基于Kafka 的跨節點消息隊列容災實踐應用
2023-08-22 01:24:02林德煜
通信電源技術 2023年11期
關鍵詞:檢測
林德煜
(中移互聯網有限公司,廣東 廣州 510653)
0 引 言
消息隊列中間件是一種為不同系統或同一系統內不同模塊提供可靠異步網絡通信的分布式框架,接收來自上游服務的消息,存儲后轉發至下游服務,在系統架構中起著承上啟下的作用[1]。Kafka 是一個處理海量數據的分布式消息系統,具有高效的數據傳輸速率,相對于其他的消息隊列系統具有較高的性能,采用發布/訂閱模式,具有較強的可靠性、海量數據處理能力以及可拓展性,是不少業務平臺選型隊列和削峰填谷功能的很好選擇[2]。
通常為了避免單點問題,高并發業務平臺通常需要滿足多節點部署。例如,業務平臺有2 個節點A和節點B 同時對外提供服務,節點A 出現故障需要容災切換時,通常會將網關入口全部切換到B 節點,如果A 節點中Kafka 隊列存在未消費消息時,為了不影響業務,需要將A 節點的未消費數據在用戶無感知的情況下同步到B 節點,并在B 節點繼續消費。
1 Kafka 生產消費模式
Kafka 支持集群部署,它的數據由broker 負責存儲和同步。Kafka broker 可以對隊列(Topic)進一步分片,Producer 負責向broker 推送數據,Consumer 負責從broker 消費數據。
Kafka 支持消費者以不同的消費組消費相同的Topic,如圖1 所示。圖1 中:每個Topic 可以分為多個分區,如P0、P1、P2、P3;每個服務器負責部分分區,一個消費組中只有一個消費者能消費到特定分區,不同的消費組內消費者可以重復消費同一個特定分區,消費者可以同時消費多個分區。

圖1 Kafka 多消費組消費
2 同步選型
在實現數據同步的過程中,按照數據源節點的流量主要分為單向同步和雙向同步[3]。對于要求實現業務雙活節點的平臺,一般需要實現雙向同步。
2.1 Kafka 同步原理
Kafka 數據包含隊列數據(包括隊列自身的Offset)和消費組Offset 數據。這2 部分數據的同步對一個高可用系統來說至關重要。數據同步指當某一節點服務器產生一條數據時,需要把該數據實時同步到其他的節點中,以便其他節點完成必要的工作或提供相關服務[4]。基于性能考慮,通常采用定期同步的方式,將隊列數據和Offset 數據從A 節點同步到備用B 節點。
為實現Kafka 不同節點的數據同步,可以在2 個節點之間引入中間件,模擬Kafka A 節點的消費者和B 節點的生產者,定期將Kafka 對應的消息數據、Topic 最新Offset 和消費組消費Offset 同步到B 節點。
2.2 Kafka 同步選型
了解了Kafka 的消費原理之后,可以選擇官方/開源的第三方框架實現異地節點,也可以自己開發一套中間件實現類似功能,二者的優缺點都很明顯。
(1)選擇官方或開源的第三方工具。其優點是可靠性相對較高,具有一定的生態成熟度,資料文檔相對完善,接入業務的時間相對較短。其缺點是相比自研工具,工具版本的更新相對不可控。
(2)選擇自研工具。其優點是版本更新迭代和代碼完全自主可控,缺點是開發周期時間長,成熟度需要時間。
綜合時間、成熟度、業務需求考慮,本次研究采用了基于官方方案做優化改進的策略。
目前,最常用Kafka 跨節點同步工具是Kafka官方自帶的Mirror Maker。Mirror Maker 在異地數據同步中廣泛使用,可靠性和成熟度較高。目前,Mirror Maker 最新的版本為Mirror Maker2(以下簡稱MM2)。MM2 基于Kafka Connect 實現,支持跨節點復制Topics 數據以及配置信息,也支持復制消費組及其消費Topic 的Offset 信息;MM2 相比Mirror Maker有較大的優化和改善,對于同一個Topic 在不同節點中配置不同的前綴,同步時識別消息歸屬,從而解決回環問題。
通常Kafka 同步組件自身并不具備良好的進度檢測,僅監控組件自身進程無法確定Kafka 是否已完成數據的同步。在實際應用中,引入一種基于滑動時間窗口的同步延遲檢測算法,基于該算法開發腳本工具MQ_Sync_Monitor,只需要在源節點部署一套,負責從源節點A 到目標節點B 的同步延遲檢測。
3 同步延遲檢測算法
3.1 檢測周期原理
滑動窗口指以固定窗口為單位不斷進行更新,如果滑動窗口已滿,那么最先進入滑動窗口的一個固定窗口被刪除,滑動窗口隨之更新一次[5]。
MM2 消費組Offset 同步時間配置字段為sync.group.offsets.interval.seconds,定義定期同步的時間為mq_sync_interval_seconds(以下簡稱MQ 同步時間MST)。該參數通常配置等于sync.group.offsets.interval.seconds,MQ 同步工具負責啟動MQ 數據的同步,因為涉及A 節點和B 節點兩邊跨節點的輸入輸出(Input/Output,I/O)操作,該操作通常需要超過1 s 才能完成。
本算法處理周期保持跟MST 一致,稱其為算法處理時間PT。
MQ 同步的Offset 數據不一致:MQ 對應的數據從A 節點同步到B 節點時,假設A 的某個Topic 最大Offset 為A_maxOffsetLast=10 000,消費者Z 對應的消費組Offset 為A_consumeOffset=8 000。
完全同步到B 節點之后,B 節點查詢得到的該Topic 最大Offset 和消費者Z 對應的消費組Offset 可能為B_maxOffsetLast=5 000、B_consumeOffset=3 000。因此,A 和B 對應的Offset 數據通常不對等。
算法原理:MQ 同步非實時,所設計B 的跨度時間要包含A 的跨度時間,假設A 的Offset 增加值為A_Sub,如果B 在跨度時間內的Offset 增加值小于A_Sub,則說明存在同步延遲問題。滑動時間活動窗口如圖2 所示。考慮間隔MPT 的同步操作可能剛好在算法處理時間PT 之前1 s 內執行,而通常同步操作可能需要超過1 s 才完成,所以即使是B 的2 次算法處理時間PT,Offset 同步上限仍然沒辦法確保包含A的1 次算法處理時間PT,因此需要計算B 的3 次算法處理時間PT。
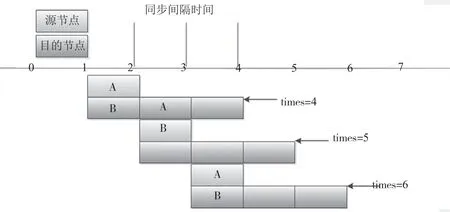
圖2 檢測滑動窗口
實現中以4 個MQ 同步時間MST 為滑動時間窗口,假如MQ 的A 間隔一次算法處理時間PT 對應的Offset 差有變動(假設差值為A_Sub),而B 對應的差值小于A_Sub,即B[times]-B[times-3]<A_SUB,則產生警告。
3.2 算法邏輯
算法邏輯如圖3 所示。

圖3 MQ 同步延遲檢測
首先,進行初始化。其代碼為
針對每個topic,包含4 個long 類型數組和一個long 類型參數
A_maxOffset//代表A 節點某topic 對應的Offset
A_consumeOffset//代表A 消費Offset
B_maxOffset//代表B 某個topic 對應的Offset
B_consumeOffset//代表B 消費Offset
times=0 算法的實現需考慮times 超過最大值的處理。同時,建議數組采用循環數組方式,只保留最新4 個元素。
其次,定時執行進度監控,間隔時間為PT,該值和MPT 時間保持一致。
通過調用MQ 提供的腳本查詢A 和B 節點MQ對應Topic 的Offset 和對應客戶端消費組Offset。
對于單位時間內A 節點自身的Offset 變化較小(如變化為0),為節省計算資源,可以選擇不做判斷處理,分別引入Min_Delay_Latest_Offset 和Min_Delay_Consume_Offset 作為topic 同一個分片最新Offset 和消費組消費Offset 同步延遲檢測判斷閾值。
如果times ≥3(B 的PT 最少要從3 開始計算),則啟動判斷:判斷A 節點的A_maxOffset[times-2]和A_maxOffset[times-3]的差值A_maxOffsetSub 是否大于Max_Delay_Max_Offset,如是,則判斷B_maxOffset[times]和B_maxOffset[times-3]的差值是否小于A_maxOffsetSub,如是,提示當前topic 最大Offset 同步延遲告警;判斷A 節點的A_consumeOffset[times-2]和A_consumeOffset[times-3]的差值A_consumeOffsetSub是否大于Max_Delay_Max_Offset,如是,則判斷B_consumeOffset[times] 和B_consumeOffset[times-3] 的差值是否小于A_consumeOffsetSub,如是,提示當前topic 消費組Offset 同步延遲告警。無論如何,執行times++。
4 生產中的應用
在實際生產中,為了實現消息隊列跨節點容災,采用Kafka MM2 實現消息數據從源節點到目標節點的同步。同時,采用腳本語言,基于上述MQ 同步延遲檢測算法實現了MQ 同步延遲檢測工具MQ _Sync_Monitor。
在每個源節點部署一套MQ _Sync_Monitor 腳本工具,負責同步延遲的檢測。需要注意的是,要實時監控MQ 同步工具和MQ _Sync_Monitor 腳本工具自身進程。生產中,可基于配置zabbix 或Prometheus 等工具實現進程的監控。通過實現該算法,當MQ 出現容災異地切換時,可以較好地保障消息數據的一致性,從而保障業務的高可用性。
5 結 論
為了實現中移互聯網有限公司業務消息隊列異地容災,采用Kafka 官方MM2 同步工具實現源節點到目標節點的數據同步,并引入了一種基于滑動時間窗口的同步延遲檢測算法,基于該算法實現Kafka 跨節點同步檢測工具。該工具在生產實踐中很好地解決了高可用分布式系統中Kafka 集群跨節點同步延遲檢測的盲區,并為內部其他項目的容災提供了新的思路和借鑒。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
