基于改進YOLOv5的駕駛員手持手機檢測算法研究
2023-08-21 09:44:03彩朔宋長明
現代信息科技 2023年12期
彩朔 宋長明


摘? 要:針對駕駛員手持手機行為檢測精度低問題,提出一種改進的駕駛員手持手機行為檢測算法。首先,在YOLOv5骨干網絡中引入改進的注意力機制模塊,更好地獲取上下文信息,提高小目標檢測的精確度。其次,采用一種改進的特征融合方法,提取三個尺度的特征,并對特征進行融合,更好地提取局部信息。實驗結果表明,與YOLOv5相比,該檢測算法在自制數據集上的精確度達到71.9%,提高了2.1%,對小目標的檢測效果顯著。
關鍵詞:目標檢測;YOLOv5;殘差模塊;注意力機制
中圖分類號:TP183;TP391.41 文獻標識碼:A 文章編號:2096-4706(2023)12-0066-04
Research on Driver Handheld Phone Detection Algorithm Based on Improved YOLOv5
CAI Shuo, SONG Changming
(College of Science, Zhongyuan University of Technology, Zhengzhou? 451191, China)
Abstract: An improved driver handheld phone behavior detection algorithm is proposed to address the issue of low accuracy in driver handheld phone behavior detection. First, an improved attention mechanism module is introduced into YOLOv5 backbone network to better obtain context information and improve the accuracy of small target detection. Secondly, an improved feature fusion method is adopted to extract features at three scales and fuse them to better extract local information. The experimental results show that compared with YOLOv5, the detection algorithm achieves an accuracy of 71.9% on the self-made dataset, get an improvement of 2.1%, which has a significant detection effect on small targets.
Keywords: target detection; YOLOv5; residual module; attention mechanism
0? 引? 言
汽車已經成為生活中普遍使用的交通工具,駕駛員在駕駛過程中接、打電話等手持手機現象比較普遍,給交通安全帶來極大的隱患[1]。因此,對駕駛員手持手機行為進行檢測具有重要意義。目前,駕駛員手持手機行為檢測算法分為:雙階段和單階段。雙階段包括:SPP NET[2]、R-CNN[3]、Fast R-CNN[4],Faster R-CNN等一系列改進后,既保證了準確度,同時也提高了檢測速度。單階段檢測算法:可通過端到端的方式直接得出檢測效果,相較于雙階段目標檢測算法,單階段目標檢測的速度更快。Redmon等最新提出了YOLO[5]、YOLOv2[6]、YOLOv3[7]、YOLOv4[8]一系列設計改進,得到的新模型檢測精度更高,檢測速度更快,但還存在檢測精度低的問題。在小目標檢測任務中YOLOv4檢測精度還沒達到理想狀態,YOLOv5更適合檢測小目標物體。
1? 目標檢測算法
1.1? 傳統的目標檢測算法
駕駛員手持手機行為檢測算法主要分為信號檢測和機器視覺檢測。基于信號檢測是通過定位手機信號,通過手機信號來檢測駕駛員是否使用手機來接打電話。TRAMER[9]等提出使用手機信號來檢測是否在接打電話,該檢測方法很容易受信號的干擾,導致檢測準確度低。魏民國[10]提出采用人臉與手機的特征點,檢測駕駛員接打電話的行為,很容易受天氣的影響。后又提出了一種基于支持向量機的駕駛員接打電話行為檢測方法,進而來判斷是否在手持手機,但該方法需要大量的計算,需要較長的時間來檢測,導致檢測速度比較慢。
1.2? 卷積神經網絡目標檢測算法
隨著深度學習的發展,卷積神經網絡目標檢測算法也得到了很大的提高。目標檢測算法大致可以分為兩大類:一階段和兩階段。雙階段Fast R-CNN網絡是以VGG16為基礎進行訓練得出的模型。在2016年,Ren等在Fast R-CNN的基礎上提出Faster R-CNN網絡模型,該網絡架構實現了端到端的兩階段目標檢測,兩級檢測器很難實現實時推理。為了解決兩級檢測器的問題,Redmon等提出了YOLO系列檢測算法,得到的新模型檢測精確度更高,檢測速度更快,但對小目標的檢測還存在不足。文獻[11]提出了用于特征增強的特征圖融合機制,融合得到檢測能力更強的特征圖來構建特征金字塔來增強小目標特征。YOLOv5增加了感受野彌補了YOLOv4對小目標檢測的不足。TPH-YOLOv5[12]是基于YOLOv5的改進,該模塊在小目標檢測上性能表現顯著。因此,在小目標檢測任務上,YOLOv5在檢測速度和精度上都能取得顯著效果。
2? 改進的YOLOv5的模型結構
YOLOv5網絡的骨干網絡對特征提取不足,隨著深度網絡層次的不斷增加,小目標會損失更多的語義信息,導致檢測精度低無法達到預想的結果。為了解決淺層特征語義信息不足而導致檢測小目標物體精度低的問題。本文提出一種改進的網絡結構,如圖1所示,通過在YOLOv5骨干網絡中引入改進的注意力機制模塊,更好地獲取上下文信息,減少語義信息的損失,更好地提高小目標檢測的精確度。其次,采用一種改進的特征融合方法提取三個尺度的特征,并對特征進行融合,以更好地提取局部信息。
2.1? 骨干增強網絡
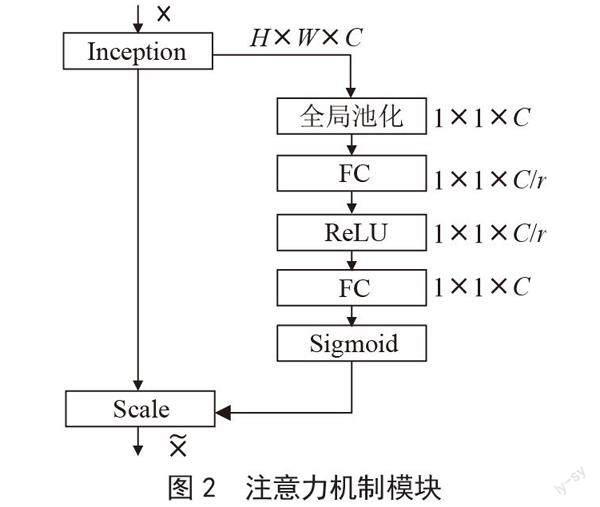
根據檢測駕駛員手持手機行為目標小、檢測距離比較遠的問題,為了提高模型的提取能力和檢測精確度,本文在YOLOv5目標檢測網絡模型不同特征提取層中分別添加坐標注意力機、通道注意力機制、空間注意力機制,通過添加多注意力機制使得新的檢測模型能夠更好地檢測小目標,同時也提高了模型的檢測速度。首先輸入特征圖并進行全局池化,得到(1×1×c)大小的特征圖。其次,把新的特征圖在進行全連接層操作,接著進行ReLU,再進行一次全連接,把高維變到低維,并且可以增加非線性因子,把有用的信息保留下來,更好的提取上下文信息。最后,經過Sigmoid激活函數得到(1×1×c)大小的權重比例,通過最后得到的權重值和原始特征圖(h, w, c)相乘得出結果。流程如圖2所示。
2.2? 改進的特征融合模塊
為了解決小目標物體檢測精度低的問題,本文通過不同特征層之間相互融合,再通過自上而下提取特征,最后將兩者進行融合從而進一步提高小目標的檢測精度,增強了淺層的語義信息,特征金字塔是自上而下的特征融合方式,增強了淺層特征的語義信息,但還存在不足。淺層的語義信息會隨著網絡結構層的增加而語義信息不斷減少,如何減少語義信息的損失,本文提出了一種改進模型。特征金字塔只對相鄰兩個尺度的特征圖進行融合,隨著網絡層次的加深,深層特征的會損失更多的信息,此時在融合相鄰特征層也不能達到理想的結果,影響特征融合的效果。可以通過提取后不同層級尺度的特征進行融合,更充分地融合局部信息和全局信息。結構如圖3所示,P2特征圖利用卷積提取局部信息;P3使用反卷積增強局部信息,進而提高其分辨率;P4表示大小為1×1的特征圖,含有全局特征,通過通道注意力機制使P4的通道數和P2通道數相同,最后通過融合操作得到F1。F1中包含了局部信息和全局信息,從而使淺層的語義信息更豐富。
3? 實驗結果與分析
實驗流程圖如圖4所示。
3.1? 準備工作
本實驗采用自制的道路監控拍攝的不同時間段、不同車型監控圖像構成的數據集。訓練集圖像采用labelimg工具進行標注,共使用1 000個數據,訓練集、驗證集、測試集劃分比例為7:2:1。實驗環境為64位Windows 10專業系統,GPU大小為12 GB的NVIDIA GeForce RTX 3060顯卡,處理器為Intel(R) Core(TM)i5-12490F。采用PyTorch深度學習網絡框架,在GPU上進行實驗。訓練后的損失函數曲線如圖5所示。
圖5中縱軸代表損失值,橫軸代表訓練次數。從圖中可以看出,隨著訓練次數的增加,損失值逐漸收斂。
3.2? 評價指標
本實驗評價指標采用準確率(Accuracy, Acc)、精確率(Precisio, P)、召回率(Recall, R)、平均精度(Average Precision, AP)、平均精度均值(mean Average Precision, mAP)。
3.3? 實驗結果與分析
為了檢驗訓練出目標檢測模型的性能,實驗對比了RetinaNet-50、YOLOv3、YOLOv4、YOLOv4-CA、YOLOv5-FIRI等算法,采用IoU閾值為0.5作為評價指標,實驗結果如表1所示。
通過表1實驗結果可以得出結論,本文改進的YOLOv5算法的準確度值達到了71.9%,與原先的算法相比,本文提出的改進YOLOv5網絡模型,精度提升了2.1%,RetinaNet-50、YOLOv3、YOLOv4三個類別的平均精確度均有所提升,YOLOv-CA和YOLOv5-FIRI的mAP也有了明顯的提高,改進的YOLOv5則在YOLOv-CA和YOLOv5-FIRI的基礎上mAP值仍有提高。這表明本文提出的改進的算法是有效的。
為了進一步驗證方案的有效性,該算法也在不同類別上進行對比,實驗結果如表2所示。
從表2可以得到,本文所提出的改進算法模型相比于YOLOv5-FIRI在不同類別上的準確率、精確率和召回率均有所提升。表明融合多注意力模塊后,改進算法能增強對深層特征顯著區域的檢測性能,減少深層特征的位置信息在傳遞過程中丟失的問題,通過精確的位置信息增強模型對目標感興趣區域的關注,有助于增強前景信息的學習同時抑制背景信息的干擾。
3.4? 消融實驗
為了驗證本文所提算法對各個模塊的作用,在自制的數據集上進行了消融實驗,實驗結果如表3所示。
由表3可知,通過在Darknet53主干網絡上加入改進的特征金字塔模塊相比基準網絡的平均精度均值(mAP)提升了2.8%、CSPDarknet53主干網絡上加入改進的特征金字塔模塊相比基準網絡的平均精度均值(mAP)提升了2.5%、Resnet18主干網絡上加入改進的特征金字塔模塊相比基準網絡的平均精度均值(mAP)提升了2.3%:證明了改進的特征融合方法對不同層級的特征進行了更好地融合,豐富深層了特征的語義信息。
3.5? 實驗結果
為了驗證模型的準確度、可靠性、有效性,本實驗采用自制的道路監控拍攝的不同時間段、不同車型監控圖像構成的數據集進行驗證,實驗效果如圖6所示。
4? 結? 論
針對駕駛員手持手機行為檢測過程中存在拍攝距離遠、目標較小等導致的檢測精度低問題,本文在YOLOv5的基礎上提出一種改進的駕駛員手持手機行為檢測算法。在YOLOv5骨干網絡中引入改進的注意力機制模塊,能夠更好地獲取上下文信息,從而提高小目標檢測的精確度。其次,采用了一種改進的特征融合方法,提取并融合三個尺度的特征,更好地提取局部信息。實驗結果表明,該算法對于小目標的檢測精度有很大的提高。
參考文獻:
[1] 劉卓凡,付銳,馬勇,等.高速跟車狀態下駕駛人最低視覺注意力需求 [J].中國公路學報,2018,31(4):28-35.
[2] HE K M,ZHANG X Y,REN S Q,et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[3] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision(ICCV).Santiago:IEEE,2015:1440-1448.
[4] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,39:1137-1149.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2015:779-788.
[6] REDMON J,FARHADI A. YOLO9000: Better, Faster, Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2016:6517-6525.
[7] REDMON J,FARHADI A. YOLOv3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].[2023-01-03].https://doi.org/10.48550/arXiv.1804.02767.
[8] 熊群芳,林軍,岳偉,等.基于深度學習的駕駛員打電話行為檢測方法 [J].控制與信息技術,2019(6):53-56.
[9] TRAMER F,KURAKIN A,PAPERNOT N,et al. Ensemble Adversarial Training: Attacks and Defenses [J/OL].arXiv:1705.07204 [stat.ML].[2023-01-03].https://doi.org/10.48550/arXiv.1705.07204.
[10] 魏民國.基于機器視覺的駕駛人使用手持電話行為檢測方法 [D].北京:清華大學,2014.
[11] 陳欣,萬敏杰,馬超,等.采用多尺度特征融合SSD的遙感圖像小目標檢測[J].光學精密工程,2021,29(11):2672-2682.
[12] ZHU X K,LYU S C,WANG X,et al. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios [C]//2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW).Montreal:IEEE,2021:2778-2788.
作者簡介:彩朔(1995—),男,漢族,河南周口人,碩士研究生在讀,主要研究方向:圖像處理;宋長明(1965—),男,漢族,河南鄭州人,教授,中理學院院長,碩士研究生,主要研究方向:偏微分方程的理論及應用、圖像處理及其教學。
