基于多表征融合的函數(shù)級代碼漏洞檢測方法
2023-07-01 06:36:40田振洲呂佳俊王凡凡
西安郵電大學(xué)學(xué)報 2023年1期
田振洲,呂佳俊,王凡凡
(西安郵電大學(xué) 計算機(jī)學(xué)院,陜西 西安 710121)
近年來,網(wǎng)絡(luò)攻擊事件頻發(fā),木馬、蠕蟲和勒索軟件等層出不窮,對網(wǎng)絡(luò)安全構(gòu)成了嚴(yán)重威脅。例如,2017年的Apache Struts漏洞導(dǎo)致1.43億消費(fèi)者的金融數(shù)據(jù)被泄露,造成不可估量的經(jīng)濟(jì)損失[1-2]。網(wǎng)絡(luò)攻擊得以實(shí)施的根源在于軟件漏洞的普遍存在。截至目前,通用漏洞披露(Common Vulnerabilities &Exposures,CVE)網(wǎng)站上已收錄的漏洞高達(dá)17余萬條[3],且漏洞數(shù)量依然呈爆發(fā)式增長態(tài)勢。
現(xiàn)有漏洞檢測方法主要分為基于代碼相似性的漏洞檢測[4-6]、基于規(guī)則的漏洞檢測[7]和基于機(jī)器學(xué)習(xí)的漏洞檢測[8-9]。基于代碼相似性進(jìn)行漏洞檢測的核心思想是,相似的代碼中很可能包含相同的漏洞,但用其檢測并非由代碼復(fù)制引入的漏洞時,存在較高的漏報率。基于規(guī)則的漏洞檢測方法定義的漏洞規(guī)則具有很強(qiáng)的主觀性,難以全面考慮各種區(qū)分有漏洞和無漏洞的情況,導(dǎo)致方法往往存在較高的漏報率和誤報率。基于機(jī)器學(xué)習(xí)的漏洞檢測方法,按照是否需要專家定義特征,又分為基于傳統(tǒng)機(jī)器學(xué)習(xí)和基于深度學(xué)習(xí)的方法兩類。基于傳統(tǒng)機(jī)器學(xué)習(xí)的漏洞檢測方法不依賴定義的漏洞規(guī)則,但依然需要人為地結(jié)合專業(yè)的領(lǐng)域知識,利用特征工程篩選出對于刻畫漏洞至關(guān)重要的代碼特征,然后利用機(jī)器學(xué)習(xí)算法實(shí)現(xiàn)漏洞檢測。
深度學(xué)習(xí)在程序語言建模[10]和情感分析[11]等諸多領(lǐng)域有著廣泛應(yīng)用,近年來也逐漸被應(yīng)用于程序漏洞檢測中。Xu等[12]利用神經(jīng)網(wǎng)絡(luò)模型在函數(shù)級上進(jìn)行基于代碼相似性的二進(jìn)制漏洞檢測。Russell等[13]針對C/C++源代碼,利用卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)處理函數(shù)Token序列,實(shí)現(xiàn)漏洞檢測。基于深度學(xué)習(xí)的漏洞檢測方法不需要手工定義特征,而是借助深度神經(jīng)網(wǎng)絡(luò)強(qiáng)大的特征學(xué)習(xí)能力,自動抽取漏洞模式或漏洞相關(guān)的指示性特征。但是,僅利用代碼的某一特定的表征結(jié)構(gòu)進(jìn)行漏洞檢測,導(dǎo)致深度學(xué)習(xí)模型難以充分學(xué)習(xí)代碼中蘊(yùn)含的深層語義信息,不利于深層漏洞的檢測。
針對上述問題,擬提出一種基于多表征融合的代碼漏洞檢測(Sequence and Structure Fusion based Vulnerability Dectection,S2FVD)方法。對不同的代碼表征使用適配的深度神經(jīng)網(wǎng)絡(luò)模型,提取深層語義特征并進(jìn)行有機(jī)融合,以期充分學(xué)習(xí)代碼中蘊(yùn)含的語義信息,實(shí)現(xiàn)代碼漏洞的精準(zhǔn)檢測。
1 S2FVD方法整體結(jié)構(gòu)
S2FVD方法為保證漏洞檢測的粒度,先選取函數(shù)而非整個程序作為基本分析單元,通過對函數(shù)的詞法和語法解析,從中構(gòu)建Token序列和屬性控制流圖(Attributed Control Flow Graph,ACFG),作為函數(shù)的兩種不同的原始表征結(jié)構(gòu)。其次,對Token序列中的Token、屬性控制流圖中的節(jié)點(diǎn)進(jìn)行詞嵌入,得到初始向量表示,并在嵌入的基礎(chǔ)上,對屬性控制流圖中的節(jié)點(diǎn)屬性使用TextCNN模型提取節(jié)點(diǎn)初始特征。然后,分別使用針對序列的神經(jīng)網(wǎng)絡(luò)TextCNN和圖卷積神經(jīng)網(wǎng)絡(luò)[14](Graph Con-volutional Nueral Network,GCN ),從中抽取深層次的代碼語義特征。最后,考慮到Token序列和ACFG是從不同角度(序列和結(jié)構(gòu))對同一函數(shù)的語義進(jìn)行的互補(bǔ)性描述,因此通過直觀的向量拼接操作,將從二者中抽取的特征向量進(jìn)行有機(jī)融合,并送入分類層,實(shí)現(xiàn)函數(shù)級漏洞的精準(zhǔn)檢測。S2FVD方法的整體結(jié)構(gòu)示意圖如圖1所示。
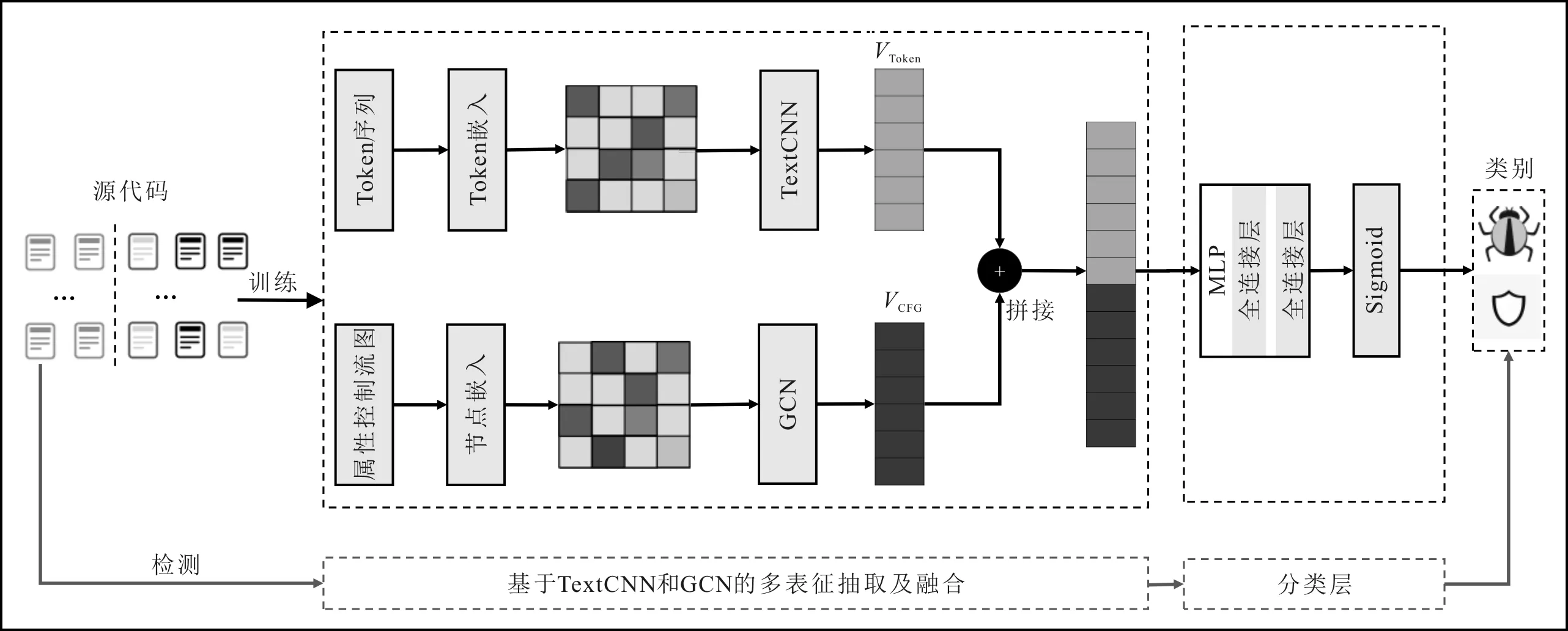
圖1 S2FVD方法的整體結(jié)構(gòu)示意圖
2 原始代碼表征提取
為了充分學(xué)習(xí)代碼所承載的語義信息,檢測出C/C++代碼中的漏洞,需要先提取每個函數(shù)的Token序列和屬性控制流圖,作為每個函數(shù)的原始代碼表征。
2.1 Token序列提取
Token序列相當(dāng)于按自然語言處理的方式處理代碼,體現(xiàn)了源代碼的自然順序,一定程度上反映了源代碼所體現(xiàn)的編程邏輯。提取Token序列時,先刪除代碼中的注釋,因為其與漏洞無關(guān)。然后,對代碼進(jìn)行標(biāo)準(zhǔn)化處理,篩選出自定義的變量名和函數(shù)名,對其進(jìn)行統(tǒng)一替換,以去除一些語義無關(guān)的信息。將同一函數(shù)中出現(xiàn)的不同變量和不同函數(shù)名按出現(xiàn)的次序映射為對應(yīng)的符號名,如“VAR1”“VAR2”表示同一函數(shù)中的不同變量,“FUN1”“FUN2”表示同一函數(shù)中的不同函數(shù)名。最后,通過詞法分析,將符號表示中的函數(shù)劃分為一系列標(biāo)記,包括標(biāo)識符、關(guān)鍵字、操作符和符號。函數(shù)轉(zhuǎn)化為Token序列的過程如圖2所示。
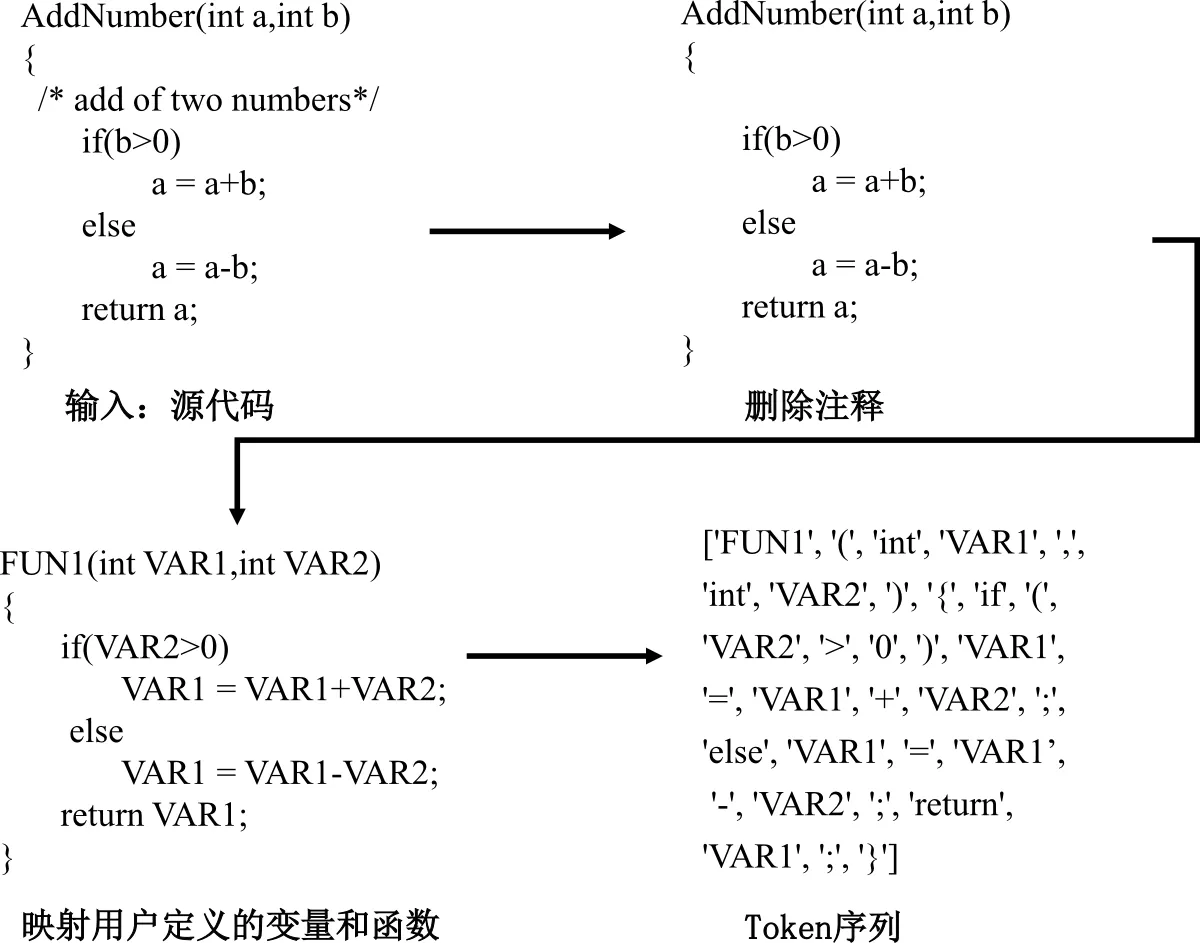
圖2 函數(shù)轉(zhuǎn)化為Token序列的過程
2.2 屬性控制流圖提取
控制流圖(Control Flow Graph,CFG)是程序分析領(lǐng)域廣泛使用的一種代碼表示結(jié)構(gòu),其蘊(yùn)含了程序代碼間的控制依賴等語義信息。進(jìn)一步地,除考慮控制流節(jié)點(diǎn)的依賴關(guān)系外,對控制流節(jié)點(diǎn)內(nèi)的程序語句進(jìn)行抽象以賦予節(jié)點(diǎn)屬性信息,從而構(gòu)建屬性控制流圖作為函數(shù)的另一種原始代碼表征結(jié)構(gòu)。
屬性控制流圖是一個有向圖,定義為G=(V,E,A),其中:V和E分別為頂點(diǎn)和邊的集合;A為頂點(diǎn)包含的信息的集合。在代碼漏洞檢測場景中,每個頂點(diǎn)是控制流圖中的節(jié)點(diǎn),每條邊代表代碼的控制流,節(jié)點(diǎn)所包含的信息作為節(jié)點(diǎn)的屬性。節(jié)點(diǎn)屬性包含節(jié)點(diǎn)的類型和節(jié)點(diǎn)所對應(yīng)的程序語句。每個節(jié)點(diǎn)都有一個類型,為節(jié)點(diǎn)所代表的程序語句的類型。如圖3所示,類型為METHOD的節(jié)點(diǎn)表示方法名,類型為METHOD_RETURN的節(jié)點(diǎn)表示返回值類型,類型為
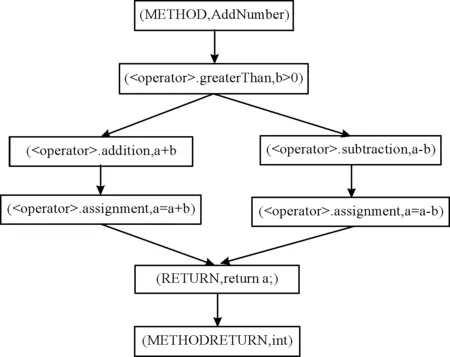
圖3 屬性控制流圖
3 基于多表征融合的漏洞檢測
3.1 基于TextCNN的代碼序列特征提取
對于函數(shù)的Token序列,采用嵌入的方式將單個Token轉(zhuǎn)化為向量表示,再使用TextCNN模型進(jìn)行代碼序列特征的提取。
1)嵌入。標(biāo)準(zhǔn)化后的Token序列必須轉(zhuǎn)換為數(shù)值向量,以便能夠作為深度學(xué)習(xí)模型的輸入。對此,利用Word2Vec詞嵌入算法,將每個獨(dú)特的Token映射成一個高維的數(shù)值向量。具體地,將標(biāo)準(zhǔn)化后的每條Token序列視為一條句子,將序列中的每個Token視為一個單詞。利用gensim庫中提供的skip-gram模型[16],迭代地通過中心詞推斷上下文窗口內(nèi)的其他詞,從而為每個獨(dú)特的Token學(xué)習(xí)一個d維向量。向量維度過高會導(dǎo)致表示空間稀疏,并增加后續(xù)神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練的時空開銷,維度過低,則可能導(dǎo)致含義不同的Token難以準(zhǔn)確區(qū)分。利用Word2Vec進(jìn)行詞嵌入的源代碼分析任務(wù)中,50、100和200為最常見的取值。采取gensim中skip-gram模型的默認(rèn)參數(shù)設(shè)置,即向量維度d和上下文窗口的值分別設(shè)置為100和5,同時,模型迭代訓(xùn)練100次。
2)TextCNN模型。在Token嵌入的基礎(chǔ)上,將每個Token序列轉(zhuǎn)換為原始特征矩陣A∈l×d,即
A=[e1,e2,…,ei,…,el]T
(1)
式中:l為Token序列的長度,Token的實(shí)際數(shù)量因函數(shù)而異,為方便批量訓(xùn)練,采取補(bǔ)零或截斷的方式,將Token序列長度統(tǒng)一調(diào)整為l;ei∈d是序列中Token相應(yīng)的嵌入。
使用卷積核進(jìn)行特征提取,與圖像處理的卷積核不同的是,經(jīng)過詞向量表達(dá)的Token序列為一維數(shù)據(jù),因此,在TextCNN中用一維卷積。在卷積層,采用結(jié)構(gòu)為n×d的m個卷積濾波器對原始特征矩陣A進(jìn)行卷積運(yùn)算,得到特征矩陣A∈(l-n+1)×m,其中,n表示卷積核的大小。為了提取特征模式的不同視圖,使用大小分別為2、3和4的不同卷積核對A進(jìn)行卷積。不同高度的卷積核得到的特征圖(feature map)大小不一樣,使用匯聚函數(shù)使其維度相同,這里使用1D-maxpooling提取出最大值。最后,拼接起來得到特征向量VToken。基于TextCNN的模型結(jié)構(gòu)如圖4所示。
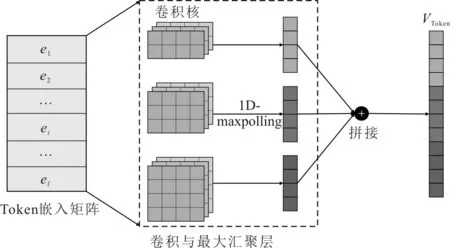
圖4 基于TextCNN的Token序列特征抽取模型
3.2 基于GCN的代碼結(jié)構(gòu)特征提取
帶屬性的控制流圖是圖結(jié)構(gòu),因此可以選擇使用GCN進(jìn)行表示學(xué)習(xí)。GCN的核心思想為學(xué)習(xí)一個函數(shù)映射,通過該映射圖中的節(jié)點(diǎn)聚合其自己特征與其鄰居節(jié)點(diǎn)特征,從而生成節(jié)點(diǎn)的新表示。
1)節(jié)點(diǎn)初始特征提取。首先,將控制流圖中節(jié)點(diǎn)的屬性通過詞法分析解析成Token序列。其次,采取gensim中的skip-gram模型,為每個獨(dú)特的Token學(xué)習(xí)一個w維向量,向量維度設(shè)置為100。將每個節(jié)點(diǎn)的屬性對應(yīng)的Token序列轉(zhuǎn)換為原始特征矩陣N∈Rk×w,其中k是Token序列的長度,設(shè)置為30。然后,使用大小分別為2、3和4的卷積核進(jìn)行特征提取。不同大小的卷積核得到的特征圖大小不一樣,使用匯聚函數(shù),使其維度相同。最后,將生成的表示進(jìn)行連接,經(jīng)過全連接層轉(zhuǎn)化為輸出特征,作為圖中節(jié)點(diǎn)的初始特征。
2)GCN模型。基于GCN的模型結(jié)構(gòu)如圖5所示。
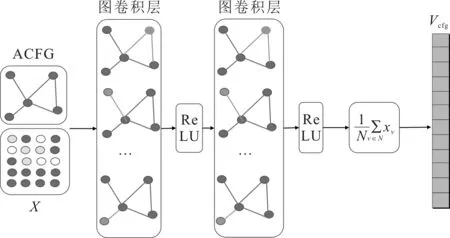
圖5 基于GCN的ACFG結(jié)構(gòu)特征抽取模型
將節(jié)點(diǎn)的初始特征組成一個n×m維的矩陣X,每個節(jié)點(diǎn)之間的關(guān)系也會形成一個n×n維的矩陣A,稱為鄰接矩陣(adjacency matrix)。其中,n為節(jié)點(diǎn)的個數(shù),m為節(jié)點(diǎn)初始特征的維度,X和A是GCN模型的輸入,則GCN模型可用公式表示為
X(l+1)=f(X(l),A)
(2)
式中,X(l)為第l層節(jié)點(diǎn)的特征。
每個節(jié)點(diǎn)與鄰節(jié)點(diǎn)關(guān)系為
(3)
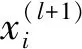
由式(3)可知,每經(jīng)過一層圖卷積,利用節(jié)點(diǎn)與節(jié)點(diǎn)之間的聯(lián)系和節(jié)點(diǎn)自身的特征進(jìn)行聚合,可生成新的節(jié)點(diǎn)表示。在讀出(Readout)操作中,采用均值匯聚的方式,將圖中新的節(jié)點(diǎn)表示的均值作為圖的表示,即
(4)
式中:N為圖中的所有節(jié)點(diǎn);xv是節(jié)點(diǎn)v的特征表示。xg對應(yīng)的特征向量為VCFG。
3.3 融合
融合的方式很多種,常見的有逐點(diǎn)相加和向量拼接兩種方式[18]。逐點(diǎn)相加的數(shù)學(xué)表達(dá)為,現(xiàn)有特征向量v1∈n和v2∈n,為了融合v1和v2,進(jìn)行對應(yīng)位置元素的相加,即v={xi|xi=v1[i]+v2[i],i=1,2,…,n}。進(jìn)行此操作的前提是這兩個向量的維度相同。
向量拼接是一個更為通用的特征融合方法,其數(shù)學(xué)表達(dá)為,現(xiàn)有特征向量v1∈n和v2∈n,則有融合特征向量v=[v1∶v2]∈m+1。對于融合機(jī)制的設(shè)計,考慮到提取的代碼表征分別是從序列和結(jié)構(gòu)的角度對函數(shù)進(jìn)行的互補(bǔ)性描述,因此選擇向量拼接融合的方式,將不同代碼表征學(xué)習(xí)到的特征向量拼接成一個單一的特征向量。
源碼分析工具Joern無法對所有的函數(shù)進(jìn)行正確解析,導(dǎo)致生成的屬性控制流圖數(shù)量略微少于數(shù)據(jù)集中的函數(shù)數(shù)量。因此,先進(jìn)行數(shù)據(jù)處理,將Token序列和屬性控制流圖進(jìn)行一一對應(yīng)。然后,將前面提取出來的特征向量VToken和VCFG直接拼接,得到特征向量Vs=[VToken∶VCFG],維度是384。最后,將特征向量Vs送入全連接層,并利用sigmoid實(shí)現(xiàn)二分類,得到標(biāo)簽的值,其中,0代表目標(biāo)函數(shù)無漏洞,1代表目標(biāo)函數(shù)有漏洞。
4 實(shí)驗
4.1 實(shí)驗環(huán)境與數(shù)據(jù)集
實(shí)驗在RTX 2080Ti GPU的硬件條件與python 3.7的軟件環(huán)境上運(yùn)行,網(wǎng)絡(luò)模型部分基于PyTorch框架和深度圖譜庫(Deep Graph Library,DGL)框架構(gòu)建。使用VDISC(Vulnerability Detection in Source Code)漏洞數(shù)據(jù)集[13],該數(shù)據(jù)集共計包含127萬余個C/C++函數(shù)。利用Clang[19]、Cppcheck[20]和Flawfinder[21]等靜態(tài)漏洞分析工具掃描源代碼得到每個函數(shù)標(biāo)記,即是否存在漏洞以及漏洞對應(yīng)的CWE(Common Vulnerabilities &Exposures)類型。處理生成的語料庫中函數(shù)Token序列長度的分布情況如圖6所示。可以看到,接近95%的Token序列的長度在400以下,約99%的Token序列長度不超過500。考慮到模型學(xué)習(xí)效率和函數(shù)語義覆蓋的完整程度,S2FVD選取400作為默認(rèn)的Token序列截斷或補(bǔ)全的長度。
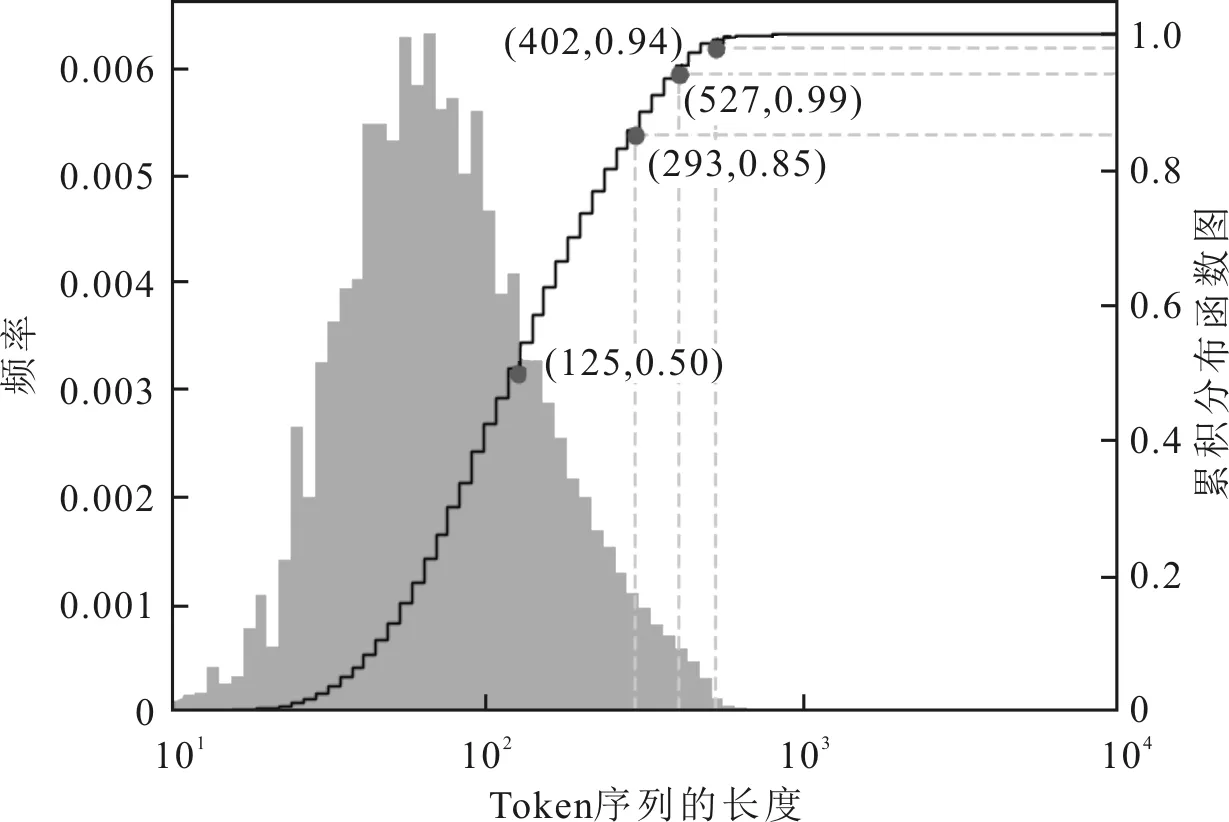
圖6 Token序列長度分布情況
4.2 實(shí)驗與結(jié)果分析
隨機(jī)選取80%的函數(shù)作為訓(xùn)練集,20%的函數(shù)作為測試集。將PR(Precision-Recall)曲線、ROC(Receiver Operating Characteristic)曲線、馬修斯相關(guān)系數(shù)(Matthews Correlation Coefficient,MCC)和F1值作為性能評估指標(biāo),對S2FVD的檢測性能進(jìn)行評估,并與文獻(xiàn)[13]漏洞檢測方法進(jìn)行對比。S2FVD方法的PR和ROC曲線分別如圖7和圖8所示,兩種方法的檢測結(jié)果如表1所示。

表1 兩種方法的檢測結(jié)果
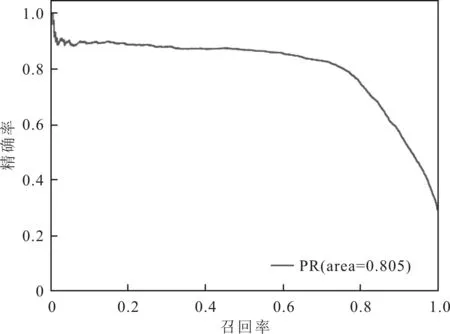
圖7 S2FVD方法的PR曲線評估結(jié)果
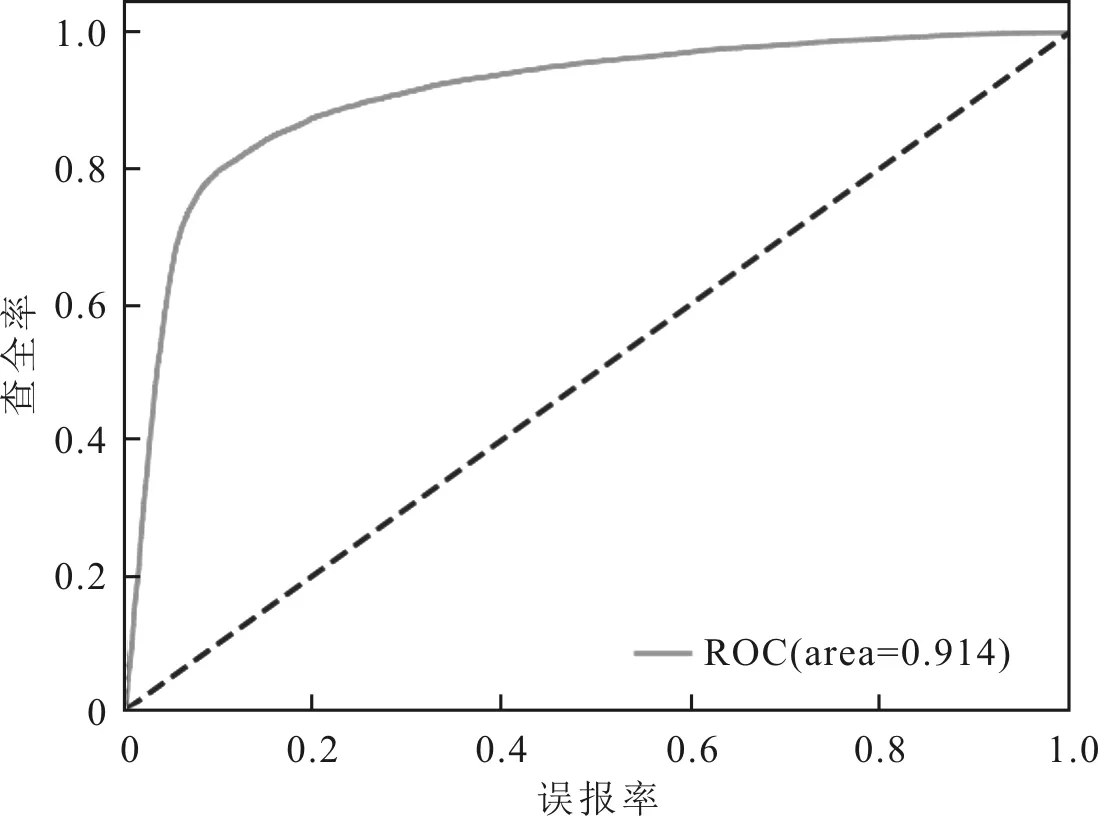
圖8 S2FVD的ROC曲線評估結(jié)果
由表1可以看到,S2FVD 方法的4種性能評估指標(biāo)均優(yōu)于文獻(xiàn)[13]漏洞檢測方法。其中,PR和ROC曲線下的面積(Area Under Curve,AUC)分別提高了28.7%和1%。特別地,F1值提高了21.7%。F1值綜合考慮了精確率和召回率的計算結(jié)果,較全面地評價了分類器的性能,其值越大說明檢測效果越理想。由此得出,S2FVD方法在漏洞檢測方面優(yōu)于文獻(xiàn)[13]漏洞檢測方法。這是因為S2FVD綜合了Token序列和屬性控制流圖兩種不同的代碼表征形式,分別利用適配的表示學(xué)習(xí)模型學(xué)習(xí)函數(shù)語義的不同側(cè)面并進(jìn)行融合,使得抽取到的函數(shù)語義特征更加全面。
為了驗證多表征融合對代碼漏洞的檢測效果好于單一表征,下面進(jìn)行消融實(shí)驗,對采取單一表征訓(xùn)練好的模型的檢測效果進(jìn)行評估。將Token序列通過TextCNN模型學(xué)習(xí)得到特征向量VToken,并送入分類層進(jìn)行二分類訓(xùn)練,記為S2FVDToken方法。將屬性控制流圖通過GCN模型學(xué)習(xí)得到特征向量VCFG,且獨(dú)立地送入分類層進(jìn)行二分類訓(xùn)練,記為S2FVDACFG方法。將S2FVDToken和S2FVDACFG兩種方法的檢測結(jié)果分別與S2FVD方法對比,如表2所示。
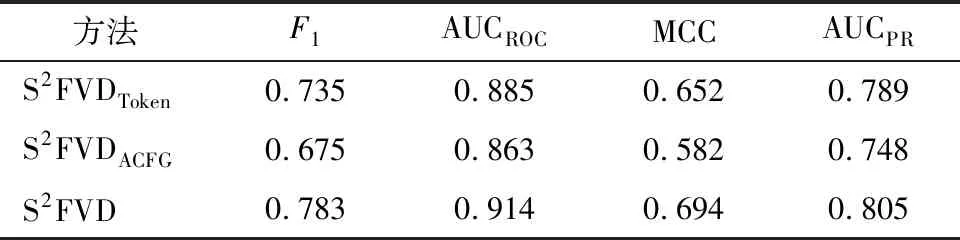
表2 多表征融合方式與單一表征的檢測結(jié)果對比
由表2可以看出,基于多表征融合進(jìn)行漏洞檢測的各項評估指標(biāo),均優(yōu)于采用單一表征的情形。說明采用單一表征進(jìn)行訓(xùn)練時,模型確實(shí)不容易充分學(xué)習(xí)代碼所承載的語義信息,導(dǎo)致產(chǎn)生相對較差的檢測效果。同時也可以推斷出,從Token序列和屬性控制流圖中抽取的特征,會有一定程度的語義上的重疊,但這些特征不相交的部分,進(jìn)一步提升了融合模型的漏洞檢測能力。
S2FVD默認(rèn)采取Word2Vec進(jìn)行Token嵌入。考慮到FastText是另一種常用的詞嵌入模型,這里對比采取不同Token嵌入模型時,S2FVD的漏洞檢測結(jié)果。同時,考慮到Token序列長度是影響模型檢測能力的關(guān)鍵參數(shù)之一,其決定了檢測模型能夠看到的函數(shù)語義的范圍。對此,對比分析Token序列長度l在不同取值(300、400和500)時,S2FVD的漏洞檢測結(jié)果。S2FVD采取不同嵌入方式和取不同l值時的檢測結(jié)果如表3所示。
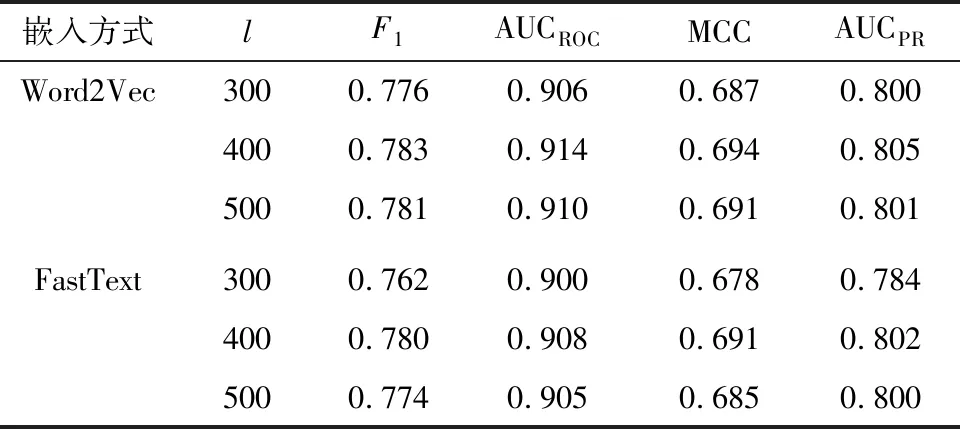
表3 采取不同嵌入方式和取不同l值時的檢測結(jié)果
如表3所示,S2FVD在不同嵌入方式下的檢測結(jié)果差異并不顯著,表明Word2Vec或FastText均能充分學(xué)習(xí)Token的共現(xiàn)關(guān)系,生成品質(zhì)區(qū)別不大的預(yù)訓(xùn)練嵌入向量。類似地,采取不同Token長度時,模型的檢測性能也并未表現(xiàn)出明顯變化。主要原因在于,S2FVD融合了TextCNN從序列中抽取的語義特征,以及GCN從ACFG中抽取的語義特征實(shí)現(xiàn)漏洞檢測,而序列長度主要影響了TextCNN從Token序列中提取的部分漏洞相關(guān)的特征,表明多表征融合有助于降低模型對參數(shù)設(shè)置的敏感性。同時,采取Word2Vec進(jìn)行Token嵌入,且Token序列長度l取值為400時,S2FVD模型表現(xiàn)出最優(yōu)的漏洞檢測性能。
5 結(jié)語
S2FVD方法基于函數(shù)中提取的Token序列和屬性控制流圖兩種原始的代碼表征結(jié)構(gòu),分別適配TextCNN和GCN神經(jīng)網(wǎng)絡(luò)模型進(jìn)行語義特征抽取,并通過語義特征向量的拼接融合,提高了漏洞檢測能力。在公共數(shù)據(jù)集上開展的實(shí)驗結(jié)果表明,S2FVD相比文獻(xiàn)[13]方法表現(xiàn)出更優(yōu)秀的漏洞檢測能力。消融實(shí)驗結(jié)果表明,對多種代碼表征結(jié)構(gòu)進(jìn)行融合學(xué)習(xí)是有必要的,檢測性能優(yōu)于僅使用單一表征結(jié)構(gòu)的情況。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
