基于深度時間卷積神經網絡與遷移學習的流程制造工藝過程質量時序關聯預測
2023-08-08 02:24:32陰艷超施成娟鄒朝普劉孝保
中國機械工程 2023年14期
陰艷超 施成娟 鄒朝普 劉孝保
1.昆明理工大學機電工程學院,昆明,6505002.昆船智能技術股份有限公司,昆明,650051
0 引言
流程制造具有生產連續性強、工序間參數耦合復雜、原料成分波動頻繁等特點。保障流程產品質量穩定的關鍵是如何在最短時間內感知工藝過程和產品質量的各種變化,并通過調整運行參數和工藝參數來保證生產全流程的整體高效運行,因此,研究精準、快速和高效的生產質量預測方法是提高流程產品質量和資源利用率的核心。
近年來,國內外學者對流程產品質量的預測方法進行了有益的探索。針對車間生產數據的關聯挖掘,梁強等[1]利用灰度關聯分析和熵值法,將多目標問題轉化為關于灰色關聯度的單目標問題;胡嘉蕊等[2]應用核主成分分析提取核主成分,實現了多輸出模型的降維。支持向量機回歸(support vector regression,SVR)模型[3-5]、反向傳播人工神經網絡(back propagation artificial neural networks,BPANN)[6-7]、深度神經網絡(deep neural networks,DNN)[8]都是以數據驅動為基礎來探索高維非線性映射關系的經典模型,在諸多場景中得到了廣泛應用,但這些方法容易受到專家經驗及獨立處理時間點的限制,提取的參數特征存在偏失。
隨著硬件算力的提高,深度學習在時間序列預測領域中的應用備受關注,國內外的研究主要集中在深度學習模型,如循環神經網絡及其變體結構[9-11]通過引入循環反饋結構來處理輸入序列間前后關聯的問題,即提取出前后時刻不斷更替的時序信息,但該方法無法解決長距離信息依賴問題。為解決上述問題,很多學者展開了混合神經網絡的研究,通過聚集不同神經網絡的優勢來彌補單一神經網絡的不足。何彥等[12]結合堆疊自動編碼器和雙向長短期記憶網絡的優點,從高維數據中提取低維特征并完成時序預測。ZHANG等[13]將卷積神經網絡和長短期記憶神經網絡相結合,旨在有效地將特征提取、融合和回歸相結合,最終實現預測。QI等[14]通過搭建卷積神經網絡來實現數據的自適應特征提取,并將提取出的特征作為支持向量回歸模型的輸入,避免了人工特征提取和特征選擇的局限性。
上述基于深度學習的方法在生產質量預測上取得了諸多成果。實際應用中,生產過程是由不同產線構成的,而不同產線獲取的數據量各不相同,存在小樣本數據集的可能,且不同產線都需要對模型進行重新訓練。這在模型訓練過程中會導致以下問題:樣本數據集過小時不足以獲得完整的工藝特征信息;樣本數據集過大時訓練時間較長,難以及時進行生產質量的在線預測。
遷移學習具有計算成本低、學習樣本小[15-16]等優點,因此本文基于遷移學習的思想,提出一種新的車間工藝質量在線預測模型。首先構建出一種能有效利用工藝參數和歷史質量指標時序信息的質量預測模型。利用遷移學習解決其他產線數據不足、難以精準建模,以及模型運行時間長、難以支持在線預測等問題。
1 問題分析
流程生產主要通過傳感器、智能終端、控制系統獲取設備運行參數、工藝參數、質量指標等包含不同維度特征信息的生產數據。制絲工藝生產中的松散回潮工序對應的生產數據包括主蒸汽壓力、工作蒸汽壓力、工藝用水壓力、壓縮空氣壓力、篩板加熱蒸汽壓力、回風風門開度、排潮風門開度和滾筒轉速等工藝參數,以及出料含水率、出料溫度兩個質量指標。實際應用中,設備運行參數與工藝參數的關聯關系和時序依賴關系特征難以獲取,致使敏感工藝和運行參數無法及時調控,進而無法保障生產質量的穩定。
傳統的工藝質量預測模型無法提取工藝數據的時序特性,因而本文借助序列到序列(sequence to sequence, Seq2Seq)的布局,提出基于時間卷積神經網絡的學習框架來預測工藝質量。在Seq2Seq模型中引入卷積結構表示和捕捉工藝數據的關聯模式,構建工藝時間序列的依賴關系,以解決Seq2Seq模型的深度特征提取不全和前序特征覆蓋的問題。
設流程車間任一工序中的質量指標序列Y=(y1,y2,…,yT)∈RT,工藝參數的運行時序數據可展開表達為
(1)
式中,xt為N個工藝參數在時刻t(t=1,2,…,T)下的數據,xt=(xt,1,xt,2, …,xt,N);xm為第m(m=1,2,…,N)個工藝參數T個歷史時刻的時間序列,xm=(x1,m,x2,m,…,xT,m)T。
本文模型是基于序列到序列的學習框架,通過綜合運用車間工藝參數特征信息和歷史工藝質量時序信息來預測工藝質量,具體操作如下:首先,通過編碼器中的時間卷積神經網絡(temporal convolution neural network,TCN)和時序注意力機制聯合提取工藝參數中的關聯時序信息;隨后,整合解碼器中的殘差長短期記憶(long short term memory, LSTM)網絡來學習表達歷史工藝質量中的時序信息,最終實現復雜工況下產品質量的精準預測。將本文模型簡記為DTCN_A模型,且將模型的整體函數記為FDTCN_A,則工藝質量預測值
(2)
實際的流程生產中,不同工序設備運行的變化會導致生成的實時數據集與參與模型訓練的樣本集有所差別,因此利用離線數據訓練得到的工藝質量預測模型難以精準預測各種未知工況下的質量指標,且預測模型在很多情況下無法重新學習。針對上述問題,利用不同設備、操作條件或產線下加工工序的相似性,引入遷移學習,提出一種適用于深度TCN的有效遷移學習方式,即將源域中的有用知識遷移到目標域,利用遷移學習來自適應跟蹤設備運行參數和工藝參數的變化,實現不同產線下的模型自適應訓練及車間工藝質量的在線預測。
2 深度TCN時序注意力網絡的建模
2.1 深度TCN時序注意力網絡的模型結構
借助Seq2seq學習結構的深度TCN時序注意力網絡模型是一種端到端的深度神經網絡模型,適合學習和表達時間序列的潛在深度特征,并最終實現預測。如圖1所示,本文提出的深度學習架構模型包括3個部分:基于擴張因果卷積網絡的編碼器、時序注意力機制和基于殘差LSTM網絡的解碼器。整體模型的輸入包括工藝參數和歷史質量指標。在模型DTCN_A的編碼器中,深度TCN通過構建擴張因果卷積來捕獲工藝參數中的長時期依賴關系;時序注意力機制用于加強關鍵生產時刻的信息表達,削弱冗余時刻信息;解碼器利用殘差LSTM網絡來挖掘工藝質量的時序信息,最后綜合模型提取工藝參數的關聯時序信息和工藝質量的時序信息來預測當前時刻的質量指標。
2.2 基于擴張因果卷積網絡的編碼器
車間工藝質量預測等時序問題需要利用歷史時段的工藝數據進行建模預測,而不能僅依賴于當前時刻的工藝參數或歷史時段的工藝質量,需要綜合考慮工藝參數與工藝質量之間的關聯時序特征和工藝質量內部蘊含的時序信息。傳統的全連接神經網絡中,同一層的不同單元之間沒有連接,故無法包含工藝參數內部蘊含的時序信息。LSTM網絡、門控循環單元(gated recurrent unit, GRU)網絡等循環神經網絡利用內部存儲單元固化“記憶”,并以序列演進方式遞歸更新,學習數據序列特征。卷積神經網絡(convolutional neural networks, CNN)通過卷積計算形成“記憶”,但這些深度學習方法均存在長距離記憶問題。
針對該問題,本文利用TCN挖掘工藝因果卷積特性的同時,有效分析車間工藝多源信息。采用擴張因果卷積提高長時間跨度記憶單元的處理效率,以高效提取工藝參數的特征信息。網絡只對歷史數據進行順序讀取,摒棄了對未來數據的信息解讀,可有效解決信息泄漏的問題。由圖1中的編碼器模塊可知,通過增加卷積核和擴張系數來堆疊多個擴張卷積,可使網絡獲得更大的感受野,即使用較少的層級來捕獲序列中的長時間依賴關系,并保證訓練時長。
編碼器模塊中,輸入數據為工藝參數X,即由N個相關工藝參數、總時間跨度為S的時間序列數據構成的S×N的矩陣。輸入數據經過網絡層中的卷積(卷積核大小為k,擴張系數為d)濾波后,輸出P為N個特征圖(圖2),其中,特征圖P(s)是由序列元素與卷積濾波f:{0,1,…,k-1}擴張卷積運算得到的,具體計算公式為
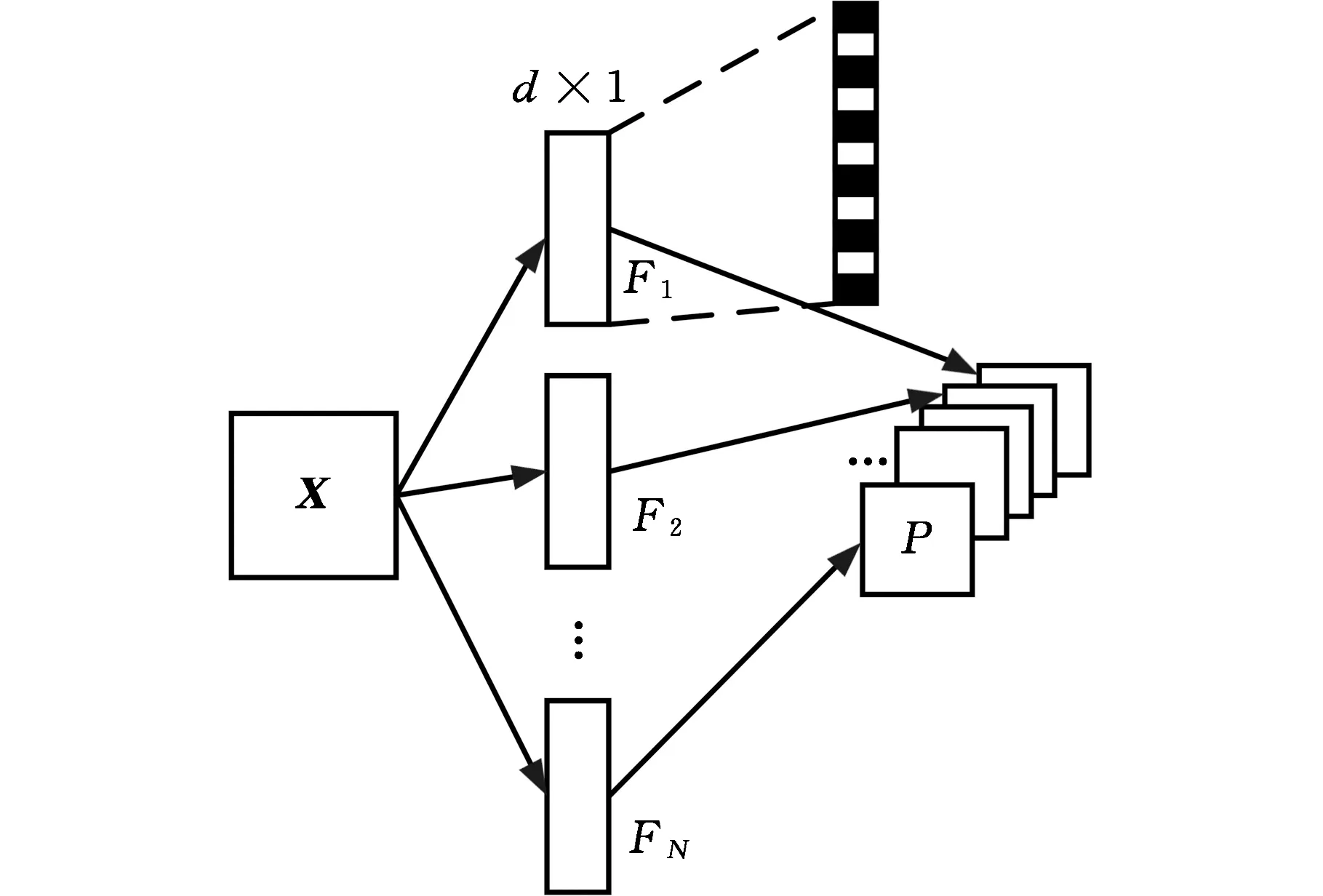
圖2 一層多維擴張卷積流程簡化圖
(3)
式中,*表示卷積運算;f(i)表示第i個濾波器;xs-di為與卷積核相乘的對應的序列元素;s表示擴張卷積中的第s個神經元。
經過多層卷積、壓縮操作后,工藝信息存在丟失或失真的可能,故引入殘差鏈接方式,使網絡能夠跨層傳輸原始數據中的關聯信息,最大限度地關聯融合高階特征與原始低階特征,完善工藝特征信息。
每個殘差塊包括直接映射部分和殘差部分,其表達式為
(4)
式中,zn為第n層卷積層蘊含的依賴信息;C(·)表示擴張卷積操作,即直接映射部分;R(·)表示跨層進行殘差映射操作。
本文模型中的編碼器模塊由多層卷積核并行構成,以提取深層次特征信息。模塊通過組合多個通用殘差塊對工藝數據進行多維度的特征提取。以殘差塊為組件,每個組件中,擴張因果卷積、權值規范化、激活函數依次排列。
為聚焦時間步長中的關鍵時刻,引入時序注意力機制對序列各歷史時刻攜帶的時序信息分配注意力權重,從而提高提取關鍵時刻信息的能力。時序注意力機制的輸入為TCN輸出的關聯特征信息{h1,h2,…,hT},計算出前t個時刻獲取的時序注意力權重lj,t,并使用softmax函數對其進行歸一化,得到時間注意力權重
(5)
將t時刻的時間注意力權重βt與TCN輸出的隱藏狀態ht點乘,得到綜合時序信息狀態
(6)
式中,lt為線性變化后的時序注意力權重向量,lt=L(Wht+b);L(·)表示激活函數,用以增強特征差異;W、b分別為可訓練權重矩陣和計算時序注意力權重的偏置向量;T為時間窗口大小。
2.3 基于殘差LSTM網絡的解碼器
為有效整合提取的工藝參數和歷史質量指標的特征信息,解碼器采用殘差LSTM神經網絡Resnet-LSTM,并添加全連接層以適應最終質量指標的輸出要求。解碼器首先利用LSTM網絡挖掘出工藝質量Yt的時序特征信息,再通過殘差網絡對提取出的信息進行更深層次的學習,最后協同由編碼器提取的工藝參數潛在深度特征輸出Ht,得到當前時刻的預測輸出:
(7)
其中,r(·)表示Resnet-LSTM網絡函數,用于提取工藝質量時序信息。
Resnet-LSTM結構見圖1中的解碼器部分,增加的神經網絡層級易引發梯度消失和梯度彌散。利用殘差鏈接能有效消除這兩個問題,并減少模型參數,提高訓練效率,提取更深層次的復雜信息。因此在殘差網絡結構的基礎上,利用LSTM提取歷史質量指標序列中的時序信息,再用批量歸一化來投影由上層網絡得到的時序信息,并使用ReLU激活函數進行非線性處理。最后,添加Dense層以保證輸出相同維度的張量,得到歷史工藝參數的潛在深層關聯時序信息。
如圖3所示,LSTM結構采用門控輸出的方式控制信息的取舍,即輸入門it、遺忘門ft、輸出門ot和兩種時間狀態(ct和隱層的輸出ht),下標t表示t時刻。
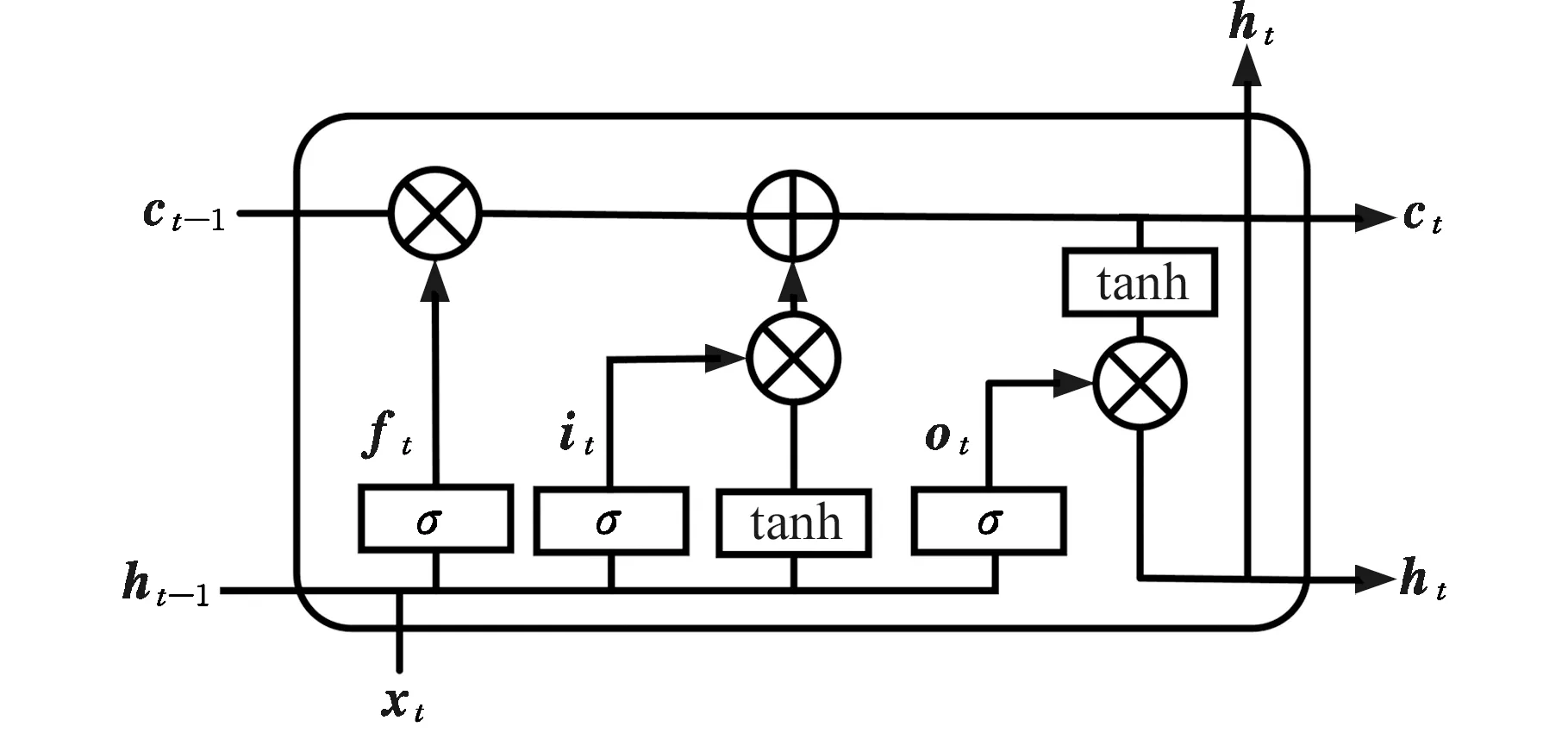
圖3 LSTM結構圖
t時刻網絡的輸出結果為
(8)
式中,σ(·)表示Sigmoid激活函數;bα為偏差,α∈{i,f,c,o,h};⊙表示矩陣的哈達瑪積。
假設給定輸入數據x=(x1,x2,…,xs),其中,s為時間步長,最后得到的輸出為
(9)
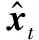
3 遷移學習
3.1 面向多產線的遷移學習
不同產線的物料、設備狀態和環境參數等不盡相同,因此不同產線需要不同的模型或模型參數。實際運行中,生產方式或設備參數調整導致該場景的樣本與原始訓練樣本存在較大差異時,預訓練出的模型參數不適用于當前的生產條件,通過預訓練模型得到的特征難以準確預測出質量指標。因此本文引入遷移學習,首先在源域數據中構建出工藝質量預測模型(用來學習工藝數據蘊含的特征知識),然后在目標域的學習任務中,利用遷移學習共享預測模型的網絡結構和參數,并根據具體的任務需求調整剩余的網絡參數,使得目標域的數據集不僅能繼承源域中的學習表達能力,還能實現自身網絡模型的再訓練,自適應地調整網絡參數,滿足預測任務需求。
3.2 遷移學習策略
不同產線的相同工序具有相似性,因此利用深度神經網絡模型挖掘工藝數據的深層次特征,并對挖掘出的特征進行遷移學習,提出適合不同產線的工藝質量預測方法。將本文構建出的深度神經網絡模型作為預訓練模型,模型的編碼網絡部分挖掘工藝參數間的關聯時序關系,解碼網絡部分解析質量指標的歷史時序關系,因此需要分析預訓練模型的不同網絡部分對目標域數據的特征挖掘能力,通過凍結全部特征提取網絡和預訓練模型參數初始化來實現模型參數的共享,其中,全部特征提取網絡包括綜合編碼器網絡和解碼器網絡。因此遷移學習可定義為:微調模型網絡、凍結編碼層、凍結全部特征提取層。為驗證遷移學習是對模型的有效改進,需對目標域中其他產線的工藝過程進行重新建模學習。構建的模型網絡結構與預訓練模型網絡結構相同,但在目標域數據中進行模型訓練即重新訓練。4種遷移學習方式的具體說明如下。
重新訓練(Mode1):預訓練模型的網絡結構不變,隨機初始化所有層的網絡參數,在目標域中重新劃分數據集,利用新的測試集訓練模型。
微調模型網絡(Mode2):將預訓練模型的網絡結構和參數全部遷移至新模型,即將預訓練模型的參數作為新模型參數的初始值。
凍結編碼層(Mode3):共享預訓練模型的網絡結構和編碼器的參數,隨機初始化剩余網絡參數。
凍結全部特征提取層(Mode4):預訓練模型的網絡結構、編碼器及解碼器的網絡參數不變,隨機初始化全連接層參數。
為區別Mode3和Mode4的模型結構,繪制出兩種遷移模型結構,如圖4所示。

(a)Mode3的遷移學習結構 (b)Mode4的遷移學習結構
3.3 工藝過程質量自適應預測流程
利用DTCN_A模型訓練某產線的離線數據,學習歷史數據得到較為完整的工藝深層特征,同時保存預訓練模型的網絡結構和網絡參數。不同的產線需要訓練出不同的質量預測模型,為縮短運行時間并保證質量預測的準確率,利用遷移學習將預訓練模型中的結構和參數運用至不同產線的工藝質量預測模型。通過對比以上4種遷移策略,選擇出最佳模型遷移方法,并構造出適應不同產線的最佳預測模型,工藝過程質量自適應預測流程如圖5所示。
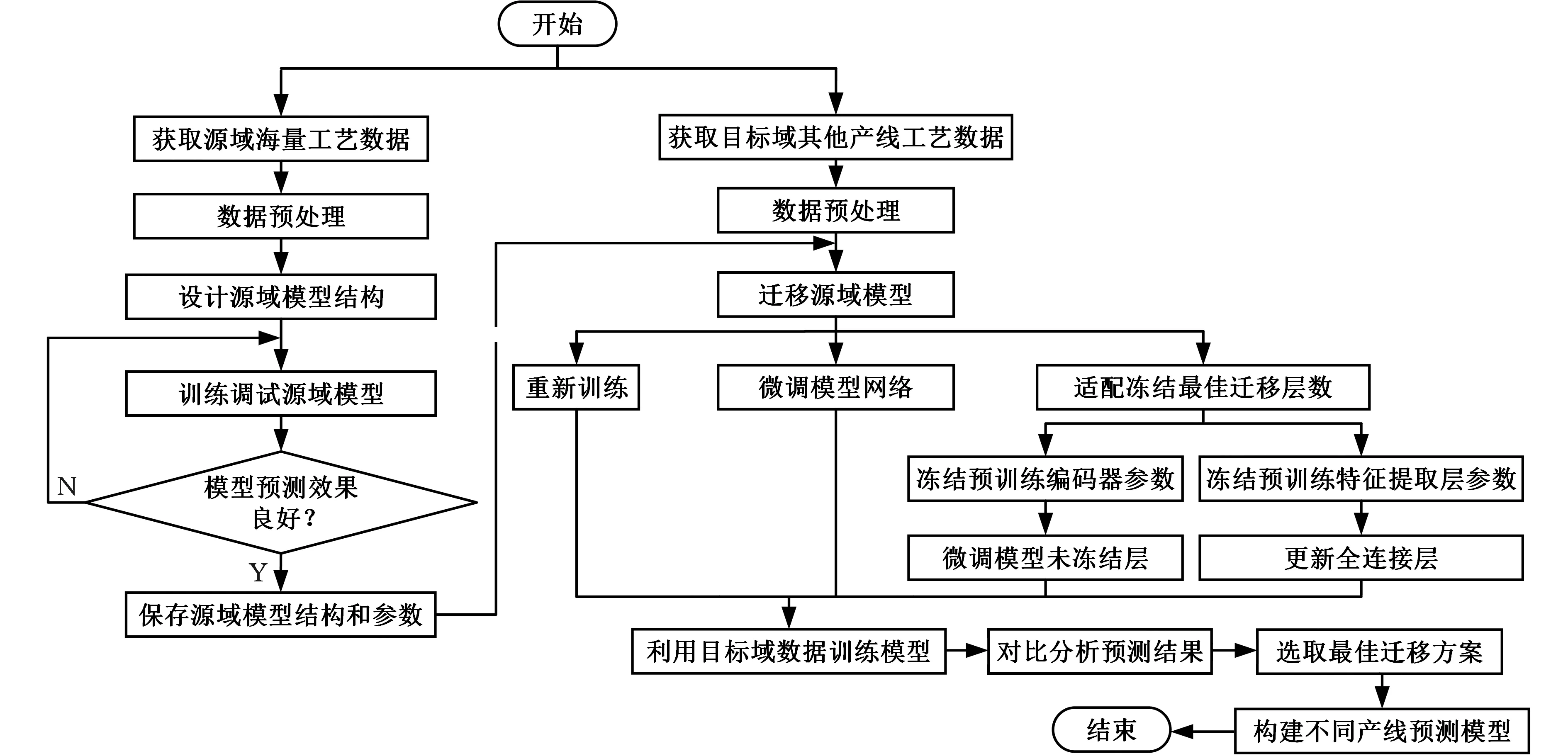
圖5 工藝過程質量自適應預測流程
4 算例與結果分析
4.1 流程實驗數據的獲取與預處理
為驗證模型的有效性,本文以某制絲生產線為例進行實驗驗證。該制絲過程根據不同葉組配方進行模塊分組加工,其中,模塊1包含A線、B線、C線(薄板干燥)和D線。部分產線生產工藝順序如圖6所示,煙葉處理過程中,松散回潮工序的質量指標對制絲的最終成品質量具有重大影響,因此每條產線需重點關注松散回潮工序。
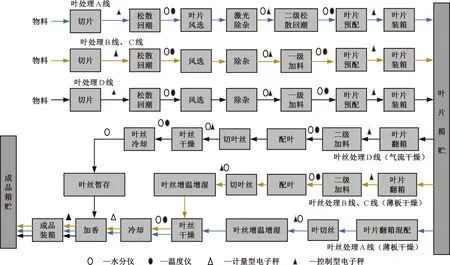
圖6 制絲工藝圖
制絲過程中,每6 s采集一次樣本數據并將其存入MES數據庫。從MES數據庫提取不同產線2021年3月—9月的穩態生產數據并進行分析。本文通過分析松散回潮工序來驗證模型的預測性能,為盡可能獲取工序的深度隱藏特征,選取樣本數據量最大的產線即模型1中的C線。C線采集的39 000條數據包括靜態參數、工藝參數和質量指標,其中,靜態參數是指設備或來料的固有屬性,無法對其進行調節;工藝參數是影響生產質量的關鍵要素,一般分為有價值調節參數和無價值調節參數。無價值調節參數大多是設備運行的設定值,在實際生產中不調整,因此本文只分析有價值工藝參數與質量指標的關聯信息,預測模型的輸入與輸出如表1所示。

表1 松散回潮設備性能參數表
料頭、料尾、停機斷料處易出現異常值,且不同生產批次之間的數據存在差異,因此將數據劃分成時序矩陣時,要保證輸入模型的時序矩陣數據是同一批次數據。各個參數的數量級不同,因此需要對采集的原始數據進行預處理(異常值處理、批次劃分和數據歸一化)。采用3σ準則檢測并刪除工藝數據中的異常值,同時使用min-max線性函數對工藝參數和質量指標進行歸一化:
(10)
式中,Xnew為歸一化后的工藝數據;Xi為原工藝數據,i=1,2,…,N;N為原工藝數據的樣本量;Xmin、Xmax分別為單一工藝數據中的最小值和最大值。
在不改變原數據分布的情況下,將工藝數據全部映射到[0,1]范圍內。
4.2 深度TCN時序注意力網絡模型的預測性能
網絡訓練及優化均以Dell DESKTOP-VI4SR6N 服務器為硬件平臺,處理器為Intel Core i7-8650U,內存為64GB,顯卡為UHD Graphics。采用 Python語言,在Keras深度學習框架下以Tensorflow為后端構建DTCN_A神經網絡模型,并通過損失函數和Adam優化器來訓練模型。建模中,訓練集和測試集的比例為7∶3。對不同的網絡模型進行50次訓練,使用各性能指標均值評估分析模型性能。
采用有監督的學習方式進行模型訓練。訓練過程中,誤差損失衰減并趨于平穩時模型停止訓練。誤差損失Floss的計算公式為
(11)
將平均絕對誤差E1和均方根誤差E2作為評估模型預測性能的指標。利用參考擬合優度R2判斷模型的擬合效果,它們的公式分別為
(12)
(13)
(14)
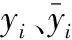
基于深度TCN的預測模型參數設置如下:時間步長s=10,迭代次數為200,學習率為0.002,擴張因果卷積的卷積核大小為2;解碼器LSTM網絡中的隱藏元個數q=10。
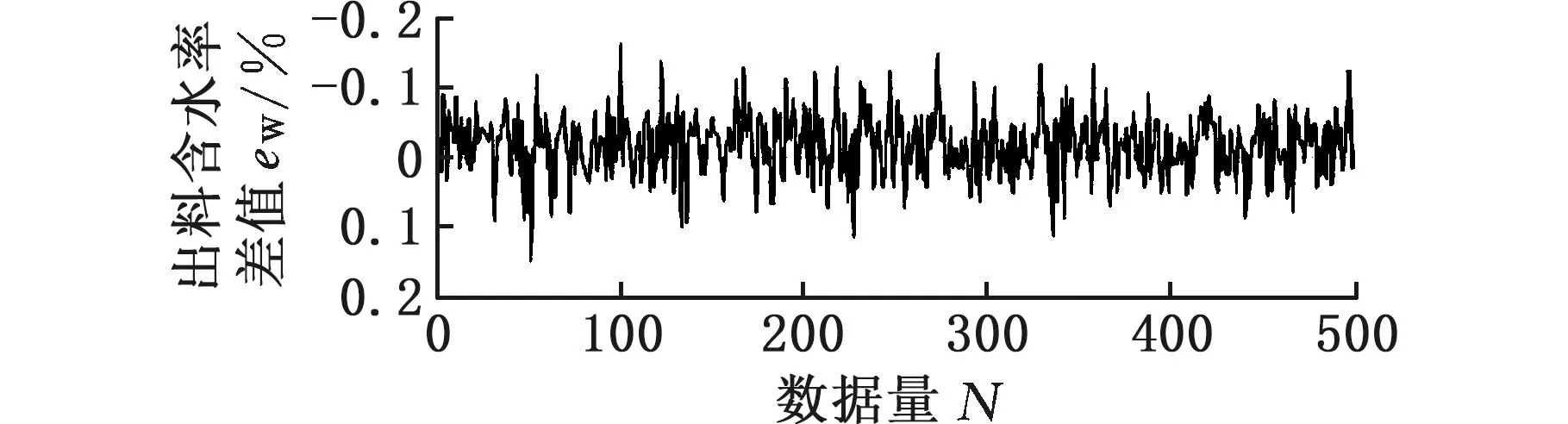
DTCN_A模型中的編碼器深度挖掘工藝參數,卷積過程中的層數對挖掘程度具有重大影響,因此設置不同的網絡層數來探索其對模型性能的影響(表2)。由表2可知,隨著編碼器層數的增加,對數據的潛在時序關聯關系的挖掘更深入;編碼器層數為7時的預測模型性能最佳。由圖7可見,出料含水率和出料溫度的預測值與真實值之間相差的數值均小于0.2。

表2 松散回潮DTCN_A模型中不同編碼器層數的模型性能
(a)出料含水率
4.2.1消融實驗
本文通過消融實驗來驗證模型網絡結構對提高預測精度的有效性,消融實驗的對比模型有TCN、殘差LSTM網絡、TCN+殘差LSTM網絡(TCN_L)、注意力機制+殘差LSTM網絡(A_LSTM)。在相同條件下訓練上述模型,結果如表3、圖8和圖9所示。由表3可以看出,TCN_L的預測效果較優于TCN和殘差LSTM網絡,A_LSTM的預測效果優于殘差LSTM網絡,這說明混合模型能提取更豐富的特征信息。TCN_L與A_LSTM都能提高模型的預測精度,因此本文在序列到序列的學習結構下結合TCN、殘差LSTM網絡和注意力機制,提出DTCN_A網絡模型。實驗證明DTCN_A的預測效果優于TCN_L和A_LSTM,驗證了DTCN_A在網絡結構上的有效性。
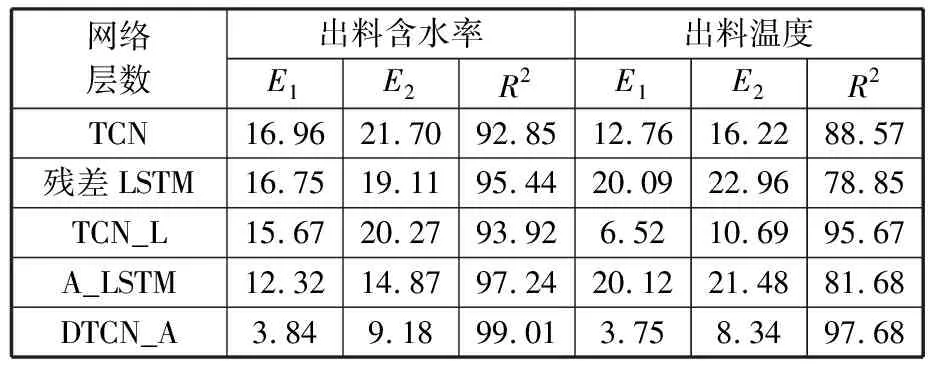
表3 消融實驗的結果

(a)TCN模型
4.2.2對比驗證
(1)模型精度對比。為驗證模型的預測效果,將傳統回歸方法(線性回歸和多項式回歸)、支持向量機回歸(SVR-LINEAR、SVR-POLY和SVR-RBF)、DNN、循環神經網絡(RNN、LSTM和GRU)、TCN、Seq2Seq按照模型挖掘特征的完整性劃分成淺層學習模型、基層深度學習模型和深度模型,將平均絕對誤差E1和均方根誤差E2作為上述模型的評估分析指標。由表4可知, DTCN_A模型具有較好的預測性能和穩定性。相較于淺層學習模型,DTCN_A模型能提取數據中的時序信息;相較于深度學習模型,DTCN_A模型可以較為全面地獲得工藝數據中潛在的深層時序關聯特征,進一步減小預測誤差。
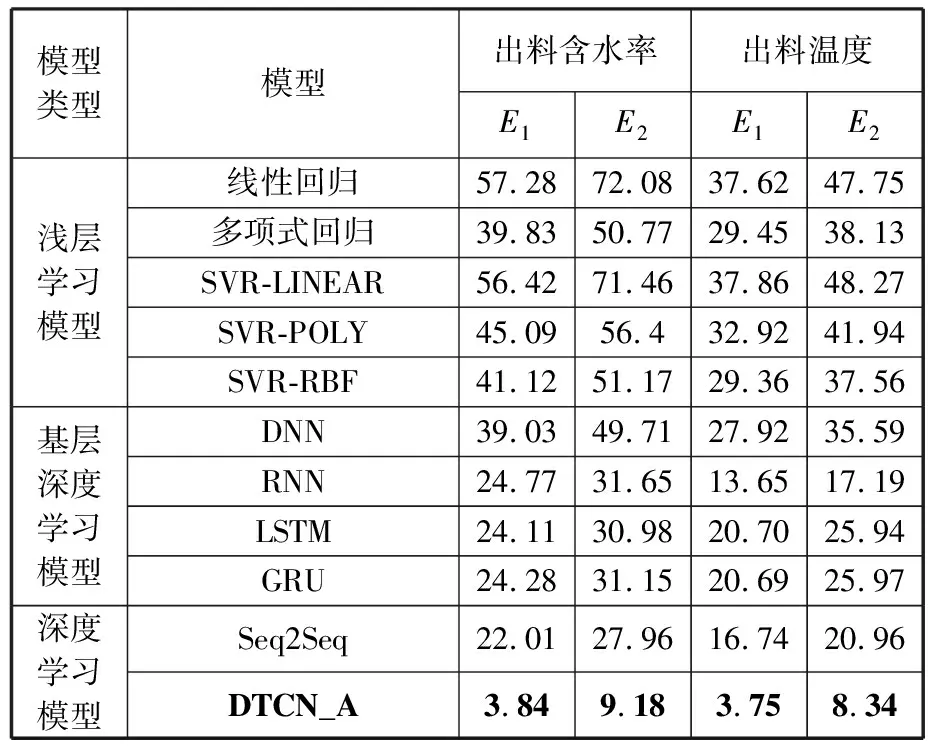
表4 不同預測模型的預測結果
(2)穩定性驗證。為進一步驗證DTCN_A模型的穩定性,在考慮預測精度的前提下,計算DNN、RNN、LSTM、GRU、Seq2Seq和DTCN_A在50次模型訓練下的平均絕對誤差和均方根誤差的最大值、最小值、極差和標準差。如表5所示,DTCN_A預測測試集數據的質量指標時,性能指標的變化幅度略小于DNN、RNN、LSTM、GRU和Seq2Seq,這體現了DTCN_A在穩定性上的優勢。

表5 50次模型訓練的預測模型性能指標
4.2.3泛化性驗證
車間工藝質量預測中,模型的泛化能力是重要指標。為測試DTCN_A模型的泛化能力,將該模型應用至一級加料工序(多輸出工序)和加香工序(單輸出工序)。
一級加料工序的質量指標與松散回潮相同,但有11個工藝參數,將相同條件下收集的33 000條數據組成數據集Ⅰ。加香工序的質量指標為出料含水率,關鍵工藝參數有5個,將相同條件下收集的37 000條數據組成數據集Ⅱ。
模型DTCN_A對數據集Ⅰ和Ⅱ的泛化能力測試結果如表6所示,DTCN_A的預測結果和真實值的擬合曲線圖10、圖11。預訓練模型在數據集Ⅰ和Ⅱ下的預測精度均在97%以上,說明本文構建的模型具備一定的泛化能力,能適應不同的場景。
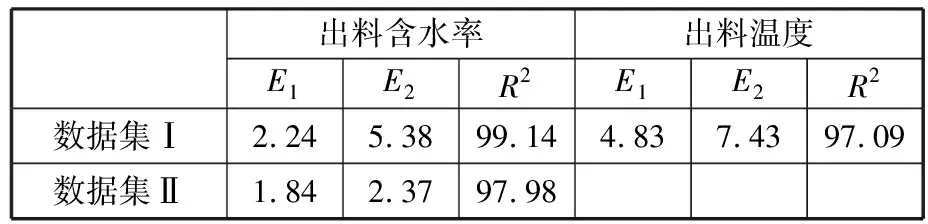
表6 預訓練模型的泛化能力測試結果

(a)出料含水率

圖11 加香工序的出料含水率預測值與真實值
4.3遷移學習策略效果對比
通過重新訓練、微調模型參數、凍結編碼層和凍結全部特征提取層4種特征遷移方式來更新訓練模型,可提高模型預測的準確率、縮短運行時間。以松散回潮工序為例,將不同產線的松散回潮工序的數據作為目標域數據(每組數據集的樣本數目不同),每種遷移學習策略均使用ADAM算法調整神經網絡各層的參數。通過對比不同遷移學習策略下測試集的準確性和模型更新訓練時間(見表7、表8)來選擇最佳的遷移學習策略。

表7 A產線松散回潮工序不同遷移學習策略的結果
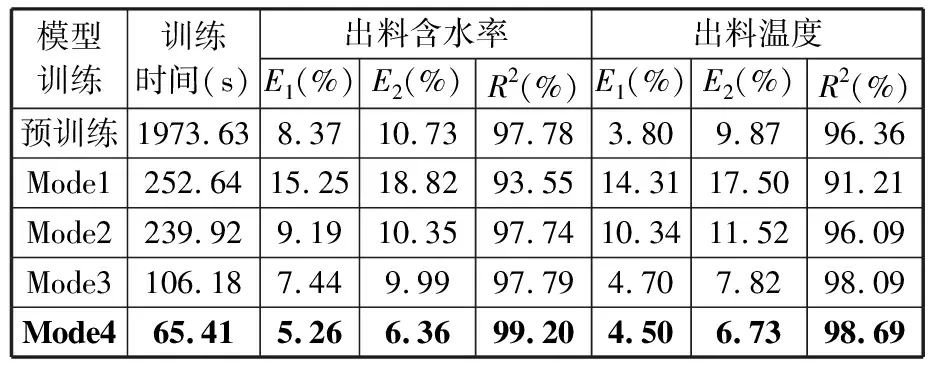
表8 B產線松散回潮工序不同遷移學習策略的結果
由表7、表8可知,在相同的訓練條件下,重新訓練(Mode1)的預測未達到滿意效果,這是由于無法從有限的訓練樣本找出深度工藝關聯特征。凍結全部特征提取層遷移學習方式(Mode4)的預測效果最佳,且模型訓練時間較Mode1短,這是因為Mode4完全繼承了原有模型的結構和參數,能較為完整地提取深度潛在特征。預訓練模型也存在不理想的預測結果,為此將預模型迭代次數改為100,對預測效果不佳的預訓練模型進行模型遷移,預測結果如表9、表10所示。
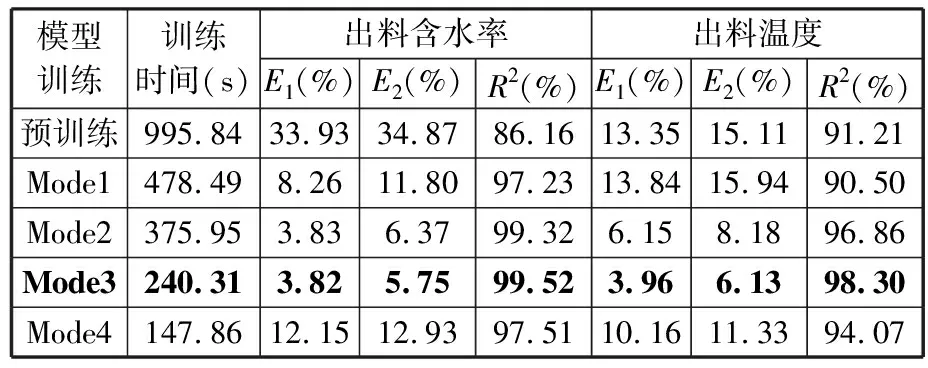
表9 預訓練模型迭代次數為100時A產線的預測結果
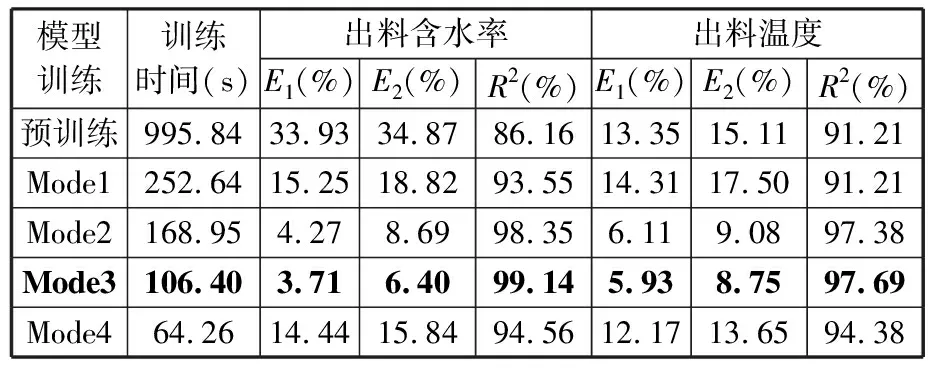
表10 預訓練模型迭代次數為100時B產線的預測結果
由表9、表10可以看出,采用凍結編碼層特征的遷移策略(Mode3)預測的結果最優,這說明迭代次數為100的DTCN_A模型中,編碼器能提取較為完整的工藝參數關聯時序特征信息,但解碼器的特征提取能力不足,需要通過模型的自適應訓練和參數更新來達到滿意的預測效果,因此模型的訓練時間較Mode4長。與Mode1相比,Mode4在保證模型精度的同時,也大大縮短了模型的訓練時間。Mode2將C產線松散回潮模型的參數作為其他產線訓練模型參數的初始值,繼承預模型中的有價值信息較少。Mode4完全采用預訓練模型中的網絡結構和參數,也繼續使用預訓練模型的無用信息,導致無法挖掘目標域數據中的工藝特征信息。由此可見,Mode3不僅能繼承歷史數據的有價值信息,還能消除預訓練模型的缺陷,進一步提高型更新速度和預測性能,使其在較短時間內提高模型預測精度,如圖12、圖13所示。

(a)出料含水率
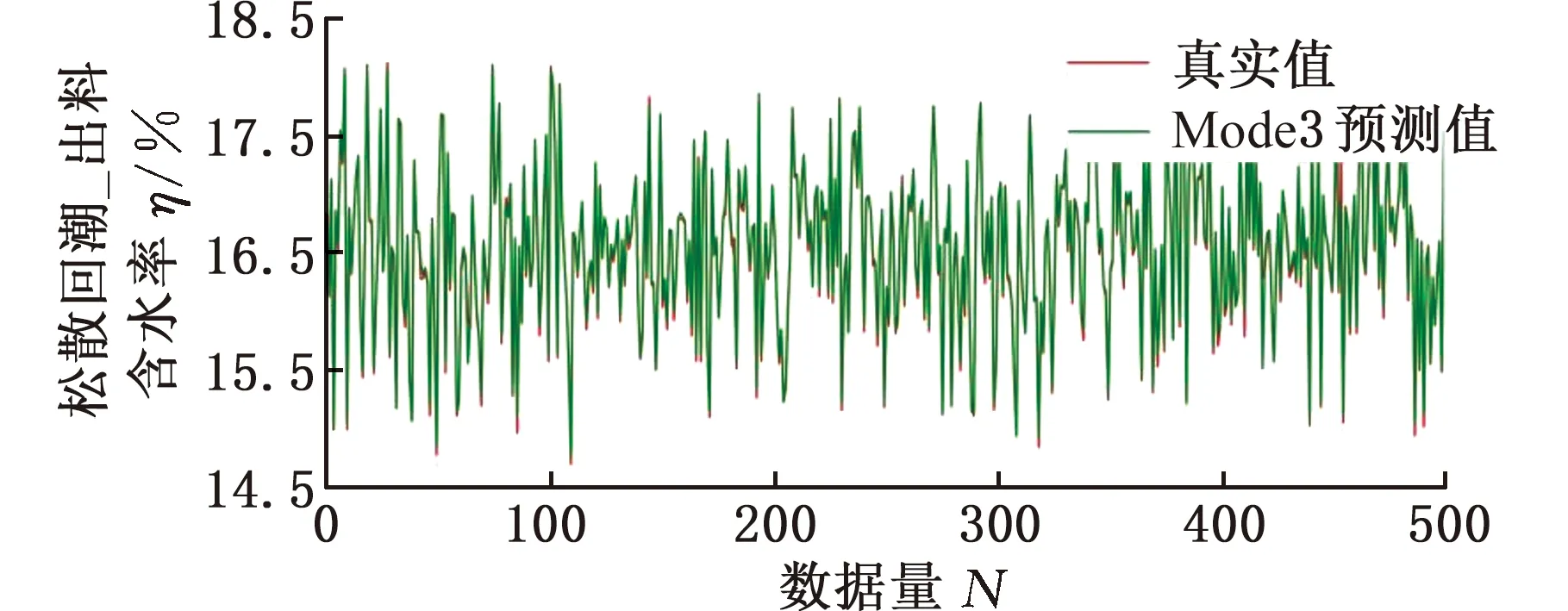
(a)出料含水率
5 結論
流程型車間工藝數據具有復雜的時序關聯特征,結合TCN與序列到序列的學習結構,構建了質量預測的深層模型DTCN_A,實現了對工藝數據特征的深層學習和表達。DTCN_A模型的編碼器通過TCN模型捕捉工藝參量數據中的長時間依賴信息,通過嵌套時序注意力機制重點聚焦關鍵工藝時刻的信息,提高模型的長時距離表達能力。DTCN_A模型的解碼器采用殘差LSTM網絡模型提取歷史質量指標的時序特征信息,訓練后的模型能有效利用時序關聯性開展單輸出和多輸出的質量預測。某生產線的實測數據仿真實驗表明,質量預測模型DTCN_A具備良好的總體預測精度和個體誤差控制能力,明顯優于SVR、RNN和Seq2Seq等預測方法。
基于提出的模型DTCN_A,針對流程型車間多產線的加工特性,提出了知識遷移的有效策略。2條生產線的仿真實驗證明,模型DTCN_A預測效果良好時,將該模型中的整體網絡結構和全部特征提取層的參數遷移至目標域中,可以有效繼承模型DTCN_A對深層潛在特征信息的提取能力;模型DTCN_A預測效果不佳時,采用共享該模型的網絡結構和編碼器參數是一種有效的遷移學習方式,該方法不僅可以繼承模型DTCN_A中提取深度特征的能力,同時還能根據目標域數據與源域數據間的差異進行模型的自適應訓練,與模型重新訓練相比,可以大幅度縮短樣本仿真時間、提高模型預測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
山東冶金(2019年6期)2020-01-06 07:45:54
世界農藥(2019年2期)2019-07-13 05:55:12
光學精密工程(2016年6期)2016-11-07 09:07:19
銅業工程(2015年4期)2015-12-29 02:48:39
新疆鋼鐵(2015年3期)2015-11-08 01:59:52
核科學與工程(2015年4期)2015-09-26 11:59:03
石油化工應用(2014年8期)2014-03-11 17:40:03
