基于粒子群算法的科技創新數據檢索系統設計
2023-07-25 09:55:20馬芳平李林郭金婷柳玉蘭徐鐳夢
電子設計工程 2023年15期
馬芳平,李林,郭金婷,柳玉蘭,徐鐳夢
(國能大渡河流域水電開發有限公司,四川成都 610095)
隨著信息化社會的進步,數字文獻信息資源的管理和檢索方法有了很大的改進,但在檢索時會出現數據檢索不安全、數據檢索效率低的問題,導致數據資源共享出現了嚴重的“數據孤島”情況。因此,建立一套完整的科技創新數據檢索體系是十分必要的。有研究人員提出深度學習驅動的跨模態數據檢索方法,建立了基于深度學習的多模式信息檢索模型,在該模型上,結合深度學習的強大學習與表達能力,采用多標記相似度測量與建模訓練技術,實現科技創新數據的檢索[1];還有研究人員提出基于哈希算法的異構多模態數據檢索研究方法,通過對圖像和文字的語義建模,以保證在模式中的語義一致性。采用CCA 算法融合文字與圖像的語義,產生最大關聯矩陣,實現對科技創新數據的檢索[2]。然而,上述方法受到原始數據集冗余信息和噪聲影響,導致檢索結果不精準。為此,提出了基于粒子群算法的科技創新數據檢索系統設計。
1 系統硬件結構設計
基于粒子群算法的科技創新數據檢索系統硬件結構如圖1 所示。
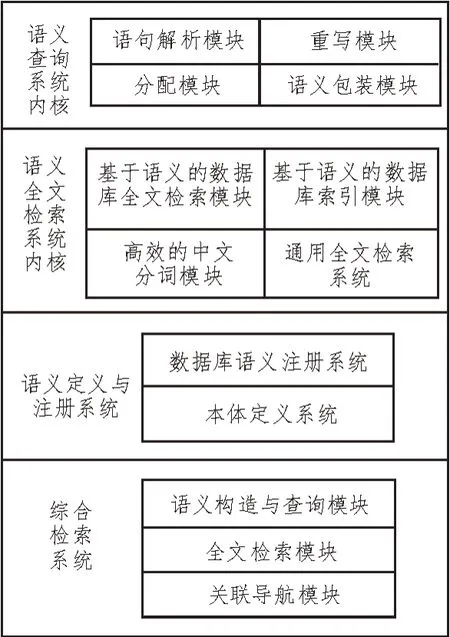
圖1 系統硬件結構
由圖1 可知,該系統硬件結構是由四個部分組成的,分別是語義查詢系統內核、語義全文檢索系統內核、語義定義與注冊系統、綜合檢索系統。基于本體論的語義搜索可以準確地對數據進行搜索,而基于語義的全文搜索系統則可以為整個搜索庫提供一個具體的關鍵詞[3]。該結構建立在一個統一的全文檢索系統之上,包括索引、中文分詞、搜索模式等。以粒子群算法為基礎的綜合檢索系統,也能給使用者提供一個較為便捷的查詢和展示界面[4]。
1.1 檢索引擎
在檢索服務器方面,按照所建立的索引庫及整個系統的特征進行檢索,并給出了相應的邏輯結構,如圖2 所示。
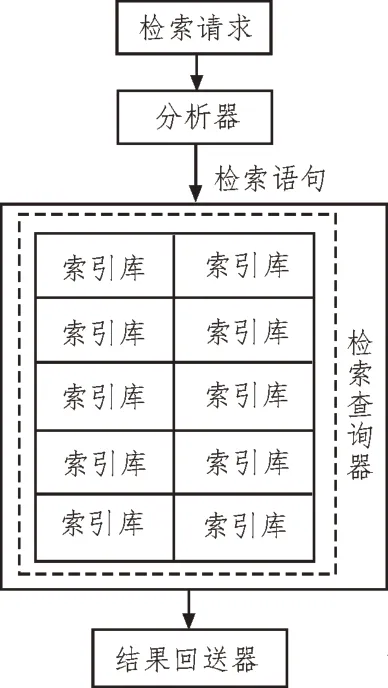
圖2 檢索引擎
在解析過程中,根據代理服務器的查詢請求,對查詢請求進行分詞處理,得到一系列關鍵字,然后根據這些關鍵字之間的邏輯關系,得到一條查詢語句[5];采用哈希方法,將索引庫中的索引關鍵詞指派到各自的檢索查詢器中,根據搜索語句的關鍵詞,在索引庫中進行檢索,產生對應的文檔鏈接,再根據關鍵詞之間的邏輯聯系,將相關結果和查詢的相關性一同傳送至最后的循環[6]。
1.2 檢索數據存儲模塊
檢索數據存儲模塊通過預定義的協作策略,實現系統各功能模塊的調用,并進行數據交互,實現協同工作[7]。該模塊所用的工具是一個動態的數據存儲模塊,其結構如圖3 所示。
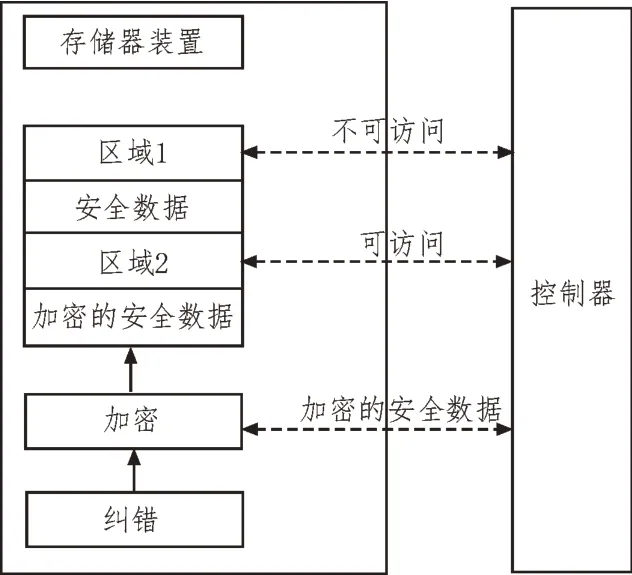
圖3 檢索數據存儲模塊
檢索數據存儲模塊是可移動的,外部硬盤的引進使儲存于存儲器裝置中的主機裝置變得更小巧、更便于攜帶。該存儲器裝置有兩個存儲區域,其中區域1 用來記憶儲存資料,外部裝置不可訪問該區域;區域2 用來儲存已加密的安全數據的,外部裝置可訪問該區域,并且加密的安全數據是區域1 中數據的加密版本[8-10]。
1.3 關聯導航模塊
關聯導航模塊如圖4 所示。
圖4 關聯導航模塊
在相關聯導航模塊中有3~5 個關鍵詞和一個長的單詞,通過首頁、內頁的宣傳鏈接來判定這些詞是否為熱門詞匯[11]。如果導航中的導航模塊以長字開頭,重點突出,且在關鍵詞排行榜中有更多的內頁,那么網站的排名將會更好,百度主頁的速度也會更快,快速提升了科技創新數據檢索速度[12]。
2 系統軟件部分設計
2.1 基于粒子群算法的數據分詞處理
由于詞串是在通道中傳送的,通道中存在噪聲干擾,使詞串失去了邊界標志變為漢字串。為此,提出了基于粒子群算法的數據分詞研究。數據分詞流程如圖5 所示。
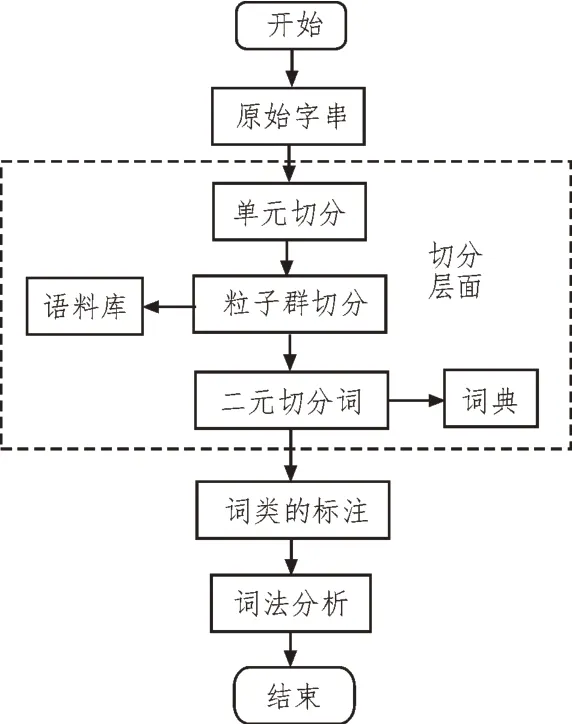
圖5 基于粒子群算法的數據分詞流程
在詞典的基礎上,找到所有可能出現的詞,并構造一個有向無回圈的分詞[13]。每一字與圖表中的一條有向邊對應,并將其分配到相應的長度(權重)。在此基礎上,采用粒子群算法計算從起始到結束的最短路徑,并將其輸出作為分詞的結果[14]。
粒子群求解過程為:設粒子群算法的種群規模為m,連續演化的時間為t,該時間段內的活動量可表示為:
式中,η(t,ai)表示粒子ai在連續演化的時間內的適應值。
如果粒子在連續演化時間內被選擇參加飛行,則新的自適應分詞表達式為:
式中,?表示可調參數。
當粒子活動量較小時,新的自適應分詞值較小,在隨后的時間里,優先參加飛行,這會強迫系統的熵值增大[15]。群體中的弱小粒子具有更大的可供選擇的可能性,使得求解空間中的探索區域和最佳粒子的駐留時間大大增加,改善算法的局部搜索性能,同時也避免了大規模的粒子聚集,保證了群體的多樣性。該方法將待優化的各向異性作為最優參數,并對其進行了速度、位置的修正,使其在最優解空間內進行最優解計算。
2.2 檢索流程設計
綜合上述基于粒子群算法的數據分詞處理過程,設計的檢索流程如下所示:
步驟一:以各個粒子的位置矢量為控制參量,求出各個粒子的適配值,隨機地對粒子的動態和行為進行初始化,決定最大可容許的重復次數,并將鏈接指向網頁[16]。通過優化二元函數,尋找最優粒子并對其編碼,評估鏈接最終價值。按照鏈接價值依次排序鏈接,并將相應的地址存入待搜索隊列之中,由此確定粒子的最優位置。
步驟二:利用數據分詞處理結果完成了對系統中的所有技術創新資料的分詞,并在后臺進行;
步驟三:當用戶輸入待檢索的關鍵詞后,由數據分詞處理步驟分詞處理關鍵詞,由此產生對應的分詞矢量;
步驟四:確定各個粒子的全局最優位置,并對文檔特征矢量表中的全部記錄進行了相關分析;
步驟五:根據相關程度進行分類,最終回歸到相應的用戶文件集中,實現了數據的檢索。
3 實 驗
3.1 科技創新數據源導入
由于技術創新的數據來源是外部資料,因此在進行研究時必須將數據來源的基本參數引入其中。圖6 中顯示了科技創新數據源的輸入過程。
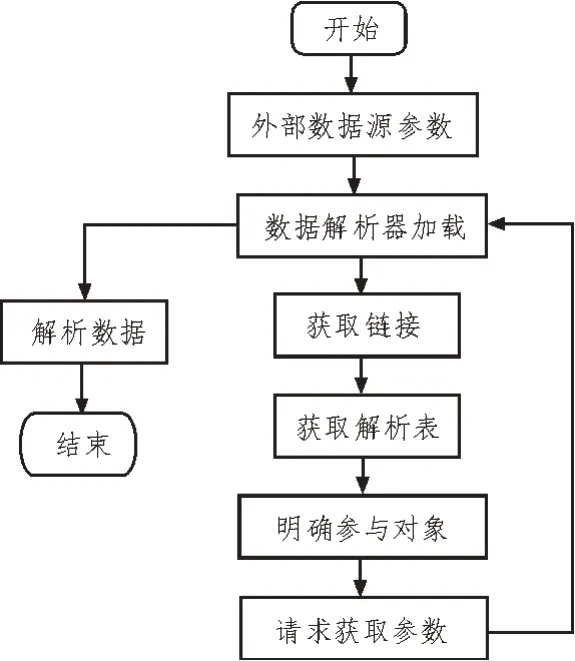
圖6 科技創新數據源導入實現流程
由圖6 可知,在該設計模式下,使用者將數據來源的參數信息填入到視圖層次,并以URL 的形式傳送至模型層。通過調用Controller 功能來獲得URL,將分析結果作為返回的數值傳遞到模型層中。模型層根據返回值的判別結果,通過適當的加載量對數據進行分析。
3.2 評價標準
采用的評價標準是數據檢索中的經典指標,即查準率和查全率,其公式分別為:
3.3 實驗結果與分析
基于評價標準,分別使用深度學習驅動的跨模態數據檢索、基于哈希算法的異構多模態數據檢索和基于粒子群算法的檢索系統,對比分析檢索查準率和查全率,如圖7 所示。
由圖7 可知,使用深度學習驅動的檢索方法查準率最高為77%,查全率最高為70%;使用基于哈希算法的數據檢索方法,查準率最高為80%,查全率最高為77%;使用基于粒子群算法的檢索系統,檢索查準率和查全率均較高,其中查準率最高為96%,查全率最高為97%,均高于另兩種方法。這是由于文中設計的檢索系統,通過基于粒子群算法的數據分詞處理步驟,能夠改善數據干擾問題,提高查準率和查全率。
4 結束語
設計的基于粒子群算法的科技創新數據檢索系統,通過粒子群算法對分詞進行實時加權,通過在線調整,使系統具有自適應性,使得檢索結果更加精準。經過對上述系統的分析,該系統真正地突破了以往的技術創新數據的限制,實現了對中心數據庫數據的快速更新。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
開放教育研究(2020年2期)2020-03-31 01:54:14
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
