面向在線健康社區的融合時間特征個性化推薦算法研究
2023-08-31 02:26:34曹錦丹鐘玉駿鄒男男等
現代情報 2023年9期
曹錦丹 鐘玉駿 鄒男男等

關鍵詞: 在線健康社區; 個性化推薦; 動態社交網絡; 個人動態偏好
DOI:10.3969 / j.issn.1008-0821.2023.09.003
〔中圖分類號〕R-058 〔文獻標識碼〕A 〔文章編號〕1008-0821 (2023) 09-0026-10
健全和完善“互聯網+醫療健康” 服務體系及支撐體系是當前推進實施“健康中國” 戰略的一項重要工作[1] 。隨著這項工作的推進, 在線健康社區(Online Health Communities, OHCs)已成為人們獲取健康信息的重要渠道。OHCs 是具有相同健康或疾病治療興趣的人在以互聯網為媒介形成的健康社區集合, 是人們獲取健康信息、得到情感支持、分享個人經驗和健康信息以及提供情感支持等各種與健康相關的活動的平臺。然而, 目前OHCs 平臺的用戶在健康信息搜尋和交互方面尚需進一步優化。隨著OHCs 用戶數量和信息資源的不斷增長, 導致大數據呈現低價值密度特征, 即信息過載問題。因此, 用戶對個性化推薦的需求越來越高, 以減少信息超載帶來的認知負荷。但是, 用戶的健康信息需求因其自身因素不同而具有個性化特點, 且用戶健康狀況會隨著時間推移而發生改變, 目前在線健康社區個性化推薦算法鮮有對用戶興趣的時間動態遷移特征進行賦權。如何有效構建更為豐富的OHCs用戶推薦算法, 提供更為針對性的服務, 以實現精準推薦, 已成為目前領域學者普遍關注的問題。
1國內外相關研究
個性化推薦是在數據挖掘基礎上實現的智能信息服務, 能夠有效滿足人們對各類信息的個性化需求[2] 。早期的推薦算法研究主要集中于傳統推薦算法, 包括基于內容的推薦算法、基于協同過濾的推薦算法和基于混合的推薦算法。近期基于深度學習的推薦模型成為一大熱點[3] , 但其與傳統推薦算法相比, 需要大量的數據作為支撐, 無法解決數據稀疏性問題。而研究表明, 將社交信息等輔助信息加入傳統推薦算法可緩解冷啟動和項目稀疏性[4] , 且考慮用戶興趣的動態遷移性可提升個性化推薦算法效率[5] 。故為彌補傳統推薦算法的不足, 研究者們嘗試采用多維度信息融合并加入推薦算法, 最典型的是社交關系信息、時間上下文信息。如琚春華等[6]通過構建仿真的微信平臺獲取數據, 將用戶社交關系與信任關系和偏好融合到推薦方法中, 提高了其有效性和準確度; 董立巖等[7] 意識到研究時間對用戶興趣影響的重要性, 通過在傳統的協同過濾算法中融入時間特征, 發現基于時間衰減的協同過濾算法在準確性上得到了顯著的提高。上述研究集中于電子商務、新聞、社交網絡、音樂、廣告等領域,但在醫療健康信息服務領域的應用程度還不足。OHCs 的推薦有其顯著的特殊性, 只包括提供內容服務、無評分信息、冷啟動和矩陣稀疏問題更嚴重等特性, 而且現實中用戶興趣會隨著健康狀況在不同時期階段的變化而發生改變。所以目前的已有個性化推薦算法在OHCs 中的應用還有待深入探索。
在線健康社區個性化推薦方法的研究尚不多見。現有研究主要是通過分析用戶社交關系和用戶生成內容文本語義構建網絡來實現話題內容的推薦, 且基于用戶興趣是一成不變的觀點, 將用戶以往產生的數據不分時間先后統一用來代表用戶現在的興趣。如Yang H 等[8] 通過隱含的社會關系, 采用自適應矩陣分解的方法為用戶進行推薦; Yang CC 等[9] 通過構建用戶和UGC 之間關系的異構醫療信息網絡, 向OHCs 中的用戶推薦話題貼; Yang H等[10] 通過構建用戶影響關系(User Influence Rela?tionships, UIRs)網絡計算用戶相似度, 提高為用戶進行內容推薦的準確度; 李賀等[11] 通過將提取的用戶評論關鍵詞之間形成語義關系網絡, 以便構建模糊認知圖, 實現相關疾病知識的推薦; 王欣研[12] 通過挖掘熱點問題以及問題主題相關關系,構建語義關聯主題圖譜并搭建了個性化推薦模型。
綜上所述, 個性化推薦算法已有較多研究將社交關系和時間上下文作為額外信息融入個性化推薦算法, 但是并不完全適用于OHCs 的用戶推薦。而現有的面向在線健康社區的個性化推薦, 均未考慮時間特征對用戶興趣的影響, 導致用戶興趣的動態遷移性無法體現。因此, 本研究基于其他領域的個性化推薦算法研究, 構建融合時間特征的在線健康社區個性化推薦算法, 深入探討用戶興趣的動態遷移性對提升推薦算法的準確度和有效性, 以獲得更加精準的推薦結果。
2基于社交關系和個人偏好的動態個性化推薦算法框架
OHCs 與其他類型的在線社區存在的最大區別是OHCs 用戶在交互過程中, 因每個用戶的健康狀況會隨著時間的推移而產生變化, 其健康信息需求和信息交互行為具有更顯著的動態遷移性。另外,OHCs 用戶興趣分為用戶間互動形成的社交關系和用戶日常發布信息即用戶個人偏好兩部分[13] 。基于以上兩點, 本文所構建的融合時間特征的個性化推薦算法分為3 部分: ①社交關系與時間特征融合的動態社交關系矩陣構建; ②用戶個人偏好與時間融合的用戶話題帖匹配矩陣構建; ③基于動態社交關系和個人動態偏好的個性化推薦算法構建。
2.1融合時間特征的社交關系矩陣構建
OHCs 與一般在線社區相比屬于弱社交關系媒體, 其社區成員間基于興趣構建社交關系。此外,用戶間的社會影響關系反映用戶間通過交換健康信息產生社會影響, 從而構成社交關系的互動過程。且OHCs 用戶間社會關系越強則代表兩者間的社會影響力越大, 并且兩用戶間相似度越大, 兩用戶間的相互影響程度也越大[14] 。且社會關聯理論表明,一方面具有相似特征的兩個個體間更容易建立社會關系; 另一方面具有社會關系的個體更容易表現出相似特征[15] 。所以, 從融合時間特征的用戶社會關系強度和融合時間特征的用戶間相似度出發, 構建OHCs 融合時間特征的社交關系網絡即用戶影響力網絡, 以體現用戶間基于興趣的動態社交關系。公式如下:
然而, 一方面, 用戶社會關系強度依賴于連接兩用戶的連通路徑的權值和數量; 另一方面, 用戶行為模式相似度依賴于用戶行為軌跡。要構建OHCs 融合時間特征的用戶影響力網絡, 因其不同于存在評分、評級和關注等顯式行為的其他類型在線社區, 需先依據OHCs 的隱式互動行為特點, 構建基于用戶間共同興趣產生參與話題帖的互動行為來表示社會關系的隱式行為網絡。因此, 本部分包括: ①融合時間特征的隱式用戶行為網絡構建; ②融合時間特征的用戶間相似度矩陣構建; ③融入時間特征的用戶間社會影響力計算。
2.1.1融合時間特征的隱式用戶行為網絡構建
OHCs 是用戶發布和回復話題帖進行交流的平臺, 其互動行為是基于興趣產生的隱式行為, 而不像其他社區存在顯式行為。因此, 本研究構建的行為網絡基于OHCs 中的隱式互動行為構建。其隱式交互行為定義為用戶參與同一話題帖, 認為參與同一話題帖的用戶具有相似的興趣, 且相似程度與共同參與話題帖的數量成正比, 且回復量比訪問量更能體現話題帖的受關注程度[16] 。但當一個話題帖成為熱門話題帖導致大多數用戶普遍參與其中時,反而該話題帖不能很好地代表用戶的興趣, 因而此帖對用戶共同興趣的貢獻度應相對降低。此外,OHCs 中用戶的健康狀況會隨時間改變而變化, 導致用戶興趣也隨之發生變化, 致使用戶間基于興趣的影響力隨時間推移而衰減, 表現為對時刻tk 的用戶uk 來說, 同一級聯中時刻tk 附近的用戶對uk的影響力應遠大于較早時刻的用戶, 有研究[17-18]證明了這一點[19] 。且Muniz C P M T 等[20] 受弱聯系社會理論的啟發, 認為最近的互動比以前的互動具有更大的影響力。
因此, 上述內容表現在隱式用戶行為網絡中,概括為以下3點:
1) 用戶間共同參與的話題帖數量越多, 即交互次數越多(當兩個用戶在多次參與一個話題帖時, 只能算為1 次), 表明兩者間健康信息興趣越相似, 用戶之間的權重越大。
2) 參與一個話題帖的人數越多, 表明該話題帖受歡迎程度越大, 此帖對邊權重的貢獻越小, 即每個話題帖的參與人數定義為Nu, 用其倒數代表該話題帖對本用戶邊權重的貢獻值。
3) 兩用戶間的交互時間距離現在越近, 表明兩者間的健康狀況相似可能性越大, 用戶間產生的社會影響力越大, 相應的邊權重值也越大, 其互動時間定義為兩者中后參與該話題帖的時間。
基于上述觀點首先構建動態隱式行為網絡, 以便獲取用戶間的連接強度, 公式如下:
然而, 在線健康社區中每個用戶的活躍程度不同, 越活躍的用戶, 參與的話題帖數量越多, 這就導致用戶差異問題的出現。為了解決上述問題, 本研究把用戶參與的話題帖數量用來代表用戶的活躍程度, 參與話題帖數量多的用戶, 興趣分布更為廣泛, 導致單一話題帖在該用戶參與的所有話題帖中所占的比重較小。因此, 為了區分每個用戶的活躍程度差異, 需要從每個用戶的角度出發, 構建有方向的用戶行為網絡。步驟包括:
首先, 將每個用戶參與的話題帖數量作為節點權重。
其次, 將用戶的活躍程度加入邊權重, 即在原有邊權重的基礎上除以起點用戶的節點權重。
最后, 將邊權重進行最大值歸一化。
2.1.2融合時間特征的用戶間相似度矩陣構建
因OHCs 是用戶根據自己的興趣參與話題帖討論產生互動行為的平臺, 所以其用戶傾向于與具有相似特征或相似健康狀況的用戶產生交流, 其相似度越大, 健康狀況越相似, 彼此間的社會影響力越大。而OHCs 的用戶間相似度通常采用用戶信息的相似度來衡量。且OHCs 中的用戶信息分為靜態信息和動態信息, 其中靜態信息主要是指用戶屬性信息, 動態信息包括用戶生成內容和用戶行為軌跡[22] 。故本研究融合時間特征的用戶相似度, 從用戶的屬性、用戶生成內容和用戶行為模式相似度展開, 其中融合時間特征體現在動態信息上。用戶相似度的計算公式如下:
①按權重排序選取n 個關鍵詞, 將其權值作為中心向量, 目標用戶的每一條內容變為n 維向量,稱作擴展向量, 若兩者出自同一文檔文本, 則表示為(0,0,0,…,wsx), 若存在m 個, 則擴展向量對應維度的值為wsx/ m。
②設置閾值。將上面的兩個向量利用余弦相似度公式計算兩者間的相似度, 如果相似度大于設定的閾值則加入用戶關鍵詞序列, 否則舍棄。
③若新加入的關鍵詞在Ku 中已經存在, 則進行關鍵詞權值的疊加, 否則, 直接加入新關鍵詞及其對應的權值, 即原來權值與時間衰減因子相乘后的值。使用歸一化余弦相似度衡量用戶生成內容關鍵詞序列相似度KSij。
3) 用戶屬性相似度
社會網絡理論中的個體屬性在社會關系的形成中起著非常重要的作用[27] , 并且疾病與個體屬性相關, 所以OHCs 中的個體屬性也是計算用戶健康狀況相似度的重要組成部分。而本文在用戶屬性相似度的計算方法上依舊沿用Yang H 等[10] 的研究,面對用戶屬性值的不同類型: 文本型數據若相同,賦值為1, 否則為0; 數值型數據采用最大最小值標準化公式進行求值。最后利用用戶所有屬性相似度的平均值代表用戶屬性相似度。
4) 利用XGBoost 確定權重系數
使用XGBoost 模型得到用戶相似度中3 個特征的重要性。XGBoost 模型中特征重要性是通過對數據集包含的每個特征進行計算并排序得出, 通常而言, 一個特征越多的被用來在模型中構建決策樹,它的重要性得分越高。
2.1.3融入時間特征的用戶間社會影響力計算
在OHCs中, 用戶根據其發帖和回帖產生的隱式交互活動進行連接, 產生社會影響, 且交互越頻繁越容易產生較大的社會影響。而用戶間的社會關系強度反映了兩者間的社會影響力, 且依賴于連接他們的連通路徑的權值和數量, 且隨著用戶之間距離的增加而降低[28] 。所以為了獲得兩用戶間最強的社會關系, 需要求兩點間的最短路徑。
Dijkstra最短路徑算法是有向加權圖中最基本和應用最廣泛的最短路徑算法。在有向圖中Dijk?stra 最短路徑算法可以表示為: 在構建好的有向帶權圖G 中, 給定源點A, 求其到圖G 中其他頂點的最短路徑, 具體貪心算法的策略是遍歷距起始點最近且未訪問過的頂點的鄰接節點, 直到遍歷到結束點。所以, 本文選用Dijkstra 最短路徑算法并基于上文構建的融合時間特征的有向隱式用戶行為網絡找出兩用戶間的最短路徑, 若存在多條最短路徑,取其中路徑權值和最大的路徑作為最短路徑。
兩用戶間社會影響力取決于用戶間路徑的邊權重和經過的邊數量, 故根據求得兩用戶間的最短路徑, 其包含的所有節點, 依次將兩節點的權值相乘,權值乘積越大, 代表用戶間基于興趣的社會影響力越強。
2.2融入時間特征的用戶話題帖匹配矩陣構建
OHCs 中最主要、最有價值的內容是反映用戶健康狀況和健康信息需求的話題帖。且OHCs 內的用戶興趣不僅受社交關系的影響, 還受其自身內容偏好的影響[10] 。故在獲得用戶間基于興趣的社交關系而產生的社會影響后, 還需根據用戶的自身偏好來判斷推薦給用戶的話題帖是否滿足用戶的健康信息需求, 具體可分為用戶自身內容偏好的特征提取、話題帖內容特征提取以及兩者之間的匹配程度3 部分。
1) 用戶自身內容偏好。其提取方法同上文中對用戶內容相似度中內容特征的提取方法, 即采用LDA 主題模型和融合時間的關鍵詞提取技術分別提取反映用戶健康信息需求的主題偏好和關鍵詞偏好。在數據利用方面, 利用OHCs 中用戶產生最多也是最重要組成部分的文本數據來分析用戶自身偏好: 一方面, 各大社交網站一般通過用戶生成的文本信息來挖掘用戶的自身偏好[29] ; 另一方面, OHCs成為公眾獲取健康信息的重要渠道, 其用戶基于發帖和回帖產生了大量用戶交互數據, 其中價值最大的是用戶溝通交流時所產生的文本數據。
2) 話題帖文本內容的特征提取。其具體步驟為: 先利用LDA 主題模型提取此話題帖在健康信息各個主題下的分布概率, 即該話題帖的主題特征向量; 再利用關鍵詞提取技術得到該話題帖中與疾病有關且反映用戶健康需求的關鍵詞向量, 但此處的關鍵詞提取技術不同于前文中的關鍵詞提取技術, 這里未融合時間, 原因為此處對話題帖的關鍵詞提取只是對話題帖本身內容特征的表示, 并非從用戶層面表示其健康信息興趣演變。
為了檢驗用戶內容偏好與話題帖的符合程度,需要將上述得到的表示融合時間的用戶內容偏好向量和話題帖向量, 利用余弦相似度計算兩者間相似度大小, 值越大表明兩者越相似, 用戶參與該話題帖的可能性越大, 也就是該話題帖越能滿足用戶的健康需求。根據匹配度得分形成用戶話題帖匹配矩陣, 公式為:
最后, 將R′與F 對應位置相乘, 得到最后的用戶話題帖興趣評分矩陣。針對目標用戶, 對其按分值大小排序, 形成TOP-N 推薦列表。
3實證研究
3.1數據來源
本研究以糖尿病為例。《Ⅱ型糖尿病防治指南》指出, 通過生活方式的干預, 可以減少糖尿病各種并發癥, 有效提高糖尿病患者的生存質量[31] 。其生活方式的干預需要根據病情和生活習慣等綜合因素制定個性化方案; 甜蜜家園是一個創辦于2005年的國內最知名、規模較大、管理制度比較完善、用戶的活躍程度較高的糖尿病社區[32] 。綜上, 本文選擇甜蜜家園中的“Ⅱ型糖尿病” 社區版塊, 并使用“后裔采集器” 采集2019 年5 月30 日—2022年7 月25 日的發帖數據: ①參與話題帖用戶的個人屬性包括性別、回帖數、主題數、糖尿病類型、治療方案、生日、簽到等級、用戶組、注冊時間和在線時間; ②用戶發布的文本內容及其發布時間;③用戶ID。
本研究共采集了3 699條主題帖, 包含2 424個用戶, 48 725條話題帖信息。根據本研究中構建算法的需要將其分為兩個大小不同的數據集, 其中小數據集包含13 955條數據, 應用于XGBoost 特征重要性算法確定用戶間相似度3 個組成指標的權重系數以及內容相似度中兩個模型向量的權重系數; 大數據集包含34 770條數據, 用來評價確定權重系數的個性化推薦算法和基準模型中的推薦算法。
3.2數據預處理
為保證數據的有效可用, 刪除發表的表情符號或“謝謝分享” “頂” “贊” 等評論、空評論, 以及參與話題帖小于3 和用戶信息缺失嚴重的數據。數據集中序數值屬性的空值利用其均值填充。
目前研究用戶在線生成內容得到認可最多且被廣泛使用的停用詞表有中文停用詞表、百度停用詞表、哈工大停用詞表以及四川大學機器智能實驗室停用詞庫, 本研究為了構建相對完整的停用詞表,在這4 個停用詞表的基礎上, 先將其整合, 再去除重復內容。使用Jieba分詞對評論文本進行分詞。
本研究認為隨機劃分訓練集和測試集會導致數據泄露的前瞻偏差問題, 致使存在把用戶最近的評論用于訓練, 而把早期的評論用于測試的可能性,喪失公平性, 且隨機劃分數據集訓練出來的模型的性能也無法推廣到現實世界的性能。因此, 本文利用時間戳列, 分別對每個用戶按照時間順序進行排序, 再按照8 ∶2 的比例劃分訓練集和測試集, 數據集中時間距離現在最近的20% 歸為測試集, 遠離現在時間的80%為訓練集。
3.3評價指標
在模型的評價指標上, 本研究選用個性化推薦算法領域中最常用的評價指標, 包括精確率(Preci?sion, P)、召回率(Recall, R)和F1 評分(F1-Score,F1)。F1-Score 評估算法的整體性能, 具體含義Precision 和Recall 的調和平均值。具體計算方法見式(12) ~(14):
其中, Hits 是目標用戶參與推薦的帖子數, r是推薦的話題帖數量, Miss 表示目標用戶參與但未正確推薦的話題帖數量。
3.4實驗結果
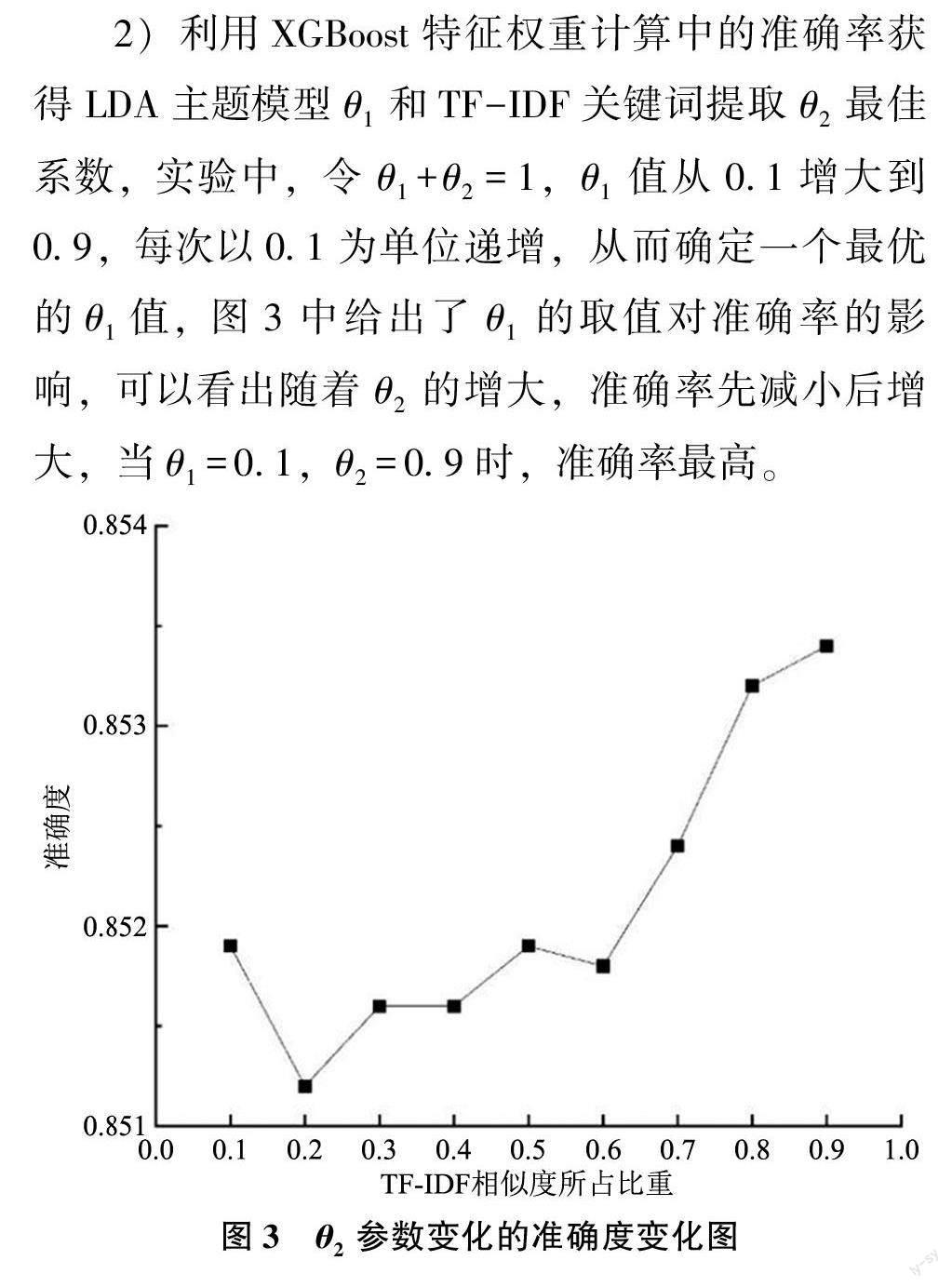
1) 在利用LDA 主題模型對文本內容進行主題分析時, 通過計算不同主題數K 所對應的主題一致性Coherence, 確定LDA 主題模型最優的主題數。主題一致性Coherence 越高表示可解釋性和語義連貫性越好, 則對應的K 值可以作為LDA 模型最優主題數, 兩個數據集分別對應K = 3 和K = 2,結果如圖1 和圖2 所示。
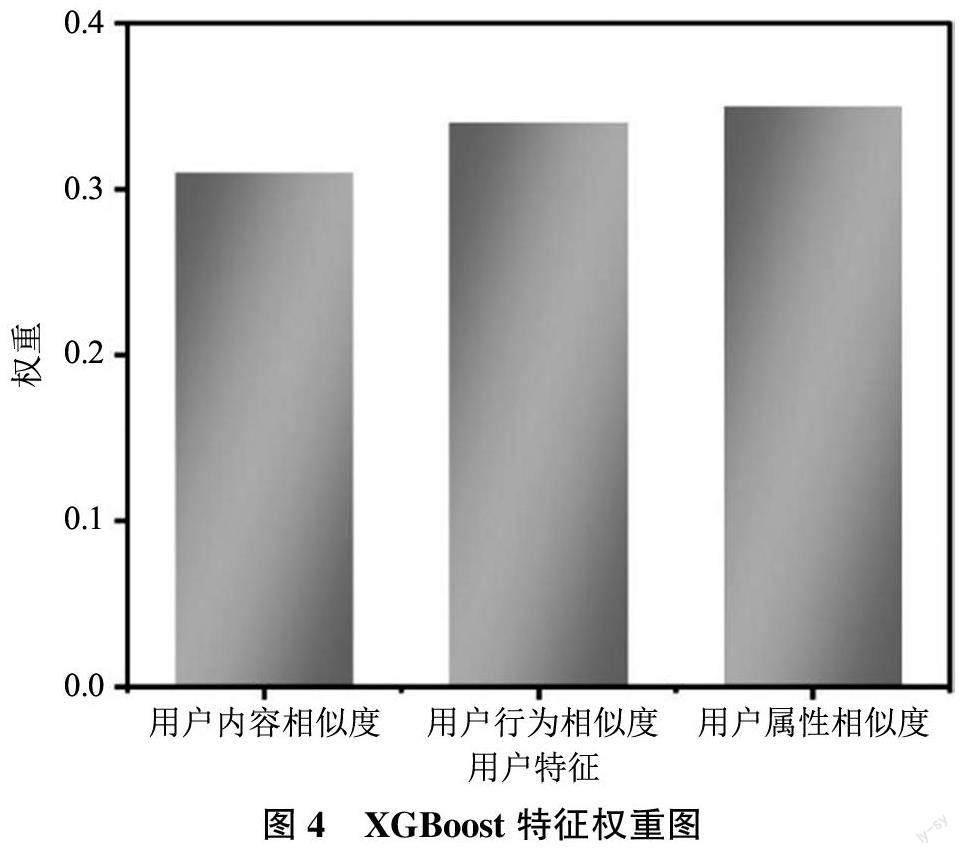
3) 利用XGBoost 確定用戶相似度3 個特征權重系數, 用戶內容相似度權重為0.31, 用戶行為相似度權重為0.34, 用戶屬性相似度權重為0.35。結果如圖4 所示。
4) 為了驗證本文構建的融合動態社交關系和個人動態偏好的個性化推薦算法(TOHCRec), 選取時間上下相關的項目協同過濾推薦算法(TItem?CF)、時間上下相關的用戶協同過濾推薦算法(TUserCF)、時間上下相關的內容推薦算法(TCB)、基于用戶社交關系和個人偏好興趣建模的推薦算法(OHCRec)。
推薦列表長度r從50~500, 步長為50。Preci?sion 隨推薦列表的增長而降低, 本文提出的TO?HCRec 方法在Precision 上明顯優于所有基準方法;Recall 隨著推薦列表長度r 的增加而上升, 本文提出的TOHCRec 方法在召回率上明顯優于所有基準方法。TOHCRec 和OHCRec 的F1-Score 隨著推薦列表長度r 的增加先下降后趨于穩定, 其他基準模型趨于穩定。
總體來看, 本文構建的TOHCRec 優于OHCRec,原因為TOHCRec 在計算用戶間社會關系和個人偏好時基于用戶興趣的動態遷移性, 考慮了時間特征, 能更加及時地感知到用戶興趣的變化。TO?HCRec 優于TCBRec 是因為TCBRec 中只考慮了用戶的個人偏好, 在很大程度上無法準確地捕捉到用戶的興趣。TUserCF 和TItemCF 是根據用戶的歷史記錄對用戶興趣建模, 分別根據用戶和話題帖的相似性生成推薦結果。其中TItemCF 更加個性化, 是將用戶參與過的話題帖進行相似度計算, 根據話題帖相似度為用戶推薦可能感興趣的內容; TUserCF與TItemCF 相比更加偏向社會化, 其考慮了兩用戶間的相互影響, 具體為先找到與目標用戶興趣相似的用戶群, 并按照相似度大小對相似用戶排序, 再將相似用戶感興趣的話題帖推薦給目標用戶。但由于OHCs 中用戶的社交關系屬于基于興趣的弱關系,導致TItemCF 的效果優于TUserCF; 而TOHCRec 優于TItemCF、TUserCF, 則是融合社交關系和個人偏好的個性化推薦算法能更準確地描繪用戶的興趣。以上所有實驗結果表明, 融合動態社交關系和個人動態偏好的個性化推薦算法, 可顯著提高推薦算法的性能。
4結語
本研究構建的融合時間特征的在線健康社區個性化推薦算法在一定程度上解決了用戶興趣存在動態遷移性的問題, 并提高了在線健康社區個性化推薦算法的準確度, 為用戶興趣存在動態遷移性和緩解冷啟動、矩陣稀疏問題提供了解決思路, 進一步完善了在線健康社區的個性化推薦算法研究, 為后續在線健康社區的個性化推薦研究提供了參考。但本研究還存在一定的局限性: 由于論壇和倫理道德的限制, 導致本研究中用戶的個體屬性不夠充足,數據來源有限, 后續可獲取多個數據平臺的數據,進行跨平臺數據的研究。
