音樂自動標注分類方法研究綜述
2023-06-07 08:29:52張如琳王海龍裴冬梅
計算機與生活 2023年6期
張如琳,王海龍,柳 林,裴冬梅
內蒙古師范大學 計算機科學技術學院,呼和浩特010022
迄今,我國同時在線音樂活躍用戶數已超7.7億,網絡用戶大量增長,音樂作品與日俱增,音樂類別日益多元化,人們對音樂信息檢索(music information retrieval,MIR)的需求達到前所未有的高度。然而,海量的音樂作品缺乏不同類別的語義標簽,導致用戶無法便捷、精準、高效地檢索音樂作品。音樂標注作為音樂信息檢索領域的重要分支,可豐富音樂信息,有效管理音樂資源,并推動音樂分類、音樂推薦以及樂器識別等其他音樂信息檢索任務的深入研究。
音樂標注是利用手工或自動的方式為音樂賦予不同類別的語義標簽,進而對音樂進行合理化分類[1]。手工標注又可分為專家型和社會型。專家型是由專業音樂人完成標注,其具有權威性且標簽質量專業性強等優勢,但存在效率低、時間及人力成本消耗量大等問題。社會型是由普通聽眾完成標注,其具備時間成本小、數據量大等優勢,但由于帶有很強的個人主觀性且音樂專業性偏低,標注易產生模糊性和隨意性,標簽質量低。音樂自動標注方式(automatic music annotation,music auto-tagging)是利用先進的計算機技術分析音樂的旋律、音色、語義并預測音樂描述性的關鍵詞或標簽[2]。該方式結合手工標注中兩種類型的優點,不僅減少了時間成本,還提高了標注準確率。通過音樂自動標注技術,人們可高效地進行相似性搜索、音樂流派分類、音樂情感分類和音樂推薦等,它是目前的主流標注方法。表1對音樂標注類型進行了總結。

表1 音樂標注類型總結Table 1 Summary of music annotation types
音樂自動標注最早可以追溯到2007年,Eck等人[3]使用傳統方法基于AdaBoost分類器對音頻特征進行標注,完成多標簽音樂自動標注,取得開創性成果,然而在標注過程中依舊面臨許多挑戰。當前業界普遍聚焦于以下兩個研究問題:(1)特征選擇與提取問題。音頻信號的特征有許多種,每個特征描述音頻信號的能力有限,因此針對特定模型需要選擇合適的特征以及合適的提取方法,以保證音頻信息的完整提取,更好地進行標注預測。(2)模型選擇問題。在傳統方法中,選擇的特征越好就意味著對模型的選擇越簡單,然而隨著人工智能的不斷進步,出現了不同的模型與方法,人們意識到更有針對性地選擇模型可影響標注性能的進一步提升。
面對音樂自動標注,Fu等人[4]圍繞任務研究進展對當時不同方法進行歸納,為后續相關工作提供幫助。然而該綜述側重于對機器學習方法進行梳理,缺乏對深度學習方法的歸類分析,并且由于同時整理了音樂流派分類、情感分類與樂器分類等不同研究方向,并未對機器學習下的音樂自動標注進行著重分析。與上述綜述不同,本文既對機器學習方法進行詳細總結與歸納,又對近年來面向深度學習的模型選擇與特征提取方法進行分析與總結。本文貢獻總結如下:首先,詳細介紹音樂自動標注的相關知識。其次,根據當前存在的研究問題,從音頻提取、機器學習模型與深度學習模型三方面進行綜述,分析對比優缺點并比較不同方法的性能。其中,對特征提取方法研究通過不同特征輸入的角度進行論述,對面向機器學習的音樂自動標注研究通過不同模型的角度進行論述,對面向深度學習的音樂自動標注研究通過不同模態的角度進行論述。然后,列舉音樂自動標注領域常用的數據集與評價指標。最后,分析目前音樂自動標注所面臨的挑戰與機遇,并指出未來的發展方向。
1 音樂自動標注相關知識
音樂自動標注為音樂預測多類別音樂標簽,被視為多標簽分類問題。與其他單標簽分類任務不同,一首音樂可同時與多個音樂標簽關聯,而其他分類任務局限于特定語義的類別標簽。例如,在圖1(a)中,音樂情感分類任務只能為音樂分配情感表述標簽;然而,圖1(b)中音樂自動標注可為音樂預測情感、流派、樂器等多個不同類別語義標簽,豐富了音樂信息。因此,當在輸入集合上定義k個二元標簽時,單標簽分類任務的輸出集合標簽僅k個,而音樂自動標注的輸出集合標簽則達到2k個。
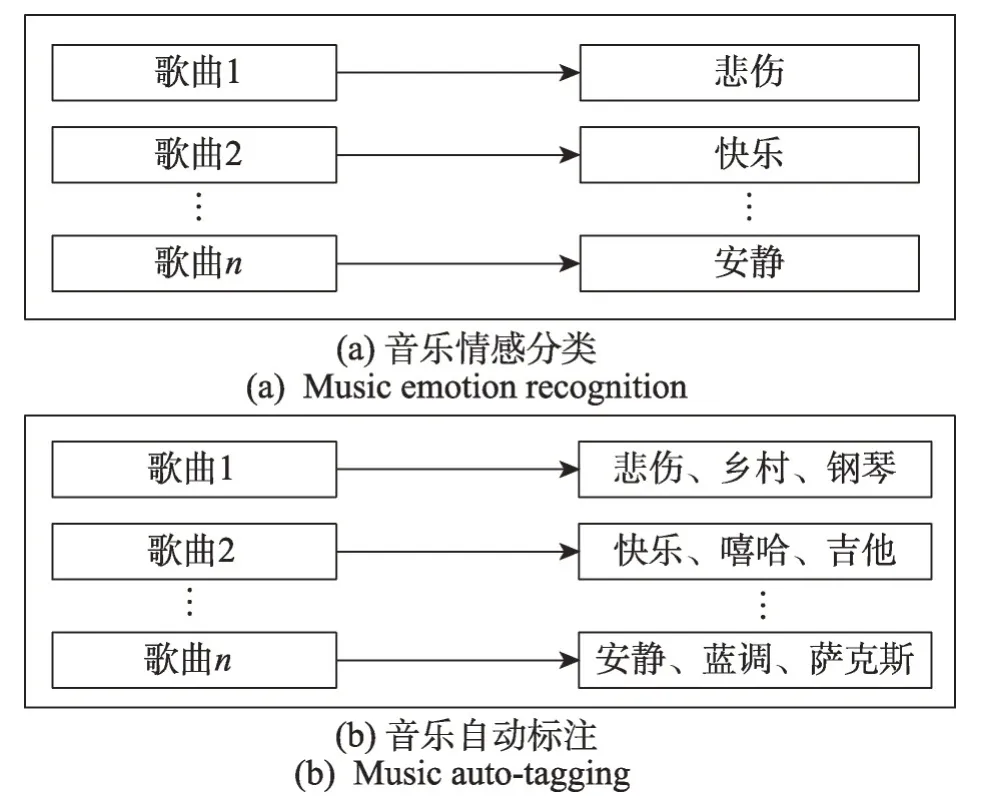
圖1 音樂信息檢索領域中單標簽分類與多標簽分類Fig. 1 Single-label classification and multi-label classification in music information retrieval
由上可知,對音樂進行標注需通過音樂標簽定義對音樂的理解與感受,因此音樂標簽是音樂自動標注的重要組成部分。音樂標簽屬于社會標簽,它能夠表達音樂特性的高層次描述性詞語。例如,描述情感的“快樂”“悲傷”等標簽,描述流派的“嘻哈”“搖滾”等標簽,描述樂器的“鋼琴”“小提琴”等標簽。音樂標簽是區分不同音樂類型最科學的表示,它具有以下特點:
(1)無界限性。聽眾受不同文化、政治和宗教等復雜因素的影響,對相同音樂有著不同評判標準,為音樂附上何種標簽并沒有嚴格的定義與界限。
(2)共享性。聽眾間共享音樂標簽資源,允許查看、添加、使用其他聽眾所標注的標簽,在主體聽眾用戶同意的情況下,可修改標簽。
(3)動態更新性。聽眾可以利用音樂平臺上傳原創歌曲或翻唱歌曲,進而使音樂數量進一步增加,平臺實時對增加的音樂進行標注并更新音樂標簽[5]。
圖2為音樂自動標注通用框架。首先,將音樂進行預處理操作,預處理是使用預加重、加窗、分幀等操作最大化呈現原始音頻的相關特征,并使后續操作更加精準。其次,通過不同方法提取音頻特征,并找到合適的數據集音樂文本標簽,將音頻特征向量與音樂標簽作為模型輸入。對于機器學習模型來說,只需將提取好的音頻特征輸入到分類器模型進行標注預測即可。對于深度學習模型來說,則分為兩種方法,一是將預處理得到的原始波形直接輸入到深度學習模型,二是將特征向量送入深度模型中自動學習音頻特征,以此來預測對應的音樂標簽。特征提取為學習模型提供大量的音頻特征數據,但會存在冗余特征,使模型無法學習到重要特征,因此對其進行降維處理。例如Nam 等人[6]使用主成分分析(principal component analysis,PCA)來消除二階依賴性并降低維度。再次,設計音樂自動標注模型算法,即學習模型,通過學習模型將音樂標簽與音頻特征建立聯系,使模型發現兩者的相關性。然后,將待測音樂輸入到訓練好的標注模型中。最后,對模型是否符合當前任務進行最終評價[7]。
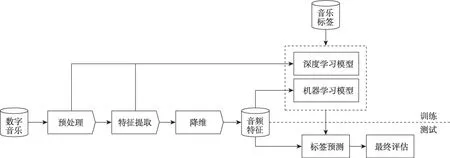
圖2 音樂自動標注通用框架Fig. 2 Generic framework for automatic music annotation
音樂自動標注問題是多標簽分類問題,形式化定義可描述為:將音樂自動標注樣本的音頻特征集合設為X={xi:i=1,2,…,m},標簽集合為Y={γj:j=1,2,…,k},給定多標簽訓練集合,設為S={(xi,Lj),i=1,2,…,q},其中xi∈X,Lj∈Y,xi與Lj為一對多的映射關系,音樂自動標注任務從訓練集S中學習到函數C:X→2Lj,設計多標簽學習模型C(·),對無標簽樣本音頻測試集合T={(xq+i,?),i=1,2,…,p}進行標注,即預測C(x)∈Y作為音頻樣本特征的標簽集合。
面對多標簽音樂自動標注問題,機器學習的核心思想是將多標簽分類任務轉換成多個單標簽分類任務。(1)二元相關性(binary relevance,BR)[8],多標簽分類任務轉換成多個單獨的二元分類學習任務。針對每個標簽均訓練分類器,使所有分類器對音頻樣本進行預測,樣本的預測標簽就是所有分類器預測標簽的集合,但該方法忽略了標簽的相關性。(2)分類器鏈(classifier chains,CC)[9]將多標簽分類任務轉換成二分類器鏈。在二元相關性的基礎上加入標簽排序,在預測當前標簽時,需考慮當前標簽的前個標簽。然而當音樂標簽與音頻樣本數量過于龐大時,會使計算效率與性能下降。在深度學習中,研究人員使用深度神經網絡模型作為多標簽分類算法,將每個輸出節點使用sigmoid 激活函數,對每個輸出節點和對應的標簽計算二值交叉熵損失函數[10]。
2 音樂自動標注音頻特征提取方法
音頻特征是區分音樂的重要依據,科學有效的音頻特征可充分表達出不同特性的音樂。因此,需合理提取不同類型的音頻特征,將它作為模型輸入進而對音樂進行準確標注。
2.1 基于領域知識輸入的特征提取方法
原始音頻是不定長的時序信號,不適合直接作為模型輸入,需轉換成專業音頻知識的特征表示。
2.1.1 基于統計特征的提取方法
統計特征是精通音樂信號的專業人士根據不同特定任務對音樂的原始波形進行傅里葉變換、倒譜分析等操作轉換成時頻表示的音頻特征。常用的音頻特征包括音色特征(梅爾頻率倒譜系數(mel-frequency cepstrum coefficients,MFCC)、頻譜質心、頻譜衰減、頻譜帶寬)、節奏特征(節拍直方圖、節拍速度)、音高特征(音高直方圖、音高等級)、和聲特征等。
單個特征無法對音樂自動標注清晰表達,研究人員將多種統計特征融合。首先將單個統計特征進行描述性分析操作,其次計算各個特征對應的統計值并將統計值拼接得到最終特征向量,最后將其輸入至分類器[11]。Wang等人[12]融合音色特征中的頻譜質心、頻譜通量、頻譜衰減以及MFCC等特征來實現音樂自動標注,同時將融合特征與單一特征MFCC進行比較,證明融合特征的性能優于單一特征,為捕捉更多特征信息進一步添加節奏特征[13]。Sordo[14]將音色特征(MFCC、頻譜質心等)、節奏特征(節拍速度、起始點等)、和弦特征進行融合,并將特征的均值、方差以及導數拼接作為整體音樂的特征向量。Ness等人[15]將MFCC、頻譜質心、頻譜通量、頻譜衰減進行融合,計算這些特征的均值和標準偏差,以此來獲取幀級音頻特征的整體表示。
基于統計特征融合的方法可有效提高音樂自動標注性能,但該方法存在一定局限性:(1)需要根據不同問題選取不同特征進行融合,消耗大量人力及時間成本。(2)對原始音樂特征做一系列融合會存在冗余信息。(3)很難全面描述音樂特點。(4)模型效果與使用不同特征進行融合的關系很大。
2.1.2 基于圖像特征的提取方法
由于統計特征融合的方法耗時耗力,需要花費大量時間在特征選擇上,研究人員嘗試自動找尋與任務相關的特征向量形式,將預處理后的波形信號通過傅里葉變換轉換成與圖像相似的時間-頻率二維聲譜圖并作為模型的輸入[16]。
梅爾頻譜圖符合大多數人非線性聽覺特征,因此梅爾頻譜圖是目前主要的輸入類型[17-18]。使用梅爾刻度濾波器組對信號進行處理可獲得梅爾頻譜圖,研究人員將其應用于實驗中進行測試[19]。Choi等人[20]使用梅爾頻譜圖與MFCC、STFT(short-time Fourier transform)特征在同一架構下進行測試,結果表明,在MTAT 數據集(MagnaTagATune Dataset)下使用梅爾頻譜圖輸入的性能值達到0.894,使用MFCC與STFT的性能值為0.862、0.846。Ferraro 等人[21]對比了不同尺寸的梅爾頻譜圖對模型的影響,證明了當減少尺寸時既可保持良好性能,又可降低訓練時間成本。Choi 等人[22]繼續對梅爾頻譜圖進行不同的對數幅度縮放、頻率加權等操作,實驗證明對數幅度壓縮可提高準確性。以上均是將梅爾頻譜圖與不同特征進行對比測試,并未有效捕捉更多音頻信息。Won等人[23]在梅爾頻譜圖前加入了諧波濾波器,使模型提取到更多音頻信息,實驗表明,加入諧波濾波器的標注模型在MTAT數據集下性能值達到0.914 1。
聲音的許多高層次特征與不同頻段的能量有關,梅爾頻譜圖更能表現音頻中時頻的效用,且效果對比其他音頻特征向量效果是最好的,然而梅爾頻譜圖也會存在周期相位變換的問題。
目前,基于圖像特征有以下三種提取方法:
(1)受限玻爾茲曼機
受限玻爾茲曼機(restricted Boltzmann machine,RBM)是一個由可視層和隱藏層組成的二分無定向圖形模型,可視層表示輸入音頻數據,隱藏層表示通過RBM 學習音頻特征。Nam 等人[24]使用了RBM 算法,將預處理后的音頻數據利用稀疏RBM 獲取音樂中豐富的局部音色特征,并且用二元評價來判斷模型優劣,當在CAL500 數據集(computer audition lab 500 dataset)下使用RBM+頻譜圖方法時,精確率為0.479,召回率為0.257,F1 值為0.289,是所有對比方法中效果最佳的。
RBM 注重訓練音頻特征本身特性,表示能力強且易于推理。雖然使用RBM的效果較好,但RBM訓練速度慢,算法很難調整,靈活性不夠強。
(2)K-均值
K-均值(K-means)算法是基于歐式距離的聚類算法,兩個音頻目標的距離越近,相似度越大。算法步驟為:首先隨機選取k個音頻特征樣本{x1,x2,…,xm},x(i)∈Rn,初始聚類質心點為u=u1,u2,…,uk∈Rn;其次計算音頻特征xi到k個聚類中心的距離,并將其分配到距離最近聚類中心所對應的標簽類中,重新計算該標簽類uj的質心;最后重復上一過程直至模型收斂。Dieleman 等人[25]與Oord 等人[26]均使用球形K-means算法學習特征,并使用多層感知器(multilayer perceptron,MLP)來標注預測。不同的是,前者將梅爾頻譜圖劃分為不同幀級大小的窗口,然后進行PCA處理,并提取K-means特征進行不同時間尺度學習,實驗證明多時間尺度比單時間尺度性能更好;而后者則使用遷移學習方法,先在MSD 數據集(million song dataset)上訓練模型并提取特征,轉移事先預訓練的MLP 權重并在其他數據集上預測標簽,實現音樂自動標注。
K-means 算法為淺層結構,相對于RBM 算法收斂速度快,聚類效果較好,然而采用迭代的方法只能得到局部最優解,且該算法需選擇最近的聚類,因此對噪音點較敏感。
以上兩種提取方法均是將音頻的局部頻譜圖映射到高維度稀疏空間中,并對特征進行統計得到音頻單層特征向量,將其輸入到模型中標注預測。它們可以處理不同長度的音頻,進一步提高模型性能,但音樂是時序變化的,在提取音頻特征時很難控制對不同變化的音頻進行標注,不能對音樂有層次化的特征向量進行學習。
(3)深度神經網絡
深度神經網絡的架構受大腦的分層結構啟發,將前幾層神經網絡充當特征提取器,無需明確的特征選擇或相關特征的計算,即特征學習。目前,研究人員利用深度神經網絡的隱藏層來表示音頻數據底層結構特征與標簽之間的映射關系。例如,Ju等人[27]使用梅爾頻譜圖作為卷積神經網絡(convolutional neural networks,CNN)輸入進行音樂自動標注學習,該方法在MTAT 數據集下的性能值達到0.918 7。深度學習音頻特征提取方法在音樂自動標注中占主導地位,僅需要將音頻信號轉化成二維輸入表示,使模型從中學習重要特征即可。該方法一定程度上避免了尋找與任務相關的音頻特征問題,提取更深層次的特征。然而這種方法的音頻數據需要具有一定的專業音樂知識,成本過高。該方法是使用深度神經網絡將特征提取與標注預測結合在同一架構下進行的。
基于知識領域的輸入是目前常用的輸入類型,它可更有效地進行表示學習,并且系統性能也隨著改進逐步提升,但領域知識輸入會消耗大量先驗知識,當為模型后端增加大量算法提升性能時,會使整體計算量急劇加大。表2 總結了基于領域知識的特征提取方法對比。
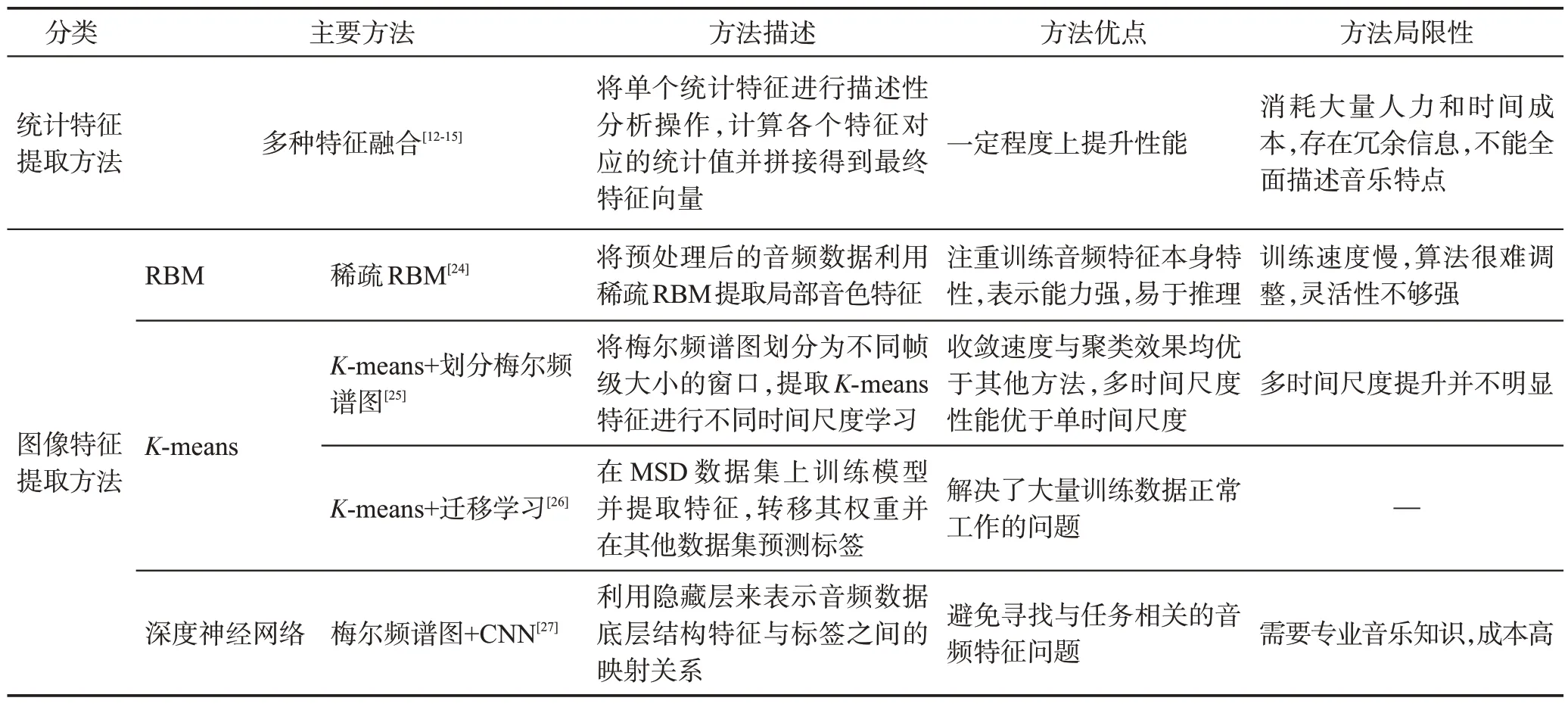
表2 基于領域知識的特征提取方法對比Table 2 Comparison of feature extraction methods based on domain knowledge
2.2 基于非領域知識特征輸入的提取方法
為進一步減少所需要的先驗知識,研究人員將原始波形信號直接輸入模型中。2014 年,Dieleman等人[28]首次使用原始波形輸入端到端對音頻進行標注預測,實驗結果顯示,原始波形的效果還有待提高,但它可避免梅爾頻譜圖存在周期相位變化問題,這也為提高原始波形的輸入性能奠定了基礎。
基于非領域知識輸入更少依賴于專業音頻知識,在音樂自動標注領域上取得了顯著成果。然而與梅爾頻譜圖輸入方法相比性能略差,原因有:(1)梅爾頻譜圖需要通過振幅壓縮方式進行提取,而人們無法在原始波形中找到合適的非線性函數代替。(2)雖然原始波形減少了先驗知識,但后續操作并未找到合適的模型繼續學習復雜的音頻結構。Lee等人[29]提出樣本級卷積神經網絡模型,將卷積神經網絡中第一層濾波器的長度和步幅減小至兩個樣本并增加深度進行標注,卷積核尺寸為1×3,通過此方法,標注性能有所提升。同時,他們更深入地研究分層學習濾波器,進行多層次、多尺度的特征聚合,對多個任務進行遷移學習與可視化[30],結合不同級別的特征進而提高性能。Pons 等人[31]根據不同數據量對原始波形輸入與梅爾頻譜圖進行比較,結果表明,當數據量有限時,梅爾頻譜圖將水平[32]與垂直[33]濾波器組合的效果更好,原始波形的效果不盡如人意;使用大量數據時,原始波形輸入可勝過梅爾頻譜圖。
研究人員對非領域知識的輸入做進一步探索,使用領域知識專注提取某種音頻特征可能會丟失部分音頻信息,使模型無法對丟失信息進行標注,進而導致標注結果不準確。Song等人[34]將原始波形轉換成散射系數,將散射變換作為循環神經網絡模型的輸入,散射變換輸入具有穩定性,可以平衡音頻信息的完整獲取與音頻特征的有效提取。他們進一步將散射變換輸入與梅爾頻譜圖和MFCC 進行比較,實驗結果表明,散射變換效果最好。該方法使用兩階散射變換。一階散射變換系數如式(1)所示:
其中,x表示信號中的一幀數據;φ(v)表示低通濾波器;表示小波模數變換,其目的是將丟失的信息從此變換中恢復;λ為小波的尺度。通過式(1)可得到長度為Λ1的向量,Λ是λ的最大值。
二階散射變換系數如式(2)所示:
通過式(2)得到長度為Λ2·Λ1的向量。零階散射變換為S0=x(v)*φ(v),該變換系數為標量,長度為1。將零階散射、一階散射與二階散射系數堆疊,得到長度為1+Λ1+Λ2·Λ1的向量,通過堆疊每幀的散射系數向量并沿對數頻率映射,構建CNN 的輸入維度Nf×(1+Λ1+Λ2·Λ1),其中Nf表示從音樂信號提取的總幀數。
非領域知識輸入將原始波形直接送入模型中,利用小濾波器的深度堆棧,分層組合上下文信息學習音頻特征,一定程度上避免了繁瑣的特征提取與梅爾頻譜圖周期波形相位變化產生的變性問題,減少了對先驗知識的需求,將所提取的音頻特征工程量降到最低,只需根據專業知識調整學習模型的超參數即可。然而當考慮更長音頻的輸入時,增加學習模型深度的方法會使計算成本變大,且更長的輸入意味著在每層都有更大的特征圖,因此GPU 內存消耗更多。表3 總結了基于非領域知識的特征提取方法對比。

表3 基于非領域知識的特征提取方法對比Table 3 Comparison of feature extraction methods based on non-domain knowledge
3 基于機器學習的音樂自動標注方法
基于機器學習的音樂自動標注是將特征提取與分類分為兩部分,分類作為音樂自動標注的主要步驟之一,選擇合適的分類器是決定性能優劣的重要因素。在機器學習中通常將分類器模型分為判別式與生成式。
3.1 判別式模型
判別式模型不需要明確學習每個樣本如何生成,僅學習不同類別之間的最優邊界即可。由于判別模型可直接判斷不同類別之間的差異,進一步提高效率,研究人員將不同判別模型應用于音樂自動標注中。首先將音頻特征與音樂標簽作為模型的輸入,其次訓練分類器模型學習音頻特征與標簽之間的映射關系,最后對待測試的音樂進行標注預測。
3.1.1 支持向量機
支持向量機(support vector machine,SVM)分類器的基本訓練原理為:首先使用SVM 核函數將音頻特征映射到高維特征空間,并找到音樂數據點的超平面以及最優線性超平面函數的參數,即確定SVM分類器。其次將測試的音頻特征輸入SVM 分類器,通過計算得到的數值來判斷音頻特征位于超平面的某一側,從而預測標簽。SVM 分類器用于解決二分類學習問題[35],而音樂自動標注為多標簽分類問題,需訓練多個SVM分類器并使用不同策略來結合其結果,以此完成音樂自動標注。常見策略為“one-againstone”與“one-against-all”。若將每個標簽看作一個類別,“one-against-one”則是選取任意兩個標簽來訓練一個SVM,構造C=k(k-1)/2 個SVM 分類器,其中k為標簽數量,然后對待測試音頻的所有預測結果做投票法組合,投票最多的標簽為最終預測標簽;“oneagainst-all”是對K個標簽訓練K個SVM,每個SVM定義一個分類函數fi用于區分該音頻片段屬于標簽i或其他標簽,待測試音頻的所屬標簽即為最大輸出的分類函數fi對應的標簽類別。最常用的分類函數公式如式(3)所示:
其中,x表示音頻特征;wi表示第i個標簽所對應的SVM的權重;bi表示第i個標簽所對應的SVM的偏置。
待測試音頻片段的標注如式(4)所示:
其中,K表示標簽個數。
為了尋找標簽之間的相關性,Ness等人[15]將堆疊泛化的方法應用到SVM分類器中并進行擴展。設詞匯表V由|W|個單詞組成,音頻片段為S=s1,s2,…,sR,音樂S中的特征向量表示為X=x1,x2,…,xT,每個向量xt代表從音頻片段中提取到的音頻特征。每首音樂的標注向量設為y=(y1,y2,…,y|V|),若wi與音頻片段相關聯,則yi>0 ;若無關聯,則yi=0,即語義權重。將語義權重映射到{0,1}范圍中,設數據集為音頻片段與標簽的集合D=(X1,Y1),(X2,Y2),…,(X|D|,Y|D|),并對待測試的數據進行標注預測。由于每個音樂片段由多個標簽標注,特征向量被多次送到多類SVM中,然后訓練SVM 并計算標簽概率輸出,將第一層SVM 的概率輸出作為第二層SVM 輸入,以此類推完成標注。相較于單獨的SVM,堆疊的SVM 性能更好。
Mandel 等人[36]結合多實例學習方法,使用實例嵌入式選擇方法(multiple-instance learning via embedded instance selection,MILES),將音頻片段作為分類的實例,標簽類別為袋。其中,Bi表示第i個袋,大小為li,袋中第j個實例為xij,j∈1…li,Bi的標簽為Yi∈{1,-1},實例xij的標簽為yij,設正袋指數集合為I+={i:Yi=1},負袋指數集合為I-={i:Yi=-1}。使所有音頻實例對袋進行映射,其次使用1-norm SVM來進行音頻特征選擇與分類,從而完成標注。
SVM 分類器是機器學習最常見的模型,其計算復雜度取決于特征向量的數目并非音頻樣本的維數,這也避免了維數災難問題。然而SVM 是二分類模型,面對音樂自動標注任務時,標簽類別存在交叉重疊部分且需對每個標簽進行二元決策,使計算效率變低,時間變慢。
3.1.2 k-近鄰
k-近鄰(knearest neighbor,kNN)模型的核心思想是:只依據最鄰近的一個或者幾個音頻樣本的標簽來決定待測試音頻特征所屬的標簽。其步驟為:預測音頻樣本特征x,首先給出距離度量方法在訓練集T中找出與音頻樣本特征x最相近的K個音頻樣本點,記為NK(x),其次根據多數投票原則,K個音頻樣本大多數對應類別y,則確定音頻特征x對應標簽y。投票如式(5)所示:
其中,i=1,2,…,N,j=1,2,…,K,I表示指數函數。
由此可見,kNN有兩個關鍵點:選取k值,計算點距離。
對于k值的選取:當k值較小時,預測結果對近鄰音頻樣本敏感,若近鄰音頻樣本點為噪音點,則預測錯誤,因此k值過小會導致模型過擬合;當k值較大時,雖模型相對具有魯棒性,但近鄰誤差偏大,距離較遠且與預測音頻樣本不相似的點同樣影響預測結果,使其偏差較大,導致模型欠擬合。因此,需通過交叉驗證的方式,選取較小的k值同時不斷增加k值并計算驗證集的方差,最終找到合適的k值。
對于距離的計算:音頻樣本空間內兩點之間的距離量度表示兩個音頻樣本點之間的相似度,距離越短,相似度越高,反之,相似度越低。目前常用歐氏距離作為距離量度方式。
Sordo[14]使用了kNN 模型,首先為待測音頻檢索一組近鄰音頻樣本,通過加權投票方式選擇音頻所對應的標簽。對于樣本的投票權重如式(6)所示:
其中,t表示標簽,n表示標簽排名。該函數為最遠的音頻樣本點提供邊際權重,因此最近的樣本點對排名較高的標簽影響較大。
kNN 為監督學習模型,音樂的標簽類別是已知的,其通過對已分類的音頻數據進行訓練學習,找到不同標簽的特征后,再對待測試的音頻數據進行分類。對比SVM 模型,kNN 模型效率更高,復雜度更低,避免每個標簽均進行訓練,更適合多標簽音樂自動標注任務,但音樂片段由成百上千個幀組成且不同標簽的幀級特征可能會彼此相似,這會限制kNN鑒別的能力且預測結果存在不均衡性。
3.1.3 條件隨機場
條件隨機場(conditional random field,CRF)模型是無向概率圖模型,為了獲取更多音頻片段信息且考慮相鄰音頻的標簽信息,將CRF 模型引入音樂自動標注任務中以更準確地表達標簽與音頻片段之間的關系。普通分類模型是將(x,y)看作一個樣本,其中x為音頻特征,y為標簽;CRF 模型為序列分類問題,將(x1,x2,…,xt,y1,y2,…,yt)整體看作一個樣本,x為音頻特征序列,y為與之對應的不同時刻或位置標簽序列。條件隨機場如式(7)所示:
其中,λK、ul表示對應權值;tk表示轉移特征函數,依賴于當前與前一個位置;sl表示狀態特征函數,依賴于當前位置;Z(x)表示歸一化因子。
局部音頻片段預測的標簽不能代表整首音樂的標簽,Wang 等人[37]將CRF 模型應用于音樂自動標注中,首先優化CRF 能量函數來計算每個片段所對應的互斥標簽集合,并不斷更新標簽直至標簽不再變化,將最后一次迭代出現次數最多的標簽作為最終標注結果。能量函數如式(8)所示:
其中,wl表示從訓練音頻數據中學習到的標簽l的回歸參數。
其中,xpwi與xqwi表示加權數;Dist()表示歐式距離;σ表示計算距離的尺度超參數;N=NS?N0,NS表示相同音樂分割的相接片段,N0表示相鄰分割的時間重疊片段。
其中,c表示控制音樂級標注與音樂片段級標注的一致性強度的權重參數;η(·)表示指示函數,滿足條件時值為1,反之為0。
CRF 模型相較其他判別模型可以通過序列化的形式對音樂進行標注,且CRF模型為無向圖,更充分地提取音樂上下時刻信息作為特征,然而該模型復雜度高,訓練時收斂速度較慢。
對于音樂自動標注任務來看,判別模型實際上是將多標簽問題轉化成二分類問題,即對N個標簽進行N次分類,其最大優勢是可以直接學習音頻之間的差異進行標注預測,相較于生成模型,靈活性較高。但也存在缺點:(1)音樂自動標注標簽類別多,在各學習模型上存在不均等表示,有時會產生數據不平衡的問題,導致模型性能下降。(2)音樂自動標注需采用一對多的方法對每首音樂進行多種標簽類別標注,然而對每個標簽進行二元決策會使效率下降,并且導致標簽之間相互獨立并不能互相關聯。
3.2 生成式模型
生成模型的特點是學習數據本身特性從而做出分類。在音樂自動標注中,生成模型將音頻特征作為特定概率下的樣本,學習音頻特征與標簽的聯合概率分布。
3.2.1 高斯混合模型
高斯混合模型(Gaussian mixture model,GMM)是一種聚類算法,由K個子高斯模型混合而成,高斯模型使用高斯概率密度函數(正態分布曲線)精確地量化事物,將一個事物分解為若干高斯概率密度函數形成的模型。音樂可被多種類別標簽定義,其音頻數據的分布并非單一橢圓形狀,單個高斯模型無法很好地描述多標簽分布,因此將高斯混合模型應用于音樂自動標注中,以此量化該分布。GMM模型核心思想是將音頻特征數據看作從各子高斯概率密度函數中生成,首先計算所有音頻特征對各個子模型的高斯概率密度函數;其次根據各子模型的高斯概率密度函數計算各子模型參數并不斷迭代更新直至最優;最后將音頻特征xi按照GMM模型聚類劃分到子模型概率最大的簇中。GMM 的概率分布如式(13)所示:
其中,γik表示第i個音頻特征為第k個子模型的概率。
Turnbull等人[38]采用數據集標簽在音頻特征空間上訓練GMM 模型,采用學習好的模型直接預測標注,并將EM算法作為參數估計。音頻特征的標簽中每個標簽的后驗概率如式(15)所示:
其中,X={x1,x2,…,xT}表示音頻片段s中的特征向量袋;P(i)=1/|V|,i=1,2,…,|V|,表示詞匯wi被標注的先驗概率,每個詞匯wi看作一個標簽,wi∈V;P(X)表示音頻的先驗概率;P(X|i)表示音頻特征空間中每個標簽wi的概率分布。
然而該方法并沒有考慮詞語之間的潛在關系,Chen等人[39]使用類似方法并針對每個詞語的反義詞也學習了GMM,從而更進一步找到每個標簽之間的相關性。反義詞集如式(16)所示:
其中,Y表示標注權重矩陣,根據標注權重Y對GMM 進行建模;Y(i)與Y(j)是在wi與wj的相關音頻片段中收集到的標注權重構成的標注向量;corr(·)表示相關系數函數,若1-Y(i)與Y(j)之間相似度大于θ1,則wj屬于wi的反義詞集。定義維數為|V|×|V|的詞-反義權重矩陣,以此構建反義詞級GMM。詞-反義權重矩陣如式(17)所示:
相較于第2.1.2 小節中K-means 算法,二者均為聚類算法且均需迭代執行,然而二者需計算的參數不同,K-means 需計算質心,即直接給出音頻特征屬于哪個標簽;而GMM則是計算各子模型的高斯分布參數,即給出每一個音頻特征由哪個子模型生成的概率。音樂自動標注的標簽分布不平衡,對于GMM模型來說,可生成不同大小的形狀簇,且少量參數就能較好地描述音頻特性。然而GMM 模型每一步迭代的計算量較大,收斂較慢且子模型標簽數量難以預先選擇。
3.2.2 狄利克雷混合模型
狄利克雷混合模型(Dirichlet mixture model,DMM)也是一種聚類算法,即狄利克雷分布混合模型。文獻[39]全面考慮了缺失反義詞標簽的問題,但沒有對每個標簽整體性進行關聯。Miotto 等人[40]提出使用DMM 模型標注音樂的新方法,基于不同的模型(GMM、SVM 等)生成標簽權重,即語義多項分布(semantic multinomial distribution,SMN),再使用DMM 對每個標簽的SMN 進行建模。DMM 模型可以進一步根據SMN中共同出現標簽的可能性調整每個標簽的SMN 權重,從而提高模型性能,結果表明DMM與GMM相結合效果最好。SMN的DMM概率分布如式(18)所示:
其中,Γ(·)表示伽馬函數。
DMM模型是建模過程中的第二個附加階段,通過對標簽之間的上下文關系進行建模來提升音樂自動標注性能。對比GMM,在標注過程中,GMM模型僅僅是在對單獨標簽進行獨立建模,而DMM可以通過利用上下文相關信息來更加細化第一階段的標注,并且DMM模型將在給定由其他共現標簽提供上下文信息的情況下調整(減少或提高)每個標簽的權重,進一步增強后驗概率估計,提高標注準確率。
生成模型下的音樂自動標注可以更好地學習每個標簽與音頻之間的相關性,與判別模型相比,生成模型只訓練與語義標簽相關的正樣本使模型直接對音頻分類,進而標注預測,而判別模型還需訓練負樣本來區分音頻類別,增加了時間成本。然而生成模型也存在缺點:(1)每個標簽都需轉化成獨立的語義模型進行訓練,當標簽存在多種類別時會使訓練過程復雜,靈活性較差。(2)不同標簽之間有關聯時,可能會丟失上下文音頻信息。(3)數據集較大時,生成模型的標注性能劣于判別模型。Wang等人[41]結合生成模型和判別模型的優點,將生成RBM與判別RBM相結合組成混合判別玻爾茲曼機(hybrid discriminative restricted Boltzmann machines,HDRBM)進行訓練,從原始音頻中提取音色與旋律特征,加入Dropout正則化方法防止過擬合,對比SVM與MLP,正則化的HDRBM在MTAT數據集上的性能分別提高了2.9%、3.3%。
雖然機器學習方法目前取得了成功,但仍有一定的局限性:(1)音樂具有連續的非線性特點且音樂語義信息也極為復雜、抽象,而分類器是淺層結構,并沒有豐富的非線性變換,同時淺層結構很難提取到復雜的語義信息,因此通過分類器來提高模型性能有一定阻礙。(2)對于分類器的濾波器選取、參數調整等問題,有時需要人工調整,這會消耗大量的時間成本且性能不穩定。(3)音樂以分鐘來計算,而短時信號的時間間隔過短不能包含整首音樂。同時,單獨音頻片段的標簽不能代表整首音樂,需長時間訓練才能發現深層次信息。表4 總結了基于機器學習的不同模型方法對比。表5 給出了基于機器學習模型的不同方法性能對比。
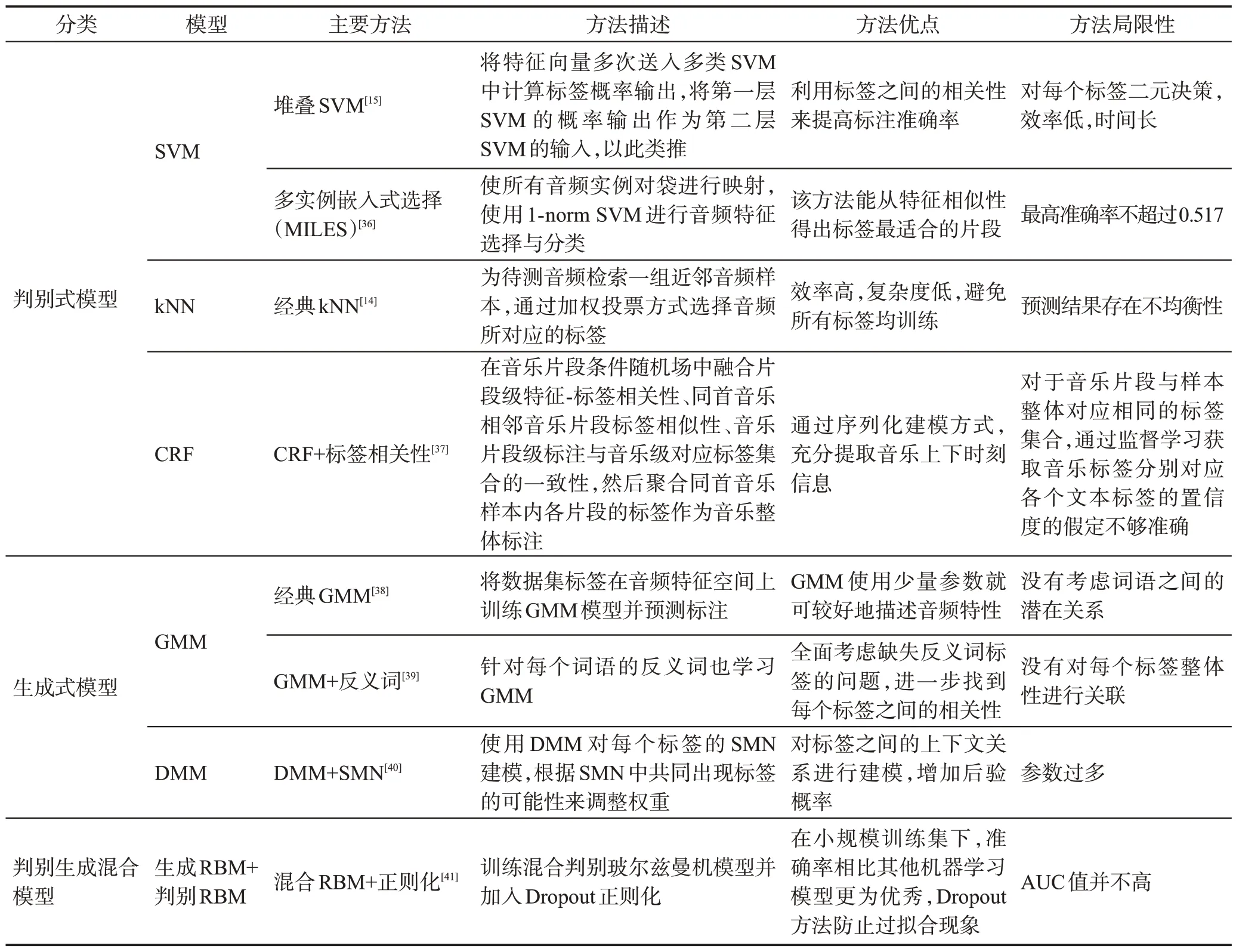
表4 基于機器學習的不同模型方法對比Table 4 Comparison of different model methods based on machine learning
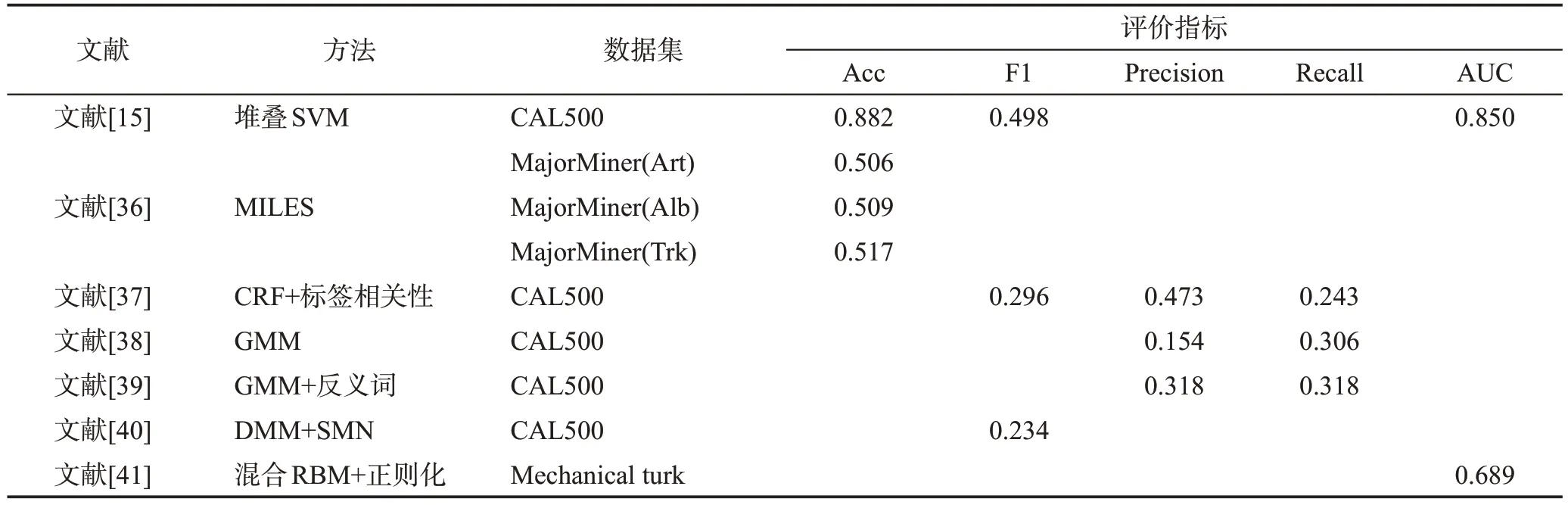
表5 基于機器學習模型的不同方法性能對比Table 5 Performance comparison of different methods based on machine learning models
4 基于深度學習的音樂自動標注方法
隨著深度學習的逐步發展,如今不同的神經網絡已成功應用于自然語言處理[42]與計算機視覺[43]等領域,研究人員使用卷積神經網絡、循環神經網絡等不同網絡提高相關任務性能,并逐漸將其應用于音樂自動標注任務。
音樂數據信息通常以多種模態存在,下面對不同模態下的音樂自動標注研究成果與特點進行梳理和分析。音頻信號是音樂主要組成部分,目前大部分工作是在音頻模態下進行,文章重點圍繞面向音頻模態的音樂自動標注進行深入探討。
4.1 面向音頻模態的音樂自動標注
4.1.1 卷積神經網絡方法
卷積神經網絡(CNN)模型可以分層學習特征且在時間和空間上具有平移不變性,在音樂自動標注中,可利用CNN 不變性來克服音頻信號本身的多樣性。大多數音樂自動標注使用CNN或其變體對音樂進行標注預測。CNN 主要由輸入層、卷積層、池化層、全連接層和輸出層所構成,其中卷積層、池化層與全連接層統稱為隱藏層。通常將音頻信號的原始特征(梅爾頻譜圖、原始波形等)作為CNN輸入,通過CNN隱藏層表示音頻原始特征與標簽之間的映射關系。其中,卷積層與池化層可學習到深層次且合適的特征向量,全連接層用于預測音頻所標注的置信度,采用ReLU作為除輸出層之外每層卷積的激活函數,并使用sigmoid函數將輸入壓縮在[0,1]之間,在每次卷積之后與激活之前添加批歸一化,并在每個池化層之后添加Dropout。
使用CNN模型一定程度上避免尋找與任務相關的音頻特征問題。Dieleman 等人[28]將經典1D-CNN模型應用于音樂自動標注。為了使特征與相關任務更好地關聯,Choi等人[20]提出了一種基于深度全卷積網絡模型(fully convolutional networks,FCN)。FCN模型僅由卷積層與子采樣組成,卷積核大小尺寸為3×3,沒有任何全連接層,通過共享權值來減少參數數量,更大程度發揮CNN的優勢,該方法的性能值超過1D-CNN模型的0.012。FCN不僅最大化卷積網絡優勢且系統不易過擬合,雖可以減少參數數量,但它將全連接網絡變成卷積層的操作使音頻空間缺乏一致性,進而導致模型不能精細地對音樂進行標注預測。Tang[44]為了保留音樂中的空間特征,將膠囊網絡應用于音樂自動標注,相較CNN方法,膠囊網絡可以通過協議路由機制提取空間特征來進行更全面化預測。
目前,基于CNN 模型的音樂自動標注主要對以下方面進行研究與探索:
(1)提高模型性能與計算效率。音樂自動標注任務最根本的目標是提高模型性能,而一些模型會存在效率低、計算量大等問題,高效率地提高系統性能也是目前所攻克的問題。Kim等人[45]在文獻[29]的基礎上對樣本級CNN 模型堆疊ResNet 和SENet,以此來進行多級特征聚合,對比原始樣本級CNN模型,該方法在MTAT 數據集上標注性能提高到0.911 3。堆疊多層的樣本級CNN 模型可提高系統性能,但模型的層數太深使計算量過大。Yu等人[46]將WaveNet[47]塊與SENet塊的分層卷積層相結合,改進后的模型不僅可以擴大感受野,還可以提高計算效率,訓練時間更少,模型也獲得更多層次的特征向量。
(2)獲取更多特征信息。音樂自動標注需要對整首音樂預測標簽,僅通過對幾秒鐘的音樂片段附上標簽顯然不具有整體性。針對此問題,Lee等人[48]使用不同大小的CNN 捕獲局部音頻特征,并從每一層卷積層中提取音頻特征,將它們聚合為長音頻,實驗證明這種方法在多層級、多尺度的音樂自動標注上是有效的。Liu等人[49]使用FCN模型架構,在輸出層前添加累積層,累積層是通過添加高斯濾波器實現的,其作用是隨著時間的推移總結前一層所做的預測,更有效地捕獲整體音樂的上下文信息。
(3)解決標簽噪音問題。音樂標簽在音樂自動標注中的作用越來越重要,而在多標簽音樂數據集中存在噪音問題。Choi 等人[50]對噪音的產生做深入研究,在MSD數據集上對標簽噪音進行分析。首先,通過標簽共現方法發現,只有39%的“獨立搖滾”標簽被同時標注為“搖滾”標簽,其余標簽則會因缺少標注信息被標注為“非搖滾”標簽,因此缺少標簽是造成噪聲的原因之一;其次,對該數據集中子集(正確標注)的標簽進行噪聲統計與精確率、召回率計算,實驗表明標簽噪聲主要分布在負標簽上,且不同標簽的噪聲差異與標注能力有關,標注能力越低的標簽在數據集中存在更多錯誤的負標注;最后,使用不同網絡結構對不同類別的不同標簽測試,證明了標簽噪聲會對網絡訓練產生不良影響。由上可知,標簽分類體系異構、不同主觀性標注使信息不足等情況會導致標簽缺失、標注較差等問題,進而使標簽產生噪聲。并且由用戶標注的部分數據集標簽會出現標簽標錯、某類別標簽過度使用、樣本標簽不平衡等問題,使其產生弱標注,同樣會導致標簽產生噪音。Wang等人[51]提出標簽深度分析法,通過卷積操作與表示學習方法來降低噪聲數據,以此挖掘標簽和音樂之間更深層的關系。Lu 等人[52]提出了雙教師-學生模型,第一個教師模型過濾掉明顯標簽噪聲,第二個教師模型防止學生模型在其余數據上過度擬合標簽噪聲。該方法提高了標簽準確性與泛化能力,并且兩個教師模型監督一個學生模型的方法最大程度上保護學生模型不受標簽噪聲的影響。損失函數如式(20)所示:
其中,Lmask表示平衡掩蔽方法,其目的是防止模型被負樣本主導,緩解數據平衡的問題;Lcon表示教師模型所提供的一致監督性;β(T)表示隨迭代次數T變化以平衡噪聲數據和一致性約束之間的權重。Lmask、Lcon、β(T)分別如式(22)、(23)、(24)所示:
其中,βmax是β(T)的上限;T0表示加速迭代次數;γ表示控制加速曲線斜率。
以上方法均是對網絡模型進行改進,在解決噪音的同時提高音樂自動標注系統的性能,然而這些方法的系統性能均取決于訓練數據的質量,且在測試時也僅將“用戶最常使用的”前50 個標簽作為參考,這會使一些冷門標簽得不到使用,導致標簽出現長尾形狀。為了使每首音樂與更多潛在相關的標簽關聯起來,提高標簽利用率,Lin 等人[53]在樣本級CNN 模型上構建標簽傳播方法,標簽傳播可為音頻生成相關標簽并移除不正確標簽,繼而減少噪聲標簽的影響。首先利用播放列表這一音樂背景在相鄰歌曲之間共享標簽,并通過多任務目標函數優化自動標注模型,該方法將之前經常使用的前50 個標簽擴展到1 000個標簽。給定輸入音樂s和被選擇的播放列表,被選擇音樂s′的概率如式(25)所示:
其中,d(s′,s)代表輸入音樂s與被選擇音樂s′之間的距離;r表示概率搜索范圍,即控制播放列表p~ 中下一個相鄰音樂被訪問的概率,r=0 即傳播更多附近音樂標簽,反之亦然。
損失函數如式(26)所示:
其中,第一個求和項表示原始二值交叉熵;第二個求和項表示支持二值交叉熵;P(s′|s)表示支持目標函數,如式(27)所示:
然而該方法會部分存在錯誤標注標簽,導致音頻與標簽之間存在弱連接問題,同義詞標簽分配給不同對象,進而使標簽在數據集中鏈接到不同音頻,導致相關標簽與音頻之前的鏈接丟失問題,這些問題均會使標簽產生噪聲。Lin等人[54]在樣本級CNN、FCN與CRNN三種模型上利用所有的音樂背景來確定相似歌曲,進一步擴大標簽傳播范圍,并將成本敏感值γ與速率α納入損失函數中,使損失函數歸于無關(負)鏈接并通過調整相關(正)鏈接對無關(負)鏈接的權重來增強魯棒性,繼而減少標簽缺失。損失函數如式(28)所示:
其中,ys∈{0,1}|T|,若對應標簽與音樂s相關則為1,反之為0,ys[t]=1(0),則音樂s與標簽t相關聯的y~s[t]相關性增加(減少);α∈[0,1]表示傳播速率;γ∈[0,2]表示正鏈接的敏感值,2-γ表示負鏈接的敏感值;P(s′|s)表示給出音樂s,其他音樂選為s~ 的概率,如式(29)所示:
其中,U為上下文信息元素集合;Us是U的子集,只包含與s連接的元素;Su是鏈接到u的一組音樂;Us~是鏈接到s~ 的一組上下文元素。
為驗證在不同影響下的標注性能,研究人員對不同模型進行對比實驗。Won 等人[55]針對音樂自動標注中不同模型的軟件版本與數據集不同的問題,進行了有關時間拉伸、音調偏移等泛化能力的實驗,實驗表明諧波CNN[56]在所有方面都表現出了最好的性能與泛化能力。通過以上討論與分析可知CNN可以解決不同問題,面對提高模型性能與獲取更多特征信息問題,需通過堆疊濾波器深度或增加不同濾波器來擴大感受野,進而可提取更多復雜特征,然而這些方式雖在一定程度上提升性能,但會使層級太深,需要的硬件設施需更強大,并且提升效果并不明顯。面對噪音問題,則主要有兩種解決思路:(1)調整模型架構,該方法需調整模型參數或增加功能性模塊來提高模型的魯棒性,然而該方法僅是通過網絡模型過濾掉噪音標簽,對于標簽的弱標注問題并未得到根本性解決。(2)改善標簽弱標注問題,該方法在原有模型架構的基礎上對標簽的標錯、標少等問題進行處理或增加標簽的使用率來進一步提高標注正確性,進而解決由弱標注產生的噪音問題,然而當所有標簽均與上下文進行關聯時會導致標注性能下降,因此還需進一步改進。CNN 通過最大池化增加整體感受野的大小,以此來捕獲局部和全局特征,它需要學習的參數比其他網絡架構要少很多,且可降低模型復雜度,增強音樂自動標注泛化能力,避免手工提取特征帶來的誤差,提升系統的標注性能。但CNN 在特征提取過程中會損失結構信息且CNN實際感受野遠小于理論感受野。另外音樂是序列數據的形式,一些聲學特性標簽局部出現就可感受到(例如樂器類別標簽),而一些其他特性則需長序列感受(例如情緒、流派類別標簽),CNN更善于挖掘語義中的深層次特征,在捕獲長距離特征方面性能較弱,并且CNN 模型設計成本較高。表6 總結了基于CNN模型的不同方法。
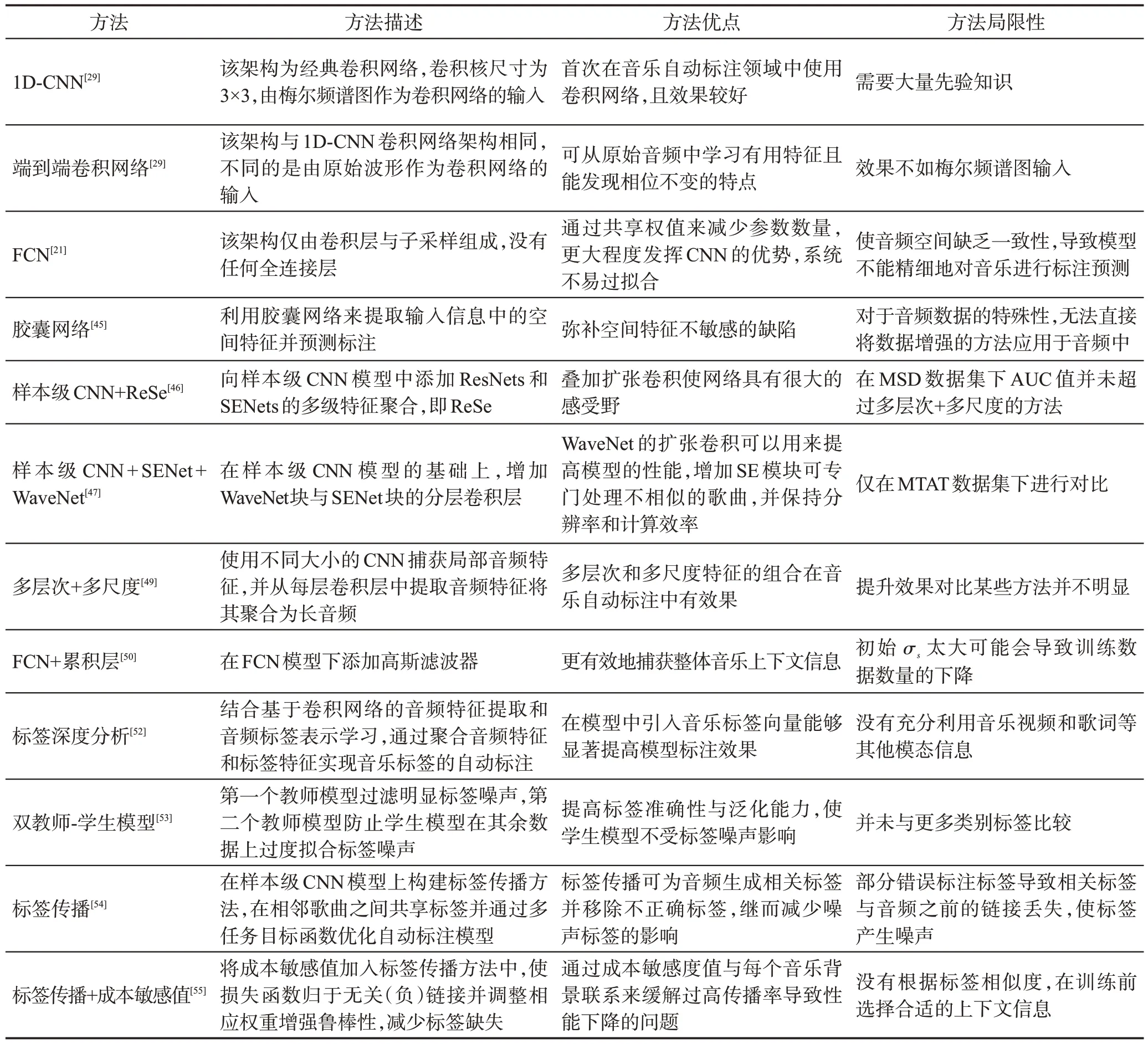
表6 基于CNN模型的不同方法對比Table 6 Comparison of different methods under CNN-based model
4.1.2 序列建模方法
音樂具有關聯性與連續性等特點,需對音頻數據進行序列化處理,循環神經網絡(recurrent neuralnetwork,RNN)將隱藏層之間的節點連接,保證前一時刻的信息可以傳遞到下一時刻,避免信息丟失[57-58],從而更好地處理時間序列數據。Choi等人[59]將RNN應用于音樂自動標注,使FCN 與RNN 相結合,得到CRNN。為了獲取全局特征,將RNN 替換最后一層CNN卷積層進行特征聚合,剩余的CNN提取局部特征,對比FCN,該模型系統性能值提升至0.862。雖然CRNN的性能有所提升,但對于長時間的序列建模問題,需要CNN堆疊較深的卷積層,這使時間分辨率下降,且長序列RNN存在計算量大、梯度消失或爆炸等問題。RNN 的許多衍生模型,例如長短期記憶網絡(long short-term memory,LSTM)、門控循環單元(gated recurrent unit,GRU)可以避免這些問題。Song等人[60]使用五層GRU,并將自注意力機制添加到最后一層CNN 中提高音樂自動標注性能。GRU 作為RNN 的變體,解決了RNN 中梯度消失及爆炸的問題并減少參數,更好地處理時間序列。Wang 等人[61-62]將GRU與CNN 融合,首先將原始波形與梅爾頻譜圖作為模型的輸入,以此對音樂進行表示學習,其次使用Bi-LSTM提取兩種輸入之間的時序相關性,最后使用注意力機制聚合音樂片段特征向量來預測音樂標簽。上述模型均將注意力機制與RNN及衍生模型結合來捕獲更多特征信息,注意力機制參數少,復雜度低,可以捕獲長時間特征且關注長特征中的特定部分[63],將二者結合可進一步提高標注性能,但RNN 及衍生模型存在序列依賴的問題,訓練速度受到限制,并行計算能力不強。為此,Won等人[64]提出了Transformer模型架構,利用半監督方法通過訓練學生模型來提高標注性能,當增加知識擴展與知識蒸餾方法時可進一步增強模型性能,使用知識蒸餾的性能值在MSD數據集上高達0.921 7,優于之前模型。Zhao等人[65]使用Transformer 的衍生模型Swin-Transformer,利用自監督方法進行預測標注,Swin-Transformer 可在分層分割的頻譜圖中提取多分辨率的時頻特征,提取更多有意義特征。Transformer 模型架構對比RNN及衍生模型,訓練時間更少,可以在整體上處理音頻片段而非依賴之前音頻信息,不存在丟失音頻特征信息的問題;對比CNN模型方法,Transformer模型能夠利用自注意力捕獲長距離依賴關系,長距離特性使模型捕獲全局信息的能力更強,此外Transformer 模型中的多頭注意力和位置嵌入等功能均可提供不同音頻之間的信息。然而Transformer模型雖然能夠捕獲更加豐富的全局上下文信息,但是不能有效應對音樂的實時變化,且訓練需要大量的時間成本,不能滿足實時性需求。
使用序列建模方法從更符合音頻知識的角度學習音樂序列特性,對音樂自動標注進行改進。但由于音樂具有時序性,音樂會隨著時間的變換而變化,細粒度的標注很難獲取。表7 總結了基于序列建模的不同方法對比。
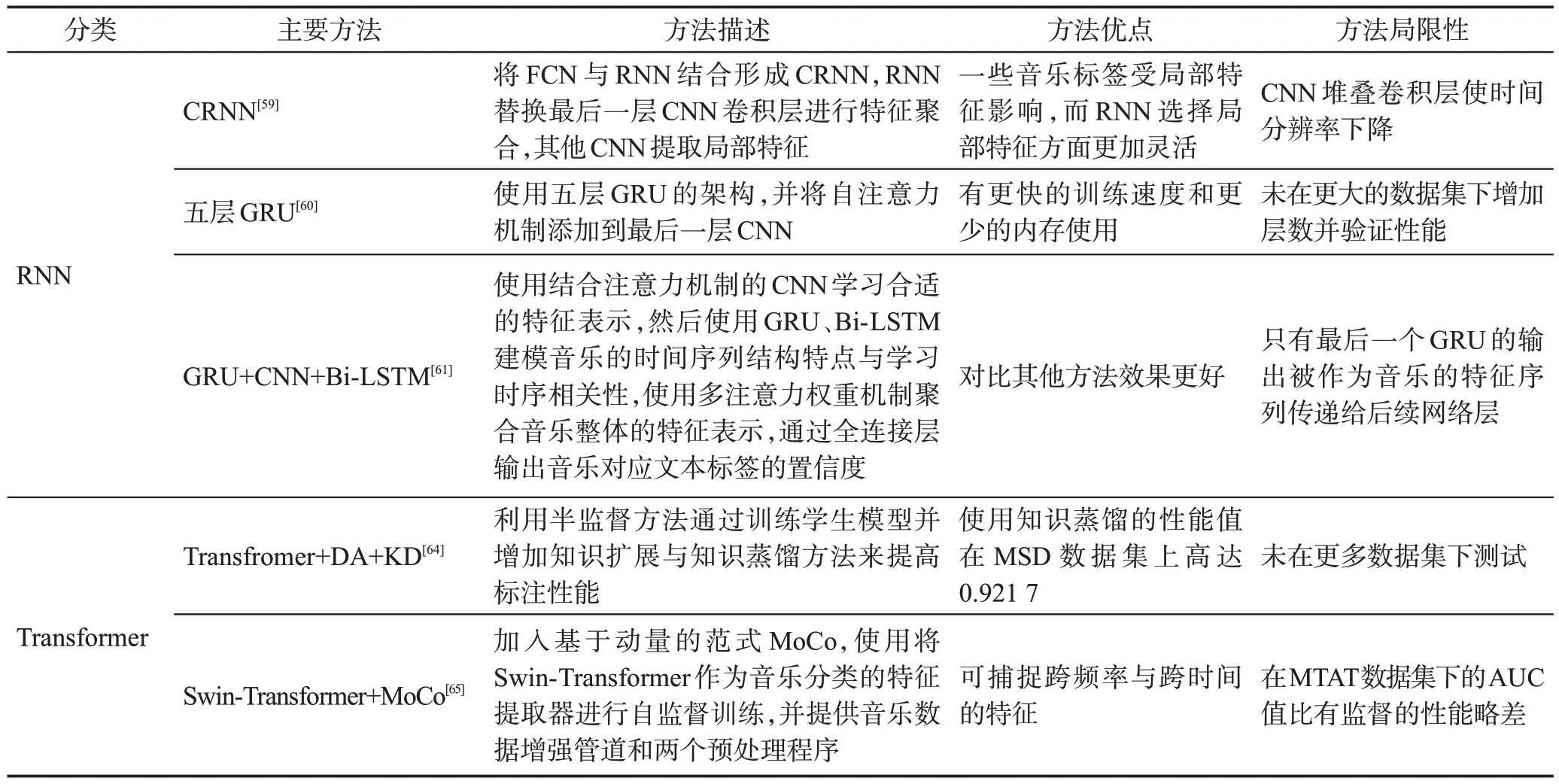
表7 基于序列建模的不同方法對比Table 7 Comparison of different methods under sequence-based modeling
面向音頻模態的音樂自動標注是目前人們解決問題最常使用的方法,但音樂的多樣性僅通過音頻提取數據信息仍不夠全面。表8 給出了基于深度學習的不同方法性能對比。
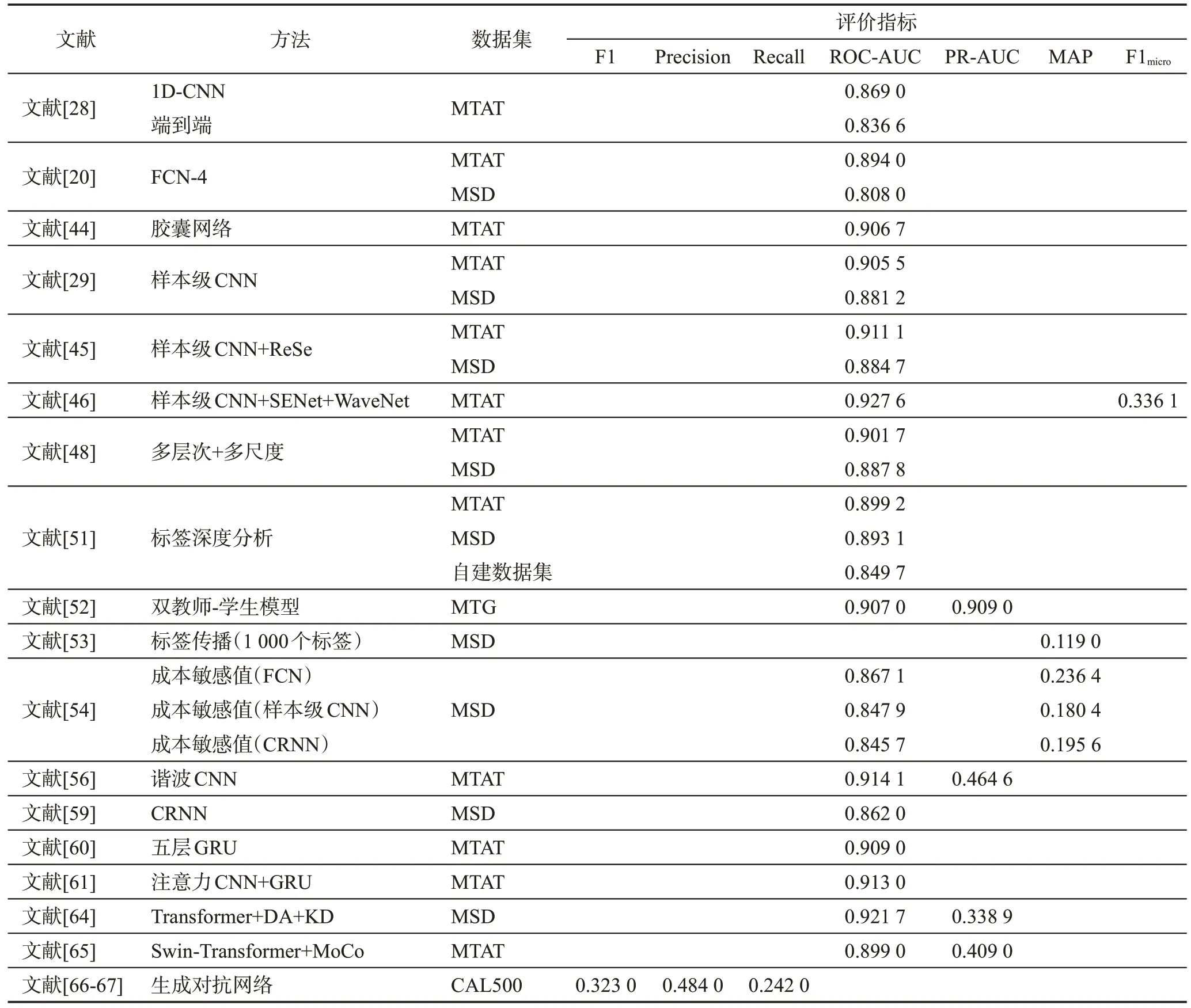
表8 基于深度學習的不同方法性能對比Table 8 Performance comparison of different methods based on deep learning
4.2 面向多模態的音樂自動標注
音頻模態下的音樂自動標注只能提取聲音的信息特征,而對于音樂來說,歌詞的文本信息與音樂視頻的圖像信息也是關鍵特征之一,為了提取更全面的特征,研究人員使用音頻與文本結合的方式對音樂進行多模態標注。Yang[68]在音頻模態下使用CNN模型完成流派與樂器類別的標注并提出不同的卷積方式,其中卷積方式K4是將局部橫向卷積核滑動,其覆蓋區域包含一個頻率和多個時間幀,實驗證明K4卷積方式的性能最佳。在歌詞文本處理方面使用了ALBERT 得到歌詞向量表示,再通過注意力機制和TextCNN 獲得全局信息,通過標簽詞典獲得局部特征,進而對情感進行標簽標注。該方法在文本與音頻模態均進行了標注,但并沒有將兩種模態做到真正的融合。Han[69]在音頻模態中將CNN 與LSTM 相結合形成混合網絡結構,在文本方面使用CBOW(continuous bag of words)模型對語料庫進行無監督訓練,構建詞嵌入字典,查找對應詞向量,并按照歌詞內容對詞向量進行順序拼接作為神經網絡的輸入,最后為防止兩種模態在融合時出現冗余相差較大等問題,對輸入音頻特征加入規范化操作。結果表明,多模態音樂自動標注的性能值達到0.815 6,比音頻模態的性能提升了0.022,比文本模態提升了0.102 8。Wang 等人[70]在音頻模態下使用CRNN 模型,文本模態使用卷積循環注意分層注意循環神經網絡(convolutional recurrent attention hierarchical attention recurrent neural network,CRAHARNN),利用早期融合與晚期融合兩種方法將歌詞特征與音頻提取特征相融合。早期融合是將不同的數據特征組合輸入到同一個模型,晚期融合是用不同來源的數據訓練各自的預測模型,再利用融合函數對預測值進行融合,最后采取多任務學習方法來學習標簽之間的相關性。實驗證明,該方法比僅使用音頻數據的單任務學習性能更好,且早期融合方法性能略優于晚期融合。
以上方法表明,音頻與文本模態相結合的多模態是通過文本模態對標簽進行處理或者對情感語義詞進行挖掘,音頻模態主要對音樂標注流派、樂器等類別標簽,且需通過整段音頻進行標注確認。多模態獲取到的特征比單模態更全面,但當兩種模態相結合時,音頻信息的冗余度、數據量與淺層特征向量維度比文本信息大,學習模型會著重學習音頻特征導致文本信息丟失,進而使模型成本較大,仍有很大的提升空間。而在電影或音頻視頻中可以通過視覺場景來描繪潛在的音樂情感,因此Avramidis等人[71]將音頻與圖像模態結合,提出VCMR(video-conditioned music representations)模型,使用自我監督的多模態框架在音樂音頻上進行訓練,并以官方視頻發布中的伴隨視覺背景為條件,利用音樂視頻的上下文信息來增強音頻音樂表征。表9 總結了多模態下不同方法對比,表10給出了多模態中不同方法性能對比。
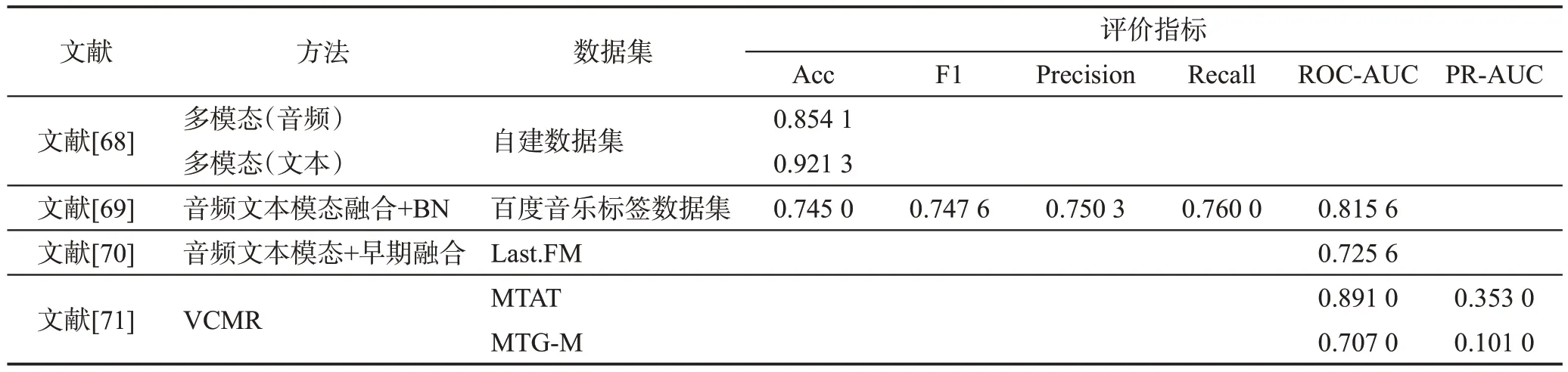
表10 多模態下不同方法性能對比Table 10 Performance comparison of different methods under multimodal
深度學習下的音樂自動標注方法與之前的模型相比,具有非線性的特點,且基于深度學習模型提取到的音頻特征泛化能力很強,目前大多數研究均基于深度學習模型展開。然而,深度學習模型也存在局限性:(1)模型對硬件設施的依賴性較大,硬件成本較高。(2)無法跳出傳統的深度神經網絡模型,很難設計性能高、泛化能力高的模型框架。(3)對模型結構的調參以及如何使模型收斂缺乏理論指導依據。基于此,大部分研究集中于對模型結構的改進。
根據上述音樂自動標注性能可以看出,最好的系統AUC 值為0.92 左右,且每一次的上升幅度并不明顯,對比音樂流派分類的分類準確率目前已高達0.967[72],其主觀原因有:(1)評價指標不同。準確率是音樂流派分類的主要評價指標,而AUC 值是目前音樂自動標注的主要評價指標。不同評價指標對模型的評判標準不一樣,且準確率雖可作為音樂自動標注的評價標準,但音樂自動標注的數據集樣本存在不平衡問題,當某一類樣本數量明顯過大時,其類別會成為影響準確率的最主要因素。(2)數據集不同。大多數音樂流派分類使用GTZAN 數據集[73],而音樂自動標注大多在MTAT數據集下進行。GTZAN數據集標簽均衡且僅有10 個流派類別標簽,每類流派標簽均有100首音樂作品,MTAT數據集有上萬條音頻數據且標簽分配不均勻,因此當數據量不同時,計算量與效率也不同。
其宏觀原因可能有:(1)起步晚。音樂自動標注的第一次出現是2007 年,而流派分類早在2002 年就已出現,音樂自動標注的前期研究較少。(2)類別多。音樂自動標注是多標簽分類任務,會出現計算量大、類別標簽互相依賴等問題,導致系統性能提升不夠明顯。(3)針對性弱。由于音樂自動標注需要為多種類別進行分類,會出現效率低、輸出空間爆炸增長等問題,因此當完成自動標注任務時,不會僅針對性能方面進行改進,需更全面地考慮可能發生的情況。雖然音樂自動標注系統性能提升效果不夠明顯,但發展前景與實際應用價值高,并且逐步提升的系統性能也為此帶來了很大動力。
5 音樂自動標注常用公開數據集與評價指標
5.1 音樂自動標注常用公開數據集
音樂自動標注數據集包含大量音頻片段與多種類別標簽,是進行音樂自動標注的數據基礎。
(1)MTAT數據集
MTAT 數據集是音樂自動標注領域最常使用的公開數據集[74]。該數據集共有25 863條音頻數據,每條數據大約29.1 s,均以MP3 格式發布,比特率為32 Kbit/s,采樣率為16 kHz,音樂標簽共188個,其中包括流派、情感、樂器、年代等標簽。數據集被分為16 個文件夾,前12 個文件夾為訓練集,第13 個文件夾為驗證集,剩余3 個文件夾為測試集[75]。它通過Tag A Tune闖關游戲向玩家收集音樂標簽,只有兩名玩家同時給出相同的音樂標簽,游戲才能通關。游戲設計者通過該游戲收集到大量音樂標簽并整理成MTAT數據集,該方法收集到的標簽也提高了標注準確性。
(2)MSD數據集
MSD 數據集是目前世界上最大的音樂數據集,也是目前音樂自動標注常用數據集之一[76]。該數據集是世界各個音樂社區音樂數據集的集合體,包括SecondHandSongs 數據集、musiXmatch 數據集、Last.fm 數據集、tagtraum 流派標注數據集等,它提供了免費的音頻和元數據。該數據集共有100萬條數據,共占用了280 GB 的存儲空間,其中每條數據約1 MB,均以MP3 格式發布,比特率約64~128 Kbit/s,采樣率約22 kHz或44 kHz。音樂標簽包括流派、年代、藝術家、專輯封面、歌曲名稱、歌詞、用戶聽歌歷史等標簽。
(3)CAL500數據集
CAL500數據集由Turnbull等人于2008年創建[77]。由于其他數據集是聽眾用戶標注,用戶的音樂專業性不強,出現了標注錯誤、很少情況考慮為音樂標注負相關標簽等問題,這些問題使數據集產生“弱標注”,導致數據集中標簽-音頻矩陣的0值代表“未知”而非“不適用”,而學習模型會將“未知”標簽認為是“不適用”的負相關標簽從而產生噪音。而CAL500數據集收錄了由500 名西方藝術家創作的500 首西方流行音樂,是“強標注”數據集。該數據集共有1 700 條音頻數據,包含174 個音樂標簽,分別為流派、情感、樂器、場景用途、人聲特點等標簽,且對音樂正相關與負相關的屬性標簽均有描述。CAL500數據集提供了兩種標注規則:
①二元標注。根據基本事實標注標簽,若標簽已標注該音樂,則標簽標注值為1,反之,值為0。
②軟標注。每個音樂片段均有3 人以上依照標注規則標注。首先,標注人員認為某標簽符合音樂片段(正相關)則將標注值附為1,反之(負相關),值為-1,若不確定,值為0。其次,將所有的標注值取平均,得到音樂對應標簽的最終權重,若權值為負,則取值0。
(4)MTG數據集
MTG 數據集是最新用于音樂自動標注的數據集[78],由Jamendo平臺在2019年構建。該數據集包含55 701條數據,每個片段數據最少在30 s以上且均以比特率為320 Kbit/s的MP3格式發布,較大的比特率使編碼質量更高,音質更好。音樂標簽共195 個,包含流派、情感、樂器等,所有標簽均由被收錄音樂的藝術家所提供,提高了標簽準確性與專業性。由于數據集是最新發布,僅有少數研究人員使用該數據集驗證模型性能。
由于多標簽音樂自動標注的輸出集合標簽高達2k個,如此龐大的數據量使計算成本急劇加大,需限制標簽數量來緩解該問題。因此,在音樂自動標注數據集中通常使用“前N個用戶最常使用”的前K個標簽作為標注依據[79]。表11歸納了常用公開音樂自動標注數據集。
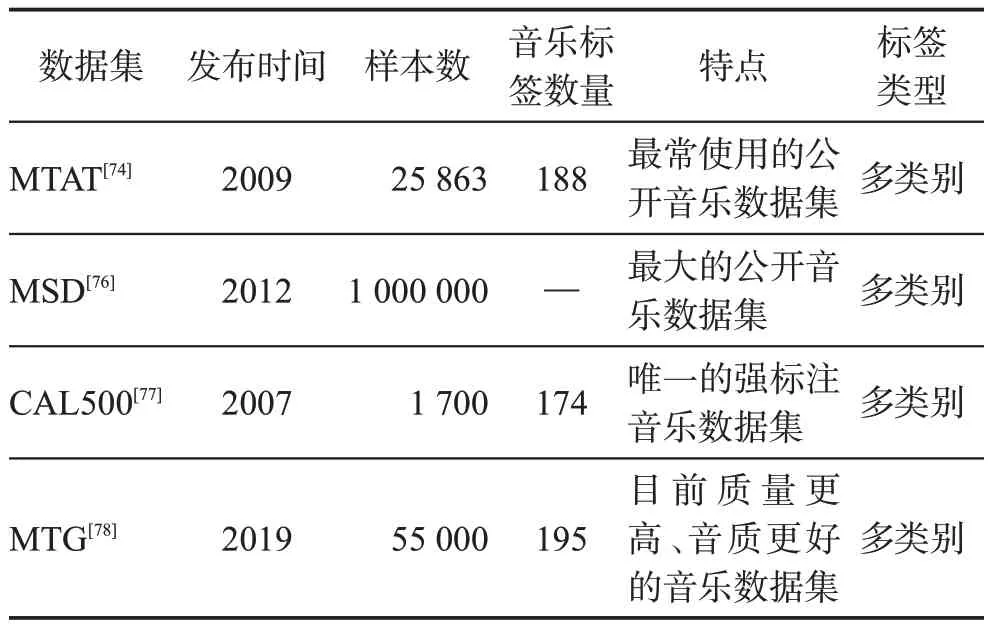
表11 公開音樂自動標注數據集總結Table 11 Summary of open music automatic annotation datasets
5.2 音樂自動標注評價指標
音樂自動標注評價指標是預測模型優劣最直觀的表達,目前有兩種類型評價指標。
(1)二元評價
二元評價是將每個標簽均看作一個二分類問題,即判斷標簽是正確或錯誤,從而預測正確的概率。二元評價通常采用準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1-measure 值作為模型的評價指標。
準確率定義如式(30)所示:
其中,TP(true positive)表示音頻樣本屬于正例且預測為正例,TN(true negative)表示音頻樣本屬于負例且預測為負例,FP(false positive)表示音頻樣本屬于負例但預測為正例,FN(false negative)表示音頻樣本屬于正例但預測為負例,TP+TN+FP+FN為音頻樣本總數。準確率是衡量測試集所有音頻預測為正例的比例。雖然準確率可以判斷總體的正確率,但在樣本不平衡的情況下,不能作為準確的衡量標準。
精確率定義如式(31)所示:
精確率是衡量學習模型預測為正例的音頻中真正正例的比例。精確率可使預測結果準確性進一步提升。
召回率定義如式(32)所示:
召回率是衡量真正正例中被學習模型預測為正例的比例。
F1值定義如式(33)所示:
其中,P為精確率,R為召回率。F1 值與精確率和召回率密切相關,二者值越高,F1 值越高,但從上述公式可知,兩者是相互制約的關系。因此,F1 值是精確率與召回率的調和均值,且F1值越高,模型越有效。
二元評價是判斷預測音頻樣本正例的概率,根據需求為學習模型設置閥值,若概率大于閥值則為正例,反之為負例。然而,當閥值較小時,預測為正例的概率則會增大,使數據產生不平衡性,僅用二元評價指標不能準確地評估音樂自動標注任務的性能。
(2)多元評價
為了排除閥值對標注預測的影響,通常將多元評價作為音樂自動標注模型性能的評價指標[80]。
ROC 曲線又稱接受者操作特征曲線,既可體現閥值不同時的分類效果,也可衡量模型類別分布的性能。它是以假正率(false positive ratio,FPR)為橫軸、真正率(true positive ratio,TPR)為豎軸構成的坐標系,將得到的(FPR,TPR)坐標點連接起來形成ROC 曲線。ROC-AUC 是ROC 曲線的下方面積,僅觀察不同ROC 曲線的凸起程度很難判定模型性能,需使用ROC-AUC值來量化ROC曲線,ROC-AUC的值越大,音樂自動標注性能越好。當正負樣本分布變化時,ROC曲線有很強的魯棒性,可避免樣本不平衡問題,但正因為不會由樣本的改變而影響判定,導致數據偏差較大,所以引入PR-AUC 作為ROC-AUC的輔助評價。
假正率定義如式(34)所示:
假正率是音頻樣本屬于負例但預測為正例與負例實際數量的比例。
真正率定義如式(35)所示:
真正率是音頻樣本屬于正例且預測為正例與正例實際數量的比例。
PR-AUC 則是P-R 曲線的下方面積。PR 曲線是以召回率為橫軸,精確率為縱軸的坐標點的連接線。曲線越接近右上角,模型性能越好。PR 曲線對正樣本較敏感,當數據樣本不平衡且主要關心正例時,PR-AUC的性能準確值優于ROC-AUC,然而當評價指標沒有明確細分的情況下,通常將AUC 看作ROC-AUC。
MAP(mean average percision)是均值平均精度,是所有音頻中所有類別的AP 的平均值。AP 為平均精度,是所有音頻中具體某類的PR曲線下的面積。
對于音樂自動標注任務來說,單個音樂標簽標注所有音頻片段的概率很低,這會使負樣本數量大于正樣本數量,當樣本預測錯誤時會更敏感地影響模型性能。而AUC有較強的魯棒性且可用一維數字直觀明了地表示模型性能,因此,ROC-AUC 與PRAUC是音樂自動標注的常用評價指標。
6 挑戰與展望
通過上述對音樂自動標注的深入分析可知,音樂自動標注是豐富語義標簽的有效解決方案之一,也是MIR 領域內的研究熱點與實用技術,但目前還處在前瞻性階段且面臨一些挑戰:
(1)音樂標簽利用率低。根據歷年實驗發現,所使用的標簽往往只有數據集的前50 個常用標簽,而超過80%的標簽與不到5%的音樂相關聯,導致標簽出現長尾分布形狀。如何使數據集中的所有標簽都能被音樂相關聯,提高標簽利用率值得進一步研究。在之前方法中,研究人員通過有監督的標簽傳播方法提高標簽利用率,為此,可使用半監督與無監督方法對標簽進行傳播,并利用每個標簽之間的相似度獲得上下文信息使標簽進一步關聯,最后調試模型的學習率、動量或批量大小確定影響因素。
(2)對文本標簽操作實施太少。通過梳理目前音樂自動標注研究進展可知,研究人員主要對音頻特征進行改進,對數據集文本標簽改進甚少,如何處理文本標簽使其對模型性能進一步優化還有待研究。Chen 等人[66-67]則對標簽進行改進,利用LDA 模型將音樂標簽聚類來獲取主題類別,運用生成對抗網絡中的衍生模型infoGAN 進行訓練,以此找到音頻特征和標簽之間的映射關系,從而實現對歌曲標簽的標注。未來,可以使用標簽推理等方法進一步使標簽學習相關信息,更好地提高標注準確性。
(3)模態提取特征單一。通過分析看出目前大多數研究人員在單一模態下提取特征信息,雖然這些方法在該模態下標注效果較好,但應用范圍有所限制。僅有少數研究人員使用多模態音樂自動標注,雖可提取到更加全面的特征,但標注性能不盡如人意,進行特征融合時也出現冗余度大等問題。在未來研究中,可同時增加文本、圖像與視頻模態信息,例如音樂發布時間、作者所處地理位置或音樂MV 等信息,挖掘更深層次的語義信息,并且可以在不同維度上進行多特征融合,如何在多模態下既能全面提取特征,又能更好地融合各個模態特征,提高標注性能值得深入探索。
(4)數據集單體化。目前大多數數據集都基于單一類別或單一模態進行創建,通用的數據集已經不能對不同國家地區的文化和語言進行正確標注。例如,蒙古族音樂在曲風、演唱方式等方面都具有較強的民族性與地域性,與主流音樂有很大區別。Song[81]對蒙古族音樂創建數據集,在標注的過程中請專業蒙古族音樂人對音樂進行半結構化標注,提高了標注準確率。基于不同地區的差異與文化,構建多元化數據集還需要進一步研究。
7 結束語
通過音樂自動標注,音樂數據信息可與多種類別語義標簽相對應,它在MIR 領域中的作用至關重要。即使針對音樂自動標注的研究仍處于探索階段,但它為后續任務奠定了基礎,具有重要的發展潛力,有很大的發展空間。論文對目前音樂自動標注領域的研究進展進行了系統梳理。首先,介紹了音樂自動標注的相關知識;其次,對該領域的音頻特征類型及提取方法進行深入探討,并進一步分析機器學習與深度學習不同模型方法的音樂自動標注分類特點;然后整理了該領域常用的數據集及評價指標并總結其特點;最后指出音樂自動標注所面臨的挑戰以及對未來的展望。在數字音樂快速發展的時代,音樂自動標注具有廣闊的發展前景與應用價值,未來會取得一定的成功。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童繪本(2017年24期)2018-01-07 15:51:37
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
東方藝術·大家(2016年6期)2016-09-05 07:30:56
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
河南科技(2014年23期)2014-02-27 14:19:15
數位時尚·環球生活(2009年8期)2009-11-19 09:16:12
