開源軟件缺陷預測方法綜述
2023-07-20 11:20:56常繼友榮景峰王子昱張光華伍高飛胡敬爐張玉清
計算機研究與發(fā)展 2023年7期
田 笑 常繼友 張 弛 榮景峰,6 王子昱 張光華 王 鶴 伍高飛,4 胡敬爐 張玉清,6,7
1 (西安電子科技大學網(wǎng)絡(luò)與信息安全學院 西安 710126)
2 (國家計算機網(wǎng)絡(luò)入侵防范中心(中國科學院大學)北京 101408)
3 (河北科技大學信息科學與工程學院 石家莊 050018)
4 (廣西密碼學與信息安全重點實驗室(桂林電子科技大學)廣西 桂林 541000)
5 (早稻田大學情報生產(chǎn)系統(tǒng)研究科 日本 808-0135)
6 (海南大學網(wǎng)絡(luò)空間安全學院 海口 570228)
7 (中關(guān)村實驗室 北京 100094)
軟件缺陷(software defect),也稱Bug 或Fault,是由于開發(fā)過程或者維護過程中存在的錯誤而產(chǎn)生的導致計算機無法正常運行的錯誤或者功能性缺陷.當在軟件測試期間發(fā)現(xiàn)缺陷時,這些缺陷可能處于多種不同的狀態(tài),常見的缺陷狀態(tài)信息如表1 所示,如果缺陷沒有被及時發(fā)現(xiàn)或者修復,則可能會影響軟件系統(tǒng)的功能從而造成巨大的財產(chǎn)損失甚至威脅人身安全.
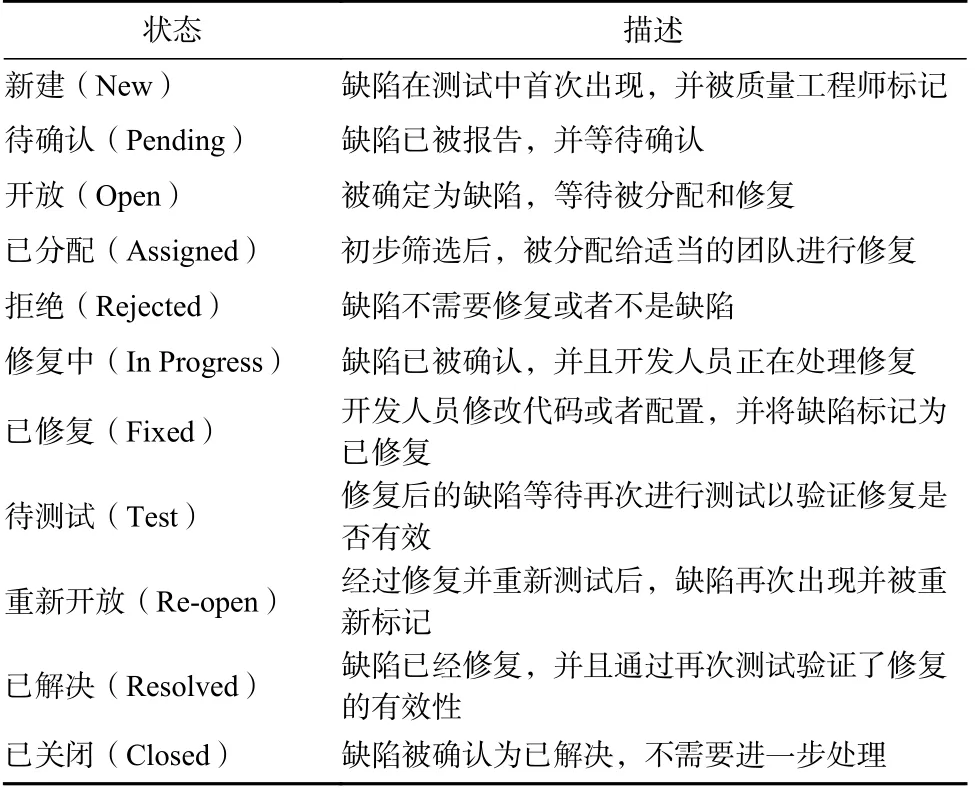
Table 1 Software Defect State Description表1 軟件缺陷狀態(tài)描述
傳統(tǒng)的軟件缺陷檢測方法,包括手動測試、自動化分析、靜態(tài)分析、代碼審查等[1],但是由于人力資源和時間資源有限,傳統(tǒng)的缺陷發(fā)現(xiàn)技術(shù)只能檢測到較少的缺陷.基于人工智能的軟件缺陷預測技術(shù)包括機器學習和深度學習,可以預測更詳細的軟件缺陷信息.軟件缺陷的檢測和預測方法對比如表2 所示,軟件缺陷預測可以在較少的時間內(nèi)發(fā)現(xiàn)更多的軟件缺陷,減少用于發(fā)現(xiàn)和修復缺陷的成本.

Table 2 Comparison of Defect Detection and Defect Prediction Methods表2 缺陷檢測與缺陷預測方法對比
軟件缺陷預測根據(jù)軟件歷史開發(fā)數(shù)據(jù)以及已發(fā)現(xiàn)的缺陷數(shù)據(jù),借助機器學習等方法來預測軟件項目中的缺陷數(shù)目和類型[2].軟件缺陷預測模型可以確定哪些組件具有最大的安全風險,軟件工程師可以根據(jù)模型預測結(jié)果做出風險管理決策,指導安全檢查和測試,并確定軟件安全防御工作的優(yōu)先級.
早期研究者利用源代碼度量從軟件源代碼中提取缺陷特征,靜態(tài)分析樣本中的缺陷數(shù)量,后來研究者定義與軟件缺陷強相關(guān)的度量,提高分類器的效率.基于軟件度量的缺陷預測模型如圖1 所示,模型首先從開源公共倉庫或者開源社區(qū)中抽取程序模塊;然后定義與軟件缺陷強相關(guān)的度量元,提取對應的度量特征從而構(gòu)造出缺陷數(shù)據(jù)集;最后通過軟件缺陷數(shù)據(jù)集訓練軟件缺陷預測模型,軟件缺陷預測模型就能夠預測目標程序模塊的軟件缺陷相關(guān)信息.
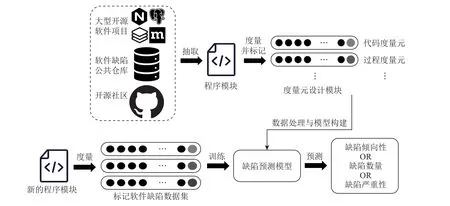
Fig.1 Defect prediction model based on software metrics圖1 基于軟件度量的缺陷預測模型
基于軟件度量的缺陷預測模型的缺陷預測方法較為簡單,只需要手工定義與軟件缺陷相關(guān)的度量元,但是該模型無法挖掘出與缺陷相關(guān)的更深層次信息,應用范圍比較局限,模型的優(yōu)劣取決于數(shù)據(jù)集和分類器.
隨著深度學習的發(fā)展,研究者開始從復雜的代碼中自動獲取更深層次的特征,表征程序的語法語義信息.基于語法語義的缺陷預測模型如圖2 所示,模型首先利用文本挖掘技術(shù)對源代碼的標識符、函數(shù)名和運算符進行解析并標記,然后提取軟件缺陷相關(guān)特征并抽象表示,最后通過編碼器模型生成向量并送入神經(jīng)網(wǎng)絡(luò)預測模型進行訓練.
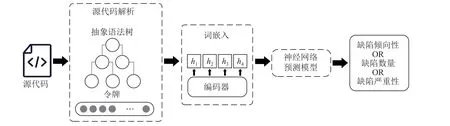
Fig.2 Defect prediction model based on semantic and syntactic圖2 基于語法語義的缺陷預測模型
漏洞是一種特定的軟件安全缺陷,受軟件缺陷預測研究的啟發(fā)和推動,漏洞預測通過挖掘軟件實例存儲庫來提取和標記代碼模塊,預測新的代碼實例是否含有漏洞,減少用于發(fā)現(xiàn)和修復漏洞的成本.與缺陷預測領(lǐng)域相同,漏洞預測研究領(lǐng)域也可以劃分為基于軟件度量的漏洞預測和基于語法語義的漏洞預測模型.基于軟件度量的漏洞預測模型使用人工設(shè)計的代碼變更、耦合和內(nèi)聚等度量,表征漏洞的相關(guān)信息[3].由于漏洞數(shù)量極少且種類繁多,這些特征不能完全理解代碼本身的含義且預測效果較差,因此該模型逐漸被舍棄.
隨著人工智能技術(shù)在各個領(lǐng)域的應用,人工智能技術(shù)被用于缺陷預測和漏洞預測任務,漏洞預測模型的效果因此得到了提升.為了能夠表征漏洞更多的信息,研究人員使用文本、抽象語法樹(abstract syntax tree,AST)、代碼屬性圖等多種方式提取軟件代碼中的特征,挖掘代碼的語法語義信息,轉(zhuǎn)化為向量的數(shù)字表示,隨后使用機器學習或者深度學習方法預測項目中的漏洞.細粒度的漏洞預測是漏洞領(lǐng)域的研究熱點,為了提取更細粒度的特征,一些研究人員將漏洞函數(shù)表征為漏洞切片,使用注意力機制預測漏洞的位置信息.本文使用defect prediction,software defect prediction,fault prediction,vulnerability prediction 和vulnerability detection 等關(guān)鍵字進行檢索,收集并調(diào)研了2000年至2022 年來自IEEE Xplore、ACM、Digital Library、SpringerLink、ScienceDirect 和中國知網(wǎng)(CNKI)等國內(nèi)外數(shù)據(jù)庫和軟件工程領(lǐng)域與網(wǎng)絡(luò)安全領(lǐng)域的國際期刊和頂級會議上的論文,總結(jié)了開源軟件缺陷預測已有的研究成果,并指出了該研究領(lǐng)域的未來發(fā)展趨勢.缺陷預測和漏洞預測各年份統(tǒng)計的相關(guān)文獻數(shù)量如圖3 所示.
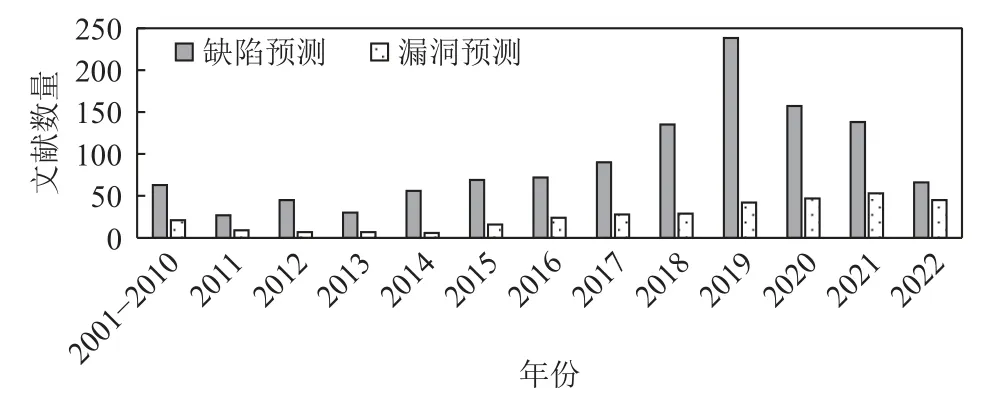
Fig.3 Number of literatures related to defect prediction and vulnerability prediction圖3 缺陷預測和漏洞預測相關(guān)文獻數(shù)量
本文的主要貢獻有4 個方面:
1)廣泛收集并調(diào)研了2000 年至2022 年12 月軟件缺陷預測現(xiàn)有文獻,從數(shù)據(jù)集、評價指標、模型構(gòu)建3 個方面分析了缺陷預測的研究現(xiàn)狀;
2)以機器學習和深度學習技術(shù)為切入點,總結(jié)了基于軟件度量和基于語法語義2 類預測模型;
3)分析了軟件缺陷預測模型和漏洞預測模型之間的區(qū)別和聯(lián)系,探討了缺陷預測和漏洞預測之間的可移植性;
4)歸納和分析了缺陷預測技術(shù)領(lǐng)域的不足,指出了當前面臨的機遇和挑戰(zhàn),給出了未來發(fā)展方向.
1 缺陷預測框架
軟件缺陷預測技術(shù)包括靜態(tài)缺陷預測技術(shù)與動態(tài)缺陷預測技術(shù).靜態(tài)缺陷預測是目前主流的軟件缺陷預測技術(shù),它通過挖掘軟件歷史倉庫,手工定義與軟件缺陷相關(guān)的度量元和從源代碼本身表征程序的語法語義信息2 種方式,借助機器學習或深度學習方法提前發(fā)現(xiàn)軟件缺陷.動態(tài)缺陷預測通過研究軟件缺陷隨時間變化的趨勢,預測軟件的下一個版本或下一個生命周期中可能出現(xiàn)缺陷的數(shù)量.基于動態(tài)軟件缺陷預測技術(shù)的核心是數(shù)學模型,包括Rayleigh分布模型[4-5]、指數(shù)分布模型[6-7]、S 曲線分布模型[8-10].對于動態(tài)軟件缺陷預測模型來說,需要對軟件產(chǎn)品進行長時間的監(jiān)測以獲取軟件的數(shù)據(jù).然而收集大量的開發(fā)數(shù)據(jù)需要耗費大量的成本,并且不同的數(shù)據(jù)集和動態(tài)缺陷預測模型會導致預測精度不盡如人意.因此缺陷預測的大部分研究目前都集中在靜態(tài)缺陷預測,后文的缺陷預測特指靜態(tài)缺陷預測.
本文以機器學習和深度學習技術(shù)為切入點,介紹了基于軟件度量和基于語法語義的2 類缺陷預測模型,這2 類缺陷預測模型框架如圖4 所示.
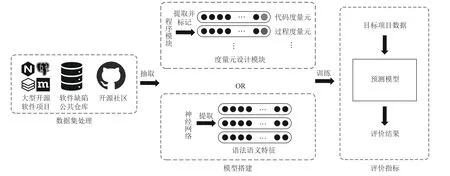
Fig.4 Defect prediction framework圖4 缺陷預測框架
缺陷預測框架由3 部分組成:
1)從軟件缺陷公共倉庫和開源社區(qū)收集缺陷數(shù)據(jù);
2)定義與軟件缺陷高度相關(guān)的度量元,提取程序模塊的軟件度量特征或者使用神經(jīng)網(wǎng)絡(luò)自動提取源代碼的語法語義特征,利用機器學習或深度學習技術(shù)構(gòu)建預測模型;
3)使用性能評價指標對預測模型進行評價.
下文從缺陷預測框架入手,分別介紹了缺陷數(shù)據(jù)、模型的評價指標以及缺陷預測模型的搭建.
2 缺陷數(shù)據(jù)集
軟件缺陷預測模型的構(gòu)建離不開缺陷數(shù)據(jù)集,但缺陷數(shù)據(jù)集中的維數(shù)災難和類不平衡問題影響著軟件缺陷預測模型的質(zhì)量.本節(jié)從缺陷數(shù)據(jù)集的來源和缺陷數(shù)據(jù)預處理2 個角度對缺陷數(shù)據(jù)集進行分析.
2.1 缺陷數(shù)據(jù)集來源
軟件缺陷數(shù)據(jù)集包含了軟件項目全生命周期的缺陷數(shù)據(jù)信息,常常被用于軟件缺陷預測的研究.
開源軟件缺陷數(shù)據(jù)集主要來源于軟件缺陷公共倉庫、開源社區(qū)和大型開源軟件項目.國內(nèi)外研究人員使用NASA,PROMISE 等公共庫進行了一系列研究,對軟件缺陷預測的發(fā)展做出了貢獻,這些公共庫提供了包含了Apache,Eclipse 等真實軟件項目的數(shù)據(jù)集,經(jīng)過驗證和標注,具有較高的數(shù)據(jù)質(zhì)量,通過對這些公共倉庫數(shù)據(jù)的分析和實驗,研究人員能夠評估不同方法在缺陷預測方面的性能和效果.隨著越來越多的開源軟件項目公開,一些研究者選擇使用大型開源軟件項目,如Nginx,Redis 和Gedit 等,評估不同的缺陷預測模型在預測軟件缺陷方面的準確性和有效性.SourceForge,GitHub 等開源社區(qū)提供了與軟件相關(guān)的特征,研究人員利用源代碼、軟件描述、錯誤修復、審查過程等開源軟件提供的信息,發(fā)現(xiàn)深層隱藏的軟件缺陷[11].
本文對2000 年至2022 年12 月的論文進行了整理分析,軟件缺陷公共倉庫的數(shù)據(jù)來源及其統(tǒng)計信息如表3 所示.大部分研究人員使用NASA,PROMISE和AEEEM 中的KC3,PC4,CM1,PC3,KC1 和PC1 等數(shù)據(jù)集,公共數(shù)據(jù)集的屬性如表4 所示,這些數(shù)據(jù)集發(fā)布在2005 年左右,主要使用C,C++,Java 等語言開發(fā).除了使用NASA,PROMISE 中的數(shù)據(jù)集外,一些研究者使用Nginx,Redis,Gedit 等大型開源軟件,在軟件缺陷預測領(lǐng)域開展一系列研究,開源軟件項目缺陷數(shù)量統(tǒng)計如表5 所示,文獻[12]使用了2 個連續(xù)版本的6 個開源軟件項目Camel,F(xiàn)lume,Tika,Gedit,Nginx,Redis,研究軟件模塊在文件級別的缺陷.文獻[13]使用了多個版本的4 個開源軟件項目Gedit,Nagios Core,Nginx,Redis,這些項目主要使用C/C++語言開發(fā),文獻[13]的作者從缺陷修復報告中收集到了這些項目的缺陷信息.此外,文獻[14]探究6 個項目在開源軟件項目的不同版本中的代碼變更,并分析了這些變更對產(chǎn)生缺陷的可能性,開源軟件代碼變更對缺陷的影響如表6 所示.

Table 3 Public Warehouse Data Sources for Software Defect Modeling表3 軟件缺陷模型的公共倉庫數(shù)據(jù)來源
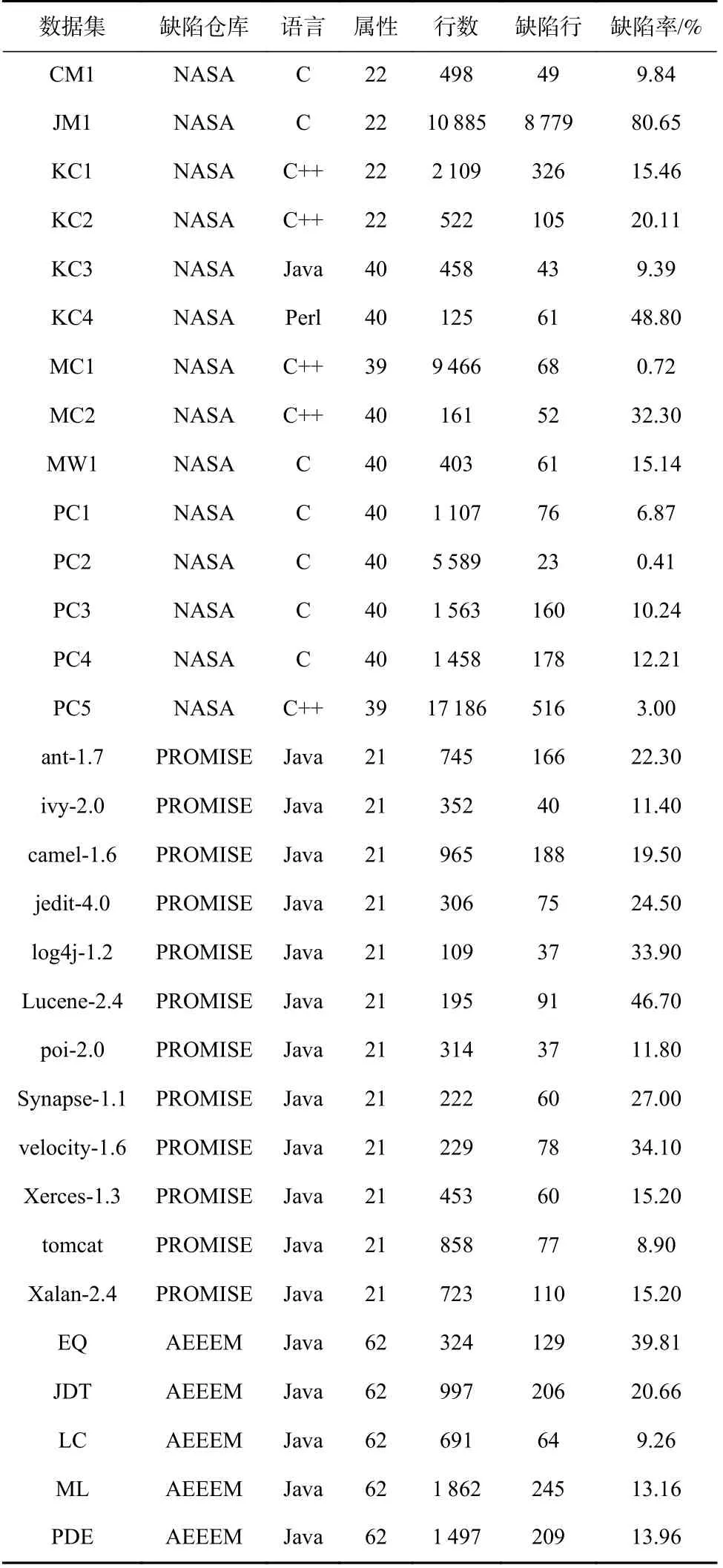
Table 4 Attributes List of the Publicly Available Datasets表4 公共數(shù)據(jù)集屬性列表
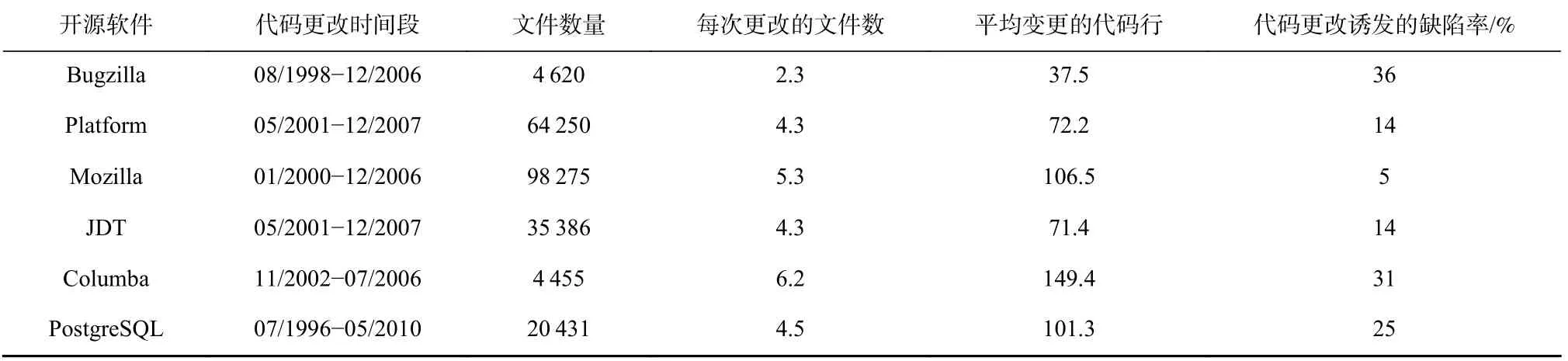
Table 6 Impact of Code Changes on Defects in Open-Source Software Projects表6 開源軟件項目代碼變更對缺陷的影響
經(jīng)過調(diào)查發(fā)現(xiàn),NASA,PROMISE 等軟件缺陷公共倉庫的數(shù)據(jù)集由LOC[15],Halstead[16]等度量元的屬性和包含缺陷的類標記組成.大部分研究者使用NASA,PROMISE 等軟件缺陷公共倉庫的數(shù)據(jù)集進行模型的比較和重現(xiàn),一些研究者使用Nginx,Redis,Gedit 等真實世界的開源軟件,在軟件缺陷預測領(lǐng)域開展一系列研究.這些公開數(shù)據(jù)集往往具有類不平衡、維度過高、預測特征不足以及分類標簽不足等缺點[17].數(shù)據(jù)集中維數(shù)災難和類不平衡的問題可以通過特征選擇[18]、降維[19-29]等方法進行處理,但是特征不足和分類標簽不足的問題則需要通過定義更細粒度的軟件缺陷度量元來解決.
2.2 缺陷數(shù)據(jù)預處理
缺陷數(shù)據(jù)集中類不平衡[23-36]、維度過高[37-43]、特征不足[44-45]以及分類標簽不足[46-50]等問題會降低軟件缺陷預測模型的性能,在使用缺陷數(shù)據(jù)時對其進行預處理,可以提高缺陷預測模型的質(zhì)量,部分缺陷數(shù)據(jù)預處理的方法如表7 所示.
2.2.1 類不平衡
程序模塊中80%的缺陷集中在20%的文件中,缺陷的數(shù)量遠少于非缺陷的數(shù)量,缺陷數(shù)量的不平衡分布會導致模型的預測性能受到嚴重影響.
20 世紀90 年代,研究人員從數(shù)據(jù)層面解決類不平衡問題,包括隨機欠采樣(random under sampling,RUS)[20]、隨機過采樣(random over sampling,ROS)[21-22],這些算法簡單高效,但是效果取決于模型的訓練算法.文獻[23]針對ADASYN[24]自適應過采樣算法造成的噪聲問題和CURE-SMOTE[25]層過采樣算法分類準確性問題,提出了一種AJCC-Ram 多層次過采樣算法,使用ADASYN 改進算法進行邊緣采樣,CURESMOTE 算法進行中心區(qū)采樣,分層次進行樣本生成,采用最近列表噪聲識別(closest list noise identification,CLNI[26])方法對噪聲進行過濾.
文獻[27]使用鄰居清理學習(neighbor cleaning learning,NCL)去除不平衡數(shù)據(jù)集中的重疊樣本,使用集成隨機欠采樣并重復多次,解決了缺陷數(shù)據(jù)集偏態(tài)分布的問題.結(jié)果表明,與CLNI、基于聚類的噪聲檢測(clustering-based noise detection,CBND)[28]兩種數(shù)據(jù)清洗算法相比,NCL 在G-mean 和AUC 評價指標上表現(xiàn)更優(yōu).
文獻[29]提出一種新的基于鄰域的欠采樣(neighbourhood based under-sampling,N-US)算法來處理類不平衡問題.N-US 首先識別缺陷實例的鄰域,計算出鄰域中的干凈實例,并從有缺陷的實例的鄰域中最近的位置消除干凈實例.結(jié)果表明,與RUS 等基線方法相比,N-US 能夠避免過度消除數(shù)據(jù)帶來的負面影響,有效地提高了分類器的性能.
算法級方法通過直接修改訓練機制解決類不平衡問題,算法級方法包括代價敏感學習方法、集成學習方法等.代價敏感學習不是通過不同的采樣策略創(chuàng)建平衡的數(shù)據(jù)分布,而是通過使用不同的代價矩陣來解決類不平衡問題,這些代價矩陣表示對特定數(shù)據(jù)實例進行錯誤分類的成本.文獻[30]提出了一種代價敏感轉(zhuǎn)移核典型相關(guān)分析(cost-sensitive transfer kernel canonical correlation analysis,CTKCCA)方法,利用代價敏感技術(shù),在遷移學習階段使用轉(zhuǎn)移核典型相關(guān)分析方法,分離有缺陷和無缺陷的實例.結(jié)果表明,該方法在PD,PF,AUC 等指標上均優(yōu)于轉(zhuǎn)移成分分析 (transfer component analysis,TCA)等基線方法.
對于機器學習來說,單個模型存在過擬合和缺乏泛化能力等缺點,集成學習通過組合多個分類器來處理類不平衡.常用的集成學習方法包括Boosting,Bagging,Stacking,Voting 以及隨機子空間方法(random subspace method,RSM)等.文獻[31]使用隨機森林(random forest,RF)、人工神經(jīng)網(wǎng)絡(luò)、K 最近鄰作為模型的主要學習者,邏輯回歸(logistic regression,LR)作為模型的次要學習者,從多個Stacking 模型中選擇了性能最好的模型.文獻[32]提出一種基于隨機近似約簡(random approximation reduction,RAR)的集成學習算法ERAR,該算法使用RAR 擾動屬性空間,以刪除冗余和不相關(guān)的屬性,采用重采樣技術(shù)擾動實例空間.為了解決學習器中數(shù)據(jù)集不平衡問題,ERARSMOTE 在ERAR 中加入了方法SMOTE,對不平衡的缺陷數(shù)據(jù)進行預處理.結(jié)果表明,ERAR-SMOTE 在F1-Score,MCC,Recall 等指標上優(yōu)于RSM,Bagging 等基線方法.
近年來,研究人員使用深度學習解決缺陷預測中的類不平衡問題.文獻[33]將嵌入最近鄰(stratification embedded in nearest neighbor,STr-NN)的分層思想引入了神經(jīng)網(wǎng)絡(luò),在標記的訓練數(shù)據(jù)集上訓練集成學習分類器,用來搜索目標數(shù)據(jù)的偽標簽,基于偽標簽確定訓練數(shù)據(jù)集中缺陷的數(shù)量.文獻[33]的作者使用最近鄰(NN)平衡訓練數(shù)據(jù)集,解決項目內(nèi)缺陷預測(within-project defect prediction, WPDP)中的類不平衡問題.對于跨項目缺陷預測(cross-project defect prediction, CPDP)的類不平衡問題,在STr-NN 的基礎(chǔ)上,引入TCA 緩解源數(shù)據(jù)和目標數(shù)據(jù)之間的特征不一致問題.結(jié)果表明,與TCA,TCA+SMOTE 相比,TCA+STr-NN 具有更高的AUC 和Recall.
文獻[34]提出了一種基于雙向生成對抗網(wǎng)絡(luò)的軟件缺陷預測模型(ADGAN-SDP),從異常檢測的角度解決類不平衡問題.該模型使用雙向生成對抗網(wǎng)絡(luò)(bidirectional generative adversarial network,BiGAN)對無缺陷樣本進行建模,并將無缺陷樣本的損失值與預定義的閾值進行比較,從而預測當前樣本是否含有缺陷.結(jié)果表明,該方法在AUC,G-mean,F(xiàn)1 等指標上優(yōu)于代價敏感、過采樣、欠采樣、集成學習等方法.
混合方法將數(shù)據(jù)級技術(shù)、算法級技術(shù)與集成方法結(jié)合,用來處理類不平衡問題.文獻[35]分別使用采樣、代價敏感、集成及混合形式構(gòu)建軟件缺陷預測模型.結(jié)果表明,相比較于采樣和代價敏感學習,集成學習實現(xiàn)了更好的預測結(jié)果.
傳統(tǒng)的Stacking 方法在處理類不平衡問題時沒有考慮代價成本問題.文獻[36]提出一種CSSG 方法,將Stacking 方法與代價敏感學習結(jié)合.結(jié)果表明,該方法能夠很好地解決項目內(nèi)缺陷預測中類不平衡問題.
討論1:不平衡的數(shù)據(jù)集中可能存在類重疊問題,主要表現(xiàn)在少數(shù)有缺陷的訓練樣本與大多數(shù)無缺陷的訓練樣本實例重疊,增加了分類器學習缺陷特征的難度.使用NCL,CLNI,CBDN 等方法可以去除不平衡數(shù)據(jù)集中的重疊樣本,提高缺陷預測的能力.
2.2.2 高維度數(shù)據(jù)
數(shù)據(jù)集中的冗余和無關(guān)特征會降低模型的預測性能,通過對高維度數(shù)據(jù)進行處理,能夠縮短模型的訓練時間并提高模型的預測性能,特征選擇方法可以從高維度特征中選擇與缺陷高度相關(guān)的特征從而實現(xiàn)特征降維.20 世紀90 年代后期,研究人員使用包裝器[37]和過濾器[38]從高維度特征中選擇與缺陷高度相關(guān)的特征.基于過濾器的方法使用獨立的學習算法評估數(shù)據(jù)集的特征,復雜度較低且不能保證學習算法的準確性.基于包裝器的特征選擇方法使用預定的學習算法評估數(shù)據(jù)集特征的優(yōu)劣,特征選擇獨立性較高,但是基于包裝器的特征選擇方法用于子集搜索評估和選擇的數(shù)量未知,存在分類器過擬合等問題.
文獻[39]改進了基于包裝器的特征選擇方法,設(shè)計了一種EWFS 模型用來動態(tài)選擇特征.該模型首先使用熵度量對數(shù)據(jù)集中的特征進行排序,然后通過增量包裝方法傳遞排序的特征,最后使用條件互信息最大化(conditional mutual information maximization,CMIM)選擇所需特征.結(jié)果表明,這種動態(tài)特征選擇方法優(yōu)于現(xiàn)有的元啟發(fā)式方法和基于順序搜索的包裝法.
混合特征選擇方法是基于過濾器和包裝器的方法.文獻[40]提出一種混合特征選擇方法,通過比較方案與理想解之間的相似度來進行排序的方法(technique for order preference by similarity to ideal solution,TOPSIS)為5 種過濾方法計算分數(shù),決策矩陣生成排序后的候選特征;使用基于Rao 的優(yōu)化的包裝器算法尋找最優(yōu)的候選特征.結(jié)果表明,該方法優(yōu)于GA[41]等特征選擇方法.
文獻[42]將代價矩陣結(jié)合到傳統(tǒng)的特征選擇方法,在特征選擇階段強調(diào)代價較高的樣本,以解決特征選擇階段的類不平衡問題.結(jié)果表明,基于代價敏感的特征選擇方法在降低成本和解決不平衡問題上優(yōu)于傳統(tǒng)的特征選擇方法.
文獻[43]提出了FECAR 特征選擇框架,在特征聚類階段,使用k-medoids 聚類算法將特征劃分為k個聚類,并根據(jù)FC-Relevance 度量從每個聚類中選擇相關(guān)的特征.結(jié)果表明,該方法可以有效地識別并剔除冗余和不相關(guān)特征.
討論2:特征選擇方法是解決高維度數(shù)據(jù)的一種有效方法,在保證數(shù)據(jù)質(zhì)量的同時選擇突出特征.基于包裝器和過濾器的特征選擇是2 種傳統(tǒng)的特征選擇方法,雖然基于包裝器的特征選擇方法優(yōu)于基于過濾器的特征選擇方法,但是基于包裝器的特征選擇方法仍存在著搜索特征子集高時間復雜度等問題,未來應在減少其時間成本的同時,維持該方法的性能.
2.2.3 數(shù)據(jù)差異
構(gòu)建性能優(yōu)越的軟件缺陷預測模型需要足夠多的歷史標注數(shù)據(jù),但是現(xiàn)實中標注足夠多的訓練數(shù)據(jù)相當困難,數(shù)據(jù)差異問題普遍存在于跨項目缺陷預測、跨版本缺陷預測中(cross-version defect prediction,CVDP).
跨項目缺陷預測使用其他項目的缺陷數(shù)據(jù)來預測當前項目是否含有缺陷.但不同項目的數(shù)據(jù)分布存在著差異,很難將通過源項目缺陷數(shù)據(jù)集訓練的軟件缺陷預測模型泛化到新的目標項目中.
文獻[44]提出TCA+方法,將TCA 與數(shù)據(jù)歸一化方法結(jié)合,但該方法性能不穩(wěn)定.隨后,文獻[45]提出了FeSCH 方法,選擇合適的特征緩解源項目和目標項目數(shù)據(jù)之間的分布差距,在特征聚類階段使用DPC 基于密度的聚類方法將原始特征劃分為多個簇,在特征選擇階段設(shè)計了特征的局部密度(local density of features,LDF)、特征分布的相似性(similarity of feature distribution,SFD)、特征的類相關(guān)性(feature-class relevance,F(xiàn)CR)這3 種策略將每個簇中的特征進行排序.結(jié)果表明,F(xiàn)eSCH 相比于TCA+等基線方法在AUC 指標表現(xiàn)更優(yōu).
但是文獻[44-45]所提方法沒有考慮到源數(shù)據(jù)中的類標簽信息,文獻[46]提出一種域適應方法LSKDSA,在子空間對齊(subspace alignment,SA)方法的基礎(chǔ)上,使用源數(shù)據(jù)的可用類別標簽,并且在域適應學習的過程中加入了判別信息,以減少源數(shù)據(jù)和目標數(shù)據(jù)分布之間的差異.結(jié)果表明,該方法在Fmeasure 和AUC 等指標上優(yōu)于TCA+等基線方法.
由于開發(fā)環(huán)境等因素的影響,各個項目的度量值會存在較大差異,導致跨項目缺陷預測的精度較低.文獻[47]提出了一種基于特征選擇和遷移學習的度量補償軟件缺陷預測方法,首先使用Pearson 計算特征和缺陷類別之間的相關(guān)系數(shù),使用相關(guān)系數(shù)選擇訓練時的特征子集;接著使用TCA 將源項目和目標項目的共同特征映射到潛在空間中;隨后,使用度量補償方法為原始度量值分配權(quán)重,以提高目標項目之間的相似性.結(jié)果表明,該方法在AUC 和Fmeasure 這2 個指標上優(yōu)于傳統(tǒng)的度量補償技術(shù).
跨版本缺陷預測同一項目、不同版本得到的數(shù)據(jù)分布存在著差異,這種差異對跨版本缺陷預測模型的預測性能造成影響.
軟件的演進會導致開發(fā)者在原先有缺陷的基礎(chǔ)上引入新的缺陷,文獻[48]考慮了連續(xù)版本之間缺陷分布的變化,提出一種主動學習方法.但該方法依賴于先前版本的標記模塊,忽略了當前版本未標記模塊的信息,文獻[49]在此基礎(chǔ)上,提出了一種混合主動學習(hybrid active learning,HAL),從當前模塊中選擇最具有價值的未標記模塊,并與先前版本的標記模塊組合,共同構(gòu)建混合訓練集.HAL 模型使用基于核方法的主成分分析(kernel principal component analysis,KPCA)方法,將混合訓練模塊的數(shù)據(jù)和剩余維標記模塊的數(shù)據(jù)映射到高維特征空間.
但是文獻[48-49]所述方法忽略了先前版本中數(shù)據(jù)分布差異的問題,文獻[50]提出了一種帶有數(shù)據(jù)選擇的跨版本缺陷預測模型CDS,該模型為噪聲較少的歷史版本以及數(shù)據(jù)集內(nèi)部與測試集相似的文件分配更高的權(quán)重.通過對比發(fā)現(xiàn),CDS 在Fmeasure 和G-mean 指標上優(yōu)于其他的基線模型.
討論3:對于性能優(yōu)越的軟件缺陷預測模型來說,大量的訓練數(shù)據(jù)必不可少,但是跨項目缺陷預測、跨版本缺陷預測中的數(shù)據(jù)差異問題影響了軟件缺陷預測模型的性能,未來研究人員的研究應著重構(gòu)建高質(zhì)量、平衡且無噪音的數(shù)據(jù)集,改善軟件缺陷預測模型的性能.
3 評價指標
本節(jié)首先統(tǒng)計了目前軟件缺陷預測研究的評價指標,分析了研究者最常用的評價指標,各項常用評價指標的具體描述如表8 所示.
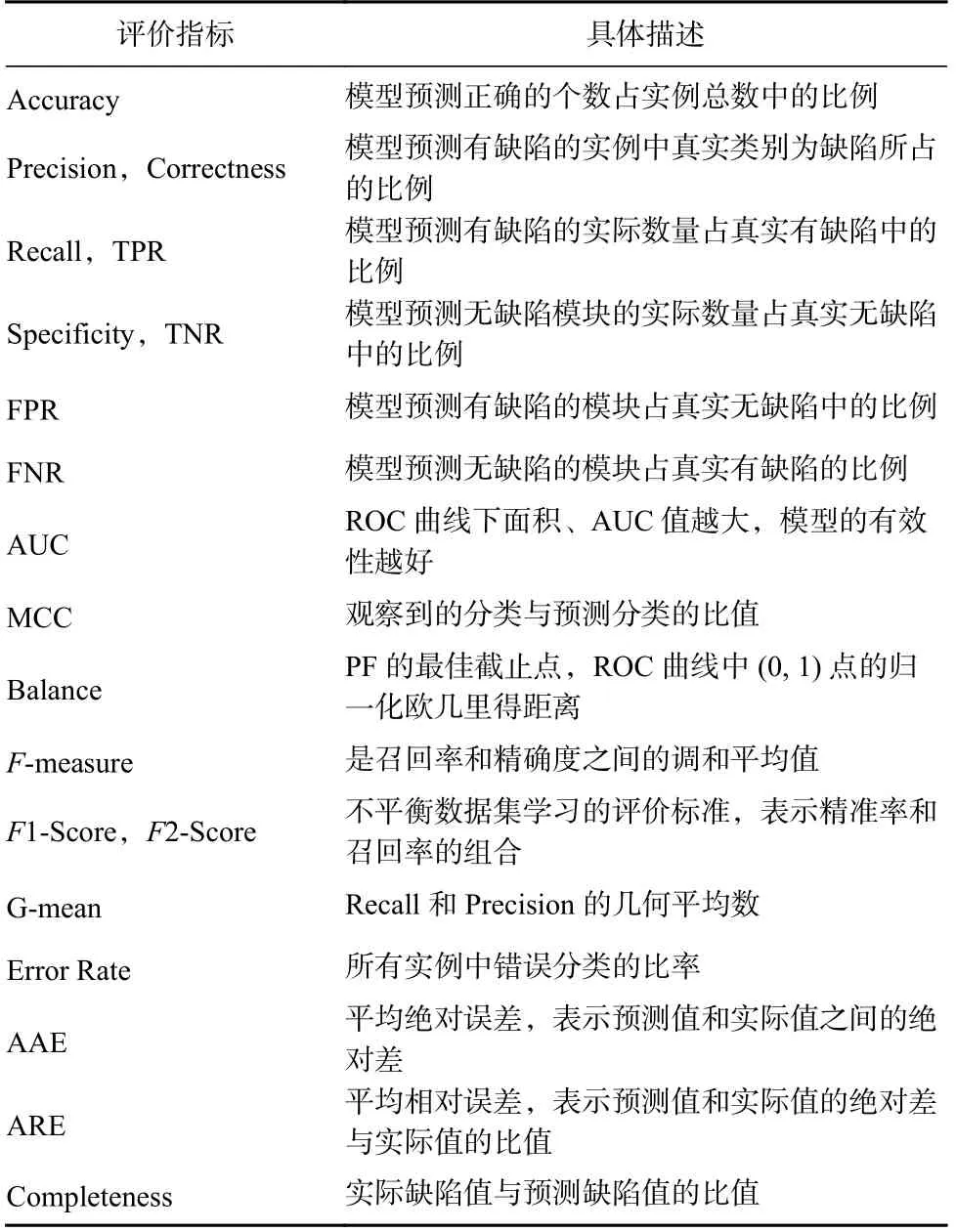
Table 8 Common Evaluation Indicators and Their Descriptions表8 常用評價指標及其描述
本文的預測指標的研究數(shù)量占比如圖5 所示,可以發(fā)現(xiàn),Recall,Precision,AUC,F(xiàn)-measure 是最常用的評價性能指標.經(jīng)調(diào)查發(fā)現(xiàn),研究人員對于模型的評價指標也有爭議:文獻[51]認為一個好的軟件缺陷預測模型應該同時實現(xiàn)高召回率和高準確率;文獻[52]對F-measure 和Precision 進行了批判,該文作者認為不是所有好的預測模型都需要高召回率和高準確率;文獻[53]發(fā)現(xiàn)使用MCC,而不是使用F1-Score 作為軟件缺陷預測的評價指標,超過1/5 的模型對比結(jié)果會發(fā)生改變.
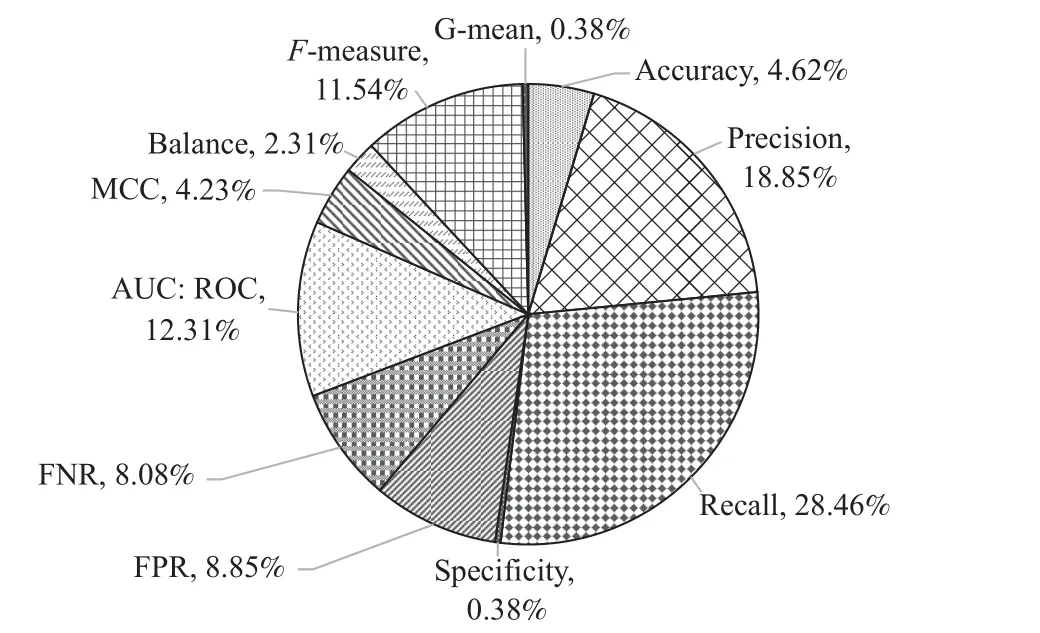
Fig.5 Summary of evaluation indicators圖5 評估指標統(tǒng)計
軟件缺陷預測研究的評價指標調(diào)查結(jié)果表明,不同模型在不同評價指標上的表現(xiàn)不同,研究者不應局限于單個指標評估不同模型的優(yōu)劣,應結(jié)合多種評價指標,針對不同的模型采用多樣性的評價指標進行評估.
4 缺陷預測模型
4.1 基于軟件度量的缺陷預測
軟件度量是在軟件開發(fā)過程對軟件進行數(shù)據(jù)收集、定義和分析的一個持續(xù)性定量化過程,描述軟件產(chǎn)品或者開發(fā)過程的指標或者參數(shù),以保證高效率、低成本和高質(zhì)量的軟件開發(fā)過程[54].度量元是最細粒度的軟件度量屬性,用于描述特定的度量特征,度量元主要分為代碼度量元和過程度量元.不同的度量元對軟件缺陷預測模型的影響不同,為了提高軟件缺陷預測模型的性能,一些研究者使用混合度量元搭建軟件缺陷預測模型.
基于軟件度量的缺陷預測模型如圖1 所示,模型首先從開源公共倉庫或者開源社區(qū)中抽取程序模塊,然后定義與軟件缺陷強相關(guān)的度量元并提取對應的度量特征從而構(gòu)造出缺陷數(shù)據(jù)集,最后通過軟件缺陷數(shù)據(jù)集訓練軟件缺陷預測模型,軟件缺陷預測模型就能夠預測目標程序模塊的軟件缺陷相關(guān)信息.
如圖6 所示,早在20 世紀70 年代,傳統(tǒng)的代碼度量基于代碼行(lines of code,LOC)[15],隨后研究人員發(fā)現(xiàn)軟件缺陷不僅取決于軟件規(guī)模,還取決于軟件復雜度,于是提出了Halstead 度量[16]、McCabe 度量[55].20 世紀90 年代,隨著面向?qū)ο蠹夹g(shù)的發(fā)展,一些研究者開始關(guān)注模塊的內(nèi)聚性、耦合度等特征,所以使用面向?qū)ο蠖攘吭饬寇浖?guī)模和復雜度.1994年,Chidamber 和Kemerer 基于面向?qū)ο蟪绦虻睦^承、耦合、內(nèi)聚特征給出了6 個類級別的CK 度量標準[56].文獻[57]提出了MOOD 度量,包含6 個度量標準.2002年,文獻[58]提出了一套QMOOD 度量,在系統(tǒng)和類的層次上評估軟件設(shè)計.2021 年,文獻[59]第一次將代碼氣味作為跨項目缺陷預測的特征,使用RF、支持向量機(support vector machine,SVM)、多層感知機(multilayer perceptron,MLP)、決策樹(decision tree,DT)、樸素貝葉斯(naive Bayes,NB)構(gòu)建軟件缺陷預測模型.結(jié)果表明,基于代碼氣味訓練的跨項目缺陷預測模型的性能相較于基于代碼度量的缺陷預測模型提高了6.5%,且基于代碼氣味訓練的缺陷預測模型的表現(xiàn)效果優(yōu)于代碼氣味和代碼度量等混合度量指標訓練的缺陷預測模型.
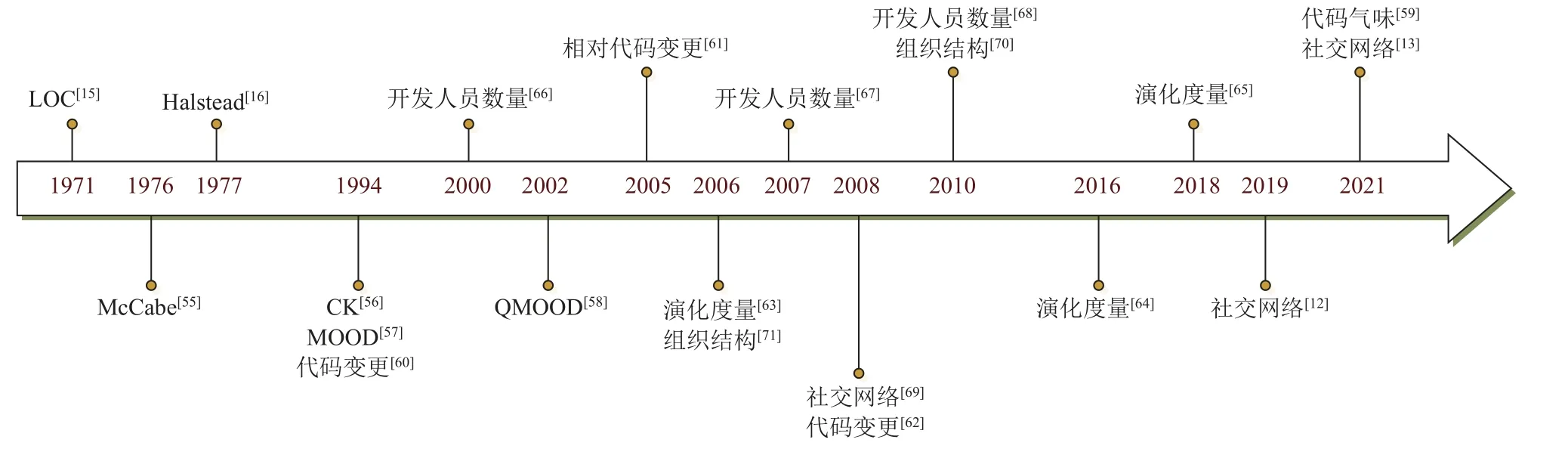
Fig.6 Timeline of metrics development圖6 度量元發(fā)展時間線
研究人員發(fā)現(xiàn)軟件缺陷不僅與軟件規(guī)模有關(guān),還與軟件開發(fā)過程的各階段有關(guān),因此提出了一系列的過程度量.代碼變更可以度量代碼在不同版本之間的增加、刪除或者修改量,它很容易從版本控制系統(tǒng)自動記錄的系統(tǒng)更改歷史中提取.20 世紀90 年代,文獻[60]使用代碼變更作為軟件質(zhì)量的衡量標準.隨后,文獻[61]提出了8 種相對代碼變更指標,預測軟件缺陷密度.文獻[62]使用了LR,NB,DT 這3 種分類模型,發(fā)現(xiàn)對于Eclipse 數(shù)據(jù),代碼變更指標比代碼度量能更好地預測缺陷.
代碼度量和過程度量并不能很好地描述軟件模塊如何隨項目演變而變化,而演化度量[63-65]是一種專門針對項目演變過程的度量元.文獻[64]使用類的年齡、類出現(xiàn)缺陷的可能性、類連續(xù)且不含有缺陷的周期來刻畫軟件演化過程中類的演化模式,研究結(jié)果發(fā)現(xiàn),與代碼度量和代碼變更相比,演化度量元能更好地預測軟件缺陷.文獻[65]將多個連續(xù)版本的文件度量按版本升序連接在一起,利用循環(huán)神經(jīng)網(wǎng)絡(luò),提供了一個新的視角來解釋文件如何隨項目的發(fā)展而變化的趨勢.
軟件缺陷的產(chǎn)生與開發(fā)人員密切相關(guān),早期研究人員僅僅將修改模塊的開發(fā)人員數(shù)作為缺陷預測的度量元,但是后續(xù)研究發(fā)現(xiàn)軟件缺陷與開發(fā)人員的數(shù)量無關(guān)[66-68].隨后,一些研究人員從社交網(wǎng)絡(luò)[12-13,69]分析開發(fā)人員的經(jīng)驗,從程序模塊的所有權(quán)等角度分析開發(fā)人員與缺陷之間的關(guān)系.文獻[69]使用網(wǎng)絡(luò)中心度來衡量開發(fā)人員貢獻的碎片化程度,開發(fā)人員的數(shù)量越多,代碼修改的次數(shù)也相應增多,導致軟件含有的缺陷數(shù)量也越多,研究結(jié)果表明中心模塊比網(wǎng)絡(luò)周圍的模塊更容易產(chǎn)生軟件缺陷.
隨著全球軟件開發(fā)的出現(xiàn),研究人員發(fā)現(xiàn)組織結(jié)構(gòu)[70-71]也影響著軟件的質(zhì)量.文獻[71]提出了8 項量化組織復雜性的度量用于研究組織結(jié)構(gòu)與軟件質(zhì)量之間的關(guān)系,實驗結(jié)果表明,組織指標比傳統(tǒng)代碼變更、代碼復雜性、代碼依賴等指標的預測效果更佳.2005—2010 年,軟件缺陷預測結(jié)合各種度量元,使用各種機器學習算法提高模型的準確性和性能.NB[72]、貝葉斯網(wǎng)絡(luò)(Bayesian network,BN)[73]、K-means[74-75]、AdaBoost[76]、DT[76]、LR[72-73,76]等方法在此期間展現(xiàn)了較好的性能.2010 年后,相比于傳統(tǒng)的機器學習方法,一些新的機器學習[14,50,77-79]方法提高了軟件缺陷預測的性能.現(xiàn)有的跨版本缺陷預測模型通常只使用一個先前版本收集的數(shù)據(jù)進行模型訓練,并沒有考慮在具有多個先前版本的跨版本缺陷預測場景中數(shù)據(jù)分布差異方差和類重疊問題.文獻[14]提出了一種基于樸素貝葉斯的改進轉(zhuǎn)移樸素貝葉斯,結(jié)果表明該模型在項目內(nèi)缺陷預測和跨項目缺陷預測中的準確率、精度、PD 都優(yōu)于轉(zhuǎn)移樸素貝葉斯模型.文獻[50]提出了一種新穎的基于聚類的多版本分類器CMVC,為每個先前版本分配適當?shù)臋?quán)重,并通過最小化目標函數(shù)來獲得現(xiàn)有文件的預測標簽,結(jié)果表明該方法優(yōu)于RF,LR,NB 等模型.
隨著深度學習的應用,一些研究人員提出了基于深度學習[65,80-81]的缺陷預測模型.文獻[80]探索了Siamese 網(wǎng)絡(luò)的優(yōu)勢,提出了一種新的軟件缺陷預測模型SDNN.與以往的方法相比,SDNN 使用2 個完全相同的全連通網(wǎng)絡(luò)學習最高相似度特征,并使用計量函數(shù)作為最高相似度特征之間的距離度量.結(jié)果表明,在F-measure 方面,SDNN 方法優(yōu)于深度神經(jīng)網(wǎng)絡(luò)(deep neural network,DNN)、長短期記憶網(wǎng)絡(luò)(long short-term memory,LSTM)、深度信念網(wǎng)絡(luò)(deep belief network ,DBN)、NB 和LR 這5 種方法.
文獻[81]提出了一種Defect-Learner 模型,從代碼自然性的角度,將交叉熵作為一種新的軟件度量方法引入到文件級缺陷預測.Defect-Learner 模型在學習階段,構(gòu)建了一個多層的LSTM 網(wǎng)絡(luò),從輸入的標記向量中學習隱含的語義特征.在預測階段,將交叉熵度量與其他度量特征結(jié)合,用來預測目標項目中的缺陷.結(jié)果表明,使用結(jié)合交叉熵的CK,QMOOD等度量,能夠改進軟件缺陷預測的性能.
討論4:本節(jié)按時間順序歸納了代碼度量和過程度量,圖6 展示了度量元發(fā)展歷程,度量元的演變過程及其對比結(jié)果如表9 所示.從分析來看,軟件的演化是一個動態(tài)的連續(xù)過程,新增模塊或者修復歷史缺陷都會產(chǎn)生新的缺陷,未來研究應該關(guān)注演化度量元,提高軟件缺陷預測的性能.
Table 9 Comparison of Metric Evolution表9 度量元的演進對比
觀點1:目前大多數(shù)研究者是手工定義與軟件缺陷相關(guān)的度量元,忽略了軟件缺陷在軟件生命周期中的產(chǎn)生方式,未來如何從存儲庫中自動提取與缺陷相關(guān)的度量元仍是研究的熱點.
4.2 基于語法語義的缺陷預測
基于語法語義的缺陷預測模型如圖2 所示,模型首先通過AST 等技術(shù)對源代碼進行解析從而提取語法語義特征信息,然后通過軟件缺陷相關(guān)的詞嵌入方法將語法語義特征編碼為向量,最后將生成的向量數(shù)據(jù)集送入神經(jīng)網(wǎng)絡(luò)模型訓練得到缺陷預測模型.
2015 年開始,深度學習、人工神經(jīng)網(wǎng)絡(luò)在軟件缺陷預測中得到廣泛應用.與傳統(tǒng)的軟件度量不同,研究者使用卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)、循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)、MLP、DBN、LSTM 和門控循環(huán)神經(jīng)網(wǎng)絡(luò)(gated recurrent unit,GRU)等深度學習算法,通過AST 等方式生成的標記向量提取特征,從而挖掘軟件程序中隱藏的語義和結(jié)構(gòu)特征,并將生成的特征數(shù)據(jù)反饋到神經(jīng)網(wǎng)絡(luò)中,訓練獲得缺陷預測模型.文獻[82]提出了一種用于即時缺陷預測的深度學習方法,利用DBN在一組初始變化特征中提取了表達特征,在選定的特征上構(gòu)建了缺陷預測模型.但具有不同語義的程序文件可能具有相同的傳統(tǒng)特征,該方法無法區(qū)分不同語義的代碼區(qū)域.
鑒于此,文獻[83]采用編輯距離相似度計算算法和CLNI 剔除可能存在錯誤標簽的數(shù)據(jù),并通過AST 分析程序源代碼獲取語法信息,最后將語法信息轉(zhuǎn)換為特征向量并輸入到DBN 網(wǎng)絡(luò)中從而建立預測模型.結(jié)果表明,該模型提高了項目內(nèi)缺陷預測和跨項目缺陷預測的性能,與傳統(tǒng)特征相比,該方法平均精度提高了14.7%,召回率提高了11.5%,F(xiàn)1 提高了14.2%.文獻[84]在文獻[82-83]所述的文件級缺陷預測的基礎(chǔ)上考慮了代碼變更,提出了一種啟發(fā)式方法,從代碼變更片段中提取重要的結(jié)構(gòu)信息和上下文信息;對于變更級缺陷預測,該方法從代碼中提取標記,并生成基于DBN 的特征;對于文件級缺陷預測,使用源文件的完整AST 生成DBN 的語義特征.結(jié)果表明,在F1 指標上,該方法在文件級和變更級缺陷預測方面上都優(yōu)于傳統(tǒng)的CPDP 和WPDP 模型.文獻[85]在DBN 模型提取語義特征的基礎(chǔ)上,將CNN 學習到的特征與傳統(tǒng)的缺陷預測特征相結(jié)合,提出了一種基于CNN 的缺陷預測框架,從程序的AST 中生成判別特征,并且保留了程序的語義和結(jié)構(gòu)特征.結(jié)果表明,在F-measure 方面,該方法比基于DBN 的方法提高了12%,比傳統(tǒng)的基于軟件度量的方法提高了16%.文獻[86]提出了一種基于注意力的RNN 的軟件缺陷預測(defect prediction via attentionbased recurrent neural network,DP-ARNN)框架,通過解析程序的AST 并將語法信息轉(zhuǎn)換為向量,然后使用字典嵌入和詞嵌入對向量編碼并輸入到ARNN 網(wǎng)絡(luò)中,利用ARNN 自動學習語法結(jié)構(gòu)特征和語義信息內(nèi)容,最后通過注意力機制生成關(guān)鍵特征向量.與RNN 相比,DP-ARNN 在F-measure 上平均提升了3%,在AUC 上平均提升了1%.
深度學習方法(CNN,DBN)使用AST 生成的標記向量以提取深度學習特征.文獻[87]發(fā)現(xiàn),CNN 和DBN 結(jié)合傳統(tǒng)軟件度量和TCA 算法,可以將源項目中提取到的深度學習特征用于目標項目,解決跨項目中分布不平衡問題.實驗結(jié)果表明,將深度學習生成的特征和傳統(tǒng)特征結(jié)合起來,比純DBN 和CNN 模型的表現(xiàn)效果要好.文獻[88]提出了一個新的跨項目缺陷預測方法S2LMMD,首先通過在指定節(jié)點拆分原始AST 構(gòu)造聯(lián)合學習語句級樹SLT,從而捕獲更精細的語義和結(jié)構(gòu)信息;然后使用雙向門控循環(huán)神經(jīng)單元(bidirectional gated recurrent unit,Bi-GRU)學習序列嵌入并生成更有效的語義特征;最后使用最大平均偏差(maximum mean discrepancy,MMD)技術(shù)緩解跨項目中的數(shù)據(jù)分布差異,提高缺陷預測性能.實驗結(jié)果表明,在AUC 指標上,S2LMMD 優(yōu)于DBN和CNN.源代碼中的語法和不同級別的語義信息通常由樹的結(jié)構(gòu)表示,文獻[89]實現(xiàn)了一種基于樹結(jié)構(gòu)的LSTM 網(wǎng)絡(luò)(tree-structured LSTM network,Tree-LSTM),使用Tree-LSTM 匹配代碼的AST,充分捕獲源代碼中的語法和不同級別的語義,使用注意力機制定位源文件中可能存在缺陷的部分.
文獻[90]提出一種基于圖卷積神經(jīng)網(wǎng)絡(luò)(graph convolutional network,GCN)的缺陷預測模型.首先該模型從源代碼中提取了7 種節(jié)點特征,根據(jù)節(jié)點特征對控制流圖(control flow graph,CFG)節(jié)點進行分類并生成節(jié)點特征值,最后為CFG 創(chuàng)建節(jié)點向量矩陣并將其傳遞給圖卷積網(wǎng)絡(luò)以自動學習特征.結(jié)果表明,該模型可以適應不同規(guī)模的軟件,在AUC,F(xiàn)1-score 等指標上優(yōu)于CNN 等傳統(tǒng)的缺陷預測模型.
缺陷特征隱藏在程序語義中,但是AST 不顯示程序的執(zhí)行過程,它只代表源代碼的抽象句法結(jié)構(gòu).文獻[91]采用CNN 的思想,將源代碼轉(zhuǎn)換為程序控制流程圖,采用多視圖多層CNN 從CFG 中自動提取學習缺陷特征,結(jié)果表明圖學習可以提高基于傳統(tǒng)特征和基于AST 方法的性能.
文獻[92]提出了一種基于增強代碼屬性圖(augmented-code property graph,Augmented-CPG)模型ACGDP,用于捕獲代碼的語法、語義、控制流和數(shù)據(jù)流信息.該模型在初始階段從缺陷代碼文件中獲得AST 和CFG,與代碼的控制流和數(shù)據(jù)流合并,生成Augmented-CPG,第2 階段提取候選缺陷區(qū)域(graph of defect region candidates,GDRC)定位可能存在的缺陷節(jié)點,第3 階段從GDRC 中獲取代碼嵌入,使用圖神經(jīng)網(wǎng)絡(luò)(graph neural network,GNN)學習GDRC 中包含的缺陷特征.結(jié)果表明,該模型在Accuracy,Precision 等指標上優(yōu)于VulDeePecker[93]模型.
代碼注釋是源代碼的另一種視圖,幫助生成反映代碼功能的語義特征,并識別軟件中含有缺陷的模塊.文獻[94]提出了一種評論增強程序的卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network for comments augmented program,CAP-CNN)缺陷預測模型,該模型在訓練過程中將代碼注釋編碼為語義特征,結(jié)果表明CAP-CNN 在F-measure 指標上優(yōu)于CNN.
近幾年,一些改進的算法被提出來用于軟件缺陷預測,網(wǎng)絡(luò)嵌入技術(shù)取得重大進展.文獻[95]提出了Node2defect,一種基于隨機游走的網(wǎng)絡(luò)嵌入技術(shù)的缺陷預測模型,該模型能夠自動學習軟件類依賴網(wǎng)絡(luò)的類結(jié)構(gòu)特征并挖掘節(jié)點鄰接信息和節(jié)點屬性,最后將學習到的特征與傳統(tǒng)度量連接并輸入到后續(xù)預測模型中.結(jié)果表明,該模型在F-measure 指標上比傳統(tǒng)的軟件度量方法提高了9.15%.文獻[96]提出了GCN2defect,一種基于GNN 的缺陷預測模型,該網(wǎng)絡(luò)學習類依賴網(wǎng)絡(luò)中節(jié)點的結(jié)構(gòu)特征,并對節(jié)點的語義和結(jié)構(gòu)新信息進行端到端的學習.文獻[96]的作者引入了傳統(tǒng)靜態(tài)代碼度量、復雜網(wǎng)絡(luò)度量和網(wǎng)絡(luò)嵌入3 種類型的節(jié)點度量作為節(jié)點的屬性,與傳統(tǒng)的軟件度量和傳統(tǒng)的網(wǎng)絡(luò)嵌入相比,該方法顯著提高了缺陷預測性能.文獻[97]在此基礎(chǔ)上提出了CGCN 模型,使用CNN 捕獲AST 中的語義信息,GCN捕獲軟件網(wǎng)絡(luò)中的結(jié)構(gòu)信息,CGCN 通過這2 種方式獲得聯(lián)合特征,并與傳統(tǒng)特征結(jié)合用于訓練分類器.結(jié)果表明,該模型優(yōu)于Node2defect 和GCN2defect 等方法.
文獻[98]使用Transformer 模型自動學習序列的語義特征和句法結(jié)構(gòu)特征,預測代碼的缺陷密度.文獻[99]考慮了源代碼的語義和上下文信息,采用BERT和雙向長短期記憶網(wǎng)絡(luò)(bidirectional long short-term memory,BiLSTM)模型預測缺陷,BiLSTM 通過BERT模型學習的token 向量學習上下文的語義信息.結(jié)果表明,與現(xiàn)有的深度學習和傳統(tǒng)特征相比,該模型更能有效提取程序的語義信息.
討論5:本節(jié)統(tǒng)計分析了基于語法語義的缺陷預測模型,根據(jù)分析結(jié)果發(fā)現(xiàn),缺陷特征隱藏在程序語義中,大多數(shù)研究者將源代碼解析為AST,利用深度學習技術(shù)學習程序的語法和句法特征.
觀點2:缺陷特征隱藏在程序語義中,但是AST不顯示程序的執(zhí)行過程,它只代表源代碼的抽象句法結(jié)構(gòu),未來研究者應使用源代碼的多種表征方式,幫助生成反映代碼功能的語義特征.
5 漏洞預測
漏洞是一種特定的軟件安全缺陷,存在能夠被攻擊者利用并造成危害的安全隱患.與軟件缺陷研究領(lǐng)域不同,漏洞的研究領(lǐng)域可以分為漏洞檢測與漏洞預測2 個任務場景.
漏洞檢測和漏洞預測2 個任務側(cè)重的研究目的不同.漏洞檢測任務針對已知的漏洞,在特定的軟件中檢測是否存在目標漏洞.漏洞預測任務則主要負責從宏觀角度進行數(shù)據(jù)上的統(tǒng)計,預測一個代碼文件中可能存在的漏洞數(shù)量,以減少漏洞發(fā)現(xiàn)和修復的成本.但隨著人工智能尤其是深度學習方法的大量引入,漏洞檢測和漏洞預測模型愈發(fā)相似,由于都使用大規(guī)模精細標注的數(shù)據(jù)集進行訓練,任務的目的和實現(xiàn)的方式也漸漸重合,在近年的許多研究工作中已經(jīng)不再區(qū)分這兩者的概念.
本節(jié)以漏洞預測過程為切入點,分別介紹了傳統(tǒng)的基于軟件度量的預測方法以及基于語法語義的預測方法.
5.1 漏洞預測模型
5.1.1 基于軟件度量的漏洞預測
基于軟件度量的漏洞預測模型通過人工設(shè)計軟件特征表示軟件漏洞相關(guān)信息,再使用機器學習算法預測并識別漏洞相關(guān)的組件.漏洞預測模型使用復雜度、代碼變更、開發(fā)者活動、耦合、內(nèi)聚等度量,并使用LR,SVM,J48,DT,RF,NB,BN 等機器學習算法預測漏洞相關(guān)的組件.
文獻[100]對Mozilla 中的JavaScript 引擎進行了案例研究,發(fā)現(xiàn)9 種復雜性度量(包括McCabe,SLOC 等度量)可以用于預測漏洞,但是誤報率較高.文獻[100]的作者發(fā)現(xiàn),漏洞函數(shù)和缺陷函數(shù)的復雜性度量僅在復雜度方面存在顯著差異,因此復雜度可以區(qū)分漏洞和缺陷函數(shù).文獻[101]使用源代碼行、代碼變更等度量預測漏洞,結(jié)果表明該回歸樹模型在最佳情況下實現(xiàn)了100%的召回率和8%的假陽率.文獻[102]研究了開發(fā)人員協(xié)作結(jié)構(gòu)與漏洞之間的關(guān)系,研究發(fā)現(xiàn),由9 個或者更多開發(fā)人員更改的文件比少于9個開發(fā)人員更改的文件具有漏洞的可能性高16 倍.文獻[103]研究了3 種軟件度量指標(復雜性、代碼變更、開發(fā)人員活動)是否可以區(qū)分易受攻擊的文件來指導安全檢查和測試.結(jié)果表明,28 個度量中至少有24 個可以區(qū)分2 個項目的易受攻擊文件和中性文件,這3 種度量可以為安全檢查和測試工作提供有價值的指導.文獻[104]研發(fā)出一個基于復雜性、耦合性和內(nèi)聚性相關(guān)的漏洞預測框架,該框架能正確預測Mozilla Firefox 的大多數(shù)受漏洞影響的文件,且誤報率較低.
觀點3:基于軟件度量的漏洞預測研究提出了大量的指標,試圖盡可能完整地從軟件代碼中手動提取出漏洞相關(guān)的特征.但這些人工定義的特征并不一定能夠完全理解代碼本身的含義,因此在實際的漏洞預測中仍具有較多不足.
例如在圖7 中的2 段Python 代碼,從功能上來看都是從棧頂彈出5 個數(shù)據(jù),但代碼1 在棧中數(shù)據(jù)不足5 個時有向下溢出的風險,代碼2 則沒有.但這2段代碼具有相同的軟件度量、代碼標記和頻率等,僅依靠人工提取的指標難以對二者進行區(qū)分,需要一種能夠提取代碼的語法結(jié)構(gòu)特征和語義信息內(nèi)容的算法.

Fig.7 Code example圖7 代碼示例
5.1.2 基于語法語義的漏洞預測
基于語法語義的漏洞挖掘通過文本挖掘、AST等方式提取軟件代碼中的特征信息,轉(zhuǎn)化為向量的數(shù)字表示,隨后使用機器學習(machine learning,ML)或深度學習(deep learning,DL)方法進行分類.使用圖算法或者注意力機制還可以具體定位可能出現(xiàn)漏洞的位置.基于語法語義的研究主要集中在探究不同的特征提取方法和各種訓練模型.
文獻[105]提出了一種依賴于源代碼文本分析的方法,將每個文件轉(zhuǎn)換為一個特征向量.該方法將源代碼的每一個字母組合都視為特征,使用給定文件源代碼中給定字母組合的計數(shù)值.該研究在開源移動應用程序上實現(xiàn)了87%的準確率、85%的精度和88%的召回率.文獻[106]將文件中的代碼標記和頻率作為代碼的文本特征,預測可能存在漏洞的組件,該模型相比于PHP 應用程序的軟件度量模型實現(xiàn)了更高的召回率.但是對詞袋模型來說,它忽略了代碼之間的語法結(jié)構(gòu)信息,隱藏在程序中的語義信息可以幫助易受攻擊的代碼提供更豐富的表示,從而改進漏洞預測模型的效果.此后的研究引入了AST 來表征句法結(jié)構(gòu),文獻[107]從代碼中提取了AST 并確定樹的結(jié)構(gòu)模式,根據(jù)樹的結(jié)構(gòu)模式自動比較代碼,該方法僅通過檢查少量代碼庫就能進行漏洞預測.文獻[108]使用Antlr 從C/C++源文件中提取AST,以每個函數(shù)為基本單元從AST 中提取向量,利用該向量訓練分類器來預測緩沖區(qū)漏洞.
許多深度學習技術(shù)也開始應用于漏洞預測任務.深度學習技術(shù)可以從復雜的代碼中自動獲取更深層次的特征信息,表征程序的語法和語義特征.文獻[109]在令牌(token)級數(shù)據(jù)上,采用深度神經(jīng)網(wǎng)絡(luò),結(jié)合N-gram 分析和特征選擇構(gòu)造特征,該模型能夠在Java Android 應用程序漏洞預測任務中實現(xiàn)高精度、高準確率和高召回率.文獻[110]利用LSTM 捕獲源代碼中的上下文關(guān)系,學習代碼的語法語義特征,結(jié)果表明該方法優(yōu)于傳統(tǒng)的軟件度量等模型.文獻[111]研究了基于文本挖掘的漏洞預測中詞嵌入算法的價值,使用word2vec 和fast-text 兩種模型學習代碼標記之間的語法語義關(guān)系,使用CNN 和RNN 模型預測文件中是否含有漏洞.文獻[111]的作者發(fā)現(xiàn),使用用于生成單詞嵌入向量的算法時,模型的F2-score 增大,且word2vec 算法效果最佳.基于深度學習的漏洞預測模型也成為了研究的熱點.
文獻[93]提出VulDeePecker 系統(tǒng),在漏洞預測任務中引入了深度神經(jīng)網(wǎng)絡(luò)BiLSTM,同時采集了一個用于評估漏洞檢測效果的數(shù)據(jù)集.文獻[112]建立了一套基于深度學習的漏洞預測系統(tǒng),能針對輸入的文件或函數(shù)進行粗粒度預測,也能針對新實例中的某一小代碼塊,進行某幾種漏洞的細粒度預測和定位.文獻[113]提出基于GNN 的Devign 模型,提取了4 種屬性AST、CFG、數(shù)據(jù)流圖(data flow graph,DFG)和自然語言中的代碼序列以完成對代碼的表征.文獻[114]提出的SySeVR 模型使用基于數(shù)據(jù)依賴的語義信息表征代碼.文獻[115]提出了IVDetect 模型,提取代碼中的數(shù)據(jù)和控制依賴關(guān)系生成5 個維度的向量表示,統(tǒng)一交由RNN 模型訓練學習,實驗結(jié)果表明,IVDetect 模型帶來了精度的提升并能夠定位到漏洞所在函數(shù)塊.基于此,文獻[116]提出了LineVul 模型,使用CodeBERT 預訓練模型完成代碼的詞向量轉(zhuǎn)化,使用行粒度數(shù)據(jù)集進行訓練,使用GNN 捕獲文本中的依賴關(guān)系,模型得到更高預測準確性的同時能夠定位漏洞所在代碼行.
討論7:從文本挖掘的角度來提取文件中的漏洞特征能夠更充分地捕獲代碼的語法語義特征.計算機算力的提升和深度學習方法的引入也使得研究者得以從復雜冗長的代碼中提取出豐富的特征.這一領(lǐng)域的學者們主要圍繞如何完成代碼到連續(xù)值向量的轉(zhuǎn)換以及深度學習模型的搭建對漏洞預測任務的優(yōu)化提升展開研究.通過總結(jié)歸納發(fā)現(xiàn)在代碼特征表征階段,AST 和RNN 這2 個思路被大多數(shù)研究者所選擇,AST 可以很好地輔助理解代碼中的邏輯結(jié)構(gòu),RNN 則可以在代碼量巨大的文件中捕獲長距離的依賴關(guān)系.除了AST 和RNN,近年來的工作開始逐漸轉(zhuǎn)向大規(guī)模語言模型(例如CodeBERT),這些大規(guī)模語言模型在程序語言任務上進行了預訓練,因此可以更好地捕獲和理解程序語言特征以應用于各項程序語言相關(guān)的下游任務.
觀點4:即便使用了AST 來表征代碼的語法結(jié)構(gòu),如何用向量盡可能充分地表征一個代碼文件依舊是研究的熱點所在.當代碼量過大時,RNN 對于代碼中的依賴關(guān)系并不能充分捕獲,梯度消失問題依舊存在,所以或許一種新的學習模型能夠給漏洞預測領(lǐng)域的研究帶來突破.此外,目前漏洞預測的結(jié)果較為單一,無法全方位多角度地描述漏洞,因此更細粒度的漏洞預測結(jié)果也是近年來研究的一個熱點.
5.2 漏洞預測和缺陷預測的區(qū)別與聯(lián)系
5.2.1 漏洞與缺陷的區(qū)別與聯(lián)系
漏洞與缺陷不是2 個完全分離的概念,具體來說漏洞是一種特殊的安全性缺陷.
文獻[117]表示軟件缺陷是導致功能單元無法執(zhí)行其所需功能的功能性缺陷,軟件漏洞是軟件規(guī)范、開發(fā)或配置中的缺陷實例,漏洞的執(zhí)行會違反安全策略.文獻[118]認為漏洞是缺陷的子集,漏洞是一種特定類型的安全性軟件缺陷.文獻[119]表示,漏洞是能夠被人利用來進行入侵行為的缺陷,漏洞的出現(xiàn)是人嘗試攻擊的結(jié)果,而不是機器運行的結(jié)果.
根據(jù)文獻的調(diào)研結(jié)果,缺陷與漏洞之間的相似性與不同如表10 所示.漏洞與缺陷的產(chǎn)生都與硬件[120]、代碼的復雜性[117-119]以及編程人員能力[121]有關(guān),且都會對軟件造成巨大的影響.文獻[120]指出硬件在漏洞和缺陷的產(chǎn)生過程中扮演了重要的角色.絕大多數(shù)的電子設(shè)備都采用典型的片上系統(tǒng)(system-on-chip,SoC)作為設(shè)備的核心部件,它由多個知識產(chǎn)權(quán)(intellectual property,IP)組成,包括處理器、內(nèi)存和輸入輸出設(shè)備等.為了降低SoC 設(shè)計成本并且滿足上市時間的要求,SoC 的開發(fā)涉及多個第三方公司的供應鏈.然而,第三方的IP 依賴性也引起了硬件安全問題,因為從不受信任的供應商收集的硬件IP 帶有硬件木馬、后門等其他問題.文獻[121]指出軟件開發(fā)者的經(jīng)驗和代碼復雜性與缺陷密切相關(guān),該文作者對2003—2011 年期間Linux 的不同版本進行了分析,研究發(fā)現(xiàn)盡管Linux 的規(guī)模在不斷增加,但缺陷數(shù)量呈現(xiàn)減少的趨勢.此外,Block,Null 等類型缺陷仍然在新的文件中引入和修復,但這些類型缺陷的影響各不相同.與缺陷不同的是,攻擊者可以利用漏洞實施一系列攻擊,造成更為嚴重的后果.
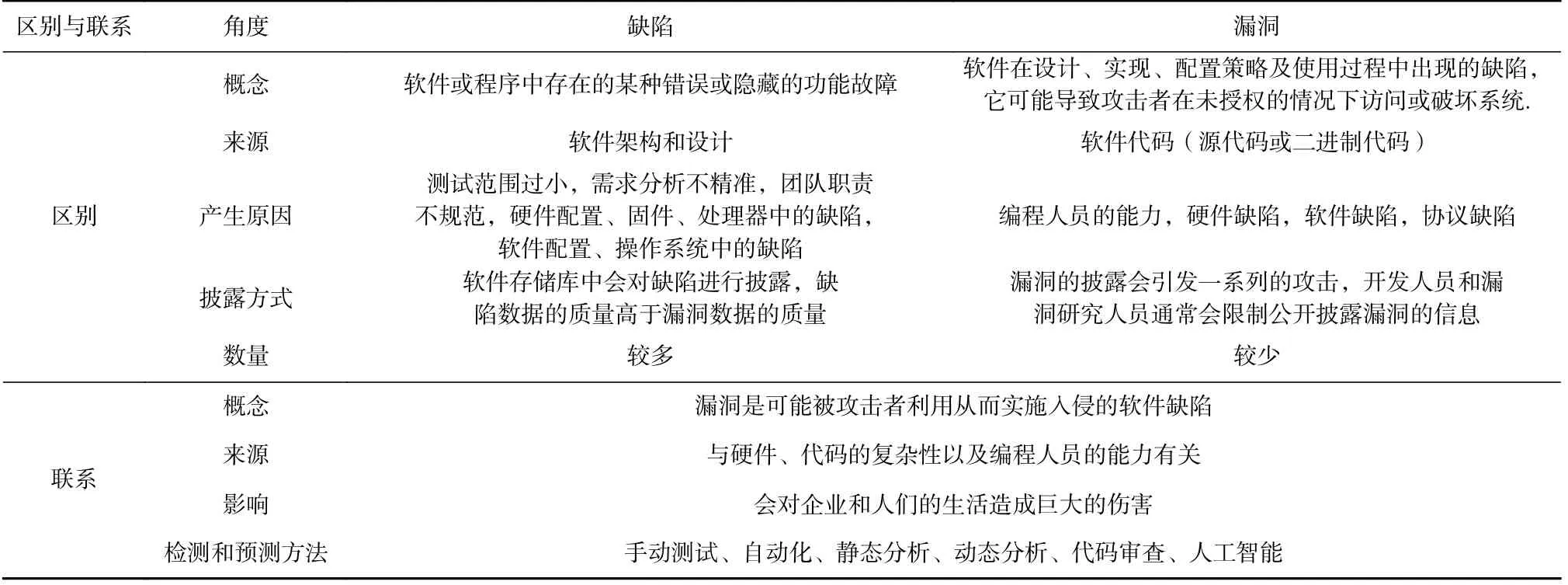
Table 10 Differences and Connections Between Defects and Vulnerabilities表10 缺陷和漏洞的區(qū)別與聯(lián)系
文獻[122]的結(jié)果表明,沒有一套通用的指標可以有效地預測漏洞,漏洞預測不像缺陷預測那么容易,在相同的度量元下,缺陷預測可以獲得合理的精度和召回率,但是漏洞預測的精度和召回率卻不盡如人意.文獻[123]使用3 種傳統(tǒng)的缺陷度量構(gòu)建了缺陷預測模型和漏洞預測模型,測量缺陷預測模型預測漏洞文件的準確性,結(jié)果表明傳統(tǒng)的缺陷預測指標可以檢測大部分易受攻擊的文件,但是誤報率較高.文獻[124]發(fā)現(xiàn),缺陷預測和漏洞預測模型提供了相似的預測性能,當模型使用傳統(tǒng)的軟件度量時,兩者可以互換使用,且缺陷和漏洞預測的性能在很大程度上受先前版本中報告的缺陷數(shù)量和漏洞數(shù)量的影響.
討論8:基于軟件度量的缺陷預測和漏洞預測提供了相似的預測性能.但是傳統(tǒng)的軟件度量不能識別語義不同的代碼,因為大多數(shù)情況下2 段代碼具有相同的復雜度,但是受到的攻擊可能不同.未來研究者可以從語義角度自動提取缺陷和漏洞相關(guān)特征,探究缺陷預測模型在漏洞預測問題上的可移植性.
5.2.2 基于語法語義的預測模型
隨著人工智能技術(shù)在各個領(lǐng)域表現(xiàn)出強大的預測能力,近年來安全研究領(lǐng)域也引入人工智能技術(shù)用于執(zhí)行缺陷預測和漏洞預測任務.
缺陷和漏洞預測的研究需要提取不同的軟件度量,基于人工智能技術(shù)的預測模型也逐漸有了類似的結(jié)構(gòu),包括向量表征、提取特征和ML/DL 分類器訓練等流程.通過對缺陷和漏洞任務中的深度學習模型統(tǒng)計發(fā)現(xiàn),CNN,RNN,DBN 等模型均是缺陷和漏洞預測任務中的常見方法,大量的研究工作用它們搭配不同的特征提取方法進行預測.
AST 能夠高效地表征程序語言的語法語義,因此AST 特征提取是目前最主流的缺陷預測和漏洞預測的向量表征方法.由于軟件代碼平均長度較長,所以許多研究也開始使用LSTM 模型來捕獲長距離代碼之間的語義依賴關(guān)系,基于LSTM 模型的注意力機制被廣泛用于定位具體缺陷和漏洞的位置.隨著BERT 模型的出現(xiàn),一些大規(guī)模語言模型加入數(shù)據(jù)流、控制流等深層次的程序語言依賴關(guān)系來幫助模型更好地捕獲和理解程序語言的語義特征.
討論9:隨著深度神經(jīng)網(wǎng)絡(luò)的可解釋性逐步增強,面臨具體問題時應當選擇的網(wǎng)絡(luò)模型也愈發(fā)明晰.而缺陷與漏洞的預測模型越來越相似,也從某方面說明2 個任務在實現(xiàn)思路上具有較強的共性,缺陷預測的可移植性問題也值得探究.
6 未來研究展望
本節(jié)通過梳理和歸納缺陷預測和漏洞預測任務的研究成果,總結(jié)了這2 個研究領(lǐng)域現(xiàn)階段面臨的挑戰(zhàn)與機遇,如表11 所示.

Table 11 Opportunities and Challenges of Defect Prediction and Vulnerability Prediction Tasks表11 缺陷預測和漏洞預測任務的挑戰(zhàn)與機遇
6.1 數(shù)據(jù)集的來源與處理
缺陷預測常用數(shù)據(jù)集及其屬性如表4 所示,研究者主要使用NASA,PROMISE,AEEEM 缺陷公共倉庫中的CM1,JM1,KC1,KC2,KC3 等數(shù)據(jù)集進行缺陷預測相關(guān)研究,但這些缺陷數(shù)據(jù)集大多數(shù)已經(jīng)無人維護.
隨著深度神經(jīng)網(wǎng)絡(luò)(deep neural network,DNN)在缺陷預測模型中的發(fā)展,預測模型對于數(shù)據(jù)集質(zhì)量的要求也越來越高.這些公共數(shù)據(jù)集不包含缺陷相關(guān)的細節(jié)信息,不能給DL 模型提供充分的特征信息.因此,創(chuàng)建新的數(shù)據(jù)集、增加多標簽預測是未來的研究點.
除了數(shù)據(jù)集的來源,數(shù)據(jù)集的標注也是一個值得關(guān)注的方面.當前研究發(fā)現(xiàn)通過GNN 或者注意力機制等方法能夠具體定位到預測缺陷和漏洞出現(xiàn)的函數(shù)塊或代碼行,并且數(shù)據(jù)標注越細粒度,模型所能捕獲的信息也越具體.
目前軟件缺陷預測和漏洞預測使用的數(shù)據(jù)集往往具有類不平衡、維度過高、預測特征不足、分類標簽不足等缺點.類不平衡和維度過高問題可以通過研究者人工規(guī)范化或者降維處理來緩解,但特征和標簽不足的問題則只能尋求更加高質(zhì)量、平衡且無噪音的數(shù)據(jù).因此,為了更好地預測缺陷、改善資源分配和修復缺陷代碼,研究者需要創(chuàng)建一個高質(zhì)量的缺陷數(shù)據(jù)集.
6.2 代碼向量表征方法
目前的代碼向量表征研究嘗試了包括變量名稱和類型、AST、程序依賴圖、數(shù)據(jù)依賴在內(nèi)的多種方法來表征代碼蘊含的語法語義信息.
除了單一表征方法外,許多研究也著眼于多維度的混合表征方法,并給模型帶來了一定的性能提升.其中,AST 能夠出色提取代碼中語法結(jié)構(gòu)特征,因此被廣泛應用于各種模型的代碼表征階段.但如何在不丟失語法結(jié)構(gòu)特征和語義信息內(nèi)容的前提下,將源代碼嵌入到向量空間,從而更好地完成代碼表征工作,仍需要研究者們繼續(xù)探索.
6.3 預訓練模型的提高
人工定義的各種代碼表征方法似乎已經(jīng)走到一個瓶頸,當前許多工作嘗試了各種方法來提取代碼中的特征,但都不能全面地捕獲程序語言的全部語義信息,于是有的研究工作開始嘗試引入code2vec模型.
近年來出現(xiàn)的Glove 等詞向量模型給代碼表征帶來了一定的啟發(fā).最近人工智能領(lǐng)域也提出了許多諸如CodeBERT 的大規(guī)模預訓練程序語言模型,但它不能深入地捕獲到程序語言的語義級別信息,它的后繼者GraphCodeBERT 加入了數(shù)據(jù)流的依賴關(guān)系,得到了更多的代碼語義表征,并在多個程序分析相關(guān)下游任務中取得了SOTA 成果.可以預見,引入更好的預訓練模型也會給漏洞挖掘領(lǐng)域的DL 方法帶來極大提升.
6.4 深度學習模型探索
由于軟件代碼的長度較長,代碼中經(jīng)常出現(xiàn)遠距離的數(shù)據(jù)和控制依賴關(guān)系,因此盡可能完整地提取其中的語法結(jié)構(gòu)特征和語義信息內(nèi)容一直是相關(guān)研究面臨的一個難題.
選擇合適的深度學習模型就可以幫助研究者更好地捕獲語法語義信息,目前主流的觀點認為使用具有記憶門單元的RNN 系列模型可以幫助提取部分遠距離依賴關(guān)系的特征,但有些研究指出RNN 在更長的代碼文本中同樣力有未逮.因此,更適合缺陷和漏洞的預測任務的深度學習模型仍待研究者們進一步探索.
6.5 細粒度預測技術(shù)
為了在實際應用中減少查找、修復缺陷和漏洞的成本,預測任務中也產(chǎn)生了定位可能出現(xiàn)的缺陷或漏洞的位置需求,因此如何更加細粒度地定位缺陷和漏洞也是未來研究工作的突破方向之一.
通過各種圖算法或者注意力機制,目前大部分預測工作可以對代碼文件或者具體函數(shù)進行缺陷和漏洞定位,甚至還有部分研究工作實現(xiàn)了將缺陷和漏洞具體定位到代碼行.可以預見,細粒度預測技術(shù)會隨著算法的改進和數(shù)據(jù)集的精細化而得到提升.
6.6 缺陷預測和漏洞預測模型的遷移
缺陷和漏洞都與代碼或者設(shè)計的復雜性有關(guān).漏洞和缺陷之間的相似性使得能夠用傳統(tǒng)的缺陷預測指標進行漏洞預測.如果缺陷預測模型可以用于漏洞預測,則不需要花費額外的時間和資源為漏洞創(chuàng)建單獨的模型.
基于軟件度量的缺陷預測模型在一定程度上提供類似于漏洞預測的功能.一些缺陷預測模型可能會具有預測漏洞的性能,但是這種缺陷預測模型并不是專門為預測漏洞而產(chǎn)生的,如果要預測漏洞則需要對模型進行一定的改進.未來,研究者可以開發(fā)一種通用模型區(qū)分缺陷與漏洞.
7 結(jié)束語
軟件缺陷預測借助機器學習或深度學習方法提前發(fā)現(xiàn)軟件缺陷,可以減少軟件修復成本并提高產(chǎn)品的質(zhì)量.研究開源軟件缺陷預測,能夠提高對各類項目的軟件缺陷的認識,更好地指導代碼檢測和測試工作.本文通過調(diào)研分析軟件預測研究領(lǐng)域相關(guān)文獻,以機器學習和深度學習為切入點,梳理了基于軟件度量和基于語法語義的2 類預測模型.基于這2類模型,分析了軟件缺陷預測和漏洞預測之間的區(qū)別與聯(lián)系.最后,對軟件預測的六大前沿熱點問題進行詳盡分析,指出軟件缺陷預測未來的發(fā)展方向.
通過總結(jié)軟件缺陷預測相關(guān)的研究,本文認為,未來的研究方向可以從4 個方面展開:1)創(chuàng)建一個高質(zhì)量的缺陷數(shù)據(jù)集有助于預測缺陷、改善資源分配和修復缺陷代碼;2)構(gòu)建一種最大程度蘊含語法語義信息的表征方法、利用其他領(lǐng)域訓練好的詞向量嵌入能夠提高缺陷預測模型的性能;3)適應細粒度的預測技術(shù)可以更加精確地定位缺陷和漏洞可能出現(xiàn)的位置;4)開發(fā)一種通用模型區(qū)分缺陷與漏洞,可以更好地預測易受攻擊的代碼位置.
作者貢獻聲明:田笑負責設(shè)計研究方案及論文撰寫和最終版本的修訂;常繼友負責調(diào)研分析、數(shù)據(jù)統(tǒng)計及畫圖;張弛負責部分論文的撰寫;榮景峰和王子昱負責調(diào)研分析;張光華、王鶴、伍高飛、胡敬爐負責論文的整體修訂;張玉清提出論文的整體研究思路,及最終論文的審核與修訂.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
