融合紅外與可見光的實驗室火焰圖像分割識別
2023-09-14 06:40:10李頎,張冉
液晶與顯示 2023年9期
李 頎,張 冉
(陜西科技大學 電子信息與人工智能學院,陜西 西安 710021)
1 引言
近年來,教育體系引入安全發展理念,其中實驗室安全建設尤為重要。高校實驗室事故仍時有發生。2021 年7 月,南方科技大學化學實驗室在實驗過程中發生火災;2021 年10 月,南京航空航天大學一實驗室發生爆炸;2022 年4 月,中南大學實驗室發生火災。安全是教育事業不斷發展、學生成長成才的基本保障[1]。
當檢測到早期火苗判斷火災有可能發生,應及時預警,避免火災的發生,降低實驗室損失。火災發生必會伴隨火焰煙霧產生,可見火焰煙霧識別仍必不可少。
近年來,基于圖像處理的火焰煙霧檢測技術發展迅速,檢測方法包括傳統機器學習和深度學習兩類。早期Toreyin 等提出基于小波變換和背景去除的方法提取煙霧火焰的邊緣紋理特征,判斷視頻中是否存在煙霧發生火災[2]。Gong 等通過獲取圖像質心點以解決火焰形狀的不規則問題,結合顏色空間和火焰特征檢測火焰,但該方法泛化能力不足,易受光線干擾[3]。Kim 等提出了多輸出編碼器-解碼器的火災檢測框架,雖檢測準確率有較大提升,但需要人工操作[4]。周泊龍等提出結合動態和靜態煙霧火焰特征識別視頻火災煙霧,但該方法易受形似煙霧物質的干擾,誤報率高[5]。
通過卷積神經網絡獲取火焰煙霧特征信息對火焰進行識別,提高了火焰識別準確率,但卷積神經網絡巨大的計算導致檢測實時性較差[6]。嚴忱等提出了融合尺度特征的視頻火焰檢測方法[7]。Hosseini等提出一種高效卷積神經網絡模型UFSNet 以檢測視頻中的火焰和煙霧[8]。本文提出一種基于紅外和可見光圖像融合的實驗室火焰煙霧分割識別模型,該模型通過融合紅外圖像和可見光圖像增強火焰煙霧目標圖像的顯著性,以提高實驗室內早期火苗識別準確性;根據不受煙霧遮擋影響的熱紅外圖像提供的熱輻射信息,增強可見光圖像光譜信息,同時通過邊緣提取模塊增強邊緣信息,以提高煙霧遮擋下火焰的分割識別精度。
2 語義感知實時紅外和可見圖像融合分割網絡
實驗室需要實時檢測實驗室內火焰和煙霧,因此要求融合網絡的實時性。語義感知的實時圖像融合分割網絡將圖像融合網絡和語義分割網絡級聯,利用語義分割損失約束圖像融合,再通過新的融合結果和優化聯合損失函數來更新分割模型的參數,可提高高層視覺任務在融合圖像上的性能,增強煙霧和蒸汽情況下火焰圖像的顯著性。網絡結構如圖1 所示。
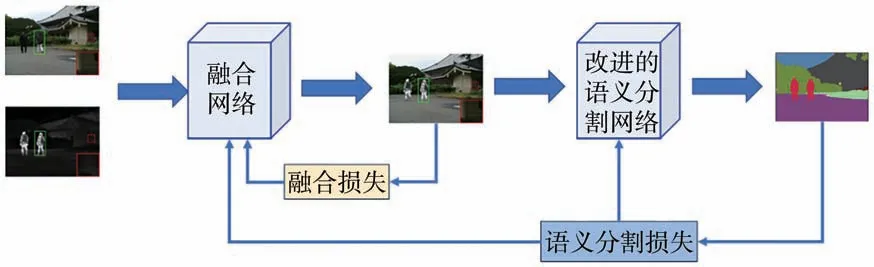
圖1 語義感知實時紅外和可見圖像融合分割網絡結構圖Fig.1 Diagram of semantic perception of real-time infrared and visible image fusion division network structure
2.1 基于GRDB 的輕量級紅外與可見光圖像融合網絡
為了實時融合熱紅外圖像和可見光圖像,語義感知實時紅外和可見圖像融合網絡采用基于梯度殘差密集塊(GRDB)的輕量級紅外與可見光圖像融合網絡,融合可見光紋理信息和熱紅外中的熱輻射信息[9]。如圖2 所示,該網絡由特征提取器和圖像重構器組成,特征提取器包含紅外特征提取流通道A 和可見特征提取流通道B,每個由一個公共卷積層、兩個梯度殘差密集塊組成來提取細粒度特征。圖像重構是由3 個串聯的3×3 卷積層和一個1×1 卷積層組成。3×3 卷積層采用LRe-LU 作為激活函數,1×1 卷積層采用Tanh 作為激活函數。

圖2 基于GRDB 的輕量級紅外與可見光圖像融合網絡結構圖Fig.2 Diagram of lightweight infrared and visible light image fusion network structure based on GRD
2.2 語義分割Deeplabv3+網絡模型
Deeplabv3+網絡結構如圖3 所示[10]。Deeplabv3+網絡分為編碼器和解碼器兩部分。編碼器包含主干網絡和空洞空間金字塔池化模塊(ASPP)。主干網絡通過下采樣提取高級語義特征,生成特征圖,隨后通過由3 個空洞率分別為6,8,12 的空洞卷積核、一個1×1 的卷積核和一個全局平均池化層組成的ASPP 模塊得到5 個特征圖,將特征圖進行級聯后經過一個1×1 的卷積核實現通道降維。解碼器是將主干網絡中4 倍下采樣獲取的低級語義特征圖經過一個1×1 的卷積核進行通道降維,隨后再與編碼器進行4 倍上采樣后的特征圖進行拼接,實現高級特征語義特征與低級特征語義特征圖的融合。再經過3×3 的卷積核提取融合后的圖像特征,最后再進行4 倍上采樣,最終輸出預測分割圖像。
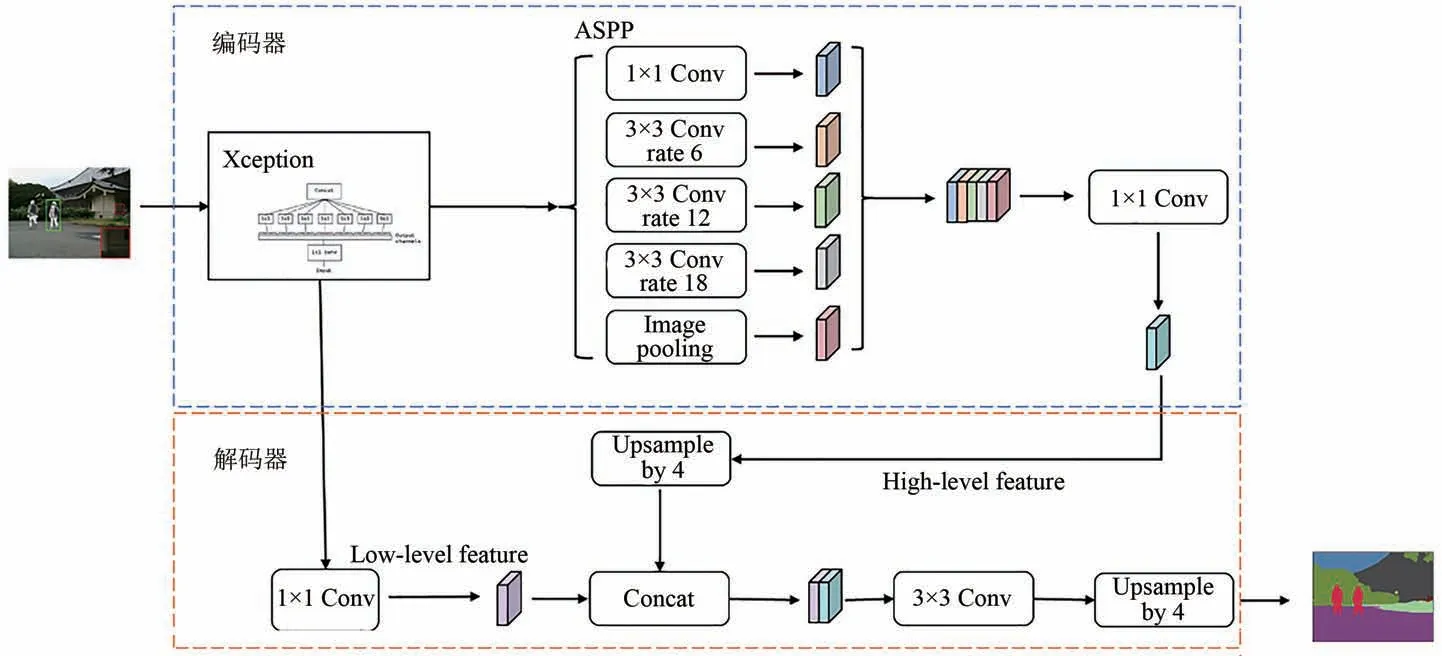
圖3 Deeplabv3+網絡模型Fig.3 Deeplabv3+network model
3 改進的語義感知實時紅外和可見圖像融合分割模型及訓練
3.1 改進的融合網絡
在融合網絡訓練階段,由于損失函數只考慮了強度和梯度信息,當存在煙霧遮擋或實驗室環境設備雜亂時,可能會丟失重要結構信息[11]。為解決該問題,本文設計一種中間特征傳輸塊,建立網絡中前后信息流之間的連接,避免卷積造成火焰圖像信息丟失。同時在網絡中引入權重塊,實現自適應結構相似性損失約束,減少中間信息損失,起到信息保護的作用。改進的融合網絡結構如圖4所示。
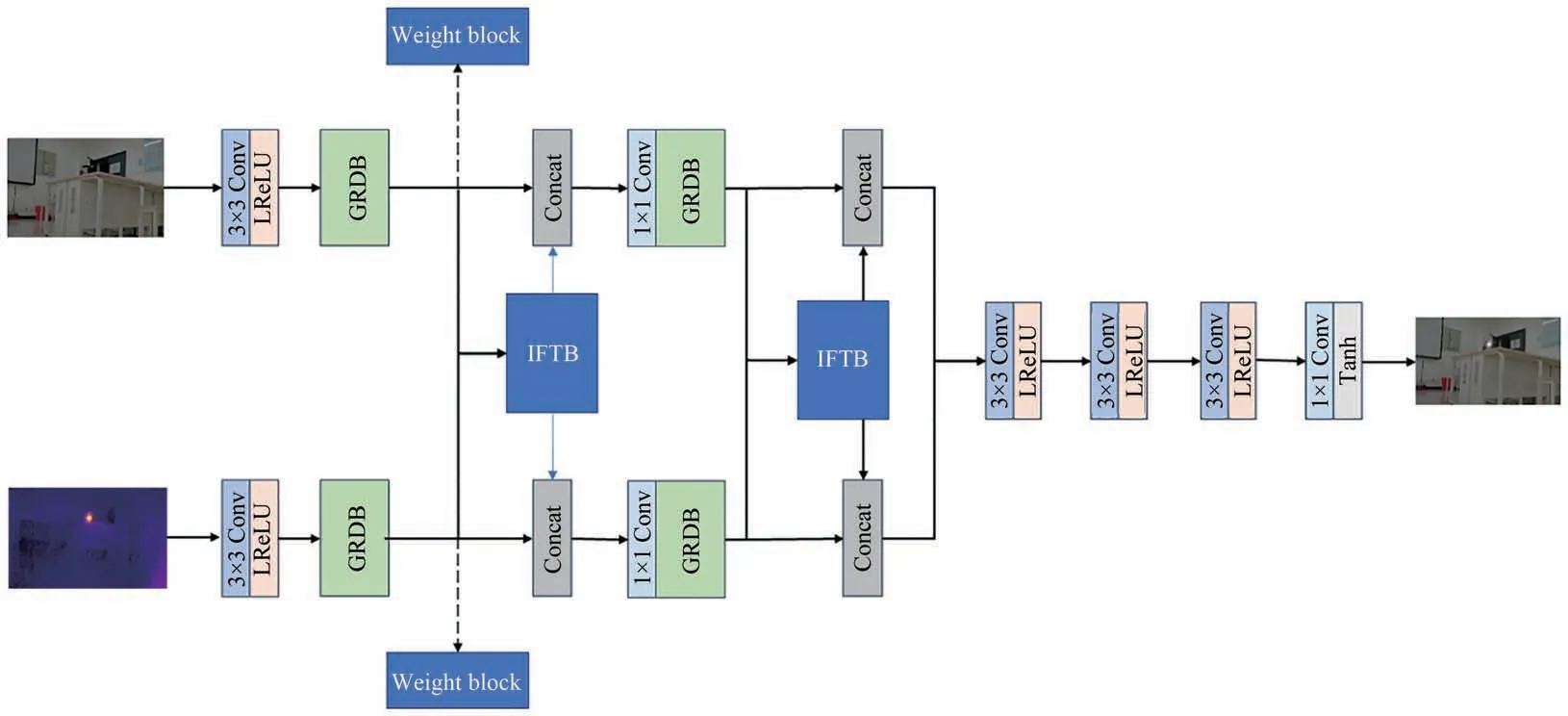
圖4 改進的融合網絡結構圖Fig.4 Diagram of improved fusion network structure
3.1.1 權重模塊
權重模塊結構如圖5 所示。該模塊由3 部分組成,即特征度量、softmax 和相似性約束,特征度量過程可定義為:

圖5 權重模塊結構圖Fig.5 Diagram fo weight module structure
其中:Φc(I)表示提取的熱紅外圖像特征Φc(IA)或可見光圖像特征Φc(IB),H、W和N表示圖像的高度、寬度和顏色通道,?2為拉普拉斯算子,‖ · ‖F表示Frobenius范數。為保留紅外和可見光圖像的細節,融合采用邊緣定位能力強、銳化效果好的拉普拉斯算子。
特征度量輸出結果為GIA和GIB,然后輸入到softmax 中。softmax 函數計算為:
其中:ω1和ω2的值在0~1 之間,且ω1+ω2=1;c為預定義的正態尺度常數,用于調節權重分布。權重越高,相應源圖像保留信息越多。損失函數通過權重ω1、ω2實現自適應相似性約束,提高融合圖像結構和內容的完整性。
3.1.2 中間特征傳輸塊
中間特征傳輸塊(IFTB)結構如圖6 所示。特征圖Φc(IA)和Φc(IB)連接后分別輸入到兩個1×1 卷積層和LReLU 卷積層組合中,提高速度同時防止過擬合。經過中間特征傳輸塊后的輸出結果分別傳輸至A 通道和B 通道,并與處理前特征圖Φc(IA)和Φc(IB)分別進行串聯連接,來交換A、B 通道之間的信息,對可見光和熱紅外圖像信息進行預融合,同時加強圖像重構階段的信息,以防止可見光圖像背景特征丟失。

圖6 IFTB 結構圖Fig.6 Diagram of IFTB structure
3.2 改進的Deeplabv3+語義分割識別模型
為提高實驗室復雜環境細小火苗的識別,通過改進的Deeplabv3+對融合后的實驗室火焰圖像進行分割,得到細小火苗語義分割圖,并對火苗分割圖進行識別。主干網絡Xception 通過4 倍下采樣獲取圖像低級特征作為解碼器輸入,但實驗室設備器材多、背景復雜,引入大量實驗室背景特征、火焰煙霧邊緣模糊會導致邊緣語義分割不精確。為增強對邊緣模糊特征的感知,提高火焰煙霧檢測分割能力,對Deeplabv3+模型的解碼器中Xception引入梯度變換邊緣特征提取模塊(EMM)[12-13],改進后的Deeplabv3+網絡如圖7所示。

圖7 改進的Deeplabv3+模型網絡結構Fig.7 Improved Deeplabv3+ model network structure
由于熱紅外提高了融合圖像中火焰煙霧的顯著性,火焰煙霧邊緣明暗變化較大,因此采用梯度處理融合圖像進行邊緣提取。首先,EMM 對融合圖像中的火焰進行顯示建模,將底層圖像特征中的火焰煙霧邊緣特征提取出來。然后,將火焰煙霧邊緣語義特征與特征ASPP 提取的高級語義特征融合,并對融合特征輸出解碼以增強火焰煙霧邊界特征。邊緣特征提取模塊結構如圖8 所示。

圖8 基于梯度變換的邊緣提取模塊結構圖Fig.8 Diagram of edge extraction module structure based on gradient transformation
將Xception主干網絡提取的特征圖作為輸入,然后分別經過全局平均池化和全局最大池化,在加強實驗室場景變換魯棒性的同時保留局部特征信息。使用1×1 卷積對池化后的特征圖進行卷積操作,得到通道數為K的特征M∈RW×H×K,然后通過argmax 得到K類標簽圖M',對標簽圖進行梯度變換,獲取K個掩模版?M'(?M1,?M2,…,?MK)。設置Sigmoid 激活函數并與M融合得到特征圖B∈RW×H×K,其表達式如式(3)、(4)所示:
其中:δ表示Sigmoid 激活函數;dis 表示距離轉換,該運算通過非背景像素點與背景像素點最近距離,計算火焰煙霧與背景之間的邊界處點的梯度值?M'。通過火焰煙霧邊緣掩模乘以特征圖M,可以在訓練過程中抑制非邊緣像素,同時在分割網絡中增強圖像中火焰煙霧邊緣定位的細節信息。
3.3 損失函數
融合火焰圖像分割的損失函數包含兩部分:一是內容損失函數,即紅外圖像中的突出目標和可見光圖像中的紋理細節保真度;二是語義損失函數,通過語義損失來反映融合圖像對高級視覺任務的貢獻程度[14-15]。
3.3.1 內容損失
改進的融合網絡利用結構相似性和灰度分布實現自適應相似性約束,通過梯度損失保證豐富的紋理細節。因此最終內容損失函數Lcontent(θ,D)由3 部分組成:
其中:θ表示網絡中的參數,D是訓練數據集,LSSIM(·)和LMSE(·)是源圖像和融合圖像之間的相似性損失項,LGrad(θ,D)為梯度損失約束,α為平衡均方誤差系數。
相似性約束包括結構相似性(SSIM)和強度分布(MSE)。結構相似性指數度量(SSIM)是一種有效的度量,廣泛用于兩幅圖像之間的結構相似性。SSIM 結合了亮度、結構和對比度3 個組成部分[16-17]。均方誤差(MSE)用來約束融合圖像以保持與源圖像相似的強度分布。LSSIM(θ,D)和LMSE(θ,D)的公式定義如式(6)、(7)所示:
式中:IA表示熱紅外圖像,IB表示可見光圖像,If表示融合圖像。權重ω1和ω2為權重模塊的輸出結果,為控制相似信息的保留度。其中,SSIM 和MSE 具體計算公式為:
式中:Ia表示熱紅外圖像或可見光圖像,If表示融合圖像,μ代表平均值,σ代表標準差,C1、C2和C3是用來保持矩陣穩定的參數,M為圖像If的像素總數,N為圖像Ia的像素總數。梯度損失函數為:
式中:H、W表示圖像的高度和寬度,If表示融合圖像,IA表示熱紅外圖像,IB表示可見光圖像,λA和λB分別表示特征提取通道A 和特征提取通道B的梯度權重,?為梯度算子。由于紅外圖像和可見圖像中包含的可見紋理細節在融合時易丟失,因此參數設置時需滿足λA>λB。
3.3.2 語義損失
本文引入實時語義分割模型來分割火焰煙霧融合圖像,分割網絡輸出包括分割結果Is∈RH×W×C和輔助分割結果Isa∈RH×W×C,因此語義損失包括主語義損失和輔助語義損失。主語義損失和輔助語義損失定義如式(11)、(12)所示:
其中:H、W、C分別表示圖像高度寬度和通道數,是對語義分割標簽Ls=(1,C)H×W進行One-Hot 編碼。語義損失表示如式(13)所示:
其中μ用于平衡語義損失和輔助語義損失的常數,初始值設置為0.1。
最后,構建聯合損失函數Lloss,用于融合模型的訓練,其定義為:
其中β是表征語義損失Lsemantic的超參數。隨著訓練的進行,分割網絡與融合模型變得自適應,β根據低級和高級聯合自適應訓練策略逐漸增加。
3.4 可見光與熱紅外融合分割網絡聯合訓練
傳統任務驅動低層次視覺方法有兩種:一是采用預先訓練的高級模型來引導低層次視覺任務模型的訓練;二是在同一個階段聯合訓練高、低級視覺任務模型的訓練。然而,在圖像融合網絡設計中,無法提供融合圖像好壞的衡量準則去訓練一個高級視覺任務模型。此外,同一個階段的聯合訓練策略可能會破壞高低視覺任務訓練之間的平衡。因此,本文對融合網絡和分割網絡進行迭代訓練,迭代次數設置為M。首先,在聯合損失Lloss的約束下,利用Adam 優化器對融合網絡中的參數進行優化,并通過迭代結果動態調整超參數β,如式(15)所示:
其中,m表示第m次的迭代。β隨著m增大而逐漸增加,因此分割網絡可以逐漸適應融合模型,語義損失函數可以更準確地引導融合網絡的訓練。γ為平衡語義損失和內容損失的常數。最后,通過最新的融合結果和優化語義損失函數來更新分割模型的參數。
4 實驗結果及對比分析
4.1 實驗配置和數據集構建
本文實驗硬件選擇AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz 和NVIDIA GeForce RTX 3060 Laptop GPU 6G,軟件環境選擇Python 3.7 和PyTorch 1.7.1。
本文通過數據清洗從MFNet 數據集中篩選4 000 對熱紅外圖像和可見光圖像(一對數據包含一張熱紅外圖像以及一張相應可見光圖像),同時在生物化學實驗室通過奧比中光相機和Lepton3.0 模塊采集成對數據集,數據集包含實驗室正常情況下的650 對、火焰燃燒前期情況下的650 對以及有大量煙霧遮擋情況下的650 對圖像。分別對3 種情況下的數據集進行數據增強至2 000 對圖像,最終總數據集包含10 000 對圖像(其中60% 為實驗室自采數據集,40% 為MFNet 數據集),其中7 000 對作為訓練數據集,2 000 對設定為驗證數據集,1 000 對作為測試集。在訓練階段,融合網絡中紅外和可見光特征提取通道的梯度權重λA=6,λB=5,正態尺度常數c=3×103,損失函數中平衡均方誤差系數α=20,聯合自適應訓練中M=4,γ=1。網絡epoch 設置為5 000,batch size 為8,Adam 優化器初始學習速率為5×10-4,終止學習率為1×10-5。
4.2 融合網絡權重模塊和IFTB 模塊的消融實驗
為了驗證權重模塊和IFTB 模塊的有效性,本文對有無模塊的性能進行了比較實驗。可見光和熱紅外原圖如圖9(a)、(b)所示。

圖9 有無權重和IFTB 模塊的融合結果對比圖Fig.9 Comparison of fusion results with or without weights and IFTB module
同時對比了無權重模塊且無IFTB 模塊、僅添加權重模塊、僅添加IFTB 模塊以及同時添加兩種模塊的4 種融合結果,如圖9(c)、(d)、(e)和(f)所示,測試時其他模塊和參數不變。由融合結果對比圖可知,無權重模塊的融合圖像會丟失結構細節信息,導致整體圖像細節信息丟失。圖9 中第一組添加了權重模塊的融合圖像的手部結構細節清晰,第二組添加權重模塊的燒杯邊緣信息較清晰。因此通過權重模塊獲得的權值控制損失函數,可以達到更好的約束效果。
對有無IFTB 模塊的算法進行融合實驗。同樣由對比結果可得,第一組添加IFTB 模塊的墻面線條信息較清晰,第二組添加IFTB 模塊的凳子結構信息較清晰,無IFTB 模塊的融合圖像相較改進的融合結果圖明顯缺乏詳細的紋理信息。可見添加IFTB 模塊對可見光與熱紅外進行預融合可以減少卷積造成的細節丟失。同時本文測試了驗證數據集,通過7 個融合網絡主流評價指標來進行客觀驗證融合網絡,包括熵(En)、空間頻率(SF)、視覺信息融合保真(VIFF)、差異相關性的總和(SCD)、平均梯度(AG),圖像結構相似度指標(QY)以及基于人類感知的度量(QCB)。由表1 可知,添加了IFTB 模塊的融合網絡在空間頻率和平均梯度上提升較大。同時可看出,增加了權重模塊在圖像熵和結構相似度指標上提升較大。權重模塊因增加了火焰煙霧權重導致融合圖像整體空間頻率下降,但權重模塊使紅外圖像和可見圖像之間的特征緊密相連,在迭代學習過程中,緊密連接的特征的傳輸使融合更加充分。綜合比較,同時添加權重模塊和IFTB 模塊能全面提升圖像融合網絡的融合效果。
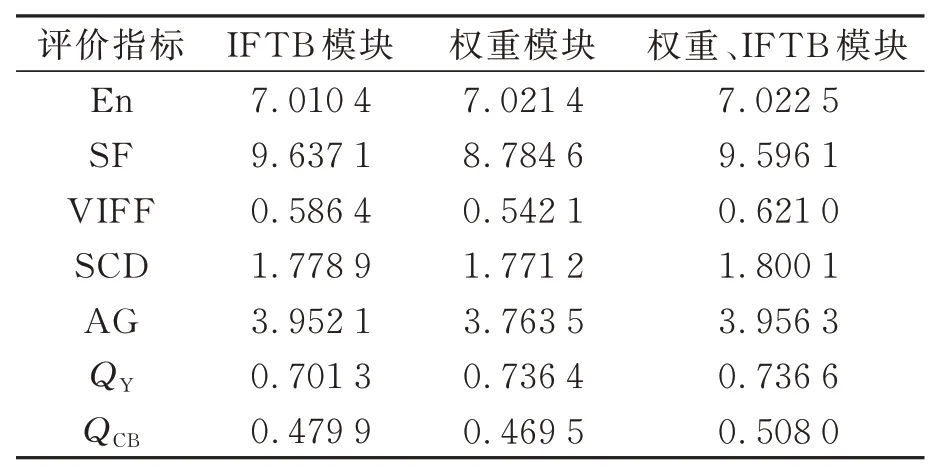
表1 權重模塊和IFTB模塊在融合結果上的平均估計指標Tab.1 Average estimation indicator of the weight module and IFTB module on the fusion result
4.3 分割網絡分割效果與性能評估
對于改進后的語義分割網絡,本文通過對比平均交并比(Mean intorsection over unin,MIoU)和每秒檢測幀數(FPS)來評估網絡的分割精度和檢測效率[18-19]。MIoU 計算公式如式(16)所示:
式中:TP 表示正確分割實驗室火焰煙霧區域的像素數量,FN 表示被錯誤標記為實驗室內背景的火焰煙霧區域像素數量,FP 表示被錯誤標記為實驗室背景的像素數量。改進的Deeplab3+分割網絡和Deeplab3+基礎分割網絡的融合實驗室火災煙霧圖像分割量化指標對比結果如表2 所示。
由表2 可知,改進Deeplabv3+分割網絡模型的MIoU 和FPS 分別為91.27%和11.96,兩種指標比Deeplabv3+基礎分割網絡模型分別提升了3.47%和-0.6,因此改進Deeplabv3+分割網絡可以通過損失較少檢測效率取得更高的分割精度。
本文在煙霧遮擋以及火苗小的情況下,通過改進后的Deeplabv3+分割網絡分別對可見光與融合圖像中的火焰進行分割識別,分析融合網絡對兩種情況下火焰煙霧分割識別性能的提升。不同情況下的Deeplabv3+火焰分割識別MIoU 結果如表3 所示。由表3 可知在煙霧遮擋情況下,融合熱紅外與可見光圖像提供熱輻射信息,提高火焰分割識別精度。在火焰燃燒前期,火苗較小,融合圖像通過增強顯著性提高了小火苗的分割識別精度。

表3 不同情況下改進Deeplabv3+的火焰分割識別結果(MIoU)Tab.3 Flame segmentation and recognition results of improved Deeplabv3+ in different cases (MIoU)
為驗證改進后的分割網絡模型的分割性能,在相同實驗環境下,對改進的Deeplabv3+網絡與Deeplabv3+基礎網絡進行實驗室火焰煙霧分割效果對比,結果如圖10 所示。實驗包含4 組,其中組1 和組2 為Deeplabv3+基礎網絡和改進的Deeplabv3+網絡對融合圖像的分割識別,由分割識別結果可知,融合后的圖像可以更好地結合可見光紋理信息和熱紅外熱輻射信息,精確地分割出火焰煙霧區域。Deeplabv3+基礎網絡可完整地分割識別實驗室火災煙霧區域,但火焰煙霧邊緣處理相較于標注圖仍存在不小的差異,將標注圖中的火焰煙霧邊緣分割過于平滑,邊緣細節信息丟失嚴重。在火焰煙霧與實驗室背景對比度較低的區域,Deeplabv3+基礎網絡存在誤分割情況。改進的Deeplabv3+網絡可以在相同圖像場景下對火焰煙霧邊緣分割識別更加準確清晰,較好地保留了火焰煙霧細節特征,具備較好的泛化能力。組3 和組4 為不同情況下改進的Deeplabv3+網絡對可見光圖像與融合圖像的分割結果對比。由組3 結果可知,當火焰初期火苗較小時,融合圖像增強火焰效果顯著,改進的Deeplabv3+網絡可分割識別出小火苗。組4結果顯示,當存在煙霧遮擋時,改進的Deeplabv3+網絡通過融合圖像熱輻射信息可精確分割識別出火焰。對于小火苗和煙霧遮擋情況,融合圖像通過提供熱輻射信息增強火焰顯著性,提高火焰分割識別精度。

圖10 改進Deeplabv3+網絡與Deeplabv3+基礎網絡分割結果對比圖Fig.10 Comparison of segmentation results between the improved Deeplabv3+ network and the Deeplabv3+ infrastructure network
5 結論
針對實驗室環境復雜、火苗小以及燃燒產生煙霧遮擋等導致相機采集到的火焰圖像顯著性不高,以及火焰伴隨煙霧遮擋影響識別精度的問題,本文改進了一種語義感知的實時紅外和可見圖像融合網絡,用于融合可見光與熱紅外圖像,提高火焰圖像顯著性,再對融合圖像進行火焰煙霧分割識別。對融合網絡增加中間特征傳輸模塊以及權重模塊,對Deeplabv3+語義分割網絡添加基于梯度變換的邊緣提取模塊。最后對融合網絡和分割網絡進行迭代訓練,并對驗證數據集進行測試。實驗數據顯示,基于融合紅外與可見光的火焰煙霧分割識別算法在測試集中平均交并比為91.27%,分割效率為11.96 FPS,分割效果優于Deeplabv3+分割算法。該網絡對融合實驗室圖像中火焰煙霧區域具有良好的分割識別能力,全場景語義細節分割能力突出,對于實驗室火災檢測具有一定的現實應用價值。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
