基于手機加速度異常極值處理的步態身份識別
2023-06-21 01:58:26陳志強苗敏敏胡文軍
智能計算機與應用 2023年6期
關鍵詞:實驗
陳志強, 苗敏敏,2, 胡文軍,2
(1 湖州師范學院信息工程學院, 浙江湖州 313000;2 浙江省現代農業資源智慧管理與應用研究重點實驗室, 浙江湖州 313000)
0 引 言
近年來,智能設備已成為日常必需品,人們每天都在依賴智能設備來完成日常生活中的各種任務,因此對智能手機的安全問題也越來越重視[1-2]。 移動智能設備最廣泛使用的身份識別技術主要分為3大類:第一類是基于PIN、密碼[3]的識別方式,這種方式的缺點是密碼容易被遺忘和泄露;第二類是基于人臉、指紋以及虹膜等生物特征[4]的識別方式,這種方式要求被監測對象必須近距離獲取信息,同時需要高昂的手機成本;第三類方法是基于三維手勢、步態等行為習慣特征[5]的識別方式,該方式具有改變困難、模仿困難等優點,其步態識別是唯一一個在遠距離非接觸情況下,也能正確識別身份的一種行為習慣特征。 如今大多數智能手機都配備了許多內置傳感器,例如加速度、陀螺儀等。 這些傳感器支持隱式身份識別技術,能從傳感器中捕捉到用戶的行為特征。 孔菁等人[6]提出采用坐標軸轉換算法,讓基準坐標系和慣性坐標系重合,提取特征后使用支持向量機算法進行分類識別,識別準確率達到95.5%。 Sun 等人[7]提出一種速度自適應步態周期分割方法和個性化閾值生成方法,與基于固定步行速度和恒定閾值的最新技術相比,用戶身份識別準確率提高了21.5%。 Hoang Minh Thang 等人[8]采用時域和頻域進行實驗,采用支持向量機對提取的特征進行分類識別,得到的準確率分別為79.1%和92.7%。胡春生等人[9]通過對數據進行特征提取和數據權重分析,構建BP 神經網絡進行訓練和匹配識別實驗,準確率可達96.67%。 王彬等人[10]建立了步頻分布的特征模型,利用相對熵判別用戶身份,識別準確率達到86%。
由于經過濾波后加速度信號中仍然存在小范圍的異常極值,為進一步提高識別的準確率,本文提出一種基于四分位數去除異常極值的算法,并采用公用數據集以及自行采集的數據集分別對所提算法進行實驗。 實驗結果表明,在兩個數據集上使用本文提出的算法后,準確率均得到提高。
1 公開數據集身份識別方案的設計
1.1 數據獲取
采用福坦莫大學無線數據挖掘實驗室所提供的公開步態數據集[11]進行實驗。 該數據集利用手機加速度傳感器采集了36 個不同受試者的步行、慢跑、靜坐、站立、上樓和下樓6 種步態,采樣頻率為20 HZ。采集過程中手機放在大腿的便攜包里,Z軸指向為前進方向。 通過文獻[12]發現重力方向上的加速度信號比其他兩個方向上的信號更穩定。 因此,本文重點分析重力方向的加速度信號,即Y軸。
為保證實驗數據充足,在6 種步態中選取步態為步行,且采樣點大于3 000 的時間序列作為實驗數據(某個時間序列代表在某一連續時間內采集到的步態加速度數據),共得到57 個步行時間序列。在各時間序列中分別選取連續的2 000 個采樣點進行實驗,其中前1 200個采樣點作為訓練數據,后800個采樣點作為測試數據。
由于受試者在步行過程中,并未始終處在穩定步行狀態,此時采集到的數據不是步行的真實數據。針對這一現象,本文提出一種基于波峰和波谷方差之和的最小值方法來自適應截取數據。 以窗口大小為2 000,步長為400 進行滑窗操作,計算Y軸方向上各窗口內所有波峰值與波谷值的方差,選取波峰方差與波谷方差之和最小的窗口作為實驗數據。 某步行時間序列各個窗口波峰方差與波谷方差之和統計如圖1 所示。 從圖中可以看到,在1 600-3 600范圍內的數據方差之和最小,表示該范圍內的數據較為平穩,因此將該段數據選為穩定步行數據進行實驗。

圖1 時間序列選擇Fig. 1 Time series selection
1.2 數據預處理
采用Savitzky-Golay 濾波[13]方法對數據進行兩次平滑處理,兩次平滑窗口分別為7 和5。 考慮到濾波之后仍然會有一些異常極值,因此本文提出一種基于四分位數[14]去除異常極值的算法來提高識別準確率。
四分位數分為下邊緣、下四分位數、中位數、上四分位數和上邊緣。 其中,下四分位數位置記為Q1,中位數位置記為Q2,上四分位數位置記為Q3。
最小估計值公式:
最大估計值公式:
其中,k表示異常值檢測因子,設定為1.5。
當數值大于最大估計值或小于最小估計值時都記為異常值。 異常極值去除算法實現步驟如下:
(1)計算信號的所有極大值點,計算如公式(3):
其中,xi表示當前時刻的采樣點,xi-1和xi+1分別是前一時刻和下一時刻的采樣點。
(2)使用公式(1)、公式(2)計算所有極大值的最小估計值和最大估計值,若滿足公式(4),則被確定為異常極大值。
其中,pi為信號的極大值。
(3)將異常極大值點前一個極大值點到后一個極大值點之間的采樣點刪除,其余兩軸使用與該軸數據相同的起始與結束位置進行刪除,以保證刪除后的三軸數據在時間上一一對應。
(4)計算去除異常極大值后信號的所有極小值點,使用公式(1)、公式(2)計算所有極小值的最小估計值和最大估計值。 若滿足公式(5),則被確定為異常極小值。
其中,vi為信號的極小值。
(5)將異常極小值點前一個極小值點到后一個極小值點之間的采樣點刪除,其余兩軸使用與該軸數據相同的起始與結束位置進行刪除,以保證刪除后的三軸數據在時間上一一對應。 得到去除異常極值后的信號。
各步行時間序列的異常波峰箱線與波谷箱線如圖2 所示。 去除異常波峰與波谷后的對比圖如圖3所示,圖3(a)和圖3(b)分別表示處理前和處理后的波形圖,可以看出使用所提算法后,異常極值已被有效去除。
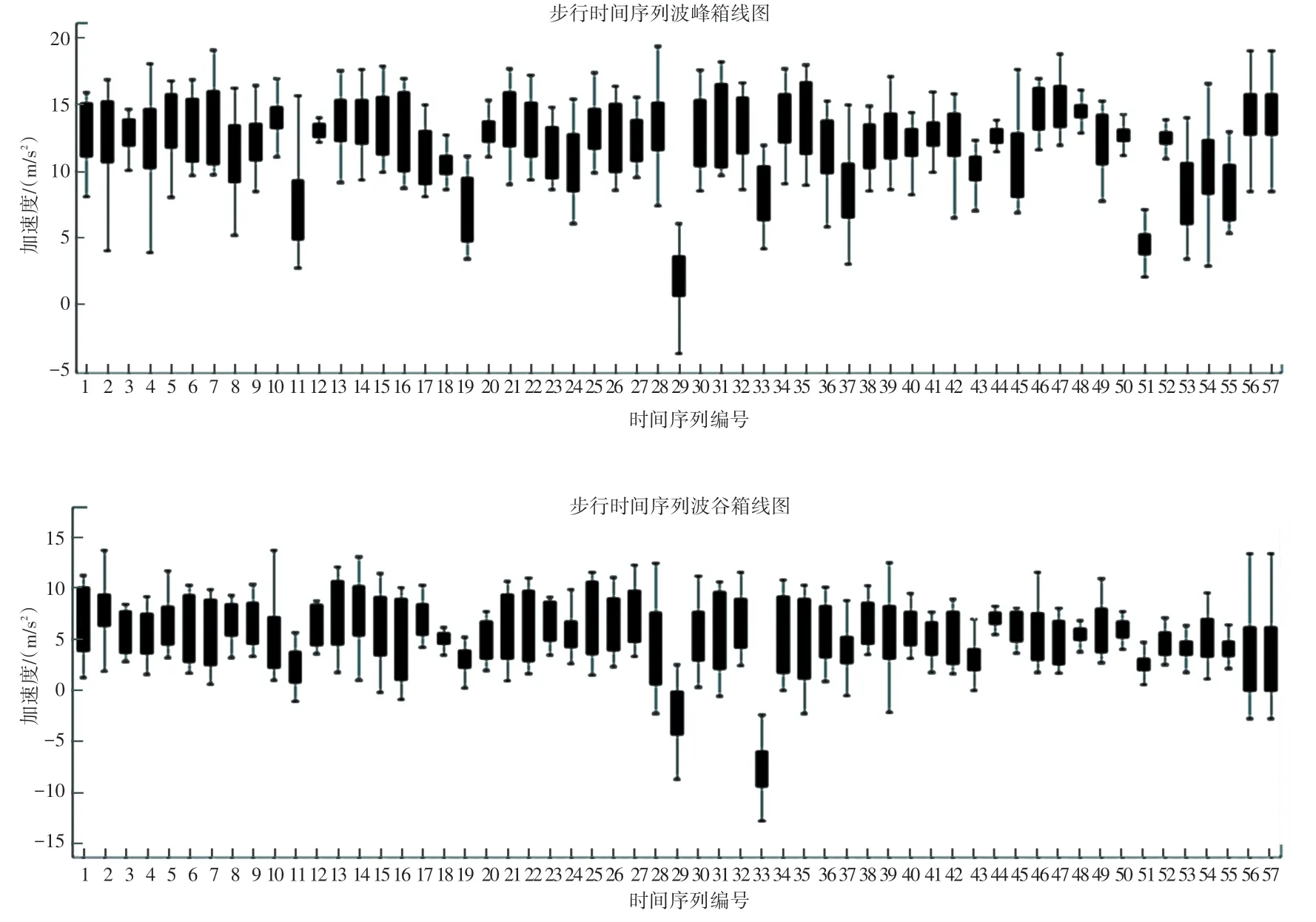
圖2 各步行時間序列的異常波峰箱線圖與波谷箱線圖Fig. 2 Abnormal wave peak and trough boxplots of each walking time series
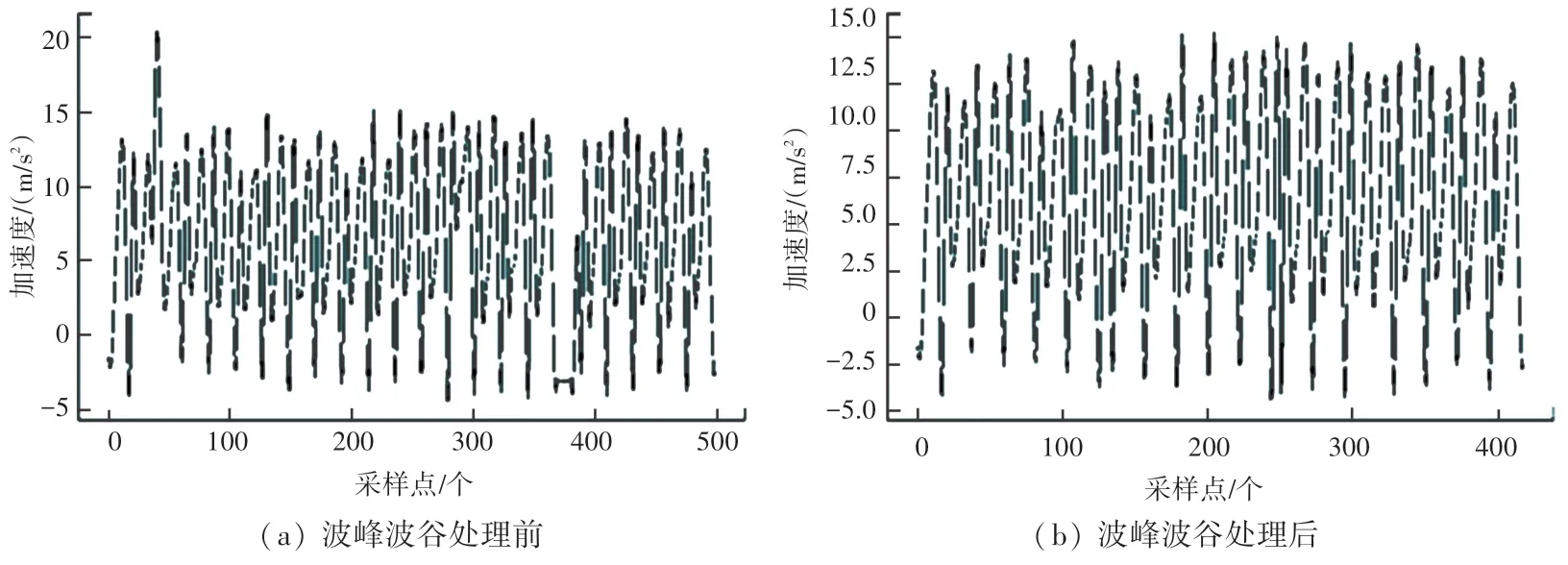
圖3 去除異常波峰與波谷前后加速度信號對比Fig. 3 Comparison of acceleration signal before and after removing abnormal wave peak and trough
1.3 模板劃分
以每8s 的步行數據作為步行模板。 由于采樣頻率為20 Hz,因此一個步行模板包含160 個采樣點。 統計步行時間序列中Y軸方向上加速度數據的波峰位置信息,以每個波峰位置作為起始點,后160個采樣點作為步行模板。
為了得到更多的步行模板,當正向截取結束后,再從最后一個波峰位置開始逆向截取,X軸與Z軸使用與Y軸的波峰位置進行數據截取。 模板截取如圖4 所示。

圖4 模板截取Fig. 4 Template to intercept
1.4 特征提取
根據文獻[15-17],從時域和頻域兩方面對步態模板進行特征提取。 下面描述這些特征,括號中注明的是每個特征類型生成的特征數量。
(1)時域特征
平均值(3):X軸、Y軸、Z軸的平均值。
標準差(3):X軸、Y軸、Z軸的標準差。
相關系數(3):X軸和Y軸、X軸和Z軸、Y軸和Z軸的相關系數。
三軸加速度合成標量最大值(1):X軸、Y軸、Z軸加速度平方和的平方根的最大值。
M為三軸加速度合成標量最大值,計算公式如式(6):
波峰平均值(3):X軸、Y軸、Z軸所有波峰的平均值。
波谷平均值(3):X軸、Y軸、Z軸所有波谷的平均值。
直方圖(10):重力方向上的加速度軸(Y軸)數據中的最大值和最小值,相減的差除以10 的結果作為間隔,算出每個間隔里點的個數所占的百分比。
(2)頻域特征
直流分量(3):X軸、Y軸、Z軸經快速傅里葉變換后頻率為0 的分量。
1.5 級聯森林模型
級聯森林是深度森林的一部分[18],每個級聯層包括兩個隨機森林和兩個完全隨機森林,每個決策器包含100 棵決策樹。 完全隨機森林中,每棵樹隨機選擇一個特征作為分裂點,然后一直增長,直到每個葉子節點細分到只有一個類別或者不多于10 個樣本。 隨機森林中,每棵樹選取個特征(n為特征維度),再通過gini 系數[19]篩選分裂節點。 級聯森林分類原理如圖5 所示。

圖5 級聯森林Fig. 5 Cascade forest
首先,將樣本特征提取后的29 維特征分別輸入兩個隨機森林和兩個完全隨機森林中,每個森林得到一個36 維概率類向量,將4 個36 維類向量與原始特征拼接成一個173 維數據,并作為下一層的輸入,以此類推。 最后輸出4 個36 維數據,將這4 個36 維數據中的每一維取平均值,得到一個新36 維數據,取36 維數據中結果最大的類別作為最終預測。
2 實驗結果與分析
在各時間序列中分別選取連續的2 000 個采樣點進行實驗,其中前1 200 個采樣點作為訓練數據,后800 個采樣點作為測試數據。 將訓練集經過預處理、模板劃分共得到14 050 個樣本,對樣本特征提取后進入模型訓練。 測試集經過預處理、模板劃分共得到8 651 個樣本。
為了驗證級聯森林分類算法在身份識別中的有效性,分別使用支持向量機和BP 神經網絡模型[9]進行對比。 其中,BP 神經網絡輸入層節點為29,隱藏層節點為30,輸出層節點為36,得到一個29-30-36 的BP 神經網絡模型。 同時為了驗證本文提出的異常峰值去除算法的有效性,設計實驗將未經算法處理的樣本與經算法處理的樣本在各識別分類算法中訓練,在各分類算法中得到的準確率見表1。

表1 各分類算法準確率對比Tab. 1 Comparison of the accuracy of several classification algorithms
從表1 中可以看出,使用異常峰值去除算法后,各分類算法的準確率均有提高,平均提高了0.98%。從各分類算法可以看出,級聯森林分類算法的準確率明顯高于支持向量機和BP 神經網絡,分類效果更佳;同時在運行時間方面(訓練+測試)也表明了級聯森林算法模型訓練的高效率以及可擴展性。
3 實驗驗證
為了驗證公開數據集實驗方案的有效性,本文自行采集人體真實步行數據進行實驗驗證。 使用自行開發的手機APP 采集受試者行走時加速度傳感器的數據,采樣頻率為14 Hz,使用一階低通濾波器去除重力的影響。 在公開數據集中,手機放在大腿的便攜包里,加速度傳感器的Y軸平行于重力加速度方向,而在自采數據集中,手持手機行走時的加速度傳感器的Z軸平行于重力加速度方向,如圖6(a)所示。 因此,在驗證實驗中以Z軸數據為基準進行實驗。

圖6 實驗采集場地和手持手機圖Fig. 6 The site for collecting data and picture of handheld phone
所選的受試者均為在校本科生和研究生,身高為155~180 cm,體重45~80 kg,年齡20~25 歲。 本次實驗共采集了11 名受試者的步行數據,要求受試者在走廊從規定的起始點步行至結束點,記為第一次步行實驗數據name1,再從結束點步行至起始點,記為第二次步行實驗數據name2。 如此反復,每名受試者采集5 次,采集到的數據以txt 文本文件記錄,以“姓名+編號”命名,實驗步行場景如圖6(b)所示。 將每名受試者的5 次步行數據樣本中,編號為1、2、3 的步行數據作為訓練集,編號為4、5 的步行數據樣本作為測試集。 由于每次步行數據的采樣點在350-450 之間,因此以步長為30 且窗口為250選擇有效數據段,將訓練集選擇后的數據以1.2 節的方法進行預處理,特征提取后使用分類算法訓練。測試集數據使用與訓練集數據同樣的數據選擇方式、預處理和特征提取操作,最后輸入到模型中進行身份識別。
選擇的訓練樣本數據和測試樣本數據得到的結果可能存在偶然性,因此對5 次步行數據樣本輪流選取3 次步行數據樣本作為訓練數據進行實驗,剩余2 次步行數據作為測試數據,即=10 組。 使用支持向量機、BP 神經網絡和級聯森林分類算法在各樣本組的準確率見表2。 其中,訓練數據樣本編號為1、2、3 在級聯森林、支持向量機和BP 神經網絡模型的混淆矩陣分別如圖7(a)、圖7(b)和圖7(c)所示。

表2 三種分類算法在各樣本組的準確率Tab. 2 The accuracy of three classification algorithms in various sample groups%
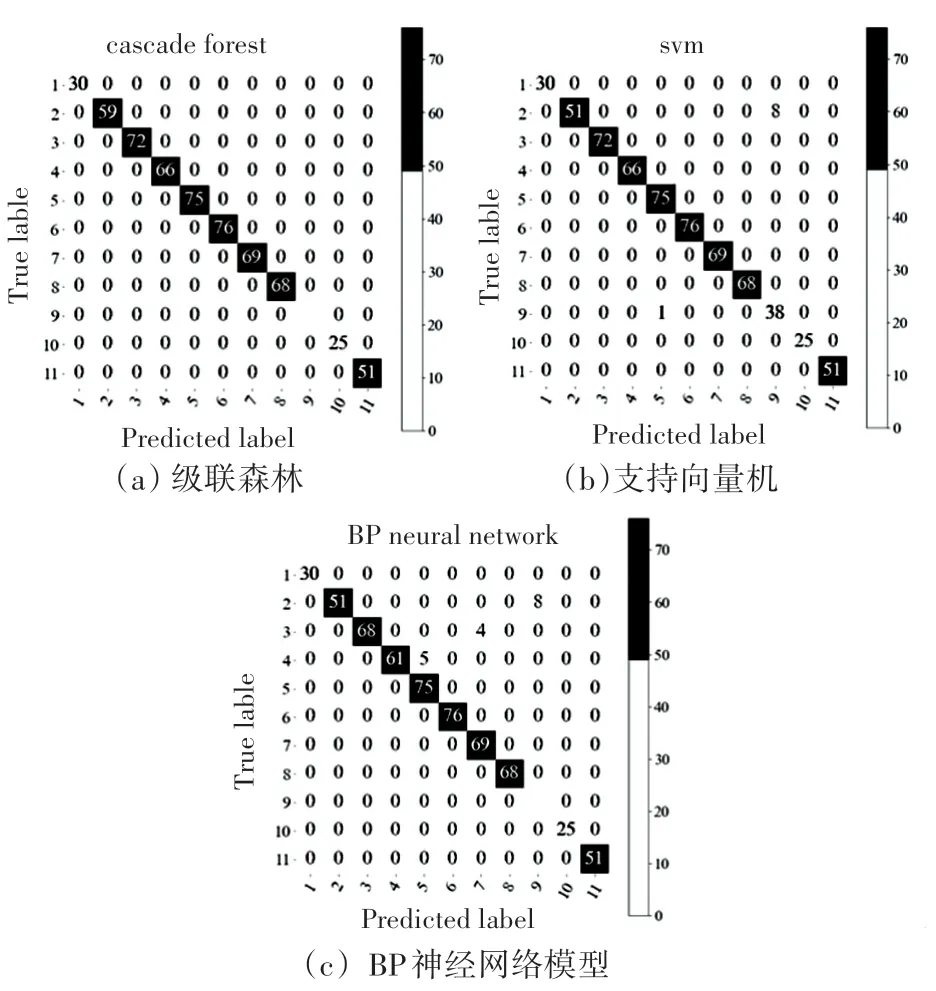
圖7 三種分類識別算法的混淆矩陣Fig. 7 Confusion matrix of three classification algorithms
為了進一步驗證所提算法的有效性,將經異常極值去除算法處理過的數據與未處理過的數據在級聯森林模型中對比,得到的10 組不同訓練集和測試集的準確率如圖8 所示。
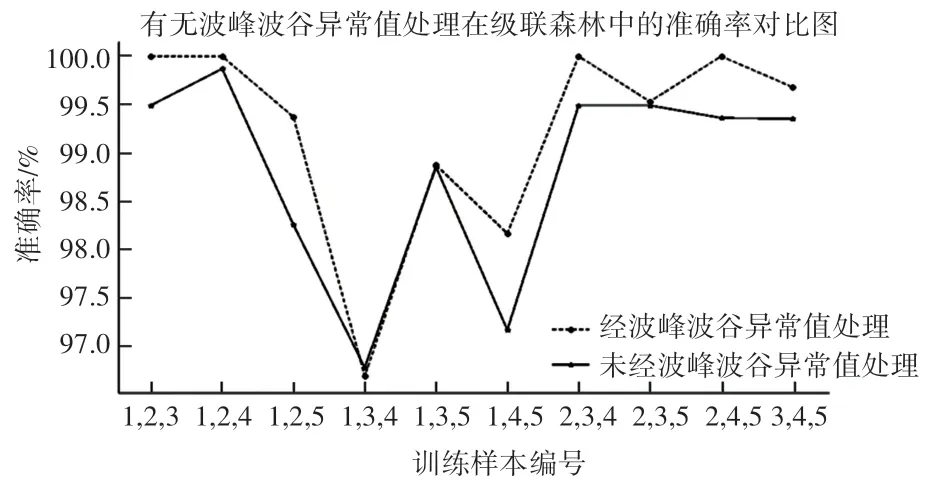
圖8 有無波峰波谷異常值處理在級聯森林中的準確率Fig. 8 Comparison of accuracy with and without peaks and troughs abnormal value processing in cascaded forest
由圖8 中可見,經異常峰值去除算法處理后的平均準確率為99.23%,未經處理的準確率為98.81%,準確率提升了0.42%,再次驗證了此方法對于提升識別準確率有較好的效果。
4 結束語
針對現階段身份識別準確率低的問題,在充分分析加速度信號之后,考慮到信號中會出現小部分異常極值的現象,提出了基于四分位數去除異常極值算法來進一步提高識別準確率。 實驗結果表明,在公開數據集和自采數據集上,經過算法處理后的識別準確率均得到進一步提高,并驗證了級聯森林分類算法在身份識別領域有較好的實際價值。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
