基于MRMR-SSA-BP的PM2.5濃度預(yù)測(cè)模型
2023-09-20 11:25:30張一準(zhǔn)顏七笙
計(jì)算機(jī)仿真 2023年8期
關(guān)鍵詞:模型
張一準(zhǔn),顏七笙
(1. 東華理工大學(xué)地球科學(xué)學(xué)院,江西 南昌 330199;2. 東華理工大學(xué)理學(xué)院,江西 南昌 330199)
1 引言
隨著世界范圍內(nèi)的經(jīng)濟(jì)和工業(yè)化的快速發(fā)展,空氣污染的問(wèn)題日益加劇,城市空氣質(zhì)量問(wèn)題已經(jīng)嚴(yán)重影響到居民的正常生活和幸福指數(shù)。2021年“十四五”開(kāi)局之年,各省和地區(qū)相繼推出生態(tài)環(huán)境保護(hù)規(guī)劃,堅(jiān)持以改善生態(tài)環(huán)境為核心,加快推動(dòng)綠色發(fā)展,而空氣質(zhì)量問(wèn)題是其中重點(diǎn)要解決的問(wèn)題。PM2.5濃度是衡量空氣質(zhì)量的一項(xiàng)重要指標(biāo),我國(guó)早已于2012年在《環(huán)境空氣質(zhì)量標(biāo)準(zhǔn)》新增PM2.5檢測(cè)指標(biāo)[1],因此尋求精確預(yù)測(cè)PM2.5濃度的方法對(duì)“十四五”空氣質(zhì)量改善行動(dòng)計(jì)劃具有重大的意義。
目前PM2.5的預(yù)測(cè)方法主要有統(tǒng)計(jì)、數(shù)值以及機(jī)器學(xué)習(xí)等方法[2]。在統(tǒng)計(jì)模型中,如徐東等[3]基于多元線(xiàn)性回歸模型對(duì)成都市PM2.5的趨勢(shì)進(jìn)行了預(yù)測(cè)研究,彭斯俊等[4]基于A(yíng)RIMA模型對(duì)PM2.5的濃度進(jìn)行預(yù)測(cè),但預(yù)測(cè)精度有待提高,因?yàn)榻y(tǒng)計(jì)模型通常要求數(shù)據(jù)具有正態(tài)分布或平穩(wěn)等特性,不適宜直接用于污染物濃度的預(yù)測(cè)[5]。數(shù)值模型是以大氣動(dòng)力學(xué)理論為基礎(chǔ),基于對(duì)大氣物理和化學(xué)過(guò)程的理解,建立的大氣污染度在空氣中的輸送擴(kuò)散模型[6],如周廣強(qiáng)[7]等基于WRF-Chem模式降水對(duì)上海PM2.5預(yù)報(bào)的影響預(yù)測(cè),但是數(shù)值模型的準(zhǔn)確性嚴(yán)重依賴(lài)于需要不斷更新的排放源清單,預(yù)測(cè)地點(diǎn)的地理特點(diǎn)的復(fù)雜性以及污染物大氣過(guò)程的復(fù)雜性都使得預(yù)測(cè)模型的實(shí)現(xiàn)復(fù)雜化[8]。而新興的機(jī)器學(xué)習(xí)模型則在PM2.5濃度的預(yù)測(cè)上展現(xiàn)出更好的效果,如李志生[9]等根據(jù)多種樹(shù)模型進(jìn)行對(duì)比,確定LightGBM預(yù)測(cè)模型在其它樹(shù)模型中訓(xùn)練更快,占用內(nèi)存更少,準(zhǔn)確率更好的優(yōu)點(diǎn),但LightGBM模型是基于偏差的算法,對(duì)噪點(diǎn)數(shù)據(jù)敏感,也可能會(huì)產(chǎn)生較深的決策樹(shù),從而導(dǎo)致模型過(guò)擬合,為了彌補(bǔ)單一模型的不足[10],許多學(xué)者開(kāi)始嘗試組合多個(gè)模型來(lái)對(duì)PM2.5濃度進(jìn)行預(yù)測(cè),例如李建新[11]等利用混合核函數(shù)(HK)對(duì)傳統(tǒng)的支持向量機(jī)(SVM)模型進(jìn)行改進(jìn)構(gòu)造的MRMR-HK-SVM模型預(yù)測(cè)PM2.5濃度,相較于原始的SVM模型,擬合程度較高,具有較好的泛化能力。
但在現(xiàn)有的PM2.5濃度預(yù)測(cè)模型中仍存在以下問(wèn)題:
1)現(xiàn)有的預(yù)測(cè)PM2.5濃度的組合模型中,大多數(shù)模型都只是模型簡(jiǎn)單的疊加,第一個(gè)模型的輸出作為第二個(gè)模型的輸入進(jìn)行預(yù)測(cè),或者模型多線(xiàn)性排列,最后的預(yù)測(cè)結(jié)果累加求均值,并沒(méi)有真正的提升和改善模型。
2)預(yù)測(cè)PM2.5濃度特征值的選取較為單一,例如黃婕[12]在對(duì)PM2.5濃度預(yù)測(cè)研究中僅以時(shí)空特征作為輸入,沒(méi)有考慮氣象因子和其它污染物對(duì)PM2.5濃度變化的影響。在空氣質(zhì)量的預(yù)測(cè)研究領(lǐng)域中,LEE et al[13]選擇了歷史污染物和氣象數(shù)據(jù)來(lái)預(yù)測(cè)空氣質(zhì)量,準(zhǔn)確率得到明顯的提升。方曉婷[14]等人研究結(jié)果表明氣溫,濕度,風(fēng)速及風(fēng)向?qū)M2.5濃度有較大影響。所以在現(xiàn)有的PM2.5濃度預(yù)測(cè)研究中,PM2.5濃度的影響因子考慮的不夠全面。
3)PM2.5的影響因素眾多,每個(gè)影響因素對(duì)PM2.5濃度的影響都不相同,有的因素對(duì)PM2.5濃度變化的關(guān)系密切,有的因素對(duì)PM2.5濃度變化無(wú)明顯交集,現(xiàn)有研究總是把所有的影響因素作為模型的輸入來(lái)進(jìn)行仿真預(yù)測(cè),難免會(huì)對(duì)最后的結(jié)果造成較大的誤差。
綜上,本文選擇了適合求解內(nèi)部機(jī)制復(fù)雜問(wèn)題的BP神經(jīng)網(wǎng)絡(luò)作為基礎(chǔ)模型,用麻雀搜索算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的初始權(quán)值和閾值,提高BP神經(jīng)網(wǎng)絡(luò)訓(xùn)練的速度和精度,用最大相關(guān)最小冗余算法從從歷史污染物和氣象數(shù)據(jù)PM2.5、PM10、SO2、NO2、CO、O3、風(fēng)向、平均氣壓、風(fēng)速、平均氣溫、相對(duì)濕度等11個(gè)影響因子提取出最優(yōu)影響特征值作為模型的輸入,構(gòu)建成MRMR-SSA-BP模型,該模型能有效的彌補(bǔ)現(xiàn)有研究的不足和缺點(diǎn),為PM2.5濃度預(yù)測(cè)提供了一種新方向。
2 研究區(qū)域和數(shù)據(jù)
2.1 研究區(qū)域
濟(jì)南市位于山東省的中西部,南依泰山,北跨黃河,地處魯中南低山丘陵與魯西北沖積平原的交接帶上,地勢(shì)南高北低,導(dǎo)致熱島效應(yīng)嚴(yán)重,風(fēng)速小,污染物不易于吹散。因?yàn)槌鞘薪?jīng)濟(jì)發(fā)展,燃煤煙塵,工業(yè)粉塵和垃圾、風(fēng)沙及車(chē)輛行駛的揚(yáng)塵日益增多,導(dǎo)致濟(jì)南市的空氣質(zhì)量在發(fā)布質(zhì)量周報(bào)的城市中長(zhǎng)時(shí)間居于倒數(shù)十名內(nèi)。在2019年更被生態(tài)環(huán)境部評(píng)為環(huán)境質(zhì)量較差城市之一。
2.2 數(shù)據(jù)來(lái)源
本文的歷史空氣污染數(shù)據(jù)來(lái)源于中國(guó)空氣質(zhì)量在線(xiàn)監(jiān)測(cè)分析平臺(tái)(https:∥www.aqistudy.cn/historydata/about.php),氣象天氣數(shù)據(jù)來(lái)源于中國(guó)氣象數(shù)據(jù)網(wǎng)(http:∥data.cma.cn)。分別采集了2019年1月1日至2019年12月31日的PM2.5、PM10、SO2、NO2、CO、O3、風(fēng)向、平均氣壓、風(fēng)速、平均氣溫、相對(duì)濕度的數(shù)據(jù)。總共365組數(shù)據(jù),所有數(shù)據(jù)均為日平均值。其中2019年1月1日至2019年11月30日為訓(xùn)練數(shù)據(jù),2019年12月1日至12月31日為測(cè)試數(shù)據(jù)。
3 預(yù)測(cè)模型
3.1 最大相關(guān)最小冗余算法
最大相關(guān)最小冗余算法(Max-Relevance and Min-Re-dundancy,MRMR)最早由彭漢川[15]等提出用來(lái)提取最優(yōu)特征值。可以使用互信息在特征集合中找出與結(jié)果相關(guān)性最大,并且特征之間相關(guān)性最小的特征[16]。因?yàn)镻M2.5的濃度影響因素關(guān)系復(fù)雜,不排除本文選擇的特征值(PM10、PM2.5、SO2、NO2、CO、O3、風(fēng)向、平均氣壓、風(fēng)速、平均氣溫、相對(duì)濕度)中有相關(guān)性。所以用最大相關(guān)最小冗余算法來(lái)去除可能存在的數(shù)據(jù)冗余。互信息可以理解為一個(gè)變量中包含的關(guān)于另一個(gè)變量的信息量。假設(shè)兩個(gè)變量為X,Y則互信息為

(1)
式中:P(X)和P(Y)是變量X,Y的概率密度函數(shù),P(X,Y)是聯(lián)合概率函數(shù)。由式(1)可得互信息I(X;Y)和互信息I(Y;X)是相等的。互信息度量了兩個(gè)隨機(jī)變量之間共有的信息量程度,這個(gè)值越大,兩個(gè)變量之間的相關(guān)性越大[17]。
以互信息為基礎(chǔ),最大相關(guān)最小冗余算法可以根據(jù)最大統(tǒng)計(jì)依賴(lài)性準(zhǔn)則來(lái)選擇特征[18]。
MRMR算法的最大相關(guān)定義為

(2)
MRMR算法的最小冗余定義為

(3)
式中:S表示特征集合,c表示類(lèi)別。I(Xi;c)為特征與目標(biāo)的互信息,本文研究中表示的是11個(gè)特征值(PM10、PM2.5、SO2、NO2、CO、O3、風(fēng)向、平均氣壓、風(fēng)速、平均氣溫、相對(duì)濕度)和下一日的PM2.5的互信息,I(Xi;Xj)為11個(gè)特征值之間的互信息。
MRMR的特征選擇標(biāo)準(zhǔn)為
信息差

(4)
信息熵

(5)
式(4)是常用的整合準(zhǔn)則方式,故本文用式(4)整合優(yōu)化[19]。
3.2 麻雀搜索優(yōu)化BP網(wǎng)絡(luò)神經(jīng)模型(SSA-BP)
3.2.1 麻雀搜索優(yōu)化算法
麻雀搜索優(yōu)化算法(Sparrow Search Algorithm, SSA)是由薛建凱[20]在2020年受麻雀覓食行為和反捕食行為提出的,該算法收斂速度快,尋優(yōu)能力強(qiáng)。該算法的原理是在把麻雀分為發(fā)現(xiàn)者和追隨者,發(fā)現(xiàn)者本身適應(yīng)度高,搜索區(qū)域廣,在整個(gè)種群中負(fù)責(zé)搜索有豐富資源的區(qū)域。追隨者為了獲得好的適應(yīng)度,追隨者利用發(fā)現(xiàn)者來(lái)獲取資源。當(dāng)整個(gè)種群面臨捕食威脅時(shí),會(huì)立即進(jìn)行反捕食行為,發(fā)現(xiàn)者和追隨者身份可以動(dòng)態(tài)變化,但是所占種群數(shù)量的比重是不變的[21]。在SSA中發(fā)現(xiàn)者會(huì)優(yōu)先獲取資源,因?yàn)榘l(fā)現(xiàn)者負(fù)責(zé)整個(gè)麻雀種群尋找資源并為追隨者提供方向。因此發(fā)現(xiàn)者的位置更新描述為

(6)
式中:t是當(dāng)前迭代次數(shù);T為最大的迭代次數(shù);α為(0,1]的隨機(jī)數(shù);Q為一個(gè)正態(tài)分布隨機(jī)數(shù);R2和ST分別為預(yù)警值和安全值,預(yù)警值和安全值分別屬于[0,1]和[0.5,1]。當(dāng)R2 剩下的麻雀為追隨者,為了獲取好的適應(yīng)能力,其位置公式為 (7) 式中:A是一個(gè)1*j的矩陣,A+=AT(AAT)-1;XP是發(fā)現(xiàn)者在t+1這次迭代時(shí)的最優(yōu)位置,XW是當(dāng)前最差的位置。當(dāng)i>n/2時(shí),種群收斂時(shí)符合標(biāo)準(zhǔn)正態(tài)分布隨機(jī)數(shù),值會(huì)收斂于0,表明適應(yīng)度值較低的第i個(gè)追隨者沒(méi)有獲得食物,處于饑餓狀態(tài),需要轉(zhuǎn)移地點(diǎn)[22]。i<=n/2時(shí),為當(dāng)前迭代時(shí)的最優(yōu)位置加上該麻雀與最優(yōu)位置的每一維距離加減,將總值均分。即為在最優(yōu)位置附近隨機(jī)找一個(gè)位置,每一維距離最優(yōu)位置的方差將會(huì)變小。 當(dāng)面臨危險(xiǎn)時(shí),麻雀會(huì)進(jìn)行反捕食或者撤回,位置更新公式為: (8) 3.2.2 BP神經(jīng)網(wǎng)絡(luò) BP神經(jīng)網(wǎng)絡(luò)(Back Propagation Neural Network,BP)是反向傳播神經(jīng)算法。原理是一種基于誤差反向傳播的多層網(wǎng)絡(luò)。憑借其復(fù)雜模式分類(lèi)能力和多維函數(shù)映射能力取得廣泛的應(yīng)用,BP神經(jīng)網(wǎng)絡(luò)分為輸入層、隱含層和輸出層,采用經(jīng)驗(yàn)風(fēng)險(xiǎn)最小和梯度下降法來(lái)調(diào)整權(quán)值和閾值計(jì)算最優(yōu)值[23]。 圖1 BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu) 3.2.3 SSA-BP算法 為提高準(zhǔn)確度,采用SSA算法對(duì)BP神經(jīng)網(wǎng)絡(luò)的初始權(quán)值和閾值優(yōu)化來(lái)改善BP神經(jīng)網(wǎng)絡(luò)的性能。在本文的研究中為了提高BP神經(jīng)網(wǎng)絡(luò)的運(yùn)算精度,隱藏層選擇了三層。 基于MRMR-SAA-BP模型算法流程圖如圖2所示。 圖2 MRMR-SAA-BP模型流程圖 1)收集濟(jì)南市的氣象數(shù)據(jù)和歷史污染物數(shù)據(jù),預(yù)處理數(shù)據(jù),把因?yàn)闄C(jī)器故障缺少的數(shù)據(jù),用相鄰兩日的平均值填充。因?yàn)樘卣髦抵胁煌卣魅≈捣秶嗖钶^大,對(duì)數(shù)據(jù)進(jìn)行歸一化處理,提升訓(xùn)練速度。 2)通過(guò)最大相關(guān)最小冗余算法特征選擇選出最優(yōu)的特征子集。根據(jù)式(1)算出各項(xiàng)特征值之間的互信息和各項(xiàng)特征值與目標(biāo)值的互信息。根據(jù)式(2)算出特征值與目標(biāo)值得最大相關(guān)性,式(3)算出特征值之間相互的冗余。最后根據(jù)式(4)作為整合準(zhǔn)則,選出最優(yōu)的特征子集。 3)確定BP神經(jīng)網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)。為了提高BP神經(jīng)網(wǎng)絡(luò)的運(yùn)算精度和運(yùn)算速度,選擇合適的隱藏層節(jié)點(diǎn)數(shù)和層數(shù)。 4)根據(jù)麻雀搜索優(yōu)化算法算出適合初始權(quán)值和閾值。首先初始化種群和迭代次數(shù),根據(jù)式(6)更新發(fā)現(xiàn)者的位置描述,為追隨者提供覓食方向。追隨者為了獲得更好的適應(yīng)度,根據(jù)式(7)更新位置,同發(fā)現(xiàn)者爭(zhēng)奪食物,或圍繞在發(fā)現(xiàn)者周?chē)捠场.?dāng)麻雀的適應(yīng)度較低,處于種群邊緣,容易受到攻擊,所以根據(jù)式(8)fi≠fg一行,調(diào)整位置來(lái)躲避攻擊,而處在種群中央的麻雀會(huì)根據(jù)式(8)fi=fg一行,去接近它們相鄰的同伴,來(lái)盡量減少它們的危險(xiǎn)區(qū)域。因?yàn)檫m應(yīng)度越大,得到的優(yōu)化參數(shù)解最優(yōu),把相鄰GAP代種群的距離小于可接受的最小距離作為判斷是否終止的準(zhǔn)則,不再依賴(lài)最大進(jìn)化代數(shù),能自動(dòng)識(shí)別[24]。 5)BP神經(jīng)網(wǎng)絡(luò)獲取參數(shù),在歸一化的訓(xùn)練集上訓(xùn)練得到預(yù)測(cè)模型。 6)把歸一化的測(cè)試數(shù)據(jù)輸入到預(yù)測(cè)模型中,得到預(yù)測(cè)結(jié)果,計(jì)算出結(jié)果的平均絕對(duì)誤差,當(dāng)平均絕對(duì)誤差值小于預(yù)設(shè)值時(shí)為符合要求,輸出結(jié)果;當(dāng)平均絕對(duì)誤差值大于預(yù)設(shè)值時(shí),重新執(zhí)行4) 5)計(jì)算出BP的權(quán)值和閾值進(jìn)行預(yù)測(cè),極大的預(yù)防了模型陷入局部最優(yōu)解的情形。 7)最后根據(jù)式(9)(10)(11)算出均方根誤差,平均絕對(duì)誤差,R-square來(lái)進(jìn)行模型評(píng)價(jià)。 本文用3個(gè)評(píng)價(jià)指標(biāo)來(lái)評(píng)估模型,分別為均方根誤差RMSE,平均絕對(duì)誤差MAE,R-square。數(shù)學(xué)公式為 (9) (10) (11) RMSE,MAE,當(dāng)預(yù)測(cè)值與真實(shí)值完全吻合時(shí)等于0,及誤差越大,該值越大。R-square是擬合優(yōu)度的一個(gè)統(tǒng)計(jì)量。表示1減去y對(duì)回歸方程的方差與y的總方差的比值,值越大代表數(shù)據(jù)擬合度越好。 濟(jì)南的PM2.5時(shí)序圖如圖3所示,濟(jì)南市的PM2.5呈現(xiàn)出兩頭高中間低的U型圖像,在1月到3月和11月到12月PM2.5急劇升高。在夏季天氣比較熱時(shí)PM2.5濃度偏低,在冬季時(shí)PM2.5曾一度逼近300大關(guān)。圖中可以看出PM2.5具有季節(jié)性分布的特點(diǎn)。賀博文[25]等研究表明,承德市的PM2.5濃度夏季減少的原因可能是因?yàn)橄募酒戏捷^強(qiáng),加上較大的降水量很大程度上緩解PM2.5的污染,加上冬季的氣候條件,導(dǎo)致排放增加,造成PM2.5濃度增加。所以風(fēng)向是研究預(yù)測(cè)第二天PM2.5濃度的一個(gè)重要指標(biāo),所以本文研究中把風(fēng)向放進(jìn)了初始的11個(gè)研究指標(biāo)當(dāng)中。 圖3 濟(jì)南市PM2.5濃度時(shí)序圖 由表1可知,濟(jì)南市PM2.5濃度最低時(shí)達(dá)到了4 μg/m3,遠(yuǎn)遠(yuǎn)高出國(guó)家環(huán)境標(biāo)準(zhǔn),可以從夏季和冬季的各項(xiàng)指標(biāo)對(duì)比入手,找出夏季冬季PM2.5濃度差距巨大的原因,對(duì)PM2.5的管控治理具有現(xiàn)實(shí)意義。表1數(shù)據(jù)中除了風(fēng)速的標(biāo)準(zhǔn)差較小,表示除了風(fēng)速以外,其它的指標(biāo)因子波動(dòng)性較大,代表指標(biāo)數(shù)值有高度復(fù)雜性。 表1 濟(jì)南市2019年氣象和大氣污染物數(shù)據(jù)統(tǒng)計(jì)結(jié)果 本文對(duì)于PM2.5的預(yù)測(cè)確立了11個(gè)特征數(shù)據(jù),但是各項(xiàng)特征不僅對(duì)PM2.5濃度有相關(guān)性,它們互相之間可能也存在緊密的關(guān)系。如果直接默認(rèn)各項(xiàng)特征值之間相互獨(dú)立而去預(yù)測(cè)PM2.5的濃度,可能會(huì)導(dǎo)致模型預(yù)測(cè)精確度的下降。互信息是兩個(gè)變量之間統(tǒng)計(jì)相關(guān)性的測(cè)度,用于表示信息之間的關(guān)系。它們相關(guān)性越高則它們的互信息值越大。特征值之間的互信息如圖4所示,根據(jù)圖中的互信息,選出與PM2.5(后一天數(shù)據(jù))相關(guān)性最大的五個(gè)特征值是風(fēng)向,氣溫,平均氣壓,相對(duì)濕度,O3。但是不能只考慮相關(guān)性也得考慮特征之間的冗余度。根據(jù)MRMR算法得出最優(yōu)特征值為:PM10,PM2.5,SO2,風(fēng)向,氣壓。可以看出氣溫和O3相關(guān)性特別高,但是它沒(méi)有被選入最優(yōu)特征集,因?yàn)闅鉁睾蚈3對(duì)PM10也有極強(qiáng)的相關(guān)性,所以不能入選。證明MRMR算法有一定的合理性,考慮了數(shù)據(jù)的冗余度。 圖4 特征指標(biāo)之間的互信息 MRMR-SSA-BP模型預(yù)測(cè)PM2.5時(shí),首先選用了MRMR選擇的最優(yōu)特征集(PM10,PM2.5,SO2,風(fēng)向,平均氣壓)作為模型的輸入,再根據(jù)麻雀搜索優(yōu)化算法,算出BP神經(jīng)網(wǎng)絡(luò)的最優(yōu)權(quán)值和閾值。根據(jù)2019.1.1到2019.11.30作為訓(xùn)練集,12.1號(hào)到12.31號(hào)為測(cè)試集,MRMR-SSA-BP模型的預(yù)測(cè)結(jié)果如圖5所示。SSA-BP結(jié)果誤差圖如圖6所示,根據(jù)SSA-BP模型的誤差分析,在夏季時(shí)預(yù)測(cè)PM2.5準(zhǔn)確度較高誤差較小,但是到春,冬兩季時(shí)誤差增多,誤差數(shù)值也變大。考慮到可能夏季和冬季對(duì)PM2.5濃度影響的因子權(quán)重在變化,在一整年中,所有的影響因子可能對(duì)PM2.5濃度的影響是處于一個(gè)動(dòng)態(tài)變化的過(guò)程中,再者因?yàn)榇憾瑑杉颈狈教鞖廪D(zhuǎn)冷,北方城市會(huì)采取集體供暖,導(dǎo)致煤炭排放增加,PM2.5濃度預(yù)測(cè)的影響因子變得更加復(fù)雜,使得春冬兩季對(duì)PM2.5濃度的預(yù)測(cè)精度降低。 圖5 MRMR-SSA-BP模型預(yù)測(cè)結(jié)果 圖6 SSA-BP模型預(yù)測(cè)結(jié)果 為了驗(yàn)證MRMR-SSA-BP模型的優(yōu)越性,本文采用模型BP、MRMR-BP、SSA-BP來(lái)進(jìn)行比較。采用相同的訓(xùn)練集和測(cè)試集,結(jié)果如圖7-圖9所示,模型評(píng)價(jià)指標(biāo)如表2所示。從預(yù)測(cè)結(jié)果圖來(lái)看MRMR-SSA-BP模型的預(yù)測(cè)效果最好,與真實(shí)值擬合度最高。其次是SSA-BP模型,可以看出MRMR算法選出的最優(yōu)特征值是可以幫助模型提高預(yù)測(cè)精度。SSA-BP模型較普通的BP模型有了顯著的提升,證明麻雀搜索優(yōu)化算法找出最優(yōu)的權(quán)值和閾值能使BP神經(jīng)網(wǎng)絡(luò)的預(yù)測(cè)提高精確度和擬合度。從預(yù)測(cè)結(jié)果圖和三個(gè)評(píng)價(jià)指標(biāo)中從表2所示各模型的評(píng)價(jià)指標(biāo)與模型預(yù)測(cè)結(jié)果圖所展示的結(jié)果一樣,最優(yōu)的模型為MRMR-SSA-BP模型它較基礎(chǔ)的BP模型2種誤差分別降低了13.254和19.441。R2也從0.743上升到了0.916。表明本模型具有很大的優(yōu)勢(shì)去預(yù)測(cè)PM2.5濃度。李建新[11]等人根據(jù)SVM為基礎(chǔ)模型建立得MRMR-HK-SVM模型對(duì)贛州市的PM2.5濃度進(jìn)行預(yù)測(cè),MRMR-HK-SVM模型的RMSE為14.891,因此,總體來(lái)說(shuō)本文提出的MRMR-SAA-BP模型對(duì)PM2.5有著更高的預(yù)測(cè)精度。 表2 模型評(píng)價(jià)結(jié)果 圖7 MRMR-BP模型預(yù)測(cè)結(jié)果 圖8 BP模型預(yù)測(cè)結(jié)果 圖9 SSA-BP誤差分析圖 針對(duì)PM2.5濃度預(yù)測(cè)本文以BP神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)模型,根據(jù)麻雀搜索優(yōu)化算法確立BP神經(jīng)網(wǎng)絡(luò)的最優(yōu)初始權(quán)值和閾值,根據(jù)MRMR算法選擇輸入數(shù)據(jù)的最優(yōu)特征值來(lái)對(duì)濟(jì)南市PM2.5濃度進(jìn)行預(yù)測(cè),建立了MRMR-SSA-BP模型,該組合模型不是多個(gè)模型的預(yù)測(cè)結(jié)果求平均值,它優(yōu)化了傳統(tǒng)BP模型性能上的不足和缺點(diǎn),根據(jù)預(yù)測(cè)結(jié)果和模型評(píng)價(jià)充分說(shuō)明了MRMR-SSA-BP模型是一種高效精確的模型。 1)根據(jù)已有的研究成果,選擇了PM10、PM2.5、SO2、NO2、CO、O3、風(fēng)向、平均氣壓、風(fēng)速、平均氣溫、相對(duì)濕度等11項(xiàng)特征值作為預(yù)測(cè)PM2.5的影響因子,雖然每個(gè)因子都對(duì)PM2.5有很強(qiáng)的相關(guān)性,但是特征值之間也會(huì)有影響。這樣會(huì)影響模型的預(yù)測(cè)準(zhǔn)確度。用MRMR算法不止考慮特征值之間的相關(guān)性,也考慮特征值之間的冗余,來(lái)提高模型的運(yùn)算速度和預(yù)測(cè)精確度。 2)BP神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)中,初始的權(quán)值和閾值都是隨機(jī)確定的,這個(gè)初始的權(quán)值和閾值對(duì)神經(jīng)網(wǎng)絡(luò)訓(xùn)練有很大的影響,但是又沒(méi)有辦法準(zhǔn)確的獲得,所以運(yùn)用麻雀搜索優(yōu)化算法找到最優(yōu)適應(yīng)度值得個(gè)體,來(lái)確立最優(yōu)的初始權(quán)值和閾值,來(lái)提高模型預(yù)測(cè)PM2.5的穩(wěn)定性和準(zhǔn)確性。 3)根據(jù)PM2.5的濃度時(shí)序圖可以看出,PM2.5有著強(qiáng)烈的季節(jié)性規(guī)律,濟(jì)南冬季時(shí)PM2.5濃度達(dá)到278μg/m3,夏季時(shí)有時(shí)只有4μg/m3,所以對(duì)于PM2.5的治理可以根據(jù)季節(jié)性規(guī)律來(lái)進(jìn)行治理調(diào)整。根據(jù)MRMR-SSA-BP模型進(jìn)行PM2.5濃度的預(yù)測(cè),有很高的的擬合能力,和較為準(zhǔn)確的預(yù)測(cè)度,為空氣污染預(yù)測(cè),和治理空氣污染提供了新的思路和方法。 根據(jù)模型運(yùn)行結(jié)果來(lái)看,雖然模型具有很好的預(yù)測(cè)能力,但是夏季和冬季的預(yù)測(cè)能力偏差較大,如圖9所示,根據(jù)SSA-BP模型的誤差分析,在夏季時(shí)預(yù)測(cè)PM2.5準(zhǔn)確度較高誤差較小,但是到春,冬兩季時(shí)誤差增多,誤差數(shù)值也變大。考慮到可能夏季和冬季對(duì)PM2.5濃度影響的因子權(quán)重在變化,因?yàn)槎颈狈匠鞘虚_(kāi)始集體供暖,煤炭燃燒增加,使得PM2.5的影響因子與PM2.5濃度變化的關(guān)系更為復(fù)雜。因此未來(lái)的研究中,可以把PM2.5濃度的預(yù)測(cè)進(jìn)行分季節(jié)預(yù)測(cè),把每個(gè)季節(jié)的影響因子進(jìn)行處理,選出適合每個(gè)季節(jié)的最優(yōu)特征值來(lái)進(jìn)行預(yù)測(cè),提高模型預(yù)測(cè)的精確度。
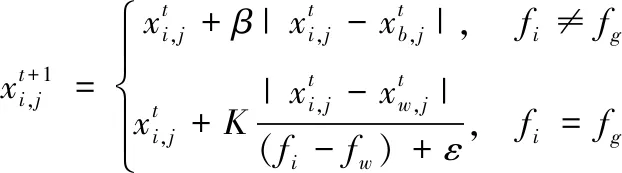


3.3 MRMR-SSA-BP模型

3.4 評(píng)價(jià)模型



4 結(jié)果與分析
4.1 濟(jì)南市污染情況分析


4.2 基于MRMR算法的特征選擇

4.3 MRMR-SSA-BP預(yù)測(cè)分析


4.4 模型評(píng)價(jià)




5 結(jié)論
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
