甲骨文識別技術研究現狀與展望
2023-06-14 13:25:45劉洋陸逸魏鈺馳孫智瑩朱立芳
知識管理論壇
2023年2期
關鍵詞:研究進展
劉洋 陸逸 魏鈺馳 孫智瑩 朱立芳
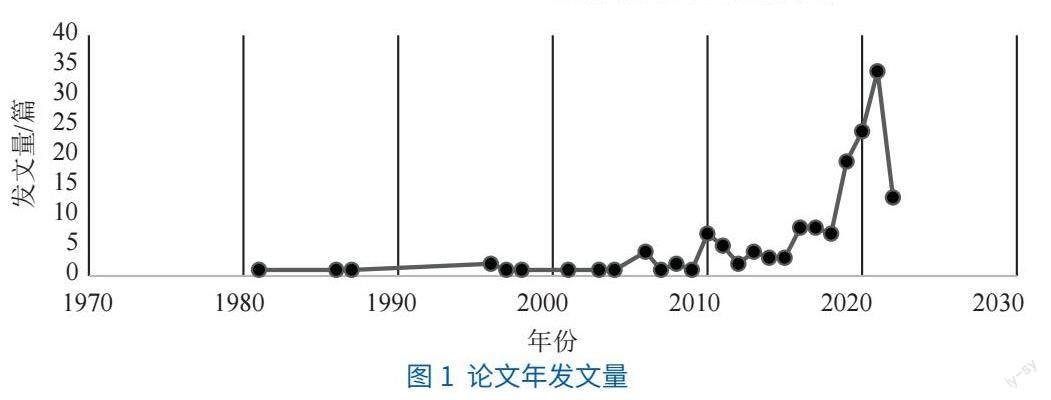
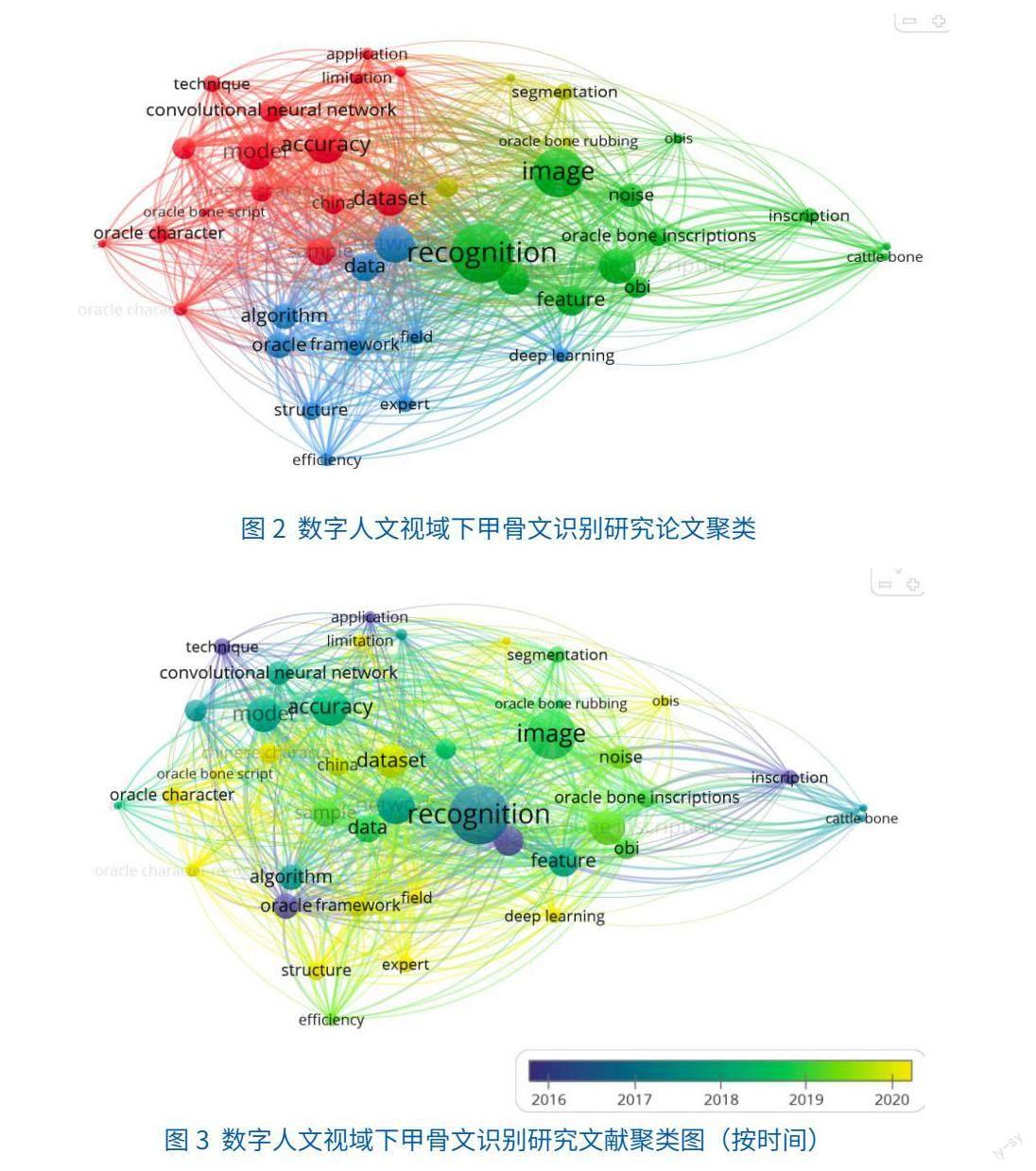
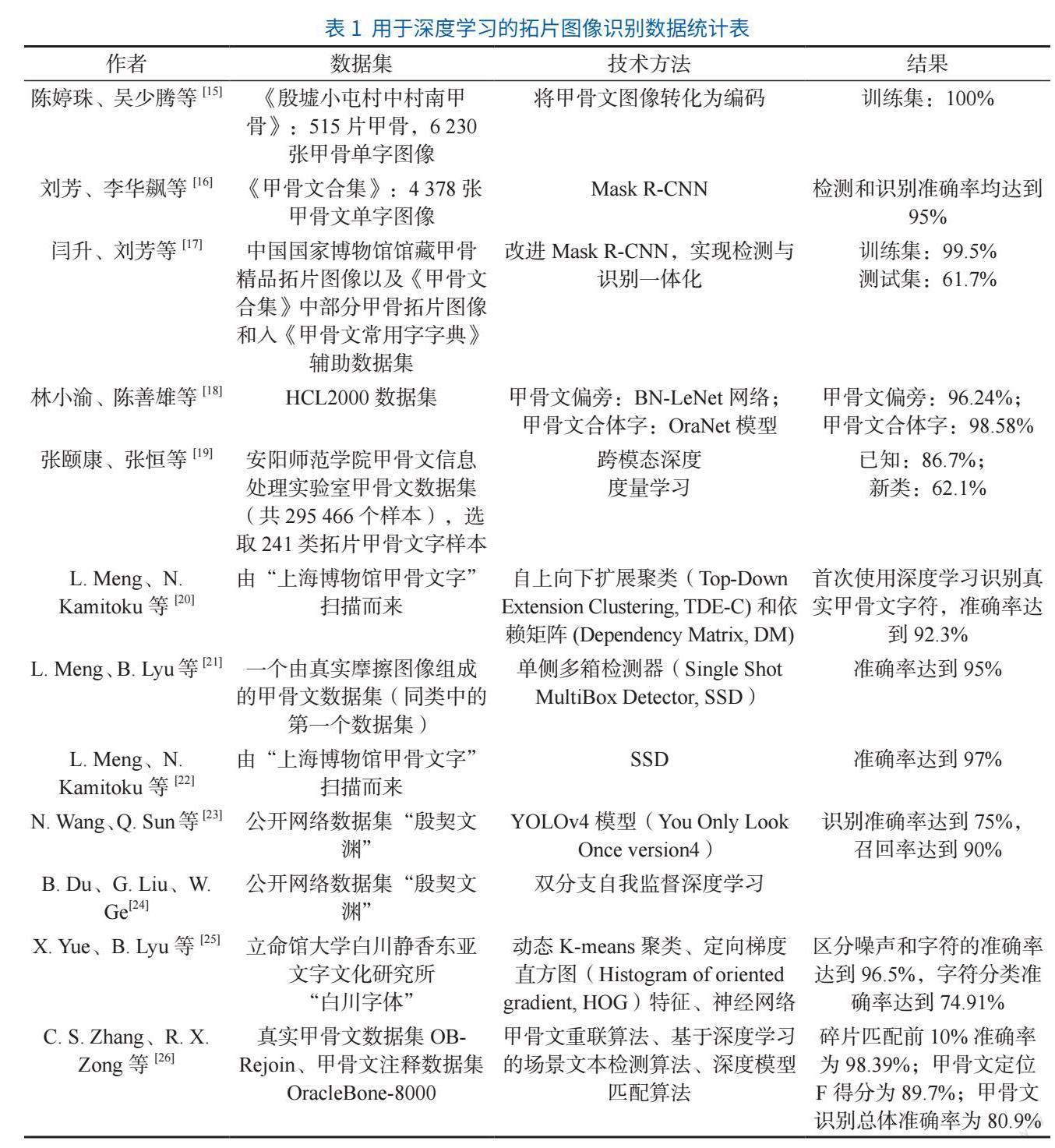
摘要:[目的/意義]對數字人文視域下甲骨文識別研究進行系統性綜述,為后續研究提供參考和借鑒,推動數字人文研究有效發展與古籍文字識別利用。[方法/過程]采用文獻計量分析的方法,在WOS、中國知網等多個學術平臺檢索文獻,共篩選103篇英文文獻和52篇中文文獻進行綜述。[結果/結論]從傳統識別技術、機器學習和深度學習3個層面解讀甲骨文識別研究現狀,但并未深入闡述識別算法機制。甲骨文識別技術由傳統的特征提取逐漸轉為基于深度學習的識別技術,在識別精度等方面有很大提升,但仍存在一些不足,同時甲骨文知識庫、知識圖譜的構建與領域知識的建立在該領域有較好的發展潛力。
關鍵詞:數字人文? ? 甲骨文識別? ? 研究進展? ?系統性綜述
分類號:G203
引用格式:劉洋, 陸逸, 魏鈺馳, 等. 甲骨文識別技術研究現狀與展望[J/OL]. 知識管理論壇, 2022, 8(2): 115-125[引用日期]. http://www.kmf.ac.cn/p/337/.
伴隨著數字技術與人文研究碰撞的不斷深入,作為交叉領域的“數字人文”研究其地位日益凸顯。數字人文借助信息技術、數字技術助力傳統人文學科研究,成為當下“新文科”發展的新生長點[1-2]。數字人文研究涉及多個領域,研究對象為人文學科領域各類可數字化的資源[3],形式上包括圖像資料、無格式文本、視頻音頻等,內容上包括歷史文獻、圖書檔案等。數字人文研究在文學、語言學、歷史、地理等多個領域發揮重要作用。
古籍數字化是數字人文研究最基礎的條件之一[4],甲骨文識別研究作為古籍數字化的重要一環,也是數字人文的研究對象,在古籍特定領域數字人文研究中具有重要意義。……
登錄APP查看全文
猜你喜歡
現代畜牧科技(2021年8期)2021-10-13 07:21:46
昆明醫科大學學報(2021年3期)2021-07-22 07:40:08
心肺血管病雜志(2019年9期)2019-12-09 08:34:04
制造技術與機床(2019年10期)2019-10-26 02:47:12
中成藥(2017年9期)2017-12-19 13:34:44
老年醫學與保健(2017年6期)2017-02-06 05:30:03
中國塑料(2016年4期)2016-06-27 06:33:22
中國醫藥導報(2015年27期)2015-02-28 22:08:05
西南軍醫(2015年2期)2015-01-22 09:09:38
西南軍醫(2015年1期)2015-01-22 09:08:36