基于聯盟鏈PBFT的BRaft共識算法
2023-09-15 03:34:18白尚旺達泓宇高改梅劉春霞黨偉超
軟件導刊 2023年9期
白尚旺,達泓宇,高改梅,劉春霞,黨偉超
(太原科技大學 計算機科學與技術學院,山西 太原 030024)
0 引言
2008 年,中本聰首次提出比特幣,數字貨幣進入了新篇章[1]。在比特幣創始論文中,區塊鏈被定義為一種數據結構,其實質是一個由區塊構成的去中心化的鏈式賬本,每個區塊按時間順序表示用戶之間的事務傳輸。區塊鏈具有去中心化、不可篡改、匿名性等基本特性[2],因此它還可以作為一個分布式網絡協議,使彼此不認識的不同參與者之間建立信任關系[3],而不涉及任何中心角色或第三方。共識算法作為區塊鏈中的最重要一環,著重解決存在故障時如何協調分布式節點之間的交互,保證各節點所維護的數據副本的一致性,避免出現數據不一致、信息不對稱等問題。根據區塊鏈的去中心化程度,可將其劃分為公有鏈、聯盟鏈和私有鏈。對于不同的區塊鏈,采用的共識算法也不同。
以比特幣、以太坊為代表的公有鏈去中心化程度最高,通常采用的共識機制有工作量證明機制PoW(Proof of Work)[4]、權益證明機制(Proof of Stake,PoS)[5]、委托權益證明(Delegated proof of stake,DPoS)[6]。私有鏈的去中心化程度最低,它的寫入權限由個人或某個組織機構所掌握,一般應用于企業內部。以Hyperledger Fabric 為代表的聯盟鏈去中心化程度介于二者之間,一般由多個機構共同參與管理,并允許授權的節點加入網絡。與公有鏈相比,具有更好的交易速度和安全性,是區塊鏈落地的主要方向。
目前,聯盟鏈共識算法主要分為拜占庭容錯(Byzantine Fault Tolerance,BFT)共識算法[7]和非拜占庭容錯共識算法兩類。BFT 算法的核心就是在存在惡意節點的情況下,保證其余正常節點間能夠達成共識。常用的BFT 共識機制主要有實用拜占庭容錯(Practical Byzantine Fault Tolerance,PBFT)[8]、聯邦拜占庭容錯(Federal Byzantine Fault Tolerance,FBFT)[9]和投機拜占庭容錯(Speculative Byzantine Fault Tolerance,SBFT)[10]共識機制,但這類共識算法普遍存在通信復雜度較高的問題。
非拜占庭容錯共識算法是建立在對所有節點的信任機制上,具有低時延、高吞吐量的優勢,常見的有Paxos[11]、Raft[12]共識算法,但不能容忍拜占庭節點的存在,由此提出一系列共識算法的改進方案。Copeland 等[13]結合Raft共識算法和PBFT 共識算法的優點提出Tangaroa 共識算法,該算法在日志復制的過程中添加了哈希函數,確保在有惡意節點攻擊的情況下仍能保持安全性,但是該算法無法容忍多個拜占庭節點的聯合攻擊。Martino 等[14]在Tangaroa 共識算法的基礎上提出一種新型高性能或可擴展性的BFT 共識算法Scal-ableBFT,可用于實現大規模的高性能許可私有鏈。黃冬艷等[15]提出一種基于Raft 集群的拜占庭容錯共識算法RBFT,將節點進行分組,組內采用Raft共識機制,而每組的Leader 節點重新構成一個管理組實行PBFT 算法。該算法較好地融合了Raft共識效率高和PBFT拜占庭容錯性能好的特點,但需要引入大量的監督節點。
本文在分析Raft 算法的不足后,通過對已有拜占庭算法進行研究,使用RSA 簽名以防止節點身份偽造和消息篡改,解決在共識過程中Leader 節點作惡的問題。同時,在PBFT 算法三段協議的基礎上引入標識位W 保證算法的一致性,實現Raft 算法在日志復制過程中的拜占庭容錯,目的在于提高Raft 算法安全性的同時又保證比PBFT 更低的算法復雜度。
1 相關工作
1.1 PBFT共識算法
PBFT 共識機制將原始拜占庭容錯共識算法的通信復雜度從指數級降到了多項式級,共識效率得到明顯提高。PBFT算法中的核心概念有3個部分:視圖(view)、副本(replica)、角色(primary,backups)。視圖表示當前系統的全局狀態,副本表示系統中所有參與共識的節點,而在每個視圖中,副本的角色又分為兩類:主節點(primary)和備份節點(backups)。假設系統中的惡意節點數為f,PBFT 需要滿足總節點數至少為3f+1。算法的共識過程如圖1所示。
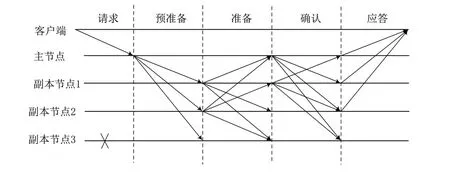
Fig.1 PBFT consensus process圖1 PBFT共識過程
PBFT 的具體執行步驟如下:①請求階段,客戶端向主節點發送請求;②預準備階段,主節點在收到客戶端發出的請求后,先檢查請求的合法性,若合法,主節點將此消息寫入本地日志然后進入預準備階段,并向其他副本節點廣播預準備消息;③準備階段,副本節點在收到消息后先確認消息的正確性,若正確就進入準備階段,并向其他副本節點廣播準備消息,同時將預準備消息和準備消息寫入本地日志;④確認階段,當一個節點在一段時間內接收到2f個以上的準備消息,就發送確認消息給所有副本節點;⑤應答階段,副本節點接收到2f個來自其他節點的確認消息后,驗證消息的一致性,并向客戶端返回應答消息。客戶端收到2f+1個應答消息,表明共識完成。
1.2 Raft共識機制
Raft 算法是Paxos 算法的改進,是從多副本狀態機的角度提出,用來對多副本狀態機的日志復制進行管理[16]。一個Raft群集中有若干個成員節點,這些節點有3 種角色:領導者(Leader)、參與者(Candidate)和跟隨者(Follower),并由Leader統一管理。
(1)Leader。Leader 由Candidate 通過領導者選舉協議選舉產生,用于接收客戶端的請求,并將客戶端請求對應的日志項追加到自己的日志中,然后轉發給Follower 進行復制,當日志復制到大多數節點時,Leader 將發送請求給Follower 進行日志提交。
(2)Follower。Follower 接收并復制由Leader 同步的日志。在Leader廣播可以提交日志后,提交日志。
(3)Candidate。在Leader 選舉過程中由Follower 過渡為Leader的臨時狀態。
參與共識的節點之間通過異步遠程過程調用(RPC)進行交互,調用請求主要分為以下兩種:
RequestVoteRPC:用來進行投票請求,包含Candidate節點的當前任期、日志中最后一條日志項的索引和任期等[17],接收到請求的Follower 通過驗證當前Candidate 節點提供的任期號,選取最優Leader,避免拜占庭Leader 節點丟棄日志或對日志任意排序。
AppendEntriesRPC:用來進行日志復制,包含領導者id、領導者當前任期term、新附加的日志項、前一個條目在Leader 日志中的索引prevLogIndex、任期prevLogterm 以及提交索引commitIndex。
1.2.1 領導者選舉
圖2 描述了3 種不同狀態節點之間的關系。當服務器啟動時,所有節點初始狀態為Follower。經過一段隨機時間后,Follower 節點當前任期加一,然后轉變為Candidate 節點,Candidate 節點首先給自己投票,隨后將RequestVote 請求發送給Follower 節點以獲取唯一投票。當Candidate 節點接收到大多數選票時,轉變為Leader節點[18]。
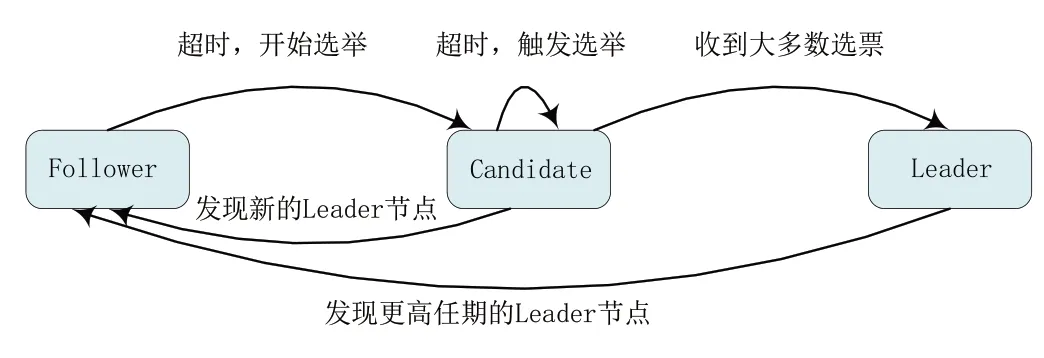
Fig.2 Raft state transitions圖2 Raft狀態轉換
收到投票請求的Follower 節點首先會檢查Candidate最后一條日志項的任期號,只有在發出RPC 的Candidate的日志項具有的任期號比它本地保存的日志項的任期號更大,或者在任期號相同但具有比它更大的索引值時,Follower才會將他們的選票授予該節點。
1.2.2 日志復制
日志是由日志項組成,日志項是一種包含用戶指定的數據、索引值、Leader 節點任期的數據格式。如圖3 所示,首先,客戶端向Leader 節點發送需要執行的請求;其次,Leader 節點在收到客戶端請求后會將帶有客戶端命令的日志項追加到自己的日志中,并向Follower 節點發送AppendEntriesRPC,進行日志復制。
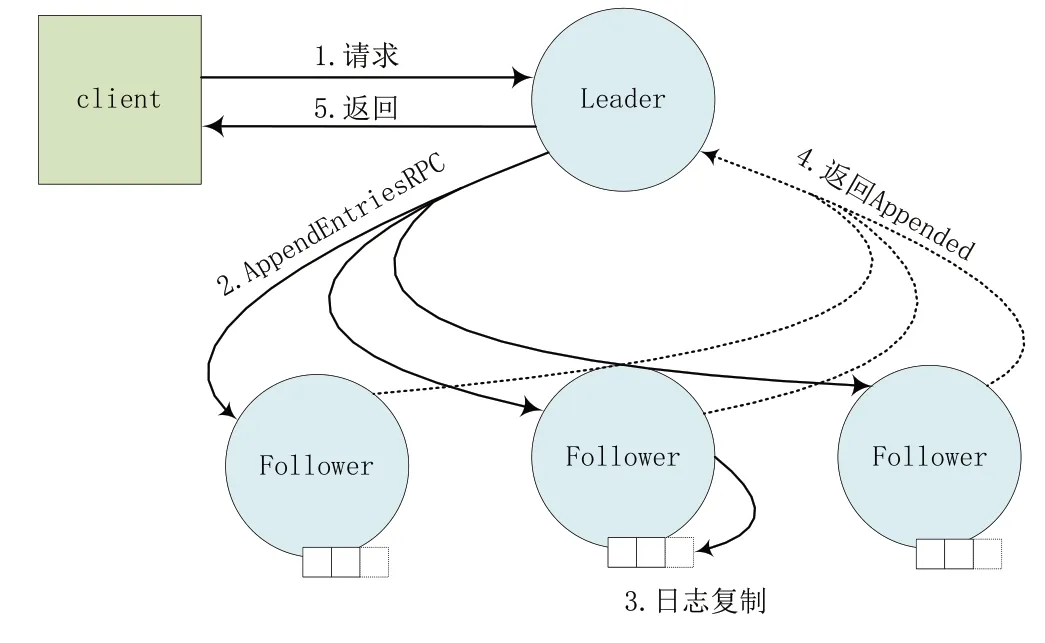
Fig.3 Log copy process圖3 日志復制過程
收到AppendEntriesRPC 請求的Follower 節點首先將自身最新條目與RPC 中的條目進行比較。如果兩個日志項具有相同的索引和任期,Follower 會將接收到的新的日志項附加到其日志并將AppendEntriesRPC 發送給Leader,表示復制成功。當Leader 在收到集群中大多數Follower 復制成功的響應后,將此日志項標記為已提交。日志項中的指令交由狀態機執行,并將結果反饋給客戶端。
2 BRaft共識算法
在Raft 算法中,日志是否提交由Leader 節點判斷,Leader 節點在向所有Follower 節點復制日志項時,如果收到一定數量Follower 節點的響應,Leader 將日志項中的指令交由狀態機執行,并在未來的心跳消息或者日志復制消息中廣播給Follower 節點。但在拜占庭環境下,Leader 節點可以發送錯誤消息給Follower 節點,Follower 節點可以在沒有將日志項添加至日志列表時惡意響應Leader,以誤導Leader 收到了一定數量的響應。由此可知,僅依賴Leader無法確保日志項被正確復制,進而無法確保算法安全性。
BRaft 通過對客戶端的消息進行數字簽名以防止拜占庭節點作惡。在Follower 節點對Leader 的消息進行驗證之后,算法在結合PBFT 的三段協議的基礎上引入標識位W,確保在拜占庭節點作惡的情況下日志項依然能夠被正確提交。這樣,不僅減少了Follower 節點作惡的可能性,并且相比于PBFT 算法的準備和確認階段,節點之間不再需要額外通信,理論上提高了日志追加的時效。
2.1 前提與假設
假設BRaft 集群中一共包含n 個節點,f 個拜占庭節點BRaft算法需要滿足式(1)以確保算法的容錯能力。
在共識過程中,節點存在宕機或者作惡的可能性,BRaft 的容錯能力分兩種情況:①當Leader 節點為拜占庭節點,Follower 集群節點數為n-1,Follower 節點中存在的拜占庭節點數為f-1,如果n-1-(f-1)個節點已經達成共識,來自f-1 個拜占庭節點的決策不會影響正常節點的決策(n-1-(f-1)-(f-1)>f-1),由此可知BRaft 集群節點總數需要滿足n>3f-2;②當Leader 節點為正常節點時,Follower 集群節點數為n-1,Follower 節點中存在的拜占庭節點數為f,如果n-1-f個節點已經達成共識,來自f個拜占庭節點的決策不會影響正常節點的決策(n-1-f-f>f),此時BRaft 集群節點總數需要滿足n>3f+1。
2.2 簽名驗證
BRaft 通過RSA 數字簽名作為消息被篡改的檢測機制,且在算法運行過程中,所有的共識節點均擁有客戶端的公鑰PK。在簽名過程中,首先,客戶端對原文進行Hash運算,得到摘要M,并使用客戶端私鑰SK對摘要M進行加密,形成數字簽名D;然后,將原文和數字簽名一同發送給Leader,Leader 節點在收到客戶端發來的數字簽名及原文后,會將自身信息與客戶端消息打包一起發給Follower 節點,Follower 節點在收到數字簽名后,先用客戶端公鑰PK對摘要進行解密,確定是客戶端消息之后,再用同樣的Hash 算法對原文計算摘要值,判斷Leader 是否對消息進行篡改。
在Follower 節點對客戶端消息驗證之后,BRaft 結合PBFT 三段協議的思想,并通過標識位W保持在拜占庭環境節點的一致性,即每一個Follower 節點存在一個標識位W(0 表示驗證不通過,1 表示驗證通過),每個標識位的初始狀態為0。當Follower 節點經過驗證之后的標識位c為1,且有2f+1 個c發生變化且值的總和至少為f+1 時,可以證明Leader 為正常節點。當Follower 節點經過驗證之后的標識位c為0,Follower 集群中當有2f-1 個標識位發生變化,且這2f-1 個c值的總和至多為f-1 時,證明Leader 節點為拜占庭節點,此時系統重新進行選舉。
算法1簽名驗證算法
2.3 共識過程
BRaft 將共識過程分為4 個階段:提出區塊、驗證區塊、更新區塊和應答階段。具體共識過程如圖4所示。
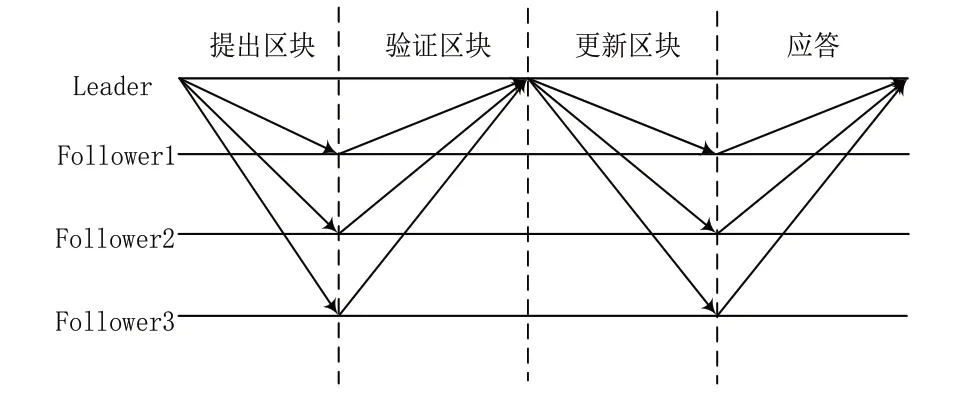
Fig.4 BRaft consensus process圖4 BRaft共識過程
(1)提出區塊。Leader 節點收集客戶端請求<Client-Request,X>sig,并驗證請求的合法性,若不合法,直接丟棄,若合法,Leader 節點將客戶端請求對應的日志項追加到自己的日志中,并在Client-Request 的基礎上加上領導者id、領導者當前任期term、前一個日志項在Leader 日志中的索引prevLogIndex、任期prevLogterm,形成<Prepare-Request,X>,并廣播給其他Follower 節點。
(2)驗證區塊。當Follower 節點i收到來自Leader 節點的<Prepare-Request,X>請求后,驗證以下條件:①通過Verify(PK,D,X)驗證Leader 節點是否篡改客戶端消息;②驗證新附加的日志項的任期號term是否大于等于Follower 本身的任期號;③驗證本地日志的prevLogIndex位置處的日志項與對應的prevLogterm是否匹配。如果以上條件都滿足,則Follower 節點i接受來自Leader 節點的Prepare-Request 請求。此時,標識位Wi為1,并向Leader 節點發送<AgreePrepare-Request,Wi>。
(3)更新區塊鏈。當Leader 節點收到2f+1 個Follower節點發來的<AgreePrepare-Request,Wi>時,且這2f+1 個Wi值的總和至少為f+1,可以證明Follower 節點已經做好準備進行日志復制。此時Leader 節點廣播<AppendEntries,X>給集群中的所有Follower 節點。
(4)應答。Follower 節點收到<AppendEntries,X>后根據條件在本地追加收到的日志項,響應追加結果。當Leader 節點在收到2f+1 個應答結果時,表示共識已完成。Leader 將日志項中的指令交由狀態機執行,隨后將處理結果返回給客戶端并通過心跳消息通知Follower 節點執行已提交的日志項。
3 算法分析
BRaft 算法作為Raft 的改進算法,需要在存在惡意節點的情況下,保證算法的安全性和活性,下文將對以上兩點進行具體分析。
3.1 安全性
安全性是指所有壞的事情不會發生,BRaft 算法的安全性體現在兩方面:Leader 節點選舉階段的安全性和日志復制階段的安全性。
在Leader 選舉階段,BRaft 通過心跳觸發Leader 選舉。Leader 節點會定期向Follower 節點發送心跳消息(包含在AppendEntriesRPC 中),以證明節點的正常運行。如果Follower 節點在一段時間內沒有收到Leader 的心跳,就會在一段隨機時間之后轉換為Candidate 節點,觸發新一輪的選舉。Candidate 節點向其余Follower 節點發送RequestVote請求,以獲取唯一投票。RequestVote 請求包含當前節點最后一條日志項的任期和索引,只有發出投票請求的Candidate 節點的任期及索引比將要進行投票的Follower 節點更高時,Follower 才會將他們的選票授予該節點,以此保證整個選舉過程的安全性。
在日志復制階段,BRaft 算法保留了Raft 算法的日志結構,通過數字簽名實現消息篡改檢測和防止身份偽造,并依賴PBFT 三段協議保證共識的一致性,保證了拜占庭節點存在情況下日志仍能夠被正確提交。BRaft 修改了狀態機提交需要1/2 節點同意的前提,當Leader 節點為拜占庭節點,在容錯范圍f<(n+2)/3 內,可以保證BRaft 的安全性。當Leader 節點為正常節點時,在容錯范圍f<(n-1)/3內,可以保證BRaft算法的安全性。
3.2 活性
活性(Liveness)是分布式共識算法的另一重要屬性,是指所有好的事情一定發生。BRaft 算法保證在任何時刻算法均具備可用性,它是單Leader 的拜占庭容錯算法,即任意時刻BRaft 需要存在一個可用的Leader。當Leader 節點是正常節點時,算法始終遵循算法正常的日志復制邏輯運行,當Leader 節點為拜占庭節點時,將篡改后的日志項發給其余Follower 節點,Follower 節點在收到日志項后,通過數字簽名可以發現日志項被篡改,拒絕將日志項添加到其日志列表中,并轉換為Candidate 狀態,發起新一輪的Leader 選舉。此時,之前被篡改的日志項并未在集群中達成共識,而發起投票的Candidate 在獲得一定數量投票后,成為新一輪的Leader,BRaft 集群即恢復正常運行狀態,上述整個過程僅耗費了一次Leader 選舉耗時,BRaft 算法保持著極高的活性。
4 實驗與分析
4.1 實驗環境
在實際運行環境中,節點間的通信均通過RPC 實現,對外提供完全一致的接口。實驗環境相關軟硬件信息如表1所示,節點IP地址如表2所示。

Table 1 Experimental environment configuration information表1 實驗環境配置信息

Table 2 Node IP address表2 節點IP地址
4.2 吞吐量
吞吐量指區塊鏈每秒鐘處理交易的數量,吞吐量越高代表算法在單位時間能處理的交易越多,性能越好。
在相同實驗環境下,對Raft、BRaft 和PBFT 算法進行數據吞吐量測試。測試過程采用Jmater 工具,通過設置不同線程數模擬多個客戶端向Leader節點發送Request消息,最后隨機選取10組數據進行比較。由于BRaft算法在日志復制過程中存在對消息簽名的解密驗證,比Raft 算法的數據吞吐量低10%左右,但與PBFT 算法相比,數據吞吐量提高1/4左右,因而BRaft在性能上仍有很大優勢,如圖5所示。
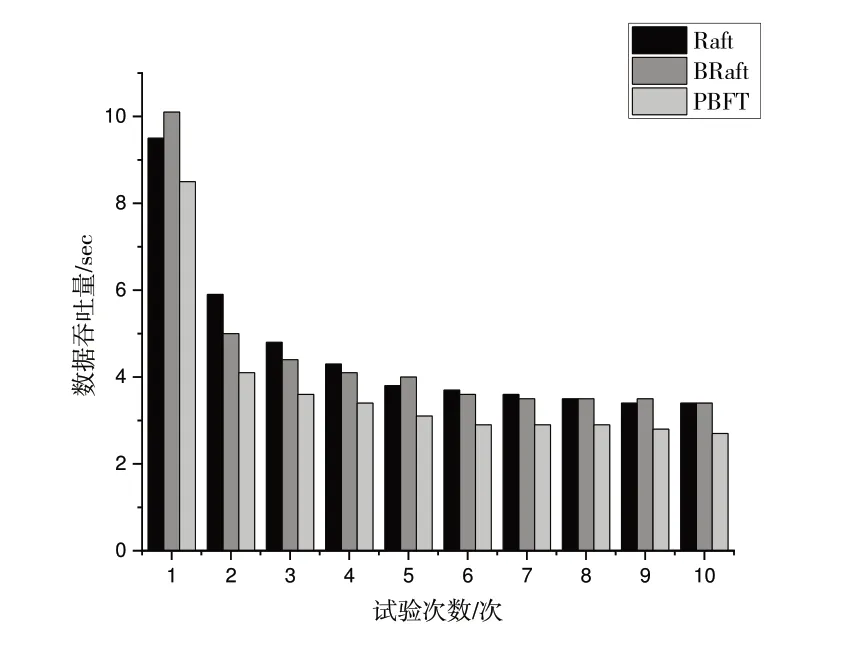
Fig.5 Throughput圖5 吞吐量
BRaft 共識算法在保證其他條件不變的情況下,分別測試了5 節點、10 節點、15 節點、20 節點下的數據吞吐量。節點數量和數據吞吐量的關系如圖6 所示。實驗結果表明,隨著節點數量的增加,BRaft 的數據吞吐量所受到的影響較小,是因為BRaft 算法在Raft 算法原有共識邏輯的基礎上,擁有比PBFT 更低的通信復雜度。
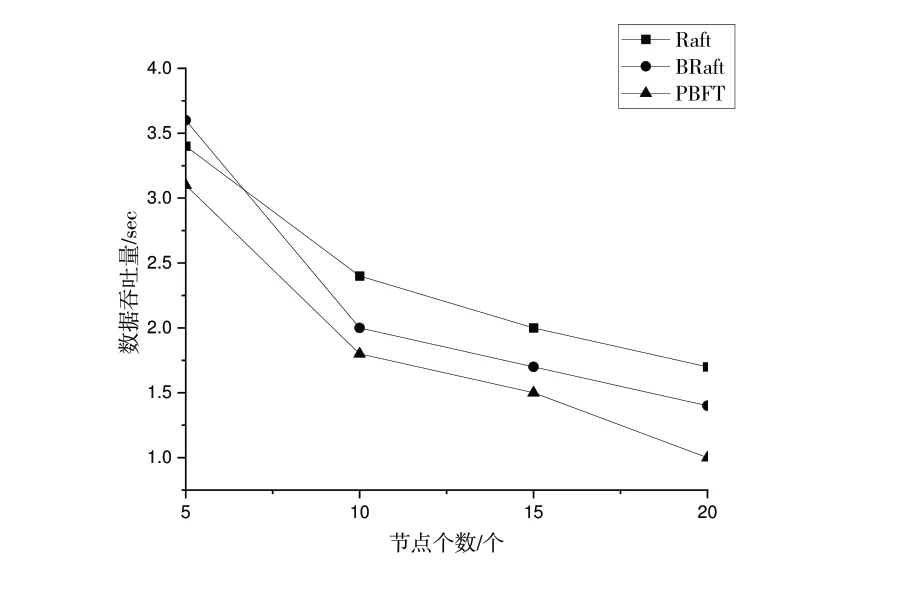
Fig.6 The relationship between the number of nodes and data throughput圖6 節點數量與數據吞吐量關系
4.3 時延
時延是衡量拜占庭容錯的分布式共識算法的另一個重要指標,時延標識了單個請求從被客戶端發送開始直至客戶端收到響應所需要的時間,包括客戶端發送請求、網絡傳輸、日志復制和客戶端接收響應五階段所需時間。
圖7 為Raft、BRaft 和PBFT 算法針對不同數量的客戶端請求達成共識所需時間。節點數目固定(n=5),在客戶端請求數量從5 遞增至1 000 的過程中,Raft 和BRaft 所需達成共識的時間均呈線性增長趨勢,且當客戶端請求數量等于1 000 時,Raft 需要4 732 ms 達成共識,BRaft 算法需要
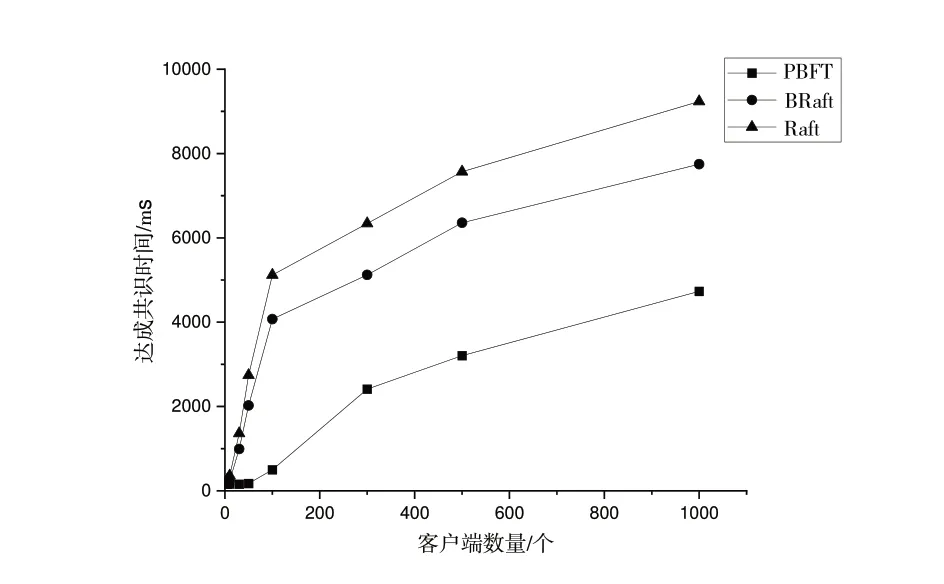
Fig.7 Consensus time for different numbers of client request圖7 不同數量客戶端請求達成共識時間
7 749 ms 達成共識,PBFT 需要9 237 ms。雖然,BRaft 應用數字簽名和哈希算法,它們對性能的損耗存在一定影響,但與PBFT 算法相比,達成共識的時間有了一定提升。
如圖8 所示,W 標識位的使用增加了Follower 節點響應Follower 節點請求的額外開銷,但減少了Follower 節點反饋錯誤消息給Leader 的可能性,且相比于PBFT 這種需要各節點之間相互進行通信的共識過程而言,算法的通信復雜度更低,且本身計算并不復雜,網絡傳輸耗時可以忽略。
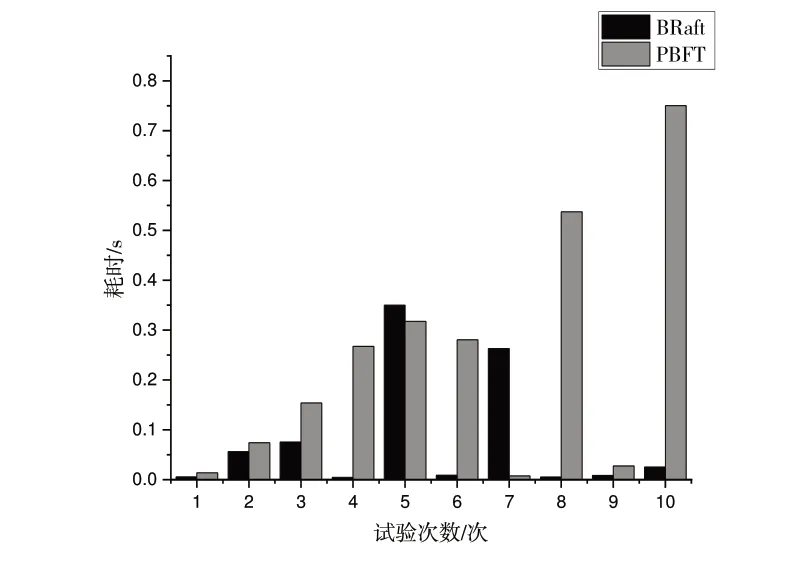
Fig.8 Time consuming to discover malicious nodes圖8 發現惡意節點耗時
5 結語
本文選取非拜占庭共識算法Raft 作為研究對象,針對拜占庭Leader 節點篡改客戶端消息的問題,采用RSA 數字簽名作為消息的檢驗機制,同時在結合PBFT 的三段協議的基礎上引入標識位W,實現Raft 算法在日志復制過程中的拜占庭容錯,確保在拜占庭節點發送錯誤消息的情況下日志項依然能夠被正確提交,很好地融合了Raft 高效和PBFT 可容錯的特點。經過改進的BRaft 共識算法相較于PBFT 共識算法通信復雜度更低,并在保證算法的可理解性和共識效率的同時,提高了算法安全性。但是本文算法還存在一些問題,如在領導者選舉階段無法選擇最優Leader,以及對拜占庭節點無法進行動態刪除、修改等操作,未來可針對這些問題加以重點研究。
