基于深度學習的醫療數據智能分析與核驗算法研究
2023-08-27 09:02:42郭鈺哲
電子設計工程 2023年17期
李 楊,郭鈺哲,龐 樂
(西安交通大學第二附屬醫院,陜西西安 710004)
互聯網技術的不斷普及推動了醫療技術的高速發展,目前也有越來越多的智能醫療設備可以為人們提供便捷的醫療監測服務。通常情況下,醫療設備首先通過傳感器采集患者的各種生理數據,例如血流量、血壓值、脈搏值與心率值等。然后再對獲取到的醫療數據進行智能分析及處理,從而有效判斷出患者的身體健康狀況,并為后續進一步診治做先驗指導。
然而,在實際使用過程中,隨著醫療設備使用次數的增多及使用年限的增長,設備運行異常的情況也時有發生。這種情況可能會導致檢測結果不準確,并對患者的健康狀況做出誤判,從而延誤治療時機[1-2]。因此,醫療設備的異常數據識別至關重要。異常數據的本質便是從設備多個維度所組成的高維數據中,分析出與大部分數據不相符的離散數據值,并根據這些數據值對設備的運行狀態進行綜合評估。
文中基于深度學習(Deep Learning,DL)模型,設計了一套醫療設備異常數據查驗系統。該系統對自編碼器(Auto Encoder,AE)算法及對抗神經網絡(Generative Adversarial Network,GAN)進行了改進與融合,從而使高維數據轉換為低維數據,且在提取特征后再進行分析。實驗表明,該算法具有一定的實用價值。
1 異常數據核驗算法設計
1.1 基于變分自編碼器的數據降維算法
自編碼器[3-4]是一種具有無監督性質的網絡模型,其可將輸入的高維數據映射至低維空間,進而學習數據的隱藏特征并完成數據重建。
通常一個基礎的AE 網絡具有三層結構,如圖1所示。其分別為輸入層、隱藏層和重構層,這三層結構實現了兩個重要的轉換,即編碼與解碼轉換。
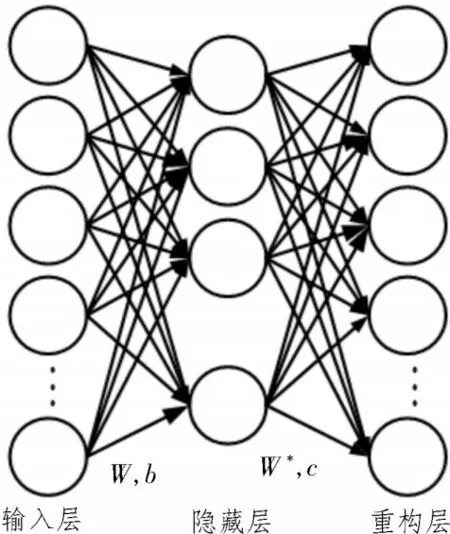
圖1 自編碼器結構示意圖
對于一個維度為n的輸入數據,可將其記為x。編碼轉換操作表征了一種空間映射關系,該映射關系實現了輸入數據x從n維到d維空間的映射轉換。編碼轉換可表示為:
式中,z表示輸入數據x映射到d維空間的輸出,σ指的是激活函數,b代表自編碼器的偏置值,W表示自編碼器的權重系數。
作為編碼轉換的逆操作,解碼轉換可表示如下:
式中,c代表自編碼器在解碼過程中的偏置值,W*表示該過程的權重系數。
深度AE 網絡將多個基礎的自編碼網絡進行疊加,作為一種無監督的深度網絡模型,其利用上一層的隱藏層表示作為網絡中下一層的輸入,從而得到更為抽象的網絡結構。深度AE 網絡的結構如圖2所示。該網絡結構模型的訓練終止目標為經過該深度自編碼網絡重構出n維空間。
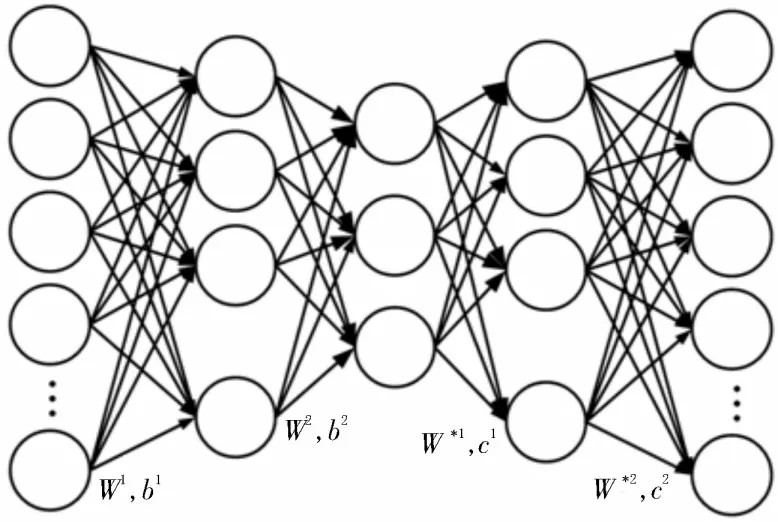
圖2 深度AE結構示意圖
數據無限接近輸入層的n維空間數據x,由此即可得到深度自編碼器的損失函數為:
其中,W代表深度自編碼器的權重系數,b、c表示偏置值,||·||2表示取L2 范數。為避免訓練過程中出現過擬合現象,此處引入權重衰減(Weight Decay),則有:
由式(4)和(5)可知,Lwd表示權重衰減。同時,在式(5)中,λ表示衰減系數,||·||F為權重系數W的F范數。
由此可見,深度AE 訓練與輸出樣本之間的映射是固定不變的,故模型對數據的噪聲較為敏感。而處理特征較多的復雜數據時,樣本的分辨誤差則較大,因此需對AE 模型進行改進。
變分自編碼器(Variational Auto-Encoder,VAE)[5-7]是生成神經網絡的模型,其結構如圖3 所示。該模型在AE 的基礎上增加了變分結構,使編碼器的輸出樣本數據對應輸入數據的均值及方差。

圖3 變分自編碼器結構
VAE 作為自編碼器的改進模型,其需要先得到觀測值p(z)的潛在分布p(x|z),具體如下所示:
在連續域z中,可將數據x使用對數表示為:
式中,DKL為KL 散度(Kullback Leibler Divergence),LVAE為x的變分下界值,其使用的是拉氏變換(Laplace Transform);q為p(z)至p(z|x)映射的變分近似;φ和θ均為編碼器的參數。求解目標即為通過優化φ和θ兩項參數,進而得到DKL的最小值。設L的表達式如式(8)所示:
由于散度值大于零,故可得:
由此即得到變分下界。
1.2 基于改進GAN的異常數據檢驗模型
生成對抗網絡[8-10]利用對抗的基礎理論來獲得理想的訓練數據。其由生成器與鑒別器兩個主要部分組成,且二者均可看作是映射函數。其中生成器通過學習真實樣本的特征,將隨機噪聲偽造成具有真實樣本特征的數據,而鑒別器則對偽造數據加以鑒別。生成器與鑒別器不斷對抗學習,直至偽造數據被判別器判定為真為止,這體現了零和博弈(Zero-sum game)的思想。該網絡的組成結構如圖4所示。
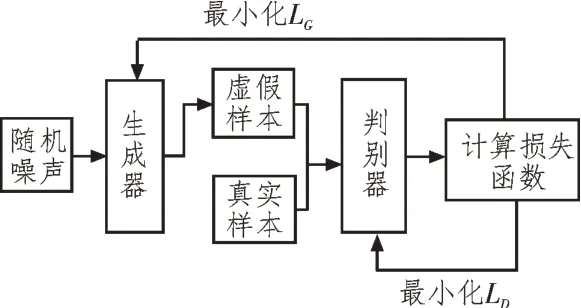
圖4 生成對抗網絡結構
在計算GAN 時,判別器通常會對輸入數據的散度進行計算,并以此作為數據真實性的判斷依據。當散度接近0 時,表示數據的虛假度較高;而接近1時,則表示數據的真實性越高。
在生成器的訓練過程中,當兩組數據的分布距離接近時,交叉熵會變為常數,此時梯度則無法下降,導致梯度消失,訓練失敗。為了解決散度導致的梯度消失問題,文中使用Wasserstein 距離取代交叉熵,其可在全局層面對各組數據的分布距離進行計算。所以,相較于初始GAN,Wasserstein 距離[11-12]能改善原始GAN 帶來的梯度下降問題。
雖然Wasserstein-GAN(WGAN)從理論上解決了GAN 模型不穩定的問題,但同時其引入的Lip 函數也會導致梯度爆炸的情況,并使算法性能變差且運算時間過長。因此,需要對WGAN 模型進行剪枝(Pruning Algorithm,PA)[13-14]操作。通過在WGAN 判別器損失函數中加入PA 項,以減少梯度運算所帶來的計算負荷。
1.3 系統模型框架
由于WGAN-PA[15-16]可對噪聲數據進行偽造,彌補了VAE 網絡對噪聲過于敏感的缺點,因此可將WGAN-PA 和VAE 進行結合,融合后的簡化模型如圖5 所示。在WGAN-PA-VAE 模型中,VAE 負責將輸入的高維數據進行編碼,并映射至低維空間;將低維數據輸入至GAN 網絡后,由GAN 中的生成器將其偽造成樣本數據;再輸入至鑒別器中,并解碼得到最終的數據,即VAE 為WGAN-PA 模型的生成器。

圖5 簡化模型結構圖
異常數據監測模型整體框架如圖6 所示。其中,輸入數據為醫療設備生成的各種狀態數據,而數據設計模塊則對狀態數據進行歸一化處理;之后再輸入至WGAN-PA-VAE 模型進行差異數據監控,并將數據傳輸至異常檢測模塊。當異常得分達到故障閾值時,便可對機器狀態做出預測,從而輸出預測結果。
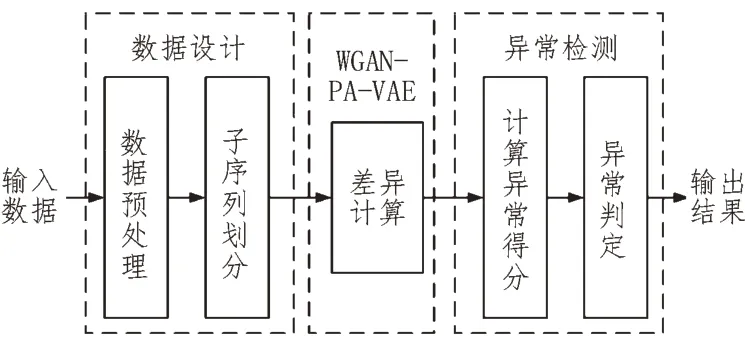
圖6 異常數據監測模型整體框架
2 實驗與分析
2.1 實驗環境搭建
實驗選擇某醫院大型醫療設備2015—2021 年運行的狀態數據作為數據集1,常用異常數據公開集KDD99-sub 作為數據集2。此外,數據集1 與數據集2 的狀態數據種類分別為12 種和41 種。數據集與實驗環境說明如表1 所示。

表1 數據集與實驗設置環境說明
2.2 算法測試
算法測試分為兩部分,分別為算法的效率及性能測試。首先進行算法效率測試,并將準確率設定為評估值,觀測準確率穩定后的迭代次數。迭代次數越少表明算法的收斂性越好,效率也越高。使用WGAN、VAE、隨機森林(Random Forest)算法及文中算法在數據集1 上進行對比驗證。最終得到的數據識別準確率與迭代次數的關系曲線如圖7 所示。
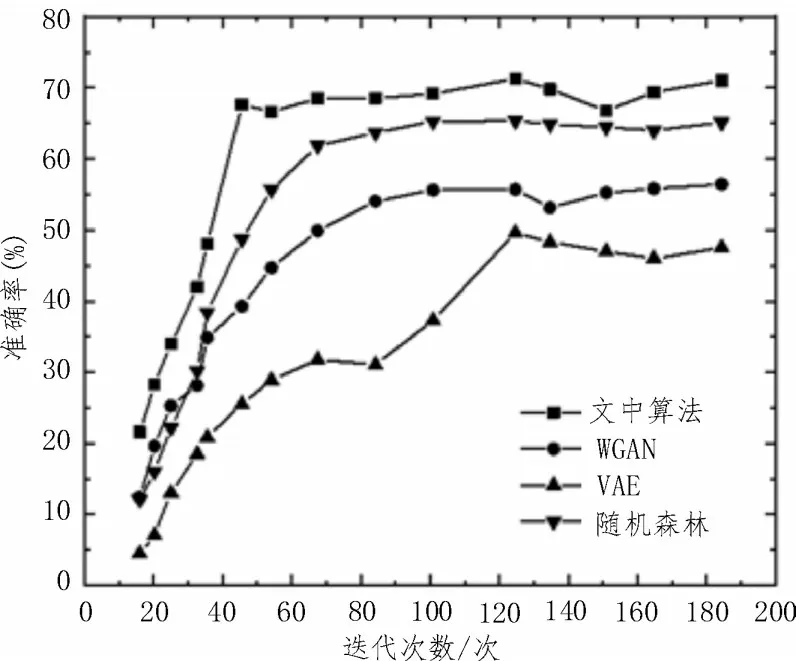
圖7 數據準確率與迭代次數關系曲線
由圖7 可知,隨著迭代次數的增加,所有算法的準確率均隨之上升并逐漸趨于穩定。其中,文中算法在四種算法中對異常數據識別的準確率最高。同時,其在所有算法中迭代次數也最少,僅使用45 次迭代即可完成。由此說明文中算法具有較高的效率,且穩定性也較優。
性能測試部分同樣對比了文中算法與WGAN、VAE、隨機森林算法,其中,WGAN、VAE 用作消融實驗(Ablation Experiment),隨機森林算法則作為外部補充對比算法。評估指標采用深度學習常用的精確率、召回率及F1 值,在數據集2 上測試的結果如表2所示。

表2 測試結果
從表2 中可以看出,所提算法的精確率、召回率及F1 值在所有算法中均為最優。這表明,將WGAN與VAE 結合可有效提升算法的性能。
同時,所提算法還能對設備的健康狀態進行分析預測。根據異常檢測模塊中的評分算法進行打分,得分高的即為異常數據量過多且易損壞的設備。此處實驗采用2015—2020 年的設備數據進行訓練,對2021 年設備情況的預測數據如表3 所示。
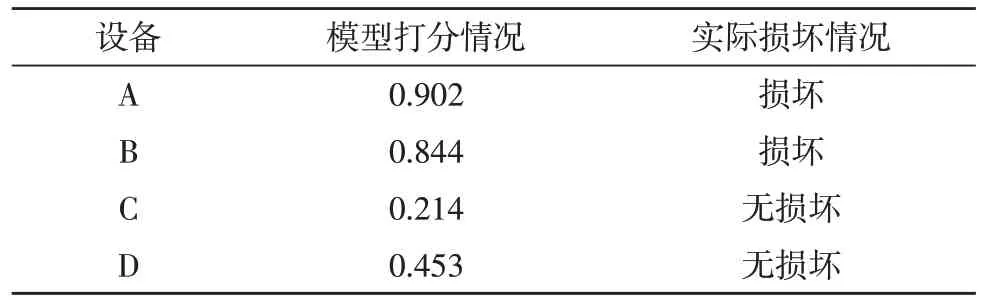
表3 得分情況
由表3 可看出,根據模型打分情況對設備的健康狀況進行評估,得到的結果較為準確,可反映設備的實際健康情況。由此證明,文中算法具有一定的實用價值。
3 結束語
異常數據監測可對復雜醫療設備的健康狀態進行全方面評估[17-18]。文中利用深度學習模型,首先,將自編碼器改進為變分自編碼器算法,然后,將對抗神經網絡進行優化并剪枝,最終,使兩種改進算法相結合,進而令模型具備了從高維數據中提取數據特征的能力。實驗結果表明,文中算法具有良好的效率及性能,可對設備的健康狀態進行打分并判斷其損壞情況,故可應用于醫療設備數據智能分析系統中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電子制作(2018年11期)2018-08-04 03:26:08
光學精密工程(2016年6期)2016-11-07 09:07:19
