基于深度學習的檳榔輪廓圖像分割算法的應用
2023-06-22 23:25:01程盼
現代信息科技 2023年5期
摘? 要:針對目前檳榔點鹵工藝中鹵水量不好精確控制的問題,文章提出采用深度學習的方式對檳榔內輪廓進行語義分割,分離出內輪廓并計算出相應面積,最后推算出比較準確的鹵水量。其中,網絡模型以UNet為基礎模型,考慮到模型的通用性,將UNet的encoder特征提取部分替換成VGG16網絡。實驗結果表明,該網絡模型對于檳榔內外腔的分割效果很好,分割精度達到97%以上,性能優于不進行遷移學習的UNet。
關鍵詞:語義分割;UNet;VGG16;檳榔輪廓分割
中圖分類號:TP391.4? ? ? 文獻標識碼:A? 文章編號:2096-4706(2023)05-0149-04
Application of Areca Nut Contour Image Segmentation Algorithm Based on Deep Learning
CHENG Pan
(Sankyo-HZ Precision Co., Ltd., Huizhou? 516006, China)
Abstract: Aiming at the problem that the brine amount is not well controlled accurately in the process of adding brine to areca nut at present, this paper proposes to use the deep learning method to perform semantic segmentation on the inner contour of areca nut, after separating the inner contour and calculating the corresponding area, and it finally calculates the more accurate brine amount. The network model is based on UNet model. Considering the universality of the model, the encoder feature extraction part of UNet is replaced by VGG16 network. The experimental results show that the network model has a good segmentation effect for the internal and external cavities of areca nut, with the segmentation accuracy of more than 97%, and its performance is better than that of UNet without migration learning.
Keywords: semantic segmentation; UNet; VGG16; areca nut contour segmentation
0? 引? 言
目前我國檳榔產品主要以青果和煙果為主,其生產流程主要工藝包括選籽、切片、去芯、點鹵、包裝等工藝。其中,點鹵工藝為其中一環。由于檳榔本身差異性很大,設備很難準確控制鹵水量,而鹵水量的準確度直接影響檳榔的食用口感,導致該工藝主要以人工點鹵為主。通過機器視覺技術分析檳榔內輪廓的面積,進而推算出需要的鹵水量,成為自動化方向的首選。然而,檳榔本身形態多變,內外輪廓特征的準確分割成為一大難題。
傳統的圖像分割算法往往基于閾值、區域/邊緣、紋理、聚類等,算法相對簡單,但是效率低,準確度不高。近年來,隨著計算機視覺技術的興起,特別是涉及深度學習非常關鍵的算法、算力、數據的不斷發展,基于計算機圖形學和機器學習的圖像分割技術受到了人們的廣泛關注。其中,卷積神經網絡(CNN)是圖像分割或分類任務的佼佼者[1-3]。2014年Simonyan等[4]提出基于小卷積核和池化核的VGG卷積神經網絡模型,該模型在2014年的ImageNet挑戰賽(ILSVRC -2014)中獲得了亞軍,后被廣泛應用于分類和定位任務中。2015年,Ronneberger[5]等提出基于Encoder-Decoder結構的UNet網絡模型。跳躍連接(Skip-Connection)有別于全卷積網絡[6](Fully Convolutional Network,FCN)采用的加操作(Summation),UNet采用堆疊操作(Concatenation),這樣的結構使得網絡在上采樣(Decoder)階段更加利于空間信息等特征的保留。由于UNet的下采樣階段(Encoder)的網絡結構與VGG高度相似,考慮到可以使用VGG預訓練的成熟模型來進行遷移學習,從而起到加速UNet的訓練的效果。結合VGG與UNet網絡模型,2018年,Iglovikov等[7]演示了如何通過使用預訓練的編碼器模型來改進UNet的架構,其中采用預訓練權重的VGG-UNet網絡模型的語義分割效果明顯優于沒有預訓練權重的模型。
UNet網絡模型及其變種模型通常用在醫學圖像、遙感圖像等的語義分割上,并取得了非常好的效果。2016年,Faustod等[8]提出了一種基于體積、全卷積神經網絡的3D圖像分割方法V-Net。2018年Zongwei Zhou等[9]提出醫學圖像分割架構UNet++,其本質上是一個深度監督的Encoder-Decoder網絡,其中Encoder與Decoder子網絡通過一系列嵌套的密集跳躍路徑連接。重新設計的跳躍路徑旨在減少編碼器和解碼器子網絡的特征圖之間的語義差距。2021年,Ali Nawaz等[10]提出用于腦腫瘤分割的VGG19-UNet和用于生存預測的集成學習模型。
考慮到醫學圖像與檳榔圖像的共性:語義較為簡單和結構相對固定,本文采用VGG-UNet網絡模型,用于檳榔圖片的語義分割任務中。其中,以UNet為基礎模型,下采樣部分用VGG16代替。
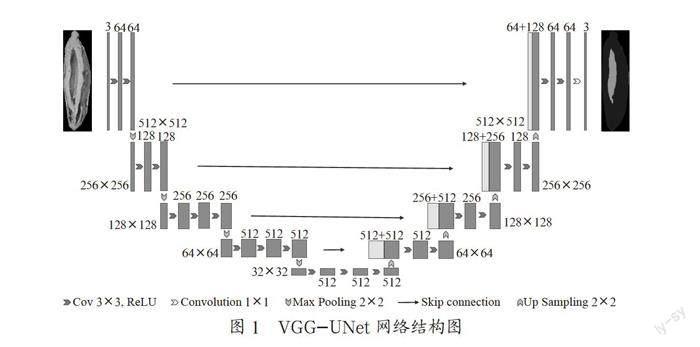
1? VGG-UNet網絡結構
VGG-UNet網絡可以看作UNet網絡的一種改進,而UNet本身也可以歸類為FCN網絡。典型的UNet包括下采樣和上采樣兩部分,分別對應Encoder和Decoder。從結構上看,本文使用的網絡與UNet網絡主要改進在于:(1)下采樣部分采用VGG16網絡結構,但是去掉了全連接層;(2)上采樣部分采用兩倍上采樣+拼接,單層輸出與跳躍連接輸入的通道數保持一致。具體網絡結構如圖1所示。
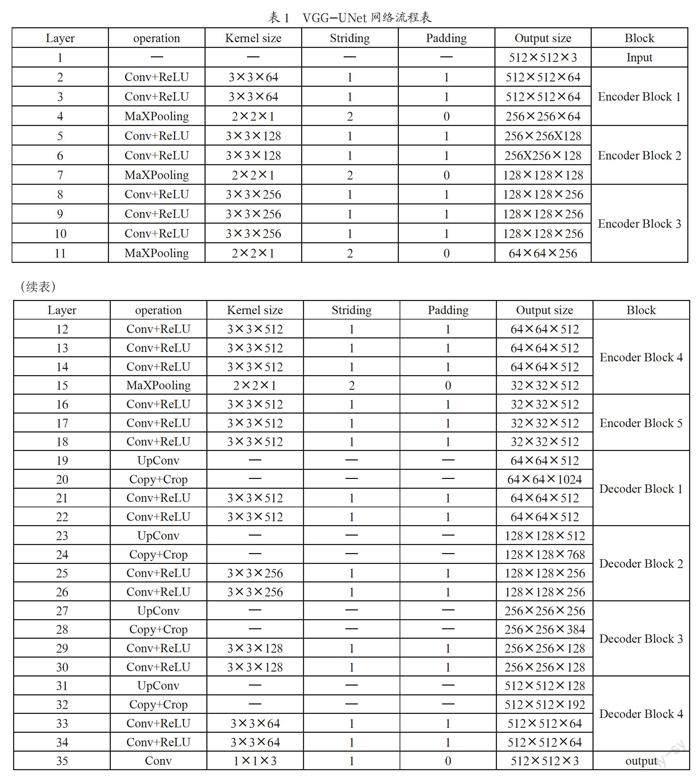
本文的VGG-UNet網絡中,卷積操作用于特征提取,絕大部分使用的卷積核(kernel)大小為3×3,步長(striding)為1,各邊緣填充(padding)等于1,這樣保證了卷積前后的長寬不變;最大池化操作使用2倍下采樣,用于降低維度和減少噪聲。反卷積操作采用2倍上采樣,用于維度的恢復。跳躍連接則主要用于底層的空間位置信息與深層特征的語義信息的融合,減少空間信息的丟失。具體流程如下,如表1所示。
(1)Input:輸入圖像大小為512×512×3。
(2)下采樣階段:
1)Block 1:輸入圖像大小為512×512×3,使用大小為3×3的64通道卷積核進行2次卷積,再進行減半池化;
2)Block 2:輸入圖像大小為256×256×64,使用大小為3×3的128通道卷積核進行2次卷積,再進行減半池化;
3)Block 3:輸入圖像大小為128×128×128,使用大小為3×3的256通道卷積核進行3次卷積,再進行減半池化;
4)Block 4:輸入圖像大小為64×64×256,使用大小為3×3的512通道卷積核進行3次卷積,再進行減半池化;
5)Block 5:輸入圖像大小為32×32×512,使用大小為3×3的512通道卷積核進行3次卷積。
(3)上采樣階段:
1)Block 1:輸入圖像大小為32×32×512,采用2倍反卷積+拼接,然后使用大小為3×3的512通道卷積核進行2次卷積;
2)Block 2:輸入圖像大小為64×64×512,采用2倍反卷積+拼接,然后使用大小為3×3的256通道卷積核進行2次卷積;
3)Block 3:輸入圖像大小為128×128×256,采用2倍反卷積+拼接,然后使用大小為3×3的128通道卷積核進行2次卷積;
4)Block 4:輸入圖像大小為256×256×128,采用2倍反卷積+拼接,然后使用大小為3×3的64通道卷積核進行2次卷積。
(4)Output:輸入圖像大小為512×512×64,使用大小為1×1的3通道卷積核進行1次卷積,得到輸出圖像大小為512×512×3。
2? 實驗及分析
2.1? 數據集
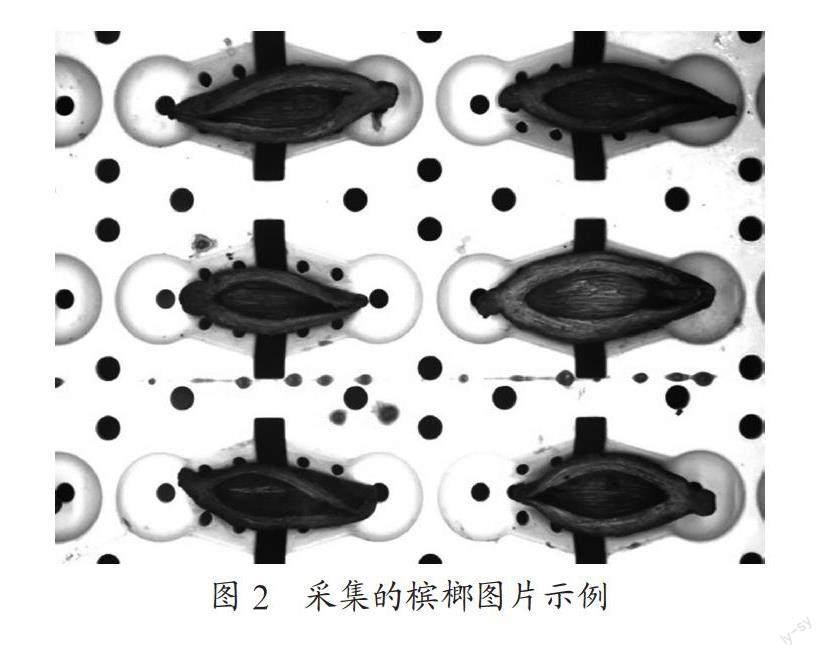
檳榔放置于料盤上,檳榔切口水平朝上時為正常狀態。考慮到檳榔的識別效果易受檳榔形狀、姿態等影響,在取圖時部分檳榔會故意將切口傾斜、整體姿態傾斜,異常檳榔約占整體數量的5%,與實際生產情況保持一致。另外,實際生產過程中料盤經常會沾到鹵水,在取圖時也需要考慮。數據采集使用130萬象素相機采集,一次拍6個檳榔,圖片大小1 280×960,總數量923張。打光采用回型背光源,通過旋轉角度,將數據增廣到3 692張。隨機選取90%作為訓練集,10%作為驗證集。相機采集到的檳榔圖片示例如圖2所示。
2.2? 模型訓練及評價指標
本文使用的VGG-UNet網絡模型采用Pytroch深度學習框架進行訓練,系統環境為Win 10,GPU使用NVIDIAGeforce RTX 2080 Ti。數據集圖片以長邊保持比例縮放到512×512,短邊不足部分補齊,灰度值設置為全白255。整個模型輸入圖片大小為512×512×3,語義分割類別有3類,分別是背景,外腔,內腔。輸出圖片大小與輸入一致。
采用的語義分割常用的評價指標為像素準確率(PA)和Dice系數,其中,PA用來預測正確的樣本數量占全部樣本的百分比,Dice系數則用于評估兩集合的相似度。
由表2可以看出,VGG-UNet的像素準確率為97.25%,比UNet的高出0.48%;VGG-UNet的Dice系數為89.58%,比UNet的高出0.38%。采用預訓練的VGG-UNet無論在準確度和Dice系數上的表現都要優于UNet。
從圖3的效果對比可以看出,VGG-UNet在圖像的細節分割更加準確。比如,UNet處理的外輪廓明顯會更多受到盤子特征的影響更多;當內輪廓分界線不是很明顯時容易丟失部分內輪廓面積。
3? 結? 論
由于先驗知識的加入,使得VGG-UNet網絡模型在訓練時收斂性更快,對圖像分割效果更加穩定,具有更好的魯棒性。實際在生產的過程中,模型的分割效果跟樣本本身也有很大關系,要注意不良樣本的比例要與實際生產保持一致。另外,此方法的不足之處還有,當兩個檳榔相連時,檳榔輪廓會找錯。輪廓的平滑性還是有些許不足,訓練比較耗時,這將是后期亟須完善的地方。
參考文獻:
[1] LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-based learning applied to document recognition [J].Proceedings of the IEEE,1998,86(11):2278-2324.
[2] KRIZHEVSKY A,SUTSKEVER I,HINTON G. ImageNet Classification with Deep Convolutional Neural Networks [J].Advances in neural information processing systems,2012,25(2):75-79.
[3] TAIGMAN Y,YANG M,RANZATO M,et al. DeepFace:Closing the Gap to Human-Level Performance in Face Verification [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus:IEEE,2014:1701-1708.
[4] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J/OL].arXiv:1409.1556 [cs.CV].(2015-04-10).https://arxiv.org/abs/1409.1556.
[5] RONNEBERGER O,FISCHER P,BROX T. U-Net:Convolutional Networks for Biomedical Image Segmentation [C]//Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015.Cham:Springer,2015:234-241.
[6] SHELHAMER E,LONG J,DARRELL T. Fully Convolutional Networks for Semantic Segmentation [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,39(4):640-651.
[7] IGLOVIKOV V,SHVETS A. TernausNet:U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation [J/OL].arXiv:1801.05746 [cs.CV].(2018-01-17).https://arxiv.org/abs/1801.05746.
[8] MILLETARI F,NAVAB N,AHMADI S A. V-Net:Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation [C]//2016 Fourth International Conference on 3D Vision (3DV).Stanford:IEEE,2018:565-571.
[9] ZHOU Z,SIDDIQUEE M,TAJBAKHSH N,et al. UNet++:A Nested U-Net Architecture for Medical Image Segmentation [C]//DLMIA 2018,ML-CDS 2018.Cham:Springer,2018:3-11.
[10] NAWAZ A,AKRAM U,SALAM A,et al. VGG-UNET for Brain Tumor Segmentation and Ensemble Model for Survival Prediction [C]//2021 International Conference on Robotics and Automation in Industry (ICRAI).Rawalpindi:IEEE,2021:1-6.
作者簡介:程盼(1988—),男,漢族,湖北天門人,高級工程師,碩士,研究方向:機器視覺。
收稿日期:2022-12-26
