模型數(shù)據(jù)混合驅(qū)動(dòng)的水聲器材防御決策方法
2023-09-20 10:36:22黃金才張馭龍郭力強(qiáng)
計(jì)算機(jī)仿真 2023年8期
關(guān)鍵詞:模型
楊 靜,黃金才,張馭龍,郭力強(qiáng)
(1. 國(guó)防科技大學(xué),湖南 長(zhǎng)沙 410073;2. 海軍潛艇學(xué)院,山東 青島 266071)
1 引言
戰(zhàn)術(shù)決策是一個(gè)連續(xù)時(shí)間決策過(guò)程,一種通用的方式是采用基于時(shí)間步長(zhǎng)推進(jìn)仿真,將連續(xù)時(shí)間離散化。在最優(yōu)決策推演、精確制導(dǎo)武器參數(shù)設(shè)定等戰(zhàn)術(shù)領(lǐng)域[1,2]應(yīng)用廣泛。過(guò)程仿真的時(shí)間步長(zhǎng)是影響仿真時(shí)間、精確程度的重要因素。在實(shí)際應(yīng)用過(guò)程中,傳統(tǒng)依賴(lài)于過(guò)程仿真的方式存在一些難以解決的困難。一是環(huán)境、態(tài)勢(shì)數(shù)據(jù)的高維特性、以及水中作戰(zhàn)環(huán)境瞬息萬(wàn)變,導(dǎo)致規(guī)劃決策空間出現(xiàn)“維度災(zāi)難”。二是水中對(duì)抗態(tài)勢(shì)演化迅速,基于仿真步長(zhǎng)的推演過(guò)程難以簡(jiǎn)化,導(dǎo)致決策實(shí)時(shí)性和決策精度之間存在矛盾。
隨著人工智能技術(shù)的發(fā)展,越來(lái)越多研究者將目光投向基于數(shù)據(jù)驅(qū)動(dòng)的智能決策技術(shù)研究。通過(guò)數(shù)據(jù)驅(qū)動(dòng)模型代替基于模型-時(shí)間步長(zhǎng)方式的推演,可以有效緩解傳統(tǒng)模型仿真效率難以提高問(wèn)題。在一次決戰(zhàn)過(guò)程中,對(duì)抗態(tài)勢(shì)發(fā)生往往緊迫而短促,無(wú)論是攻擊還是防御決策數(shù)據(jù),快速采取有效攻防對(duì)策都是決勝的重要因素。特別是水中潛艇存在著保持隱蔽性的特殊需求,攻擊、防御器材的使用不當(dāng)可能導(dǎo)致行動(dòng)無(wú)效甚至意外暴露,因此對(duì)防御決策提出了更高的可靠性要求,單純從數(shù)據(jù)出發(fā)的學(xué)習(xí)模型其靈活性、實(shí)時(shí)性、抗風(fēng)險(xiǎn)能力等很難保證。
水中對(duì)抗、特別是水中防御問(wèn)題決策屬于一個(gè)嚴(yán)重的不均衡數(shù)據(jù)學(xué)習(xí)問(wèn)題[1,2]。已經(jīng)證明在近距離條件下的有效防御決策空間在整體決策空間中所占的比例非常小。如何從不均衡數(shù)據(jù)中學(xué)習(xí)一個(gè)無(wú)偏模型,一直是一個(gè)具有挑戰(zhàn)性的任務(wù)。傳統(tǒng)的不均衡學(xué)習(xí)基于隨機(jī)假設(shè)條件設(shè)計(jì)重采樣和重新設(shè)計(jì)權(quán)重的機(jī)制。但是經(jīng)常會(huì)導(dǎo)致執(zhí)行效率不穩(wěn)定,適應(yīng)性較差,而且一旦任務(wù)復(fù)雜、初始假設(shè)不成立,計(jì)算代價(jià)極高甚至結(jié)果發(fā)散等問(wèn)題。
本文的貢獻(xiàn)在于:一是以水中對(duì)抗環(huán)境下,潛艇使用水聲器材防御來(lái)襲魚(yú)雷的決策問(wèn)題為例,提出一種全新的數(shù)據(jù)和模型混合驅(qū)動(dòng)的仿真決策方法,以同時(shí)滿(mǎn)足決策效率和抗風(fēng)險(xiǎn)能力等需求。二是提出了一個(gè)新的集成不均衡學(xué)習(xí)框架,可以在訓(xùn)練集上每次迭代的時(shí)候自適應(yīng)的選擇采樣策略,從而得到不同的分類(lèi)器,并得到集成模型。文中的學(xué)習(xí)框架不同于已有的基于元學(xué)習(xí)的不均衡學(xué)習(xí)策略,通過(guò)在元采樣基礎(chǔ)上獨(dú)立訓(xùn)練一個(gè)元分類(lèi)器的方法,將模型訓(xùn)練和元訓(xùn)練步驟解耦合。這使得文中的策略可以在大部分學(xué)習(xí)模型上兼容,并且,元采樣器也可以很好的適應(yīng)新的任務(wù)。
2 水聲器材防御模型
本節(jié)將首先對(duì)決策模型及其仿真過(guò)程進(jìn)行描述。
2.1 防御決策問(wèn)題的描述
假設(shè)1:潛艇魚(yú)雷報(bào)警態(tài)勢(shì)用魚(yú)雷到潛艇的距離D和魚(yú)雷所處的潛艇舷角X表示。以潛艇為坐標(biāo)原點(diǎn),潛艇當(dāng)前運(yùn)動(dòng)方向?yàn)?度航向(以正北方向表示);
假設(shè)2:預(yù)設(shè)當(dāng)前來(lái)襲魚(yú)雷正按照有利射擊提前角的方向行進(jìn),如圖1所示。

圖1 潛艇防御魚(yú)雷態(tài)勢(shì)圖
潛艇使用水聲器材防御魚(yú)雷的具體過(guò)程為:
i)潛艇接到魚(yú)雷報(bào)警后,以速度Vsub,轉(zhuǎn)向半徑Rsub開(kāi)始做轉(zhuǎn)向Hb角度的規(guī)避,并同時(shí)發(fā)射一枚誘餌,以誘導(dǎo)來(lái)襲魚(yú)雷并為我轉(zhuǎn)向規(guī)避爭(zhēng)取時(shí)間;
ii)發(fā)射誘餌的速度為vbait,其固有轉(zhuǎn)向半徑為rbait,誘餌出水后首先轉(zhuǎn)向αb1角度,然后直航tb1時(shí)間,再轉(zhuǎn)向αb2角度,然后再直航至航程終了。其中轉(zhuǎn)向過(guò)程仍以其轉(zhuǎn)向半徑做勻速圓周運(yùn)動(dòng),直航時(shí)為勻速直線(xiàn)運(yùn)動(dòng)。
iii)來(lái)襲魚(yú)雷速度為vtor(vtor>vbait>vsub)做勻速直線(xiàn)航行搜索,其初始航向?yàn)楫?dāng)前態(tài)勢(shì)下魚(yú)雷與潛艇相遇三角形對(duì)應(yīng)方向Htor,其計(jì)算方法如式(1),魚(yú)雷在未發(fā)現(xiàn)目標(biāo)時(shí)做直線(xiàn)運(yùn)動(dòng),一旦目標(biāo)進(jìn)入其探測(cè)扇面,則轉(zhuǎn)向追擊目標(biāo)。

(1)
在模擬一次仿真的過(guò)程中,每個(gè)實(shí)體都按照有限狀態(tài)機(jī)模型運(yùn)動(dòng)(如圖2)。決策的目的是在整個(gè)狀態(tài)空間內(nèi),找到最優(yōu)的潛艇使用魚(yú)雷防御方案的四元組(Hb,αb1,tb1,αb2),其中Hb,αb1,tb1,αb2分別為潛艇轉(zhuǎn)向角,誘餌的第一次轉(zhuǎn)向角、第一段直航時(shí)間和第二次轉(zhuǎn)向角。

圖2 使用水聲器材防御魚(yú)雷過(guò)程有限狀態(tài)機(jī)
2.2 仿真優(yōu)化與復(fù)雜度分析
2.2.1 價(jià)值函數(shù)
決策四元組的狀態(tài)空間內(nèi),每次仿真過(guò)程,潛艇與魚(yú)雷探測(cè)扇面的最小距離可以作為價(jià)值函數(shù),定義為
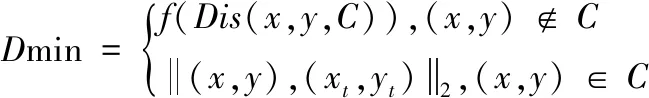
(2)
其中,C為魚(yú)雷搜索扇面,函數(shù)Dis(x,y,C)為潛艇當(dāng)前所在坐標(biāo)(x,y)到魚(yú)雷搜索扇面C的最小距離,求得一次仿真的最小距離算法如下所示。
算法1:OneSim(D,X,Δt,Hb,αb1,tb1,αb2,init[11])
初始化:潛艇狀態(tài)機(jī)=1;潛艇參數(shù);魚(yú)雷狀態(tài)機(jī)=1;
魚(yú)雷參數(shù);誘餌狀態(tài)機(jī)=1;誘餌參數(shù);
for Δt in total_Time:
潛艇到扇面D=f(Dis(x,y,C));
誘餌到扇面D_bait=f(Dis(x,y,C));
誘餌到識(shí)別扇面D_bait2=f(Dis(x,y,C));;
if D if Dmin<0 do return Dmin; if StateS==1 do 潛艇轉(zhuǎn)向 else: 潛艇直航 ∥StateS=2; if StateB==1 do 誘餌準(zhǔn)備 elseif StateB==2 do 誘餌轉(zhuǎn)向 elseif StateB==3‖StateB==5 do誘餌直航 elseif StateB==4 do 誘餌轉(zhuǎn)向 else do State B=6 if 誘餌達(dá)到最大航程do State B=6 if StateT==1 do魚(yú)雷直航 else魚(yú)雷尾追目標(biāo)∥StateT=2 end for return Dmin 一次搜索過(guò)程的決策粒度取決于搜索的Δt,如果仿真步長(zhǎng)過(guò)大,則可能會(huì)忽略重要的極小值點(diǎn),造成決策失誤。在一次仿真過(guò)程中,每個(gè)實(shí)體按照觸發(fā)條件進(jìn)行基于有限狀態(tài)機(jī)的運(yùn)動(dòng)模擬,因此,一次仿真過(guò)程本身的復(fù)雜性決定了其無(wú)法從算法上進(jìn)一步并行優(yōu)化。 算法2:MTaskSim() 初始化:態(tài)勢(shì)參數(shù)(11維) fori1 in range(1,N): for i2 in range(1,N): fori3 in range(1,N): for i4 in range(1,N): Dmin=OneSim(D,X,Δt, Hb[i1],αb1[i2],tb1[i3],αb2[i4],init[11]); if DminYou>Dmin DminYou=Dmin; end if end for end for end for end for 而整個(gè)仿真決策的過(guò)程中,通過(guò)對(duì)四元組在整個(gè)狀態(tài)空間的組合搜索,找到所有最小值Dmin中的極大值: Dminyou=max(Dmini),i=1,…,n4 (3) 其中,n是決策四元組(Hb,αb1,tb1,αb2)的搜索粒度,四元組的搜索空間為 Hb?[-π,π],αb1?[-π,π], tb1?[0,Lbait/vbait],αb2?[-π,π] (4) 因此,最終決策組合的搜索空間為O(n4),然而考慮到一次仿真本身需要計(jì)算M個(gè)仿真步長(zhǎng),仿真的時(shí)長(zhǎng)約為魚(yú)雷整個(gè)航程段,以仿真魚(yú)雷航行20分鐘、選取步長(zhǎng)1s為例(對(duì)于連續(xù)事件仿真,該仿真步長(zhǎng)往往并不能滿(mǎn)足決策精度的要求,真實(shí)環(huán)境下往往需要時(shí)間步長(zhǎng)0.1s甚至更短),則需要計(jì)算超過(guò) 1000次復(fù)雜度為O(n4)的仿真計(jì)算,一次真實(shí)的對(duì)抗過(guò)程,往往3-5分鐘就結(jié)束了,而基于模型在狀態(tài)空間搜索的方式求解最優(yōu)決策往往需要耗時(shí)超過(guò)5分鐘,即使通過(guò)并行手段對(duì)搜索空間進(jìn)行并行化可以實(shí)現(xiàn)103的優(yōu)化(即本文簡(jiǎn)化參數(shù)條件下,實(shí)現(xiàn)5分鐘/103=0.3秒一次仿真,這是加速的極限情況,達(dá)到103加速意味著需要多達(dá)1000核的計(jì)算資源),但由于本模型假設(shè)輸入?yún)?shù)均為確定值,真實(shí)情況還需要考慮目標(biāo)的方位、速度、航向的誤差散布,即使不確定變量?jī)H多出三個(gè),對(duì)每種變量的散布選取100個(gè)樣本用于統(tǒng)計(jì)結(jié)果,則計(jì)算量也將增加0.3s×1003≈83hour,因此,通過(guò)分析可以得出結(jié)論:一次戰(zhàn)術(shù)仿真過(guò)程,隨著輸入態(tài)勢(shì)參數(shù)的增加,僅考慮并行優(yōu)化方法是無(wú)法滿(mǎn)足決策實(shí)時(shí)性要求的。因此,本文提出一種新的基于模型與數(shù)據(jù)混合驅(qū)動(dòng)的決策方法,其主要框架如圖3所示。 圖3 數(shù)據(jù)與模型混合驅(qū)動(dòng)決策框架 圖5 隨機(jī)3組不均衡數(shù)據(jù)迭代訓(xùn)練中的AUCPRC準(zhǔn)確率 如圖3所示,右側(cè)是傳統(tǒng)仿真過(guò)程,左側(cè)是基于仿真模型的集成學(xué)習(xí)網(wǎng)絡(luò)。通過(guò)對(duì)該態(tài)勢(shì)下的仿真數(shù)據(jù)分析發(fā)現(xiàn),有效決策存四元組存在一個(gè)決策邊界,在近距離遇敵防御條件下,整個(gè)決策空間中有效決策樣本僅占極小的比例,只有當(dāng)Dmin值大于0時(shí),該決策策略才可以實(shí)現(xiàn)防御,因此本文通過(guò)對(duì)決策數(shù)據(jù)和Dmin取值正負(fù)的對(duì)應(yīng)關(guān)系,訓(xùn)練了一個(gè)二分類(lèi)的集成學(xué)習(xí)網(wǎng)絡(luò),考慮當(dāng)近距離遇襲條件下,數(shù)據(jù)的不均衡IR極高(達(dá)到26以上)的情況,為了獲得更高的決策效率和準(zhǔn)確度,本文采用了如左圖所示的基于元學(xué)習(xí)的集成學(xué)習(xí)模型(在第3部分詳述),再將決策網(wǎng)絡(luò)與仿真相結(jié)合,首先通過(guò)仿真確定樣本空間,將仿真數(shù)據(jù)樣本交給集成學(xué)習(xí)網(wǎng)絡(luò)進(jìn)行預(yù)測(cè),再?gòu)念A(yù)測(cè)出的決策邊界內(nèi)尋找最優(yōu)解,同時(shí),為了確保決策邊界劃分的準(zhǔn)確性能夠適應(yīng)不同態(tài)勢(shì)參數(shù)的狀態(tài),在預(yù)測(cè)模型的同時(shí),將會(huì)同時(shí)對(duì)決策邊界附近的樣本進(jìn)行仿真比對(duì),如果模型預(yù)測(cè)結(jié)果與仿真結(jié)果不符,則將該數(shù)據(jù)加入權(quán)重?cái)?shù)據(jù)庫(kù),增大邊界樣本學(xué)習(xí)模型的影響,從而實(shí)現(xiàn)決策模型的動(dòng)態(tài)自適應(yīng)。 考慮到問(wèn)題的特殊性,采用水聲器材防御通常是在近距離遇襲條件下,為了爭(zhēng)取時(shí)間而采用的策略,當(dāng)距離較近時(shí),通過(guò)對(duì)數(shù)據(jù)分析(詳見(jiàn)第4部分),以及對(duì)決策四元組與安全余量Dmin的相關(guān)性分析,可以看到?jīng)Q策狀態(tài)樣本離散但集中在特定空間,僅有少量特定樣本會(huì)出現(xiàn)決策邊界模糊的情況,因此,在防御仿真前,首先通過(guò)集成學(xué)習(xí)對(duì)不均衡數(shù)據(jù)做有效的判斷,僅對(duì)Dmin取值大于0的情況進(jìn)行仿真,可以極大提高仿真決策的效率,同時(shí)又能保證決策的可靠性。 在數(shù)據(jù)驅(qū)動(dòng)模型中,關(guān)鍵在于解決對(duì)于Dmin取值是否大于0的判斷,屬于二元不平衡分類(lèi)問(wèn)題,數(shù)據(jù)集中只存在兩個(gè)類(lèi)別:少數(shù)類(lèi),即本文中的屬于決策空間內(nèi)的樣本數(shù)量較少的類(lèi);多數(shù)類(lèi),即樣本數(shù)量相對(duì)較多的類(lèi)別。本文用D來(lái)表示全部訓(xùn)練樣本的集合,其中,每一個(gè)樣本用(X,y)表示,標(biāo)簽y∈{0, 1}。在二分類(lèi)條件下,y取值為1代表該樣本屬于正類(lèi)(少數(shù)類(lèi)),為0則代表該樣本屬于負(fù)類(lèi)(多數(shù)類(lèi))。即: 少數(shù)類(lèi)集合:P={(x,y)|y=1},(x,y)∈D 多數(shù)類(lèi)集合:N={(x,y)|y=0},(x,y)∈D 其中:P∩N=?,P∪N=D 本文采用文獻(xiàn)[1]的定義,對(duì)于(高度)不平衡的數(shù)據(jù)集,在|N|?|P|情況下,采用不平衡比IR(Imbalance Ratio)為多數(shù)類(lèi)樣本數(shù)量與少數(shù)類(lèi)樣本數(shù)量的比值 IR=|N|/|P| (5) 對(duì)于不平衡數(shù)據(jù),分類(lèi)正確率很難有效表示分類(lèi)器的效果,因此數(shù)據(jù)模型采用的評(píng)價(jià)指標(biāo)為AUC-PRC。AUC(Area Under Curve,曲線(xiàn)下面積)采用ROC下面的面積,可以用于衡量分類(lèi)器的優(yōu)劣。另外,考慮到數(shù)據(jù)的極端不平衡特性,還結(jié)合準(zhǔn)確召回率曲線(xiàn)PRC(Precision Recall Curve,準(zhǔn)確召回率曲線(xiàn)),在負(fù)樣本的數(shù)量遠(yuǎn)遠(yuǎn)大于正樣本數(shù)量的情況下, PRC更能有效衡量檢測(cè)器的好壞,因此,本文引用AUC-PRC作為評(píng)價(jià)指標(biāo)。 考慮到過(guò)去對(duì)于不均衡數(shù)據(jù)的處理方法主要從兩個(gè)方面:一是從數(shù)據(jù)層面,通過(guò)重采樣[5]或者欠采樣[6]方法,以提高學(xué)習(xí)過(guò)程中樣本的不均衡比例;二是從模型的角度考慮,采用集成學(xué)習(xí)[4]的思想,通過(guò)多個(gè)弱分類(lèi)器加權(quán)的方式代替單一分類(lèi)器,以提高對(duì)于不均衡樣本學(xué)習(xí)的魯棒性。數(shù)據(jù)采樣和多分類(lèi)器都是為了能夠從不平衡數(shù)據(jù)中(特別是少量樣本中)學(xué)習(xí)一個(gè)無(wú)偏模型。然而,多個(gè)弱分類(lèi)器采用隨機(jī)策略對(duì)數(shù)據(jù)進(jìn)行分類(lèi),因此容易陷入局部極值,且對(duì)分類(lèi)器的數(shù)據(jù)設(shè)計(jì)要求較高。 因此,本文考慮采用元學(xué)習(xí)的策略,通過(guò)對(duì)分類(lèi)器的權(quán)重進(jìn)行先驗(yàn)性的調(diào)整,構(gòu)建一個(gè)元學(xué)習(xí)框架,具體的思想是:直接通過(guò)仿真數(shù)據(jù)樣本學(xué)習(xí)一個(gè)參數(shù)化的采樣策略,代替過(guò)去集成模型的隨機(jī)假設(shè)策略。框架包括三個(gè)部分,元采樣、集成學(xué)習(xí)和元訓(xùn)練。 3.2.1 元采樣方法 本文首先引入文獻(xiàn)[4]中的“元狀態(tài)”思想,希望可以找到一種對(duì)集成學(xué)習(xí)訓(xùn)練過(guò)程的信息有效的任務(wù)表示,從而提供有效的元采樣信息。采用“梯度/硬度”分布的概念,引入了對(duì)訓(xùn)練樣本和驗(yàn)證誤差的直方圖分布作為集成訓(xùn)練系統(tǒng)的元狀態(tài)。 具體的做法是:把樣本集的先驗(yàn)信息作為元采樣的輸入,給多數(shù)類(lèi)的每個(gè)樣本設(shè)計(jì)一個(gè)加權(quán),將計(jì)算得到的權(quán)重作為每個(gè)樣本前面的系數(shù)。對(duì)于每個(gè)數(shù)據(jù)樣本集D,其權(quán)重u定義為:μ~gμ,σ(μ|D),其中g(shù)μ,σ為高斯方程用于衡量數(shù)據(jù)樣本的分類(lèi)誤差,定義為 (6) 則對(duì)于樣本集D,假設(shè)正樣本比例(少數(shù)類(lèi)為P,多數(shù)類(lèi)為N,其D=P∪N中,對(duì)于每個(gè)(xi,yi)∈N,則其權(quán)重計(jì)算為 (7) 令N′=w·N,每次采樣得到|N′|=|P|,并以子集D′=N′∪P作為每次元采樣的數(shù)據(jù)集。 3.2.2 集成學(xué)習(xí)訓(xùn)練 基于一個(gè)采用元采樣策略得到的數(shù)據(jù)樣本,可以迭代的訓(xùn)練一個(gè)基分類(lèi)器。假設(shè)采取k次迭代得到的分類(lèi)器結(jié)果作為最終分類(lèi)結(jié)果。則在第t次迭代過(guò)程中,將元采樣得到的數(shù)據(jù)集D′劃分為訓(xùn)練集DT和驗(yàn)證集Dv。對(duì)于分類(lèi)器Γt(x),分類(lèi)誤差e可以定義為分類(lèi)器Γt(x)與其真實(shí)標(biāo)簽之間的差,即|Γt(x)-y|,通過(guò)下方式(8)進(jìn)行計(jì)算。 iD=|x,y|i-1b|≤|Γt(x)-y|≤ib||D|,(x,y)∈D (8) 其中i∈[1,b],然后,可以將訓(xùn)練集和測(cè)試集的誤差分布向量進(jìn)行拼接,就可以得到一個(gè)元狀態(tài) s=[Dt:Dv]∈R2b (9) 然后,按照元采樣的思想,將分類(lèi)誤差e作為新的采樣依據(jù),令 (10) 作為更新權(quán)重,這個(gè)過(guò)程重復(fù)迭代k次,最后得到的結(jié)果作為最終分類(lèi)結(jié)果。分析可知:誤差分布直方圖可以直觀的表示出分類(lèi)器對(duì)于數(shù)據(jù)的分類(lèi)能力,本文考慮b=2的情況,其中分類(lèi)準(zhǔn)確率為1D,分類(lèi)錯(cuò)誤率2D。而當(dāng)b>2時(shí),就代表在分布的“無(wú)爭(zhēng)議”樣本(誤差接近0)和“有爭(zhēng)議”樣本(誤差接近于1)之間取了更為細(xì)致的粒度,因此,本模型未來(lái)也可以對(duì)多分類(lèi)問(wèn)題如何使用元信息提供借鑒。另外,由于同時(shí)考慮訓(xùn)練集和驗(yàn)證集,元狀態(tài)可以通過(guò)當(dāng)前集成模型的偏差提供一個(gè)元采樣器,用于輔助決策。 3.2.3 元訓(xùn)練 元采樣的目的是通過(guò)多次迭代選擇訓(xùn)練數(shù)據(jù)的方式優(yōu)化決策效率,它基于當(dāng)前樣本狀態(tài)s(式(9))作為訓(xùn)練輸入,通過(guò)高斯方程的輸出參數(shù)u來(lái)決定每個(gè)樣本的采樣概率。元分類(lèi)器的目的是通過(guò)當(dāng)前的狀態(tài)st、動(dòng)作u得到新的狀態(tài)st+1,并通過(guò)多次迭代在效率優(yōu)化的條件下,通過(guò)減少差分優(yōu)化訓(xùn)練過(guò)程。這一過(guò)程與強(qiáng)化學(xué)習(xí)類(lèi)似: 采用基于強(qiáng)化學(xué)習(xí)的設(shè)定,基于馬爾可夫決策過(guò)程(MDP)的四要素(SApr)可以定義為:狀態(tài)空間S,動(dòng)作空間A:[0,1]都是連續(xù)的。而狀態(tài)轉(zhuǎn)移概率p:S×S×A代表的是下一個(gè)狀態(tài)st+1在當(dāng)前狀態(tài)st和當(dāng)前動(dòng)作A條件下的概率密度。在每次迭代中,分別訓(xùn)練k個(gè)分類(lèi)器,并形成k個(gè)集成分類(lèi)器F。給定一個(gè)性能度量函數(shù)P(F,D),獎(jiǎng)賞r定義為r=P(Γt+1,D)-P(Γt,D)。則元分類(lèi)器的優(yōu)化目標(biāo)變成了集成分類(lèi)器的性能。 在不同初始態(tài)勢(shì)條件下生成了以安全距離為判定依據(jù)生成了大量仿真數(shù)據(jù)樣本。隨著來(lái)襲魚(yú)雷與我相對(duì)距離靠近,數(shù)據(jù)樣本的不均衡比例大幅提高(在其它態(tài)勢(shì)參數(shù)不變情況下,相對(duì)距離D從3海里縮短到2.7海里,相同時(shí)間步長(zhǎng)的810000條數(shù)據(jù)中,不均衡數(shù)據(jù)比例從2.6提高到了29.4。這也從一個(gè)側(cè)面說(shuō)明,對(duì)于來(lái)襲高速武器防御,越早采取有效策略,防御的成功概率越大,但對(duì)于決策時(shí)間的要求也越高。考慮相對(duì)極端條件下的快速?zèng)Q策,本文的后續(xù)實(shí)驗(yàn)采用D=2.7條件下的,相對(duì)弦角X在區(qū)間[-π,π]內(nèi)取30個(gè)區(qū)間值,每個(gè)值對(duì)應(yīng)生成81萬(wàn)條數(shù)據(jù),采用批量為10(batchsize),對(duì)30個(gè)區(qū)間采樣的8.1萬(wàn)條數(shù)據(jù)進(jìn)行組合,構(gòu)成10個(gè)樣本集,每個(gè)樣本集大小為243萬(wàn)(30×8.1萬(wàn))。總數(shù)據(jù)樣本IR約為29.4,單獨(dú)取出的10個(gè)數(shù)據(jù)樣本集不均衡比例范圍為為21.7-30.9之間,可以認(rèn)為抽樣數(shù)據(jù)基本滿(mǎn)足總數(shù)據(jù)樣本特征分布。 通過(guò)數(shù)據(jù)處理,將Dmin>0情況的flag為1,其余情況flag為0,得到數(shù)據(jù)總分布,和mini-batch分布分別如下圖a、b所示。 通過(guò)對(duì)上述仿真模型進(jìn)行分析,一次仿真的最小安全距離可以作為判定決策四元組Hb,αb1,tb1,αb2是否能夠有效防御來(lái)襲魚(yú)雷的依據(jù),通過(guò)對(duì)狀態(tài)空間內(nèi)所有四元組組合的分析,發(fā)現(xiàn)可防御四元組僅占總體決策空間的極小一部分,然而,傳統(tǒng)的基于仿真方法需要遍歷所有狀態(tài)空間以尋求最優(yōu),即使采用及早停止的相關(guān)策略,仍然無(wú)法避免在所有決策空間上的遍歷(算法1的OneSim過(guò)程),極大影響決策性能,因此,考慮采用數(shù)據(jù)與模型混合驅(qū)動(dòng)的方式,利用數(shù)據(jù)學(xué)習(xí)模型實(shí)現(xiàn)兩個(gè)任務(wù):一是針對(duì)當(dāng)前態(tài)勢(shì),預(yù)測(cè)狀態(tài)空間的范圍;二是在對(duì)狀態(tài)空間的最小安全距離Dmin給出合理的回歸分析,實(shí)現(xiàn)高可靠度的預(yù)測(cè)。 在81萬(wàn)條數(shù)據(jù)中通過(guò)等間隔方式劃分為10個(gè)子集,每個(gè)子集數(shù)據(jù)81000條。再?gòu)闹须S機(jī)選取3個(gè)樣本集分別用于訓(xùn)練、驗(yàn)證和測(cè)試,重復(fù)這個(gè)過(guò)程7次得到的模型用于最終數(shù)據(jù)與模型混合驅(qū)動(dòng)仿真模型,其中,數(shù)據(jù)訓(xùn)練的樣本準(zhǔn)確率采用AUCPRC準(zhǔn)則進(jìn)行評(píng)估,下圖是隨機(jī)選取3組不均衡數(shù)據(jù)比例為22.6,22.8,23.9的81000數(shù)據(jù)子集作為訓(xùn)練集、驗(yàn)證集、測(cè)試集時(shí),迭代訓(xùn)練過(guò)程中的AUCPRC準(zhǔn)確率。數(shù)據(jù)驅(qū)動(dòng)模型在單個(gè)訓(xùn)練集上極容易過(guò)擬合,但是在驗(yàn)證集、測(cè)試集上都可以達(dá)到98%以上的預(yù)測(cè)準(zhǔn)確率,考慮到預(yù)測(cè)的目的是縮小決策空間,對(duì)于一個(gè)仿真模型,對(duì)其決策空間預(yù)測(cè)準(zhǔn)確率達(dá)到98%,并在該決策空間內(nèi)進(jìn)一步搜索決策最優(yōu)解,可以認(rèn)為是可行的。 尤其是當(dāng)這種決策可以極大程度提高模型運(yùn)算效率的情況下,下表給出了三種態(tài)勢(shì)下,模型仿真與使用文中的元訓(xùn)練模型預(yù)測(cè)的時(shí)間和決策方案。 態(tài)勢(shì)說(shuō)明:態(tài)勢(shì)1,距離D取3.2海里,樣本不均衡比例IR=1.6;決策四元組(-3.1416,-1.1916,0.0502,-0.3245);態(tài)勢(shì)2,距離D取2.7海里,樣本不均衡比例IR=22.7;態(tài)勢(shì)3,距離D取2.4海里,樣本不均衡比例IR=59;決策方案是最小安全距離Dmin的最大值所對(duì)應(yīng)的方案四元組,以及對(duì)應(yīng)的Dmin取值。 混合模型的決策時(shí)間包括兩部分:一是7輪樣本訓(xùn)練的總耗時(shí),二是決策模型仿真時(shí)長(zhǎng),以?xún)刹糠旨雍妥鳛榭倹Q策時(shí)長(zhǎng)。 可以看出,雖然混合模型并未得到最優(yōu)解對(duì)應(yīng)的決策方案,但是仍在可行域內(nèi)得到了相對(duì)較優(yōu)的決策方案,且計(jì)算效率大大提升。從D為3.2海里到2.4海里,隨著時(shí)間流逝,可行決策空間大幅下降,這也從另一方面表明水中防御態(tài)勢(shì)情況緊急,快速?zèng)Q策對(duì)于緊急條件具有重大意義。采用混合決策模型,運(yùn)行時(shí)間分別下降了63、16、8.8倍,越早決策,可行空間越大,因此從整體上看,模型與數(shù)據(jù)混合驅(qū)動(dòng)方法可以很好的提高決策效率。 首先對(duì)元集成學(xué)習(xí)的方法和其它6種有代表性的不均衡集成學(xué)習(xí)方法進(jìn)行了對(duì)比。包括2種欠采樣策略(ORG、RUSBoost[9])和4種過(guò)采樣不均衡集成學(xué)習(xí)方法(SMOTE[7]、 BorderSMOTE[8]、SMOTEENN、SMOTEomek)。采用的都是同一個(gè)數(shù)據(jù)樣本(從30*10個(gè)樣本中選出的不均衡比例最高的81萬(wàn)條數(shù)據(jù)),測(cè)試其分類(lèi)效率和準(zhǔn)確性。對(duì)于不同的基分類(lèi)器,比如K近鄰、高斯貝葉斯(GNB)、決策樹(shù)(DT)、自適應(yīng)梯度(AdaBoost)和梯度下降(GBM),通過(guò)不同的采樣策略與這些分類(lèi)器進(jìn)行結(jié)合,記錄了不同方法的決策精度和執(zhí)行時(shí)間(執(zhí)行時(shí)間都是10次運(yùn)算取平均值),如下表1。利用AUCRPC分?jǐn)?shù)來(lái)記錄不同集成學(xué)習(xí)算法的效果,并對(duì)所有方法AUC和運(yùn)行時(shí)間做了對(duì)比。結(jié)果表明,文中的元訓(xùn)練方法在幾個(gè)不均衡比例很高的數(shù)據(jù)樣本集上在精度較高條件下,計(jì)算時(shí)間也更短。 表2 不同集成學(xué)習(xí)方法分類(lèi)效率和準(zhǔn)確性對(duì)比 本文主要關(guān)注的是戰(zhàn)術(shù)決策問(wèn)題,傳統(tǒng)的戰(zhàn)略決策的仿真常用的方法是基于決策狀態(tài)空間的搜索。然而這種搜索即使有提前終止策略,由于決策過(guò)程是連續(xù)的,離散化仿真的時(shí)間步長(zhǎng)是很難進(jìn)行優(yōu)化的,特別當(dāng)水中對(duì)抗條件下,實(shí)體的數(shù)據(jù)探測(cè)、感知往往就在分秒之間。 本文通過(guò)數(shù)據(jù)與模型混合驅(qū)動(dòng)的方式,可以在決策初始通過(guò)集成學(xué)習(xí)方法,利用仿真樣本學(xué)習(xí)縮小決策空間,從而提高最終模型搜索的精度。然而,水中防御是一個(gè)相對(duì)復(fù)雜的戰(zhàn)術(shù)對(duì)抗過(guò)程,未來(lái),一方面還將從模型上考慮敵我雙方的博弈與對(duì)抗;另一方面,還需要通過(guò)擴(kuò)大樣本規(guī)模、探究當(dāng)高維狀態(tài)空間數(shù)據(jù)存在更多種變化時(shí),模型的遷移、泛化能力。隨著高維環(huán)境數(shù)據(jù)的變化,防御模型中的決策狀態(tài)空間也會(huì)發(fā)生劇烈的變化。因此,未來(lái)這種數(shù)據(jù)模型混合驅(qū)動(dòng)方式的模型可遷移性和適用場(chǎng)景問(wèn)題是我們需要特別考慮的。2.2 復(fù)雜度分析


2.3 基于模型與數(shù)據(jù)混合驅(qū)動(dòng)的決策方法
3 基于模型與數(shù)據(jù)混合驅(qū)動(dòng)的決策方法
3.1 不均衡數(shù)據(jù)的模型定義與評(píng)價(jià)指標(biāo)
3.2 元學(xué)習(xí)方法與集成模型
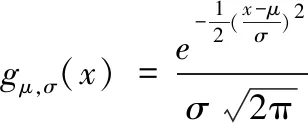

4 仿真研究
4.1 數(shù)據(jù)分析
4.2 基于元集成學(xué)習(xí)方法的訓(xùn)練
4.3 不均衡數(shù)據(jù)學(xué)習(xí)方法比較

5 結(jié)論與展望
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
