非鋪裝道路凹凸不平特征語義分割方法研究*
2023-08-25 01:01:44伍文廣田雙岳張志勇
汽車工程 2023年8期
伍文廣,田雙岳,張志勇,張 斌
(長沙理工大學汽車與機械工程學院,長沙 410114)
前言
不同于平整的鋪裝道路,非鋪裝道路的凹凸不平特征將增加自動駕駛車輛路徑規劃和主動控制的難度,同時影響車輛安全性和舒適性,因此凹凸不平特征的分類識別對自動駕駛汽車在非鋪裝道路上行駛具有重要意義。由于非鋪裝道路存在表面起伏不定、道路特征紋理復雜等問題,以往應用于鋪裝道路的路面特征識別方法難以應用。現有的路面識別策略包括間接識別方法與直接識別方法。前者主要基于車輛的動態響應,可分為基于模型的方法與基于數據驅動的方法;后者通過專用儀器或傳感器直接識別路面。
基于模型的方法是指通過建立數學模型并推導路面輸入與車輛響應之間的數學關系來識別路面特征的方法。Liu 等[1]基于1/4 車輛模型得到路面輸入與簧下質量加速度之間的傳遞關系,實現路面不平度等級的在線估計。Hassen 等[2]提出一種獨立分量分析方法(ICA)應用于3 種不同的車輛模型實現路面輪廓識別。劉浪等[3]提出了一種考慮車輛加速度、基于增廣卡爾曼濾波算法的路面識別方法。綜上,基于模型的方法雖然能直觀表示出模型輸出與輸入之間的數學關系,但識別準確性依賴于模型參數。基于數據驅動的方法無須具體的數學分析過程,而是基于算法模型自主學習信號的潛在信息。應用最為廣泛的算法模型包括長短期記憶網絡(LSTM)[4-5]、概率神經網絡(PNN)[6]、支持向量機(SVM)[7]、人工神經網絡(ANN)[8-9]等。總之,間接識別方法依賴于車輛動力學響應,因此前瞻性往往不足且僅能獲取車輛車輪行駛部分的道路情況,難以用于自動駕駛汽車的路徑規劃。
直接識別方法是指采用路面輪廓儀、視覺傳感器、激光雷達等設備直接獲取路面特征信息的方法。Lushnikov 等[10]研究了幾種用于測量路面縱向粗糙度的輪廓儀特性及其測量路面粗糙度的精度。路面輪廓儀雖能達到較高的識別精度,但其移植能力差,無法廣泛應用于常規車輛,主要用于道路養護工作。基于低成本、高質量和易于使用的視覺傳感技術在過去得到快速發展[11]。Yousaf 等[12]通過尺度不變特征變換(SIFT)來建立路面圖像詞匯表并基于SVM對路面圖像單詞直方圖進行訓練和測試,實現坑洞檢測,但僅能解決路面是否存在坑洞的二分類問題。Tedeschi 等[13]開發了一種基于OpenCV 庫的自動路面故障識別系統并將其嵌入到移動應用程序中,能夠識別3 種常見的路面故障:坑洞、縱向-橫向裂縫和疲勞裂縫。卷積神經網格(CNN)由于其能直接輸入圖像而無需復雜的圖像預處理過程,被廣泛運用于圖像識別領域[14-16]。沙愛民等[17]設計了3 種CNN,分別用于病害識別、裂縫特征提取和坑槽特征提取。CNN 通常使用滑動窗口掃描整張圖像,因而實時性較差,為此Ren 等[18]提出Faster R-CNN,其采用區域建議網絡(PRN)來生成候選區域,大大提高了算法實時性能。Li[19]等基于雙目立體視覺獲取路面坑洼的圖像信息,并對圖像進行特征點匹配、視差計算等處理實現坑洼的三維重建和形態特征提取。總之,基于視覺方法雖能有效識別出道路特征,但由于受環境光線影響較大,在雨霧場景中識別性能受到較大影響。激光雷達由于其更遠的掃描距離、更高的掃描精度被廣泛搭載于自動駕駛汽車、飛行器等平臺用于環境感知、測繪工作[20-22]。Zhao 等[23]通過激光雷達掃描路面,預覽路面高程信息。劉家銀等[24]設計了一種具有互補能力的多激光雷達安裝方式,并通過距離閾值與點密度閾值對凹坑進行識別。近年來,基于點云的深度學習得到快速發展[25],Qi等[26]開創性地提出以點云為直接輸入的網絡模型PointNet,并進一步改進提出了具有局部特征學習能力的網絡模型PointNet++[27],能較好地完成點云分類、部件分割、語義分割等任務。當前公開點云數據集主要針對城市道路場景,如SemanticKITTI[28]、Waymo[29]、nuScenes[30]等,針對非鋪裝道路場景,由于缺乏相關數據集,深度學習的應用研究較少[31]。此外,由于非鋪裝道路環境復雜,路面狀況惡劣,加大了非鋪裝道路點云數據集采集、標注的難度和成本。據統計[32],一個職業點云標注者標注ScanNet數據集中的1 201個點云場景,平均每個點云場景標注時長68 s,耗費總時長為2 周(10 天,每天工作6 h),因此通過實驗制作大型的非鋪裝道路點云數據集需耗費的人力和時間成本過高。
總之,間接識別方法前瞻性不足,難以適用于復雜多變的非鋪裝道路;基于視覺方法對目標三維特征信息感知不強且受環境光線影響較大,難以對非鋪裝道路的凹凸不平特征進行準確表達。相比之下,激光雷達探測距離遠、受環境光線影響較小且能獲取準確的路面三維信息,但目前基于激光雷達的路面識別方法一方面主要針對鋪裝道路場景,在非鋪裝道路場景下難以直接適用;另一方面路面凹凸不平特征信息表達方法復雜,算力要求大且難以用于自動駕駛汽車的識別。為此,本文首先構建了基于高斯函數的凹凸不平特征表達模型,并提出了一種非鋪裝道路仿真點云生成與標注方法;其次,構建了包含仿真與真實數據的非鋪裝道路點云數據集,解決了非鋪裝道路點云數據集缺乏、制作成本高的問題;最后,提出了一種非鋪裝道路凹凸不平特征語義分割方法,通過對路面凹凸不平特征進行標簽分類,實現路面凹凸不平特征信息的簡化表達,滿足自動駕駛汽車在非鋪裝道路場景進行路徑規劃、決策與控制的需求。
1 總體框架
圖1 所示為具有凹凸不平特征的非鋪裝道路,自動駕駛汽車的路徑規劃與主動控制須考慮各類凹凸不平特征對車輛通過性、安全性與舒適性的影響。為簡化表達非鋪裝道路凹凸不平特征,本文提出了一種非鋪裝道路凹凸不平特征語義分割方法,整體框架如圖2所示,可分為3個部分。(1)非鋪裝道路點云數據集構建。基于非鋪裝道路仿真模型構建仿真路面點云數據集,以及通過實驗采集數據構建真實路面點云數據集。(2)凹凸不平特征語義分割。構建基于Pointnet++的凹凸不平特征語義分割模型,輸入仿真路面點云數據集訓練學習得到最優性能模型。(3)仿真與實驗驗證及魯棒性驗證。基于各評價指標對訓練結果進行分析,驗證模型在真實路面點云數據下的適用性以及對不同場景的魯棒性。

圖1 非鋪裝道路
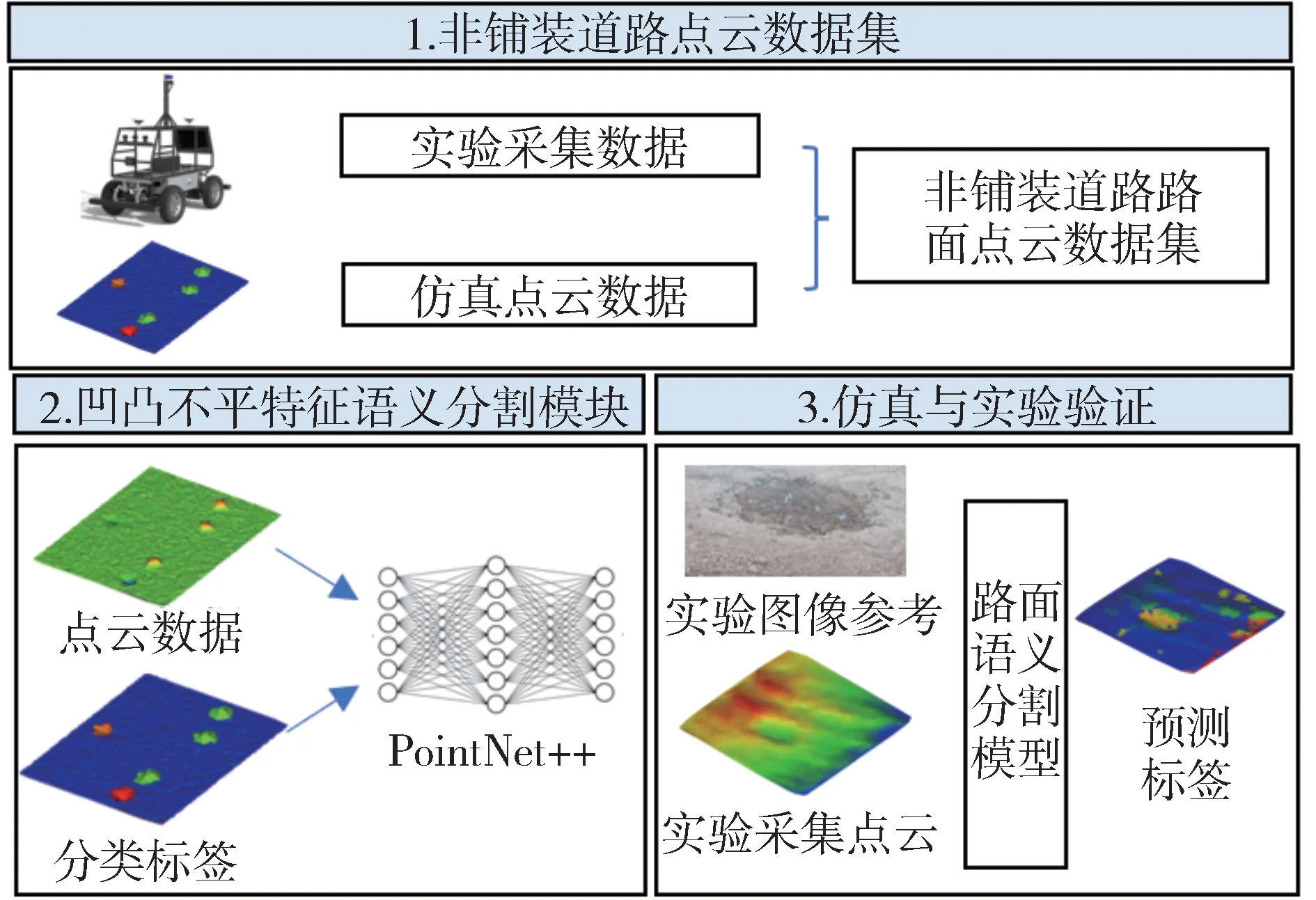
圖2 非鋪裝道路凹凸不平特征語義分割整體框架
2 非鋪裝道路點云數據集構建
非鋪裝道路環境復雜,路面狀況惡劣,加大了非鋪裝道路點云數據集采集構建的難度和成本。為此,本文提出一種非鋪裝道路仿真點云生成與標注方法,如圖3 所示。首先,構建基于高斯函數的路面凹凸不平特征表達模型,并基于隨機的形狀、范圍、位置種子參數實現路面凹凸不平特征模型的表達;其次,基于凹凸不平特征高程差計算對點云數據進行自動標注;最后,采用點云三維剛體平移方法拼接得到指定寬度長度的路面點云數據。為驗證本文提出的非鋪裝道路仿真點云生成與標注方法的可行性,采集實際路面點云數據對結果進行驗證。
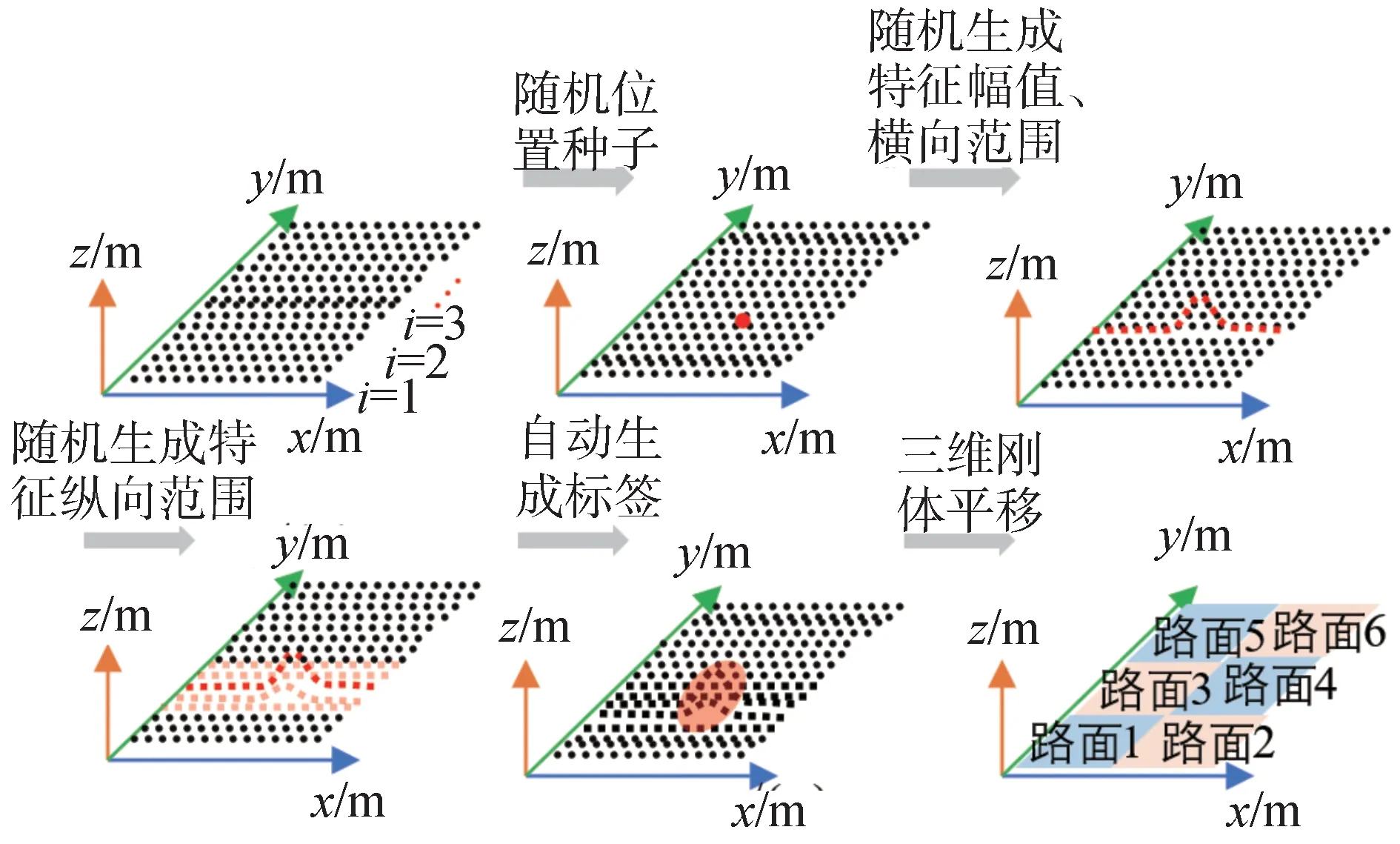
圖3 非鋪裝道路仿真數據集生成與標注流程
2.1 非鋪裝道路仿真點云生成與標注方法
非鋪裝路面凹凸不平特征的分布具有隨機性,且凹凸不平特征的深度、高度、平緩程度、范圍大小均不相同,引入高斯函數構建凹凸不平特征表達模型,如式(1)和圖4 所示。通過改變函數參數值A、B±C、B、C,可表達出凹凸不平特征的深度、高度、范圍、分布位置、平緩程度。非鋪裝道路表面布滿泥土、沙礫、石子等,十分粗糙,為此在凹凸不平特征表達模型中加入隨機噪聲來表達路面粗糙。如圖3 所示,沿y軸方向位置i處路面點云通過如式(2)所示的函數Fi(x)表示。
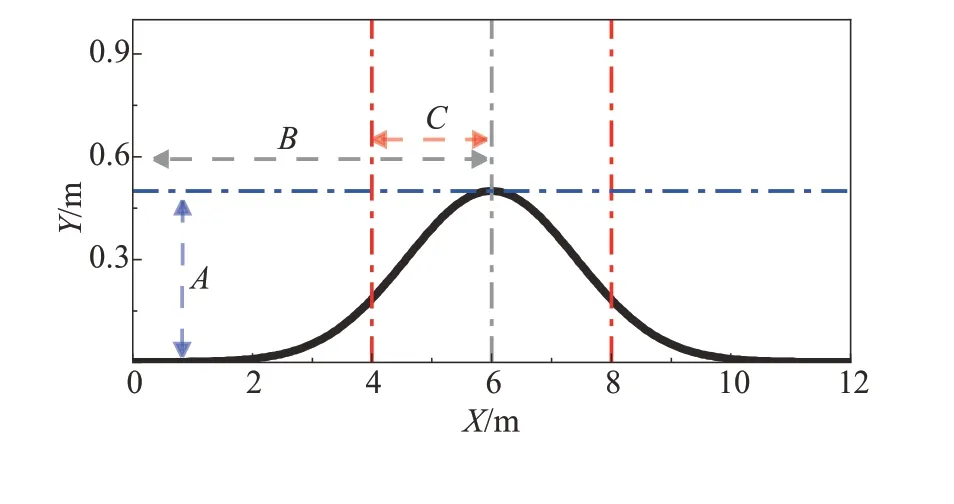
圖4 高斯函數
式中:i為函數F(x)沿y軸方向的位置編號;Ai、Bi、Ci為高斯函數參數值;ω(x)為均勻分布的隨機函數。
路面凹凸不平特征的高程差、范圍、位置對車輛行駛安全性、通過性有不同程度的影響,其中最為重要的參數是特征的高程差,影響車輪跳動量[33]、車輛通過性等性能。為此,本文選擇以凹凸不平特征深度/高度作為標簽的分類基準以簡化對非鋪裝道路凹凸不平特征的表達,制定如表1 所示的分類標準。
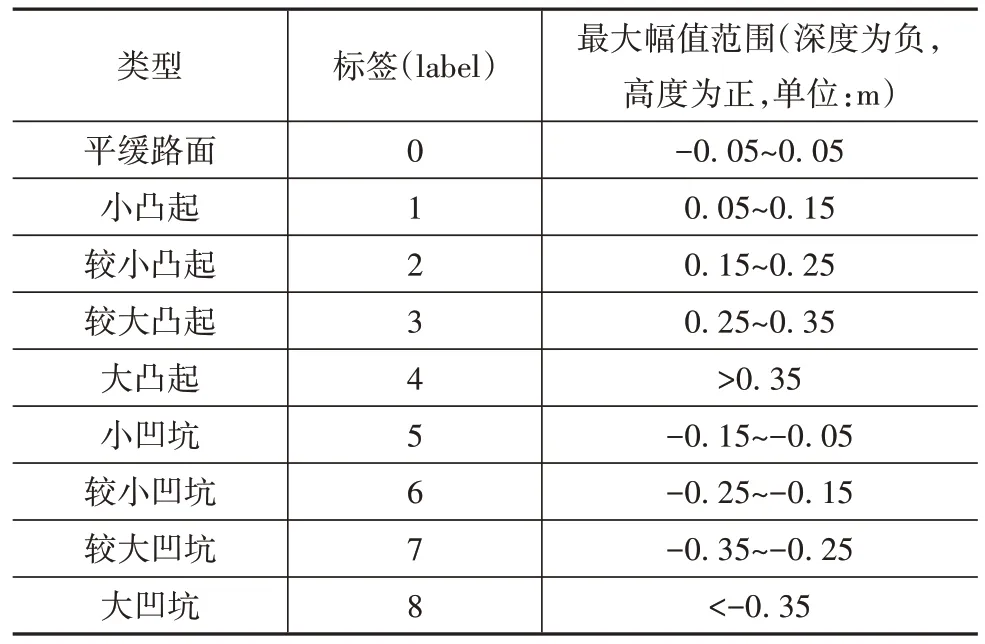
表1 標簽分類標準
本文通過如式(3)所示的點云三維剛體平移方法拼接路面點云,實現不同范圍大小的路面點云數據生成。
式中:x、y、z為變換后點云坐標;x′、y′、z′為變換前點云坐標;xT、yT、zT為點云沿X、Y、Z軸平移量。
為避免由于仿真路面點云坐標單一,使訓練模型過擬合,對路面點云進行隨機的旋轉與平移。其中點云三維剛體平移方法如式(3)所示,點云三維剛體旋轉方法如式(4)所示。
α、β、θ分別為繞X、Y、Z軸旋轉的角度。
本文處理數據設備采用型號為i9-12900KF 的處理器,圖形顯卡為RTX 3060Ti 8G。圖5 所示為采用本文方法測試10 次生成5 000 組非鋪裝道路仿真點云數據并完成自動標注的時間,得到平均值為523.73 s,平均每個道路場景生成和自動標注時間為0.105 s,而一個職業點云標注者標注ScanNet 數據集平均每個場景耗時68 s,盡管本文數據集場景和ScanNet場景不同,但可以說明的是采用本文方法能極大減少非鋪裝道路點云數據集采集和標注的時間以及人力成本。
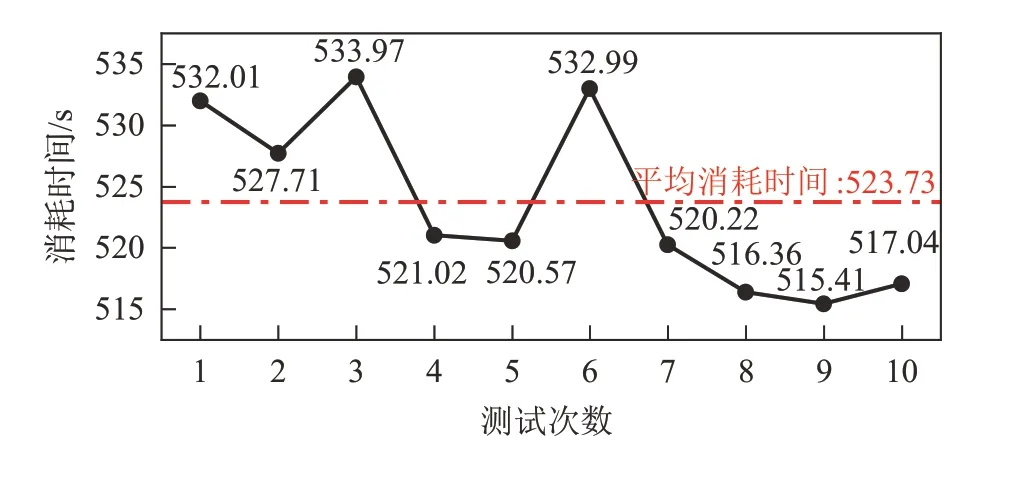
圖5 數據集生成時間
2.2 實驗點云數據采集
在實驗室環境下搭建實驗沙盤用于模擬非鋪裝道路場景,圖6 所示為實驗點云數據采集設備和實驗場景。實驗設備包括Velodyne VLP-16激光雷達、Apollo D-Kit 自動駕駛開發小車、電子傾角儀、工控機等。其中激光雷達用于采集點云數據,電子傾角儀用于測量激光雷達傾角,其技術參數如表2 所示。本文共搭建30 個非鋪裝道路場景,不同場景中凹凸不平特征數量、大小、位置等均存在差異,以盡可能體現出非鋪裝道路的復雜性,車輛與沙盤模型距離大約4 m,面向模型以約為1 m/s的速度行駛。
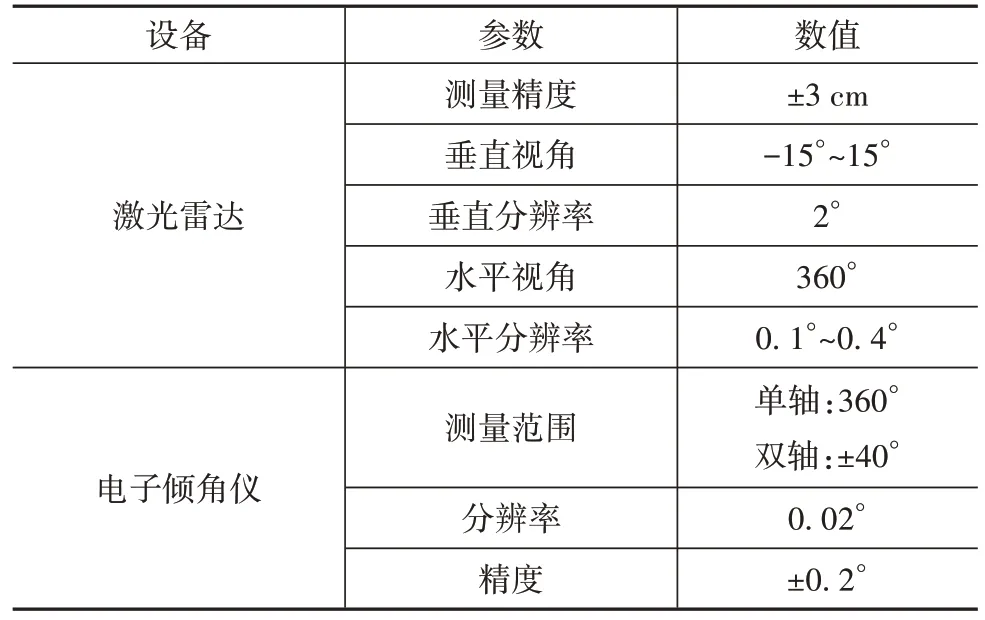
表2 技術參數

圖6 實驗設備和場景
由于激光雷達水平安裝導致路面點云數據量較少,傾斜安裝將增加路面點云數據。實驗數據采集具體流程如圖7 所示。首先,基于點云累計方法將多幀點云合成,提高點云數據密度;然后,基于點云三維剛體旋轉方法,將點云坐標系轉換至激光雷達傾斜前的坐標系;最后,基于直通濾波方法實現路面點云提取。
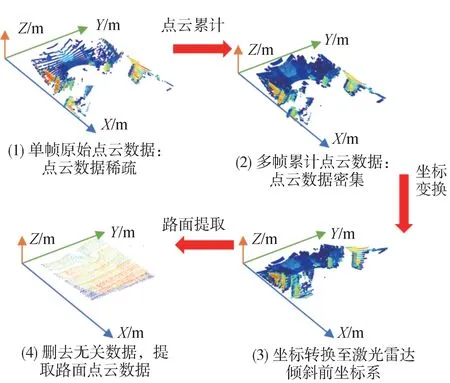
圖7 實驗數據采集流程
3 凹凸不平特征語義分割模型
3.1 道路凹凸不平特征語義分割
如圖8 所示,在道路凹凸不平特征語義分割任務中,Pointnet++基于距離插值和跨層跳躍鏈接的分層傳播策略將凹凸不平特征從下采樣點傳播至原始點。首先,在一個特征傳播層次中,通過在Nl-1個點坐標處插值Nl個點的特征值f來實現特征傳播,其中Nl-1與Nl(Nl≤Nl-1)分別為凹凸不平特征提取層l的輸入和輸出點集大小,插值函數f為基于k個最近鄰的反距離加權平均,如式(5)所示。然后,將Nl個點上的插值特征與跳躍連接點特征進行拼接,并將級聯后的特征通過"Unit Pointnet"進行類似于CNN 中的逐個卷積處理。最后,使用少數幾個共享的全連接層和ReLU 層更新每個點的特征向量,重復這個過程,直到將特征傳播到原始點集[27]。
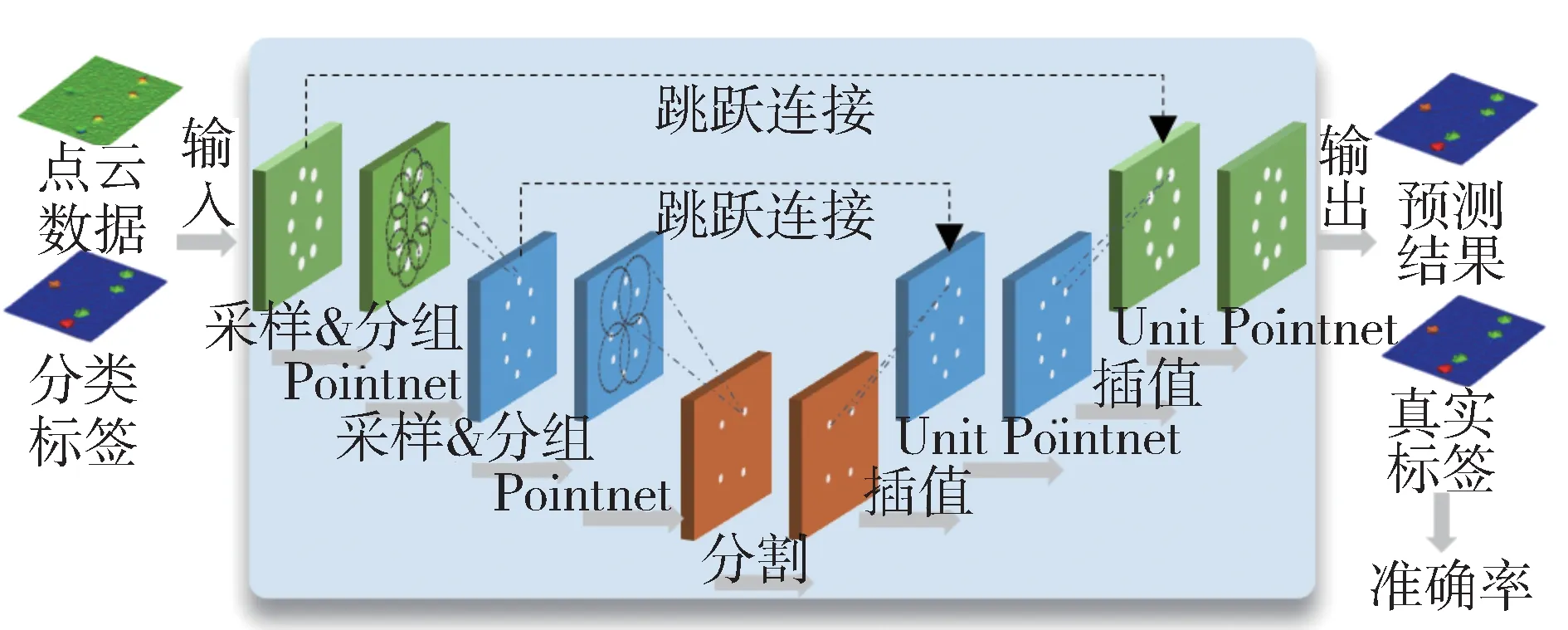
圖8 Pointnet++語義分割流程
圖9 所示為道路凹凸不平特征語義分割流程,首先,通過非鋪裝道路仿真點云生成與標注方法制作不同點云密度以及不同路面范圍的仿真點云數據集,采樣選取其中部分數據集作為訓練集,并輸入至Pointnet++道路語義分割模型進行訓練,對模型訓練準確率進行評估,保留性能最優的模型。然后,輸入不同點云密度數據集與不同路面范圍數據集驗證模型在不同工況下的魯棒性。最后,輸入實驗點云數據集至最優模型進行預測,驗證模型分割性能。
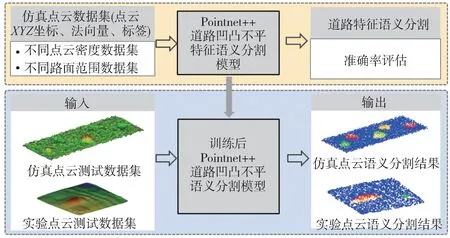
圖9 道路語義分割流程
3.2 訓練過程
訓練集包括3 500 組道路場景,測試集包含1 000 組道路場景,驗證集包含500 組道路場景,用于模型訓練的超參數如表3 所示,采用表中模型訓練超參數,模型訓練最終收斂至準確率Acc為95.30%,Loss為0.12。圖10所示為訓練集標簽占比情況,道路中大部分為較為平坦的路面,因此大部分數據標簽為0,而其它標簽占比較低。
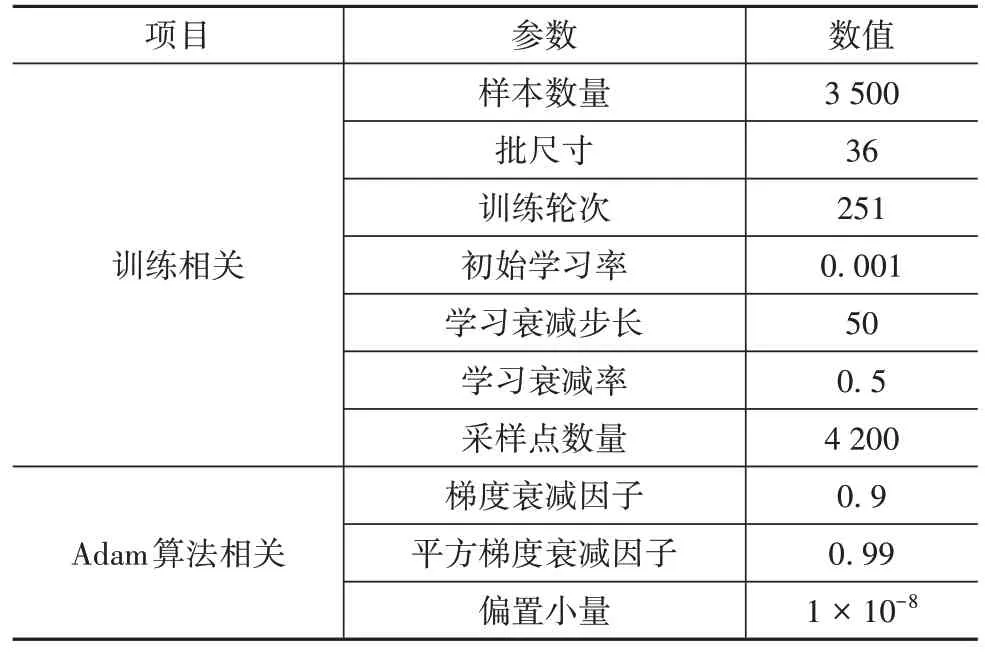
表3 模型訓練超參數設置
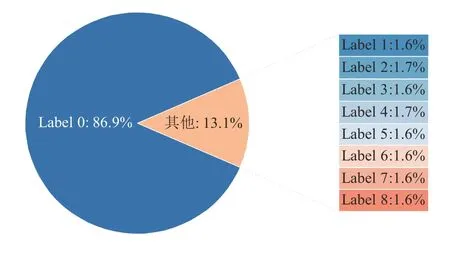
圖10 數據集標簽占比
4 仿真與實驗結果分析
4.1 評價指標
一般基于模型的準確率Acc(accuracy)、精準率p(precision)、召回率r(recall)、mIoU(平均聯合交集)來評估深度學習語義分割模型性能。但以上評價指標針對全局模型性能,在深度學習中常存在類不平衡問題,即不同類別數據比例不平衡、數據量差異較大,導致數據量多的類別準確率高于數據量少的類,模型的全局準確率不能反映各個類別的準確率。在本文中,由于路面大部分數據為較為平緩路面,導致類別0 的數據量顯著高于其它類別,因此若采用全局的評價指標,不能準確反映各個類別的分割性能。為此,本文引入局部的準確率Acci、精準率pi和召回率ri值來評估模型各類別分割性能,通過mIoU、全局準確率Acc來評估模型的整體性能。具體如式(7)~式(9)所示。
式中:TPi為真陽性,代表實際為真,預測也為真;TNi為真陰性,代表實際為假,預測也為假;FPi為假陽性,代表實際為假,預測為真;FNi為假陰性,代表實際為真,預測為假;i為類別;k為類別數。
4.2 結果分析
4.2.1 仿真數據集結果分析
將仿真點云數據集輸入至非鋪裝道路凹凸不平特征語義分割模型中進行訓練,模型超參數如表3所示,在驗證集上測試模型是否發生過擬合,在測試集上測試網絡的準確率Acc,結果如表4 所示,表明訓練的網絡整體上有較好的性能。圖11 所示為測試集部分預測結果,其中左側為真實標簽,右側為預測標簽,可知大部分預測類別與實際類別一致,錯誤預測的類別相差等級較小。如圖11(a)所示,部分預測標簽結果為8,而實際標簽為7;圖11(b)預測標簽為3,而實際標簽為4。
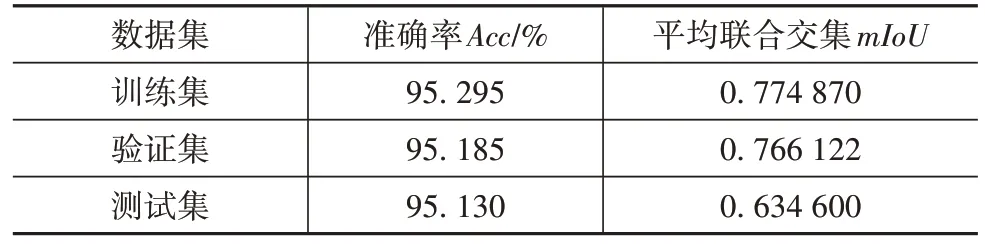
表4 不同數據集準確率
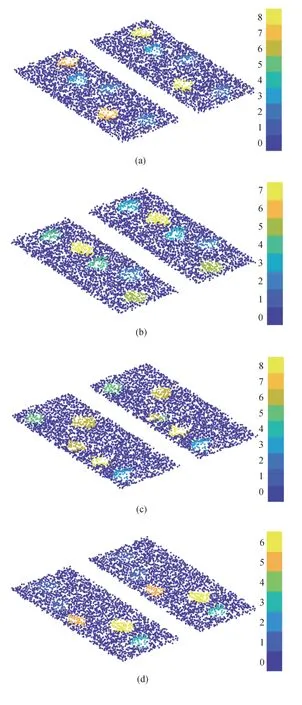
圖11 仿真數據集預測結果
測試集的混淆矩陣結果如圖12 所示,其中圖右側對應各類別召回率ri,下側對應各類別的精準率pi。從結果可以看出,類別0的召回率與精準率遠遠高于其它類別,原因是設定的路面模型中絕大部分為較為平緩路面(標簽為0),因此對于類別0的學習數據量最多,訓練效果最好。此外,其它類別的召回率與精準率相差不大,分布在70%~80%范圍內,這些特征類別識別效果差于標簽0,一方面是特征與路面連接處實際較為平緩,模型將其預測為標簽為0 的平緩路面,另一方面是相鄰標簽間存在差別不顯著的情況,如標簽1最大幅值范圍為0.05~0.15 m,標簽2最大幅值范圍為0.15~0.25 m,當數據在0.15附近時兩者相差很小,導致模型預測結果較差。在混淆矩陣圖中可以更好地體現上述原因,類別1~8錯誤預測結果中大約一半將標簽預測為0,另外一半預測結果與實際標簽相差±1。總之,模型整體在各數據集下有較高的預測準確率,且通過分析各類別的精準率與召回率,盡管類別1~8 預測效果稍差于類別0,但其召回率與精準率依舊能保持在70%~80%范圍內,且極少出現預測結果類別與實際類別差異很大情況(在近500 000個數據點的預測結果中僅有4 個數據點將真實標簽為凸起預測為凹坑),因此模型在仿真數據集下表現有較優的性能,可通過實驗數據集進行進一步的驗證。
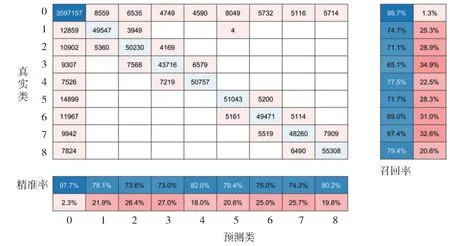
圖12 仿真測試數據集混淆矩陣
4.2.2 實驗數據集結果分析
將實驗點云數據集輸入至訓練后的語義分割模型,得到實驗點云的預測分割結果。圖13 所示為部分非鋪裝道路實驗場景的路面特征分割結果,圖左側為實驗得到的路面點云數據高程圖,右側為模型預測語義分割結果。
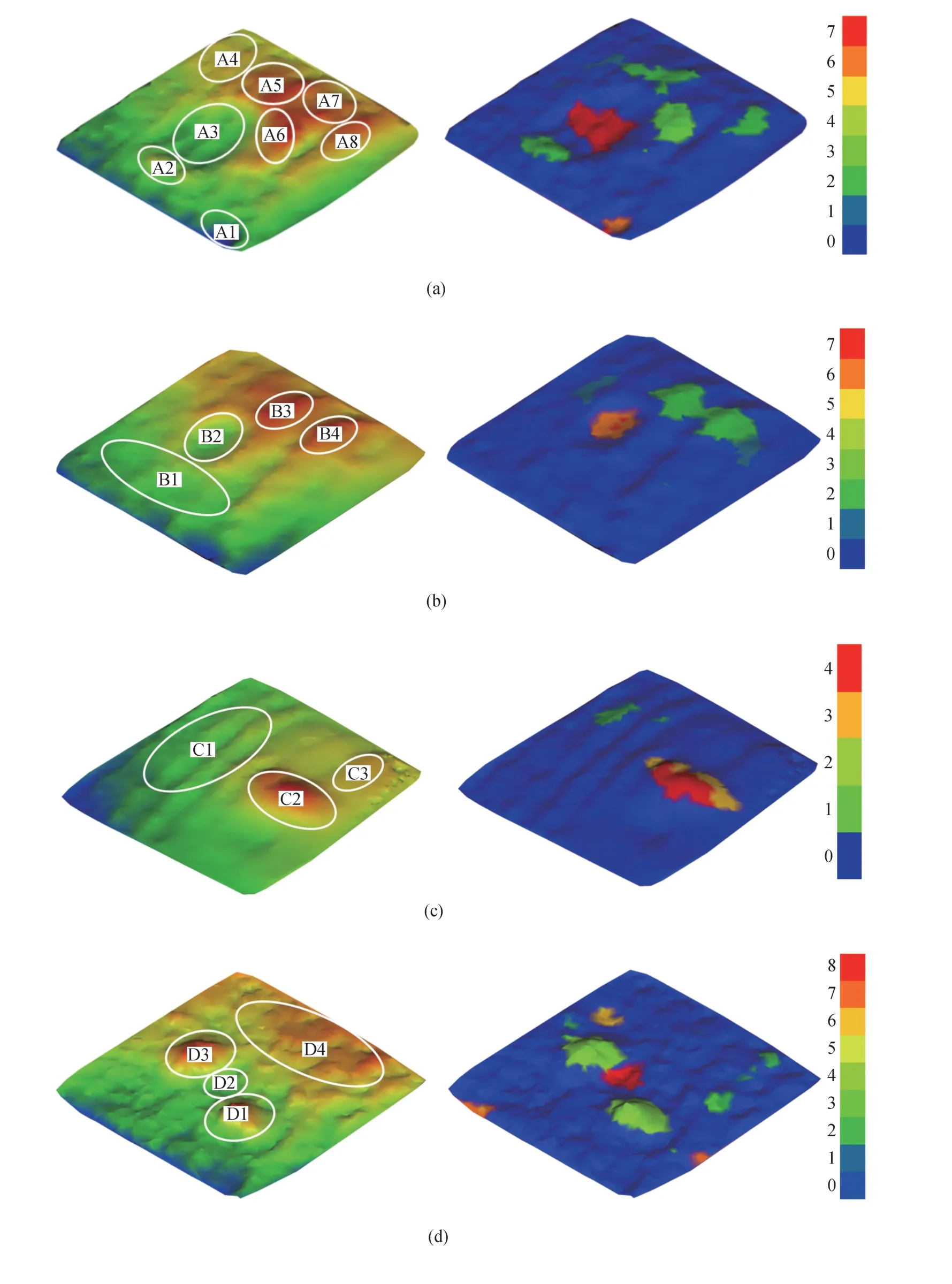
圖13 實驗數據集預測結果
從結果可以看出,在各場景下模型均有較準確的預測分割結果,在圖13(a)中存在一個凹坑A3 和多個凸起A2、A5、A6、A8,預測結果中將A3 分割為較大凹坑(標簽7),將凸起分割為較小凸起(標簽2)和較大凸起(標簽3);在圖13(b)中存在一個凹坑B2和多個凸起B3、B4,預測結果中將B2 分割為較小凹坑(標簽6),將B3、B4 分割為較小凸起(標簽2);圖13(c)中存在一個凸起區域C2,在預測結果中將C2中間較高部分識別為最大凸起等級(標簽4),而邊緣靠近C3區域部分由于與周圍區域高程差減小,預測結果中識別為較大凸起(標簽3);圖13(d)存在兩個凸起區域D1 和D3,由于這兩個區域與周圍區域存在較大的高程差,在預測結果中將凸起D1 和D3識別為最大凸起等級(標簽4)。
此外,在圖13(a)的A4、A7 區域,圖13(c)的C3區域,圖13(d)的D4區域雖然高程差較大,但由于坡度較平緩,因此將其識別為正常平緩路面;在圖13(b)的B1區域即使高程差較低,但由于較為平緩,因此將其識別為正常平緩路面;在圖13(c)的C1 區域雖然坡度較低,但由于存在一定的凸起,因此將其部分識別為凸起高度較小的標簽1,其余部分識別為正常平緩路面。總之,訓練后的道路凹凸不平語義分割模型能在實驗點云中具有良好的語義分割性能,能將圖13 中各非鋪裝道路場景下的凹坑與凸起進行合理預測分類,將有較大高程差的區域能準確預測為凹凸不平特征并分類為合理的等級,同時對高程差較小的區域也能準確預測為平緩路面,證明通過仿真路面點云數據訓練得到的模型能較好地適用于非鋪裝道路場景,完成凹凸不平特征語義分割任務。
4.3 魯棒性分析
在不同環境條件下算法的性能可能受到不同程度的影響,為驗證本文非鋪裝道路凹凸不平特征語義分割方法的魯棒性,分別考察不同路面點云數據密度、路面范圍的魯棒性。
4.3.1 點云數據密度
在實際路面點云數據采集過程中,由于激光雷達采樣頻率、數據量和通道數不同,以及車輛行駛速度的不同都會影響點云數據密度,因此本文研究點云數據密度對模型性能的影響。訓練集設定為路面點云范圍為10 m×4 m的路面,點云數據量為3 200,測試集設定為在與訓練集相同路面點云范圍情況下點云數據量為2 200~4 200 的仿真數據集,數據量越大點云的密度越大。如圖14 所示,在不同的采樣點數目下,通過已訓練網絡進行驗證,在各個采樣點數目下準確率均在94%以上,且隨采樣點數目無明顯的變化趨勢,結果表明模型對點云數據密度有較優的魯棒性。
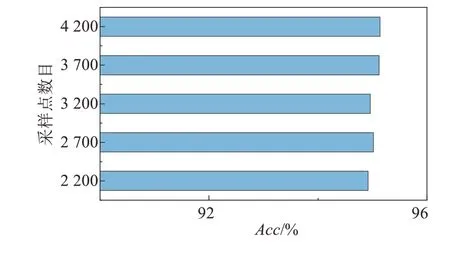
圖14 實驗數據集預測結果
4.3.2 路面范圍
非鋪裝道路路面寬幅變化大,激光雷達型號、安裝方式的不同會導致激光雷達掃描到路面的范圍不同。為研究模型對不同路面范圍變化的魯棒性,設計如表5 所示的不同尺寸路面點云作為測試集,將測試集編號為2、4、7、9 的路面點云數據集分別選取3 500個路面數據組合為訓練集,模型訓練超參數如表3所示。
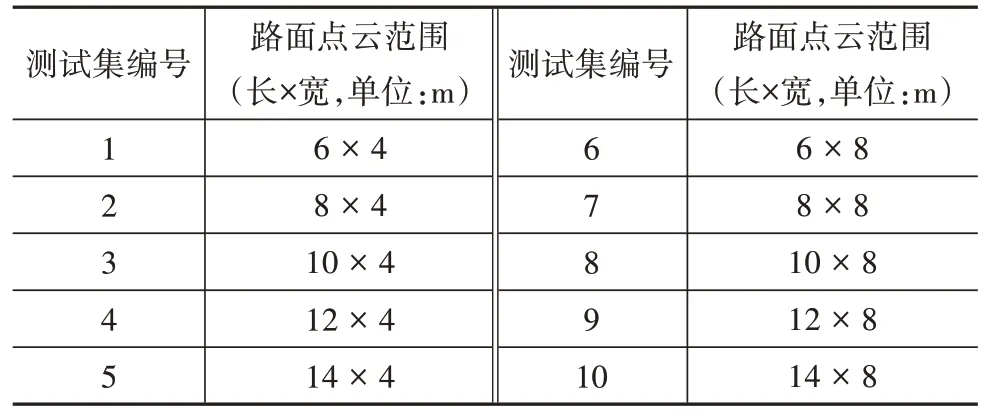
表5 不同尺寸路面點云測試集
圖15 所示為路面范圍魯棒性預測結果,其中Acc為整體預測準確率;Acc1~8表示標簽1~8的平均準確率;mIoU為平均聯合交集。從結果可以看出,各測試集下Acc都高于93%,說明模型整體預測結果較為準確。在各測試集下的Acc1~8值低于Acc值,但都高于60%,其主要原因有以下兩點:(1)在凹凸特征邊緣處錯誤識別為正常平緩路面(標簽0);(2)將凹凸特征錯誤識別為相鄰標簽。各測試集mIoU在1~8 測試集都在0.6 以上,9~10 兩個測試集在0.5 以上。模型整體對路面范圍具有一定的魯棒性,但會隨著路面長度的增加,其識別準確率降低,如測試集1 至測試集5,當路面長度由6 依次增加至14 m 時,模型的Acc、Acc1~8、mIoU分別從95.68%、73.74%、0.672 6 下降至94.35%、66.86%、0.588 9。此外,路面寬度也會影響模型識別準確率,如圖15 中測試集1~5 的Acc、Acc1~8、mIoU都高于對應的測試集6~10,說明模型識別準確率隨著路面寬度增加而降低。總之,模型對路面范圍具有一定的魯棒性,但應結合實際情況,選取盡可能小范圍的路面點云數據作為模型的輸入,以實現最佳的識別準確率。
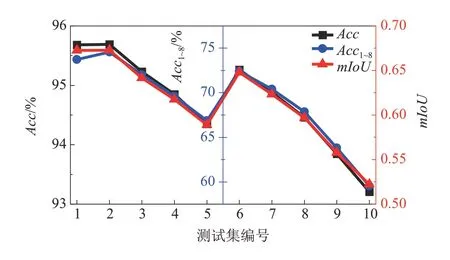
圖15 路面范圍魯棒性預測結果
5 結論
本文構建了非鋪裝道路點云數據集,提出了一種非鋪裝道路凹凸不平特征語義分割方法。研究結果提高了非鋪裝道路點云數據集標注效率,實現了非鋪裝道路凹坑和凸起等典型特征的精確識別和簡單化表達,有助于自動駕駛汽車非鋪裝道路場景下的路徑規劃與主動控制。本文相比于現有研究,主要貢獻有:
(1)構建了包含仿真與真實數據的非鋪裝道路點云數據集,用于非鋪裝道路凹凸不平特征語義分割模型的訓練與驗證,彌補了該領域的空白。
(2)提出了一種非鋪裝道路仿真點云生成與標注方法,通過提出的非鋪裝道路凹凸不平特征表達模型,生成與標注一個非鋪裝道路場景平均僅需0.105 s,實現了仿真點云數據集的快速低成本建立。
(3)首次提出了基于Pointnet++的非鋪裝道路凹凸不平特征語義分割方法,實現非鋪裝道路凹凸不平特征的準確簡化表達,結果表明該方法有較高精度、效率和魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
