可能性聚類假設的多模適應學習方法
2023-06-07 08:30:16但雨芳陶劍文趙寶奇
計算機與生活 2023年6期
但雨芳,陶劍文,趙 悅,潘 婕,趙寶奇
1.寧波職業技術學院 電子信息工程學院,浙江 寧波315800
2.哈爾濱工業大學 航天學院,哈爾濱150001
在統計學中,評估一個參數模型需要大量的訓練樣本。在現實的某些視覺應用中,可以輕松、廉價地收集未標記數據,獲取大量已標記數據則需耗費大量的人力和物力[1]。為此,一種常見的策略是將有限標記數據和大量未標記數據都利用起來,以學習更有效的學習模型,稱為半監督學習(semi-supervised learning,SSL)[2]。基于圖的SSL(graph SSL,GSSL)[3]具有優雅的數學表示和出色性能,已發展成為SSL領域最熱門的研究主題之一。調和函數方法[2]和局部與全局一致性方法[4]是兩種代表性的GSSL 方法,這些方法屬于GSSL轉導式推理;而流形正則化[5-7]是一種有效的GSSL歸納式推理,通過添加基于幾何的正則化項,實現將支持向量機(support vector machine,SVM)的回歸和分類都擴展到半監督形式。通常情況下,采用GSSL 推理方式都需要采用某種假設,比較常見的聚類假設為:“類似的實例應具有相同的類別”[8-9]。該假設還具有一個隱含條件就是每個實例都只屬于一個類別,即,硬分類。然而,在實際視覺應用中無法滿足該條件。為了解決該類聚類假設的硬分類問題,Wang等人[10]提出了一種新的基于聚類假設半監督分類方法(semi-supervised classification based on class membership,SSCCM),是聚類假設的一種軟分類方法,其旨在“類似實例應共享相同的標簽隸屬度”,每個實例可以隸屬于多個類別和相應的隸屬度值,很好地利用了模糊性聚類假設[11],其約束條件是每個實例對于不同標簽的隸屬度值之和總為1,可能會導致屬于某個類別的某些噪聲數據標簽隸屬度值與正常數據的標簽隸屬度值相近,甚至某些噪聲數據標簽隸屬度值會更大,最后導致錯誤分類。
針對SSCCM 方法存在的問題,但雨芳等人[12]提出基于可能性聚類假設的半監督分類方法(semisupervised classification method of possibilistic clustering assumption,SSPCA),方法放寬了SSCCM 中隸屬度和為1的約束條件,并通過模糊熵正則化項來增加樣本判別信息量,使得隸屬度函數具有更好的泛化性,從而克服噪聲、異常數據對分類方法的干擾,更進一步提高魯棒有效性。Wang等人[13]提出具有安全意識的半監督分類(safety-aware semi-supervised classification,SA-SSCCM)方法,通過對未標記數據是否有利于模型訓練分別指定了SSCCM 方法為上界和最小二乘SVM(least-square support vector machine,LSSVM)方法為下界,即,如果未標記數據有利于模型訓練,那么SA-SSCCM 的性能與SSCCM 接近;如果未標記數據對模型訓練起到反作用,那么,SASSCCM 的性能就接近LS-SVM 方法,也避免了噪聲數據干擾SA-SSCCM 模型的訓練。SSPCA 方法和SA-SSCCM方法均要求訓練數據和測試數據為獨立同分布,而在現實應用中,較難保證二者數據獨立同分布,導致識別準確率也會有一定的影響;比如,車牌識別中,訓練圖像數據都是晴天拍攝的,卻在雨天識別車牌;人臉識別,訓練圖像數據都是正臉采集的,由于人臉識別器的攝像頭與需識別的人高度不一致,采集到的人臉圖片有可能不是正臉等,都可能導致數據分布不同。
為了解決訓練數據和測試數據分布不同導致識別準確率降低問題,本文借鑒了有關計算機視覺和機器學習[14-15]的領域適應學習方法(domain adaptation learning,DAL)[16-18],DAL 的常見劃分有基于實例的DAL、基于特征的DAL 和基于模型的DAL[1]。基于實例的DAL 和基于特征的DAL 均需在訓練階段訪問源數據集,當源數據集相對較大時,訓練效率會降低;基于模型的DAL 是利用基于某些源數據集上預訓練好的源分類器模型來學習有效的目標分類器模型,其具有較好的分類有效性和高效率。有興趣了解有關DAL類別的更多詳細信息的讀者可以參考文獻[1]。故本文提出一種基于可能性聚類的多模型適應學習方法(multi-model adaptation method of possibilistic clustering assumption,MA-PCA)。該方法的主要思路是:首先,根據流形學習假設[5-7],局部結構內樣本之間具有判別相似性,根據文獻[12]中的式(1),局部加權均值點由k-近鄰樣本集凸包組合而成,其代表了局部結構均值,因此,該局部結構內的樣本應與該均值具有判別一致性,即局部結構內各樣本與其對應局部均值點的標簽理應是相似(或一致)的。故此,假設每個樣本點與其對應的局部加權均值點(local weighted mean,LWM)[19-21]的標簽隸屬度相似,然后,通過決策函數和隸屬度函數將各自得到的分類預測結果進行相互驗證來提高分類可靠性,再通過模糊熵正則項來增大樣本判別信息量,得到一個泛化能力更強的隸屬度函數,從而克服噪聲和異常數據對分類結果的干擾,提高該分類方法的魯棒性。最后,通過加入多模型適應正則項,針對訓練數據與測試數據分布相同與不同來獲得泛化性能更好的分類模型。本文的主要貢獻在于:(1)提出了一種基于可能性聚類的多模型適應學習方法;(2)在多個輔助判別模型可以幫助少量標簽樣本進行半監督學習的假設下,引入了局部一致性拉普拉斯正則項和多模型適應的貢獻度約束正則項,其目的是擴大目標域的判別空間和保證源域與目標域內部數據間的幾何結構一致性,并解決了訓練數據與測試數據分布不一致問題;(3)最后在實際數據集上做了大量的實驗,證明了該方法具有更好的魯棒有效性和泛化性。
1 MA-PCA
本章將詳細介紹MA-PCA 的構思,其主要是利用從現有相關源數據集中獲得多個源模型(利用從某些不同源域的不同分布中訓練得到的模型)來學習具有魯棒半監督分類模型。為此,將兩個核心組件有機地統一到MA-PCA中:(1)任意一個實例應與其對應的局部加權均值點具有相似的標簽隸屬度;且通過模糊熵[22]正則項的加入來增大數據的判別信息量,提高模型的分類準確率和對噪聲數據的魯棒性。(2)假設多個源模型可以幫助從少量標記樣本進行半監督學習,則利用現有多源模型進行多源領域適應學習建立魯棒目標域分類模型,并同時考慮相同與不同分布的數據,通過約束多源模型的貢獻度參數來尋找最佳源模型,對目標域進行模型訓練。
1.1 問題描述
其中,Ne(xi)定義為xi的k個最近鄰實例的集合,xj∈Ne(xi)。G=(X,D)定義為無向權值圖,其中,D∈Rn×n為權重,Dji=Dij≥0。其中元素值的計算方法為:
1.2 MA-PCA的基本形式
由于SSPCA 方法與SA-SSCCM 方法均需要訓練數據與測試數據屬于同分布,那么,本文將SSPCA方法與多模型適應學習方法合理結合,即為具有更好泛化性的魯棒多模型適應學習的SSPCA 方法(MA-PCA),既提高了對噪聲的魯棒性,又解決了由標簽數據不足且有帶噪聲數據影響模型性能的問題以及訓練數據與測試數據分布不同的問題。因此,MA-PCA的基礎公式可為:
其中,ΩB(W,vm(xj)) 是SSPCA 方法中的目標函數,ΩM(W,γ)是多模型適應正則化函數,ΩB(W,vm(xj))公式描述為:
其中,λs、λ、C均為平衡參數,可以通過調節平衡參數來避免模型過擬合訓練,公式中其余參數請查看文獻[15]。
1.3 MA-PCA的多模型適應正則項構建
散度矩陣在將源分類器橋接到目標分類器中起重要作用,其將推動目標分類模型的學習導向目標數據的真實分布方向,進而提升適應學習的泛化性能,這與其他基于DAL 模型的領域適應正則項[20]具有本質上不同。為了更貼合模型思想,本文將式(4)稱為散度約束多模型適應正則化項的構建。
1.4 最終形式
通過將SSPCA方法和多源分類器模型進行結合來獲得更好的模型分類結果,故將式(3)和式(4)結合起來得到一個統一框架MA-PCA,聯合學習W、vm(xj)、γ,MA-PCA的優化問題可描述為:
其中,γ=[γ1,γ2,…,γq]T,γ∈Rq×1,γT1q=1,q為源域模型的個數;當β=0 時,MA-PCA就退化到SSPCA;當β>0 時,β作為一個平衡參數;當γi為常量1時,表明只有單一源域,且與目標域分布相同,此時的MA-PCA近似SA-SSCCM方法;當0 ≤γi<1,則MAPCA 是基于可能性聚類假設的多模型適應學習方法,其源域與目標域分布可以相同,也可以不同。
2 算法優化
MA-PCA 的優化問題是一個關于(W,vm(xj),γ)非凸問題,本文是采取交替迭代優化的策略來分別實現決策模型W、標簽隸屬度模型vm(xj)和源域模型的貢獻度系數γ的優化求解,且每一步迭代均有一個閉環解。
2.1 固定vm(xj)和γ 求解W
2.2 固定W 和γ 求解vm(xj)
然后,固定W和γ求解vm(xj),目標函數(即式(5))的原始優化問題可描述為:
2.3 固定W 和vm(xj)求解γ
定理1[24]式(11)的優化解可由如下公式得出:
定理1 表明,最優γ只有ζ個非零項,那么該優化方法可依據γ自動選擇相對重要的源域,忽略不相關源域或噪聲源來進行判別區分。由于可以通過給定最優ζ來計算最優γ,Masayuki等人[24]進一步提出了一種尋找最優ζ的算法,如果給定源域數量保持在中等大小,則可以證明該算法足夠有效。
本文采用基于坐標下降的算法來求解式(11),類似于文獻[25]中的方法。每次迭代循環中,在其他項都固定的情況下選擇兩項進行更新,且每次迭代結束均需滿足約束條件γT1q=1。例如,在某次迭代循環中,對第i和第j項進行更新,可得出如下迭代公式:
迭代遍歷γ中的所有配對項,并使用式(12)優化γ中的任何兩個項,直到優化函數(5)收斂為止。直觀來看,式(12)中的更新標準傾向于分配給γi的值越大,Ai就越小。由于Ai衡量第i個源模型對目標域的分布距離,Ai越小,第i個源域模型與目標域的相關性越高。
在求得最優解W和vm(xj)后,目標域樣本的標簽矩陣亦可得出,噪聲影響可以得到有效抑制。而對于新樣本的標簽和隸屬度可通過W和vm(xj)推算出來。最后,W分類的性能依賴于所習得圖G=(X,D)的質量以及多源域模型的域適應。
2.4 收斂性討論
由于目標函數式(5)是多目標優化函數,難以保證整體最優解,本文算法實現采取交替迭代優化策略,其針對單個優化變量的目標函數(即,式(6)、式(8)和式(11))是凸函數,其迭代解析式為合式(closed form),因而能獲得迭代最優解。在此,本文僅依據目標函數的迭代目標值進行算法的漸進收斂性推導,推導過程見式(13):
其中,Witr、vitr、γitr分別為第itr輪迭代的參數最優值,ε是一個非常小的常量,因此,目標函數將收斂于一個局部最優。推導的過程證明了算法迭代目標值呈下降趨勢,當迭代目標值下降到一定閾值(至少大于常數ε>0)時停止算法迭代過程,目標函數將收斂于各單個優化變量的局部目標值最優。
3 算法描述
MA-PCA 是采用交替迭代的優化策略,大多數半監督學習方法常用迭代式學習進行優化。另外,初始化未帶標簽的實例隸屬度值能通過以下任一種方法獲得:某種模糊聚類方法(如FCM(fuzzy C-means)等)、隨機化策略或全部初始化為0。因此,MA-PCA方法的學習一開始就是帶標簽學習來初始化決策模型W,當目標函數收斂時,迭代終止。具體來說,本文算法采用了基于窗口的停止準則來更好地控制算法收斂:給定一個窗口大小?,在第itr次迭代中計算?=|maxΘitr-minΘitr|/maxΘitr,其 中Θitr={Objitr-?+1,Objitr-?+2,…,Objitr}表示由該窗口中的歷史目標值組成的集合,當?小于某個閾值ε時,即?<ε,算法將停止迭代。該算法描述如算法1所示。
算法1MA-PCA算法
4 實驗
本章將通過實驗證明所提MA-PCA方法在目標識別、Web圖像標注和視頻概念識別三種多源域適應學習任務上的魯棒性和泛化性。為了評估MA-PCA方法的多源域適應學習性能,利用多個真實圖像數據集,例如通用目標集(Caltech-256[26]和Office[27])、圖像集(NUS-WIDE[28])和視頻語料庫(TRECVID 2005)[29],本章將總結分析在交叉域的視覺識別任務上關于域自適應學習的結果。
4.1 數據集描述
Caltech-256 數據集:該數據集最初是為了評估視覺域自適應學習方法而被廣泛應用,包含256個目標類別,其中一個類別在目標識別任務中為負類,該數據集中所有目標以層級形式進行管理,從而可輕松識別相關和不相關類別。本文下載了預計算的特征(http://files.is.tue.mpg.de/pgehler/projects/iccv09/)[30],并為圖像特征選擇了尺度不變特征變換(scale invariant feature transform,SIFT)描述語[31],其均在空間金字塔中進行計算,本實驗只考慮第一層(即從整個圖像中提取的信息),且對該數據集采用留一交叉驗證策略(即輪流將一個類別作為目標域,其余類作為源域)進行實驗。
擴展Office 數據集:該數據集包含4 個視覺源Amazon(A)、DSLR(D)、Webcam(W)和Caltech-256(C)。每兩個視覺源之間有10個共同類別,總共包含2 533個圖像。根據實驗設置[32],通過多源域適應學習來評估本文MA-PCA方法,將設定一個視覺源為目標域,且其他都為源域,在目標域的31個類別上進行測試。在本實驗中,所有圖像尺寸按照比例縮放為150×150以內大小并轉換為灰度圖。在源域中,Amazon和Caltech中每個類別分別選擇20個訓練樣本,DSLR和Webcam中每個類別分別選擇10個訓練樣本。
NUS-WIDE 數據集:本文在該數據集上為交叉域圖像標注任務做了一系列實驗,此數據集包含81個概念的269 648個帶標簽的Web圖像,本實驗使用的特征是500 維視覺詞袋。為了模擬有意義的自適應環境,本文實驗從數據庫中選擇了12種動物概念,包括熊貓、猴子、貓、斑馬、老虎、鳥、狗、青蛙、馬、蝴蝶、蛇和長頸鹿。這些動物被認為具有一些共同特征,可以利用這些特征來進行領域自適應學習。在實驗中通過7 種劃分方式分別隨機抽取多個概念作為源域,剩余定義都作為目標域。詳細劃分信息在表1中顯示。

表1 NUS-WIDE數據集的域設置Table 1 Domain setting of NUS-WIDE dataset
TRECVID 2005 視頻語料庫(http://www-nlpir.nist.gov/projects/trecvid):該數據集是以研究為目的的最大帶標簽視頻數據集之一,包含從6個不同廣播頻道(包括3 個英語頻道CNN、MSNBC、NBC,兩個中文頻道CCTV、NTDTV 和一個阿拉伯語頻道LBC)共108 h視頻節目中提取的61 901個關鍵幀。每個頻道關鍵幀總數量列在表2中。從LSCOM精簡詞典中選擇了36 個語義概念[33],其涵蓋了廣播新聞視頻中出現的36個主流視覺概念,包括目標、位置、人物、事件和節目,且這36 個概念已經手動標注來描述TRECVID 2005 數據集中關鍵幀的視覺內容。從中可知,這6 個頻道的數據分布完全不同,其更適于評估域自適應學習方法。本文在測試數據上使用分類文獻[33]精度作為評估指標[34],如下所示:

表2 TRECVID 2005數據集的描述Table 2 Description of TRECVID 2005 dataset
其中,f(x)為分類算法的預測標簽,yx為x的真標簽,整體精度Acc為分類度量的參照。具體而言,在視頻概念檢測問題中,為了進行性能評估,本文使用非插值平均精度(average precision,AP)[33],該精度自2001 年以來一直作為TRECVID 的官方性能指標。AP與召回率曲線的多點平均精度值相關,在計算AP時包含召回對整個分類結果的影響。
4.2 基礎設置
該實驗將以多源視覺識別任務比較本文所提MA-PCA方法與以下最新相關基準方法:
(1)沒有領域適應的方法:SSPCA[15]。
(2)多核適應方法:FastDAM[35]。該代碼可以在線獲 取(http://vc.sce.ntu.edu.sg/transfer_learning_domain_adaptation_data/DAM-TNNLS2012.html)。
(3)多模型知識遷移:Multi-KT[32]。該代碼可以在線獲取(http://homes.esat.kuleuven.be/~ttommasi/source_code_CVPR10.html)。
(4)自適應SVM:A-SVM[29]。MATLAB代碼可以在線獲取(http://www.robots.ox.ac.uk/~vgg/software/tabularasa/)。
(5)域選擇機制:DSM[36]。
由于帶標簽和無標簽數據是從不同分布中抽樣得到的,對于使用交叉驗證的源分類器不可能進行參數自動調優,本文在數據集上評估所有方法都是通過經驗搜索參數空間來進行優化參數設置,以此獲得每個方法最好的結果。所有方法的參數調整都是為了得到最好結果,特殊指定的參數除外。
對于沒有領域適應的方法SSPCA 而言,本實驗將融合從每個源域與目標域中帶標簽樣本獨立訓練得到所有分類器的決策值,DSM、Multi-KT、A-SVM和FastDAM 能處理來自多源域的訓練樣本,對于ASVM,本實驗也將對所有基本分類器的決策值進行融合,且每個分類器都是由一個源域中帶標簽樣本而習得,對于每個源域,均通過帶標簽樣本進行訓練SVM 的,對于每個測試樣例x,通過采用sigmoid 函數(即g(t)=1/(1+exp(-t)))。將p個SVM 分類器獲得的決策值轉換成概率值,最后,將p個概率值的平均值作為測試樣例x的最終預測值。
在式(5)中有一些超參數需要提前設置,首先,該實驗在迭代優化過程中確定了最重要的參數(例如γi)當作優化變量,僅有幾個至關重要的參數在本文所提模型中需要預定義(例如λ、λs、C、η、β),考慮到在機器學習領域中參數確定是一個還未得到解決的開放問題,在過去的工作中均根據經驗確定參數。由于γi的指數在優化的γi過程中都是扮演著避免平凡解的角色,根據文獻[37]中所證明的,γi的指數越大,所有權重值就更接近一致。為了體現出不同源域間的差異性,根據經驗,本實驗將設置γi的指數為2。下一節實驗結果中會驗證該選擇的有效性。超參數λ、λs、C、η、β是在{10-4,10-3,…,103,104}范圍內進行調整。此外,為了在MA-PCA(同樣也在SSPCA)中構建最近鄰圖,本實驗在網格{3,5,10,15,17}范圍內搜索最優最近鄰數量并從最優參數配置中獲取排名第一的識別準確率。
對于非線性學習方法MA-PCA、FastDAM 和Multi-KT,高斯核Ki,j=exp(-σ||xi-xj||2)作為默認的核函數,其中σ=1/d(d為特征維數)。在FastDAM中,設置了每個源的權重γi=2,…,S),其中δ=100。對于基準方法SSPCA,在沒有任何域適應的情況下直接將目標域樣本映射到源域,均等地融合從每個源域與目標域中帶標簽樣本獨立訓練得到所有分類器的決策值。
4.3 在不同數據集上的實驗分析
4.3.1 在Caltech-256數據集上的結果
首先考慮從Caltech-256中隨機抽取分別有10類別和有20類別的兩個數據集,每類由80個目標和80個背景的圖像組合而成,其中,第二個數據集是在第一個數據集中隨機添加10 個類別所組成。圖1 為MA-PCA 方法和所有基準方法在兩個具有不同類別數量的數據集上的實驗結果,主要是針對具有代表性的6個目標類別進行識別性能比較。從該圖中可獲得3 個有價值的信息:(1)沒有領域適應的SSPCA 方法僅通過源域的標簽數據進行訓練,在目標任務上執行效果差,且其在所有情形下與其余方法相比性能最差,證明了在不同類別間存在分布差異;(2)在大部分情況下,MA-PCA的性能都比其他方法更好,歸因于在多源域適應中,MA-PCA 方法能挖掘出更多相關知識以及判別信息;(3)對于領域適應而言,對于目標域更有用的先驗知識的概率會隨著先驗源域有用信息的增加而增大,因此,在同等情況下,20 個類別的識別精度肯定要高于10個類別的識別精度。
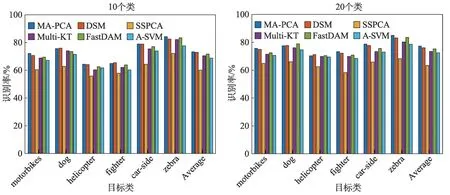
圖1 6個具有代表性目標類別的識別率Fig. 1 Recognition rate on 6 representative target classes
尤其在DA應用領域,人們期望先驗源域的有效數據量能及時增長。針對該問題,對于具體任務有必要探討每個先驗源域的可靠性[38]。因此,在Caltech-256 數據集中通過分別連續改變目標域帶標簽樣本數為150 和256 個對象類別來進行幾個實驗。在該情況下,實際執行的MA-PCA具有半監督學習特點,MA-PCA、DSM、Multi-KT、FastDAM和具有平均先驗模型的A-SVM的識別精確度如圖2所示。
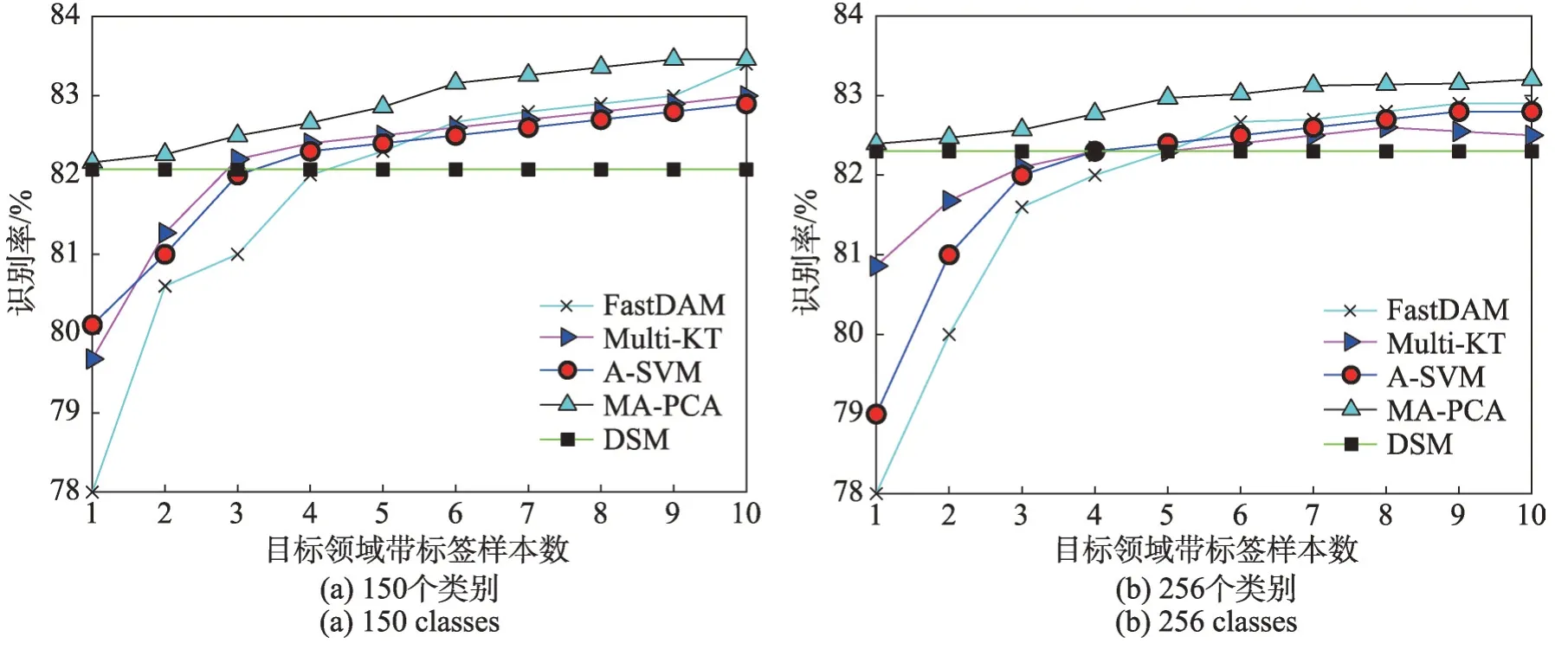
圖2 對于不同源域數據量的識別性能Fig. 2 Recognition performance for different number of source sets
此外,從圖2 可以得出,除了DSM 方法,其余方法對于帶標簽數據是敏感的,并顯示一致上升趨勢,表明了使用有限帶標簽的目標域數據有利于學習性能的改善;值得注意的是,隨著目標域帶標簽樣本的增加,MA-PCA的性能平滑穩定提升,而FastDAM和Multi-KT只有在目標域帶標簽樣本相對較大時,其性能才令人滿意。另外,在目標域訓練樣本相對大時,FastDAM優于Multi-KT和A-SVM,而MA-PCA卻比FastDAM 具有更好的效果;在目標域帶標簽樣本相對少的情況下,FastDAM 的性能最差,導致該情形的原因可能是除了使用源間的相關信息外,MA-PCA還能通過多源適應正則化選擇最相關源域的最佳權重。此外,FastDAM是基于MMD方法將權重分配給所有源域,可能會引起負遷移問題,導致其性能退化。
4.3.2 在Office-Caltech數據集上的結果
本實驗中,旨在評估本文所提MA-PCA 方法對Office-Caltech 數據集上所有31 個類別的識別性能,圖3 為6 種可能數據集組合成不同源域和目標域的識別精度。
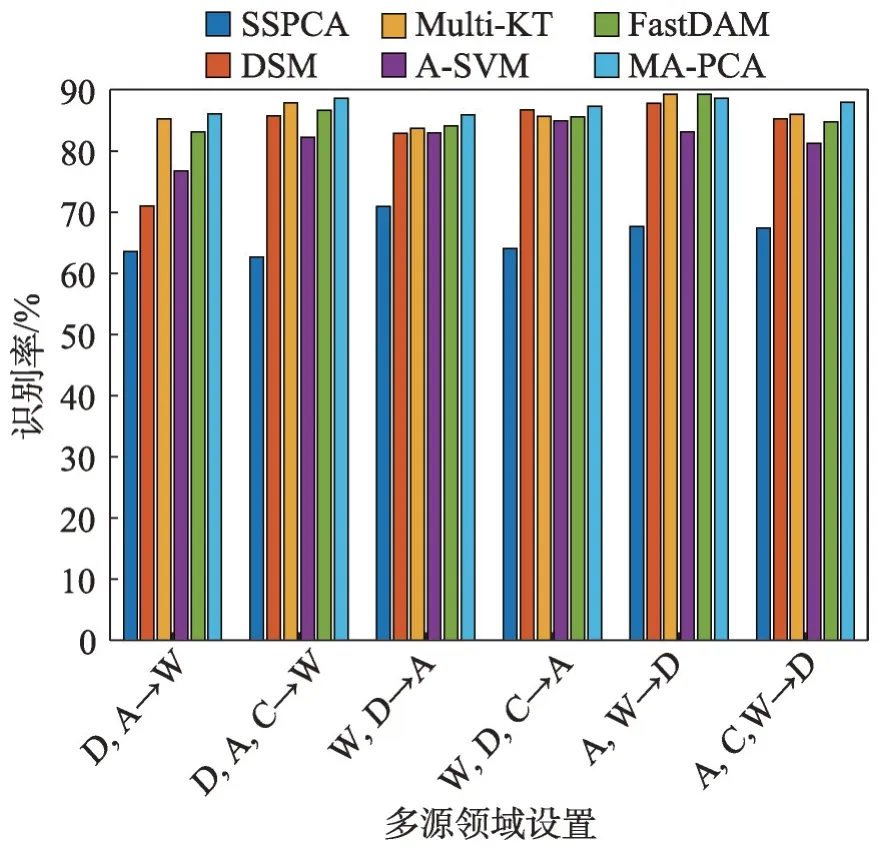
圖3 在擴展Office數據集上的對象識別率Fig. 3 Object recognition rate on extended Office dataset
從實驗結果可以得出,盡管MA-PCA 方法與其他方法比較沒有明顯優勢,但是MA-PCA 在所有組合中依然獲得更高分類精度,甚至優于在其他5種情況中的FastDAM 和Multi-KT 方法,其證明了MAPCA方法挖掘多源間和特征間相關性的多源共同適應的有效性。從圖3 中可知,FastDAM 和Multi-KT具有不穩定性,其可能是由于在這些核方法中核函數選擇不合適。SSPCA 在所有任務中的性能都最差,這是由于數據本質分布差導致的,對于不具備遷移學習能力的方法,源域訓練數據得到的模型在目標域上較難具備令人滿意的性能。最后,在大部分情況下,A-SVM與其他DA方法相比普遍較差,主要原因是,A-SVM不能考慮多個源域散度的分布度量。
4.3.3 在圖像標注上的結果
不同算法的圖像標注精度如圖4所示,且從圖中易看出,MA-PCA 方法在不同設置下均獲得相對較好性能,說明該算法在目標域中能有效改進圖像標注性能。另外,SSPCA 算法依然性能最差。還可以得出,A-SVM 相較于大部分的DA 方法獲得較差標準精度,其可能原因為,在域差較大時難以評估出最小化的域分布。最后,所有域適應方法都展示了隨著源域數增加其具有相同的上升趨勢。而在源域數逐漸增加時,MA-PCA方法具有更明顯的性能提升。
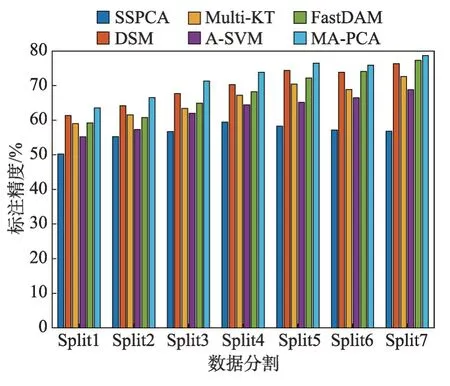
圖4 具有不同數據分割的圖像識別率Fig. 4 Image recognition rate with different dataset split
4.3.4 在視頻識別上的結果
在視頻數據集上不同方法的識別精度如圖5 所示,在大部分情形下,MA-PCA方法的性能明顯優于其他方法,由于MA-PCA 方法利用了源間相關信息進行特征選擇的判別多源域適應,能成功縮減域間分布差以及發現域間內部判別依據[39]。從圖5(a)中易知,FastDAM和Multi-KT在36種不同的MAP概念上實現了類似的性能,A-SVM 和Multi-KT 在所有頻道上達到了相似性能。除了MA-PCA 方法,DSM 獲得了在所有頻道的最好性能,其可能原因是,DSM可以通過在復雜的多源自適應場景中有判別地選擇一組預先學習的基分類器來學習更魯棒的目標分類器進行領域自適應。
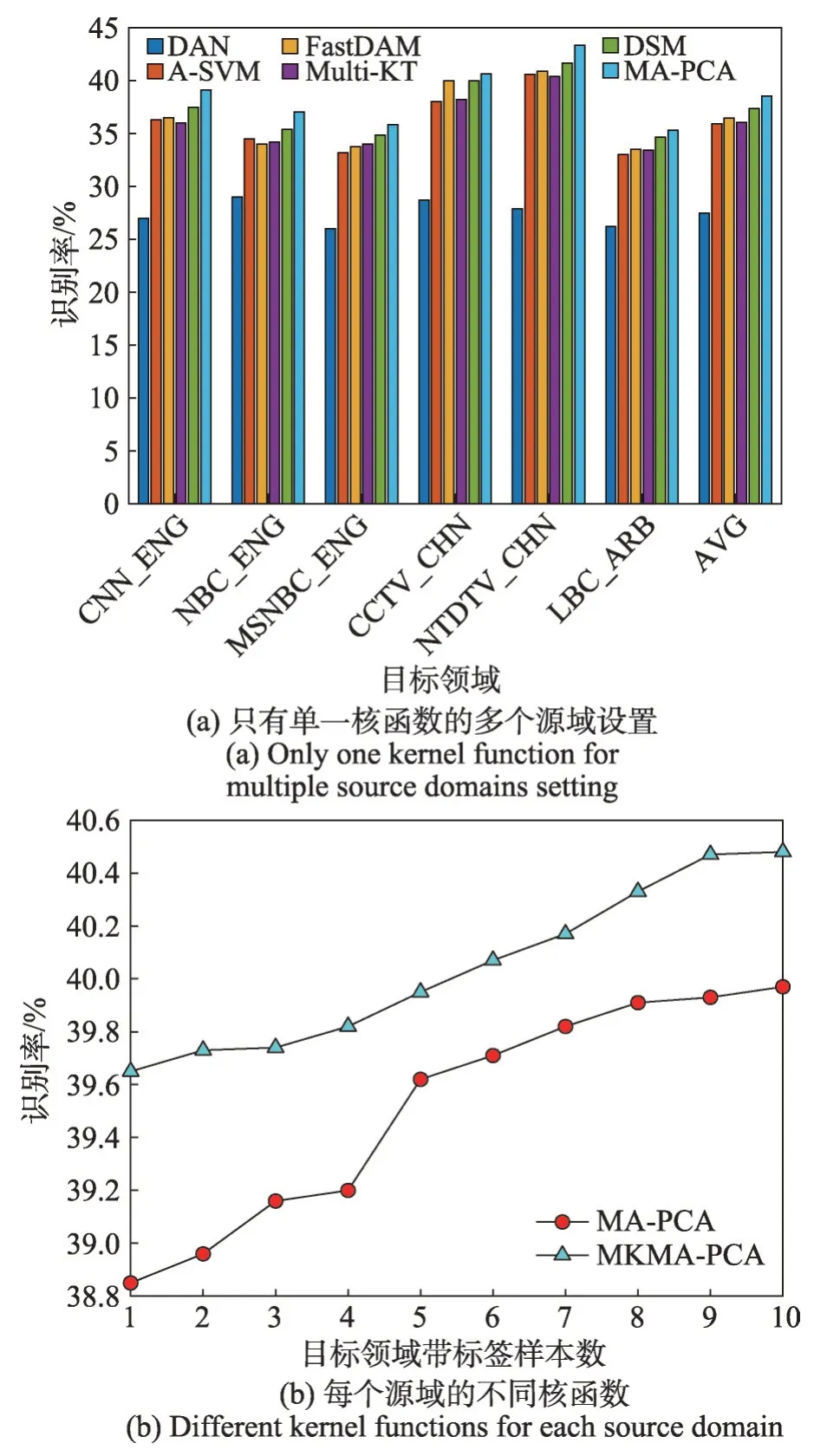
圖5 在36個定義上所有算法的識別性能Fig. 5 Recognition performance of all algorithms over 36 concepts
接下來進一步評估MA-PCA方法在每個源域使用不同核函數(簡稱為MKMA-PCA)的有效性。首先,值得說明的是,在基于核的機器學習方法(如SVM)中,核函數的選擇對于模型的泛化能力提升尤為關鍵。然而,核函數的優化選擇是一個開放性問題,即,核函數的有效性有賴于訓練數據的分布結構,如,線性核函數適用于線性分布結構數據,高斯核函數適用于非線性或球狀結構數據等。為了解決核函數的優化選擇問題,現有相關研究多采用多核函數組合技術來實現非線性模型學習[39],多核模型學習實際上是采用多個不同核函數來進行加權集成學習,以克服單一函數功能局限性所帶來的負面效應,該技術在一定程度上緩解了核函數的選擇難題。故此,MKMA-PCA方法采用多核組合技術來提升模型學習性能,除了采用上面提到的高斯核,還采用其他三種類型的核:拉普拉斯核、距離平方倒數核Kij=1/(1+σ||xi-xj||2)以及距離倒數核假設經驗核映射集合為,將每個Xi映射到不同核空間,本實驗通過串行方式將映射后的所有子空間都正交地整合到最后空間,例如,xj∈Xi,且Xi為第i個源的數據,ni為第i個源中樣本數量,在新空間中的最終核矩陣被定義為Knew=,其中,是第i個特征空間的核矩陣。本實驗將所有源域均領域適應到目標域,在[1,10]范圍內的隨機數為目標域帶標簽樣本數,從實驗結果圖5(b)易知,MKMA-PCA 的MAP 性能顯然比MA-PCA 方法更好,這表明采用多核函數組合技術能一定程度上提升MA-PCA方法的泛化性能。
4.4 多模適應回歸的魯棒性
本節進一步評估本文所提多模適應回歸框架在Caltech-256 數據集上的魯棒性。本文通過源和目標在背景知識不同相關性的兩組數據中進行實驗結果對比,從Caltech-256數據集中抽取指定的6個不相關類別(豎琴、微波爐、消防車、牛仔帽、蛇、盆景)和6個相關類別(都是車輛:推土機、消防車、摩托車、校車、雪地車、小汽車),并對Bing 文本搜索而收集到的每個類別web 圖像進行圖像增廣,允許噪聲范圍是{1,5,10,15,20,25,30},依次將每個類當作目標域,抽取20 個訓練樣本和100 個測試樣本,其中一半正樣本和一半負樣本。由于web 圖像是從網絡上隨機獲取,不可避免地在目標域訓練數據中出現大量的噪聲和異常數據[40-41]。
上述數據集的實驗結果如圖6,每個結果對應每個算法10次實驗的平均分類精度。從圖6中可以看出,由于MA-PCA方法采用了源模型選擇,有效利用了相關性較強的源模型,有助于提高目標域分類模型的訓練精度,MA-PCA方法在噪聲增加的情況下具有較好的穩定性和魯棒性。隨著噪聲的增加,所有方法的分類精度都有一定程度的降低,而MA-PCA方法相較于其他方法下降更慢。圖6(a)和圖6(b)的結果相似,這表明MA-PCA 方法對不相關類和相關類的噪聲都有較強的魯棒性,在這種情況下,目標分類器的魯棒性對于提高其泛化性能非常重要。
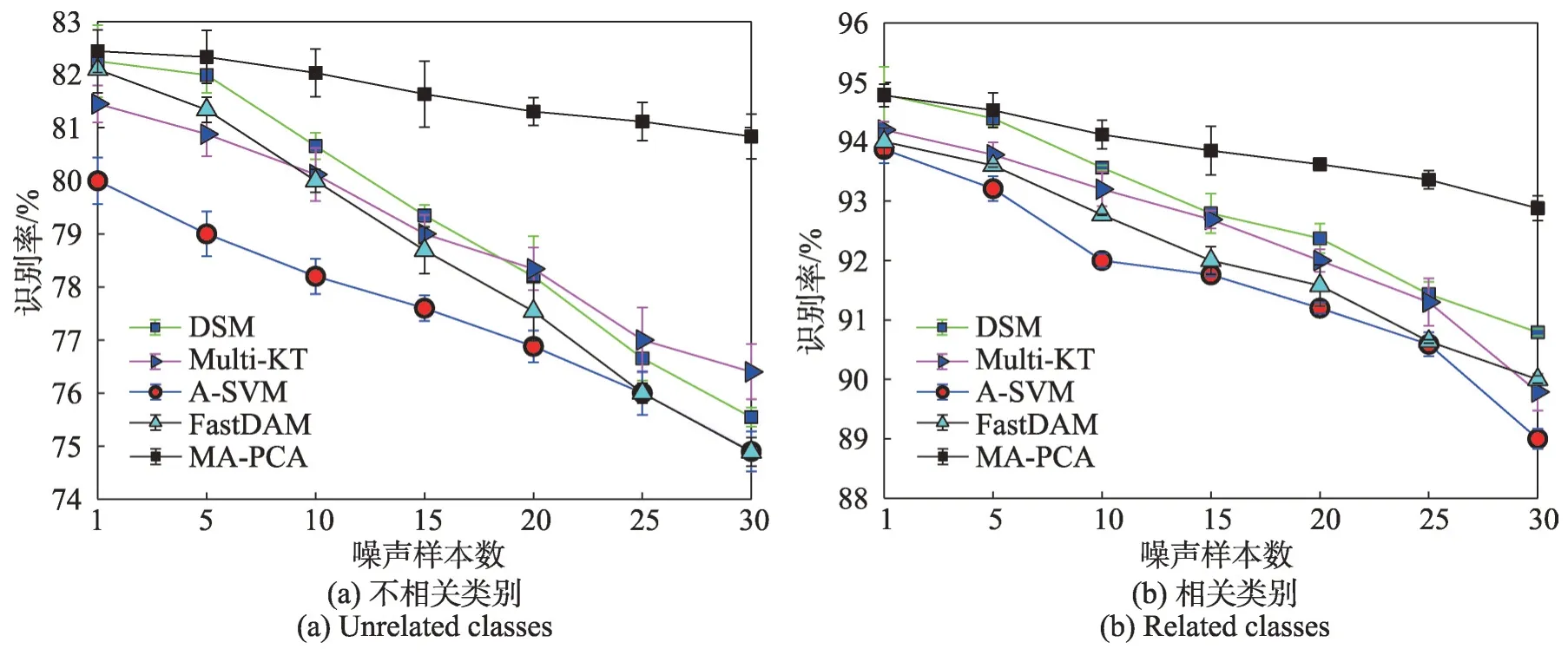
圖6 在具有不同噪聲大小時不同算法的識別率Fig. 6 Recognition rate for different algorithms with different sizes of noise
4.5 散度約束多模適應正則化的有效性
當多源設置有效時,鄰域適應學習(DAL)可考慮3種主要策略:(1)對于目標問題,僅選擇一個被評估為最佳的源;(2)假設所有源都是同樣重要的,對所有的源進行平均;(3)不同源具有不同程度的重要性,為每個源分配適當的權重來體現不同源的貢獻度,其中(1)和(2)為兩種極端的策略。本實驗重點研究第三種策略,分析源選擇對MA-PCA性能的影響。
值得注意的是,MA-PCA方法能找出權重向量γ中每個元素的最優值,即,每個源域對目標域貢獻度大小的值,并根據散度約束的多模適應學習來決定領域適應的方向和程度。為了便于對比,本文設計兩個計算權重向量γ的基準方案作為對比:(1)平均先驗知識(average prior knowledge,APK)[42],該方案對先驗知識的可靠性不做任何假設,先驗知識通常指所有已知源的平均值;(2)距離權重知識(distanceweighted knowledge,DWK),該方案已經在FastDAM和DTMKL[8]中采用,其在目標域和第i(i=1,2,…,q)個源域使用了最大均值差(MMD)來定義適應權重γi且,其中,為目標域與第i個源域的距離。本節評估了MA-PCA 在Caltech-256 數據集上的源選擇和散度約束的正面效果,從Caltech-256 數據集中分別隨機抽取10 個類別和20 個類別的兩個數據集,并比較了兩個數據集上所獲得的結果。為了進行區分,MA-PCA_NSC 表示沒有散度約束(即S=Id×d)的MA-PCA。MA-PCA算法使用總散度約束來自定義每個源模型與目標任務的相關性,此處分析獲得的權重向量γ作為領域適應過程的一個附加項,以此來驗證其元素在目標模型與每個源模型間是否有對應關系。本節將分析4個比較結果,即,MA-PCA 通過采用以下3種方案計算源模型的權重系數,例如APK、DWK以及判別選擇方案分別命名為MA-PCA_AVG、MA-PCA_MMD 和MA-PCA,和沒有散度約束的MA-PCA被命名為MAPCA_NSC。
最后,所有的結果如圖7 所示,從圖中得到以下比較有意義的觀察結果:
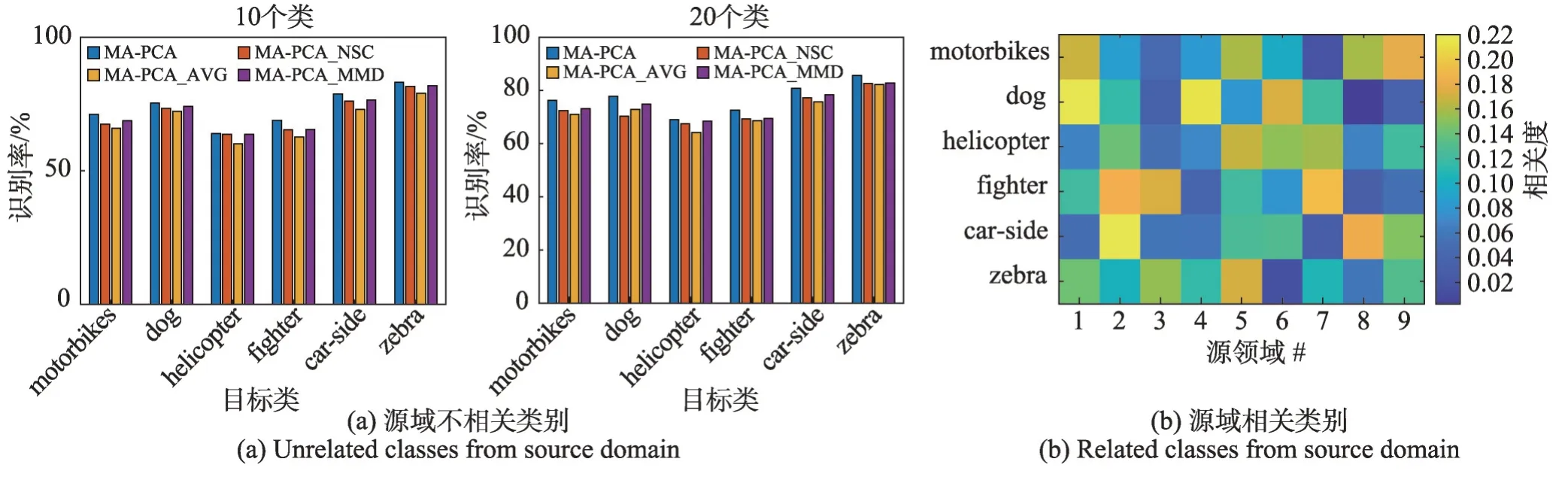
圖7 源域不相關類別和源域相關類別在6種有代表性目標類別上的識別率Fig. 7 Recognition rates of unrelated classes and related classes from source domain on 6 representative target classes
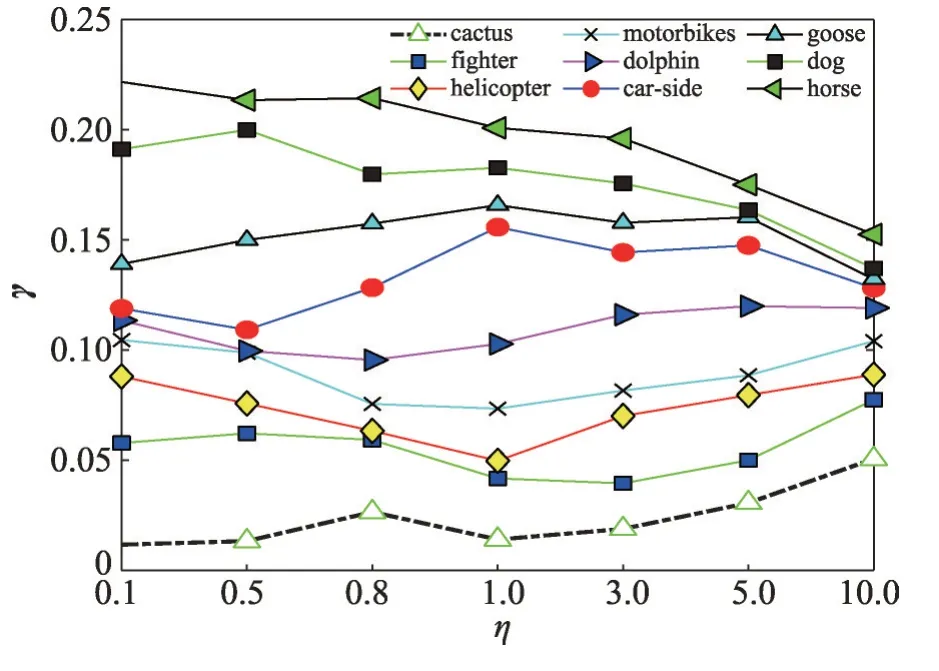
圖8 在具有10個類別的斑馬對象識別上η的變化路徑(γ ∈R10)Fig. 8 Regularization path for η on zebra object recognition with 10 classes(γ ∈R10)
(1)從圖7(a)中易發現,MA-PCA優于其他方法,歸因于在MA-PCA方法中源模型選擇策略的有效性。
(2)MA-PCA和MA-PCA_MMD方法適當地為每一個先驗源模型賦予權重值比MA-PCA_AVG方法對所有已知模型進行平均更好。從圖7(a)中可發現,在所有情況下,MA-PCA_NSC依然優于MA-PCA_AVG,這可能是由于MA-PCA有效利用了相關性較強的源模型。然而,MA-PCA_NSC的性能比MA-PCA稍差,該現象證明了散度矩陣S保留了數據的整體幾何結構信息,更進一步提高了模型分類可靠性。
(3)在圖7(b)中,關于γ的權重熱圖表明了MA-PCA 并不是以一種固定不變的方式使用源模型,而是適時選擇部分可用知識進行重用。從整體結果來看,γ向量在對象類別間的語義關系中包含有意義的值。換言之,對應于目標對象的類別斑馬,相似度不同的源域所對應的權重不同,不相關類別(比如側面汽車、戰斗機、直升飛機、摩托車等)具有較低權重,而相關類別(比如,狗)則具有相對較高權重。
4.6 收斂性
本文為了解決MA-PCA的優化問題而開發了一個迭代更新規則,這個規則的收斂性已經在本文2.4節中證明,這個收斂過程采用該更新規則,在目標識別上是{A,C,D}到W的設置,在圖像標注中采用表1中的劃分4 設置,在視頻識別上采用多源的設置,該更新規則的實驗結果在圖9中顯示。
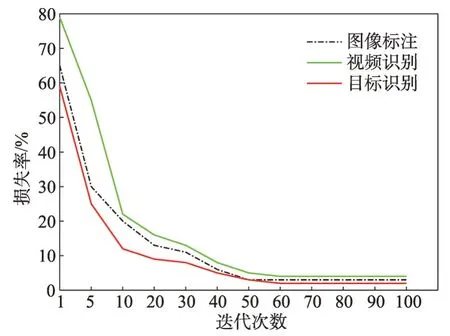
圖9 MA-PCA的收斂性Fig. 9 Convergence of MA-PCA
從圖9中可知,所提更新規則收斂速度快。該實驗也表明了在這3個數據集上進行20次以內迭代的MA-PCA收斂速度快,從而表明更新規則是有效的。
5 結束語
對于基于圖的半監督學習(GSSL)問題,解決訓練數據和測試數據必須同分布的局限以及噪聲、異常數據對分類準確性能的影響成為GSSL 成功的關鍵之一,而現有的GSSL方法僅考慮了訓練數據和測試數據同分布時的模型學習,使得其在具體應用上存在一定的局限性。對此,本文從解封訓練數據和測試數據必須同分布的新穎視角,提出一種有效的可能性聚類假設的多模型適應學習方法,即MAPCA。該方法采用了模糊熵正則項來減弱噪聲、異常數據對分類所帶來的影響,經過分析指出所提方法中采用的多模適應學習方法在訓練數據和測試數據同分布和不同分布問題上具有較好的泛化性能,從而使得所提方法在GSSL的分類問題上的分類性能得到一定程度的提高。需要進一步研究的問題:(1)如何提高多核模型的學習效率;(2)如何更高效地提升所提算法的整體運行效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
