基于保潔機器人垃圾分類任務的數據重標記算法
2023-09-15 03:34:04王中磐李清都萬里紅
軟件導刊 2023年9期
王中磐,袁 野,李清都,萬里紅,劉 娜
(1.上海理工大學 健康科學與工程學院,上海 200093;2.上海交通大學 電子信息與電氣工程學院,上海 200030;3.中原動力智能機器人有限公司,河南 鄭州 450018)
0 引言
隨著我國經濟快速發展,城市化進程加快,人口不斷增加,城市生活垃圾日益增多,垃圾分類已成為社會熱點話題[1-2]。目前,國內垃圾處理廠基本采用人工流水線分揀的方式進行垃圾分揀,工作環境惡劣、勞動強度大、分揀效率低。隨著深度學習技術在視覺領域的應用與發展,使用機器人和AI 深度學習進行智能化垃圾分類任務成為可能,既極大提升了垃圾分揀效率,又節約了人力資源。
卷積神經網絡(Convolutional Neural Network,CNN)具有卷積計算的人工神經網絡結構,是計算機視覺領域常用的深度學習模型。1998 年,Lecun[3]最早提出卷積神經網絡,盡管結構較為簡單,但定義了卷積層、池化層、全連接層這些基本結構。
隨著計算機算力提升,更多模型架構被提出并應用到視覺領域中。Krizhevsky 等[4]提出AlexNet 網絡模型,包含ReLU 激活函數、Dropout 方法,使用GPU 加速模型訓練的方法已在深度學習領域廣泛應用。Simonyan 等[5]提出VGGNet 挖掘網絡深度對模型造成的影響,證明使用小卷積核、增加網絡深度可有效提升模型效果,但網絡過深會引發模型退化問題。He 等[6]引入殘差模塊提出ResNet 能較好地解決網絡過深的問題,后續提出的卷積神經網絡大部分基于ResNet進行改進。
在視覺任務中,卷積神經網絡技術的顯著成就很大程度上歸功于大規模已標注的均衡數據集。然而,相較于常用的公共數據集(ImageNet[7]),真實數據集通常以不平衡數據分布為主[8],即少數類別包含多數樣本(頭部類),大多數類別只有少數樣本(尾部類[9-10])。由于垃圾數據集具有以上特點,因此在這些分類失衡數據集上訓練的模型容易發生過擬合現象,導致模型在少數類別上的泛化性能較差[11-12]。
1 相關研究
現有類別不平衡解決策略可分為重采樣(Re-sampling)[13-14]和重加權(Re-weighting)[15-16]。其中,重采樣通過對頭部類進行欠采樣或過采樣尾部類來調整訓練數據分布類別,緩解數據不平衡問題。例如,GAN-over-sampling[17]通過對抗生成網絡(Generative Adversarial Networks,GAN)生成尾部類的樣本,從而使數據集重新達到平衡狀態;重加權則為每個類別分配不同權重,使模型能更專注于擬合尾部類的樣本[18],相關方法包括Focal Loss[19]、CB Loss(Class-balanced loss)[20]等。Focal Loss 通過研究類別的預測難易度,并提升預測難度高的樣本權重,認為不平衡數據集中尾部類預測難度更高,該類的預測概率遠低于頭部類[19];CB Loss 引入一個有效樣本數的概念來近似不同類樣本的期望值,并使用一個與有效樣本數成反比的權重因子來改進損失函數[20]。
雖然重采樣與重加權策略可改善推理尾部類別的性能,但在一定程度上會損失頭部類的性能,并且簡單地過采樣尾部類樣本可能會導致模型過度擬合[21],在訓練過程中直接提升尾部類的權重也將使模型降低對頭部類的關注度。因此,在提升尾部類別泛化能力的同時,還需要保持頭部類的分類性能,即在垃圾分類任務中在保持常見垃圾類別識別精確度的基礎上,提升尾部罕見垃圾類別識別精確度。
為此,本文提出一種從標簽層面分析數據集的重標記算法框架,從源頭上緩解類別不平衡對模型訓練造成的影響,在一定程度上保證頭部類的識別精度不受損失。首先提出一種針對數據樣本的重標記算法解決類別不平衡、降低模型泛化性能的問題。該算法將頭部類劃分為多個子類并分配相應的標簽,以緩解標簽層面的不平衡問題;然后針對多種不同垃圾類別,制作具有長尾分布的垃圾數據集。實驗表明,所提算法能在著提升長尾數據集中尾部類性能的前提下,基本不損失頭部類性能。
2 垃圾分類任務方案設計
本文所提重標記算法旨在緩解類別不平衡的垃圾數據集對模型分類性能造成的影響,最終將部署到保潔機器人等邊緣計算設備上,以更好地完成垃圾分類任務。因此,垃圾檢測分類工作是基礎,需要設計垃圾分類流程,完成長尾版本垃圾數據集的建立與分析,具體流程設計如圖1所示。
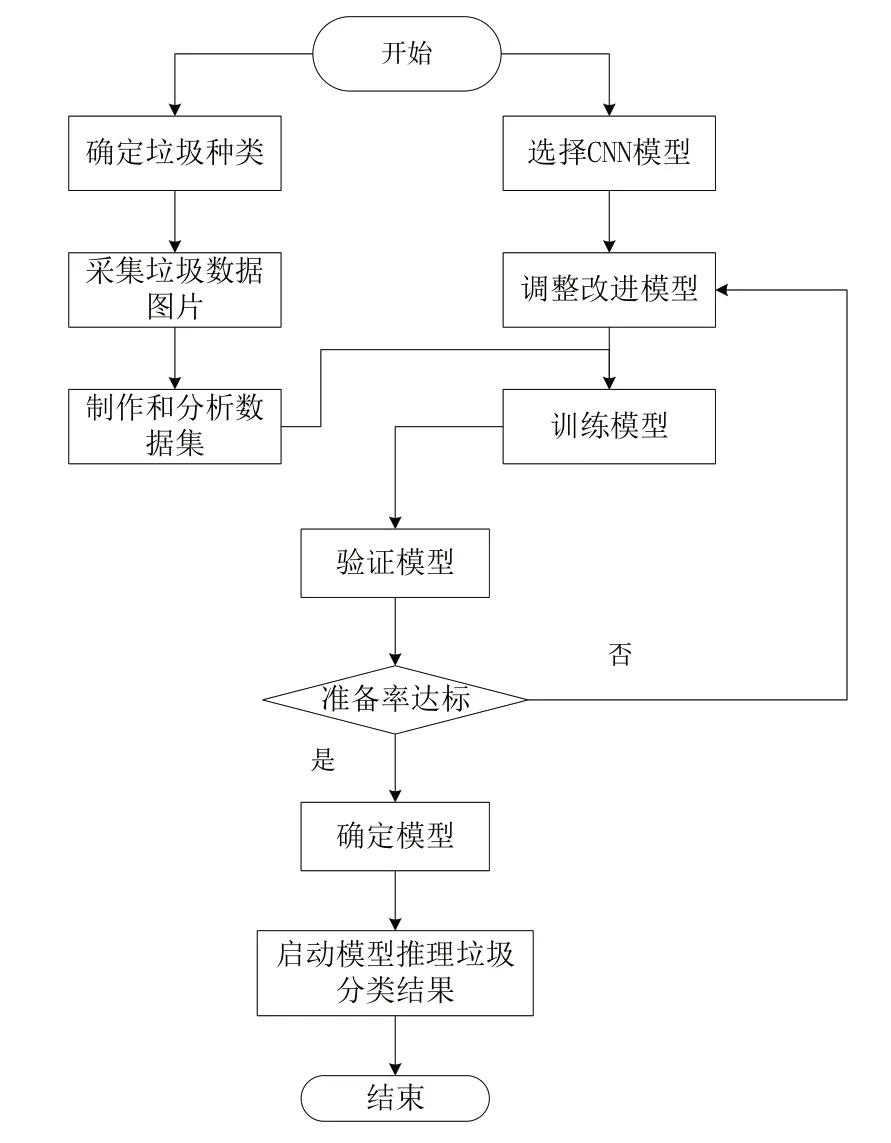
Fig.1 Waste sorting process圖1 垃圾分類流程
由圖1 所示,該流程主要包括數據集采集與分析、模型調整與訓練兩個部分。首先,確定數據集的垃圾種類,采集相應數據并對數據集進行篩選和預處理,制作出具有長尾分布的數據集版本。然后,確定分類CNN 模型,根據任務要求對模型進行調整與改進。最后,在確定數據集和模型后開始訓練模型和驗證測試工作,若模型精度達到項目要求則開始垃圾識別任務,反之將進一步調整模型參數,直至模型達到目標精度。
本文實驗所用的垃圾圖像數據大部分來源于自身相機拍攝的圖片,一部分來源于比賽開源數據,共整理、制作了20 436 張,10 個類別的長尾版本數據集,數據集制作、分析流程如圖2所示。
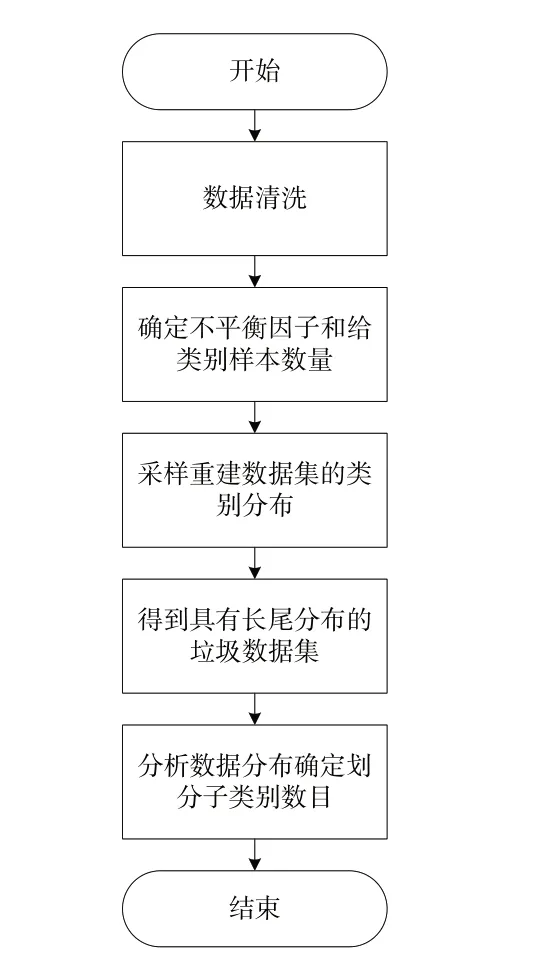
Fig.2 Dataset production and analysis process圖2 數據集制作和分析流程
由圖2 可見,該流程首先將采集的垃圾數據集進行數據清洗,篩選出質量較高的圖片構成原始數據集;然后確定待構建的長尾數據集的不平衡因子,并進行采樣重建,將原始垃圾數據集制作為具有長尾分布的數據集版本;最后綜合考慮數據分布與聚類方法的分析結果,確定每個類別待劃分的子類數。
本文實驗中垃圾數據集的類別數不多且具有嚴重的類別不平衡分布情況,目前常用的網絡為ResNet[6]、EfficientNet[22],由于ResNet 網絡的分類精度與較為先進的EfficientNet 模型相當,但參數量更少,運行時占用內存較少,更適合部署保潔機器人的邊緣計算設備,能提升算法實施和落地的可行性。因此本文分類模型選用ResNet 網絡進行后續實驗。
3 數據重標記算法設計
3.1 總體框架
圖3 為本文所提重標記算法的總體框架,主要包含特征提取模塊、特征聚類模塊和標簽映射模塊。其中,特征提取模塊由ResNet32 的主干部分構成,利用卷積神經網絡提取輸入圖像特征;特征聚類模塊根據提取特征的類內距離將其劃分為幾個子類,并為每個子類樣本生成唯一的偽標簽,完成數據重標記;標簽映射模塊將偽標簽空間映射到真實標簽空間。
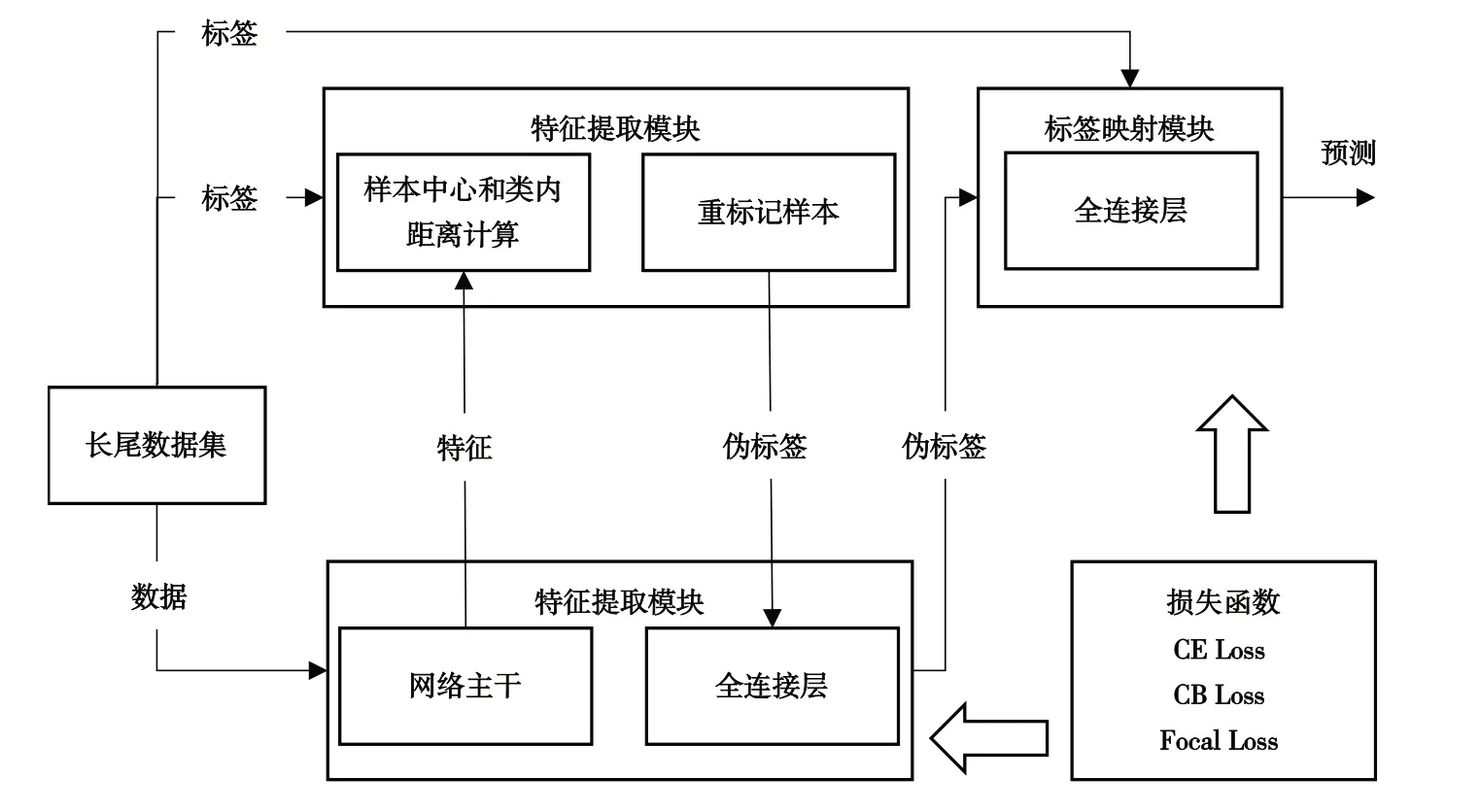
Fig.3 Overall framework of data relabeling algorithm圖3 數據重標記算法整體框架
3.2 特征聚類模塊
特征聚類模塊將樣本特征劃分為指定數量的子類,并重新標記對應的偽標簽。具體的,首先在訓練過程中的卷積神經網絡主干部分提取訓練樣本特征;然后通過動態特征聚類方法,根據對應類別樣本中心的距離大小,將屬于同一類的特征劃分為若干個小的子類別;最后為每個子類賦予一個偽標簽并計算損失。動態特征聚類方法計算公式如式(1)、式(2)所示。
式中:SCt為訓練時第t個batch 中某個類別的樣本中心;Si為該類別第i個樣本;SN表示該類別劃分的子類別數,即樣本和樣本中心的最大距離被均勻劃分為SN個區間;dt為每個區間的長度。
在訓練期間,將樣本分批輸入框架中,對每批每一類數據樣本重復進行下述操作:①根據所有樣本特征計算每個類別的樣本中心;②計算樣本到樣本中心的最大距離,然后將該距離分為多個區間;③根據每個樣本到樣本中心的距離排序關系確定樣本的所屬區間,并為其分配一個唯一的偽標簽。此外,劃分的子類數目為一個超參數,其值與數據集分布情況相關。
3.2.1 樣本中心
Mini-batch 的訓練策略雖然非常適合視覺任務,但會導致樣本中心計算成本過高。為了高效計算樣本中心,本文采用指數移動平均法(Exponential Moving Average)使每批中各類別的樣本中心更接近數據集中與之相對應類別的整體情況,樣本中心計算公式如式(3)所示。
式中:α(0<α<1)表示權重衰減程度;yt表示第t批中某個類別特征的平均值;SCt表示樣本中心,即第t批中某一類別特征的指數移動平均值。
3.2.2 子類數目
子類數目由數據集的不平衡程度和類內距離決定。一方面,本文所提方法旨在將嚴重不平衡的數據集中大多數類別劃分為更多子類;另一方面,本文通過實驗分析子類數對模型造成的影響,得出子類數越大,樣本類內距離越小,當子類數過大時將降低模型分類精度。
因此,本文將對數據集中每個類別進行聚類分析,結合數據集的分布情況綜合考慮子類數目,保證子類數量盡可能大一些,但不能使得類內距離過小。特征聚類模塊中的動態特征聚類方法作為重標記算法的核心部分,具體計算流程如下:
算法1重標記算法
3.3 特征映射模塊
為了將偽標簽空間映射到真實標簽空間,本文在特征提取模塊后設置一個標簽映射模塊,該模塊也是一個多層全連接網絡。在訓練過程中,由于特征聚類模塊對每個類別的樣本進行聚類,并將其分成幾個子類,因此偽標簽的總數會大于真實標簽數量。為了完成初始分類任務,將相同類別樣本的所有偽標簽映射到真實標簽,三層全連接層的輸入維度設置為偽標簽總數,并且輸出維度等于真實標簽總數。
3.4 兩階段訓練策略
由于特征提取模塊和標簽映射模塊是兩個相對獨立的網絡,因此本文采用兩階段訓練方式更新整個算法框架的權重參數,如圖4 所示。第一階段,通過特征聚類模塊生成的偽標簽計算骨干網絡損失值,并更新特征提取模塊的權重參數。第二階段,將標簽得到的真實標簽作為ground-truth,計算標簽映射模塊網絡的損失值,并更新該部分權重參數。第一、第二階段交替進行,訓練過程中損失函數保持一致。
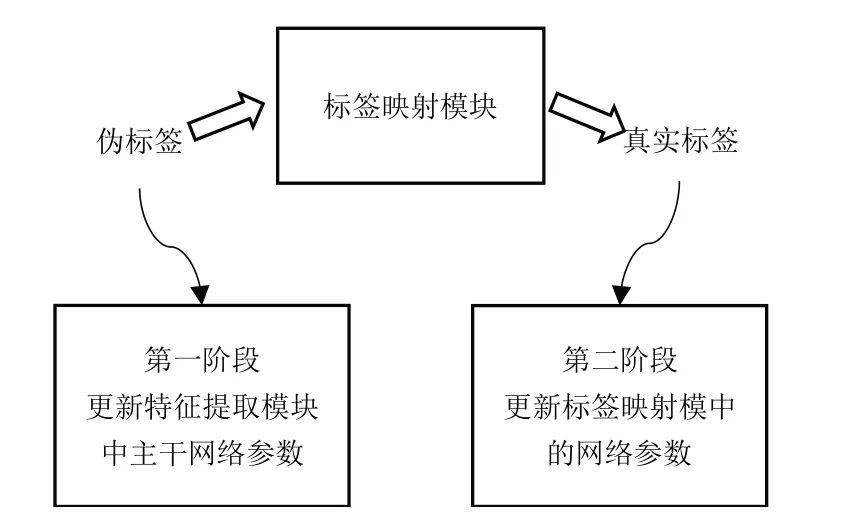
Fig.4 Two-stage training strategy圖4 兩階段訓練策略
4 實驗與結果分析
4.1 數據集
本文數據集的不平衡因子定義為最小類別的訓練樣本數除以最大類別的值,以反映數據集的不平衡程度。實驗中,不平衡因子分別設置為0.01、0.1,由于數據分布的不平衡化只影響數據集中的訓練集,因此平衡分布測試集類別。長尾垃圾數據集分別為0—樹葉、1—易拉罐、2—果皮、3—包裝袋、4—紙、5—塑料瓶、6—瓜子殼、7—布制品、8—煙盒、9—煙頭。實驗結果如圖5、圖6所示。
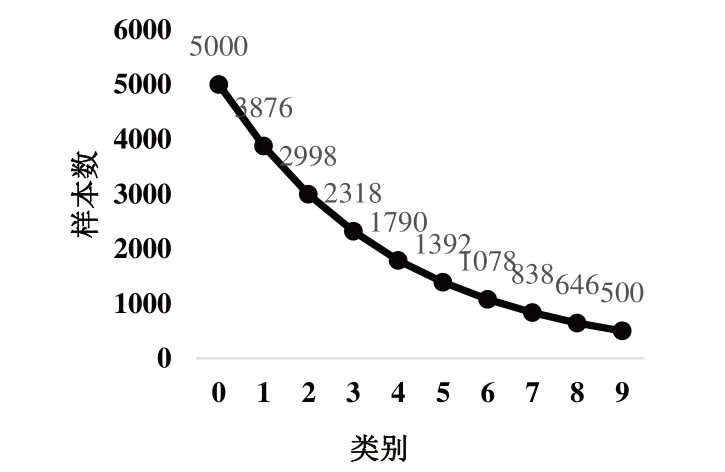
Fig.5 Distribution of garbage datasets with an unbalanced factor of 0.1圖5 不平衡因子為0.1時的垃圾數據集分布
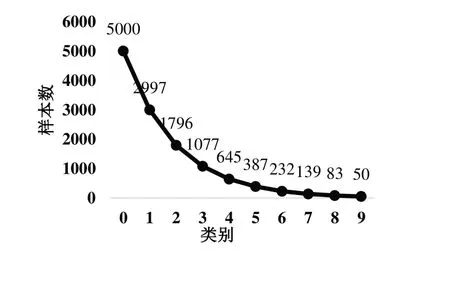
Fig.6 Distribution of garbage datasets with an unbalanced factor of 0.01圖6 不平衡因子為0.01時的垃圾數據集分布
4.2 實驗設置
本文將所提算法與重采樣(Re-sampling)[14]、重加權(Re-weighting)[15]、Focal loss[19]、交叉熵損失(CE Loss)[23]進行比較。其中,重采樣根據每個類別的有效樣本數的倒數對樣本進行重采樣;重加權根據每個類別的有效樣本數的倒數加權因子對樣本進行重新加權;Focal loss 增加了預測難度較高樣本的損失,降低了分類效果較好的樣本權重;CE Loss不改變樣本權重,代表最基礎的方法。
本文將CE Loss、Focal Loss 兩種損失函數與None、重采樣和重新加權3 種方法相結合,作為不同訓練基準方法。其中,重加權、重采樣、CB Loss[20]的訓練方法和參數一致,使用PyTorch 深度學習框架[24]訓練所有模型,并且模型均采用ResNet[6]架構。
本文采用ResNet-32 作為骨干網絡,對所有長尾垃圾數據集進行實驗,模型均采用隨機初始化。另外,優化器選用隨機梯度下降算法(SGD)[25](動量=0.9)對網絡訓練200 個epoch,并按照CB Loss[20]的訓練策略將初始學習率設置為0.1,然后在160、180 個epoch 分別衰減1%,實驗顯卡為NVIDIA RTX 3090,batch_size 為128。
4.3 實驗結果
本文采用基礎方法直接訓練長尾數據集(CE Loss+None)、SOTA 方法(Focal Loss+Reweight)與本文所提重標記方法(Relabel)進行比較,綜合分析3 種方法在不平衡因子為0.1 時垃圾數據集上每個類別的精度與平均精度,如表1 所示。由此可見,本文所提重標記方法在該數據集上的平均精度最高,達到88.37%,相較于CE Loss+None、Focal Loss+Reweight 分別提升1.72%、1.24%。此外,重標記方法能普遍提升樣本數較少的尾部類精度,對于樣本數較多的頭部類精度損失相對較少。
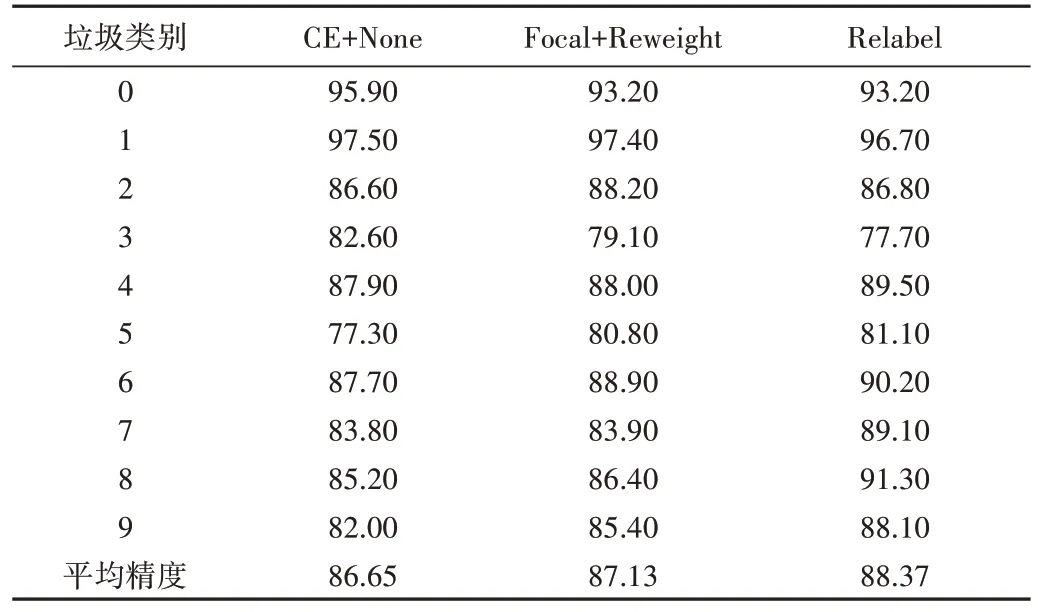
Table 1 Experimental results with an imbalance factor of 0.1表1 不平衡因子為0.1的實驗結果(%)
同時,本文將3 種方法在不平衡因子為0.01 的垃圾數據集上測試的精度、平均精度如表2 所示。由此可見,本文所提重標記方法平均精度最高,達到79.78%,相較于CE Loss+None、Focal Loss+Reweight 分別提升9.56%、4.39%。此外,重標記方法能普遍提升樣本數較少的尾部精度,對樣本數較多的頭部類精度損失相對較少。
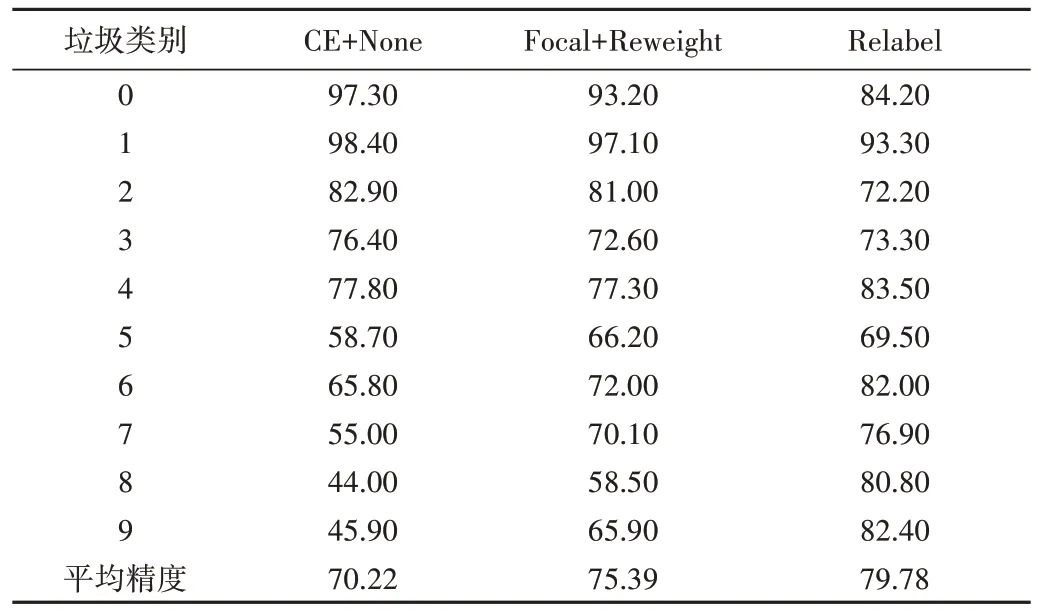
Table 2 Experimental results with an imbalance factor of 0.01表2 不平衡因子為0.01的實驗結果(%)
綜上所述,采用本文所提重標記算法能提升長尾數據集的分類精度,相較于現有SOTA 方法效果更優,并且對于高度不平衡的長尾垃圾數據集,平均精度提升更顯著。
如圖7 所示,實時測試時將重標記算法加入檢測模型后(圖7 下半部分),相較于較改進前方法,在保持其他類別識別效果的同時,對數目較少的煙頭類別識別效果更優。
4.4 消融實驗
為了研究所提重標記算法相較于baseline 中已有的多類別不平衡學習策略的提升效果,對無重標記算法、重標記算法與現有不同學習策略相結合的多種情況進行比較實驗。在不平衡因子分別為0.1、0.01 的垃圾數據集的各方面實驗結果如表3、表4所示。
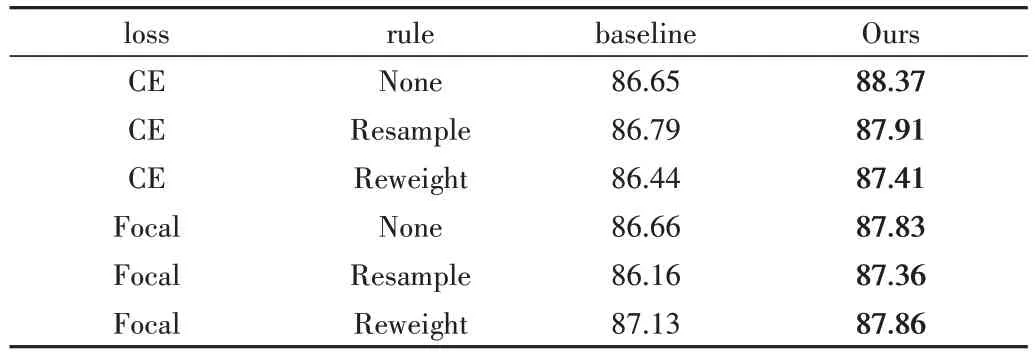
Table 3 Experimental results of different strategy combinations when the imbalance factor is 0.1表3 不平衡因子為0.1時不同策略組合實驗結果(%)
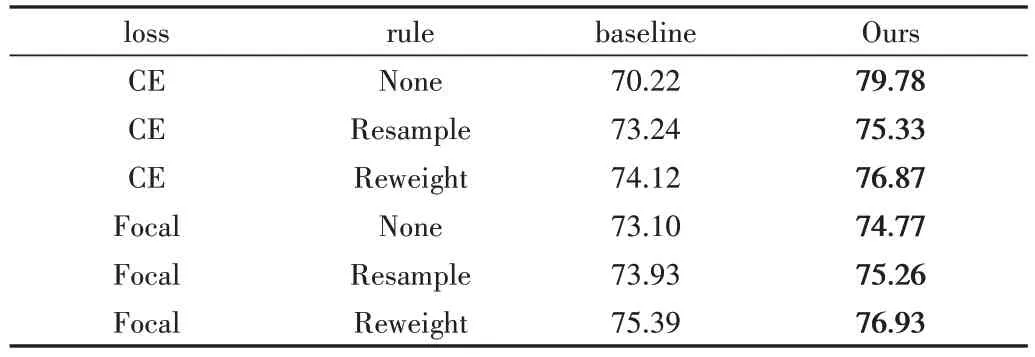
Table 4 Experimental results of different strategy combinations when the imbalance factor is 0.01表4 不平衡因子為0.01時不同策略組合實驗結果(%)
由表3、表4 可知,在不平衡因子為0.1、0.01 的垃圾數據集中,重標記方法能結合baseline 中現有訓練方法進一步提升模型識別效果,相較于CE Loss+None 組合方式平均精度分別提升1.72%、9.56%,達到了88.37%、79.78%。實驗表明,本文所提算法能應用于現有多個不同類別的不平衡訓練策略,可進一步提升模型在長尾垃圾數據集上的分類精度,當直接采用重標記算法且不采用其他訓練策略時,垃圾分類精度最高。
此外,本文對算法中采用不同子類數劃分的方式進行比較,以平衡因子為0.1 時為例,選取兩種不同子類劃分方式,分別對應兩組子類數目的參數:①根據數據分布劃分,即按照每個類別的樣本數量占數據集的比例劃分,參數選取為[10,8,6,5,3,2,2,1,1,1];②聚類分析劃分,即提前對數據集的每個類別進行聚類操作,確定可劃分出的子類,參數選取為[5,3,2,2,1,1,1,1,1,1],實驗結果如表5所示。由此可見,重標記算法在不結合其他baseline 方法時,采用數據分布劃分方式效果更好,分類精度最高;在結合其他baseline 方法后,采用聚類分析的劃分方式效果更好。
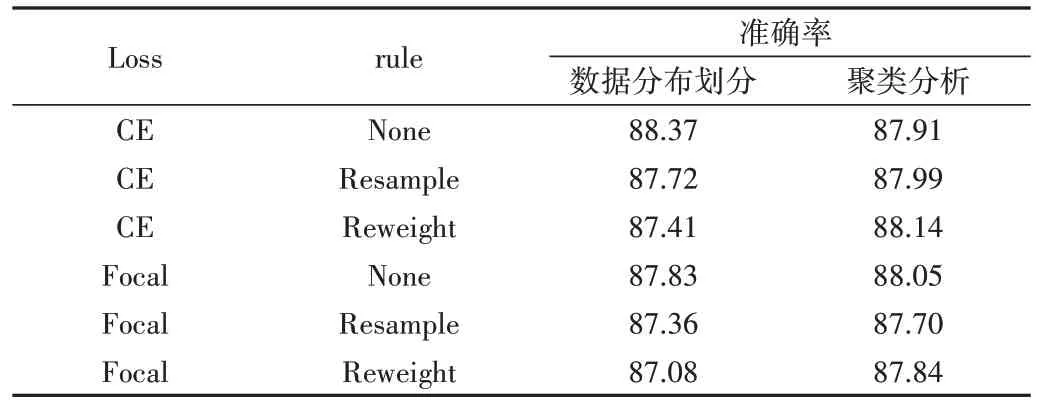
Table 5 Experimental results of different subclass classification methods when the imbalance factor is 0.1表5 不平衡因子為0.1時不同子類劃分方式實驗結果(%)
5 結語
本文為解決人工分揀垃圾環境差、效率低及垃圾數據集類別不均衡分布對保潔機器人等計算設備,在垃圾分類識別時對識別效果產生的負面影響,提出一種針對數據樣本的重標記算法與卷積神經網絡分類模型相結合的策略完成垃圾數據分類任務,并能部署在保潔機器人等邊緣計算設備端。
該算法為每個類別生成多個子類和相對應的偽標簽,緩解了標簽層面的數據不平衡問題,在預測時通過標簽映射將偽標簽轉換為真實標簽。實驗表明,本文算法能顯著提升常用卷積神經網絡模型對垃圾分類的泛化性和精確度,可進一步提升邊緣計算設備垃圾分類任務的效率,實現了自動化、智能化垃圾分類,有助于建設生態文明社會。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
