基于多特征融合和增強模型的惡意代碼檢測方法*
2023-08-17 12:38:28熊其冰王世豪
通信技術 2023年5期
熊其冰,郭 洋,王世豪
(河南警察學院,河南 鄭州 450000)
0 引言
隨著互聯網和通信技術的進步,網絡應用深度融入人們日常工作和生活的方方面面,極大地促進了信息的高效傳輸和處理。與此同時,勒索病毒、木馬、挖礦病毒、釣魚郵件等惡意代碼造成的網絡安全事件頻發,引起了人們的廣泛關注。2023 年3月,國際知名安全軟件測評機構AV-TEST 統計數據顯示[1],Windows 平臺的惡意代碼數量已增長至7.6 億多,占惡意代碼總量的61.3%。2022 年國家互聯網應急中心發布的第25 期《網絡安全信息與動態周報》數據顯示[2],在6 月13 日至19 日一周時間內,境內計算機惡意程序傳播次數高達6 342.2萬次,境內感染計算機惡意程序的主機數量約為121.6 萬。惡意代碼規模依然呈現高速增長的態勢,嚴重威脅著網絡空間安全。因此,亟須設計能實現惡意代碼精準檢測和高效分類的方法。
1 相關工作
針對惡意代碼的檢測與分類,早期研究方法多以特征碼匹配技術為主[3],人工分析判定惡意代碼的種類,提取共性惡意功能代碼片段作為特征,結合規則匹配方法,實現惡意代碼的檢測與分類。當前,主流的惡意代碼檢測與識別方法主要包括靜態特征分析、動態特征分析、混合特征分析[4]。
1.1 惡意代碼特征提取
圖像特征、字節熵、文件結構等是惡意代碼檢測中常用的幾種靜態特征,可直接從惡意代碼文本中提取。Nataraj 等人提出將惡意代碼文本圖像化的方法[5],用灰度圖像表征惡意代碼。Guo 等人在此基礎上提取惡意代碼的圖像GIST 特征[6],集成K 最近鄰(K-Nearest Neighbor,KNN)算法和隨機森林等模型實現惡意代碼檢測。蔣永康等人提出將匯編指令映射為圖像矢量[7],并基于圖像矢量實現惡意代碼的檢測與分類。Al-Khshali 等人提出基于惡意代碼文件結構和機器學習算法的檢測模型[8],驗證了惡意代碼文件結構特征的有效性。孫博文等人提出了基于代碼圖像增強的惡意代碼檢測方法[9],在灰度圖像基礎上構建RGB 三維圖像,實現檢測與分類。Saxe 等人使用信息熵分析惡意代碼文本[10],提出利用字節熵直方圖檢測惡意代碼的方法。Gibert 等人將熵特征應用于惡意代碼的同源性分析[11],實現了惡意代碼的家族分類。
操作碼序列OPCODE、控制流圖(Control Flow Graph,CFG)等靜態特征需要借助IDA Pro、OllyDump 等逆向分析工具,可獲取惡意代碼樣本的程序語義等相關特征。Santos 等人提出基于操作碼和密度空間聚類算法實現惡意代碼檢測的方法[12]。Lee 等人在提取操作碼的基礎上[13],采用N-Gram算法生成操作碼序列,以提取惡意代碼語義特征,進而實現檢測與分類。
本文主要采用靜態特征實現惡意代碼的檢測與分類,還有一些學者通過虛擬環境來動態模擬執行惡意代碼樣本,捕獲惡意代碼實時運行的行為狀態作為動態特征,以及利用靜態特征和動態特征組合起來的混合特征實現惡意代碼的檢測與分類[14]。
1.2 惡意代碼檢測模型
近幾年,機器學習算法得到了快速發展,在惡意代碼檢測與分類中也取得較多成果。Luo 等人利用圖像特征[15],結合KNN、支持向量機(Support Vector Machine,SVM)等機器學習方法實現惡意代碼的檢測和分類。Li 等人對操作碼序列進行篩選[16],結合增量學習策略改進SVM 算法的分類效果。唐明東等人將KNN 算法應用于惡意代碼的檢測與識別[17],胡君萍[18]和黃光華等人[19]從距離計算和權重組合等方面對KNN 算法進行了改進。楊望等人提出了一種基于多特征集成學習的惡意代碼靜態檢測框架[20]。
本文設計了一種基于多特征融合和增強模型的惡意代碼檢測方法。一是將傳統的單特征提取方式改變為多維度提取惡意代碼特征,并采用優化算法對特征進行優化處理,增強了特征的區分度;二是將傳統的單模型模式改變為聚合增強模型模式,利用貝葉斯優化策略進行多指標的超參數優化,采用投票策略進行增強模型結果的聚合。
2 特征提取及優化
本文選取惡意代碼的圖像GIST 特征、操作碼序列、字節統計值、文件結構4 種靜態特征作為惡意樣本的特征;并采用主成分分析法、隨機森林等算法對上述特征進行優化,刪除冗余、無效的特征,篩選出區分度高、信息增益強的特征,以提高惡意代碼檢測分類性能。
2.1 圖像GIST 特征
可視化惡意代碼檢測方法是靜態特征提取的主流方法之一,核心思想是將PE 文件可視化為灰度圖像,提取圖像的紋理和結構特征,從而實現惡意代碼的檢測與識別。本文選擇將PE 文件可視化為灰度圖像,采用GIST 算法進行圖像GIST 特征的提取。圖像GIST 特征提取流程如圖1 所示。

圖1 圖像GIST 特征提取流程
2.2 操作碼序列
操作碼序列包含了豐富的代碼功能信息,能較好地表達程序的語義,廣泛應用于惡意代碼的檢測與識別任務中。計算機程序執行時,需要將源代碼翻譯為匯編指令,進而由計算機硬件實現相關功能。匯編指令通常包含操作碼和操作數兩部分,其中操作碼表示指令要執行的功能信息。
本文先將PE文件批量輸入反匯編工具IDA Pro,以獲取樣本的匯編指令信息,包含操作碼、操作數,并采用N-gram 算法[21]對匯編指令進行切片,提取PE 文件的OPCODE 序列特征,該特征包含了惡意代碼的程序語義信息。操作碼序列特征提取流程如圖2 所示。

圖2 操作碼序列提取流程
2.3 PE 文件結構
PE 文件中存儲了代碼的文件結構屬性和執行邏輯等相關內容。本文通過LIEF 工具對惡意代碼文件進行解析,從文件屬性、文件頭信息、導出表、導入表、節區信息等角度進行統計分析,獲取惡意代碼的文件結構特征。
2.4 字節統計值
Windows 惡意代碼的PE 文件在計算機內部存儲的也是一連串01 二進制數值。本文利用統計學方法,對PE 文件中的字節進行統計分析,提取了字節統計特征。字節統計特征包含字節統計值和字節熵兩部分。字節統計值是統計文件中每8 個二進制位的整數值(0~255)的出現頻率。字節熵是統計滑動窗口內的(字節值,熵)對的出現頻率,生成字節熵直方圖。
2.5 主成分分析法和隨機森林
主成分分析法(Principal Components Analysis,PCA)是一種用于機器學習任務中進行數據降維的方法[22],能有效提取數據的主要特征分量。PCA 的主要思想是基于方差最大理論,將方差最大的方向作為主要特征,構造多組正交特征,實現主成分提取,從而實現特征優化和數據降維的效果。數據降維過程:先對原始數據零均值化,計算協方差矩陣,計算對應的特征向量和特征值,計算每個特征值的貢獻度,計算特征值的累計貢獻度,篩選出主成分。
隨機森林(RandomForest,RF)是由多棵決策樹構建的森林模型,常用于特征重要性排序。主要思想是基于信息增益、信息增益率、基尼系數、均方差等信息,依據數據誤差,計算特征相對重要性,實現特征重要度排序。
2.6 超參數優化
貝葉斯參數優化是一種常用的參數調優策略,本文將其應用于模型的參數優化,以獲取最佳參數組合的模型。貝葉斯優化算法通過對目標函數形狀進行學習,充分利用先驗信息,找到使目標函數向全局最優值提升的參數。
3 算法模型
3.1 模型框架
基于多特征融合和貝葉斯優化策略,本文設計了一種多特征融合和增強模型的惡意代碼檢測方法,該方法包含特征融合和增強模型兩個層次。第1 層為特征融合層,依據特征提取算法分別提取惡意代碼的圖像GIST、OPCODE 序列、PE 文件結構、字節統計值4 種特征,分別采用PCA、RF 等方法進行特征優化,獲取惡意代碼的融合特征,用于后續模型的檢測分類。第2 層為增強模型層,選擇RF、SVM、KNN 等作為學習模型,在訓練過程中使用貝葉斯優化策略,對上述3 種模型的參數進行優化,得到最優參數組合的增強模型。采用投票策略實現多模型預測結果的聚合,作為最終預測結果。多特征融合和增強模型檢測方法框架如圖3所示。
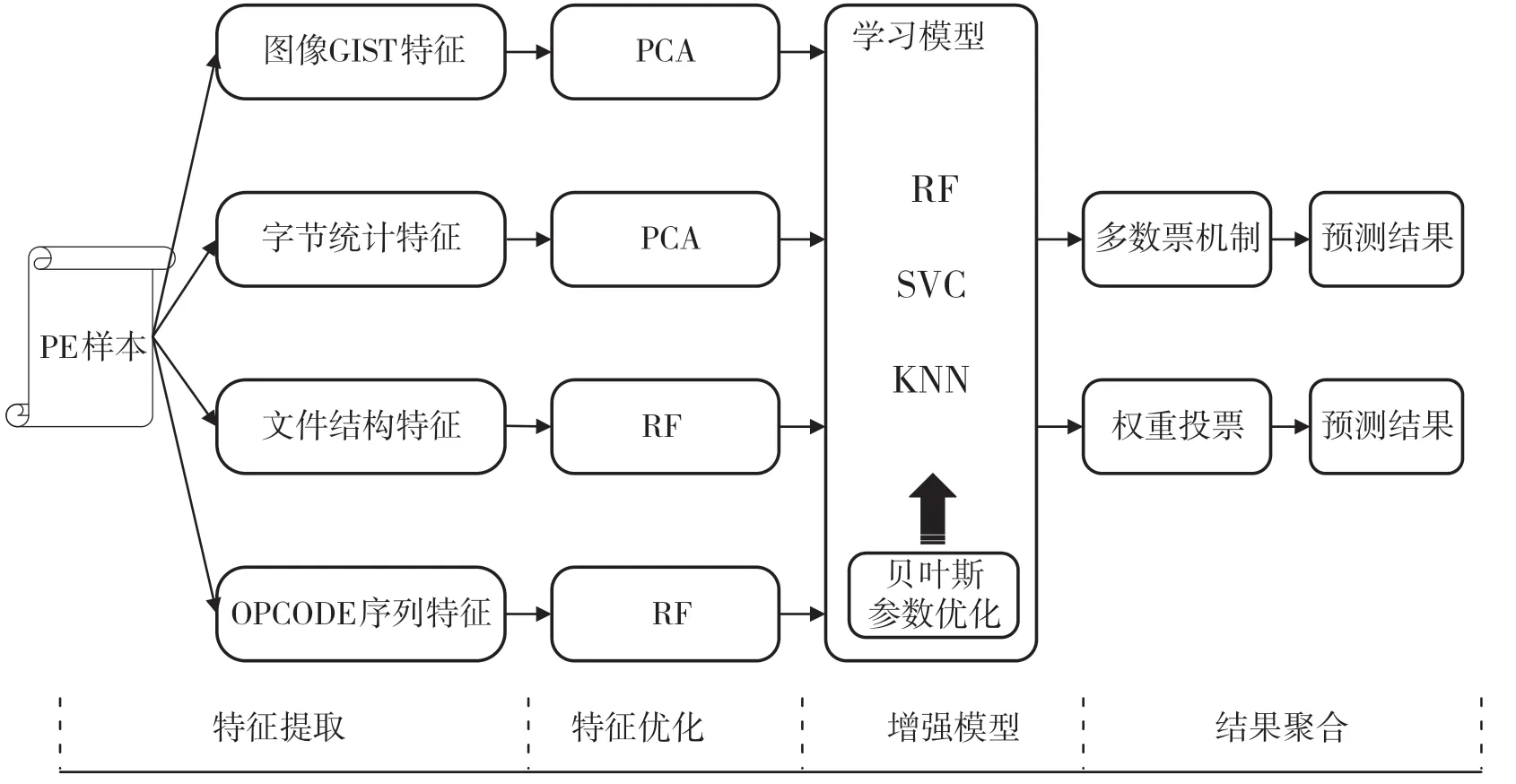
圖3 多特征融合和增強模型檢測方法框架
3.2 特征融合層
特征融合層的主要功能是實現惡意代碼樣本的特征提取并優化,融合優化后的特征作為惡意代碼的特征。通過GIST算法、IDA反匯編工具、LIEF工具、統計方法等分別提取惡意代碼的圖像GIST 特征、OPCODE 序列、PE 文件結構、字節統計值4 種特征,經過PCA、RF 等方法進行特征優化降維,以獲取惡意代碼的高區分度、低維度的組合特征。
3.3 增強模型層
增強模型層的主要功能是利用貝葉斯優化策略對選用的KNN、支持向量機、隨機森林等學習模型進行超參數優化。分別依據準確率和精準率兩個指標,進行模型的訓練優化,可得貝葉斯優化后的最佳參數組合,即為增強模型。將惡意代碼的數據特征分別輸入上述增強模型中,采用多數票和權重投票等方式進行結果聚合,計算得到最終的預測結果。
對于支持向量機算法,優化的參數主要有:懲罰系數(C)、核函數類型(kernel)、gamma等。對于隨機森林算法,優化的參數主要有:弱分類器數量、評估標準、最大深度、最大特征個數等。對于KNN 模型,優化的參數主要有:k值(n_neighbors)、距離度量(distance)、權重組合方式(weights)等。本文還改進了KNN 算法的距離度量方式和權重組合方式,其中:距離度量方式有曼哈頓距離(manhattan)、歐式距離(euclidean);權重組合方式有歸一化加權(Normalize)、反比例加權(Reciprocal)、高斯加權(Gauss)。上述3 種權重組合方式的公式為:
式中:weights[i]為當前第i個鄰居的權重值;dis[i]為與第i個鄰居的距離;dis_max為k個近鄰中的最大距離;dis_min表示k個近鄰中的最小距離;反比例加權中,const為常量;高斯加權中,sigma為常量。
4 實驗結果及分析
4.1 數據集及評價標準
本文的實驗選用DataCon 開放數據集中的16 051個樣本進行測試[23]。將數據集分別按訓練數據與測試數據的比例為5 ∶5 和8 ∶2 兩種情況開展模型驗證實驗。在實驗過程中,將訓練數據與測試數據的比例為5 ∶5 的稱為實驗1,將比例為8 ∶2 的稱為實驗2。本文選取準確率(Accuracy)、精準率(Precision)、召回率(Recall)、F1 值這4 個指標進行模型評價。
4.2 實驗設置與結果分析
在特征融合階段,將提取得到的圖像GIST 特征、字節統計值等特征通過PCA 方法進行優化,特征貢獻度設定為0.90,即保留能夠解釋原數據90%以上的方差。將提取得到的PE 文件結構、OPCODE 序列等特征通過RF 優化方法進行特征優化,將特征重要度閾值設定為0.005。本文在選定操作碼序列特征時,分別提取了2-gram 和3-gram操作碼片段,將兩組操作碼片段按權重策略組合為變長操作碼序列,即操作碼序列特征。本文保留了操作碼序列特征的前1 000 維數據進行優化。
經特征優化方法,實驗1 中數據原特征維度由2 485 降到296,約為原數據維度的11.9%。實驗2 中數據原特征維度由2 485 降至323,約為原數據維度的12.9%。兩組實驗中,圖像GIST 特征和OPCODE 序列特征下降幅度最為明顯。數據特征優化方法及優化結果數據如表1 所示。PE 文件結構特征重要度排序、操作碼序列特征重要度排序分別如圖4、圖5 所示,圖示數據為重要度排序前30 的主要數據特征。

表1 各特征優化方法及結果
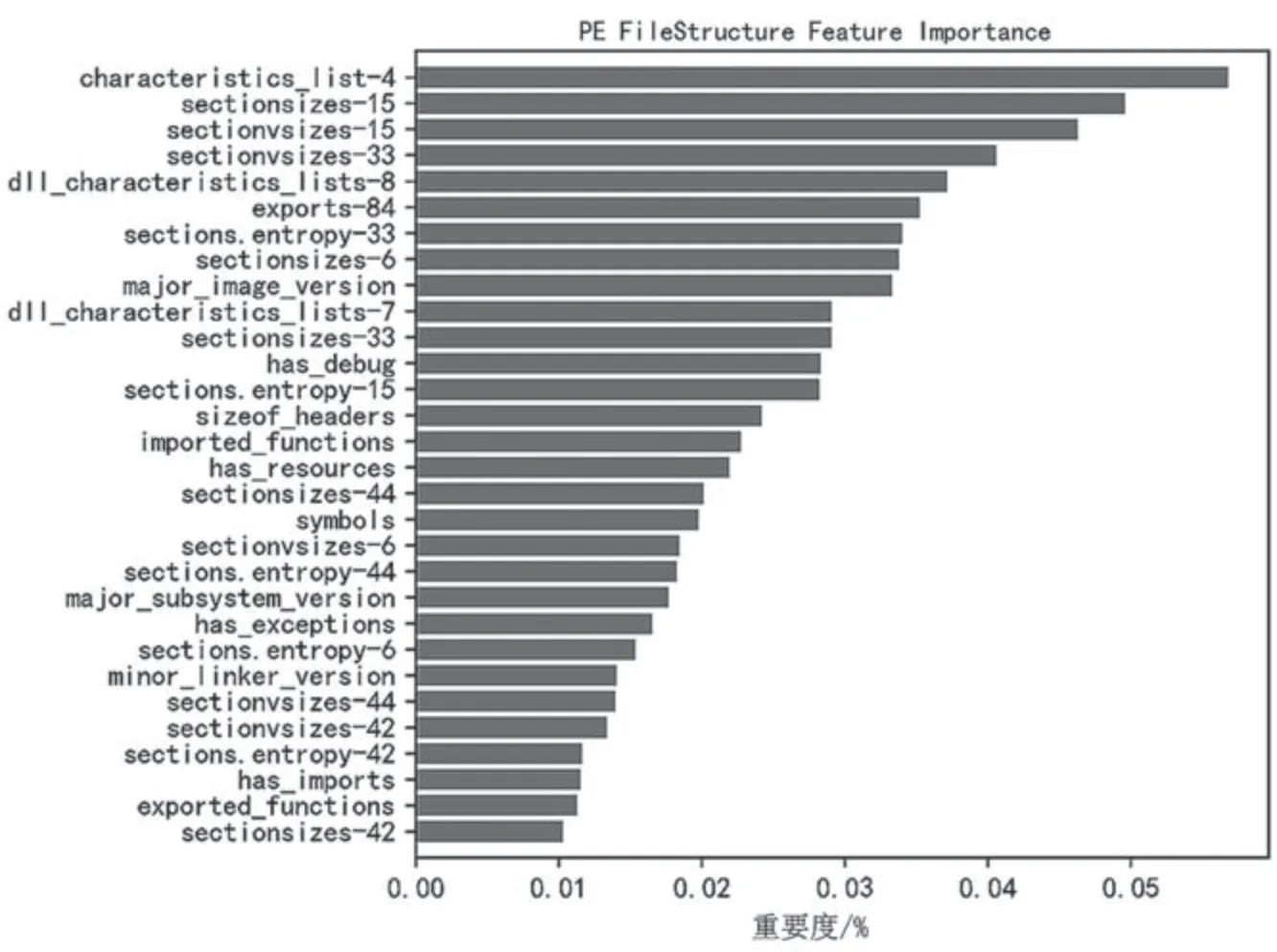
圖4 PE 文件結構特征重要度排序
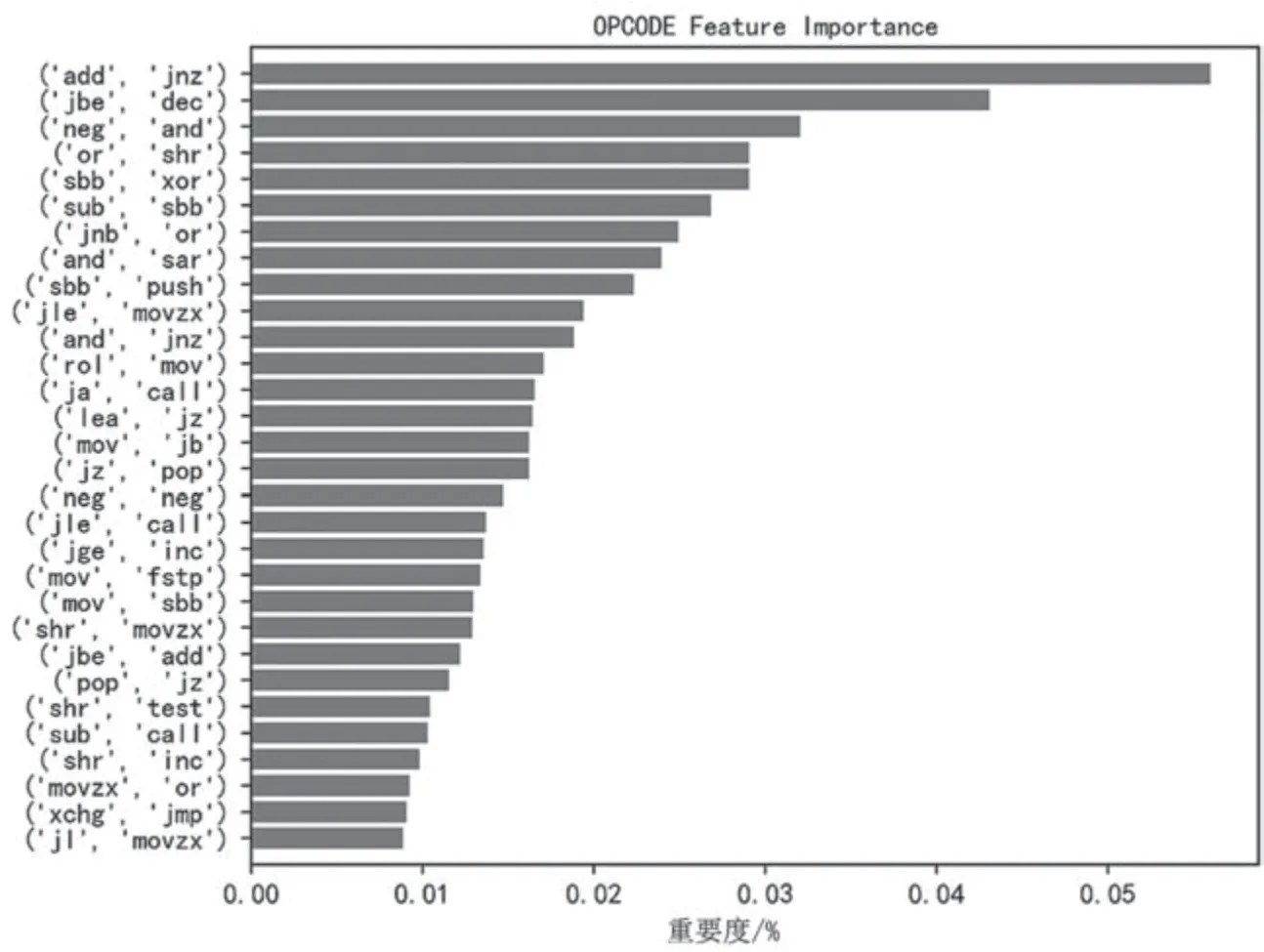
圖5 操作碼序列特征重要度排序
在增強模型階段,利用貝葉斯優化策略分別對KNN、支持向量機、隨機森林等學習模型進行超參數優化。在貝葉斯優化算法執行過程中,本文選取準確率和精準率兩個指標進行優化,得到兩組優化參數組合,可分別得到KNN、支持向量機和隨機森林的兩種增強模型。
為了驗證本文方法的分類性能,分別在實驗1數據和實驗2 數據上進行了分析驗證。首先,提取惡意代碼的GIST 特征、PE 文件結構、OPCODE 序列等特征;其次,利用PCA、RF 等方法進行特征融合,將訓練數據輸入KNN、支持向量機、隨機森林等模型進行訓練,訓練中結合貝葉斯優化方法進行模型增強;最后將測試數據分別輸入增強模型進行結果預測,并采用投票策略聚合預測結果。
本文還選取了未經參數優化的KNN、隨機森林、SVM 等模型,以及機器學習中常見的多層感知機(Multilayer Perceptron,MLP)、AdaBoost 等 模型進行對比分析。其中,多層感知機是一種簡單的神經網絡模型,AdaBoost 算法是采用Boosting 學習策略的集成學習方法,兩種模型都經常應用于分類任務。相關實驗結果數據分別如表2、表3 所示。
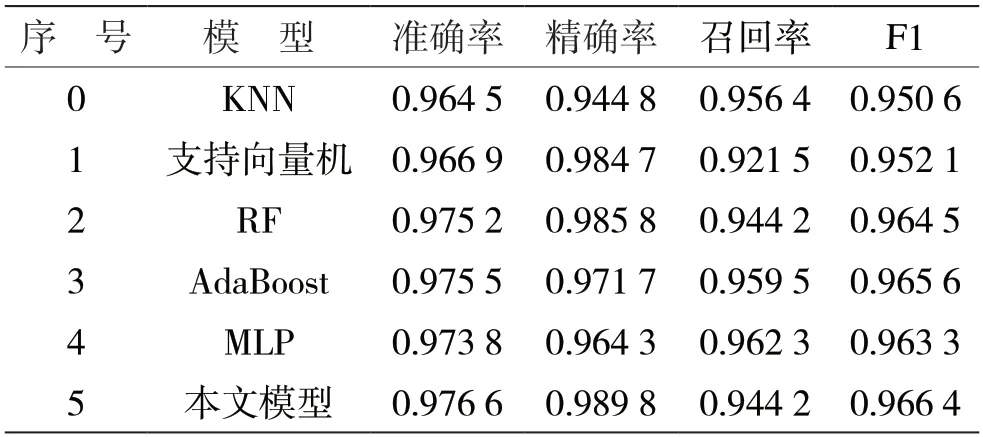
表2 多特征融合和增強模型實驗1 結果
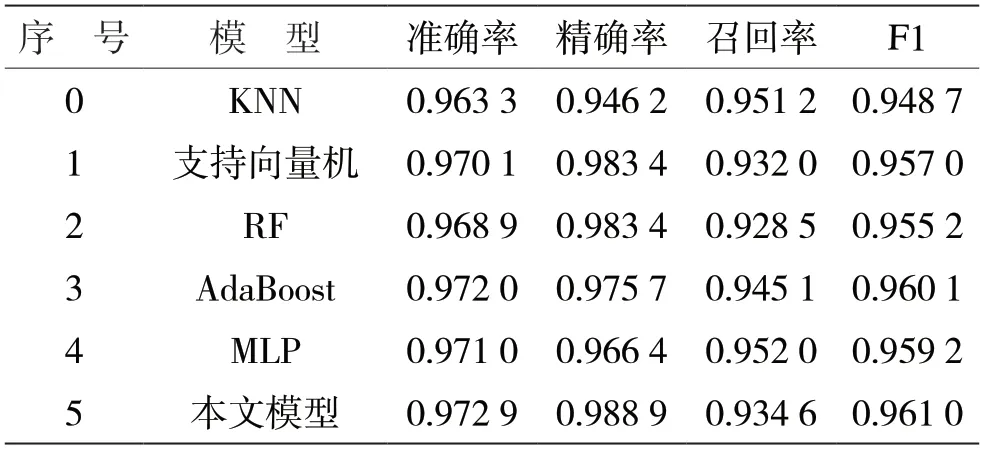
表3 多特征融合和增強模型實驗2 結果
從表2 和表3 的數據,可以看到本文設計的方法在實驗1 和實驗2 中,準確率、精準率和F1 值均為最高,驗證了多特征融合和增強模型方法的有效性。其中在實驗1 數據中,精準率達到了98.98%,準確率達到了97.66%,F1 值達到了96.64%,顯示了該方法具有良好的分類效果。
與未經參數優化的學習模型對比,可以看到本文模型在準確率、精準率、召回率和F1 值等4 個指標上,均優于支持向量機和隨機森林,在準確率、精準率和F1 值等3 個指標上高于KNN 算法。此外,本文設計的方法的檢測性能也優于常見的多層感知機、AdaBoost 等方法。
5 結語
本文提出了一種多特征融合和增強模型的惡意代碼檢測方法,該方法使用低緯度的數據特征、采用貝葉斯增強模型,經實驗測試,檢測性能及泛化能力較優。針對機器學習模型在單特征單模型上易出現過擬合問題,從圖像GIST、PE 文件結構、字節統計、操作碼序列等多個層面進行特征提取,采用PCA、RF 等方法進行特征優化,使用貝葉斯優化策略增強SVM、KNN、隨機森林等學習模型,對各增強模型的預測結果采用投票策略進行聚合,增強了本文模型的泛化能力。由于當前惡意代碼及對抗技術的加速發展,后續的工作中將在操作碼序列的規范化和優化處理上進一步改進和完善,并結合深度學習模型,如循環神經網絡、卷積神經網絡等,改進結果聚合策略,進一步提高模型的檢測性能。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
