基于 BERT?BiLSTM?CRF 的非法出入境筆錄文本提取模型
2023-07-17 09:30:30郭婧婧李俊杰周衛(wèi)等
計算機應用文摘 2023年13期
郭婧婧 李俊杰 周衛(wèi)等

摘要:為提高非法出入境筆錄信息提取方面的命名實體識別能力,提出了一種融合語言模型的非法出入境筆錄信息提取模型。該模型首先利用BERT模型對輸入序列中的單詞進行編碼,得到每個單詞的向量表示,然后將這些向量輸入到BiLSTM網(wǎng)絡中,利用LSTM網(wǎng)絡時輸入序列進行建模,學習輸入序列中的上下文信息和語法結(jié)構(gòu)等。最后,通過一個CRF層對BiLSTM網(wǎng)絡的輸出進行標注.從而得到最終的輸出序列。實驗結(jié)果表明,該模型能較好地應用于非法出入境筆錄文本提取的任務。在與廣西邊防檢查總站的合作項目里,最終將該模型應用于實際生產(chǎn)工作中,為邊檢警方的筆錄提取工作提供便利。
關(guān)鍵詞:非法出入境筆錄文本;命名實體識別;BERT預訓練語言模型;BiLSTM;CRF
中圖法分類號:TP391 文獻標識碼:A
1 引言
廣西地處西南邊陲,與越南毗鄰,是中國對外開放的“橋頭堡”,且擁有多個國家級和省級的對外開放口岸。近年來,越南和廣西之間的交流日益頻繁,但大規(guī)模、高頻次的跨境流動人口中夾雜大量非法勞工,相關(guān)部門在對非法入境人員進行立案時,必須對被收容人的姓名、性別、國籍、民族、戶籍、學歷、身份證、手機等多項個人信息做詳細的記錄,而傳統(tǒng)的人工采集方式需要消耗大量人力物力,且效率低下。為解決上述問題,本文通過廣西出入境邊防檢查總站提供的原始筆錄數(shù)據(jù)構(gòu)建非法出入境筆錄文本的命名實體識別語料庫,提出了基于預訓練模型的非法出入境筆錄信息提取模型,并取得了較好的效果。
2 相關(guān)工作
1996 年,R. Grishman 和B. Sundheim 在MessageUnderstanding Conference(MUC?6) 上提出了“命名實體”的概念,該概念被廣泛應用于自然語言處理領(lǐng)域[1] 。早期的命名實體識別主要依賴于規(guī)則和詞典等手動構(gòu)建的模板,與被識別的文檔進行匹配以抽取實體。之后,基于特征工程和機器學習的方法成為主流,常用的方法包括最大熵[2] 、隱馬爾可夫模型[3] 、支持向量機[4] 和條件隨機場[5] 等。近年來,命名實體識別中出現(xiàn)了越來越多的神經(jīng)網(wǎng)絡模型[6] ,例如LSTM 模型[7] ,在LSTM 的基礎(chǔ)上,研究人員引入條件隨機場來增強模型的約束條件,預訓練模型也逐漸被廣泛應用于命名實體識別領(lǐng)域,提高了中文實體識別的效果。
國內(nèi)外對于非法出入境筆錄信息的命名實體研究較少,且可用的數(shù)據(jù)集稀缺,該領(lǐng)域的信息抽取問題亟待解決,主要包括:(1)基于機器學習的實體識別方法對人工特征依賴驗證,難以捕獲長距離上下文信息;(2)目前專門針對筆錄信息提取領(lǐng)域的命名實體識別研究還十分稀少,也未構(gòu)建相應的語料庫;(3)筆錄信息中常包含特征相似的實體,如越南身份證號碼和越南手機號碼均為數(shù)字組成,且位數(shù)相同,對于存在相似特征的實體,會增加實體提取的難度。
3 BERT?BiLSTM?CRF 模型
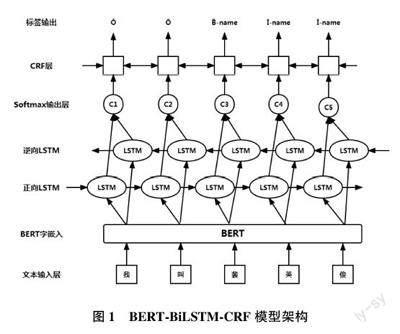
本文將非法出入境筆錄文本作為原始語料,分段清洗后并對其進行標注。這些標注數(shù)據(jù)被輸入到BERT?BiLSTM?CRF 模型中進行實體識別。該模型由3 個部分組成。(1)BERT 預訓練模型,用于提取文本的豐富特征,并表示為字向量。(2)BiLSTM 模型,通過雙向循環(huán)神經(jīng)網(wǎng)絡提取雙向文本信息,將上一層輸出的字向量輸入到BiLSTM 模型中得到雙向狀態(tài)序列,進一步獲取數(shù)據(jù)隱藏層的高級特征。(3)CRF 模型,用于根據(jù)相鄰標簽的概率關(guān)系獲得最優(yōu)標注序列。結(jié)合CRF 中的狀態(tài)轉(zhuǎn)移矩陣對BiLSTM 模型的輸出序列進行約束處理,根據(jù)相鄰標簽信息得到一個全局最優(yōu)標簽序列。通過將三者結(jié)合起來,BERT?BiLSTM?CRF 模型可以獲得語義表示和序列信息的最佳結(jié)合。BERT?BiLSTM?CRF 模型架構(gòu)如圖1 所示。
3.1 BERT
BERT(Bidirectional Encoder Representations fromTransformers)是一種預訓練語言模型,由J. Devlin 等在2018 年提出。其基于Transformer 架構(gòu),主要由2個部分組成:編碼器和多頭注意力機制。BERT 使用大量的文本數(shù)據(jù)進行預訓練,學習了語言中的上下文關(guān)系。在實際應用中,BERT 可以將文本數(shù)據(jù)轉(zhuǎn)換為語義表示,并將這些表示作為上層模型的輸入,以解決各種自然語言處理任務。
3.2 BiLSTM
BiLSTM 是雙向LSTM 的縮寫,意味著該模型同時從正向和反向2 個方向讀取序列數(shù)據(jù)。雙向LSTM 的模型結(jié)構(gòu)如下所示:一個正向LSTM 層,讀取序列數(shù)據(jù)從左到右;一個反向LSTM 層,讀取序列數(shù)據(jù)從右到左;兩個LSTM 層的輸出連接在一起,作為最終的語義表示。
3.3 CRF
CRF(Conditional Random Fields)是一種用于標記序列數(shù)據(jù)的生成模型。CRF 層利用序列的上下文信息和語法結(jié)構(gòu),對每個單詞的標注結(jié)果進行聯(lián)合建模,使得標注結(jié)果不僅取決于當前單詞的特征,還考慮了整個序列中標注結(jié)果的一致性。
4 數(shù)據(jù)集及參數(shù)指標
4.1 數(shù)據(jù)集
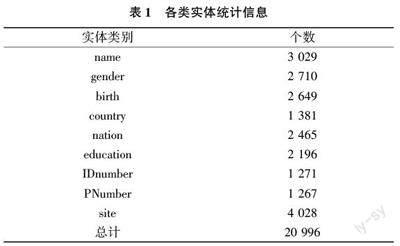
本文采用的是自建數(shù)據(jù)集,所用的語料為廣西邊防檢查總站提供的非法出入境筆錄文本數(shù)據(jù),通過對筆錄文本數(shù)據(jù)進行清洗分類,選取有效文本2 822 個,通過分析筆錄文本數(shù)據(jù)的特點,設置了9 種實體類別,各類實體的統(tǒng)計信息如表1 所列。
4.2 參數(shù)指標
本文采用命名實體識別的3 個常用評價指標,即準確率(P)、召回率(R)和F1 值。各項指標的具體計算公式如式(1) ~式(3)所示:
5 實驗與分析
5.1 實驗環(huán)境
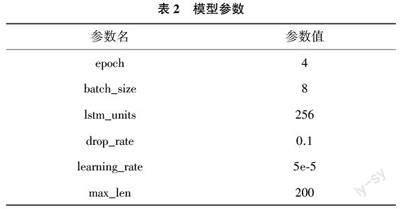
實驗采用的網(wǎng)絡架構(gòu)為Tensorflo,1.14.0, Python版本為3.7。本文模型參數(shù)設置如表2 所列。
5.2 實驗結(jié)果
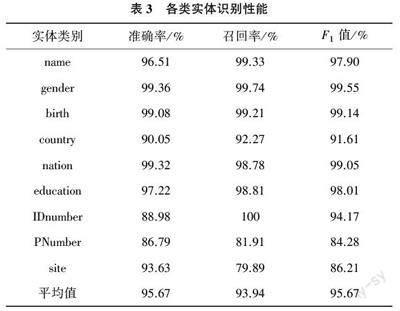
本文構(gòu)建數(shù)據(jù)集的標注采用的是BIO 的方式,并將其分為訓練集、測試集和驗證集,占比分別為70%,15%,15%。模型識別結(jié)果如表3 所列。
模型對于非法出入境筆錄信息中name,gender,birth,nation,education 的識別效果都達到了95% 以上,對country,IDnumber,PNumber,site 的識別效果都達到了80%以上。由于非法出入境的筆錄文本中部分被查獲人員的IDnumber 和PNumber 有缺失,導致數(shù)據(jù)量不足,因此實體識別存在一定難度。但在有限的數(shù)據(jù)樣本中,本文的模型結(jié)果仍能達到95%左右的識別水平。
6 結(jié)束語
本文針對非法出入境筆錄文本提取的專業(yè)領(lǐng)域分析,采用了BERT?BiLSTM?CRF 模型,并對其進行命名實體識別,提取出筆錄文本中被查獲人的個人信息。實驗結(jié)果表明,在自建的非法出入境筆錄文本數(shù)據(jù)集上,采用BERT?BiLSTM?CRF 模型表現(xiàn)良好,這為后續(xù)的筆錄信息分析提供了基礎(chǔ)。在未來的工作中,需要繼續(xù)完善數(shù)據(jù)集以提高模型的魯棒性,同時增加實體類別的劃分,以平衡每個實體類別的數(shù)量。
參考文獻:
[1] GRISHMAN R, SUNDHEIM B M. Message understandingconference?6:A brief history[C] ∥COLING,1996 Volume1: The 16th International Conference on ComputationalLinguistics,1996,1:466?471.
[2] BERGER A,DELLA PIETRA S A,DELLA PIETRA V J.Amaximum entropy approach to natural language processing[J].Computational linguistics,1996,22(1):39?71.
[3] HU W, TIAN G, KANG Y, et al. Dual sticky hierarchicalDirichlet process hidden Markov model and its application tonatural language description of motions[J].IEEE transactionson pattern analysis and machine intelligence,2017,40(10):2355?2373.
[4] CHEN P H,LIN C J,SCH?LKOPF B. A tutorial on ν ‐support vector machines[J]. Applied Stochastic Models inBusiness and Industry,2005,21(2):111?136.
[5] LEE C,HWANG Y G,OH H J,et al. Fine?grained namedentity recognition using conditional random fields for questionanswering[ J]. Lecture notes in computer science, 2006,4182: 581?587.
[6] COLLOBERT R, WESTON J, BOTTOU L, et al. Naturallanguage processing (almost) from scratch[J]. Journal ofmachine learning research, 2011, 12 ( ARTICLE): 2493?2537.
[7] HAMMERTON J. Named entity recognition with long short?term memory[C]∥Proceedings of the seventh conference onNatural language learning at HLT?NAACL 2003,2003: 172?175.
作者簡介:
郭婧婧(1996—),碩士,研究方向:自然語言處理。
李俊杰(1984—),本科,研究方向:應用系統(tǒng)研發(fā)( 通信作者)。
