機器學習在宇宙線粒子鑒別中的應用*
2023-07-27 10:58:58劉燁牛赫然李兵兵馬欣華崔樹旺
物理學報 2023年14期
關鍵詞:模型
劉燁 牛赫然 李兵兵 馬欣華 崔樹旺?
1) (河北經貿大學管理科學與工程學院,石家莊 050061)
2) (河北師范大學物理學院,石家莊 050024)
3) (中國科學院高能物理研究所粒子天體物理重點實驗室,北京 100049)
4) (四川天府新區宇宙線研究中心,成都 610000)
基于熱中子探測器實驗模擬數據,使用決策樹(decision tree,DT)、隨機森林(random forest,RF)和BP神經網絡(back-propagation neural network,BPNN)構建了宇宙線粒子鑒別機器學習模型,對每種粒子分別使用不同的機器學習算法基于模擬數據進行模型訓練,并針對算法進行超參數調整,將每種算法的AUC 值和Q 品質因子作為粒子成分鑒別的評價指標.實驗結果表明,不同機器學習模型對粒子預測精度影響很大.在測試檢驗中,經過交叉網格搜索方法調參后的決策樹鑒別模型對中成分(碳氮氧和鎂鋁硅)比較敏感,鑒別模型AUC 值均在0.95 以上,Q 品質因子均大于6;經交叉網格搜索方法調參后的隨機森林鑒別模型對于宇宙線粒子鑒別的效果最好,所有粒子鑒別模型的AUC 值均大于0.92 且Q 品質因子均在4 以上;BP 神經網絡算法只對質子和鐵核比較敏感.本研究對宇宙線粒子鑒別和篩選提供了新的方法和選擇,可為熱中子探測器后續開展宇宙線能譜測量提供新思路.
1 引言
宇宙線是唯一來自外太空的物質樣本,本質是高能帶電粒子流,能量從keV 到EeV 跨越17 個量級,并且在傳播過程中會與星際物質相互作用產生少量次級核子和反質子、反電子、伽馬光子、中微子等次級宇宙線粒子[1-3].在宇宙線研究領域中,宇宙線能譜結構和次級宇宙線粒子成分的精確測量是解決宇宙線起源、加速、傳播機制等問題的關鍵[4,5].目前,多個實驗已經測量到了宇宙線能譜中的“膝區”結構,但是“膝區”的確切位置及成分存在較大差異[6],因此精確鑒別宇宙線中的粒子成分十分重要,是開展相關科學研究的重要基礎和前提.
傳統宇宙線成分鑒別大多基于多變量分析方法完成,該方法需要人工選取特征,耗費人力資源的同時容易丟失數據信息[7],而機器學習方法能直接在原始數據的基礎上進行分析,節省人力資源的同時盡可能挖掘數據的信息.機器學習是人工智能的分支之一,是統計學、人工智能和計算機科學交叉的研究領域,可以通過學習多源、復雜的數據內在模式和結構,挖掘隱藏在數據背后的信息,并用于解決分類、回歸、聚類等復雜問題[8].隨著機器學習的不斷完善和計算能力的提升,機器學習算法也逐漸幫助科研人員分析和處理大量的物理學相關數據.Herrera 等[9]評估了人工神經網絡(ANN)、極端梯度提升樹(XGBoost)、支持向量機(SVM)和K 近鄰(KNN)算法對超高能宇宙線成分的分類效果,并使用五折交叉驗證的方法對算法的超參數進行優化,結果表明極端梯度提升樹對所有成分都表現出優異性能,準確率和f1 評分均為0.97,且運行時間最短,支持向量機的準確率和f1 評分均為0.94,但是運行時間較長,人工神經網絡和K 近鄰算法效果稍差;Pang 等[10]在高能核物理領域利用卷積神經網絡(CNN)模型,將不同狀態方程下相對論流體力學演化末態的粒子分布作為神經網絡輸入,將演化使用的和物質狀態方程種類作為標簽做監督學習,將尋找QCD 相變臨界點的任務轉化為兩個相變區域分類問題;高澤鵬等[11]使用LightGBM 決策樹算法訓練初始化過程中有無形變效應給出的反應末態的自由質子、帶點碎片及π+,π-的pt-y0譜,通過碰撞末態數據反推初態結構,分類的準確率在60%—70%之間,同時,此研究還通過LightGBM 決策樹算法計算了特征重要性,發現彈靶快度區形變的帶電碎片敏感于彈靶核的初始形變,與相關理論分析相一致.
本研究以熱中子在探測器模擬數據為研究對象,以粒子的原初能量、天頂角、電子數、中子數及芯距5 個量作為特征,應用決策樹(decision tree,DT)、隨機森林(random forest,RF)和BP 神經網絡(back-propagation neural network,BPNN) 3 種機器學習算法,構建了3 種宇宙線粒子鑒別模型,并調整3 種算法的超參數以提高其對宇宙線成分鑒別能力,然后使用相關評價指標對這3 種模型的結果進行評估,得到了性能最優的鑒別模型.最后,用驗證數據驗證了最優鑒別模型的精度和泛化能力,為后續開展宇宙線能譜精確測量提供依據和參考.
2 研究方法
本文選擇決策樹、隨機森林和BP 神經網絡3 種常用的機器學習算法建立宇宙線粒子鑒別模型.實驗中,首先通過宇宙線粒子在探測器上的坐標計算出粒子的芯距,并選擇宇宙線粒子原初能量(E0)、天頂角(theta)、中子數(neutron_total)、電子數(MIPs_total)和芯距(core_distance),5 個量作為成分敏感特征值,然后將5 種成分的數據混合在一起,定義模型輸出值若為“0”則對應目標成分,若為“1”則對應其他成分,并將數據按4∶1∶5的比例隨機的劃分為訓練集、測試集和驗證集,分別用于模型的訓練、測試和泛化能力的檢驗,并且在訓練過程中根據模型和粒子成分鑒別的評價指標,不斷的對模型的超參數進行調整,篩選出最優鑒別模型.本文中機器學習模型的訓練、測試和驗證均基于Python 語言中scikit-learn 和Pytorch庫實現,技術路線圖如圖1 所示.

圖1 宇宙線成分鑒別模型技術路線圖Fig.1.Technical roadmap of the cosmic rays component identification model.
為評估各機器學習鑒別模型對數據集分類的效果,本文使用算法AUC 值和宇宙線研究領域中的Q品質因子作為檢驗算法分類效果的評價指標.AUC 值等于ROC 曲線下方面積,是機器學習中一個通用的評價算法性能的指標,用于權衡正確分類的收益和錯誤分類的代價之間的關聯[12].ROC曲線分別以假正率(FPR)和真正率(TPR)為x軸和y軸:
其中,TP 表示真正類,即被模型預測為正類的正樣本數;FP 為假正類,即被模型預測為正類的負樣本數;TN 為真負類,即被模型預測為負類的負樣本數;FN 為假負類,即被模型預測為負類的正樣本數.
熱中子探測器模擬數據鑒別是一個分類問題,但不能只使用統計學中常用的準確率判別模型分類好壞,因此本文使用高能物理領域中一個常用的評價指標Q品質因子對模型區分效果進行衡量[7],其定義為
其中 Perp為挑選目標成分的保留率,Pere為宇宙線其他成分的保留率.
2.1 數據集建立及預處理
本文使用的熱中子探測器模擬數據由CORSIKA 軟件模擬生成,該軟件包含多種粒子反映模型,可以模擬粒子到達不同海拔高度的相關信息,包括粒子種類、能量、天頂角等,這些參數已經得到了實驗證實,應用在眾多宇宙線相關領域的實驗中[13].熱中子探測器模擬分為兩部分,首先利用CORSIKA 軟件模擬宇宙線在大氣中級聯簇射過程,產生宇宙線粒子原初能量、天頂角、方位角及粒子位置等信息,然后利用Geant4 工具包開展熱中子探測器響模擬.最終熱中子探測器模擬數據為質子、氦核、鐵核、鎂鋁硅、碳氮氧,每種成分各4000 個事例,能量范圍為1—10 PeV,天頂角0°—60°,方位角為0°—360°.
冗余特征可能會造成模型效率低或者過擬合等問題[14],因此本文在構建特征過程中首先根據粒子位置信息計算出粒子到探測器中心的芯距,并用其代替粒子其他位置信息,作為特征加入到模型訓練和測試過程.因此,本文在建模過程中使用宇宙線粒子的原初能量、天頂角、電子數、中子數及芯距5 個量作為特征.
2.2 機器學習模型構建
2.2.1 決策樹模型構建
決策樹算法(DT)是一種經典的機器學習算法,因其結構簡單、學習成本低且可解釋性強,在機器學習領域有著廣泛應用,常用的決策樹算法有ID3,C4.5,CART 算法等[15].決策樹的構建過程就是根據數據的不同特征,將數據劃分到不同區域,使得同一區域的數據盡可能是同一種類型.決策樹算法構建過程是選擇具有較強分類能力的特征生成決策樹,ID3 算法是采用信息增益作為選擇選擇特征的度量,而C4.5 算法采用信息增益比[16].但由于決策樹算法具有強大的建模能力,因此會產生過擬合的問題,CART 算法在特征選擇時以基尼系數為度量,然后對所有屬性可能進行遍歷,選擇劃分子集后基尼系數最小的節點進行分支,這樣可以簡化樹的結構,避免過擬合問題[17].在信息論中,信息熵用于描述變量分布的不確定性,決策樹在劃分子樹時以信息熵為基礎,進行相關計算,然后選擇特征劃分子樹.對于離散型隨機變量D,其信息熵為
式中,K為樣本類別總數,|Dk|為第k類樣本的數目,|D|為數據集D的數目.使用特征A對變量D的條件熵為
則選擇A構建子樹的信息增益、信息增益比和基尼系數分別為
本文建模過程中,使用交叉網格搜索方法,對樹的深度最小分割樣本數和最小分割葉子節點數等主要超參數進行調整.交叉網格搜索方法是指定超參數取值的一種窮舉搜索方法,用于搜索算法的最優超參數組合.通過將需優化算法的超參數運用交叉驗證的方法進行優化,即將各個超參數可能的取值進行排列組合,列出所有可能的組合結果生成“網格”,然后將各組合用于算法訓練,并使用交叉驗證的方法對表現進行評估,將平均得分最高的超參數組合作為最佳的選擇,返回給算法[18].決策樹算法使用交叉網格搜索方法進行調整超參數時,將表1 所示的超參數設置在指定范圍內,將參數cv 設置為4,其他參數默認,搜尋最佳超參數組合.決策樹算法鑒別各種成分最佳超參數如表1 所示.

表1 決策樹鑒別不同成分最佳超參數Table 1. Optimal hyperparameters of decision tree identifying different components.
2.2.2 隨機森林模型構建
隨機森林算法(RF)是一種監督機器學習算法,廣泛用于解決分類和回歸問題.本質上,其是由多個決策樹集成之后構建的,使用Bagging (自助聚類)方法訓練而成,通過隨機有放回的抽樣方式選取數據構建分類器,最后 通過組合學習得到的算法提升算法整體效果[19].隨機森林結構如圖2所示.

圖2 隨機森林算法建模流程圖Fig.2.Flow chart of random forest algorithm modeling.
隨機森林算法可以看作是對原有決策樹算法的整合和改進,能夠很好地處理變量間的非線性關系,有著分類準確率高、抗噪能力優異、抗過擬合能力較強以及能夠平衡非平衡數據的誤差等優點;此外,隨機森林算法能夠在觀測變量較少的前提下完成分類任務,適合宇宙線粒子這種非平衡數據的分類[20].本文使用隨機森林算法建立宇宙線粒子成分鑒別模型過程中,使用交叉網格搜索方法進行算法超參數調整,調整結果如表2 所示.

表2 隨機森林鑒別不同成分最佳超參數Table 2. Optimal hyperparameters of random forest identifying different components.
2.2.3 BP 神經網絡模型構建
人工神經網絡算法(ANN)是一種常用的非線性數據建模算法,通過學習尋找并建立輸入數據和目標數據之間的映射關系,十分適合解決非線性和不確定性問題.BP 神經網絡,即前饋神經網絡是一種多層前饋的人工神經網絡,其基本原理是輸入信號前向傳播,誤差反向傳播[21].在前向傳播過程中,輸入信號經過輸入層和隱藏層處理后,到達輸出層后輸出.若輸出結果與預期結果不一致,則根據預測誤差,使用梯度下降算法(gradient descent)調整各層網絡的權重和偏置,使得算法輸出結果無限逼近預期結果,直至得到損失不再降低或達到指定循環次數,該過程稱為反向傳播[22].BP 神經網絡結構一般分為3 層,即輸入層、隱藏層和輸出層,輸入層負責接收輸入數據并轉換為信號,輸出層負責輸出模型結果,隱藏層負責建立二者的映射關系.本文BP 神經網絡結構示意圖如圖3 所示.

圖3 本文BP 神經網絡結構示意圖Fig.3.Structure diagram of BP neural network in this paper.
隱藏層第j個神經元的輸出值為Oj,計算公式為
輸出層第k個神經元的輸出值為Ok,計算公式為
其中,nj和nk分別為隱藏層第j個神經元和輸出層第k個神經元的輸入;αij和λj分別為輸入層第i個神經元到隱藏層第j個神經元的權重和偏置;βjk和γk分別為輸入層第j個神經元到隱藏層第k個神經元的權重和偏置;N和M分別代表輸入層和隱藏層的神經元個數;φ和ψ分別代表隱藏層和輸出層的激活函數.
本文使用BP 神經網絡進行建模過程中,首先對數據進行預處理以消除極端數據對于模型訓練的影響,數據預處理原理為
其中xscalered為標準化后的數據,xmax和xmin分別為數據的最大值和最小值.
然后,確定BP 神經網絡的拓撲結構.本文中神經網絡的輸入和輸出層均設置為一層,輸入層和輸出層神經元個數分別設置為5 個和2 個,隱藏層節神經元數由Kolmogorov 公式a計算得出[23],其中Nh為隱藏層神經元數,Nin為輸入層神經元數,Nout為輸出層神經元數,a為取值范圍為1—10 的常數.實驗中選取宇宙線粒子5 個特征敏感值輸入網絡,故Nin為5;實驗中在輸出層中通過Softmax 函數計算并輸入數據標簽為“0”和“1”的概率,故Nout為2.因此隱藏層節點數的取值范圍是Nh∈[3,13] .然后,為了確定最佳隱藏層節點數,采用控制變量法,使用動態調整學習率算法,初始學習率設置為0.01,每迭代2000 次,學習率變為原來的0.7 倍,其余條件不變,只改變隱藏層節點個數,并通過損失函數圖像確定迭代次數,進行模擬實驗.以鑒別氦核為例,采用BP 神經網絡算法核驗結果如表3 所示.

表3 BP 神經網絡(鑒別氦核)隱藏層節點核驗結果Table 3. BP neural network (identifying helium) hidden layer nodes verification results.
綜合考慮AUC 值和Q品質因子,確定隱藏層節點數為13,因此本文使用的BP 神經網絡結構為5-13-2 的拓撲結構,對熱中子探測器中的氦核模擬數據進行鑒別.表3 給出本文根據評價指標確定BP 神經網絡算法鑒別氦核最佳拓撲結構的核驗結果,BP 神經網絡鑒別其他成分最佳超參數組合的確定方法同上,結果如表4 所示.

表4 BP 神經網絡鑒別不同成分最佳超參數組合Table 4. Optimal hyperparameters of BP neural network identifying different components.
圖4 為3 種宇宙線粒子鑒別模型鑒別氦核的10 折交叉驗證檢驗圖,可以看到10 折交叉驗證過程中3 種模型訓練和測試的準確率之差均不超過0.2,即3 種模型均不存在嚴重的過擬合問題.

圖4 三種宇宙線鑒別模型鑒別氦十折交叉驗證核驗圖Fig.4.Results of three cosmic rays identification models identifying helium using 10-fold cross validation method.
3 結果與討論
本文在訓練過程中將目標成分向“0”方向訓練,其他成分向“1”方向訓練,并輸出相應的概率.為了描述3 種機器學習算法對目標成分(target)鑒別的結果,定義臨界值Tc來計算目標成分鑒別的純度(purity)和效率(efficiency),計算公式如下:
以鑒別目標成分氦核為例,3 種鑒別模型將粒子種類判定為氦核的概率如圖5 所示,綜合考慮氦核純度及效率后本文選擇臨界值Tc為0.5,即: 1)在BP 神經網絡鑒別模型中,T≤ 0.5 時,氦核鑒別效率及純度分別為36.0%,52.8%;2) 在決策樹鑒別模型中,T≤ 0.5 時,氦核鑒別效率及純度分別為83.3%,80.1%;3) 在隨機森林鑒別模型中,T≤0.5 時,氦核鑒別效率及純度分別為79.3%,95.7%;由此可以看出,隨機森林算法鑒別氦核純度較高,達到94.5%,鑒別氦核的效率在79%左右.

圖5 三種宇宙線粒子鑒別模型鑒別氦核概率分布圖Fig.5.Probability distribution of three cosmic rays identification models identifying helium.
與模型鑒別氦核過程類似,其他成分鑒別效率及純度如表5 所示.1) 在利用BP 神經網絡鑒別模型和隨機森林鑒別模型鑒別各成分時,重成分(鐵核)鑒別的效率及純度較高,其中神經網絡算法效率和純度分別為82.8%和87.5%,隨機森林鑒別模型鑒別鐵核的效率和純度分別為91.1%和93.5%;2) 在利用決策樹鑒別模型鑒別成分時,對于中成分(鎂鋁硅、碳氮氧)鑒別效率及純度較高,效率和純度均可以達到90%以上;3) 利用3 種鑒別模型鑒別輕成分(氦核、質子),決策樹與隨機森林鑒別模型鑒別輕成分效率在74%以上,純度在77%以上,而神經網絡鑒別模型鑒別輕成分效率,尤其是對氦核的鑒別效率與純度并不高,對質子鑒別效率與純度在64%以上.
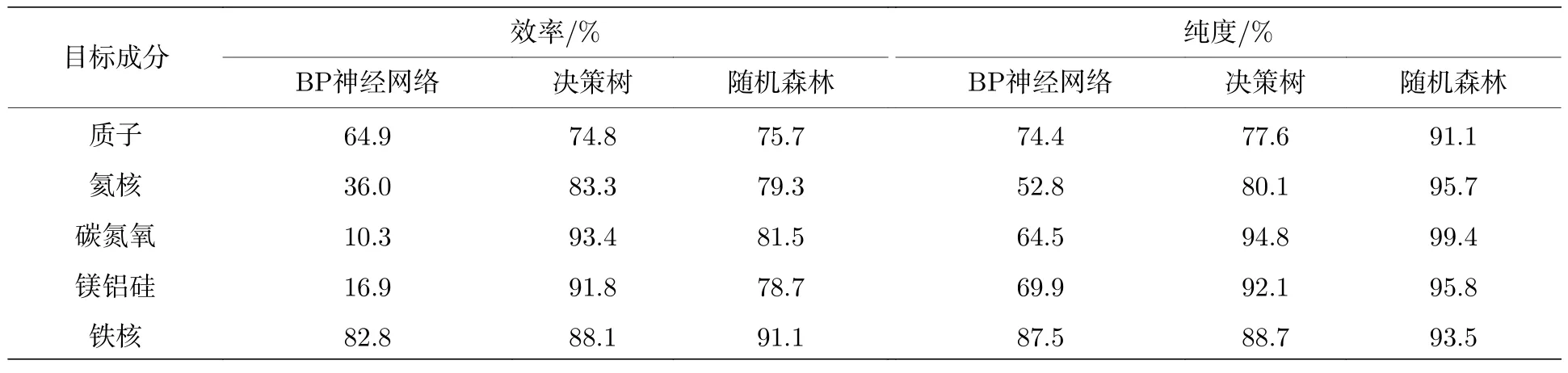
表5 三種宇宙線粒子鑒別模型鑒別不同成分效率及純度Table 5. Efficiency and purity of three cosmic rays identification models identifying different components.
隨后,本文根據各成分鑒別結果得到算法分類效果檢驗的評價指標AUC 值與宇宙線研究領域中的品質因子Q值(如表6 所示),結果表明: 1) 隨機森林算法在各成分判別中純度均可達到90%以上,Q品質因子較高,即對宇宙線各成分鑒別能力比其他兩種算法要好;2) 決策樹算法在中成分(鎂鋁硅、碳氮氧)鑒別正確率可達90%以上,Q品質因子在6 以上;在輕成分和重成分中的鑒別正確率達85%以上,Q品質因子在3 左右;3) 神經網絡算法在重成分(鐵核)鑒別中具有一定優勢,判別正確率達到87%,Q品質因子為2.96.

表6 三種宇宙線粒子鑒別模型鑒別不同成分AUC 值及Q 品質因子Table 6. AUC and Q quality factor values of three cosmic rays identification models identifying different components.
客觀來講,天頂角、能量以及簇射芯位在陣列中的位置等相關參量也都會受到原初宇宙射線的重建精度的影響,本文目前在算法建模中采用的參量還比較理想化,未將以上參量進行綜合考量,下一步我們將在此基礎上繼續優化和修正機器學習算法模型.
4 結束語
本文將決策樹、隨機森林、BP 神經網絡算法應用在宇宙線粒子分類問題中,并針對不同算法進行超參數優化調整,以提高算法判別的正確率及鑒別效率.實驗結果表明,機器學習算法在宇宙射線粒子成分鑒別領域有較大的應用前景.目前本文只考慮了BP 神經網絡、決策樹和隨機森林算法對于宇宙線粒子成分分析的高效率,還未使用其他算法對宇宙線粒子成分進行分析,而且訓練和模擬所用參數過于理想化,因此,下一步研究工作中將加入更接近實驗中實際探測的觀測量,進一步優化機器學習算法,提升粒子鑒別能力,并將繼續深入探索其他機器學習算法在宇宙線粒子鑒別中的應用.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
