基于云計算的分布式數據庫技術
2023-08-04 00:47:32李軍丹馮學曉
通信電源技術 2023年9期
李軍丹,馮學曉
(鄭州工業應用技術學院,河南 鄭州 451150)
0 引 言
隨著互聯網技術的飛速發展,數據量呈爆發式增長,傳統的關系型數據庫已經不能滿足大規模數據存儲和處理的需求[1,2]。云計算技術的出現為企業提供了靈活、高效、低成本的互聯網基礎設施,使得分布式數據庫得以大規模應用。分布式數據庫具有高可用、可擴展、負載均衡等特性,能夠為企業提供高效的數據存儲和處理服務[3,4]。因此,研究基于云計算的分布式數據庫技術具有重要的實際意義。
目前,分布式數據庫技術已經廣泛應用于云計算平臺。在分布式數據庫領域已經涌現出了許多成熟的解決方案,如Google 的Spanner、阿里巴巴的OceanBase、騰訊的TDSQL 等[5-7]。這些分布式數據庫系統在分布式事務、數據一致性、負載均衡等方面都具有出色的表現,但是它們都是封閉的商業系統,缺乏可移植性和靈活性。因此,研究基于開源技術的分布式數據庫系統具有重要的意義。
本文旨在基于KVM 云計算平臺設計一種分布式關系型數據庫,實現數據的高可用、可擴展、負載均衡等特性。具體研究內容包括MON 節點、GUEST 節點和底層數據庫節點組成的系統設計,一致性哈希算法實現數據的分布式存儲和分配,構建針對客戶端、管理端以及底層計算存儲節點的觀察者模式通信架構。
1 KVM 云計算環境下的分布式數據庫架構設計
KVM 是一種開源的虛擬化技術,可以將一臺物理服務器分割成多個虛擬機,并且每個虛擬機可以獨立運行自己的操作系統和應用程序[8]。KVM 虛擬化技術可以幫助企業更好地利用服務器資源,提高資源利用率和靈活性,同時降低成本。
1.1 系統總體設計
如圖1 所示,本文設計的基于云計算的分布式系統數據庫技術分為3 個模塊,分別是MON、GUEST以及Cloud Pool。系統運行時,GUEST 模塊接收到用戶發送的結構化查詢語言(Structured Query Language,SQL)請求后,根據請求中指定的數據存儲節點的信息,將請求轉發給相應的數據庫節點進行處理。數據庫節點從Cloud Pool 模塊中獲取數據并進行相應的處理,并將處理結果返回給GUEST 模塊,GUEST 模塊再將結果返回給用戶。MON 模塊可以實時監測每個數據庫節點的運行狀態和通信情況,并及時發出警報。當數據庫節點出現異常情況時,MON 模塊可以進行自動化處理,如自動進行故障轉移或數據恢復等。3個模塊協同工作共同實現了基于云計算的分布式系統數據庫技術。

圖1 系統總體設計
1.2 MON 節點的實現
在KVM 中,本系統使用虛擬機監控器(Virtual Machine Monitor,VMM)來實現MON 節點的功能。VMM 是KVM 虛擬化技術的核心組件之一,負責協調和管理各個虛擬機實例的運行。具體來說,VMM 可以通過對虛擬機實例的資源分配和監控,實現對整個分布式系統的監控和管理。
1.3 GUEST 節點的實現
本系統使用虛擬機(Virtual Machine,VM)實現GUEST 節點的功能。每個GUEST 節點對應一個虛擬機實例。該虛擬機實例可以運行關系型數據庫管理系統,并提供對外的數據服務。當用戶發送SQL 請求時,GUEST 節點會根據請求內容,將請求轉發給相應的底層數據庫節點進行處理。
1.4 底層數據庫節點的實現
本系統使用虛擬化存儲技術實現底層數據庫節點的功能。具體來說,可以使用分布式存儲系統(如Ceph、GlusterFS 等)存儲數據庫的數據文件,并通過KVM 虛擬化技術將其掛載到虛擬機實例上。當GUEST 節點接收到SQL 請求時,它會將請求轉發給相應的底層數據庫節點進行處理底層數據庫節點處理完畢后,將執行結果返回給GUEST 節點,最終由GUEST 節點將結果返回給用戶。
2 分布式存儲和分配
哈希算法是一種將任意長度數據映射為固定長度數據的算法[9]。其核心思想是將數據通過哈希函數計算后得到一個哈希值,可以唯一地表示原始數據。哈希函數通常具有以下特點:對于相同的輸入數據,哈希函數總是返回相同的輸出;對于不同的輸入數據,哈希函數返回不同的輸出;計算速度快。
一致性哈希算法是一種分布式哈希算法,將哈希值映射到一個環上,將數據存儲在離該哈希值最近的節點上。在這個環上,每個節點都被賦予一個唯一的標識符,通常是一個哈希值。當新的數據到達時,先通過哈希函數計算出一個哈希值,然后在環上順時針找到離該哈希值最近的節點,并將數據存儲在該節點上。當節點出現故障時,該節點上存儲的數據會自動轉移到下一個節點上,從而實現數據的高可用性和負載均衡。
在本系統中,一致性哈希算法可以實現數據的分布式存儲和分配。具體來說,系統中的每個節點都被賦予一個唯一的標識符,該標識符可以通過哈希函數計算得出。當新的數據到達時,先通過哈希函數計算出一個哈希值,然后在節點標識符的環上順時針找到離該哈希值最近的節點,并將數據存儲在該節點上。這樣系統中的數據就可以分布式地存儲在不同的節點上,從而提高了系統的可擴展性和可靠性。同時,由于一致性哈希算法可以實現節點的動態加入和退出,因此可以很好地適應系統的擴展和縮減。
3 通信架構
如圖2 所示,本文的通信架構由客戶端、管理端、底層計算存儲節點3 部分組成,采用觀察者模式[10]。
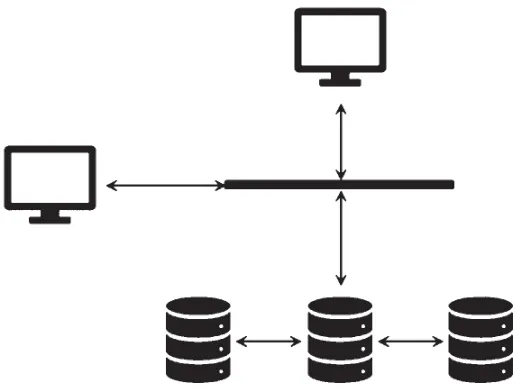
圖2 總體通信架構
觀察者模式是一種設計模式,定義了對象之間的一種一對多的依賴關系。當一個對象狀態發生改變時,它的所有依賴者都會收到通知并自動更新。在本文的通信架構中,客戶端、管理端和底層計算存儲節點之間的通信正是采用了觀察者模式。
在該架構中,每個節點都可以充當觀察者或者被觀察者。當一個節點作為觀察者時,它會觀察其他節點的狀態。當狀態發生改變時,它會自動更新自己的狀態。當一個節點作為被觀察者時,它會定期向其他節點發送狀態信息。當其他節點接收到該信息時,會更新自己的狀態。
具體來說,當客戶端作為觀察者時,會觀察管理端和底層計算存儲節點的狀態。當客戶端發起請求時,它會向管理端發送請求信息。管理端接收到請求信息后,會向底層計算存儲節點發送相應的命令。底層計算存儲節點收到命令后,會執行相應的操作,并將執行結果返回給管理端。管理端收到執行結果后,會將結果返回給客戶端。在這個過程中,客戶端、管理端和底層計算存儲節點之間形成了一個松耦合的通信架構,各個節點之間可以獨立地進行狀態的維護和更新。同時,由于采用了觀察者模式,當系統中的某個節點狀態發生改變時,其他節點會自動收到通知并進行相應的更新,從而實現信息的實時同步和系統的高效運行。
4 分析與討論
該系統采用了一些先進的技術和方案,以達到更好的性能和可擴展性。具體來說,該系統采用了KVM 虛擬化技術作為底層支持,采用一致性哈希算法進行數據的分布式存儲和分配,并采用了觀察者模式作為通信架構,使得系統具有較好的可靠性和可擴展性。
從性能分析的角度看,該系統具有以下幾個優點。(1)可伸縮性強。該系統采用云計算平臺和分布式技術,使得系統可以根據業務需求動態擴容和縮容,從而提高系統的性能和可擴展性。(2)可用性高。該系統采用觀察者模式作為通信架構,保證了系統在節點故障時的可用性,并通過MON 節點進行整體監控和管理,從而提高了系統的可靠性。(3)分布式存儲和分配。該系統采用一致性哈希算法進行數據的分布式存儲和分配,使得系統可以實現數據的負載均衡和高效的數據訪問。但是,該系統也存在以下一些缺點。(1)資源占用較高。該系統采用了虛擬化技術和分布式存儲系統,因此需要較高的資源占用,包括中央處理器(Central Processing Unit,CPU)、內存和磁盤等。(2)系統復雜度較高。該系統采用多個技術和方案,使得系統的復雜度較高,需要較高的技術和人力投入進行維護與管理。(3)系統響應時間較長。系統采用虛擬化技術和分布式存儲系統,使得系統響應時間較長,可能會影響用戶體驗。因此,在實際應用中,需要根據具體業務需求和技術條件進行選擇與權衡。
5 結 論
本文介紹了一種基于云計算的分布式系統數據庫技術,旨在解決傳統單機關系型數據庫在大規模數據處理和高并發請求下的性能瓶頸。本系統主要包括MON 節點、GUEST 節點和底層數據庫節點3 個模塊。其中,MON 節點負責監控集群整體運行狀況;GUEST 節點作為SQL 接收和處理端,負責接收用戶發送的SQL 請求并進行數據存儲節點的定位;底層數據庫節點則是運行在KVM 云計算平臺的虛擬機實例,用于存儲和處理數據。為了實現數據的分布式存儲和分配,本系統采用了一致性哈希算法。該算法通過將數據映射到哈希環上,然后將數據存儲到離其最近的節點上,從而實現數據的負載均衡和動態擴展。在通信架構方面,本文采用觀察者模式實現了高效的數據傳輸和響應速度。
總的來說,本文的研究成果在分布式數據庫技術方面有較大的創新和應用價值。該系統采用云計算平臺作為基礎,實現了數據的分布式存儲和處理。但是,該系統還存在一些缺點,如數據一致性問題、分片過程中的數據遷移問題等,需要在后續的研究中加以解決。另外,本文著重研究了理論框架,具體實現方案還有待進一步完善。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
