一種新的半監(jiān)督歸納遷移學(xué)習(xí)框架:Co-Transfer
2023-07-20 11:21:34文益民
計算機研究與發(fā)展 2023年7期
文益民 員 喆 余 航
1 (桂林電子科技大學(xué)計算機與信息安全學(xué)院 廣西 桂林 541004)
2 (廣西圖像圖形與智能處理重點實驗室(桂林電子科技大學(xué))廣西 桂林 541004)
3 (上海大學(xué)計算機工程與科學(xué)學(xué)院 上海 200444)
遷移學(xué)習(xí)已被廣泛應(yīng)用于將知識從源域遷移到相關(guān)的目標(biāo)域的任務(wù)[1-2].根據(jù)Pan 等人[1]的工作,遷移學(xué)習(xí)可分為3 類:歸納遷移學(xué)習(xí)、直推式遷移學(xué)習(xí)和無監(jiān)督遷移學(xué)習(xí).有著與前面這3 種遷移學(xué)習(xí)不同的設(shè)置,一種名為“半監(jiān)督遷移學(xué)習(xí)”的研究開始被學(xué)術(shù)界關(guān)注[3-6],它被用于解決許多實際應(yīng)用問題,其學(xué)習(xí)范式一般是目標(biāo)域中僅有少量樣本被標(biāo)記,而源域中的所有樣本都被標(biāo)記或者是源域中有一個預(yù)訓(xùn)練模型.但是,與這種“半監(jiān)督遷移學(xué)習(xí)”不一樣,在許多實際應(yīng)用中,源域和目標(biāo)域中包含標(biāo)記和未標(biāo)記樣本的情形則非常常見.例如,在計算機輔助診斷(computer-aided diagnosis,CAD)系統(tǒng)[7]應(yīng)用中,由于標(biāo)注大量的醫(yī)學(xué)圖像非常耗時且成本昂貴,醫(yī)學(xué)專家僅能夠仔細(xì)診斷標(biāo)注少量圖像.由于設(shè)備的老化或升級,先前采集的醫(yī)學(xué)圖像很可能與當(dāng)前采集的醫(yī)學(xué)圖像的分布不再相同[8-9].也就是說,在2 個不同時間間隔內(nèi)采集的數(shù)據(jù)分布不相同.因此,接下來的挑戰(zhàn)是如何從源域中的標(biāo)記和未標(biāo)記樣本有效地學(xué)習(xí),以實現(xiàn)對目標(biāo)域中樣本的更準(zhǔn)確分類?
半監(jiān)督多任務(wù)學(xué)習(xí)可用于處理上述問題.文獻[10]通過Dirichlet 過程的變體在多個分類器參數(shù)上使用軟共享先驗來耦合幾個參數(shù)化的半監(jiān)督分類器.文獻[11]在高斯過程的協(xié)方差中結(jié)合了數(shù)據(jù)的幾何形狀和任務(wù)之間的相似性.文獻[12-14]使用深度學(xué)習(xí)提取多個半監(jiān)督任務(wù)之間共享的特征表示.然而,文獻[10-14]所述的這些方法都需要依賴特定類型的分類器.
為應(yīng)對上述挑戰(zhàn),本文提出一種新的半監(jiān)督歸納遷移學(xué)習(xí)框架,稱為Co-Transfer,它將半監(jiān)督學(xué)習(xí)[15-16]與歸納遷移學(xué)習(xí)相結(jié)合.Co-Transfer 首先生成3 個TrAdaBoost[17]分類器,用于將知識從原始源域遷移到原始目標(biāo)域,同時生成另外3 個TrAdaBoost 分類器,用于將知識從原始目標(biāo)域遷移到原始源域.這2 組分類器都使用從原始源域和原始目標(biāo)域的原有標(biāo)記樣本的有放回抽樣來訓(xùn)練.在Co-Transfer 的每一輪迭代中,每組TrAdaBoost 分類器使用新的訓(xùn)練集更新,其中一部分訓(xùn)練集是原有的標(biāo)記樣本,一部分是本組TrAdaBoost 分類器標(biāo)記的樣本,另一部分則由另一組TrAdaBoost 分類器標(biāo)記.值得強調(diào)的是,本文使用Tri-training[18]方式來挑選可靠的偽標(biāo)記樣本.迭代終止后,將從原始源域遷移到原始目標(biāo)域的3 個TrAdaBoost 分類器集成作為原始目標(biāo)域的分類器.在4 個UCI 數(shù)據(jù)集[19]和文本分類數(shù)據(jù)集[17]上的實驗結(jié)果表明,Co-Transfer 可以有效地學(xué)習(xí)標(biāo)記和未標(biāo)記樣本提升泛化性能.
本文的主要貢獻體現(xiàn)在2 點:
1)提出一種源域和目標(biāo)域都只有部分樣本被標(biāo)記的半監(jiān)督歸納遷移學(xué)習(xí)類型.這種學(xué)習(xí)類型在實際應(yīng)用中其實很常見.
2)提出一種新的半監(jiān)督歸納遷移學(xué)習(xí)框架Co-Transfer.該學(xué)習(xí)框架在源域和目標(biāo)域之間進行雙向同步的半監(jiān)督學(xué)習(xí)和遷移學(xué)習(xí),它能很好地適用于源域和目標(biāo)域都僅有部分樣本被標(biāo)記的遷移學(xué)習(xí)且不需要特定類型的分類器.
1 相關(guān)工作
本節(jié)簡要回顧半監(jiān)督學(xué)習(xí)、基于實例的遷移學(xué)習(xí)、半監(jiān)督遷移學(xué)習(xí)以及半監(jiān)督多任務(wù)學(xué)習(xí)等相關(guān)工作.
1.1 半監(jiān)督學(xué)習(xí)
半監(jiān)督學(xué)習(xí)[15]的主要思想是學(xué)習(xí)少量標(biāo)記樣本和大量未標(biāo)記樣本以提高模型泛化能力.半監(jiān)督學(xué)習(xí)假設(shè)未標(biāo)記樣本與標(biāo)記樣本具有相同分布.已有的半監(jiān)督學(xué)習(xí)方法主要分為四大類:生成式模型[20]、包裝方法[18,21]、低密度分離模型[22]以及基于圖的方法[23]等.其中,包裝方法是一類簡單且受歡迎的方法,它首先在原有標(biāo)記樣本上訓(xùn)練分類器,然后利用訓(xùn)練好的分類器來預(yù)測未標(biāo)記樣本的類別,使用置信的偽標(biāo)記樣本與原有標(biāo)記樣本一起重新訓(xùn)練分類器.
Blum 等人[24]提出了Co-training 算法,它需要數(shù)據(jù)有2 個充分且冗余的視圖.Co-training 分別在2 個不同的視圖上訓(xùn)練2 個分類器,并且使用每個分類器置信的偽標(biāo)記樣本來增強另一個分類器.Dasgupta等人[25]證明了當(dāng)數(shù)據(jù)具有2 個充分且冗余的視圖時,Co-training 訓(xùn)練的分類器可以通過最大化不同組件分類器對未標(biāo)記樣本的一致性來降低分類錯誤率.在實際應(yīng)用場景中,由于數(shù)據(jù)很難滿足這一要求,Zhou 等人[18]提出Tri-training 算法,該算法不再要求訓(xùn)練數(shù)據(jù)有2 個充分且冗余的視圖.Tri-training 采用“多數(shù)教少數(shù)”的方法來避免對分類置信度的估計.Li 等人[21]提出Co-forest 算法將Tri-training 擴展到可使用更多的組件分類器.在Tri-training 和Co-forest 中,使用模糊集理論來確保新的偽標(biāo)記樣本能起到積極效果.Van Engelen 等人[15]綜述了一些其他包裝方法,如Self-training 與Boosting 系列.此外,Triguero 等人[26]提供了一個關(guān)于半監(jiān)督分類中自標(biāo)記技術(shù)的全面綜述.
1.2 基于實例的遷移學(xué)習(xí)
基于實例的遷移學(xué)習(xí)方法其直觀思想是將源域中部分樣本與目標(biāo)域樣本一起訓(xùn)練得到一個更高準(zhǔn)確率的分類器.
Dai 等人[17]通過擴展AdaBoost 提出TrAdaBoost遷移學(xué)習(xí)算法.TrAdaBoost 迭代地重新加權(quán)源域和目標(biāo)域樣本以減少“壞”的源域樣本的權(quán)值,同時增大“好”的目標(biāo)域樣本的權(quán)值.此外,Dai 等人[17]還從理論上分析了TrAdaBoost 的可收斂性.Kamishima 等人[27]通過擴展bagging 提出TrBagg 方法.TrBagg 訓(xùn)練過程包括2 個階段:學(xué)習(xí)和過濾.在學(xué)習(xí)階段,使用源域和目標(biāo)域的抽樣樣本來訓(xùn)練弱分類器;在過濾階段,使用目標(biāo)域樣本來評估這些弱分類器.分類精度低的弱分類器會被丟棄,而分類精度高的弱分類器會被選擇來產(chǎn)生最終分類器.Shi 等人[28]通過擴展Cotraining 算法提出COITL 算法.COITL 算法的關(guān)鍵思想是通過將Co-training 算法中給樣本打偽標(biāo)記的操作替換為對源域樣本進行加權(quán)來擴充訓(xùn)練樣本集.在算法COITL 中,首先使用目標(biāo)域樣本訓(xùn)練2 個組件分類器,然后每個分類器使用另一個分類器加權(quán)的源域樣本進行增強.
1.3 半監(jiān)督遷移學(xué)習(xí)
目前半監(jiān)督遷移學(xué)習(xí)的工作還非常有限,與本文要解決的問題不同,已有的半監(jiān)督遷移學(xué)習(xí)旨在解決源域是監(jiān)督設(shè)置但目標(biāo)域是半監(jiān)督設(shè)置的問題.根據(jù)源域形式的不同,主要分為2 類:源域樣本直接可用或源域樣本不可用但源域上的預(yù)訓(xùn)練模型可用.
Liu 等人[3]提出一種基于Tri-training 的半監(jiān)督遷移學(xué)習(xí)方法TriTransfer.在TriTransfer 中,使用從源域抽樣的樣本與目標(biāo)域的標(biāo)記樣本一起訓(xùn)練3 個組件分類器,然后使用“多數(shù)教少數(shù)”的策略來重新訓(xùn)練這3 個組件分類器,最后加權(quán)集成這3 個組件分類器來產(chǎn)生最終分類器.
Tang 等人[4]提出一種半監(jiān)督遷移方法以解決漢字識別問題.首先,使用大量源域樣本來訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò);然后使用目標(biāo)域中少量的標(biāo)記樣本對卷積神經(jīng)網(wǎng)絡(luò)模型微調(diào);最后使用目標(biāo)域中大量的未標(biāo)記樣本和少量的標(biāo)記樣本對微調(diào)后的卷積神經(jīng)網(wǎng)絡(luò)繼續(xù)訓(xùn)練以最小化多核最大均值差異(multiple kernel maximum mean discrepancy,MK-MMD)損失.
Abuduweili 等人[5]提出一種半監(jiān)督遷移學(xué)習(xí)算法,它可以有效地利用源域的預(yù)訓(xùn)練模型以及目標(biāo)域中的標(biāo)記和未標(biāo)記樣本.在所提出的算法中利用自適應(yīng)一致性正則化方法來將預(yù)訓(xùn)練模型與目標(biāo)域的標(biāo)記和未標(biāo)記樣本結(jié)合在一起訓(xùn)練.自適應(yīng)一致性正則化包括2 個含義:源模型和目標(biāo)模型之間的自適應(yīng)一致性;有標(biāo)記和無標(biāo)記樣本之間的自適應(yīng)一致性.
Wei 等人[6]提出一種用于圖像去雨的半監(jiān)督遷移網(wǎng)絡(luò).該網(wǎng)絡(luò)經(jīng)過合成的帶雨圖像樣本訓(xùn)練后可以遷移于真實且不同類型的帶雨圖像,解決了目標(biāo)域缺少訓(xùn)練樣本及真實圖像與合成圖像間分布差異的問題.
1.4 半監(jiān)督多任務(wù)學(xué)習(xí)
半監(jiān)督多任務(wù)學(xué)習(xí)旨在有效挖掘任務(wù)之間的相關(guān)性并探索每個任務(wù)中未標(biāo)記樣本的有用信息.Liu等人[10]基于Dirichlet 過程的變體使用任務(wù)聚簇方法對不同任務(wù)進行聚類,且在每個任務(wù)中,使用隨機游走過程來探索未標(biāo)記樣本中的有用知識.Skolidis 等人[11]使用共區(qū)域化的內(nèi)在模型在高斯過程的框架下編碼任務(wù)之間的相關(guān)性.此外,半監(jiān)督多任務(wù)學(xué)習(xí)與深度學(xué)習(xí)被結(jié)合用于解決實際任務(wù),如疾病演化[12]、藥物間相互作用[13]、語義解析[14]和文本挖掘等[29].
2 Co-Transfer
在本文中,為了形式化定義所提出的半監(jiān)督遷移學(xué)習(xí)框架,我們引入一些符號.
本文假設(shè)源域DS和目標(biāo)域DT具有相同的特征空間但分布不同.X表示特征空間,Y∈{0,1}表示類別空間.DS和DT均包含標(biāo)記和未標(biāo)記樣本.定義DSL=和DTL=分別表示源域和目標(biāo)域中的標(biāo)記樣本,其中∈X是源域中的一個實例,∈Y是對應(yīng)的類別標(biāo)記,而∈X則是目標(biāo)域中的一個實例,∈Y是對應(yīng){的類別標(biāo)記.定義DSU=和DTU=,分別表示源域和目標(biāo)域中的未標(biāo)記樣本.此外,還存在測試數(shù)據(jù)集DTest=可用,它與目標(biāo)域分布相同.通常,未標(biāo)記樣本的數(shù)量要遠大于標(biāo)記樣本的數(shù)量,設(shè)置m?l和n?p.所提出的半監(jiān)督歸納遷移學(xué)習(xí)的目標(biāo)是利用L=[DSL,DTL]和U=[DSU,DTU]在目標(biāo)域上學(xué)習(xí)一個函數(shù)f:X→Y,使得f能正確預(yù)測DTest中樣本的類別標(biāo)記.為簡潔起見,本文使用L[0]和L[1]分別表示DSL和DTL,使用U[0]和U[1]分別表示DSU和DTU.
在Co-Transfer 中,需訓(xùn)練2 個集成分類器H0=和H1=.初始時,H0中的每個組件分類器使用目標(biāo)域與源域的原有標(biāo)記樣本的有放回抽樣來訓(xùn)練,采用TrAdaBoost 算法實現(xiàn)從目標(biāo)域到源域的遷移學(xué)習(xí).相對應(yīng)地,H1中的每個組件分類器也使用源域與目標(biāo)域的原有標(biāo)記樣本的有放回抽樣來訓(xùn)練,采用TrAdaBoost 算法實現(xiàn)從源域到目標(biāo)域的遷移學(xué)習(xí).抽樣策略能保持H0和H1各自的組件分類器之間的多樣性.像這樣的源域和目標(biāo)域之間的雙向同步遷移學(xué)習(xí)會迭代很多輪,在每一輪中使用各自新增的偽標(biāo)記樣本分別對H0和H1中每個組件分類器進行更新.由于Co-Transfer 在源域和目標(biāo)域之間實施雙向同步遷移學(xué)習(xí),本文將原本的源域和目標(biāo)域分別稱為原始源域和原始目標(biāo)域.在從原始源域到原始目標(biāo)域的遷移學(xué)習(xí)中,原始源域仍然是源域,原始目標(biāo)域仍然是目標(biāo)域;而在從原始目標(biāo)域到原始源域的遷移學(xué)習(xí)中,原始目標(biāo)域被當(dāng)成源域,原始源域則被當(dāng)成目標(biāo)域.
算法1.Co-Transfer 算法.
更詳細(xì)地,在Co-Transfer 的每一輪雙向同步遷移學(xué)習(xí)中,將集成分類器Hd(d∈{0,1},d=0對應(yīng)原始源域,而d=1對應(yīng)原始目標(biāo)域)的組件分類器(i∈{1,2,3})作為初始分類器,使用Tri-training 方式從U[d]中選擇樣本打上標(biāo)記.具體做法是:若其他2 個組件分類器(j≠k≠i)對未標(biāo)記樣本給出的類別標(biāo)記相同,則該未標(biāo)記樣本才會被標(biāo)記,將該偽標(biāo)記樣本添加到數(shù)據(jù)集(i∈{1,2,3}).另外,若集成分類器Hd(d∈{0,1})中的3 個組件分類器對未標(biāo)記樣本都給出了相同標(biāo)記,則該未標(biāo)記樣本會被選中作為偽標(biāo)記樣本而添加到數(shù)據(jù)集Ld.然后,將Ld與原始標(biāo)記樣本L[d]合并作為新的源域數(shù)據(jù),再將(i∈{1,2,3})分別與L[(d+1)%2]合并作為新的目標(biāo)域數(shù)據(jù).最后,利用TrAdaBoost 算法進行訓(xùn)練,以實現(xiàn)從源域到目標(biāo)域的遷移學(xué)習(xí),而得到由新的組件分類器(i∈{1,2,3})構(gòu)成的集成分類器H(d+1)%2.值得注意的是:由Hd和Hid選擇的所有未標(biāo)記樣本都不會從U[d]中刪除.因此,它們可能會在接下來的迭代中被再次選中.d=0和d=1所對應(yīng)的2 個遷移學(xué)習(xí)過程被同步執(zhí)行.當(dāng)Hd(d∈{0,1})中的每個組件分類器都不再被重新訓(xùn)練時,迭代結(jié)束,將最終得到的H1作為原始目標(biāo)域上的分類器.
第1 種情況是如何選擇U[d]中未標(biāo)記樣本作為目標(biāo)域樣本以重新訓(xùn)練(i∈{1,2,3}).令和表示在第t輪和第t-1 輪迭代中使用Tri-training 方式從U[d]中選擇可打標(biāo)記的樣本,大小分別為和和分別表示在第t輪和第t-1 輪迭代中的分類錯誤率的上界.因此,根據(jù)Zhou等人[18]提出的理論,需滿足約束:
第2 種情況是如何選擇U[(d+1)%2]中未標(biāo)記的樣本作為源域樣本以重新訓(xùn)練(i∈{1,2,3}).令Ld,t和Ld,t-1分別表示在第t輪和第t-1輪迭代中從U[d]中選擇可打標(biāo)記的樣本,其大小分別為和ed,t和ed,t-1分別表示Hd在第t輪迭代和第t-1 輪迭代中的分類錯誤率的上界.因此,同樣根據(jù)Zhou 等人[18]提出的理論,需滿足約束:
第2 種情況引入的約束使得標(biāo)記更可靠的偽標(biāo)記樣本加入源域,使源域數(shù)據(jù)分布更接近真實數(shù)據(jù)分布,進而導(dǎo)致更可靠的偽標(biāo)記樣本添加到目標(biāo)域中,這對于Co-Transfer 中的迭代過程非常重要.
采用決策樹作為組件分類器的Co-Transfer 算法偽代碼在算法1 中給出,其中參數(shù)N為TrAdaBoost的迭代次數(shù).行⑤~⑦表示分別從L[(d+1)%2]和L[d]通過函數(shù)Bootstrap抽樣而得到和.將和分別作為源域和目標(biāo)域數(shù)據(jù),用TrAdaBoost學(xué)習(xí)得到初始的集成分類器.在行?中,函數(shù)MeasureEnsemble-Error用于估計集成分類器Hd的分類錯誤率.在行?中,函數(shù)MeasureClassifierError則用于估計=的分類錯誤率.這2 個錯誤率都是在原有標(biāo)記數(shù)據(jù)集L[d]上估計的.詳細(xì)來說,估算Hd的錯誤率是通過將Hd的3 個組件分類器(i∈{1,2,3})預(yù)測一致但分錯的標(biāo)記樣本數(shù)與預(yù)測一致的標(biāo)記樣本數(shù)之比來近似得到.類似地,的錯誤率是通過將預(yù)測一致但被分錯的標(biāo)記樣本數(shù)與預(yù)測一致的標(biāo)記樣本數(shù)之比來近似估算.在行?中,函數(shù)PseudoLabel是從U[d]中選擇和給出相同標(biāo)記的樣本打上偽標(biāo)記.在行?中,函數(shù)S creenPseudoLabel是從中選擇出偽標(biāo)記相同的樣本.函數(shù)S ubsample(S,t)從S中隨機刪除t個樣本.行使用新的源域數(shù)據(jù)和目標(biāo)域數(shù)據(jù)來重新訓(xùn)練Hd的每個組件分類器.圖1 中的數(shù)據(jù)流圖描述了Co-Transfer 的訓(xùn)練過程.

Fig.1 Data flow diagram of Co-Transfer training process圖1 Co-Transfer 訓(xùn)練過程的數(shù)據(jù)流圖
3 實 驗
3.1 數(shù)據(jù)集
本文使用遷移學(xué)習(xí)研究[17,28]中常用的4 個UCI數(shù)據(jù)集和文本分類數(shù)據(jù)集Reuters 進行實驗.這些數(shù)據(jù)集都已被證明原始源域能有效地助力原始目標(biāo)域的學(xué)習(xí).表1 羅列了這些數(shù)據(jù)集的詳細(xì)信息.
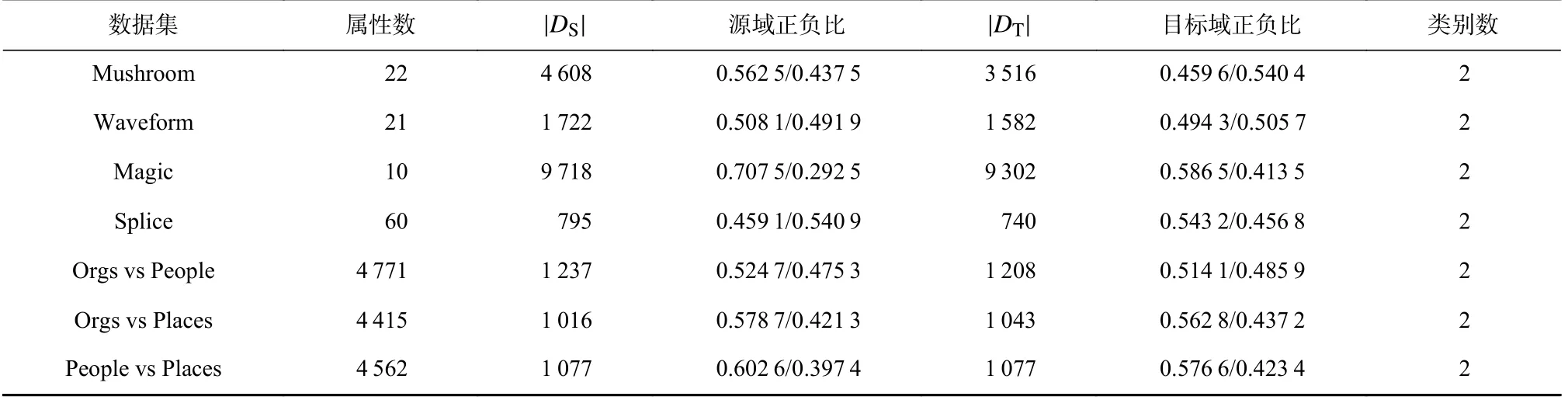
Table 1 Experimental Data Sets表1 實驗數(shù)據(jù)集
3.2 實驗設(shè)置
對于表1 中每個數(shù)據(jù)集的目標(biāo)域數(shù)據(jù)使用5 折交叉驗證進行分類錯誤率評價.在每折交叉驗證中,將目標(biāo)域中的樣本劃分為目標(biāo)域訓(xùn)練數(shù)據(jù)集DT和測試數(shù)據(jù)集DTest,而將源域中的全部樣本當(dāng)作訓(xùn)練數(shù)據(jù)集DS.再根據(jù)預(yù)設(shè)的有標(biāo)記樣本比,隨機從源域訓(xùn)練數(shù)據(jù)集DS和目標(biāo)域訓(xùn)練數(shù)據(jù)集DT中挑選樣本構(gòu)成標(biāo)記樣本集DSL和DTL,剩余的樣本構(gòu)成未標(biāo)記樣本集DSU和DTU.為增加樣本標(biāo)記的隨機性,在每折交叉驗證中,重復(fù)2 次對源域訓(xùn)練數(shù)據(jù)集DS隨機劃分為DSL和DSU,重復(fù)3 次對目標(biāo)域訓(xùn)練數(shù)據(jù)集DT隨機劃分為DTL和DTU.因此,最終的錯誤率是30(5× 6)次測試結(jié)果的平均值.
為評測與分析Co-Transfer 是否可以有效學(xué)習(xí)源域和目標(biāo)域中的標(biāo)記樣本與未標(biāo)記樣本,引入7 個算法進行對比,包括決策樹(decision tree, DT)、TrAda-Boost、Tri-training、TrAdaBoostA、Co-TransferS、TrAda-BoostS、Co-TransferT.
對于應(yīng)用型本科院校而言,教師專業(yè)化就是指根據(jù)社會對應(yīng)用型人才的需求,教師遵循應(yīng)用型特征的教育教學(xué)規(guī)律,特別注重專業(yè)實踐能力。教師專業(yè)化發(fā)展強調(diào)教師的終身學(xué)習(xí)和終身成長,包括職前培養(yǎng)、新任教師培養(yǎng)和在職培訓(xùn),在教師的整個專業(yè)生涯中,通過學(xué)習(xí)和專業(yè)訓(xùn)練,提高專業(yè)素養(yǎng)、專業(yè)實踐能力和個人職業(yè)道德等,促進教師從新手到熟手,從熟手到專家。
算法DT 表示僅在DTL上訓(xùn)練決策樹對測試數(shù)據(jù)進行分類;算法TrAdaBoost 表示在DSL和DTL上使用TrAdaBoost 方法訓(xùn)練分類器對測試數(shù)據(jù)進行分類;算法Tri-training 表示在DTL和DTU上使用Tri-training方法訓(xùn)練分類器對測試數(shù)據(jù)進行分類;算法TrAdaBoostA表示在將DS和DT中的全部樣本打上標(biāo)記再使用TrAdaBoost 方法訓(xùn)練分類器對測試數(shù)據(jù)進行分類;算法Co-TransferS表示采用Co-Transfer 的框架進行學(xué)習(xí),但在迭代過程中目標(biāo)域的樣本只使用DTL,也就是說在雙向迭代過程中不會在DTL的基礎(chǔ)上再增加偽標(biāo)記樣本;算法TrAdaBoostS表示將DS中的全部樣本打上標(biāo)記和DTL使用TrAdaBoost 方法訓(xùn)練分類器對測試數(shù)據(jù)進行分類;算法Co-TransferT則表示采用Co-Transfer 的框架進行學(xué)習(xí),但在迭代過程中源域樣本只使用DSL,也就是說在雙向迭代過程中不會在DSL的基礎(chǔ)上再增加偽標(biāo)記樣本.表2 列出了Co-Transfer 和各對比算法的樣本使用策略.

Table 2 Data Strategy Used by the Algorithms表2 各算法的數(shù)據(jù)使用策略
由表2 可知:當(dāng)原始源域到原始目標(biāo)域能實現(xiàn)正遷移時,DT 的分類錯誤率應(yīng)該最高,TrAdaBoostA的分類錯誤率則應(yīng)該最低.與Co-Transfer 相比較,Co-TransferS不使用DTU,而 Co-TransferT不使用DSU.TrAdaBoost 則既不使用DSU,也不使用DTU.因此,將Co-Transfer 分別與 TrAdaBoost,Co-TransferS,Co-TransferT相比較,可觀察Co-Transfer 是否可以有效地從原始源域和原始目標(biāo)域的未標(biāo)記樣本中學(xué)習(xí).與TrAdaBoost 相比,TrAdaBoostS多用了DSU,因此,將TrAdaBoostS與TrAdaBoost 對比可知利用DSU能否輔助原始目標(biāo)域?qū)W習(xí)得更好.
本文使用標(biāo)準(zhǔn)t 統(tǒng)計檢驗檢查Co-Transfer 和每個對比算法的泛化能力的區(qū)別是否具有95%置信度的顯著性.
各算法的參數(shù)設(shè)置:對于Tri-training,使用C4.5決策樹作為組件分類器并且不做剪枝處理;而對于TrAdaBoost,TrAdaBoostA,Co-TransferS,TrAdaBoostS,Co-TransferT,Co-Transfer,使用相同的參數(shù),即對于數(shù)據(jù)集Mushroom 設(shè)置迭代次數(shù)N=10,樹的深度D=10;對于數(shù)據(jù)集Waveform 設(shè)置N=65,D=4;對于數(shù)據(jù)集Magic 設(shè)置N=35,D=20;對于數(shù)據(jù)集Splice 設(shè)置N=15,D=50;對于數(shù)據(jù)集Orgs vs People 設(shè)置N=50,D=5;對于數(shù)據(jù)集Orgs vs Places 設(shè)置N=20,D=4;對于數(shù)據(jù)集People vs Places 設(shè)置N=50,D=3.
3.3 實驗結(jié)果和分析
表3~6 顯示,當(dāng)原始源域和原始目標(biāo)域的標(biāo)記比率相同時,不同標(biāo)記比率下Co-Transfer 和所有對比算法在原始目標(biāo)域測試集上的分類錯誤率.從表3~6可以觀察到:在各種標(biāo)記比率條件下,DT 的分類錯誤率最高.當(dāng)標(biāo)記比率為10%和20%時,TrAdaBoostA顯然要比Co-Transfer 的泛化能力強;而當(dāng)標(biāo)記比率為40%和50%時,TrAdaBoostA與Co-Transfer 的泛化能力則變得相當(dāng);在各種標(biāo)記比率條件下,Co-Transfer 的泛化能力比TrAdaBoost,Tri-training,Co-TransferS的泛化能力都要好,這說明Co-Transfer 能有效利用源域的標(biāo)記樣本和目標(biāo)域的未標(biāo)記樣本.
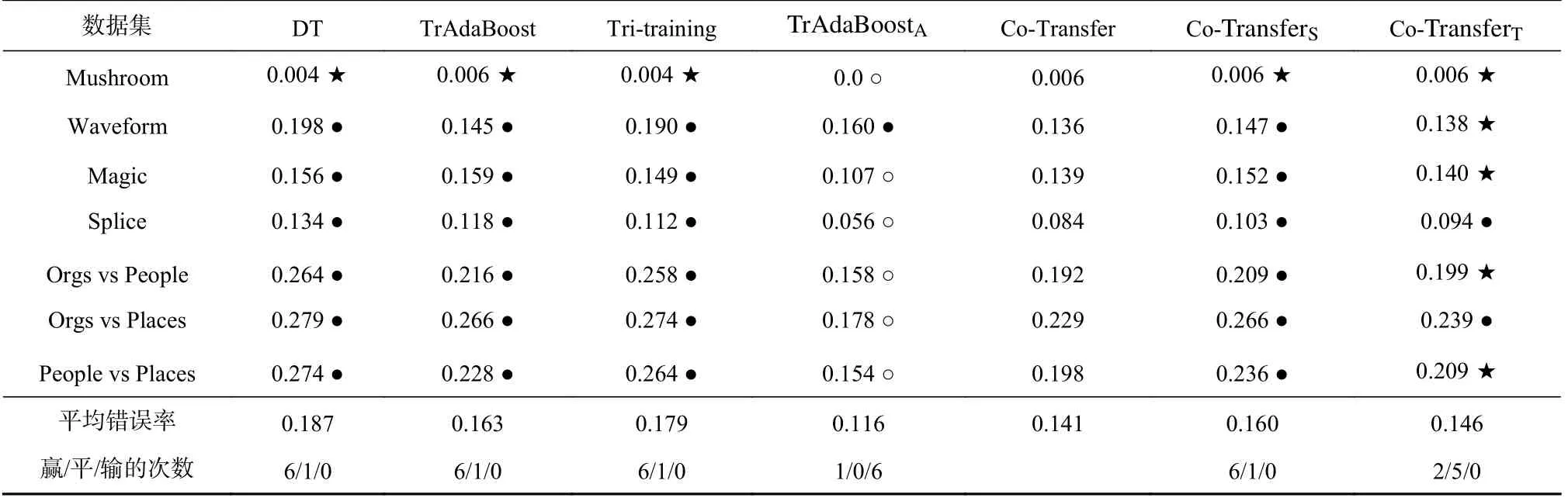
Table 3 Error Rates of the Comparative Algorithms Under the Label Rate 10% of Original Source Domain and Target Domain表3 在原始源域與原始目標(biāo)域標(biāo)記比率均為10%下所對比算法的錯誤率
從表3~6 還可以觀察到:Co-Transfer 的泛化能力不比Co-TransferT弱.為分析Co-Transfer 能否有效利用原始源域的未標(biāo)記樣本DSU,我們將TrAdaBoostS與TrAdaBoost 進行了比較,結(jié)果如表7 所示.從表7 中可以觀察到:1)標(biāo)記比率超過20%后,提升標(biāo)記比率不太可能會帶來TrAdaBoostS的泛化能力的顯著提升;2)在各種標(biāo)記比率下,對于數(shù)據(jù)集Mushroom,Waveform,Magic,TrAdaBoostS與TrAdaBoost 在原始目標(biāo)域上的泛化能力沒有顯著區(qū)別;3)對于數(shù)據(jù)集Splice,Orgs vs People,Orgs vs Places,People vs Places,增加源域的標(biāo)記樣本數(shù)量可能得到正向遷移的效果.再結(jié)合表3~6 可知:Co-Transfer 能否有效利用原始源域的未標(biāo)記樣本應(yīng)該與數(shù)據(jù)集的自身特性相關(guān).
為更深入觀察Co-Transfer 的學(xué)習(xí)過程,我們平均不同標(biāo)記比率下各種對比算法在文本分類數(shù)據(jù)集上每輪迭代的分類錯誤率.圖2 描述了各算法從初始迭代到最終迭代的平均錯誤率的變化.需要解釋的是:1)在與Co-Transfer 對比的算法中,僅有Tritraining,Co-TransferS,Co-TransferT使用了無標(biāo)記樣本,其他算法都只使用標(biāo)記樣本;2)當(dāng)一個算法提前終止了,我們保持其錯誤率補齊了數(shù)據(jù).從圖2 中可以觀察到:1)不使用無標(biāo)記樣本的算法無迭代過程,僅有最終分類錯誤率,DT 錯誤率最高,其次是TrAdaBoost 和TrAdaBoostS,最后是TrAdaBoostA;2)初始迭代時,Co-Transfer,Co-TransferS,Co-TransferT的平均分類錯誤率幾乎相同但略微低于Tri-training,隨著迭代不斷進行,Co-Transfer 的平均分類錯誤率不斷降低,并快速收斂.
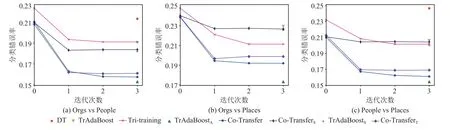
Fig.2 Error rates of the comparative algorithms during their iteration on the text classification tasks圖2 文本分類任務(wù)上各對比算法在迭代過程中的錯誤率
此外,還觀察了原始源域的標(biāo)記比率要高于原始目標(biāo)域的標(biāo)記比率這一情況.表8 和表9 顯示原始源域標(biāo)記比率為50%,而原始目標(biāo)域的標(biāo)記比率分別為10%和20%時,Co-Transfer 與各對比算法的分類錯誤率.可以觀察到:DT 的分類錯誤率最高;TrAdaBoostA顯然要比Co-Transfer 的泛化能力強;在各種標(biāo)記比率條件下,Co-Transfer 的泛化能力比TrAda Boost,Tri-training,Co-TransferS的泛化能力都要好.這說明:在原始源域的標(biāo)記比率比原始目標(biāo)域的標(biāo)記比率高時,Co-Transfer 還能有效地利用原始源域的標(biāo)記樣本和原始目標(biāo)域的未標(biāo)記樣本.

Table 8 Error Rates of the Comparative Algorithms Under the Label Rate 50% of the Original Source Domain and 10% of the Original Target Domain表8 在原始源域標(biāo)記比率為50%、原始目標(biāo)域標(biāo)記比率為10%下所有對比算法的錯誤率
從表8 和表9 中還可觀察到:Co-Transfer 的泛化能力不比Co-TransferT弱.為分析Co-Transfer 能否有效利用原始源域的未標(biāo)記樣本DSU,同樣將TrAdaBoostS與TrAdaBoost 進行比較,結(jié)果如表10 所示.可以觀察到:當(dāng)原始源域標(biāo)記比率較高時,增加原始源域標(biāo)記樣本的數(shù)量很可能不帶來原始目標(biāo)域分類錯誤率的顯著下降.因此,表8~10 中暫不能解釋Co-Transfer的泛化能力不比Co-TransferT弱.
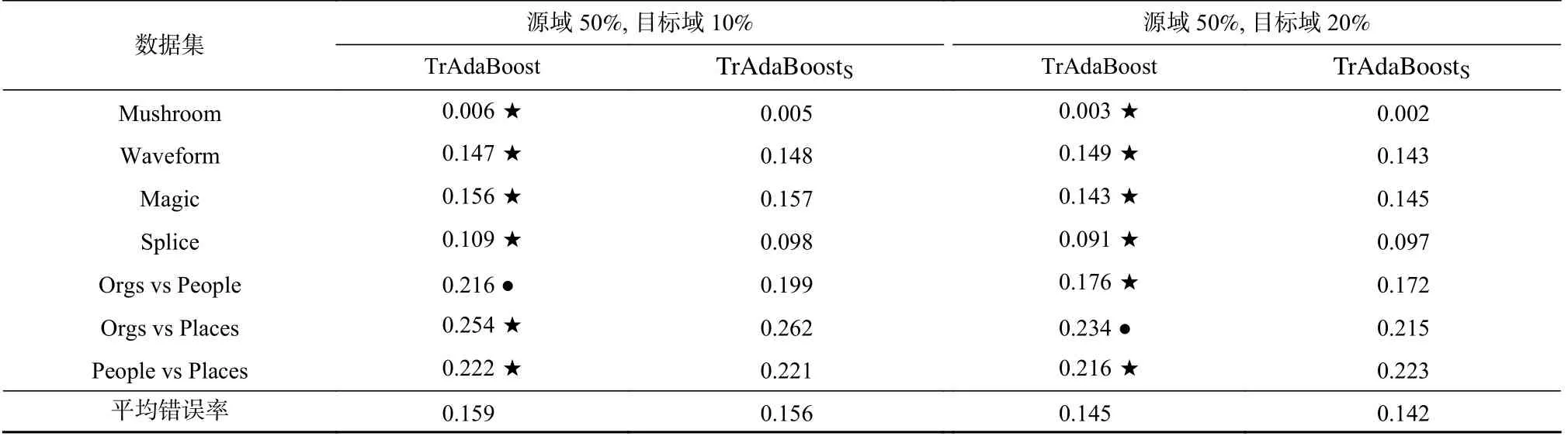
Table 10 Error Rates of TrAdaBoost and TrAdaBoostS Under the Label Rate 50% of the Original Source Domain and 10% and 20% of the Original Target Domain, Respectively表10 在原始源域標(biāo)記比率為50%、原始目標(biāo)域標(biāo)記比率分別為10%和20%下TrAdaBoost 與TrAdaBoostS 的錯誤率
綜合表3~10 中實驗結(jié)果,可以進一步推測:原始源域和原始目標(biāo)域的標(biāo)記比率的同步提升對于Co-Transfer 的學(xué)習(xí)過程的影響比較復(fù)雜.這是因為:僅增加源域標(biāo)記樣本數(shù)量并不一定總能提升遷移學(xué)習(xí)的效果;目標(biāo)域標(biāo)記樣本數(shù)量的增加會掩蓋源域標(biāo)記樣本帶來的正向遷移.因此,在Co-Transfer 的學(xué)習(xí)過程中,源域和目標(biāo)域很可能存在一個博弈過程.
當(dāng)Co-Transfer 的分類器采用決策樹時,考慮到?jīng)Q策樹的深度D和TrAdaBoost 的迭代次數(shù)N可能會影響Co-Transfer 的泛化能力.因此,在文本分類數(shù)據(jù)集上進一步研究了樹的深度D和迭代次數(shù)N對Co-Transfer 泛化能力的影響.圖3 描述了將不同的標(biāo)記比率條件下的分類錯誤率平均后Co-Transfer 的變化曲線.從中可以觀察到:在文本分類數(shù)據(jù)集上,參數(shù)N和D對Co-Transfer 算法分類錯誤率有較大影響.當(dāng)固定D時,隨著N的增大Co-Transfer 的分類錯誤率越來越低;然而當(dāng)N較小時,Co-Transfer 的分類錯誤率隨參數(shù)D的變化較大;隨著N的增加,Co-Transfer的分類錯誤率對參數(shù)D的敏感性變小.
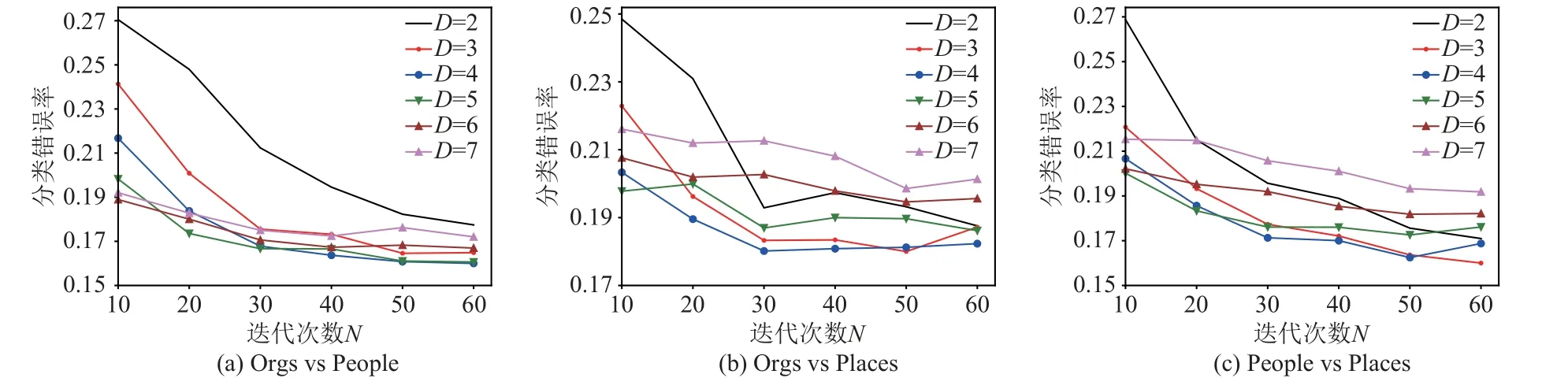
Fig.3 Error rates of Co-Transfer with different N and D圖3 不同N 和D 條件下Co-Transfer 的錯誤率
4 結(jié) 論
本文提出了一種半監(jiān)督歸納遷移學(xué)習(xí)框架——Co-Transfer.在4 個UCI 和文本分類任務(wù)數(shù)據(jù)集上與7 個算法的對比實驗表明:Co-Transfer 的這種雙向同步遷移的機制可以有效地學(xué)習(xí)源域和目標(biāo)域的標(biāo)記和未標(biāo)記樣本來提升泛化性能.我們未來的工作包括:使用多種類型的組件分類器來評測Co-Transfer的分類性能,如神經(jīng)網(wǎng)絡(luò)、樸素貝葉斯等;源域和目標(biāo)域之間的雙向可遷移性對Co-Transfer 的影響.此外,還應(yīng)該使用更多的數(shù)據(jù)集,尤其是實際應(yīng)用中的數(shù)據(jù)集來評測Co-Transfer 的泛化能力.本文偽代碼可以從 https://gitee.com/ymw12345/co-transfer.git 下載.
作者貢獻聲明:文益民負(fù)責(zé)算法研討、算法設(shè)計及論文修改;員喆負(fù)責(zé)算法設(shè)計、論文初稿撰寫及論文修改;余航參與算法研討、論文修改.
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
人大建設(shè)(2020年4期)2020-09-21 03:39:12
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(shè)(2017年2期)2017-07-21 10:59:25
人大建設(shè)(2017年9期)2017-02-03 02:53:31
少兒科學(xué)周刊·少年版(2015年3期)2015-07-07 21:00:00
浙江人大(2014年5期)2014-03-20 16:20:28
