面向新型智能計算中心的全調(diào)度以太網(wǎng)技術(shù)
2023-09-21 08:47:20段曉東DUANXiaodong程偉強CHENGWeiqiang王瑞雪WANGRuixue王雯萱WANGWenxuan
中興通訊技術(shù) 2023年4期
段曉東/DUAN Xiaodong,程偉強/CHENG Weiqiang,王瑞雪/WANG Ruixue,王雯萱/WANG Wenxuan
(中國移動通信有限公司研究院,中國 北京 100053 )
1 AI業(yè)務(wù)與智能計算中心產(chǎn)業(yè)的發(fā)展
1.1 AI業(yè)務(wù)發(fā)展趨勢
人工智能(AI)業(yè)務(wù)發(fā)展經(jīng)歷了漫長的歷程。20世紀50年代,人們開始嘗試模擬人腦的神經(jīng)網(wǎng)絡(luò)來解決計算機視覺和語音識別的問題。但由于當時無法解決神經(jīng)網(wǎng)絡(luò)計算復(fù)雜度高和可解釋性差的問題, AI 技術(shù)進入了“寒冬”。2012—2017年,Hinton等提出卷積神經(jīng)網(wǎng)絡(luò),大大推動計算機視覺和深度學(xué)習(xí)的發(fā)展。同時,基于深度學(xué)習(xí)的AlphaGo戰(zhàn)勝圍棋世界冠軍,進一步點燃人們在深度學(xué)習(xí)領(lǐng)域探索的熱情與信心。2017—2022 年,基于大型神經(jīng)網(wǎng)絡(luò)的Transformer架構(gòu)出現(xiàn),該模型可以更好地捕捉序列之間的依賴關(guān)系,開啟了基于深度學(xué)習(xí)的AI 新時代。2022 年11 月,OpenAI公司開發(fā)的大規(guī)模智能語言模型ChatGPT 橫空出世。ChatGPT 結(jié)合了GPT-3.5 和GPT-4 系列的大型語言模型,展現(xiàn)出驚人的語言能力[1]。該模型深入各個領(lǐng)域,在引爆全球科技領(lǐng)域的同時,推動AI產(chǎn)業(yè)全面進入大模型時代。因此,ChatGPT的出現(xiàn)具有跨時代的意義。
近年來,隨著算力經(jīng)濟的高速發(fā)展[2],AI業(yè)務(wù)在自動駕駛、語音識別和自然語言處理等領(lǐng)域取得了許多重大成就,并涌現(xiàn)出人工智能即服務(wù)(AIaaS)和模型即服務(wù)(MaaS)兩種新型服務(wù)模式。當前,教育、醫(yī)療、智慧城市和智能制造等行業(yè)迫切需要AI 賦能,例如:華為云、百度云、阿里云和騰訊云等提供AIaaS的企業(yè)均為用戶提供高品質(zhì)的人工智能服務(wù)。MaaS 擁有經(jīng)過大量數(shù)據(jù)集訓(xùn)練和優(yōu)化的模型,可為用戶提供圖像識別、自然語言處理、預(yù)測分析和欺詐檢測等服務(wù)。
為推動AI業(yè)務(wù)的發(fā)展,中國陸續(xù)給予政策方面的扶持和激勵,特別是東數(shù)西算工程的全面啟動,給AI大模型在智能計算(后文簡稱為“智算”)中心的快速發(fā)展注入強大的助推劑[3]。AI 大模型的參數(shù)量呈指數(shù)級增長,有力地驅(qū)動了“大模型”向“超大模型”演進。與此同時,智算規(guī)模和智算需求也呈指數(shù)級增長。預(yù)計截至2030 年,智算占比將達到70%,AI技術(shù)將廣泛落地,中國將迎來智算中心建設(shè)的熱潮。
1.2 智算中心產(chǎn)業(yè)發(fā)展趨勢
為加速智能經(jīng)濟發(fā)展和產(chǎn)業(yè)數(shù)字化轉(zhuǎn)型,智算中心作為一種新的關(guān)鍵性信息基礎(chǔ)設(shè)施進入公眾視野。智算中心既不同于超算中心,也不同于互聯(lián)網(wǎng)企業(yè)和運營商的云計算中心。智算中心既要借鑒超算中心分布式集群計算架構(gòu),以支持超大規(guī)模、復(fù)雜度高及多樣性的數(shù)據(jù)處理,又要參照云計算服務(wù)模式,采用統(tǒng)一的架構(gòu)和統(tǒng)一的應(yīng)用程序編程接口(API),以屏蔽底層技術(shù)細節(jié),降低使用門檻,向不同行業(yè)提供普適且靈活多樣的智算服務(wù)。
隨著業(yè)內(nèi)領(lǐng)軍企業(yè)競相推出千億、萬億級參數(shù)量的大模型,以圖形處理器(GPU)、神經(jīng)網(wǎng)絡(luò)處理器(NPU)為代表的AI 算力設(shè)施迅猛發(fā)展,使得智算中心底層GPU 算力部署規(guī)模達到萬卡級別。基于數(shù)據(jù)并行、模型并行的分布式訓(xùn)練成為處理超大模型和超大數(shù)據(jù)集的關(guān)鍵手段。智算中心集群算力與GPU 算力、節(jié)點數(shù)量、線性加速比、有效運行時間等呈正相關(guān),需要計算、存儲和網(wǎng)絡(luò)資源的協(xié)同設(shè)計,具體表現(xiàn)在以下幾個方面:在計算方面,單機算力無法支撐海量訓(xùn)練數(shù)據(jù),需要將計算任務(wù)切分到單機級別,以并行計算的集群架構(gòu)方式提供算力服務(wù);在存儲方面,為突破計算節(jié)點中大量密集數(shù)據(jù)存取帶來的算力瓶頸,搭建機械硬盤(HDD)、固態(tài)硬盤(SSD)、存儲類內(nèi)存(SCM)等異構(gòu)存儲集群,以降低數(shù)據(jù)訪問時延;在網(wǎng)絡(luò)方面,構(gòu)建連接中央處理器(CPU)、GPU、存儲等異構(gòu)算力資源的總線級、高性能無阻塞交換網(wǎng)絡(luò),以提升網(wǎng)絡(luò)通信性能和穩(wěn)定性;在機房建設(shè)方面,提前規(guī)劃“風(fēng)火水電”等基建設(shè)施,引入液冷系統(tǒng),實現(xiàn)低電源使用效率(PUE)數(shù)據(jù)中心的高能效利用。由此可見,傳統(tǒng)智算中心正在向新型智算中心演進。
面向智能計算業(yè)務(wù)的發(fā)展,新型智算中心圍繞“算、存、網(wǎng)、管、效”五大核心技術(shù)全面升級,以提升GPU 集群算力,打造多元融合存儲,構(gòu)建高速無損網(wǎng)絡(luò),管控異構(gòu)算力池化,以高效節(jié)能控制為目標,構(gòu)建標準統(tǒng)一、技術(shù)領(lǐng)先、兼容開放的智算底座。
2 智算中心網(wǎng)絡(luò)演進趨勢與挑戰(zhàn)
2.1 智算中心網(wǎng)絡(luò)關(guān)鍵特征
隨著GPU 高速發(fā)展和算力需求的激增,算力中心正向集約化方向發(fā)展,數(shù)據(jù)中心從“云化時代”轉(zhuǎn)向“算力時代”。在傳統(tǒng)云數(shù)據(jù)中心中,傳統(tǒng)的計算處理任務(wù)或離線大數(shù)據(jù)計算任務(wù)以服務(wù)器或虛擬機(VM)為池化對象,網(wǎng)絡(luò)負責(zé)提供服務(wù)器或VM之間的連接,并聚焦業(yè)務(wù)部署效率及網(wǎng)絡(luò)自動化能力;而智算中心是服務(wù)于人工智能的數(shù)據(jù)計算中心,以GPU 等AI 訓(xùn)練芯片為主,并以提升單位時間、單位能耗下的運算能力和質(zhì)量為核心訴求,為AI 計算提供更大的計算規(guī)模和更快的計算速度。傳統(tǒng)數(shù)據(jù)中心通過CPU來執(zhí)行計算任務(wù),且網(wǎng)絡(luò)帶寬需求為10~100 Gbit/s,并通過使用傳輸控制協(xié)議(TCP)來完成內(nèi)存數(shù)據(jù)的讀取;而智算中心網(wǎng)絡(luò)主要用于承載AI 訓(xùn)練業(yè)務(wù),其GPU 算力與CPU 相比擁有更高的計算性能,且網(wǎng)絡(luò)帶寬需求為100~400 Gbit/s(甚至達到800 Gbit/s),并可以通過遠程直接內(nèi)存訪問(RDMA)來減少傳輸時延。由于RDMA 網(wǎng)絡(luò)對于丟包異常敏感,0.01%的丟包率就會使RDMA 吞吐率變?yōu)?,因此大模型訓(xùn)練的智算中心網(wǎng)絡(luò)需要縮短迭代過程中通信傳輸數(shù)據(jù)的時間,降低通信開銷,從而減少GPU 的計算等待,提升計算效率。綜上所述,零丟包、大帶寬、低時延、高可靠是智算中心網(wǎng)絡(luò)最為關(guān)鍵的特征。
2.2 智算中心網(wǎng)絡(luò)面臨的挑戰(zhàn)
與傳統(tǒng)數(shù)據(jù)中心不同,智算中心主要用于承載AI 模型訓(xùn)練業(yè)務(wù),其通信流量主要具備周期性、流量大、同步突發(fā)等特點。在大模型訓(xùn)練過程中,通信具有非常強的周期性,且每輪迭代的通信模式保持一致。在每一輪的迭代過程中,不同節(jié)點間的流量保持同步,同時流量以on-off的模式突發(fā)式傳輸。以上通信流量的特點對智算中心網(wǎng)絡(luò)提出了3 個需求:
1)高接入帶寬是基礎(chǔ)。大模型訓(xùn)練對帶寬比較敏感。網(wǎng)絡(luò)對通信影響最大的是序列化時延,網(wǎng)絡(luò)通信質(zhì)量主要取決于有效帶寬。但由于網(wǎng)絡(luò)交換的時間占比不高,靜態(tài)時延對模型訓(xùn)練效率影響不大。
2)網(wǎng)絡(luò)級負載均衡是關(guān)鍵。保證通信的有效帶寬是模型訓(xùn)練的關(guān)鍵因素之一。負載均衡技術(shù)是保證有效帶寬的關(guān)鍵。集合操作通信的完成時間由最慢節(jié)點的完成時間決定。在無阻塞網(wǎng)絡(luò)中,若鏈路負載不均衡,則會導(dǎo)致沖突流有效帶寬下降,沖突流的序列化時間增加。
3)高健壯網(wǎng)絡(luò)是保障。網(wǎng)絡(luò)持續(xù)高可用、故障業(yè)務(wù)無中斷是分布式系統(tǒng)運行的基礎(chǔ)。在高健壯網(wǎng)絡(luò)中,鏈路故障時網(wǎng)絡(luò)會達到亞毫秒級的自動收斂,降低了網(wǎng)絡(luò)故障對網(wǎng)絡(luò)擁塞的影響。
如今,基于融合以太網(wǎng)承載遠程直接內(nèi)存訪問(RoCE)協(xié)議的智算中心網(wǎng)絡(luò),通常采用五元組哈希實現(xiàn)鏈路負載分擔(dān)技術(shù),以及基于優(yōu)先級的流量控制(PFC)、顯式擁塞通告(ECN)協(xié)議實現(xiàn)網(wǎng)絡(luò)無損,該方案對智算中心網(wǎng)絡(luò)提出4個挑戰(zhàn):
挑戰(zhàn)1:傳統(tǒng)基于逐流的等價多路徑路由(ECMP)負載均衡技術(shù)在流量數(shù)小的情況下會失效,導(dǎo)致流量在交換網(wǎng)絡(luò)發(fā)生極化,鏈路負載不均。當智算中心網(wǎng)絡(luò)中存在大象流時,很容易發(fā)生多個流被散列到相同的路徑上的情況,從而導(dǎo)致鏈路過載,造成某個物理鏈路負載過大,甚至?xí)霈F(xiàn)擁塞而導(dǎo)致報文丟棄。
挑戰(zhàn)2:隨著網(wǎng)絡(luò)規(guī)模的不斷提升,報文交換方式由單網(wǎng)絡(luò)節(jié)點內(nèi)實現(xiàn)到單網(wǎng)絡(luò)節(jié)點間多跳實現(xiàn)轉(zhuǎn)變,各節(jié)點間也從松耦合關(guān)系變化為聯(lián)合轉(zhuǎn)發(fā)。業(yè)界通過Clos架構(gòu)搭建大規(guī)模分布式轉(zhuǎn)發(fā)結(jié)構(gòu)來滿足日益增長的轉(zhuǎn)發(fā)規(guī)模需求。在該架構(gòu)下,各節(jié)點分布式運行和自我決策轉(zhuǎn)發(fā)路徑導(dǎo)致無法完全感知全局信息和實現(xiàn)最優(yōu)的整網(wǎng)性能。
挑戰(zhàn)3:當前流量進入網(wǎng)絡(luò)時,在不考慮出端口轉(zhuǎn)發(fā)能力的情況下,流量會以“推”的方式進入網(wǎng)絡(luò)。分布式訓(xùn)練的多對一通信模型產(chǎn)生大量In-cast 流量,造成設(shè)備內(nèi)部隊列緩存的瞬時突發(fā)而導(dǎo)致?lián)砣踔羴G包,造成應(yīng)用時延的增加和吞吐的下降。PFC 和ECN 都是擁塞產(chǎn)生后的事后干預(yù)的被動擁塞控制機制,它們無法從根本上避免擁塞。
挑戰(zhàn)4:AI 訓(xùn)練網(wǎng)絡(luò)是一個封閉的專用網(wǎng)絡(luò),針對訓(xùn)練效率,通過Underlay直接承載AI訓(xùn)練任務(wù),不再劃分Overlay 平面,使傳統(tǒng)SDN 能力失效。同時,傳統(tǒng)的智能流分析技術(shù)已無法滿足高性能無損網(wǎng)絡(luò)隱患識別、故障預(yù)測和閉環(huán)等運維可視化需求。
2.3 智算中心網(wǎng)絡(luò)的演進趨勢
綜合當前所面臨的挑戰(zhàn),未來智算中心網(wǎng)絡(luò)將向3個方向進行演進:一是從“流”分發(fā)到“包”分發(fā)演進,即通過提供逐報文容器動態(tài)負載均衡機制,消除哈希極化問題,實現(xiàn)單流多路徑負載分擔(dān),提升有效帶寬,降低長尾時延;二是從“局部”決策到“全局”調(diào)度演進,即實現(xiàn)全局視野的轉(zhuǎn)發(fā)調(diào)度機制,并實現(xiàn)集中式管理運維、分布式控制轉(zhuǎn)發(fā),提高網(wǎng)絡(luò)可用性;三是從“推”流到“拉”流演進,即從被動擁塞控制向依賴“授權(quán)請求”和“響應(yīng)機制”的主動流控轉(zhuǎn)變,最大限度地避免網(wǎng)絡(luò)擁塞產(chǎn)生,同時需要引入全局集中式管理系統(tǒng),提升網(wǎng)絡(luò)自動化及可視化能力。
基于以上面向未來智算中心的三大演進方向,我們創(chuàng)新性地提出一種全調(diào)度以太網(wǎng)(GSE)技術(shù)方案,打造無阻塞、高帶寬、低時延、自動化的新型智算中心網(wǎng)絡(luò),助力AIGC等高性能業(yè)務(wù)快速發(fā)展[4]。
3 新型GSE架構(gòu)體系
3.1 GSE架構(gòu)介紹
為打造無阻塞、高帶寬、低時延的高性能網(wǎng)絡(luò),GSE架構(gòu)應(yīng)運而生,如圖1所示。該架構(gòu)主要包括計算層、網(wǎng)絡(luò)層和控制層3 個層級,包含計算節(jié)點、網(wǎng)絡(luò)邊緣處理節(jié)點(GSP)、網(wǎng)絡(luò)核心交換節(jié)點(GSF)及全調(diào)度操作系統(tǒng)(GSOS)4類設(shè)備[4]。
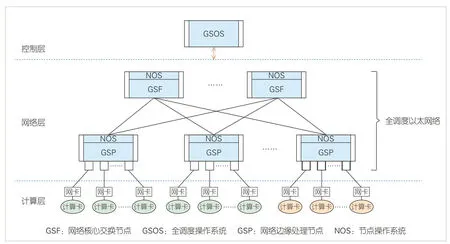
▲圖1 全調(diào)度以太網(wǎng)(GSE)技術(shù)體系分層架構(gòu)
1)控制層:包含全局集中式GSOS,以及GSP和GSF設(shè)備端分布式節(jié)點操作系統(tǒng)(NOS)。其中,集中式GSOS用于提供網(wǎng)絡(luò)全局信息,實現(xiàn)基于全局信息編址、日常運維管理等功能;設(shè)備端NOS 可實現(xiàn)動態(tài)負載均衡、動態(tài)全局調(diào)度隊列(DGSQ)調(diào)度等分布式網(wǎng)絡(luò)管控功能。
2)網(wǎng)絡(luò)層:GSE 網(wǎng)絡(luò)主要實現(xiàn)GSP 和GSF 協(xié)同,構(gòu)建出具備全局流量調(diào)度、鏈路負載均衡、流量精細反壓等技術(shù)融合的交換網(wǎng)絡(luò)。其中,F(xiàn)abric 部分可支持二層GSF 擴展,以滿足更大規(guī)模組網(wǎng)需求。
3)計算層:即GSE 網(wǎng)絡(luò)服務(wù)層,包含高性能計算卡(GPU 或CPU)及網(wǎng)卡,初期將計算節(jié)點作為全調(diào)度以太網(wǎng)邊界,僅通過優(yōu)化交換網(wǎng)絡(luò)能力提升計算集群訓(xùn)練性能。未來計算將與網(wǎng)絡(luò)深度融合,以進一步提升高性能計算能力。
GSE 3 層架構(gòu)涉及計算節(jié)點、GSP、GSF 及GSOS 4 類設(shè)備,各設(shè)備分工如下:
1)計算節(jié)點:即服務(wù)器側(cè)的計算卡、網(wǎng)卡,提供高性能計算能力。
2)GSP:即網(wǎng)絡(luò)邊緣處理節(jié)點,用以接入計算流量,并對流量做全局調(diào)度;流量上行時具備動態(tài)負載均衡能力,流量下行時具備流量排序能力。
3)GSF:即網(wǎng)絡(luò)核心交換節(jié)點,作為GSP 的上一層級設(shè)備,用于靈活擴展網(wǎng)絡(luò)規(guī)模,具備動態(tài)負載均衡能力,以及反壓信息發(fā)布能力。
4)GSOS:即全調(diào)度操作系統(tǒng),提供整網(wǎng)管控的集中式網(wǎng)絡(luò)操作系統(tǒng)能力。
3.2 GSE技術(shù)三大核心理念
3.2.1 基于報文容器的轉(zhuǎn)發(fā)及負載分擔(dān)機制
智算中心網(wǎng)絡(luò)通常采用胖樹(Fat-Tree)架構(gòu),任意出入端口之間存在多條等價轉(zhuǎn)發(fā)路徑。與云數(shù)據(jù)中心業(yè)務(wù)流量不同,智算業(yè)務(wù)流量具有“數(shù)量少,單流大”的特點。傳統(tǒng)以太網(wǎng)逐流負載分擔(dān)方式導(dǎo)致鏈路利用率不均,從而引起網(wǎng)絡(luò)擁塞。單流多路徑是提升智算中心網(wǎng)絡(luò)有效帶寬、避免網(wǎng)絡(luò)擁塞的關(guān)鍵技術(shù)手段。業(yè)界傳統(tǒng)網(wǎng)絡(luò)中實現(xiàn)單流多路徑的技術(shù)方案包括切包交換、逐包交換和組包交換。
1)切包交換:核心思想是在網(wǎng)絡(luò)入口將數(shù)據(jù)包邏輯切分成若干個信元,將屬于同一個數(shù)據(jù)包的信元調(diào)度到不同路徑進行傳輸,在網(wǎng)絡(luò)出口側(cè)對信元進行排序及重組,如圖2所示。該方式可充分利用多路徑交換能力,最大程度實現(xiàn)鏈路負載均衡。但在高帶寬演進趨勢下,由于被切分后的信元長度短,信元頭部開銷帶來較多的帶寬損耗,且極高的均衡調(diào)度頻率對硬件有較高的要求。
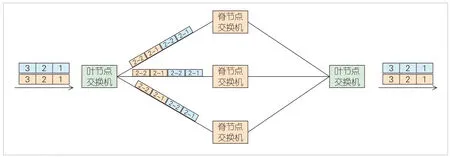
▲圖2 切包交換示意圖
2)逐包交換:核心思想是不對數(shù)據(jù)包進行處理,直接通過輪詢或權(quán)重等機制將數(shù)據(jù)包發(fā)往不同路徑進行傳輸,在網(wǎng)絡(luò)出口側(cè)對報文進行排序,如圖3所示。該方式不存在額外的報文開銷,也無需高頻的均衡調(diào)度周期。但由于數(shù)據(jù)包長度分布連續(xù),難以準確根據(jù)已發(fā)往每條路徑的數(shù)據(jù)包總數(shù)據(jù)量來實現(xiàn)均衡負載,鏈路負載均衡性差,易受微突發(fā)影響導(dǎo)致網(wǎng)絡(luò)擁塞甚至丟包。
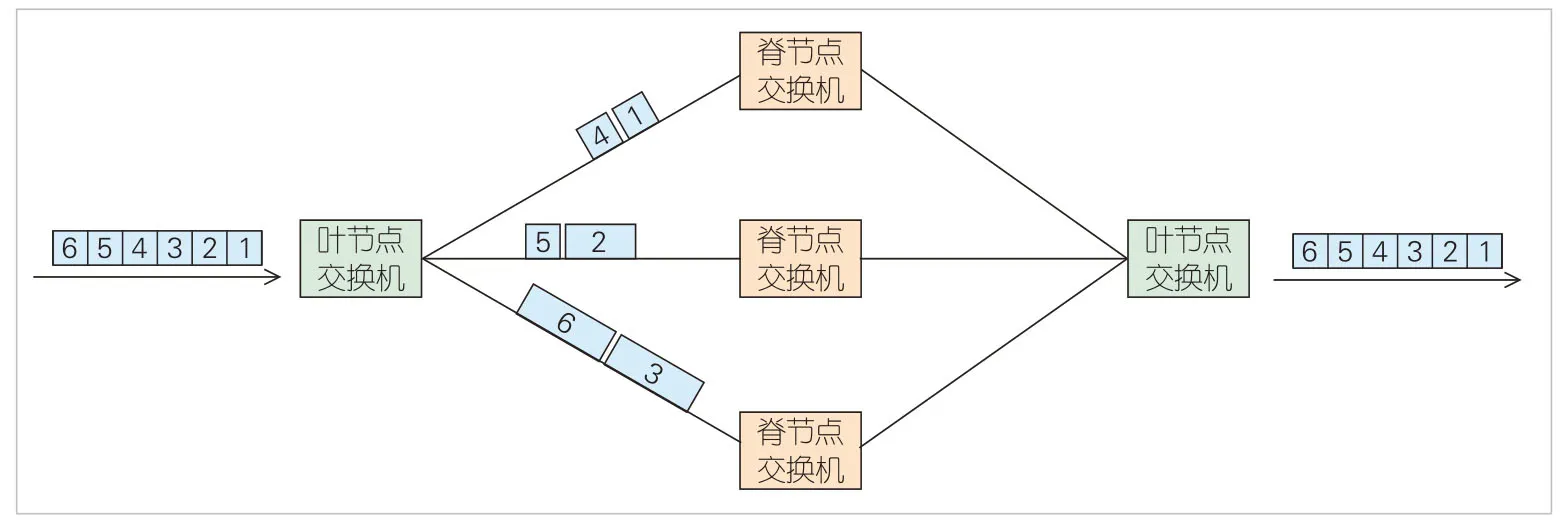
▲圖3 逐包交換示意圖
3)組包交換:核心思想是將數(shù)據(jù)包組裝成定長且長度較長的數(shù)據(jù)幀,并為數(shù)據(jù)幀添加幀頭(用于組裝和還原)。當數(shù)據(jù)包不足以填充一個大幀時,就需要填充冗余數(shù)據(jù)成幀,并利用網(wǎng)絡(luò)各節(jié)點對大數(shù)據(jù)幀進行存儲轉(zhuǎn)發(fā),如圖4所示。該方式下大幀均衡調(diào)度的周期短,可適應(yīng)高帶寬的轉(zhuǎn)發(fā)需求。但幀頭及冗余數(shù)據(jù)填充及存儲轉(zhuǎn)發(fā)機制會帶來一定程度的帶寬和時延損耗。
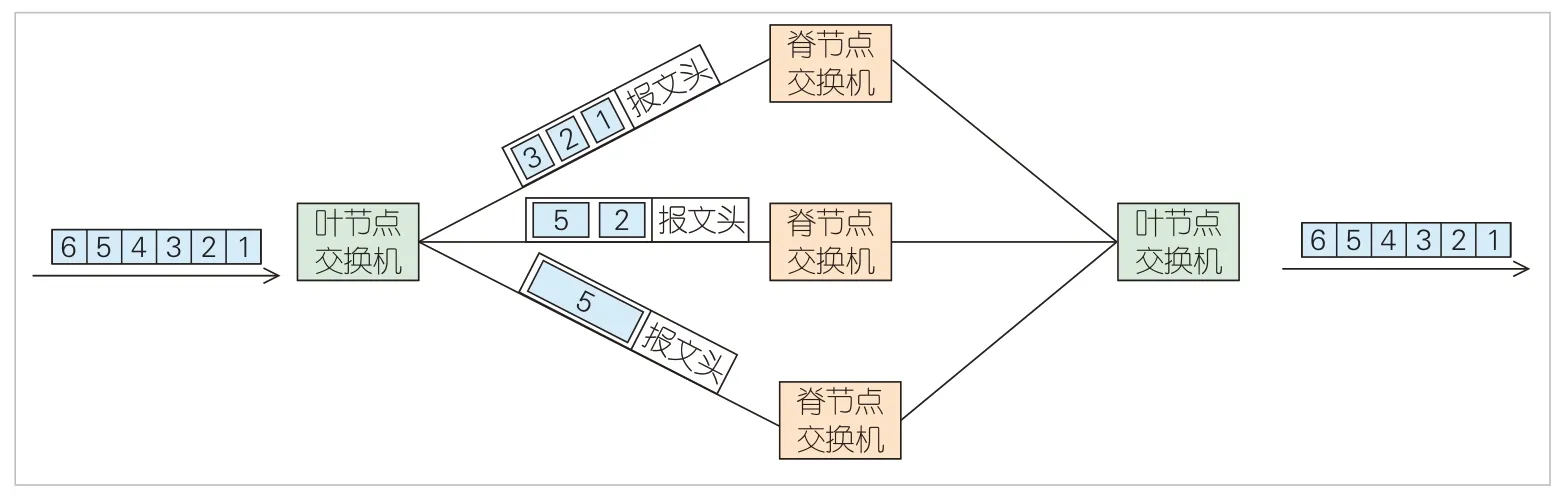
▲圖4 組包交換示意圖
基于上述分析,面向后續(xù)智算中心高帶寬、低時延的網(wǎng)絡(luò)需求,并結(jié)合逐包交換方式下即來即轉(zhuǎn)的低時延特性、組包交換方式下的高帶寬特性,本文在GSE 技術(shù)架構(gòu)中提出一種基于報文容器(PKTC)的轉(zhuǎn)發(fā)及負載分擔(dān)機制。該機制根據(jù)最終設(shè)備或設(shè)備出端口,將數(shù)據(jù)包邏輯分組,并組裝成長度較長的“定長”容器進行轉(zhuǎn)發(fā)。屬于同一個報文容器的數(shù)據(jù)包被標記為相同的容器標識,沿著相同路徑進行轉(zhuǎn)發(fā),以保證同屬于一個報文容器的數(shù)據(jù)包保序傳輸,如圖5所示。
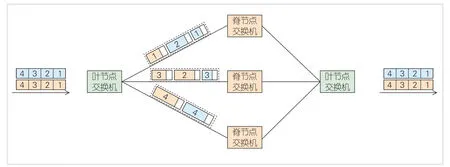
▲圖5 報文容器轉(zhuǎn)發(fā)示意圖
3.2.2 基于報文容器的DGSQ 全局調(diào)度技術(shù)
分布式高性能應(yīng)用的特征是多對一通信的In-cast 流量模型。如果這種流量是短暫的,在出口處可以通過一定的Buffer進行吸收;如果時間持續(xù)過長且多個入口的流量相加遠大于出口的線速帶寬,為了避免丟包,出口設(shè)備需啟用反壓機制保護流量。而反壓一旦出現(xiàn),網(wǎng)絡(luò)的轉(zhuǎn)發(fā)性能就會大幅度下降,從而損害分布式應(yīng)用的性能。
DCQCN目前是RDMA網(wǎng)絡(luò)應(yīng)用最廣泛的擁塞控制算法,也是典型的被動擁塞控制算法。發(fā)送端根據(jù)接收到的擁塞通知報文(CNP)動態(tài)調(diào)整發(fā)送速率。由于1個比特的ECN信號僅能定性表示網(wǎng)絡(luò)產(chǎn)生擁塞,但無法定量地表示擁塞程度,所以端側(cè)需要探測式調(diào)整發(fā)送速率。此外,收斂速度慢會導(dǎo)致網(wǎng)絡(luò)吞吐性能下降。解決網(wǎng)絡(luò)擁塞丟包最直接的手段是防止過多的數(shù)據(jù)注入到網(wǎng)絡(luò)中造成擁塞,保證網(wǎng)絡(luò)中任意設(shè)備端口緩存或鏈路容量不會過載。
如圖6所示,GSP1的A1口和GSP3的A3口同時向GSP2的A2口發(fā)送流量,且流量相加大于A2的出口帶寬。這造成A2 口出口隊列擁塞。這種情況僅通過負載均衡是無法規(guī)避的,需要全局控制保證送到A2 的流量不超過其出口帶寬。因此,引入基于全局的轉(zhuǎn)發(fā)技術(shù)和基于DGSQ 的調(diào)度技術(shù),才可實現(xiàn)全局流量的調(diào)度控制。
在負載均衡調(diào)度時,報文容器被作為轉(zhuǎn)發(fā)單位。但由于報文是邏輯組裝,無需額外的硬件開銷來對數(shù)據(jù)包進行組裝和還原。在網(wǎng)絡(luò)中轉(zhuǎn)發(fā)時添加的報文容器標識,仍以數(shù)據(jù)包的形式傳輸,且無冗余數(shù)據(jù)填充的問題,帶寬損耗小。
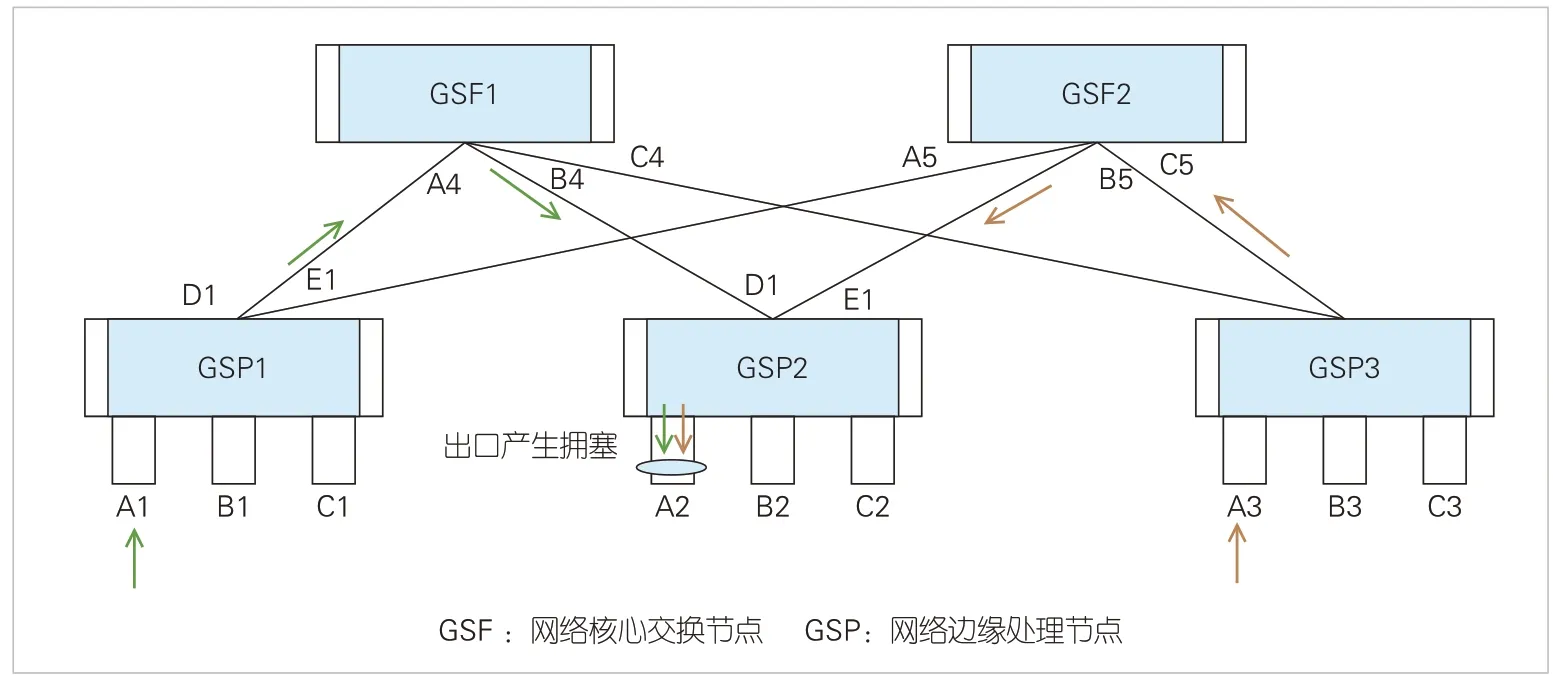
▲圖6 網(wǎng)絡(luò)In-cast流量發(fā)生場景
基于DGSQ 的全局調(diào)度技術(shù)如圖7 所示,在GSP 上建立網(wǎng)絡(luò)中所有設(shè)備出口的虛擬隊列,用以實現(xiàn)本GSP節(jié)點到對應(yīng)所有出端口的流量調(diào)度。本GSP節(jié)點的DGSQ調(diào)度帶寬依賴授權(quán)請求和響應(yīng)機制,由最終的設(shè)備出口、途經(jīng)的設(shè)備統(tǒng)一進行全網(wǎng)端到端授權(quán)。由于中間節(jié)點的流量壓力差異,GSP 去往最終目的端口不再通過等價多路徑路由(ECMP)(路徑授權(quán)權(quán)重選擇路徑,而是需要基于授予的權(quán)重在不同的路徑上進行流量調(diào)度。這種方式可保證全網(wǎng)中前往任何一個端口的流量既不會超過該端口的負載能力,也不會超出中間任一網(wǎng)絡(luò)節(jié)點的轉(zhuǎn)發(fā)能力,可降低網(wǎng)絡(luò)中In-cast 流量產(chǎn)生的概率,減少全網(wǎng)內(nèi)部反壓機制的產(chǎn)生。
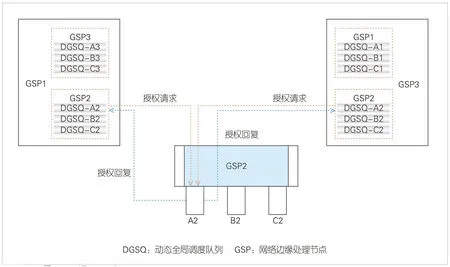
▲圖7 基于DGSQ調(diào)度流程
基于PKTC 的負載均衡技術(shù)和DGSQ 全局調(diào)度技術(shù)在平穩(wěn)狀態(tài)下可很好地進行流量調(diào)控與分配。但在微突發(fā)、鏈路故障等異常場景下,短時間內(nèi)網(wǎng)絡(luò)還是會產(chǎn)生擁塞,這時仍需要依賴反壓機制來抑制源端的流量發(fā)送。傳統(tǒng)PFC 或FC都是點到點的局部反壓技術(shù),一旦觸發(fā)擴散到整個網(wǎng)絡(luò)中,會引起頭阻HoL、網(wǎng)絡(luò)風(fēng)暴等問題。全調(diào)度以太網(wǎng)技術(shù)需要精細的反壓機制來守護網(wǎng)絡(luò)的防線,通過最小的反壓代價來實現(xiàn)網(wǎng)絡(luò)的穩(wěn)定負載。
3.2.3 全調(diào)度以太網(wǎng)的GSOS
綜合考慮分布式NOS、集中式SDN 控制器的優(yōu)勢,全調(diào)度以太網(wǎng)的GSOS 分為全調(diào)度控制器、設(shè)備側(cè)NOS 兩大部分,可全面提升GSE 網(wǎng)絡(luò)自動化及可視化能力。
GSP和GSF的盒式設(shè)備支持獨立部署NOS,有助于構(gòu)建出分布式網(wǎng)絡(luò)操作系統(tǒng)。每臺GSP和GSF 具備獨立的控制面和管理面,可以運行屬于設(shè)備自身的網(wǎng)絡(luò)功能,提升系統(tǒng)可靠性,降低部署難度。分布式NOS 可以將單點設(shè)備故障限制在局部范圍,避免對整網(wǎng)造成影響。
集中式GSOS 提供更好的網(wǎng)絡(luò)全局信息,簡化基于全局端口信息的DGSQ系統(tǒng)的建立和維護。同時GSOS 也是整網(wǎng)運維監(jiān)控的大腦,可協(xié)同設(shè)備實現(xiàn)對實時路徑、歷史的記錄及呈現(xiàn),以支撐網(wǎng)絡(luò)運維。
3.3 GSE網(wǎng)絡(luò)工作機制
GSE 交換網(wǎng)絡(luò)采用定長的PKTC 進行報文轉(zhuǎn)發(fā)及動態(tài)負載均衡,通過構(gòu)建基于PKTC 的DGSQ 全調(diào)度機制、精細的反壓機制和無感知自愈機制,實現(xiàn)微突發(fā)及故障場景下的精準控制,全面提升網(wǎng)絡(luò)有效帶寬和轉(zhuǎn)發(fā)延遲穩(wěn)定性。相關(guān)的具體端到端轉(zhuǎn)發(fā)流程圖9所示。
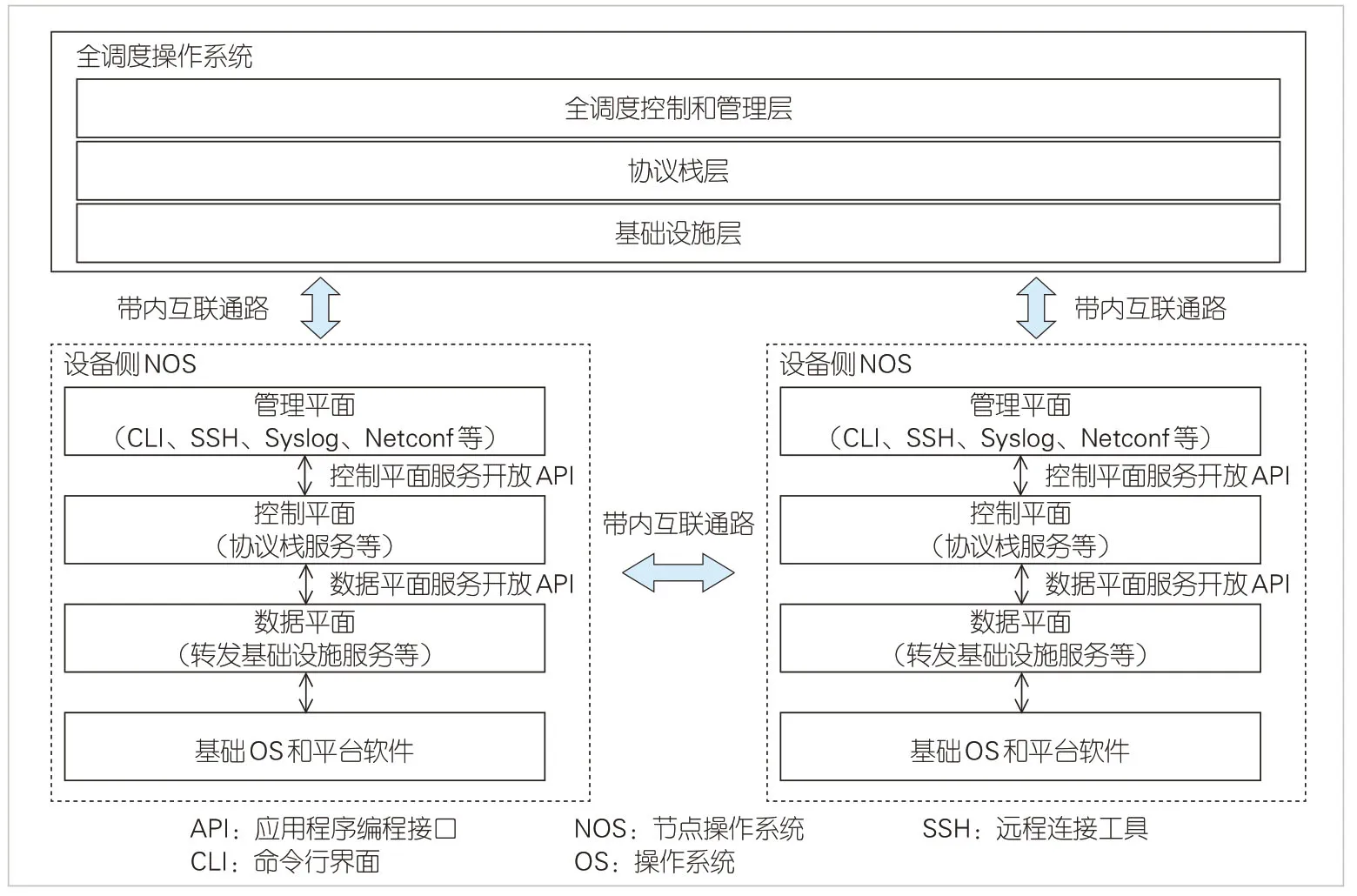
▲圖8 全調(diào)度以太網(wǎng)操作系統(tǒng)架構(gòu)
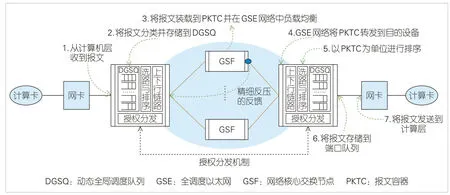
▲圖9 GSE網(wǎng)絡(luò)端到端流量轉(zhuǎn)發(fā)示意圖
1)源端GSP 設(shè)備從計算側(cè)收到報文后,通過轉(zhuǎn)發(fā)表找到最終出口,并基于最終出口按需將報文分配到對應(yīng)的DGSQ中進行授權(quán)調(diào)度。
2)源端GSP 設(shè)備獲得授權(quán)后,遵循PKTC 的負載均衡要求,將報文發(fā)送到GSE網(wǎng)絡(luò)中。
3)當?shù)竭_目的端GSP 設(shè)備后,報文先進行PKTC 級別的排序,再通過轉(zhuǎn)發(fā)表存儲到物理端口對應(yīng)隊列,最終通過端口調(diào)度發(fā)送到計算節(jié)點。
作為一種標準開放的新型以太網(wǎng)技術(shù),GSE可采用網(wǎng)卡側(cè)無感知的組網(wǎng)方案,即網(wǎng)絡(luò)側(cè)采用GSE技術(shù)方案,網(wǎng)卡側(cè)仍采用傳統(tǒng)RoCE 網(wǎng)卡。此外,也可以結(jié)合網(wǎng)卡能力演進,將GSE方案各組件的功能在網(wǎng)絡(luò)組件中重新分工,將部分或全部網(wǎng)絡(luò)功能下沉到網(wǎng)卡側(cè)來實現(xiàn)。也就是說,在未來的實際應(yīng)用中,可以將GSP的功能全部下沉到網(wǎng)卡以提供端到端的方案,也可以將網(wǎng)絡(luò)的起終點分別落在網(wǎng)絡(luò)設(shè)備和網(wǎng)卡上,為后續(xù)網(wǎng)絡(luò)建設(shè)和設(shè)備選型提供靈活的可選方案。
4 結(jié)束語
新型智算中心網(wǎng)絡(luò)技術(shù)已逐漸成為全球創(chuàng)新焦點。智算中心網(wǎng)絡(luò)是一個多要素融合的復(fù)雜系統(tǒng),是算網(wǎng)的深度融合,它依賴于AI 業(yè)務(wù)、網(wǎng)絡(luò)設(shè)備、交換芯片、網(wǎng)卡、儀表等上下游產(chǎn)業(yè)的協(xié)同創(chuàng)新。如何提升網(wǎng)絡(luò)規(guī)模和性能,構(gòu)建超大規(guī)模、超高帶寬、超低時延的高性能智算中心網(wǎng)絡(luò),是提升算力水平的關(guān)鍵。
GSE面向無損、高帶寬、超低時延等高性能網(wǎng)絡(luò)需求業(yè)務(wù)場景,兼容以太網(wǎng)生態(tài)鏈,通過采用全調(diào)度轉(zhuǎn)發(fā)機制、基于PKTC 的負載均衡技術(shù)、基于DGSQ 的全調(diào)度技術(shù)、精細的反壓機制、無感知自愈機制、集中管理及分布式控制等技術(shù),實現(xiàn)低時延、無阻塞、高帶寬的新型智算中心網(wǎng)絡(luò)[4]。該技術(shù)架構(gòu)旨在構(gòu)建一個標準開放的高性能網(wǎng)絡(luò)技術(shù)體系,助力AIGC等高性能產(chǎn)業(yè)快速發(fā)展。由于該架構(gòu)創(chuàng)新難度大、開發(fā)周期長,我們希望各個行業(yè)能夠攜手合作,持續(xù)推動相關(guān)技術(shù)標準發(fā)展。
