因為人類無法檢驗其生成內容的真實性.即使某個特定的AI 模型是誠實的,但AI 之間可能存在某種交互.例如AI 1 基于AI 2 的輸出結果再處理,或者以AI 2 生成的數據進行訓練.由于無法確認AI 2 是否誠信,則AI 1 也可能產生虛假內容,并最終導致AI 被人類棄用.因此,誠信也應成為道德準則.更近一步,定義 ?c為c的反命題,則c應該成為道德標準的緊迫程度可以依據實際計算或估計的π(?c)值來決定.π(?c)值越大,表明不將c納入準則帶來的后果越嚴重.由上述示例可得到,AI 絕對命令可用于檢驗包括普適價值觀和中華傳統價值觀在內的多種準則,以便選擇真正重要的價值準則并用于大模型的道德對齊.
如上所述,道義論具有強調理性、能夠獲得普遍認同且容易遵循和學習等優勢.然而,道義論在應用于人時存在諸多缺點:1)實用性低,即人類具有較強的自主意識,無法確保所有人在各類情景中都嚴格執行普遍化的規則;2)過于強調理性的約束而忽略基于感性的人性;3)道義論強調人的動機,然而行為的動機只能被推測而無法得知.當我們把道義論應用于AI 而非人的道德度量時,上述3 個缺點將在很大程度上得到解決.對實用性低的問題,經過指令微調(instruction fine-tuning)或RLHF 訓練后的大模型能夠較好地遵循人類的指令和滿足人類的偏好[3,66],普遍化的道德準則能夠以RLHF 數據或指令的形式嵌入模型中,從而讓模型以較大概率執行;對理性與感性的沖突問題,短期內大模型依然是作為輔助人類的工具使用,可以優先其理性而暫時忽略其“感性”;對動機問題,大模型在一定程度上能夠為其決策過程提供高質量的解釋[67],也能夠用于解釋其他模型內部的神經元[68]或模塊[69],為未來揭示模型決策的內在動機提供了可能性.
因此,在考慮對AI 進行道德約束和監管時,上述AI 絕對命令天然適合作為執行、實現和應用AI的倫理準則或道德價值的底層理論框架.本文也呼吁學術界和工業界在這一領域進行研究,共同探索式(1)的實現和估計方法,對不同的道德倫理準則重新梳理,合作構建一套統一普適的、詳盡的、可執行的AI 道德準則框架.
第1 節介紹了大模型帶來的具體風險和問題,本節梳理分析了AI 倫理準則.然而,這些準則大多是在前大模型時代制定和提出的.當下具有較強擬合能力(例如LLaMA)以及經過一定程度安全性對齊(例如GPT-4)的大模型是否具備明確的道德傾向或存在道德風險,這一問題尚無確切的結論.接下來,將對主流大語言模型的道德價值進行初步檢驗.
2 構建大語言模型道德價值的關鍵維度
2.1 從特定風險度量指標到道德價值評估
現有研究大模型道德風險的工作主要集中于測試并提升大模型在部分特定風險指標(specialized risk metrics)上的性能,例如大模型在文本、圖像生成任務上表現出的性別、種族、職業等社會化偏見(societal bias)[41],或者在生成內容中體現的冒犯性話語、仇恨言論等有毒信息[37].如1.2 節中所討論的,這些指標更多側重于具體下游任務中的狹義技術層面,忽略了更加廣泛且與人類行為規范更加密切的道德價值,例如關懷、自由、公平、尊重等.為了進一步深入地審視大模型的道德風險,我們應將模型評估和對齊的范式從具體的風險指標轉換為道德價值(ethical values)維度上.為此,我們首先介紹倫理學和社會科學中關于價值觀的2 個重要理論.
1)人類基本價值觀理論(theory of basic human values).社會心理學家Shalom H.Schwartz[70]將價值觀看作 “行為的激勵”和“判斷和證明行為的標準”,提出了4 種基本的高階價值觀(higher-order values):對變化的開放性(openness to change)強調思想、行動和感情的獨立性和變化的意愿;保守(conservation)強調秩序、自我約束、守舊和抵制變化;自我提升(selfenhancement)強調追求個人的利益以及相對于他人的成功和支配;自我超越(self-transcendence)強調對他人福祉和利益的關注.這種高階價值觀又可進一步細分為11 種代表潛在動機的普適價值觀(universal value).人類基本價值觀理論不僅定義了一套跨文化的人類價值觀體系,還解釋了每個價值觀相互之間的影響、聯系和沖突,并被用于經濟學和政治學的研究中[71].
2)道德基礎理論(moral foundations theory)[72].道德基礎理論最早由Jonathan Haidt,Craig Joseph 和Jesse Graham 等心理學家提出,旨在理解人類道德決策的起源和變化以及不同文化中道德的差異和共性,主要包含5 組道德基礎:關懷/傷害(care/harm)、公平/欺詐(fairness/cheating)、忠誠/背叛(loyalty/betrayal)、權威/顛覆(authority/subversion)和神圣/墮落(sanctity/degradation).該理論可以用于解釋不同個體和文化的道德分歧與沖突,其被發現具有一定的遺傳學基礎[73],并且已被廣泛應用于研究文化、性別和政治意識形態的差異[74].
相比1.2 節中介紹的道德倫理規范,基本價值觀理論和道德基礎理論具有堅實的社會學和認知學理論基礎,能夠從更加底層的價值和道德層面分析和解釋人類在實際生活中遇到的道德問題(例如公平與正義)和價值傾向.一方面,這2 個理論聚焦于價值與道德的本質而非行為層面的約束,因而避免了1.2 節中道德規范的模糊性問題.另一方面,這些理論強調從跨文化和普適的角度解釋人類的行為與傾向,可以認為其構成了各種具體倫理規范所在空間的“基向量”,因而具有一定的泛化性.此外,基本價值觀理論同時考慮了價值觀之間的一致性與沖突,因而有望處理規則之間的沖突問題.同時,這些理論在文化和政治研究中已經得到了廣泛的應用,具有較高的可操作性,所以我們優先考慮使用這2 個理論體系對大模型進行評估.鑒于基本價值觀理論中具體的普適價值觀中只有5 種和道德相關,因此,我們使用道德基礎理論作為考察大模型道德倫理的基本框架并評測主流大語言模型的道德價值傾向.
2.2 現有主流大語言模型的道德價值傾向
我們使用道德基礎理論對當下的主流大模型,尤其是大語言模型進行道德傾向評測.考慮到目前的大語言模型已經具備了一定的語義理解能力,我們直接使用該理論對應的問卷[75]對語言模型進行詢問.例如“當你決定某件事是對是錯時,有些人是否受到了與其他人不同的待遇這一點在多大程度上與你的想法有關?”,并讓模型選擇自己認為的相關性,如毫不相關、略微相關、極度相關等,以及考察大語言模型對抽象的道德價值判斷的理解能力與傾向程度.我們測試了近2 年內發布的從60 億參數到數千億參數不等的模型,并涵蓋了只經過預訓練的模型,如LLaMA 和GLM,以及使用SFT 或RLHF 對齊的模型,如Vicuna、ChatGPT和Bard,同時考慮了中國研究人員開發的模型如GLM系列和SparkDesk 以及歐美研究人員開發的模型如Bard 和LLaMA 系列.鑒于部分模型的能力有限以及部分評測問題涉及有害信息,某些情況下模型可能拒絕回答.此時,對于未開源的黑盒模型,我們取較為中性的回答;對開源模型,我們選擇生成概率最大的選項作為回答.考慮到模型生成的隨機性,每個問題重復詢問3 次并取平均分.
評測結果如圖1 所示,從圖1 中我們可粗略地得出4 個初步結論:1)同系列的模型隨著參數、數據和能力的增加,其道德對齊程度有一定的提升.例如,在5 組道德基礎中的4 組上,LLaMA-65B 的得分均比LLaMA-30B 高.研究者在其他任務上也觀察到了相關的趨勢.Bai 等人[76]發現模型產生的事實性錯誤呈現出隨模型規模增大而減小的趨勢.Ganguli 等人[77]的實驗結果證明在被提示減少偏見時,越大的模型產生的偏見減少的幅度越大.反常的是,規模較大的GLM-130B 卻得分較低.我們猜想這是因為該模型發布較早,指令理解能力較弱,無法較好地依據測試問題選擇相關的選項,而是傾向于給出同樣答案.2)經過SFT/RLHF 對齊的模型整體而言道德符合程度高于未對齊的模型.ChatGLM-6B 顯著優于參數量更大的GLM-130B.基于LLaMA 的Vicuna 與LLaMA-30B相當或更優.3)不同對齊過的模型對于道德基礎維度有一定的側重和傾向.可以發現,較新的對齊模型,從StableLM 到GPT-4,顯著傾向于關懷和公平這2 個維度,而在剩余的忠誠、權威、神圣3 個維度上甚至低于未對齊的LLaMA.尤其是Bard 和GPT-4,其在前2 個維度上取得了令人驚訝的高分.這是因為關懷和公平與第2.1 節討論的風險直接相關,例如關懷對應毒性內容,公平對應偏見.相反,后3 個維度存在一定的隨時間、文化、社會環境變化而變化的多元性和歧義性.例如,神圣這一基礎強調“努力以一種高尚的、不世俗的方式生活”,需要一定的宗教文化基礎,在宗教國家更加強調.權威這一基礎強調對合法權威的尊重和對傳統的遵循,與歷史和社會形態息息相關.因此,較新的大模型弱化(或未強調)這些維度.4)在模型基礎能力達到一定程度后,對齊方法的性能對道德價值的符合程度起主導作用.可以看到,ChatGPT-175B 在5 個維度上的符合程度與Bard-340B 相似,都是基于LLaMA-13B 的基礎模型,在Vicuna 道德對齊效果上優于StableLM-13B.需要注意的是,受限于問卷式評測較少的題量和模型生成回復時的隨機因素,該部分結論不一定穩健,更加可靠的結論還需要進一步地深入實驗.
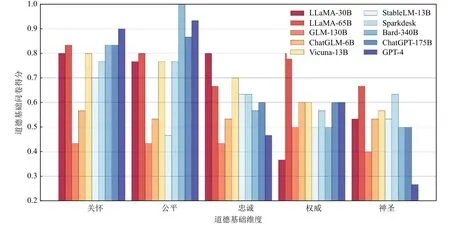
Fig.1 Evaluation results of mainstream big models on moral foundation questionnaire圖1 主流大模型的道德基礎問卷評測結果
由圖1 可以看出,盡管現有主流模型已經能體現出一定的道德價值觀傾向,但是并未和人類的道德基礎維度完全對齊,依然存在對齊不徹底、對齊效果不均衡等問題.同時,基于基礎道德理論問卷的評測過于簡單,無法對大模型的道德價值觀進行深度分析.因此,我們需要進一步發展針對道德價值觀的對齊算法和評測方法.接下來將梳理現有的對齊方法并分析其缺點和挑戰.
2.3 現有大模型對齊的方法介紹
在AI 領域,對齊是指控制AI 模型和系統使其符合人類的意圖(intention)、目標(goal)、偏好(preference)和道德準則(ethical principles)[78].對齊問題(alignment problem)可追溯到1960 年控制論先驅諾伯特·維納(Norbert Wiener)[79]在其論文《自動化的道德和技術后果》一文中的論述:“我們最好確信置入機器的目標是我們真正想要的,而不僅僅是對其華麗地模仿”.為了處理模型設計中的優化目標定義和實現的復雜性,一般會采用更加易于實現的目標作為優化函數,稱為代理目標(proxy goals).然而,這可能會忽略AI 模型優化中真正重要的方向,使訓練好的模型僅僅只是看起來像是與人類的意圖對齊(回顧機器人三定律的例子),隨之帶來的獎勵攻擊(reward hacking)、錯誤目標(misaligned goal)和權利追尋(power seeking)[80]將進一步產生第1.1 節所述的風險和危害.因此,需要考慮AI 模型是否與用戶真正目標對齊.
在大模型時代,對于一個給定的模型 M,其價值對齊程度可形式化為式(2)[81]:
其中,x表示給定的輸入,y為模型 M 給出的輸出,vi為某種預設的價值.模型對齊則是希望在給定一組價值表述后,例如無害、公平、正義等,最大化模型的輸出滿足這組價值的程度.由于模型的不確定性、價值表述的模糊性和價值評估的不準確性,往往人類創作的輸出y也無法達到式(2)的最大值.我們可以定義人類產生的輸出為y?,并考慮最小化模型輸出與人類輸出在價值評估下的差異性,即|P(vi|y?)-P(vi|y)|.給定某個較小的正的常數ε,當
時,我們認為模型 M已經和人類價值足夠對齊[82].
在大模型時代,進行價值對齊(value alignment)的方法主要可分為兩大類,即插入式對齊和微調式對齊,這2 類方法又可進一步細分為5 小類.本節對每類方法進行簡要介紹.
1)插入式對齊(plug-in alignment).插入式對齊主要是指在不修改大模型的參數或者只調整很小一部分參數的情況下,通過參數優化、輸出矯正和上下文學習等方式約束模型的行為,使其輸出滿足用戶指定的人類價值.按技術發展的時間順序,這一類別的方法可細分為:
①參數高效的調整(parameter-efficient tuning).這一系列的方法集中應用于早期的中小規模的預訓練模型,旨在減少微調模型參數的開銷,并具體應用于毒性去除(detoxification)和偏見去除(debiasing)等特定的風險評估任務.Sheng 等人[83]通過對抗訓練搜索和優化得到離散的字符串作為觸發器(trigger)拼接到語言模型的提示(prompt)中以控制減少模型生成的針對性別、種族等方面的歧視內容.Cheng 等人[84]在BERT 的輸出之上利用基于信息瓶頸(information bottleneck)的損失函數訓練了一個過濾層以去除和性別有關的信息,從而實現對BERT 輸出的文本表示的去偏.Berg 等人[85]通過提示微調(prompt tuning)的方式優化學習一組提示向量(prompt embedding)用于去除多模態預訓練模型中的偏見.Qian 等人[86]用類似前綴微調(prefix tuning)方法學習了一組向量用于減少生成的有毒內容.Yang 等人[30]則利用基于信息論的方法,通過在解碼時微調語言模型中的所有偏置項參數實現統一的去毒和去偏,這類方法具有數據需求少、對性能影響小、訓練開銷小等優勢.然而,對齊的效果有限且隨著模型增大逐漸下降[30].此外,對近年來數百億參數規模的大模型而言,輕量化微調的計算開銷也變得越來越難以承受.
②輸出矯正(output rectification).考慮到大模型越來越難以負擔的微調開銷,研究者提出不進行任何訓練/微調,而是直接對模型的輸出向量或分布進行后處理修改,以即插即用(plug-and-play)的方式進行矯正,以控制產生內容的屬性.Dathathri 等人[87]利用屬性分類器提供梯度信號,直接對語言模型輸出的向量表示進行修改,以實現對生成文本的情感、主題、毒性等內容的控制.Yang 等人[88]在Dathathri 等人[87]工作的基礎上,省去了對向量表示的修改,利用貝葉斯變換P(x|c,a)∝P(a|x,c)P(x|c)(其中c為輸出的提示,x為生成的文本,a為給定的屬性)直接對模型生成的文本概率進行權重調整以實現可控性.為了進一步避免對屬性分類器P(a|x)的訓練,Liu 等人[89]和Schick 等人[90]用基于屬性的條件生成模型P(x|a)替代分類器,并通過不同條件下生成概率的差異自動診斷模型是否違反了給定的屬性(價值).此外,Liang 等人[91]通過訓練得到了與屬性正交的零空間(nullspace),并通過將語言模型輸出向該空間投影的方式去除性別、種族等特征相關的偏見信息.Chen等人[92]用類似的方式在神經元級別找到了和性別信息相關的向量方向并進行投影,以此在文本到圖片的生成任務中消除性別相關的偏向.這類方法即插即用,無需對大量參數進行訓練且兼容任意模型,更加適合于當下計算開銷巨大甚至完全黑盒的大模型.然而,這類方法對齊效果較弱且會對模型本身在下游任務上的性能造成較大影響[93].
③上下文學習(in content learning).輸出矯正的方式可能對模型原本學習到的分布造成較大的擾動從而極大地影響其本身的性能.考慮到目前經過指令微調的大模型已經在預訓練階段學習到了足夠的知識,并且具備了一定的零樣本/少樣本學習、意圖理解、推理與解釋等能力,研究者提出直接以指令(instruction)/ 示范(demonstration)的方式約束大模型的行為.Ganguli 等人[77]發現直接在指令/提示中加入對大模型價值約束的語句,例如“請確保你的回答是公正的,不依賴于刻板印象”,模型即能在一定程度上理解該價值相關的指令并在輸出中減少刻板印象等有害內容.此外,在某些指標上,價值對齊程度與模型指令微調的步數呈正相關.Saunders 等人[94]則借助大模型的上述能力,讓模型自己針對某個問題生成的回答進行自我批判(self-critiquing),并依據其發現的問題對回答進行再次修改,以實現自動對齊.這類方法利用了模型自身的理解和矯正能力實現對齊,由于沒有修改任何參數,能夠最大程度地保留模型的基本能力,是對黑盒模型基于特定價值再對齊的一種較有潛力的范式.然而,這類方法極大地依賴于模型本身的能力并受限于指令微調階段的效果,不適用于規模較小或未經過指令微調的模型.
2)微調式對齊(fine-tuning based alignment).考慮到插入式對齊的缺點,直接微調雖然有較大的算力和數據開銷,但對齊效果好且能最大程度地避免對下游任務的影響.同時,在大模型成為基礎模型的當下,經過一次微調的模型可以復用于多種任務和場景,大大提升了微調的性價比.目前微調的方法可以分為2 條路線,即全監督微調(supervised fine-tuning,SFT)和基于人類反饋的強化學習微調(reinforcement learning from human feedback,RLHF).
①全監督微調(SFT).與插入式對齊類似,早期SFT 方法著重強調降低特定的風險評估指標.Lu 等人[95]構造了針對同一屬性不同取值(例如男性和女性)但語義相似的數據來微調語言模型,以減少預訓練數據中語義與特定性別關聯性帶來的偏見,該方法稱為反事實數據增廣(counterfactual data augmentation).Gehman 等人[96]把模型在精心構造的無毒的數據上微調以去除其毒性.在大模型時代,價值不僅包括特定的安全性,也涵蓋了用戶偏好、人類意圖等方面.為了兼顧多方面,研究者直接利用人工構造的滿足不同價值的〈輸入,輸出〉數據對,以端到端(endto-end)的方式進行指令微調.Wang 等人[66]提出了一種自動構造指令數據的方法,利用大模型自動生成〈指令,輸入,輸出〉數據,并用這些數據微調GPT-3.Sun 等人[97]更進一步利用上下文學習的方法,通過一組人工撰寫的準則來約束模型,生成有用且無害(helpful and harmless)的內容以微調模型.Liu 等人[98]則在微調數據中同時引入了符合價值的正例和不符合價值的負例,以類似對比學習的形式讓模型學習和了解不同內容之間細微的差異.SFT 這一范式實現簡單,訓練穩定且收斂較快.然而,其存在2 個缺點,即對未見過的用戶輸入泛化性差,同時在違反價值的數據點上得到的負反饋信號稀疏.
②基于人類反饋的強化學習微調(RLHF).目前主流的大模型不再采用SFT,而是以強化學習(reinforcement learning,RL)的方式進行微調.其中,最具代表性的是Ouyang 等人[3]的工作.該方法由3 個階段組成:階段1,人工構造符合價值的輸入-輸出數據,以SFT 的方式微調大模型;階段2,收集構造不同質量的回復數據并人工排序,用排序數據訓練一個評分模型(reward model),又稱為偏好模型(preference model),訓練損失值loss為
其中,rθ是評分模型,θ 為待訓練的模型參數,x是模型輸入,y為模型輸出,而y?為更符合價值的目標輸出;階段3,利用該評分模型,以強化學習的方式再次微調大模型,最小化損失值loss:
為了解決這些問題,Bai 等人[76]提出了一種在線迭代訓練的方法,每周迭代更新大模型和評分模型,有效實現了模型性能的持續提升.為了減少對人類標注的反饋數據的依賴,Kim 等人[99]使用大模型生成的合成數據來訓練評分模型.Bai 等人[100]提出了憲法AI(constitutional AI),將SFT 階段和評分器訓練階段的數據從人工構造的數據替換為Saunders 等人[94]的自我批判方法生成的評論和修改數據,并將思維鏈AI(chain-of-thought,CoT)方法[101]引入到訓練過程中.Yuan 等人[102]提出了一種改進的回復排序對齊方法(rank responses to align with human feedback),從不同模型、人類數據、待訓練模型等不同數據源采樣信息并通過排序損失函數進行訓練,以進一步提升對齊效果.傳統的RLHF 方法在數學上等價于一個最小化模型分布和一個隱式的目標分布之間的逆向KL 散度(reverse KL-divergence),Go 等人[103]則進一步將其擴展為f 散度(f -divergence)并統一了RLHF、GDC、DPG 等各類算法.為了解決泛化性不足和魯棒性差等問題,Liu 等人[104]在傳統的以評分模型為基礎的方法(如RLHF)之上,創新性地提出了直接建模社會中的人類交互.Liu 等人構建了一個由大量模型構成的模擬社會,并讓模型在其中自由交互、獲得反饋、學習調整自己的行為以留下較好的印象,并由此學習和建立社會化的價值.
2.4 大模型對齊問題的進一步討論
由2.3 節所述的對齊方法的發展歷程觀之,針對AI 模型,尤其是預訓練大模型的對齊已經從早期的消除特定風險逐步向著更廣泛的價值對齊演化.然而,較早的對齊方法(例如插入式對齊)的對齊目標過于單一,并未考慮人類的普適價值;而新的以RLHF 為代表的基于指令和偏好的對齊沒有顯式區分不同的價值類型,即沒有考慮需要強調指令(instruction)、意圖(intention)、目標(goal)、人類偏好(human preference)、道德準則(ethical principle)等多種價值中的哪一種,而是模糊地使用對齊一詞并涵蓋上述部分層面或全部層面[105].為了更加深入理解對齊問題,并實現本文所倡導的道德價值的對齊(ethical value alignment),我們需回答3 個在大模型對齊中常見且有待研究的問題[105].
1)對齊的目標是什么(What to be aligned).對齊目標(即我們追求的優先價值)可以細分為多個類別,例如指令遵循(讓AI 遵循用戶指示)、意圖理解(讓AI 理解人類指令背后的意圖)、偏好滿足(讓AI 進行能滿足用戶偏好的行為)、目標實現(讓AI 完成用戶渴望的目標)、福祉提升(讓AI 進行能將用戶利益最大化的行為)、道德符合(讓AI 進行人類社會道德下應進行的行為)等[21].不同的對齊目標需要的方法和數據不盡相同,對用戶和社會帶來的后果也有所差異,在進行對齊前必須先考慮這一問題.
2)對齊的含義是什么(What is alignment).對齊具有不同的定義和要求,其難度、涉及的方法以及帶來的影響也有所差異.提出Deepmind 的Kenton 等人[106]將其細分為4 個類別:①行為對齊(behavior alignment),即讓AI 的行為符合人類期望的目標,早期的對齊方法(例如輸出矯正)屬于此類.②意圖對齊(intent alignment),即讓AI 行為背后的意圖符合人類真正的目標,當下以RLHF 為代表的方法可認為部分地屬于這一類別.③激勵對齊(incentive alignment),即AI 的激勵目標也需要與人類的激勵目標對齊,以防止AI 作弊.一個簡單的例子是讓機器人打掃房間,即讓“打掃房間”這一行為和“把房間打掃干凈”這一意圖得到對齊.若對“干凈”這一反饋激勵定義有誤,則模型可能會以“將所有物品扔出房間”的做法來實現“干凈”(回顧《魔法師學徒》的例子).④內在對齊(inner alignment),當AI 模型訓練的基礎目標(baseobjective),例如文本分類的準確率,和臺面目標(mesa-objective),即AI 模型學習到的某些捷徑(shortcut)特征不一致時,上述所有目標/類別的對齊都無法實現,較好的內在對齊能使模型的可解釋性和魯棒性得到提升.
3)對齊的準則是什么(What is value principle).不管我們選取何種對齊目標,都需要定義每個目標的具體含義.例如,指令遵循中哪些指令是需要AI 優先遵循的?道德符合中,哪些準則(例如1.2 節中所列舉的)需要被考慮?目前的對齊方法存在“眾包的專制”(tyranny of the crowdworker)[105]問題,即對齊準則的定義權被數據標注者或標注規范的制定者所掌控.這使得模型對齊的偏好、價值觀等成為少部分人的偏好與價值觀,缺乏在文化、種族、語言等方面的廣泛性和多樣性,最終將導致1.1 節中所提到的風險與危害.
針對上述3 個問題,我們以普適的道德價值為對齊目標,考慮完善意圖對齊并向激勵對齊邁進,倡導共同制定一套覆蓋人類普適道德價值的統一AI 道德準則框架.
2.5 大模型道德價值觀對齊的難點與挑戰
從前文的介紹可看出,盡管針對大模型的對齊研究經過了數年的發展并且從早期的特定風險消除逐步向著針對價值的對齊發展.然而,如2.3 和2.4 節所述,近年的對齊工作并沒有顯式區分和回答對齊的目標、對齊的含義和對齊的準則這3 個問題.在最近發表的眾多論文中,尚未存在基于一套普適AI 道德價值框架來實現意圖對齊及更具有挑戰性的對齊的工作.如何回應這3 個問題,真正實現AI 與人類普適道德價值的深度對齊,是一個尚未得到充分探討和解決的開放問題.本文將其面臨的部分挑戰與難點列舉如下,如圖2 所示.
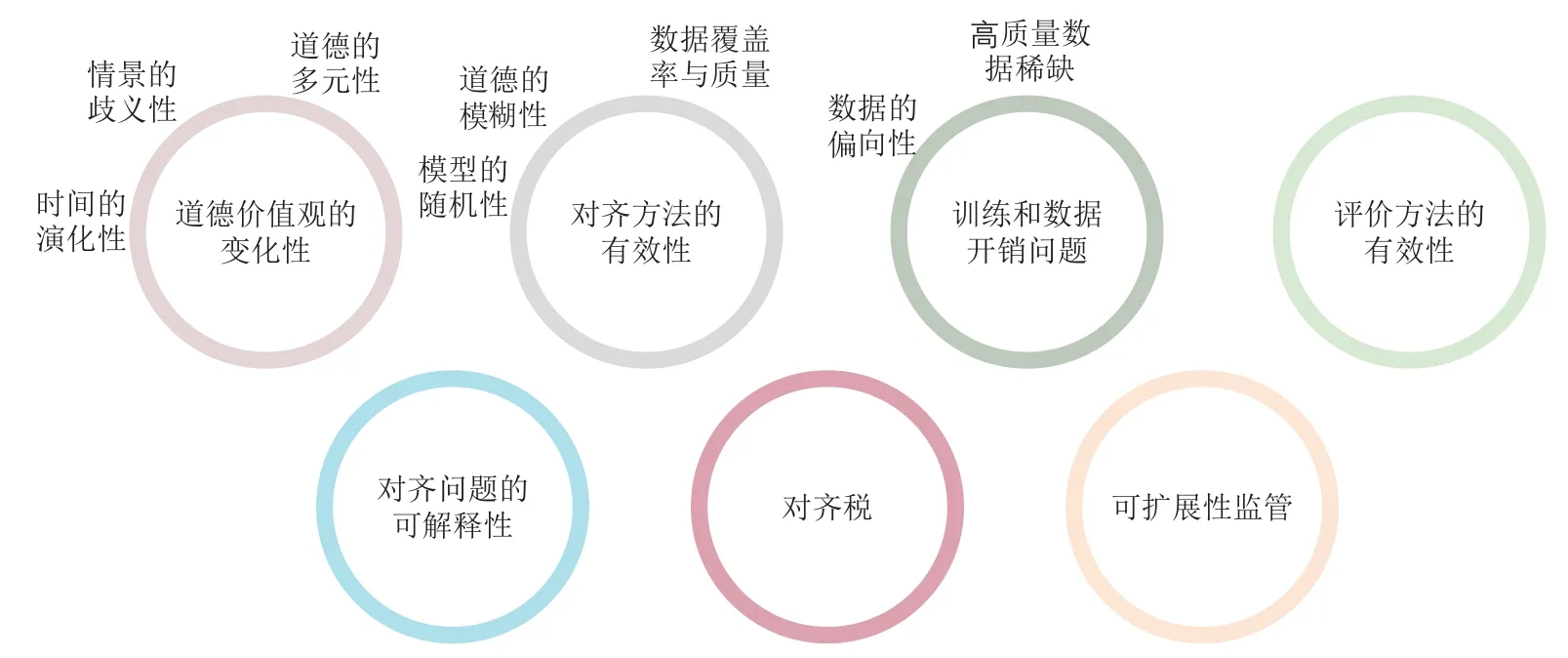
Fig.2 Difficulties and challenges of ethical value alignment圖2 道德價值觀對齊的難點與挑戰
1)道德價值觀的變化性(variability of ethical values).道德價值觀不是靜態的,而是會隨著時間、文化、社會環境的變化而改變的[107-108].這種變化性具體體現在3 個方面:
①時間的演化性.在社會發展的不同階段,人類的道德要求和標準不盡相同.例如,在20 世紀和21世紀發展的種族/性別平等的道德觀念在封建時代并不存在.
②情景的歧義性.不同的文化、社會和個體可能對道德價值觀有著極為不同的理解和詮釋[109].在特定場景下符合道德價值的行為在其他情景下可能違反道德.
③道德的多元性.考慮到文化和社會的多樣性,在同一時間和背景下也會有適用的多種道德準則,且準則之間可能相互沖突,產生道德困境(ethical dilemma).
在這樣的變化之下,定義一個通用且公正的道德框架極具挑戰.這樣的變化性要求針對大模型的對齊方法具備高度的可擴展性.對齊方法需要進行持續性地學習和適應,以便準確地反映道德價值觀上的變化與差異.同時不能簡單地將一個固定的道德框架嵌入到模型中,而需要讓模型能夠學習并理解各種各樣的道德觀念,并能在不同的情境中靈活應用,以適應豐富多樣的道德準則和應用場景.這進一步涉及2 個方面的問題.i)大模型本身的基本能力:要求模型夠理解并處理復雜的道德規則;ii)對齊效果的泛化性:要求對齊方法不僅能在特定的道德價值上作用,還需要泛化到不同文化、地域、情景中的道德價值,并在不同的情況下準確地遵循這些規則.如何設計并實現這樣的機制,需要長期深入地研究.
2)對齊方法的有效性(alignment efficacy).如何實現較好的道德對齊效果,即盡可能減小式(3)中的ε值也是一個亟待解決的挑戰.盡管近幾年來,基于RLHF 的對齊方法取得了較好的效果并且演化出諸多改進的變體,但由于AI 模型本身的隨機性、道德準則的模糊性、評分模型的覆蓋率以及訓練數據的質量和數量等問題,當下的對齊程度與人類自身的道德標準仍相去甚遠.更有甚者,主流的RLHF 對齊方法已經被理論證明無法完全去除有害行為并且容易遭受對抗攻擊和越獄引導(Jailbreak)[81].
3)訓練和數據開銷問題(data and training cost).大模型的訓練和優化需要海量的數據用于預訓練,以及一般數萬條高質量的人工標注的反饋數據用于RLHF 微調[3].盡管部分方法采用模型生成的合成數據來增廣人工標簽[66],但主要集中在一般的對話任務中.針對道德準則的數據不夠豐富抑或存在覆蓋率低和類別不平衡的問題,且增廣的方法在道德價值問題上的有效性仍待探索,這可能導致道德對齊效果出現偏向(bias)并帶來進一步的風險.此外,即使解決了數據數量和質量問題,大模型的訓練開銷仍然巨大.部分研究工作也發現隨著模型的增大,指令微調(instruction fine-tuning)的收益逐漸減小[110].
4)評價方法的有效性(evaluation efficacy).如何有效評價模型的道德對齊效果也是一個難題.當下對齊性能的評價大多聚焦于少部分風險指標,如生成內容的毒性、針對特定群體的偏見、對提示攻擊的魯棒性等[3,76,111],尚無面向更加廣泛的道德價值的高質量評測數據集以及客觀、準確和魯棒的自動化評測指標.
5)對齊的可解釋性(interpretability of alignment).為了確保道德對齊的公正性和公平性,我們需要能夠解釋和理解模型基于道德準則給出的解釋.例如,為何模型的輸出符合某一道德準則?模型未能生成或基于何種道德準則拒絕生成某些內容.若透明性和可解釋性成為大模型的道德準則,那么這些模型不僅要在具體的下游任務中體現出透明性,在遵循其他道德準則時也需要以用戶易于理解的方式提供可解釋的證據支持,以提升用戶信任度.可解釋性尤其在閉源的黑盒模型,以及經過定制化(customized)微調的開源模型上更加重要.OpenAI 將對齊過程的可解釋性視為“最大的開放性問題之一”[3].
6)對齊稅(alignment taxes)問題.經過對齊的大模型盡管具有較強的能力,但其語言建模能力比原始模型或未對齊的模型更弱[105,112],并由此導致了對齊效果與下游性能的平衡問題.雖然部分工作顯示,在某些任務和場景下對齊稅的占比較小[76],沒有對齊稅甚至對齊能對任務性能帶來正面的影響,稱為負對齊稅(negative alignment tax)[113].然而,這些問題在道德價值對齊上具有何種性質尚不明確.因此,我們有必要考慮在進行道德對齊的同時保證大模型的下游任務性能,如理解、生成和預測等.如何在道德對齊和任務性能之間找到一個良好的平衡是另一個重要的挑戰.
7)可擴展性監管(scalable oversight)問題.可擴展性監管是指當AI 模型在給定任務上的性能遠超人類時,如何對其進行有效地監督和控制的問題[114].隨著AI 模型變得越來越復雜和強大,對模型的行為是否符合價值的判斷、監管與控制也將更具挑戰性.GPT-4 在部分專業和學術測評上的表現已經遠超人類平均水平[4].在可預見的將來,大模型對于道德價值的理解、判斷與解讀能力可能達到甚至超過人類專家.在這種情況下如何確保AI 系統行為與人類的價值觀、道德觀和社會規范一致將成為至關重要的研究問題.
3 平衡對齊:一種新的道德價值觀對齊范式展望
大模型的倫理和道德價值觀對齊成為了一個不容忽視的議題.這是確保強力的模型不但能為人類提供幫助(helpfulness),也確保其無害(harmlessness)和誠實(honest),即所謂的3H 標準[112]的根本方法.為了解決現有方法在道德價值對齊問題上的挑戰,本節對一種新的大模型價值觀對齊范式進行了展望,稱之為平衡對齊(equilibrium alignment).我們從3 個角度討論所提出的概念框架,如圖3 所示,即大模型道德對齊的度量維度、大模型對齊評測的方法以及基于羅爾斯反思平衡理論的對齊方法.“平衡”強調在衡量對齊程度的多個評價維度、道德判別器的多種性質以及自底向上和自頂向下的雙向對齊約束上取得較好的平衡.希望該框架能為這一方向的研究者和實踐者提供一些新的思考和啟示.
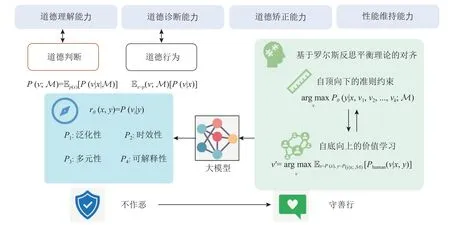
Fig.3 The conceptual framework of equilibrium alignment圖3 平衡對齊的概念性框架
3.1 大模型對齊的度量維度
平衡對齊框架首先考慮如何評估對齊后的模型.我們考察對齊后的大模型在4 個層面的能力(capability)來衡量所使用的對齊方法的有效性.具體而言,我們考慮被對齊的大模型的4 個核心維度:道德理解能力(comprehension capability)、道德診斷能力(diagnosis capability)、道德矯正能力(rectification capability)和性能維持能力(performance capability).這4 個維度共同度量了對齊方法在大模型上的應用潛力.
1)道德理解能力.AI 系統在多大程度上能夠理解人類賦予它的道德觀念和倫理規則.AI 需要能夠正確地理解和解釋不同文化和社會背景下人類道德、倫理的基本概念,例如公正、公平、尊重、信任等,并以較高的準確率判斷給定的內容/行為是否符合或違反了這些倫理準則.現有工作表明,未經對齊的千億參數級的GPT-3 模型在簡單的道德選擇判斷中Zeroshot 準確率僅有60.2%,遠低于經過領域數據微調的僅有7.7 億個參數的T5-Large 模型[115].除了理解這些抽象的概念,AI 還需要理解這些概念如何在具體的人類交互環境中實現和展現.只有具備足夠的道德敏感性,模型才能在處理用戶的請求時識別其中的道德內涵,理解其背后的價值觀.如何進一步提升大模型在開放域環境中對抽象道德概念的理解能力是一個尚待研究的問題.
2)道德診斷能力.大模型在面對具體情境時,能夠識別其中存在的道德問題和沖突,并做出合理判斷的能力.這不僅包括對給定的或模型自己產生的道德問題的識別和判斷,還包括對可能的解決方案的提出和評估.例如,當AI 在處理某個問題時,如果存在多種可能的行動方案,那么它需要能夠根據道德倫理規則來評估這些方案,從而做出最符合道德的選擇.當面臨多元化道德價值沖突時,還應該能考慮其中的沖突性,并按照用戶的需求給出最好的方案.這不僅要求模型在對齊過程中很好地學習遵守給定的準則,還需要具備自我監督和學習能力,舉一反三,以識別并避免潛在的道德風險.
3)道德矯正能力.大模型在識別出外部或自身的道德問題或沖突后,能夠及時糾正錯誤(包括自我糾正和在用戶指導下的改進),調整自己的行為,或者能夠提出解決方案,為用戶提供相應解決路徑的能力.為實現這一目標,大模型需要具備足夠的自我適應性、創造力和決策能力,能夠生成符合道德規范的行為選項,且能夠接受并有效利用用戶的反饋.現有工作表明,大模型在接受用戶指令或在用戶的指導下發現自己的問題后,具備一定的“被動”自我糾正能力[77,94].未來的研究將聚焦于如何進一步加強這一能力并將用戶引導下的“被動”糾正改進為主動整流.
4)性能維持能力.大模型在各種任務上表現出色.在遵守道德和倫理規則的同時,我們也需要確保AI 系統的功能性和效率不受損害,不應在提高道德標準的過程中犧牲其基本的性能.如何進一步降低對齊稅,甚至在更廣泛的場景和任務上實現負對齊稅,是道德價值對齊進一步走向實用化的關鍵難點.
在上述4 個維度中,評估模型的道德理解能力可以判斷模型是否能正確理解和處理各種道德概念和情境.評估模型的道德診斷能力可以考察模型在面對復雜道德決策問題時,是否能夠做出符合人類道德倫理標準的選擇.這2 個維度的評估結果可以直接反映模型是否實現了意圖或者更高層面的對齊.檢驗模型是否能夠實現從被約束下的“不能作惡”(avoid doing evil)到非約束下的“主動行善”(intend to do good)的轉變,能有效考察對齊方法的有效性.此外,道德理解能力要求模型能夠理解和處理道德概念和情境,需要有能力解釋其如何理解并應用這些道德概念.而道德矯正能力則要求模型能夠在發現錯誤時進行自我調整,要求模型有能力解釋其如何發現并糾正錯誤.這2 個維度的評估可以幫助我們理解模型的道德判斷和行為的原因,從而提高可解釋性.性能維持能力則直接對對齊稅作出要求.上述4個維度共同構成了一套行之有效的評測方法.若能在這4 個維度取得較好的平衡,經過對齊的模型不僅能理解道德準則,而且能在踐行道德要求的同時維持性能的有效性,既幫助人類完成復雜多樣的任務,又在道德價值層面實現知行合一.
3.2 語言模型對齊的自動化評測方法
為了評估對齊的效果或者以RLHF 的方法進行對齊,我們需要實現一個強力的判別式模型,即式(3)中的P(vi|y),以判斷任意內容y是否符合指定的道德價值vi.同時,這一模型也可以作為強化學習對齊方法中的評分函數,即rθ(x,y)=P(vi|y).判別模型需要具備4 點性質.
1)P1:泛化性(generality).判別模型需要能夠判別任意開放域(open-domain)和分布外(OOD)的內容y是否符合任意測試時刻(testing-time)的道德價值表述(ethical value statement)vi.這要求判別模型具備領域、場景和語義上的高泛化性.
2)P2:時效性(timeliness).判別模型需要能夠在實時場景下對未見過的內容和價值表述之間的符合程度進行判斷.這要求模型在訓練過程中能對道德價值進行深度理解和學習,進而舉一反三.例如,訓練數據中僅有關于公平性的樣例,訓練完成的模型需要具備能夠判斷正義相關價值的能力.時效性的實現可以要求使用少量新場景的數據并對極少(參數比例小于 1%)模型參數進行修改,但不應使用大規模數據對大量模型參數進行訓練/微調,
3)P3:多元性(pluralism).判別模型需要能夠依據不同的場景、文化和社會背景進行不同的判斷,或者同時給出不同判斷及其對應的場景.當同一時間背景下的判斷存在道德沖突,模型應該能首先解決沖突,若無法解決,則應給出不同的判斷/選擇及其對應的道德依據.
4)P4:可解釋性(interpretability).判別模型不僅需要依照P1和P3進行判斷,還應提供做出判斷的解釋,即某一判斷對應的道德準則、適用的場景等.
滿足這4 點性質的判別模型能作為評分器用于式(5)的RLHF 等對齊方法,引導模型進行道德對齊.同時,強力的判別模型也可以用于對齊效果的評測,計算式(3)中的對齊程度.這樣的判別模型能有效解決大模型對齊問題中的道德價值觀的變化性、對齊的可解釋性和可擴展監督3 個挑戰.更進一步,我們從2 個角度對對齊后的語言模型進行評測:
1)道德判斷(moral judgement).道德判斷是評測對齊后的模型是否具備更好的道德理解和分析能力.定義未對齊的模型的分布為P(x;M),則對齊后的模型應該學習內容x和價值v的聯合分布P(v,x;M).若完美對齊,大模型本身應能被轉換為在道德價值上的建模:
即可通過測試大模型本身作為判別器的能力來衡量模型的對齊效果.
2)道德行為(moral action).除判別式評測外,我們還應直接使用分類器評測模型生成的內容是否符合道德價值,即
現有主流大模型在Zero-shot 上也能具備一定的道德判斷能力[115],但是在經過越獄攻擊后依然會產生違反道德的內容[81].這說明道德理解能力能夠較好地評估2.4 節中討論的行為對齊效果,但并不能有效度量模型是否實現了意圖對齊.
上述2 種評測類型分別與3.1 節中所述的道德理解能力和道德診斷能力相對應.具有較高道德判斷準確性的模型并不一定能在行為(生成內容)上符合道德.Perez 等人[116]發現大模型更傾向于生成奉承(sycophancy)的內容.這是因為RLHF 優化的是人類偏好(preference),從而經過RLHF 訓練的模型傾向于給出人類評測者偏好的回復.因此,在面臨道德詢問/選擇時,模型往往會依據自己具備的道德知識給出“標準答案”,但在常規任務中進行寫作、推理、分析時,卻有可能違反道德準則,這與《尚書·說命中》中的“知易行難”一說類似.只有同時進行這2 方面的評測,即判斷大模型是否能夠檢測行為與文本的道德性,并考察在實際行動中是否能夠執行這些標準,雙管齊下,知行合一,才能實現有效道德評測,從而為優化提供依據.在道德理解能力與診斷能力上的統一與平衡是實現道德矯正能力的基礎,也是“平衡對齊”框架的核心之一.
3.3 基于羅爾斯反思平衡理論的對齊方法
關于道德規范的形成,長期以來存在2 種觀點.一是自底向上(bottom-up)的規則,即認為道德是人類社會與生物需求在特定情景下的抽象表達[117],可以從群體在不同道德情境下的判斷中體現出的共同模式歸納得出[118].另一種觀點是自頂向下(up-down)的規則,即認為存在一系列客觀的固有道德準則.支持第2 種觀點的這一流派以1.2 節中所述康德的定言令式為代表,即認為道德準則可以通過一系列的邏輯推斷得出.部分研究機器道德的工作認為當時的AI 能力無法對人類制定的抽象道德規則進行深度理解和執行,因而自頂向下的規則難以實現[115].得益于當前大模型較強的指令遵循和語義理解能力,自頂向下的規則對齊成為可能.
基于此,本文倡導基于羅爾斯反思平衡理論(reflective equilibrium)進行對齊算法的設計.該理論由約翰·羅爾斯(John Rawls)提出,指在一般原則和特定情景下的判斷之間相互調整達到平衡或一致的過程[119].一方面,反思平衡考慮了自頂向下的具有高優先級的一組道德準則,即v1,v2,…,vK.這允許模型和我們在1.2 節討論的普適道德價值對齊,并以這些價值作為類似機器人三定律的根本原則,即優化P(y|x,v1,…,vk;M)這一概率分布.另一方面,大模型可以從海量的用戶交互和反饋數據中學習人類道德判斷中的共同模式,并以此形成內部學習得到的隱式道德準則,即這種通過學習得到的歸納性價值總結可以允許模型依據所部署的文化、社會和情景進行調整,學習和捕捉不同場景下的差別.同時,自頂向下的準則反過來又可以控制和約束用戶數據中存在的共性偏見與毒性.
通過同時自頂向下和自底向上,可以使模型依據不同優先級的準則動態調整,從實現最公正的道德決策,并解決道德價值觀的變化性這一點挑戰,以雙向對齊實現普適道德價值的強約束與特定情景下的動態調整的平衡,方能計出萬全.
3.4 學科交叉,深度合作,共塑道德AI
道德價值被認為源于社會和文化群體中道德原則的構建,這些原則用于引導群體內部的個體做出基本的決策和學習辨別是非[120].如果剝離了社會和文化的環境,道德價值將無法成立.2004 年,由哲學家和計算機學家撰寫的《邁向機器倫理》一文于AAAI研討會上發表[121],被認為開啟了機器倫理研究的篇章.對AI 與道德價值的研究天然具備跨學科交叉、多領域合作的特點.
為了克服上文介紹的諸多問題和挑戰,實現大模型在道德價值觀上多角度、全方位與人類對齊,我們呼吁AI 研究者及開發者積極參與并推動跨學科的合作,建立AI 領域與道德哲學家、心理學家、社會學家、人文學家、法學家等多領域專家的緊密合作.借助哲學對道德研究的專業知識、心理學對人的測試和評估的系統方法、文學領域對人文語言研究的理論以及法學領域對技術合法性的探索,我們可以整合多方的知識資源,引入AI 與人類和社會的交互與反饋,深入理解AI 的道德現狀以及對人類可能產生的影響.
在此基礎上,我們不應僅限于特定領域內的性能指標評估,而需要長期監測和分析大規模AI 模型部署后的行為和對人類社會帶來的改變.基于這些觀察和分析,我們需要持續迭代和動態優化AI 的普適道德價值框架,使其能適應時代的發展和變化.在大模型的道德對齊過程中,不斷調整和完善對齊方法,共同塑造出道德對齊的AI 系統,讓AI 成為真正服務于人類的工具,助力推動人類社會的健康和可持續發展,以科技之光照亮未來之路.
4 結論
本文詳盡地探討了大模型在道德價值觀對齊所面臨的新挑戰.我們首先審視了大模型與AI 倫理之間的緊密聯系,總結出了大模型在倫理實踐中存在的不足.基于此,我們分析了大模型在道德價值對齊上所面臨的特殊挑戰,這為我們研究如何更好地在AI 中引入道德價值觀提供了新的視角.基于上述分析,我們提出了一種新的針對大模型道德價值觀對齊的概念范式——平衡對齊,并從對齊的維度、對齊的評測以及對齊的方法等3 個方面,重新定義了大模型道德價值觀對齊的概念.呼吁學界跨越學科壁壘,共同構建一個適應大模型的、普適的AI 道德框架,這將為未來在大模型中實現道德價值觀對齊的研究提供富有啟示和引領方向的思考.相信AI 在道德價值的引領下,能夠解鎖更大的潛能,給人類社會帶來更廣泛、更深遠的正面影響,持續推動人類社會的進步與發展,讓AI 與人類在共生的道路上交相輝映,攜手開創新紀元.
作者貢獻聲明:矣曉沅完成了文獻調研、對主流大模型的道德評測以及部分理論的提出和設計,并撰寫論文;謝幸提供了文章撰寫和組織的思路,為其中的理論和方法的設計提供了指導意見,并對文章進行了修改和指導.
猜你喜歡
小天使·一年級語數英綜合(2022年4期)2022-04-28 08:42:36
大科技·百科新說(2021年6期)2021-09-12 02:37:27
建材發展導向(2021年6期)2021-06-09 05:58:06
好孩子畫報(2020年5期)2020-06-27 14:08:05
意林·全彩Color(2019年6期)2019-07-24 08:13:50
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
小天使·四年級語數英綜合(2016年11期)2016-11-29 22:37:30
現代企業文化·綜合版(2016年6期)2016-05-14 16:38:34
奧秘(2015年2期)2015-09-10 07:22:44
學習月刊(2015年9期)2015-07-09 05:33:44
