基于改進YOLOv7的口罩佩戴檢測
2023-08-16 07:02:02付惠琛高軍偉車魯陽
液晶與顯示 2023年8期
付惠琛, 高軍偉*, 車魯陽
(1.青島大學 自動化學院, 山東 青島 266071;2.山東省工業控制技術重點實驗室, 山東 青島 266071)
1 引言
新冠疫情爆發以來,我國堅持動態清零政策,保證了極低的感染率、病亡率,而居民外出佩戴好口罩,仍是預防疫情反撲的重要方法[1]。但隨著時間的推移以及國家正確政策下社會有條不紊運行的情況,讓許多居民心存僥幸,麻痹大意,出現了不規范佩戴口罩的情況,例如口罩未覆蓋口鼻、口罩戴在下巴上甚至會有不佩戴口罩的情況出現[2]。因此,在人流密集的公共場合進行口罩佩戴檢測,對疫情防控有著重要的作用。傳統的口罩檢測只是檢測了人臉和口罩這兩個目標,只能判斷出目標人物是否佩戴口罩而無法檢測出目標人物的佩戴情況是否有誤,針對側面和遮擋等情況的識別效果也不盡如人意。
隨著社會的需要和深度學習[3]的發展,出現了不少目標檢測算法,如Fast-RCNN算法[4]、SSD算法和YOLO系列算法[5]等。文獻[6]在YOLO算法中引入了MobileNetv2網絡對口罩的佩戴情況進行分類,提高了動態檢測的速度;文獻[7]在YOLOv4算法的基礎上增加了路徑聚合網絡,并使用標簽平滑來降低損失函數,但只是簡單地分了是否佩戴口罩這兩個類別,沒有考慮佩戴錯誤的情況。YOLO系列算法的檢測速度快,精度較高,但考慮到某些具體的檢測目標有特征復雜、背景多樣等特點,必須對網絡結構進行相應的改進。文獻[8]通過引入數據增廣的方法,提高了細胞信息的利用率。隨著檢測算法精度和速度的提升,出現了不少能完成實時檢測任務的算法。文獻[9]通過模板匹配與LSTM相結合,提升了模型檢測準確率且能夠實現目標實時檢測。在實際的檢測場景中,多目標檢測逐漸成為主流。文獻[10]中基于熱力圖的Top-down和Bottom-up方法可以有效地完成多目標檢測任務。隨著網絡復雜性的提高,網絡模型的泛化能力十分重要。文獻[11]通過設計隨機擴散器的方法,提高了網絡的泛化能力。
本文將居民佩戴口罩時常見的3種情況(沒有佩戴口罩、正確佩戴口罩、錯誤佩戴口罩)設為檢測目標,對YOLOv7算法進行改進。在Head區域加入了卷積注意力機制(CBAM),從通道和空間兩方面入手,使得網絡更加關注于目標的重要特征,提高了網絡對口罩佩戴目標的學習能力。在主干網絡(Backbone)區引入了改進后的ConvNeXT,對原有的SPPCSPC進行改進,在原有池化層的結構上增加了串行連接,在不降低識別精度的同時加快了收斂速度和識別速度。
2 YOLOv7算法
YOLOv7算法在2022年由Alexey Bochkovskiy團隊提出,在檢測精度和速度兩方面均優于YOLOv5。YOLOv7的整體結構由輸入層、主干網絡(Backbone)、Head和預測端4部分組成,其模型結構如圖1所示。其中輸入層對數據的部分預處理方法延用YOLOv5,如Mosaic數據增強、自適應錨框計算和圖片自適應縮放等。
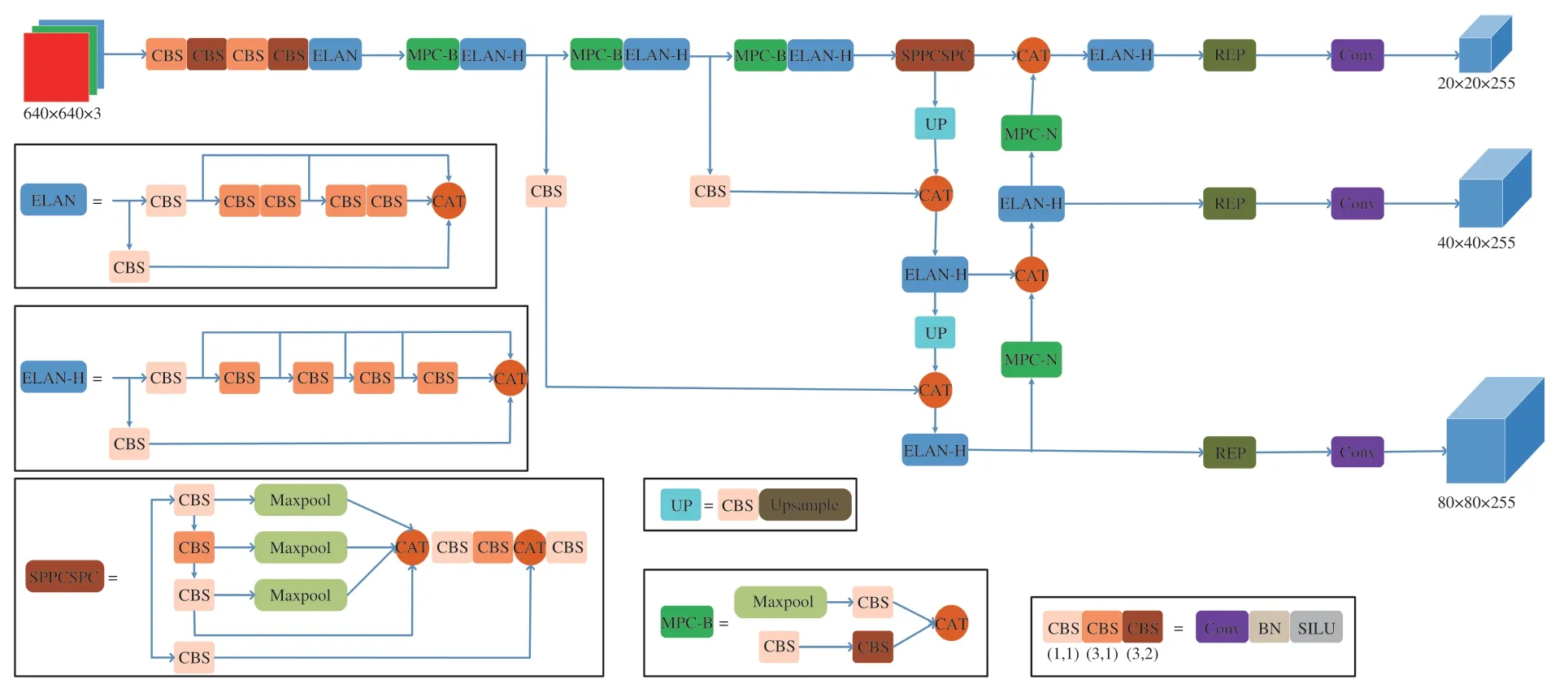
圖1 YOLOv7模型結構圖Fig.1 YOLOv7 model structure
Mosaic數據增強通過對圖片進行隨機的縮放、裁剪、排布來充實檢測目標的背景變相地對batch_size進行提高。自適應錨框計算會在網絡模型訓練的初始狀態設定好錨框,隨后輸出一個預測框,將錨框跟真實框進行對照,再多次計算誤差并進行反饋,通過不斷的計算和補償來選取適應度最好的錨框,從而產生最后的預測框[12]。圖片自適應縮放通過獲取較小的放縮系數減少圖片放縮后增添的黑邊,在推理時減少信息冗余,大幅減少計算量以及提高檢測的速度[13]。
YOLOv7對Mosaic數據增強方法進行了優化。傳統的Mosaic方法會選取4張圖片進行增強,而YOLOv7則會根據函數的隨機生成值與超參數值進行比較,當隨機值過小時會關閉Mosaic數據增強功能,當隨機值適中時會抽取4張圖片進行增強,而隨機值過大時則會選取9張圖片進行增強,從而更加靈活地增加了數據的多樣性。
主干網絡Backbone由CBS模塊、ELAN模塊和MPC-B模塊組成。其中CBS模塊包含了卷積(Conv)、批正則化層(BN)和SiLU激活函數這三部分。MPC-B模塊由1個池化層和3個CBS組成,作用是下采樣,同時通過卷積和池化層的結合可以獲取局部小區域所有值的信息,避免了池化層只獲取最大值的弊端。ELAN模塊由多個CBS組成,是一個高效聚合的網絡結構,刪除了1×1的卷積,提高了GPU計算效率,大幅降低了訪問內存的消耗,并采用了梯度分割的思想,在卷積網絡的輸出和輸入層直接添加了較短的連接,使得梯度流在不同的網絡結構中傳播,解決了輸入以及梯度信息的過度膨脹,同時能控制最短和最長的梯度路徑,使得網絡能提取更多的特征,使訓練更加高效和精確。
Head層主要由SPPCSPC模塊、ELAN-H模塊、MPC-N模塊、UPSample模塊和RepConv模塊組成。SPPCSPC是一種空間金字塔池化改進模塊[14],內部由多個CBS模塊和池化層組成,通過最大池化來得到不同的感受野,在使得算法能適應不同分辨率的圖片的同時,能防止圖像在剪裁和放縮過程中出發生失真,還能避免卷積對圖像的特征重復提取,降低計算量,加速預選框的生成。ELAN-H模塊與ELAN模塊在功能和結構上高度類似,區別于ELAN模塊在第二條分支將3個輸出進行相加,ELAN-H則將5個CBS的結果取和。MPC-N模塊則是在MPC-B模塊的基礎上增加了與前向輸出層的鏈接。UPSample模塊的作用是上采樣,采用最近鄰插值的方法[15]能減少網絡的計算量。RepConv模塊是一個結構重參數化模塊,能將訓練中結構的改變轉變為推理過程時參數的變化,將結構的等價替換轉變為參數的等價替換,從而達到提高性能、節省空間的目的。
最后的預測端包括了損失函數計算以及邊界框預測。總體損失函數由定位損失、目標置信度損失和分類損失3部分組成,其中目標置信度和分類損失采用了BCEWithLogitsLoss算法,坐標損失采用CIoU算法。
3 改進的YOLOv7
3.1 卷積注意力機制(CBAM)
除了網絡結構的深度、寬度以及網絡的基數這3個重要因素外,注意力機制也能提高卷積網絡的性能[16]。注意力機制的添加能幫助卷積神經網絡更重視目標重要的特征以及忽略不必要的特征。卷積注意力機制(CBAM)結構如圖2所示。

圖2 卷積注意力結構圖Fig.2 Convolutional attention structure diagram
卷積運算基于通道和空間兩種信息來綜合提取信息特征。卷積注意力機制(CBAM)從這兩個方面入手,融合了通道注意模塊(CAM)和空間注意模塊(SAM)來提高卷積神經網絡的學習能力。
通道注意力Mc來關注特征的通道信息,從而確定圖像中由主要特征的目標及通道。通道注意力Mc的計算如公式(1)所示:
式中:σ為sigmoid函數,W0∈RC/r×C,W1∈RC×C/r,當σ在W0前時為ReLU激活函數。空間注意模塊(SAM)也使用了平均池化(AP)和最大池化(MP)的方法,采用了特征空間的關系來產生空間注意力Ms從而確定空間內包含主要特征信息的位置。Ms的計算如公式(2)所示。式中σ為sigmoid函數,f7×7是大小為7的卷積核。
3.2 網絡改進ConvNeXt
近幾年來,Transformer[17]網絡以其模態融合能力和全局特性被大量研究和應用,但是因其計算效率低下,局部信息獲取的能力較弱且頂層梯度會被歸一化部分阻斷等問題,使Transformer的應用不如卷積神經網絡廣泛。ConvNeXt在ResNet50卷積網絡的基礎上引入了Transformer的優點,在保留卷積網絡結構簡潔的同時提高了性能[18]。ResNet50網絡使用的卷積核尺寸為3,而ConvNeXt借鑒了Transformer將卷積核尺寸上調為7,同時將ResNet50中常用的ReLU激活函數替換為Transformer網絡中常用的GeLU激活函數,并從Transformer網絡中獲得啟發,減少了激活函數和正則化函數的使用,從而減少了計算量。本文通過自身數據的特點對ConvNeXt進行改進,將正則化函數中的層正則化(Layer Normalization)替換成批正則化(Batch Normalization)。進一步提高了模型的魯棒性。改進后的ConvNeXt的結構如圖3所示。

圖3 ConvNeXt改進結構圖Fig.3 Improved ConvNeXt structure diagram
3.3 空間金字塔池化改進
空間金字塔池化的功能主要是使圖像可以以任意大小和像素寬高比輸入,其輸入端可以接納任意大小的圖片[19]。本文對原有的SPPCSPC結構進行改進,將原有的3個并行的池化層添加上串行結構,在不改變原有結構感受野的情況下,提升檢測速度同時能幫助網絡收斂和抑制過擬合。改進前后的結構如圖4所示。具體實現過程為:
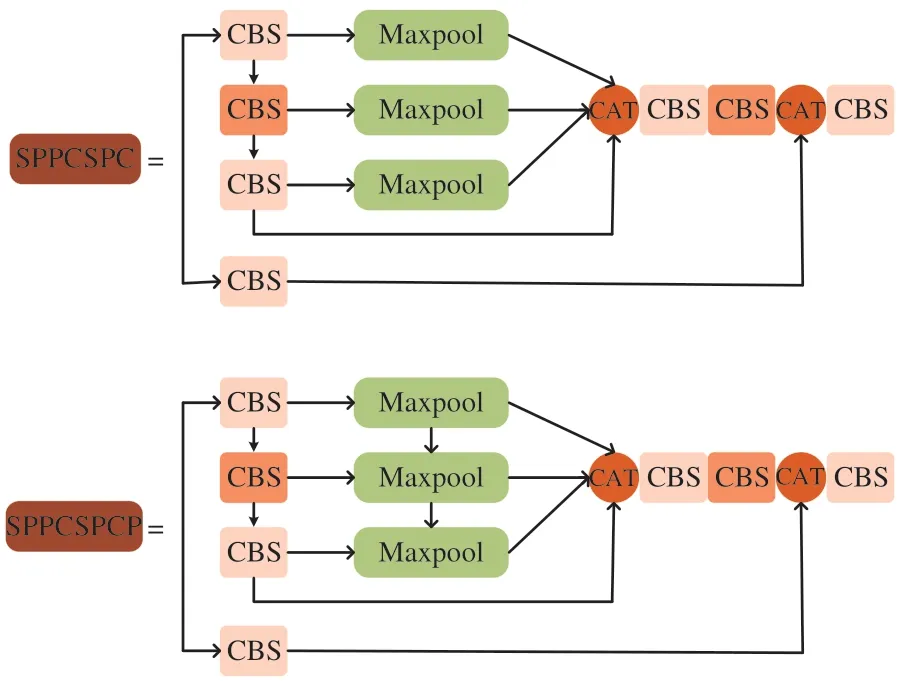
圖4 空間金字塔池化結構改進圖Fig.4 Diagram of improved space pyramid pool structure
(1)對Backbone主干網絡中ELAN-H模塊的特征輸出進行CBS卷積操作,即分別經過卷積操作、批正則化和SiLU激活函數處理。
(2)對第一步中進行過一次CBS卷積操作的特征再進行兩次CBS卷積操作,并在每個卷積操作后進行一次最大池化處理,隨后將3次最大池化后的特征進行串并行連接,并進行特征層融合。
(3)將第二步中的結果經過兩次CBS卷積處理后與第一步中的結果融合,再最后進行一次CBS處理,即可得到最終輸出特征層。
4 實驗與結果分析
4.1 實驗環境
本文的算法在Pycharm集成軟件中實現,采用的編程語言為Python3.9,使用Pytorch 1.12.1作為深度學習框架,并使用了CUDA11.3硬件加速工具。實驗平臺使用了NVIDIA RTX3080 GPU,Intel(R)Core(TM)i7-12700KF @ 3.60 GHz處理器,操作系統為Win10,設備內存為32.0 GB。
4.2 數據集的準備
由于目前網絡上公開的口罩佩戴情況數據集較少,而且很少有不正確佩戴口罩的數據集,因此本文通過在互聯網查找和組織同學拍攝共計9 000余張圖片,采用LabelImg軟件自行標注制作了口罩佩戴數據集。數據集包括了各種不同的場景,其中有不佩戴口罩、正確佩戴口罩和錯誤佩戴口罩3種情況,包含了正臉、左側臉、右側臉3種角度及不同的背景、光線和遮擋等情形,如圖5所示。

圖5 數據集圖片示例Fig.5 Example of dataset images
數據分類包括沒有佩戴口罩、正確佩戴口罩和不正確佩戴口罩3種,并將訓練集、測試集以及驗證集按照8∶1∶1的比例進行分割,訓練批次為16,學習率0.005,模型迭代150次。
表1展示了數據集中各類情況的數量。
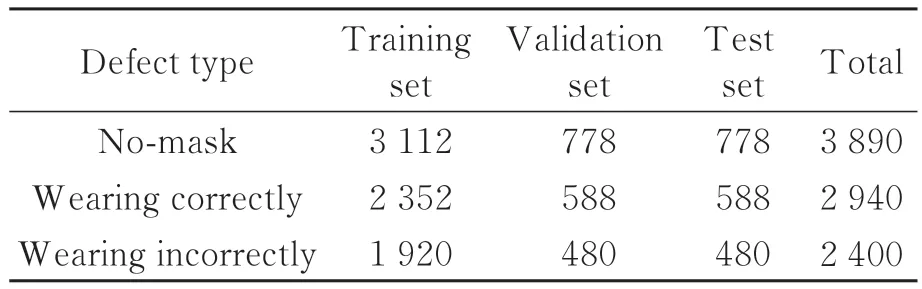
表1 數據集中的目標分類及數量Tab.1 Classification and number of targets in the data set
4.3 模型評估指標
本文采用精度(P)、召回率(R)、均值平均精度(mAP)作為評價指標檢驗模型的效果。精度和召回率的表達式為:
以本文檢測中沒有佩戴口罩類別No-mask為例,TP為訓練完成的模型將沒有佩戴口罩的圖片目標檢測為No-mask類別的數量,FP為模型將正確佩戴口罩以及錯誤佩戴口罩的圖片目標檢測為No-mask類別的數量,FN為模型將沒有佩戴口罩的圖片目標檢測為正確佩戴口罩(Wearing correctly)和不正確佩戴口罩(Wearing incorrectly)類別的數量。精度(P)描述了模型對該類別分類的精確情況,召回率(R)描述了模型對該分類的漏檢情況,平均精度(AP)是P-R曲線與橫縱坐標正半軸所圍成的面積,從精度(P)和召回率(R)兩個方面評估模型在該類別上的檢測效果。均值平均精度(mAP)是模型中所有分類的平均精度(AP)的均值,能有效評估該模型對所有分類的檢測情況。平均精度(AP)和均值平均精度(mAP)的計算公式如式(5)和式(6)所示:
4.4 實驗設計
為了驗證改進后的算法對口罩佩戴檢測的效果,本文采用了兩組對照實驗,第一組將改進后的算法模型與和原始的YOLOv7算法以及不同改進部分的算法模型進行對照,第二組將改進后的算法與Faster-RCNN算法進行比較。
4.4.1 損失函數收斂對比
改進前后的YOLOv7 在訓練過程中驗證集的損失函數變化如圖6所示,圖中曲線A為原始YOLOv7損失函數,曲線B為改進后的損失函數。損失函數曲線在初始階段下降較快且波動很大。隨著訓練輪數的增加,在訓練50個Epoch之后,波動起伏開始變小,損失函數逐漸降低,曲線趨于平穩。在訓練約100個Epoch時,損失函數逐漸穩定,模型逐漸收斂。由圖6可見改進后的算法損失函數更低且收斂更快。

圖6 損失函數對比Fig.6 Example of dataset images
4.4.2 改進方法對模型性能的影響
本文通過對不同改進方法的檢測指標進行對照實驗,分析不同改進部分對網絡性能提升情況,表2為不同改進方法對模型性能的改進結果。由表2中數據對比可見,YOLOv7-A在Head層引入卷積注意力(CABM)使得原始模型的精度提升3.2%,mAP值提升0.7%。YOLOv7-B在YOLOv7-A的基礎上在Backbone層中引入了改進的ConNeXt網絡結構,使得原始模型的精度提升2.7%,mAP值提升1.7%。YOLOv7-C在YOLOv7-B的基礎上在Head層中對SPPCSPC進行優化,使得原始模型的損失函數顯著下降,精度提升2.2%,mAP值提升3.6%。

表2 不同改進方法的性能指標Tab.2 Performance index of different improvement methods
4.4.3 改進前后與主流檢測模型的性能對比
模型訓練完成后,采用多次檢測抽樣的統計方法,將驗證集中的數據進行測試,并與改進前的YOLOv7以及Fast-RCNN進行對比,驗證集中包含了單人、多人及側面等不同情況,部分對比結果如圖7所示。由圖7(a)、圖7(b)和圖7(c)對比可以看出,從側面角度檢測時,改進后的算法置信度比Fast-RCNN和原始YOLOv7算法均有提升;由圖7(d)、圖7(e)和圖7(f)對比可以看出,目標錯誤佩戴口罩時,改進后的算法置信度比Fast-RCNN和原始YOLOv7算法均有提升;由正面和側面對比可以得出,側面的識別置信度要低于正面的識別置信度;由圖7(g)、圖7(h)和圖7(i)對比可以看出,在3種類別中,改進后的算法的置信度比其他兩種算法高,同時圖7(g)中Fast-RCNN算法發生錯檢情況且3種類別的置信度均較低,圖7(h)中改進前的算法將錯誤佩戴口罩的情況誤檢為正確佩戴口罩,而圖7(f)中改進后算法則進行了正確的分類。從3種算法的檢測情況對比可以得出,改進后的YOLOv7算法檢測結果最好,尤其在側面和多人的檢測情況下,效果提升更多。

圖7 Fast-RCNN、YOLOv7與改進YOLOv7的檢測結果對比。Fig.7 Comparison of Fast-RCNN, YOLOv7 and improved YOLOv7 detection results.
將本文算法與其他的檢測算法的檢測指標進行對比,結果如表3所示。改進后的YOLOv7的mAP值比其他算法有所提升,比Fast-RCNN高21.4%,比YOLOv7_A、YOLOv7_B以及原始YOLOv7分別高1.9%、2.9%、3.6%。相較于原始YOLOv7,各個類別的檢測精度均有提升,沒佩戴口罩類別的AP值提升6.8%,正確佩戴口罩類別的AP值提升2.1%,不正確佩戴口罩類別的AP值提升1.7%。通過數據對比可以得出結論,改進后的YOLOv7的檢測指標要優于其他算法。

表3 不同檢測算法的性能指標對比Tab.3 Comparison of performance indicators of different detection algorithms
5 結論
針對目前部分居民口罩佩戴不正確等問題,本文提出了一種改進YOLOv7的口罩佩戴檢測算法。通過自行拍攝和網上搜集,豐富了口罩佩戴錯誤類別以及側面遮擋等情況的數據集。通過在Head層引入卷積注意力機制,加強了網絡結構在空間和通道上對有效特征的重視,提高了網絡對口罩佩戴目標的學習能力。在Backbone層引入ConvNeXt網絡結構,提高了網絡結構的性能和魯棒性。對Head層SPPCSPC模塊進行優化,有效減少了損失函數,將平均精度從90.2%提高到93.8%。同時各個類別的檢測精度均有提升,沒佩戴口罩、正確佩戴口罩、不正確佩戴口罩類別的精度提升分別提升6.8%、2.1%、1.7%;并且減少了漏檢和錯檢的情況,提高了系統的魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
