基于XGBoost 的網絡輿情文章預警模型建立
2023-06-21 01:58:38方茜
智能計算機與應用 2023年6期
方 茜
(貴州師范學院數學與大數據學院, 貴陽 550018)
0 引 言
隨著互聯網的快速發展,越來越多的網絡應用成為廣大民眾暢所欲言的平臺。 絕大部分的網民主要從手機新聞app、微博、論壇、微信公眾號等平臺獲得資訊,而這些平臺在提供資訊的同時也提供用戶對文章進行評論、轉發、點贊等互動功能。 網絡的開放性及自由性使得人們通過網絡表達對文章報道事件的看法及心聲,而這些看法及心聲反映著民眾的態度,同時也反映著社會輿情。 然而當負面的輿情占比較大時,輿情危機產生,從而對社會造成重大影響,擾亂社會秩序,導致相關部門的管理失衡。
網絡輿情預警是在預警對象傳播的整個生命周期采取不間斷的監測工作。 通過實時采集預警對象的數據并對其分析,當達到監測閾值時,應使用預警模型及時反應預警對象的預警等級。 預警使得一些可能產生輿情危機或已成為危機的信息能夠被及時發現,由相關部門做出相應的引導決策,及時控制不良信息及不好輿論泛濫成災。
1 相關工作
目前,國內的研究中提出了多種類型的輿情指標體系。 其中,曾潤喜等人[1]通過文獻調研,將網絡輿情監測與預警指標體系分為4 類:
(1)基于社會預警啟示的指標,從警源、警兆和警情3 個一級指標來構建指標體系,該方法的主觀性較強;
(2)基于主題分類的指標體系[2],從輿情事件產生背景及指向性設計指標體系,然而該方法缺少指標量化研究;
(3)基于輿情不同發生主體的指標體系,從特定領域的角度設計指標體系(如高校)[3]等;
(4)基于網絡輿情內在機理的指標體系[4],使用輿情發展周期中出現的因素建立指標體系。 國內已有輿情預警研究中,有的將網民的情感極性[5]作為其中一個預警指標,也有直接通過分析文本的情感極性[6]對輿情進行預警。
研究中發現,基于指標體系的預警研究大部分還處于理論研究階段,實際應用價值不高,并存在以下問題:
(1)指標體系建立依賴專家經驗知識,主觀因素較強,缺乏數據驅動的客觀實證性研究。
(2)一些定性指標的量化依賴專家打分,導致輿情預警綜合研判滯后,難以實現對預警對象的及時預警。
(3)已有的基于指標體系的預警研究還處于理論期,實用性較差。 因此,本文提出一套基于文章預警的特征,通過相關性分析和特征篩選的方法,對預定義文章的預警特征進行篩選,并使用XGBoost 方法建立文章預警模型。
2 網絡輿情文章預警指標體系的建立
2.1 預選指標特征
本文以新聞文章為預警對象,通過分析造成文章預警因素,并結合以往輿情預警研究的指標體系綜合分析,從文章特征、受眾特征兩方面考慮,列出對文章預警具有影響的特征作為預選指標。
2.1.1 文章特征
文章特征從文章內容出發,通常描述某一事件內容,不同類型事件其影響程度不同。 文章特征主要有以下幾點:
(1)文章主題重要性(topic_importance)
文章主題重要性用于衡量這篇文章報道事件內容的重要程度。 不同的主題所造成的影響程度不同,通過提取文章的關鍵主題詞,關鍵主題詞出現頻率越高,對文章的主題表現就越重要。 因此,統計該關鍵主題詞頻占文章中總詞的頻率作為文章重要性判斷。
(2)文章情緒(mood_emotion)
文章情緒表示文本內容特征信息所表達出的情緒,文章本身的情緒對閱讀文章的網民情緒具有一定的影響。 文章情緒可以使用Lei J[7]提出的方法,計算出文章的情緒標簽,并取概率值最大的情緒作為文章的情緒,該值為離散值。
2.1.2 受眾特征
受眾特征表示除文章本身信息外的其它信息,其來源于網民在閱讀完文章后對文章的一系列行為動作產生的數據。 主要包括以下特征:
(1)參與人數P(participants_num)
參與人數用于表示閱讀該文章的網民中參與評論總人數C及對評論點贊的人數Z之和,也即是評論區參與總人數:P=C+Z。 文章的參與人數反映網民對這件事的關注程度,可以通過爬蟲直接從新聞頁面獲取得到。
(2)評論總數C(comments_num)
評論總數表示對這篇文章進行評論的總人數,可以通過爬蟲直接從新聞頁面獲取。 評論越多,表示網民對這件事的反響越強烈,同時也會使該文章成為熱點文章,從而受到更多人的關注。
(3)評論情感傾向CE(comment_emotion)
文章評論反映網民對文章報道事件的態度傾向,情感傾向的正負極表示網民對這件事是支持還是反對。 通過現有的情感分析技術判斷評論情感得分,用F_score表示每條評論情感分值,文章所有評論的情感傾向值:使用均值來表示。 當負面評論較多時,CE <0,表示為-1,CE≥0 時,表示為1。
(4)評論變化拐度
評論變化率是指單位時間內評論數的變化,評論變化率Cfre=(C t2- Ct1)/Δt,Δt=t2- t1。 其中,Ct1表示單位時間t1 的評論數,Ct2表示在單位時間t2 的評論數。 通過一段時間內評論數的變化,能夠了解到在這段時間內網民對這篇文章的關注趨勢變化。 若評論數在某一時段內持續上升時,應引起相關部門關注,預防輿情危機產生。 評論變化拐度用于描述評論數在前一時間段轉變到后一時間段趨勢變化的情況,分別用前一時間段評論數變化率和后一時間段評論數變化率進行比較得出。 通過分析,拐度的7 種情況見表1。

表1 評論變化拐度情況列表Tab. 1 Comments on the change of the inflection situation list
從G1 ~G7 窮舉所有可能的拐度情況,G1 ~G3表示相對于前一段時間,下一時間段往評論變大的方向拐;當兩時間段內容評論變化率相等時,G4 表示持平狀態,下一時間段評論往持平方向; G5 ~G6表示相對于前一段時間,下一時間段評論往變小方向拐。 通過分別統計一定時間段內出現評論變大、變小、持平的占比,來表示評論變化拐度情況。 在表1 列舉的11 種評論拐度圖形中,任意一種圖形出現一次則計數為1,所有評論拐度圖形出現的次數之和為拐度總次數,用Gtotal表示。
變大的占比(g_up)為
持平的占比(g_bal)為
變小的占比(g_down)為
(5)文章每種情緒投票占比
網民閱讀完文章后,可以通過投票方式表達對此文章的情緒態度。 總投票數和每類情緒的投票數可以通過爬蟲代碼從網頁直接獲取。 使用每種情緒的投票占比來表示網民對這篇文章的實際情緒,其由每類情緒的投票數除以總投票數得到。 情緒共有6 種:分別為憤怒(angry)、震驚(shocked)、搞笑(funny)、新奇(novel)、感動(moved)、難過(sad)各投票數。
綜上,本文預選取的所有預警指標特征見表2。

表2 文章預選指標特征列表Tab. 2 Feature list of article pre-selected indicators
用于文章預警的特征包含連續特征和離散特征,表2 中離散特征名稱中標注?,其余為連續特征。 由于這些特征的量綱不同,其度量范圍和數量差別較大。 因此,為便于綜合評價,減少數量級差異,本文使用min-max 方法對特征進行歸一化處理,使其值在[0,1]之間。
2.2 指標特征分析
通過分析文章的相關信息,預選15 個特征用于文章預警研究,本節使用皮爾遜相關性判斷特征與預警相關性,通過相關性分析可以得到本文預選的預警特征指標是否與預警相關。
由表3 可知,本文預選的特征指標除主題重要性f1、讀者憤怒情緒投票f10、難過情緒投票f15 相關性最低且不顯著以外,其它特征都表現較強的顯著性。 主題重要性f1 相關性最低且不顯著,其原因可能是因為該方法的量化是通過主題詞在全文中出現的概率來反應主題重要性,不同文章通過該方法計算得到的概率值相差不大,導致每篇文章的主題重要性區分度不高。 由于該特征與預警相關性小于0.1,可篩除該指標。 因此,通過上述特征分析,本文預選的特征基本與預警顯著相關。

表3 文章預選特征指標與預警的相關性Tab. 3 The correlation between pre-selected feature indicators and early warning
3 基于XGBoost 的預警模型建立
本文目標旨在輿情監測過程中收集到一篇文章相關數據后,能夠對其判斷是否要對文章輿情預警,以及確定預警級別。 參考《國家突發公共事件總體應急預案》[8],其按突發公共事件產生的危害程度、可控性和影響程度、發展態勢、緊急程度等因素,本文將文章預警等級分為5 個等級,分別為特別嚴重(1 級)、嚴重(2 級)、較重(3 級)、一般(4 級)、不預警(0 級)。 同時輿情監測預警系統中需要對監測的預警對象的預警級別及時準確反饋,以達到預警目的。 因此,在模型的選擇上需要使用一個速度快、準確率高的模型。
由chen 等人[9]提出的 XGBoost ( Extreme Gradient Boosting),因其速度快、準確率高等優點而受到廣泛應用。 XGBoost 方法是GBDT(Gradient Boosting Decision Tree)梯度提升樹的改進版本,其與GBDT 不同在于基學習器除決策樹外還支持線性學習器,并加入正則項使得偏差與方差均衡。 傳統的GBDT 在優化過程中只用到一階泰勒展開,而XGBoost 用到泰勒一階展開和二階展開。
梯度提升樹是由Boosting 方法結合Gradient 梯度得到的。 Boosting 是集成學習中的一種,其核心思想是通過迭代過程中前一輪的誤差率動態更新訓練集權重,每一輪都是一個弱學習器,由多個弱學習器集成強學習器實現回歸和分類。 而GBDT 方法的每一輪迭代目標是找一棵決策樹模型的弱學習器使得本輪的損失函數最小。 GBDT 模型是由k個基學習器組成加法運算,可表示為
其中,F表示所有基學習器組成的函數空間。對于n個樣本,其損失函數為
損失函數表示模型的偏差,最小化損失函數就是最小化模型的偏差。 為了使模型的偏差和方差達到較好的平衡,加入正則項來抑制模型的復雜度,因此模型的目標函數表示為
式中Ω表示基學習器的復雜度,即模型的結構風險。
由于本文以決策樹模型作為基學習器,因此可以使用樹的深度、葉節點的個數等反應模型的復雜度。 GBDT 前向分布算法的思想是從前往后建立基學習器,以此來逐漸優化,逼近目標函數Obj的過程。 該過程以一個常數項開始,每次添加一個新的函數,其過程如下:
上述過程中(0)~(t) 表示從第0 輪到第t輪,每一輪添加一個基學習器,主要在于GBDT 的目標函數,即每個基學習器的加入都是以優化目標函數為目的。 公式(7) 表示第t輪的預測值計算,ft(xi) 為要加入的基學習器,則此時的目標函數為
使用泰勒公式展開公式(8)中的目標函數。 令gi為目標函數中的一階偏導,令hi為二階偏導,是t前一輪的訓練結果,yi是其對應的真實值,可作為常數處理,則由公式(8)轉化為
當對目標函數公式(8)只求一階偏導時,模型為GBDT,求一階、二階偏導時,模型為XGBoost,即公式(9)為XGBoost 的目標函數,損失函數不同對應著不同的gi和hi。 在XGBoost 中復雜度Ω(ft) 的公式為
其中,λ為學習率;T表示葉子節點個數;wj為葉子節點的權重。Ω(ft) 作為結構風險,將葉子節點的個數加入懲罰項,以限制模型的復雜度,并使用L2 正則避免過擬合。
模型構建如圖1 所示,模型的輸入為上節中通過特征分析后得到的文章預警特征指標,輸出為文章預警級別。 通過文章數據集提取文章數據,并量化各項文章預警特征,輸入到XGBoost 模型中,訓練得到基于XGBoost 的網絡輿情文章預警模型。 該模型的內部是由多棵CART 樹構成,一篇文章的預警等級由其所在的多棵樹中的葉子節點權重共同確定,除第一棵樹以外,每一棵樹都是訓練上一棵樹的損失值,使得整個樣本的損失盡可能減少,得到最優的分類結果。

圖1 基于XGBoost 的文章預警建模過程Fig. 1 The modeling process of article early warning based on XGBoost
4 實驗
4.1 實驗數據
實驗數據是使用爬蟲代碼,爬取新浪社會新聞網站情緒排行榜上的新聞數據而得,其中包括新聞標題、新聞內容、每篇文章對應的情緒投票結果及每篇新聞的評論數據。 這些情緒分別為感動、震驚、搞笑、難過、新奇、憤怒6 類情緒。 選擇6 名網絡輿情研究的學者,分別對收集到的3 310 篇文章標記預警等級,通過Fleiss Kappa 一致性檢驗后,得到Kappa=0.758(Kappa 系數劃分為大于0.75 為優秀,0.40~0.75 為正常至良好,低于0.40 為差),因此使用標記預警等級后的數據集作為實驗的真實值。 每類預警級別(從1 級到4 級預警嚴重程度逐級遞減,0 級表示不預警)的樣本數見表4。

表4 每類預警級別樣本數Tab. 4 Number of samples for each warning level
4.2 實驗結果與分析
實驗一預警特征篩選結果及分析
通過XGBoost 模型訓練得到的指標特征重要性得分如圖2 所示。 橫軸表示特征重要性得分值(F_score),縱軸對應表2 中的每個特征指標。

圖2 指標特征重要性Fig. 2 The importance of features
可以看出,文章的參與人數(participants_num)具有最高的重要性得分,說明一篇文章的參與人數越多,越有可能需要預警。 其次是網民對文章報道事件的震驚情緒(shocked),說明當看完文章的網民產生震驚情緒時越有可能需要預警。 特征重要性得分排名前三的特征是衡量預警等級的最重要特征。而文章情緒特征重要性得分較低,說明其對預警等級的重要性較小。 其中,文章情緒為難過(mood_sad)時最低,說明文章情緒表現為難過時,對預警等級的分類影響較弱。
實驗二基于XGBoost 的文章預警模型效果及分析
表5 展示了采用3 種方法建立網絡輿情文章預警模型的性能指標對比結果。 其中SVM 方法對預警等級的劃分效果最差,而基于決策樹的預警模型比基于SVM 的預警模型效果要好。 性能最好的是基于XGBoost 建立的預警模型,其能夠達到77%的平均準確率,且其F1-measure 的值能夠達到56.2%。說明本文提出使用XGBoost 建立的預警模型能夠很好的實現對網絡輿情文章進行預警等級的分類。
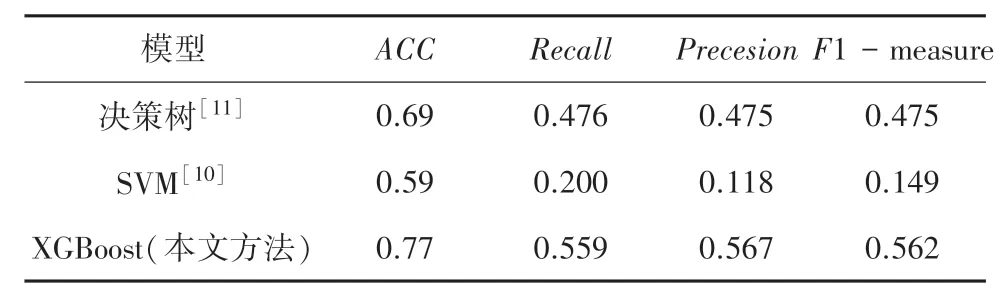
表5 三種模型性能對比Tab. 5 Performance comparison of three models
為了查看每個預警等級被分類準確的性能效果,本文選擇準確率較高的基于決策樹和基于XGBoost 建立的預警模型的ROC曲線進行對比展示,如圖3、圖4 所示。 圖中不同顏色代表不同的預警等級(0 級~4 級)的ROC曲線,深藍色的表示整體平均的ROC曲線。 area 對應每個預警等級ROC曲線下的面積,即AUC值,該值越高,表示預警模型越能判別出該預警等級。

圖3 基于決策樹的預警模型ROC 曲線Fig. 3 ROC curve of early warning model based on decision tree
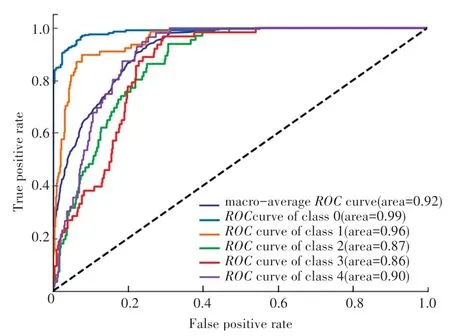
圖4 基于XGBoost 的預警模型ROC 曲線Fig. 4 ROC curve of early warning model based on XGBoost
從圖3 和圖4 中可知,基于XGBoost 的預警模型在每個預警等級的判定命中率上均高于基于決策樹的預警模型。 其中,宏平均AUC相差8%,除等級0(無警)的AUC相差3%以外,其他預警等級的AUC相差6%~10%之間,說明基于XGBoost 的模型更有助于預警等級的判定。
綜上,本文提出以數據驅動的方式客觀驗證提出的特征指標的有效性,使用XGBoost 建立網絡輿情文章預警模型對文章預警等級分類在宏平均評估指標ACC、F1、及AUC均取得了較好的效果,顯著優于使用SVM 建立預警模型以及非集成的決策樹模型,且對文章預警等級為非常嚴重的判斷明顯優于其他等級,有效防止高嚴重級別的等級被誤判為低嚴重級別。
5 結束語
針對現有研究中輿情預警多集中在以主觀經驗設計的指標體系為核心的靜態預警模型研究,指標體系的建立主觀性太強,依賴于專家經驗,缺乏基于數據驅動的實證研究。 本文通過分析引起文章輿情危機的因素,為新聞文章的預警等級的綜合判定設計一套全面可量化的預警特征集,以真實數據驗證所提指標體系對輿情文章預警的重要性,建立了全面可量化的文章輿情預警指標,使得預警指標體系更具客觀性。 不僅解決了現有指標體系預警方法的主觀性,并提出使用集成方法XGBoost 建立文章預警模型,實現對文章預警級別的判定。 通過對比實驗的結果表明,本文提出的方法明顯優于現有的基于決策樹的預警模型和基于SVM 的預警模型,能夠有效實現對新聞文章預警等級的判斷。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
